Lec 7 多核编程
Leiserson, Charles. “The Cilk++ Concurrency Platform.” The Journal of Supercomputing 51, no. 3 (2010): 244–257.
Frigo, Matteo, Charles Leiserson, and Keith Randall. “The Implementation of the Cilk-5 Multithreaded Language.” Proceedings of the 1998 ACM Sigplan Conference on Programming Language Design and Implementation (PLDI) (1998).
Leiserson, Charles and Ilya Mirman. “How to Survive the Multicore Software Revolution (or at Least Survive the Hype) (PDF - 3.5MB).”
大纲
- 共享内存的硬件
- 并发平台
- Pthread库(和WinAPI Thread)
- 线程构建块
- OpenMP
- Cilk Plus
引言
Intel Haswell-E架构
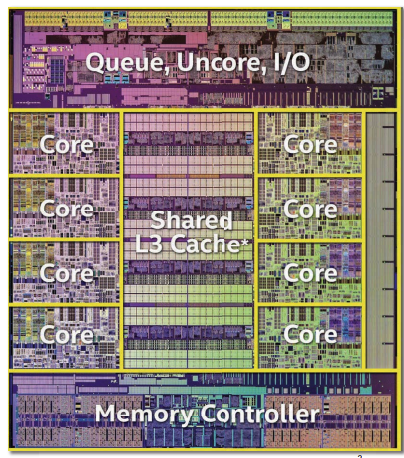
Question: 想想为什么半导体提供商处理器芯片是多核的呢? Ans: 由于在2004年左右晶振频率的达到了瓶颈(4GHz左右,存在“漏电流增加”,导致电压、功耗、温度极具增加),而根据摩尔定律的发展规律来说,时钟频率瓶颈虽然限制了,但可以通过增加核心数量来提高整体处理能力,适应对性能的要求。 能效上讲,多核设计也有助于提高处理器的能效。相对于提高单个核心的时钟频率,使用多个较低频率的核心更为能效,因为更低的时钟频率通常意味着更低的功耗和发热。
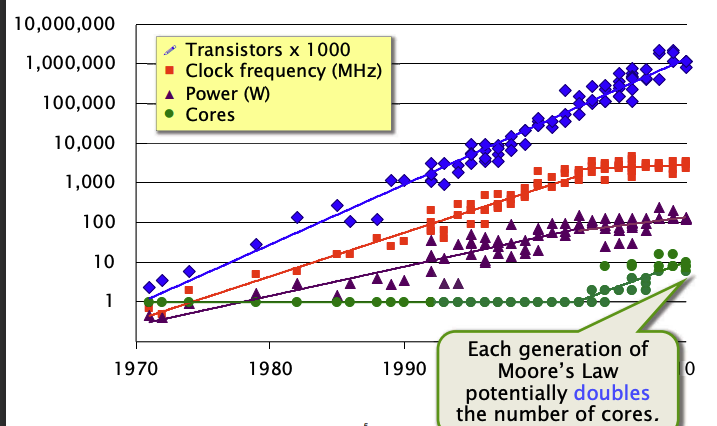
上图可以发现,摩尔定律的每2年迭代潜在伴随着核数量的翻倍。也就是说,核数量的增加是2004年后为摩尔定律继续生效的关键因素。
多核处理器架构的抽象
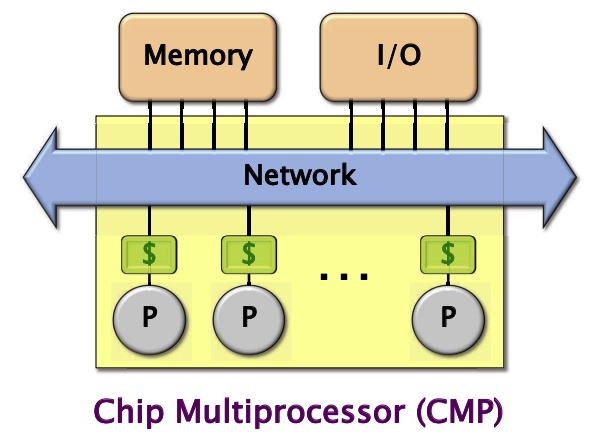
片上Cache结构是多核处理器的重要内容,每个核有自己的私有 Cache(L1和L2, 假如L2 Cache共享则称其为片上共享Cache,因效率低,不常用),且拥有共享cache(L3)连接到一起,通过这个网络可以共享同样的主存空间;这里I/O通常是划分到另外的网络上,因此共享了I/O接口
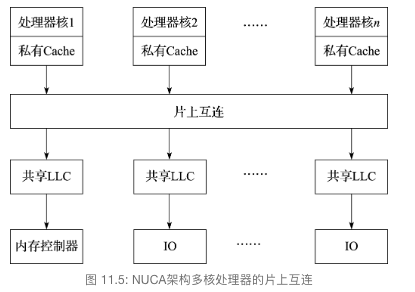
共享内存硬件
计算模型
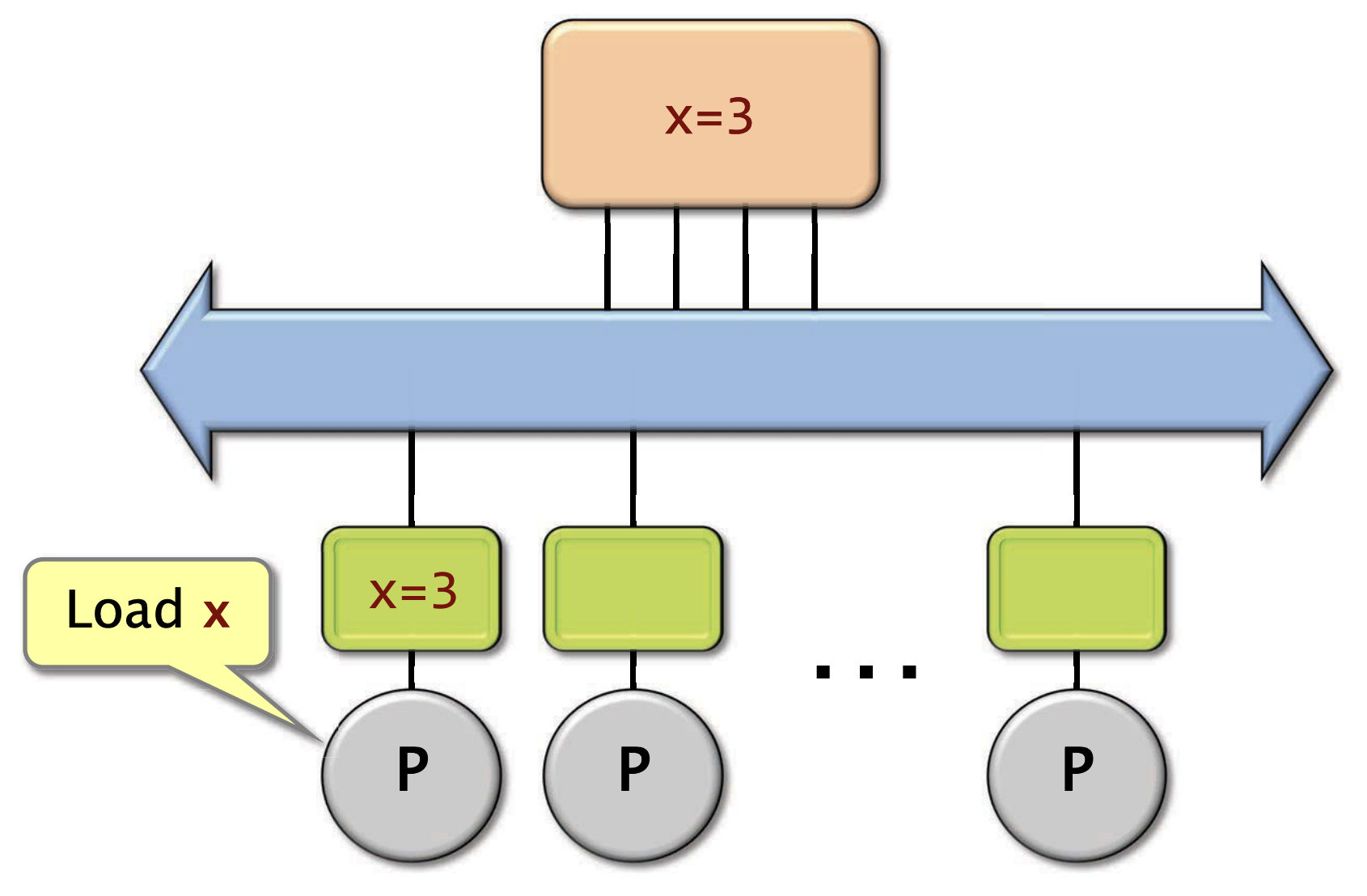
缓存一致性问题这里不赘述,最简单的解决方法是MSI协议。每个Cache行(一般是64B,有些可能是128B)都带上脏位的标记:有三种状态
- M(modified): cache块已经被改变了,没有其他缓存以M或S的状态包含这块区域
- S(shared): 其他caches可能正共享这块cache块
- I(invalid): 该cache块无效(可看作不在)
在一块cache改变一个位置前,硬件会将无效化其他所有的副本,将状态S改成I;
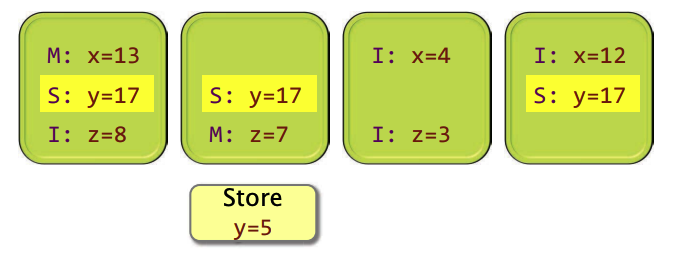
并且将申请更改缓存的CPU的对应的cache line的脏位从S改成M,并更新缓存内容(y=5)
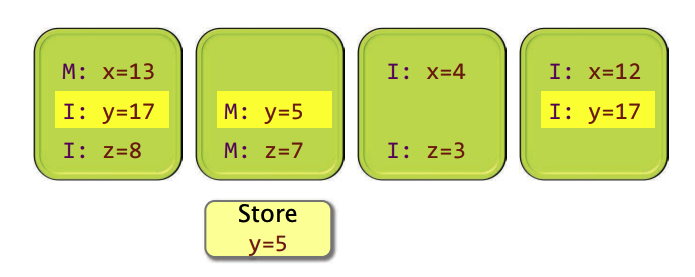
在CPU视角下,什么情况下可以直接读/LOAD?
如果状态是S或着M则可直接读,否则需要从另外一个核,或者主存中读取。
上述是最简单的缓存一致性算法。其他一些
- MOESI
- MESI
并发平台
直接在处理器核心上编程既痛苦又容易出错。并发平台则对处理器核心进行了抽象,处理同步和通信协议,并执行负载平衡。
Pthreads
是线程的标准API,所有基于Unix的计算机都支持
- 如果用微软的产品,WinAPI也用类似的方法。
Do-it-yourself(自己动手)的并发平台
用特殊的非C的语法实现库函数
每个线程用来实现一个处理器核心的抽象,这些处理器核心被多路复用到机器资源上(线程一般比处理器核心要多);
线程之间的通信通过共享内存
库函数隐藏了涉及到线程之间协调的通信协议;
int pthread_create(
pthread_t *thread,
// reutrn identifier for the new thread
const pthread_attr_t *attr,
// object to set thread attributes(NULL for default)
void *(*func)(void *),
// routine executed after creation
void *arg
// a single argument passed to func
) // return err status
int pthread_join(
pthread_t thread,
// identifier of thread to wait for,
void **status
// terminating thread's status (NULL to ignore)
) // return err status例子
Pthreads的限制
| 性能损失大 | 新建一个thread的需要大于 |
|---|---|
| 伸缩性差 | 如果运行在核数更多的机器上,我们可能需要重写一下代码 |
| 模块化被破坏 | Fib的逻辑将不能整洁的封装到fib()函数中了 |
| 代码变得臃肿 | 程序猿需要序列化参数,并且为了方便负载均衡,程序猿可能会被卷入到容易出错的协议中(缓存一致性 ) |
线程构建块(TBB)
Threading Building Blocks
由Intel开发并发库
用C++实现,运行在原生的thread之上
程序猿指定tasks而非thread
Task是自动进行负载均衡的,是由线程间用到了工作偷窃(work-stealing)算法
- 实际上也是收到MIT cilk的启发
专注性能
示例

其他TBB的特性
- TBB提供了很多C++模版来简化表达常见的模式,比如
- parallel_for: 循环并行
- parallel_reduce: 用于数据聚合
- pipeline 和 filter: 用于软件流水线
- TBB提供了并发容器类,使得多线程能够安全并发访问和更新其中的元素
- TBB还提供很多互斥的库函数,比如lock和atomic updates
OpenMP
相比之下,这是语法层面的解决方案
行业联盟制定的规范接口
跨平台,多种编译器都适用,GCC、Clang等等
供了对 C、C++ 和 Fortran 语言的扩展,以支持并行编程。编译器指令通常以
#pragma形式出现,这是一种编译器特定的指示,用于告知编译器如何处理下面的代码段。在 OpenMP 中,#pragma omp用于表示 OpenMP 指令OpenMP 可以在原生线程(native threads)的基础上运行。这意味着 OpenMP 代码可以在支持线程的系统上运行,并利用这些线程进行并行执行
OpenMP 提供了多种并行模型,包括
循环并行性(loop parallelism)
任务并行性(task parallelism)
流水线并行性(pipeline parallelism)
示例

- omp:表示这是编译器指令
- task: 下面语句是单独的任务
- shared:显式管理共享的内存块
- taskwait:在上面两个任务完成后在继续
OpenMP 提供多种 pragma 指令来表达常见的模式,例如:
parallel for用于循环并行化,reduction用于数据聚合,- 还有用于调度和数据共享的指令。
OpenMP 还提供了多种同步构造,例如:
- 屏障同步,
- 原子更新,
- 以及互斥锁 (mutex locks)
Cilk
Cilk Plus 中的 "Cilk" 部分是对 C/C++ 进行的语言扩展,以支持 fork-join 并行模型。(“Plus" 部分提供了对矢量并行性的支持)
有MIT衍生公司Cilk Arts公司开发,在2009年被Intel收购
基于 MIT 开发的且获奖无数的 Cilk 多线程语言
Cilk Plus 包含一个被证明高效的工作窃取调度器。工作窃取是一种并行任务调度策略,其中空闲线程从其他线程的任务队列中“窃取”任务执行,以保持处理器的高效利用
Cilk Plus 提供了一个 hyperobject 库,用于支持对具有全局变量的代码进行并行化
Cilk Plus 生态系统还包括 Cilkscreen race detector(检测并发竞争条件的工具)和 Cilkview scalability analyzer(分析并行可扩展性的工具)等工具。
后续我们将适用opencilk平台,它是基于Tapir/LLVM编译器,使用了Intel的Cilk Plus 运行时系统(runtime system),它还支持其他特性比如spawning of code blocks。
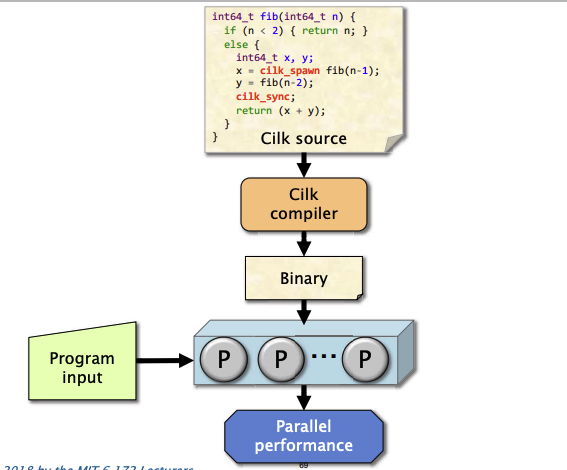
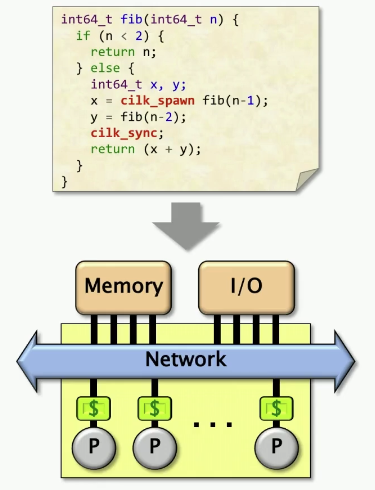
示例:Fib

cilk_spawn: 当你在父函数中调用某个子函数并使用 cilk_spawn 时,该子函数(称为“子任务”)可以与父函数并行执行(但并不是并行运行的指令)。父函数不会等待子任务完成,而是继续执行接下来的代码。(BTW: spawn有”生成“,”产卵“意思)
cilk_sync: 控制流在遇到 cilk_sync 时会暂停,直到之前使用 cilk_spawn 生成的所有子任务都返回。也就是说,程序在这点之前必须确保所有并发执行的任务已完成。
cilk_for: 循环的每次迭代都可以并行执行
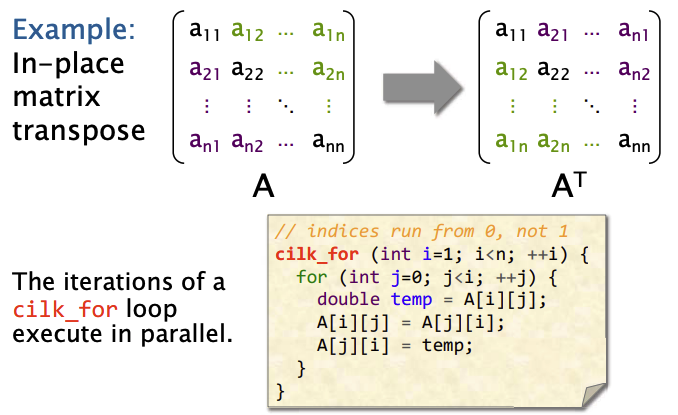
示例: 矩阵转置
我们在看另外一个例子,累加和。第一段代码是否能得到正确的答案?不能。 因为每个迭代它不是独立的,依赖于其他迭代的结果,我们称之为确定性竞态(determinacy race),多个处理器核会同时向同一块内存空间写入数据。
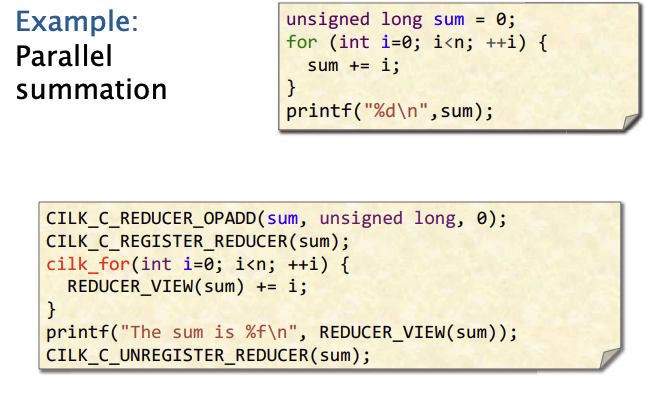
超对象——reducer
下面一段,是一个超对象(hyperobject)的例子, 我们首先声明我们要创建一个加法型的reducer。
关于reducer的创建,还有一种方法是用Monoid(一种元素的集合,函数式编程经常有这种概念,满足结合律和幺元,自行google),Cilk除了有加法型的,还有乘法型、min/max型,and/or/xor型等等,我们也可以定义自己的reducer。
Cilk 程序的串行版本始终是程序语义的合法解释。记住,Cilk 关键词仅授予并行执行的许可,而不是强制并行执行。
#define cilk_for for
#define cilk_spawn
#define cilk_sync调度
- Cilk 并发平台允许程序员在应用中表达逻辑上的并行性。
- Cilk 调度器在运行时动态地将执行中的程序映射到处理器核心上。
- Cilk 的工作窃取调度算法被证明是高效的。
常用工具
Cilkscan 可以定位确定性竞争(determinacy races)
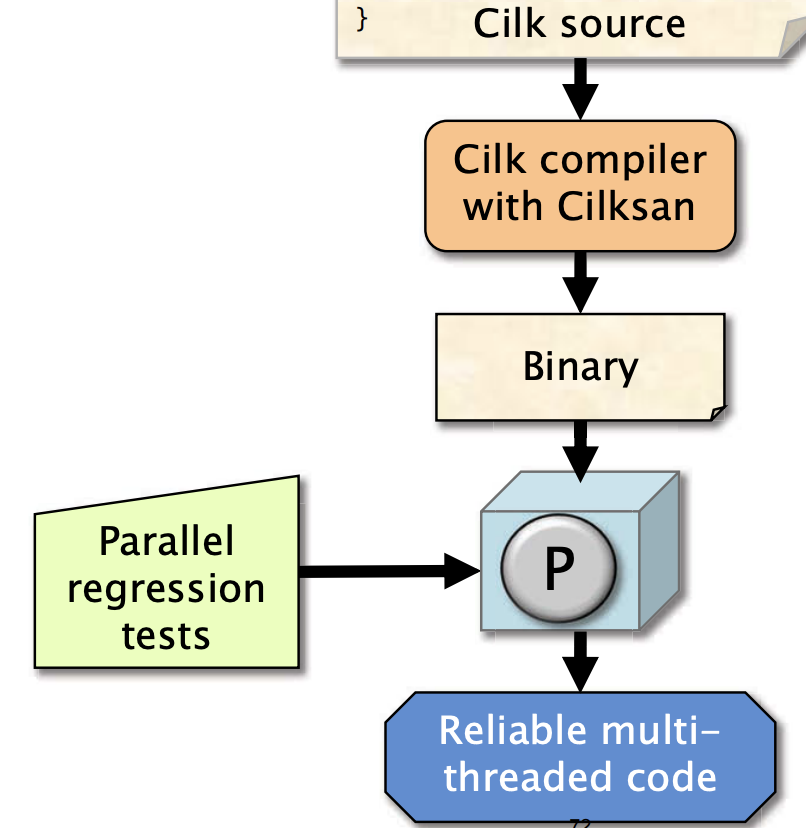
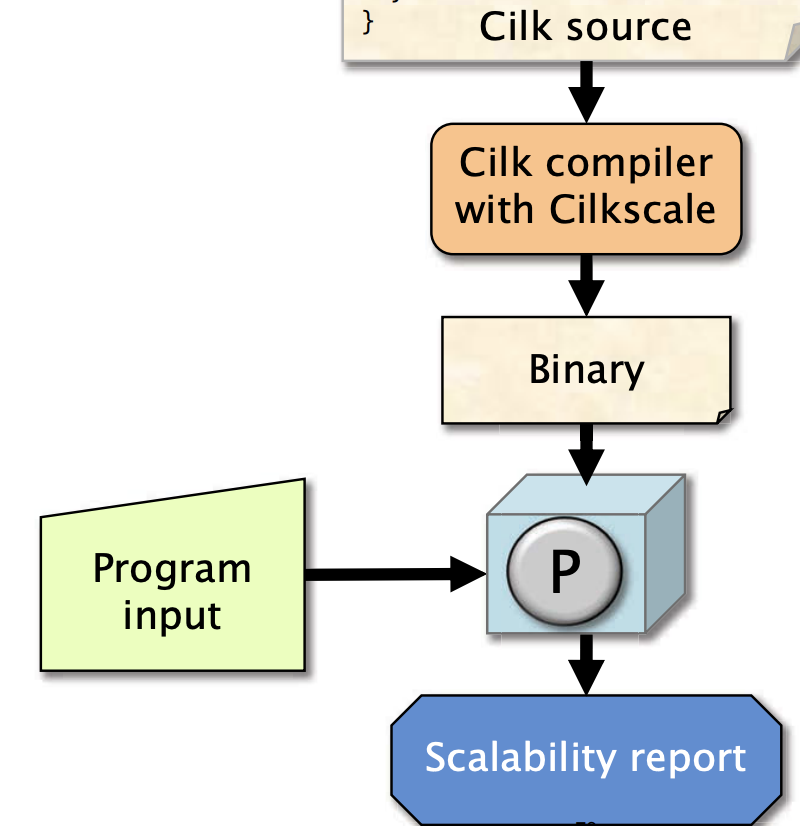
Cilksccle 用于分析程序在更大规模机器上扩展的效果
总结
- 当今的处理器基本都是多核架构,追求高性能需要并行编程
- 直接对每个处理器核心编程是很痛苦且容易犯错的
- 介绍了当前并发平台,及其使用方法
- Clik抽象了处理器核心,能够处理同步和通信协议,并且在负载均衡(一种工作窃取算法)上表现出色