Lec 9 多线程算法分析
总览
分治法
- 主定理
Cilk循环语句
矩阵乘法(TD)
归并排序(TD)
分治法
主定理
The Master Method 是求解分治(divide-and-conquer)递归的方法,用到了递归形式
其中其中a >=1, b > 1
a表示子问题的个数或者递归调用的次数
b 表示每次递归时问题规模的缩小比例
f(n) 是随着 n 增大而趋近正无穷的正函数
当讨论基本情况时,如果n足够小时, T(n) = θ(1)
递归树分析
用递归树可以比较容易理解主定理
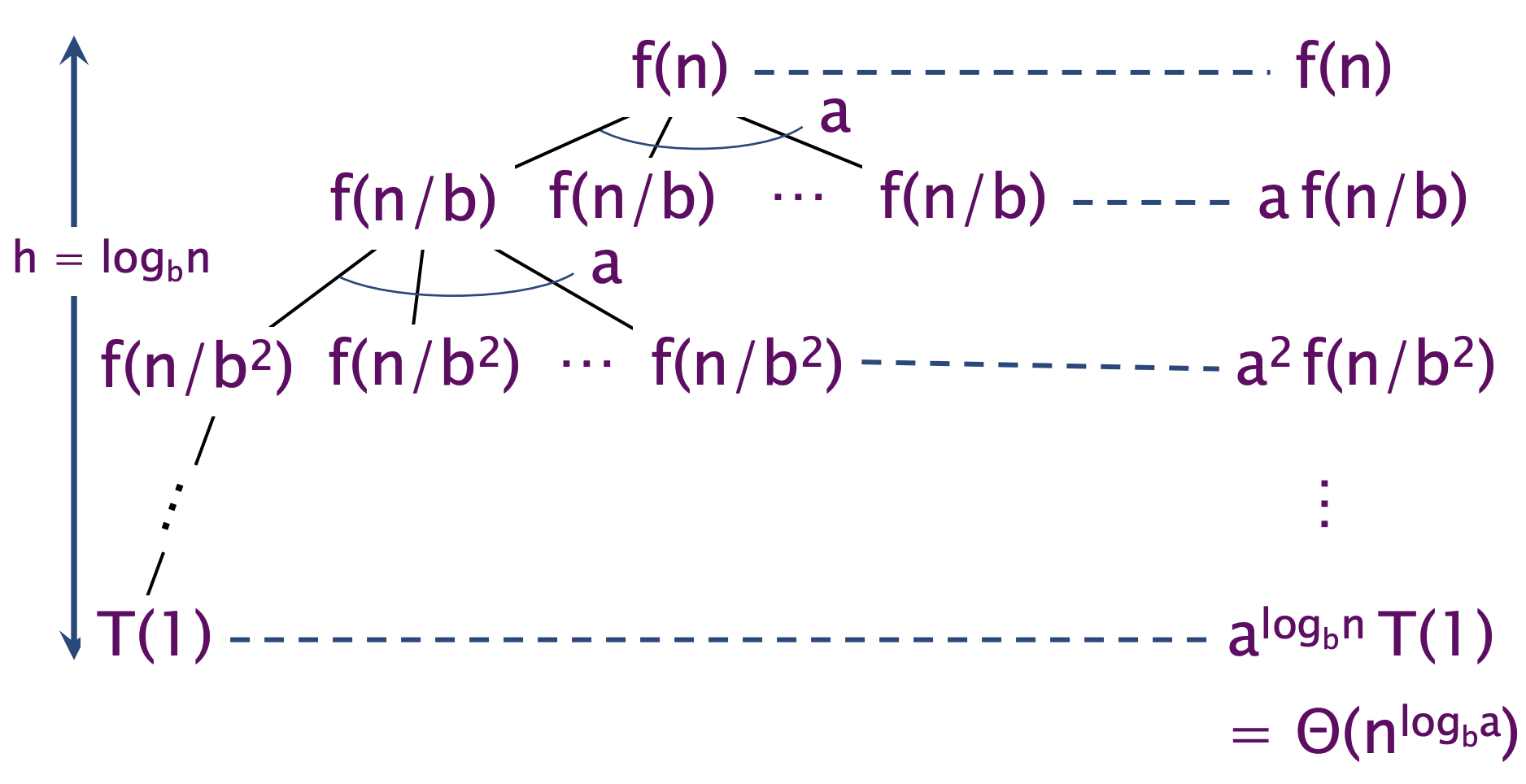
在递归树分析中,叶子结点表示递归结束时最小问题规模。主定理中的叶子节点数是由递归的深度决定的,为
关键是: 将 $n^{\log_b{a}} $与 f(n) 进行比较
Case 1:$n^{\log_b{a}} \gg f(n)
n^{\log_b{a}}$比 f(n) 快得多。 更具体来说, , 是一个常数 Case 2$n^{\log_b{a}} \approx f(n) $,表示 f(n)以相似的增长速率增加(代数增加)。更具体来说,
,其中某些$ k \ge 0$ 成立 Case 3: 指数级下降, $n^{\log_b{a}} \ll f(n)
f(n) = \Omega(n^{\log_b{a}+\epsilon}) \epsilon > 0$成立,且 满足如下的正则性条件:对于某个常数 ,有
总结

测验

Cilk循环语句
示例: 矩阵的原地转置
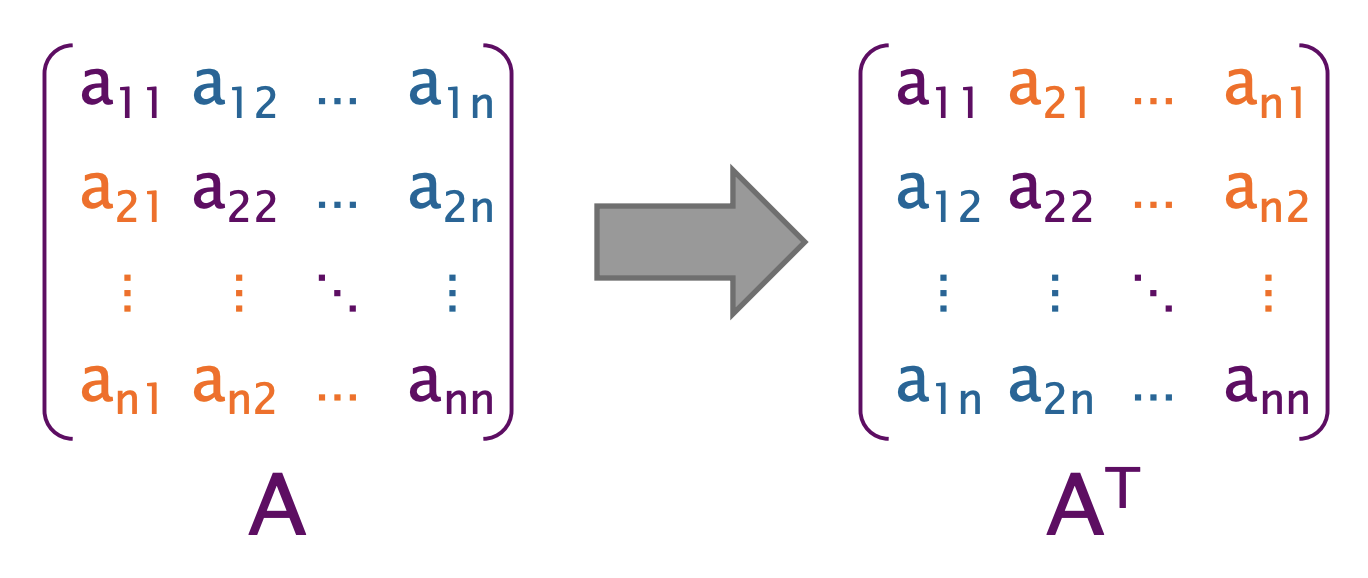
// indeces run from 0, not 1
cilk_for (int i = 1; i < n; ++i) {
for (int j = 0; j < i; ++j) {
double temp = A[i][j];
A[i][j] = A[j][i];
A[j][i] = temp;
}
}我们会发现工作量是不均匀的,而Tapir/LLVM 编译器在-O1或以上实现了cilk_for循环的优化
void recur(int lo, int hi) {
if (hi > lo + 1) {
int mid = lo + (hi - lo) / 2;
cilk_spawn recur(lo, mid);
recur(mid, hi);
cilk_sync;
return;
}
int i = lo;
for (int j = 0; j < i; ++j) {
double temp = A[i][j];
A[i][j] = A[j][i];
A[j][i] = temp;
}
}
recur(1, n);他做的就是找到一个中间点,然后递归调用自己,类似树分裂一样。
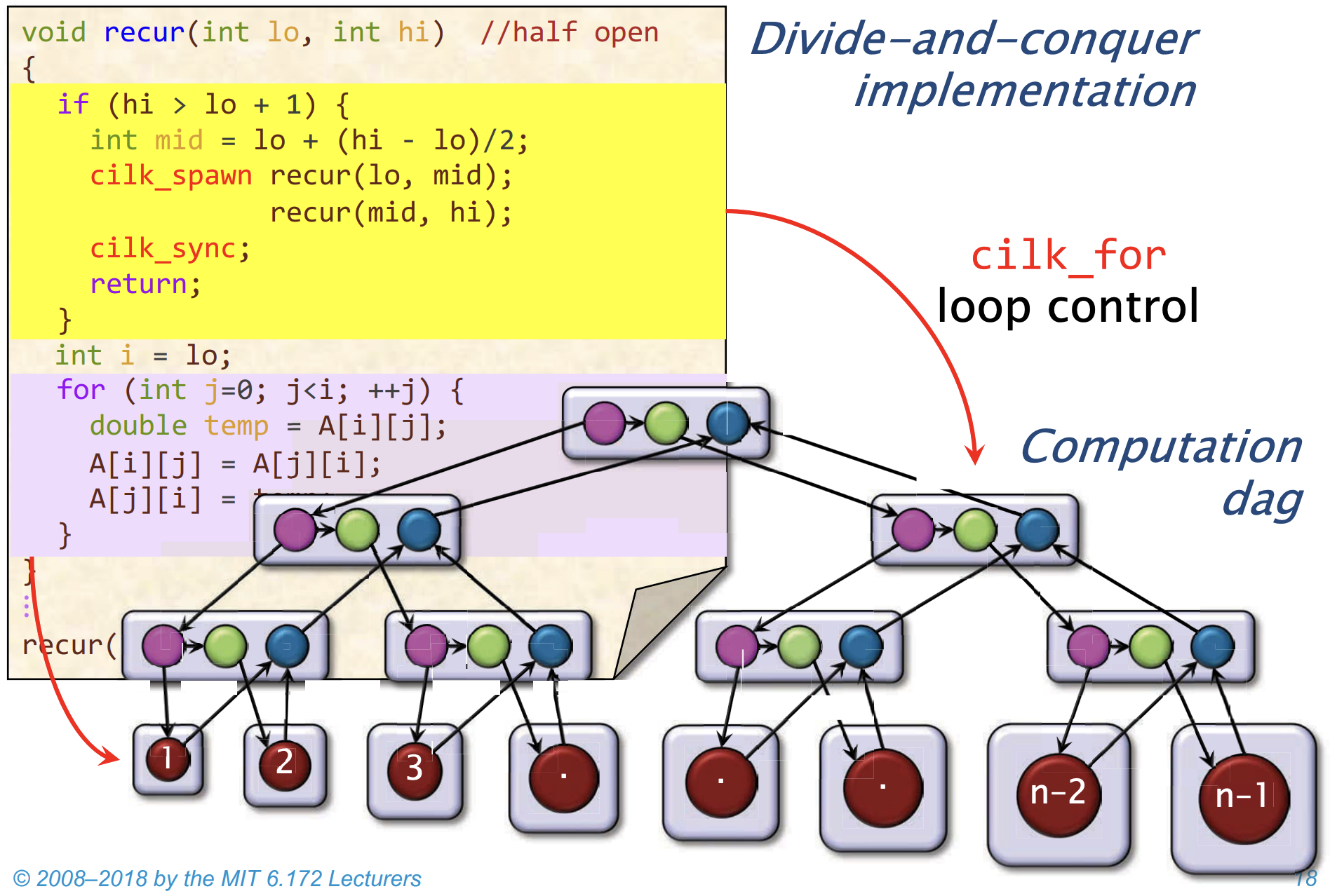
recur 通过二分法拆分范围,生成对数层级的递归调用树,因此 控制结构的跨度是 =
主循环内的操作涉及数组元素的交换。最坏情况下,该循环的计算复杂度:
- 工作量:
- 关键路径:
= - 上图最右边的叶子结点,从上到下然后返回,需要
- 执行叶子结点需要
- 上图最右边的叶子结点,从上到下然后返回,需要
- P并行度:
, 这很棒! : )
如果我们不仅仅并行化外循环,而且也内循环呢?
// indeces run from 0, not 1
cilk_for (int i = 1; i < n; ++i) {
clik_for (int j = 0; j < i; ++j) {
double temp = A[i][j];
A[i][j] = A[j][i];
A[j][i] = temp;
}
}NOTE
一个经验,并行化的工作,一般来说不能改变工作量(而且可能还会增加同步,生成子任务的工作量),它所做的只是减少计算的跨度,通过减少跨度,让每个工作尽可能均匀,从而达到很大的并行度。
外循环控制结构的跨度是 =
内循环最大控制结构的跨度是 =
Span of Body =
- 工作量:
- 关键路径:
= - 上图最右边的叶子结点,从上到下然后返回,需要
- 执行叶子结点需要
- 上图最右边的叶子结点,从上到下然后返回,需要
- 并行度:
, 比上面的方法更好!: )
NOTE
一个经验, 并行度越大就真的加速得越好吗? 不一定的,并行就像是一个极限,还记得并行宽容度吗?并行宽容度 = 并行度 / 处理器数量,这个值越大越好。如果你的并行度足够大了,比处理器数量大得多,那你就没必要搞内循环的并行了。
示例:向量加法
clik_for (int i = 0; i < n; ++i) {
A[i] += B[i];
}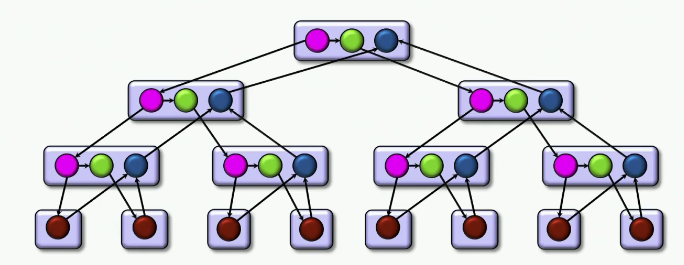
- 工作量:
- 包含了大量的开销
- 关键路径:
- 并行度:
粗化并行循环
粗化并行循环(Coarsening Parallel Loops, 自己翻译的)
#prama cilk grainsize G
cilk_for (int i = 0; i < n; ++i ) {
A[i] += B[i];
}通过这种方式,编译器会将其优化成(类似)如下代码,如果未指定粒度(grainsize)指令,Cilk 运行时系统将自行进行最佳猜测,以最小化开销。
void recur(int lo, int hi) { // half open
if (hi > lo + G) {
int mid = lo + (hi - lo) / 2;
cilk_spawn recur(lo, mid);
recur(mid, hi);
cilk_sync;
return;
}
cilk_for (int i = lo; i < hi; ++i ) {
A[i] += B[i];
}
}
...;
recur(0, n);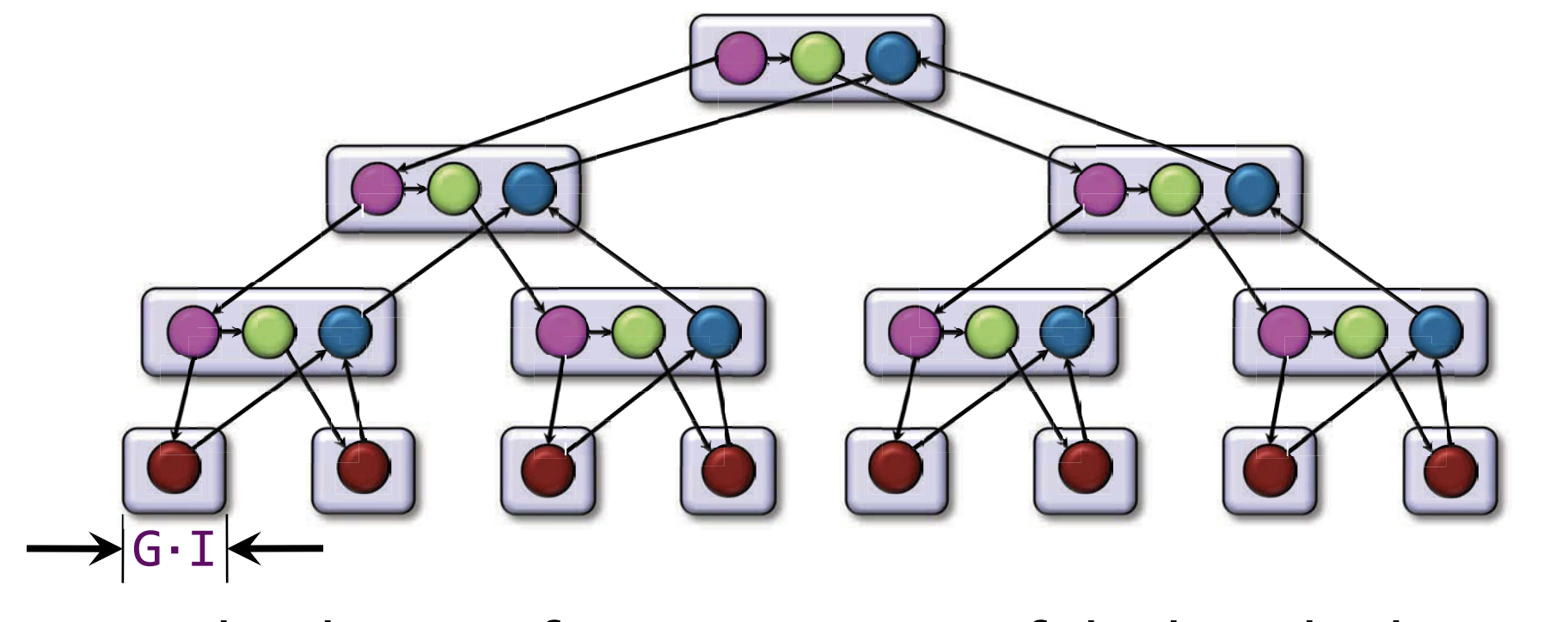
设
- 主要成本来自三次内存操作和一次加法运算 A[i] += B[i]
设 spawn和return的时间。
分析:
工作量: $T_1 = n · I + ( n / G - 1) · S $
n次迭代= 叶子节点数量
n / G 表示将所有 n 次迭代划分为多少组,也就是需要生成多少个任务
n / G -1 :代表的是生成的子任务的数量,减去 1 表示初始任务不需要生成自己
执行所有循环体所需的时间 + 是并行执行中由任务生成和同步带来的开销
关键路径: $ T_{\infty} = G · I + \lg(n/G) · S $
- n 总迭代次数,G粒度
- n/G 子任务数量,
就是任务生成层数
我有两件事想解决:
- 我希望工作量尽可能小,尽可能为n · I
- 我希望关键路径越小越好
对于工作量而言G越大越好,而对于关键路径而言,希望G越小越好,他们朝着相反的方向,根据等式我们计算结论,在 $ G \gg S / I$基础上G尽可能小
另外一种实现clik_for循环
void vadd(double *A, double *B, int n) {
for (int i = 0; i < n; i++) A[i] += B[i];
}
....;
for (int j = 0; j < n; j += G) {
clik_spawn vadd(A + j, B + j, MIN(G, n-j));
}
clik_sync;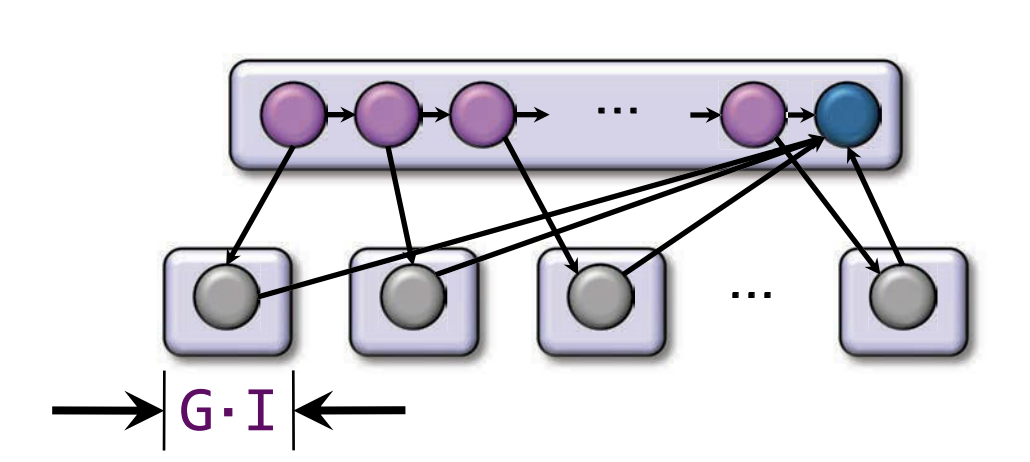
cilk_spawn 函数里面有一个循环,因此它是G次迭代
假设
工作量:
关键路径:
并行度:
, 不嘻嘻了 : (
IMPORTANT
【定理】Trip Minimizing 是指在并行算法中,当你将工作划分为过多的小任务时,会导致调度和同步的开销相对较高,你没有减少span路径
再分析一下G,
工作量:
关键路径:
- 求导可知 $G = \sqrt{n} $可以 有极小值
并行度:
Quiz
设 P 为处理器刷领,代码A,B的并行性相比如何?
Code A
c#prama cilk grainsize 1 cilk_for (int i = 0; i < n; i += 32) { for (int j = i; j < MIN(i + 32, n); ++j) A[j] += B[j]; }Code B
c#prama cilk grainsize 1 cilk_for (int i = 0; i < n; i += n/P) { for (int j = i; j < MIN(i + n/P, n); ++j) A[j] += B[j]; }
Solution:
分析A代码:
工作量
关键路径
并行度:
分析代码B:
工作量
关键路径:
并行度:
总结——性能技巧
最小化跨度以最大化并行性:尝试生成比处理器数量多 10 倍的并行性,以实现接近完美的线性加速。
如果有大量并行性:尝试牺牲一些并行性以减少工作开销。
使用分治递归或并行循环:而不是一个接一个地生成小任务。

确保工作量 / spawn数量 的比值足够大。 • 通过使用函数调用和在递归的叶子节点附近内联来进行粗化,而不是生成任务。
如果必须做出选择:优先并行化外层循环,而不是内层循环。

注意调度开销。
经典例子: 矩阵乘法
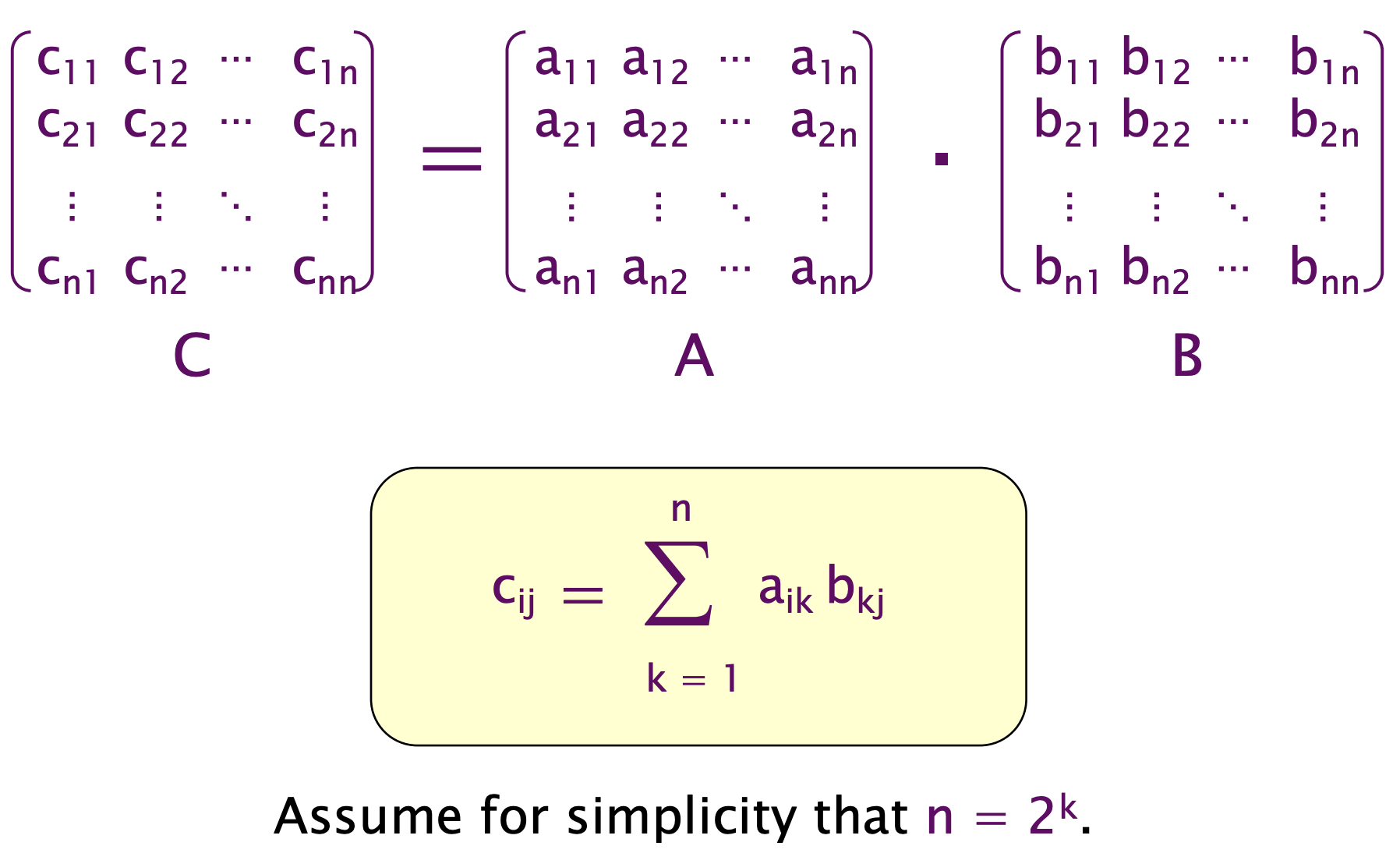
一个很自然的想法
cilk_for (int i = 0; i < n; ++i) {
cilk_for (int j = 0; j < n; ++j) {
for (int k = 0; k < n; ++k)
c[i][j] += A[i][k] * B[k][j];
}
}分析:
Work:
Span:
Parallelism:
用递归分治
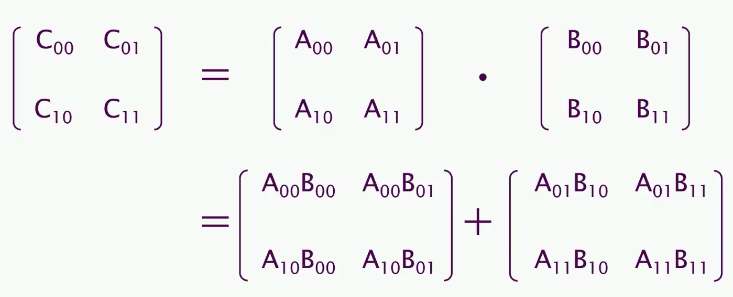
- 8次 n / 2 * n / 2矩阵的乘法
- 1次 n * n矩阵的加法
首先我们先了解如何索引每个元素
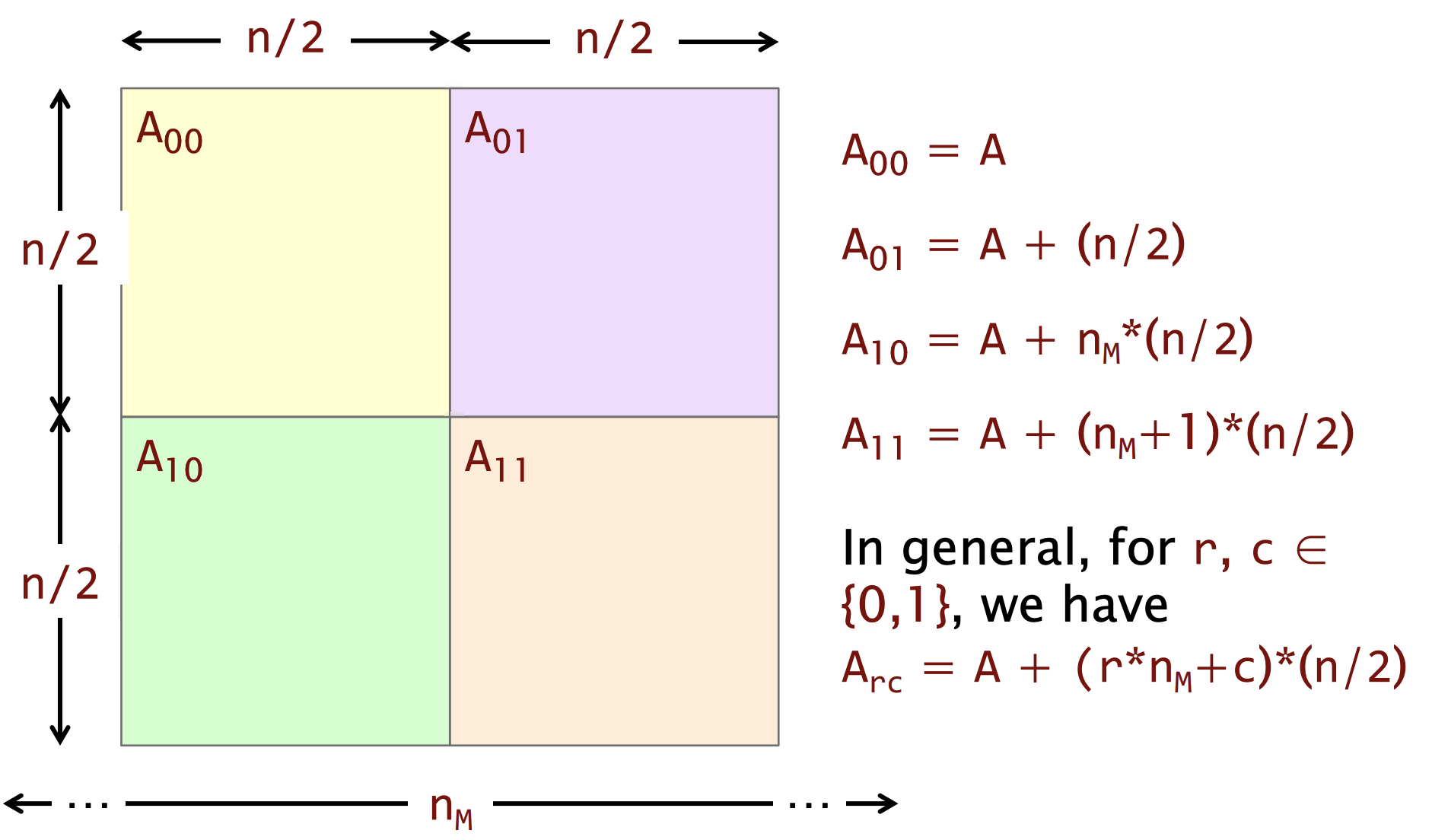
最终代码(TODO)