Lec 3 比特运算技巧
比特范围的操作符有
- 与或非&,|, ~
- 移位 << , >>
- 异或 ^
Outline
- 掩码操作
掩码操作
- 设置第k个bit
- 清除第k个bit
- 翻转第k个bit
- 提取一个bit字段
- 设置一个bit字段
设置第k个Bit
问题:将x第k个bit设置成1
💡💡思路: 左移 + 并
y = x | (1 << k);
清除第k个bit
问题:清除第k个比特
💡💡思路: 左移,补码 + 并
y = x & ~(1 << k);
翻转第k个bit
问题: 将x的第k个bit进行翻转
💡💡思路: 左移 + XOR(异或)
y = x ^ (1 << k)
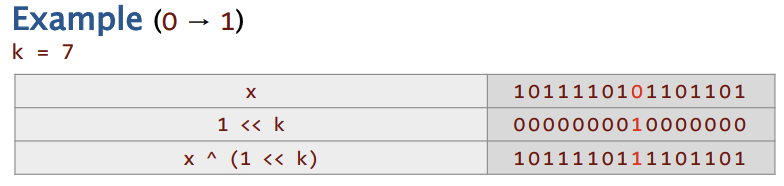
提取bit字段
问题: 从一个字x中提取一个位字段
💡💡思路:掩码和移位技术
(x & mask) >> shift;
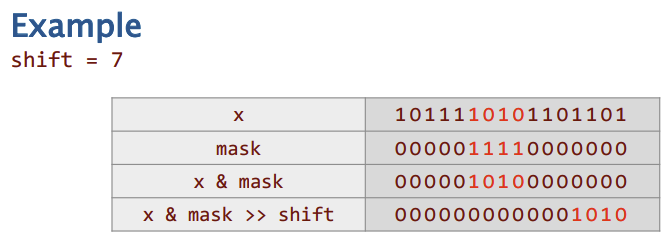
设置一个bit字段
问题: 在字x中设置一个比特字段
💡💡思路: 将掩码去反清除,OR 和 将值进行移位
x = ( x & ~mask) | ( y << shift);

2的幂
我们可以利用一串2进制性质(POWERS OF 2)解决一些问题。
最低有效位
这个问题的目的是计算一个数字(word)中最低有效位为1的掩码(mask)。换句话说,就是找到一个整数中的最右边的 1,并生成一个二进制掩码,其中只有这个最低的1位是1,其他位都是0。等效说,能整除x的最大2的幂是多少?
💡思路,由于 -x = ~x + 1
r = x & (-x);
试问是第一个比特?或者说
= ?
Solution: 这就引出的新的问题,怎么计算
已知r是2的幂,快速求出它是几次幂
deBruijin序列
德布鲁因序列(deBruijin sequences)s 的长度为
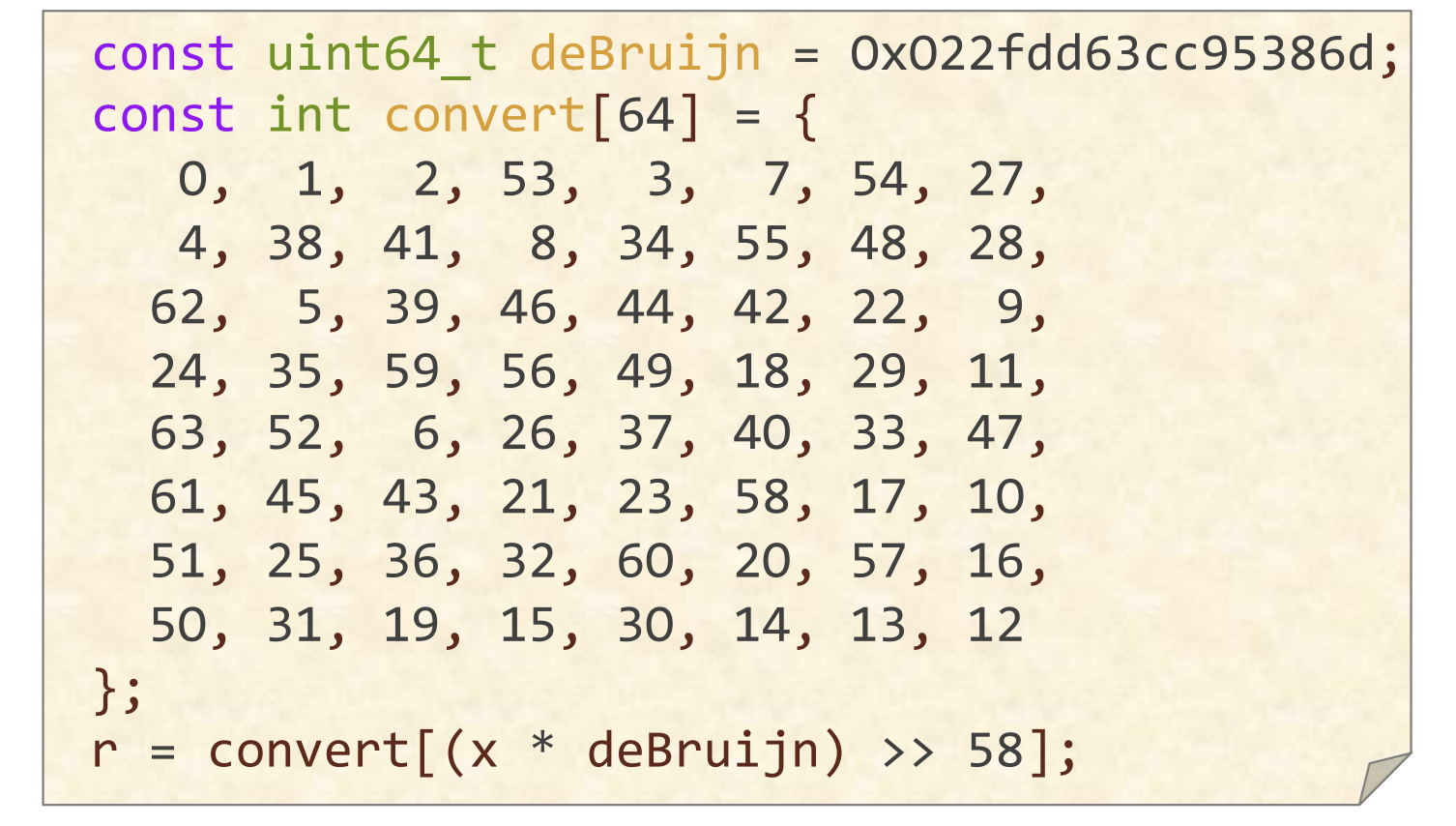
当k = 3时,所有长度为 3 的二进制字符串有 000, 001, 010, 011, 100, 101, 110, 111。一个可能的 de Bruijn 序列是 00011101。该序列在循环时,包含了所有可能的长度为 3 的二进制子串。

现在我们创建一个长度为8的转换表,里面的元素代表序列的索引
const int convert[8] = {0, 1, 6, 2, 7, 5, 4, 3};我们的问题是如何计算, 怎么计算
- 将其与deBruijin序列相乘,
- 提取出前面3位,也就是右移5位实现,
- 通过转换表即可得到结果,
NOTE
可以使用硬件指令获取
int __builtin_ctx(int x);
计算
无临时值交换
交换两个变量的值,传统的我们需要
t = x;
x = y;
y = t;我们可以通异或进行无中间值的交换
x = x ^ y;
y = x ^ y;
x = x ^ y;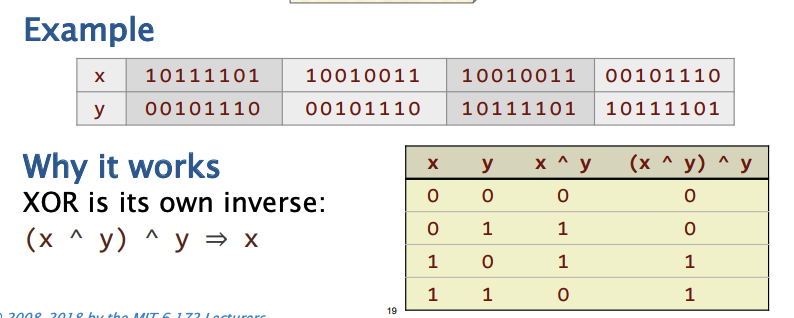
y = (x ^ y) ^ y = x ^ (y ^ y) = x ^ 0 = x
虽然这个方法巧妙,但其性能并不理想,原因在于指令级并行性(ILP),具体来说,这里有数据依赖。
无分支求最小值
传统方法
if (x < y) r = x;
else r = y;
// or
r = (x < y) ? x: y;性能分析: 一次错误预测的分支会清空处理器的流水线。
无分支的方法
r = y ^ ((x^y) & -(x < y));分析:
- 在C语言中,true是1,false 是 0
- 如果
x < y那么有-(x < y) ) => -1,也就是全为1的补码,因此我们可以得到y ^(x ^ y) => x - 反之则有
y ^ 0 => y
示例: 归并两个数组
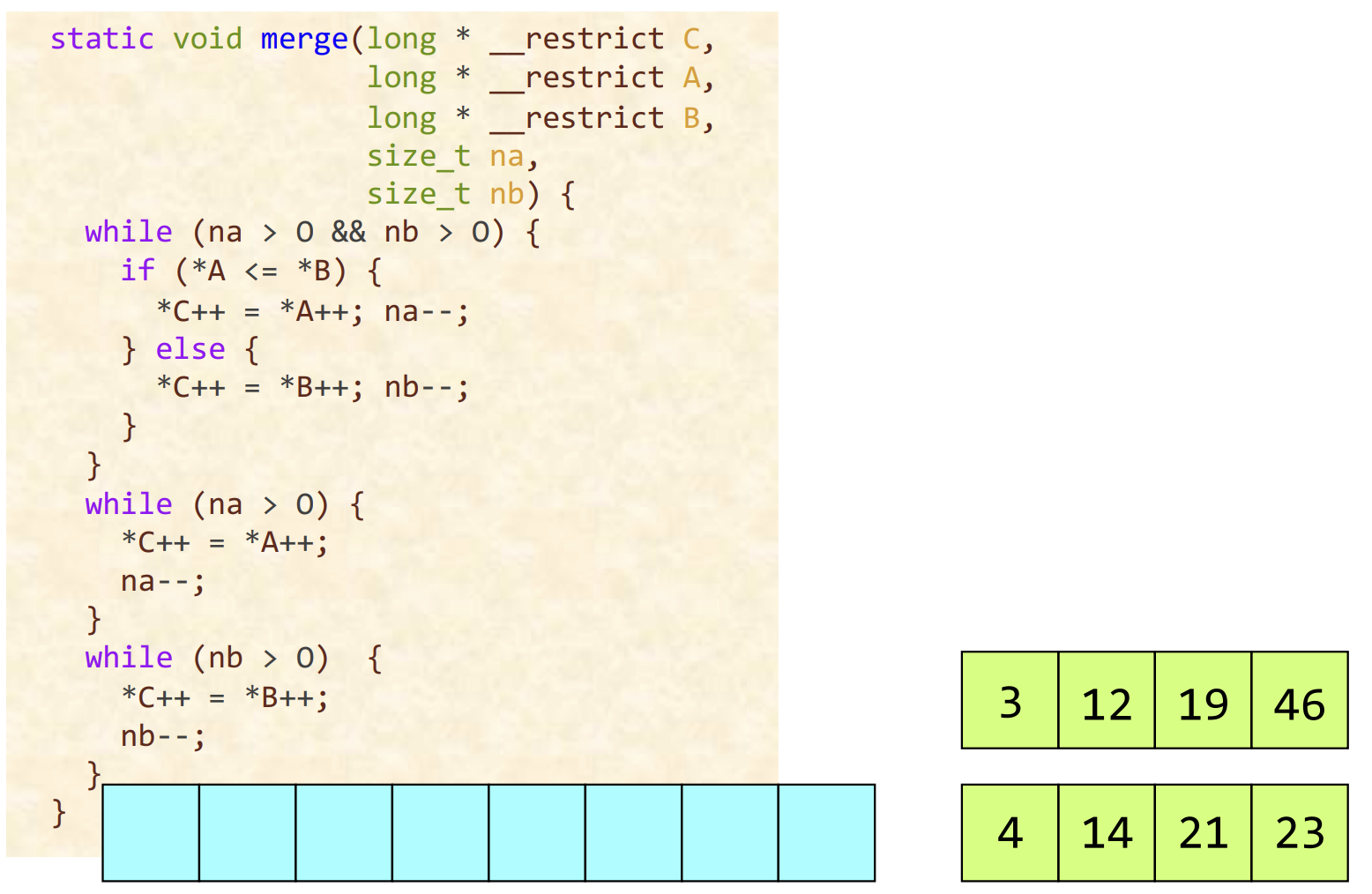
- __restrict 是一种指针限定符,用来告诉编译器,指向的内存不会通过其他指针进行修改。这种提示允许编译器进行更激进的优化,从而提高程序的性能
restrict主要用于C99及以后的标准,在C++中并不原生支持。
问题:这几个分支语句是否可预测?
分支可预测是说,大多数情况下是可以判断的,除了最后一次,那么我们说这是可预测的分支
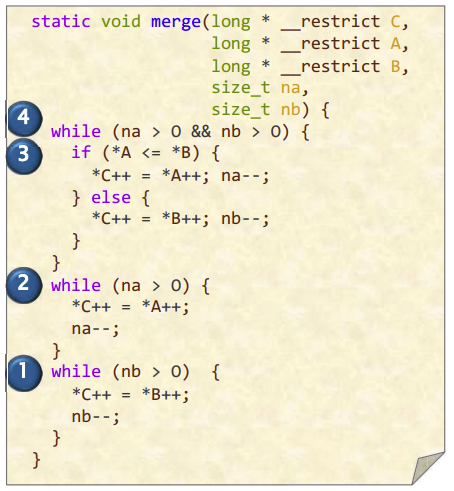
Solution:
| 分支 | 可预测? |
|---|---|
| 1 | Yes |
| 2 | Yes |
| 3 | No |
| 4 | Yes |
这种优化在某些机器上效果很好,但是在使用clang -O3的现代机器上,无分支版本通常比有分支版本更慢。现代编译器通常能比你更好地完成这种优化!

那为什么要学习位运算技巧,如果它们甚至不起作用?
- 因为编译器会执行这些操作,理解这些技巧有助于你在查看汇编代码时明白编译器在做什么。
- 因为有时编译器不会进行优化,你不得不手动进行优化。
- 因为很多针对字(words)的位运算技巧可以自然地扩展到向量的位和字操作。
- 因为这些技巧在其他领域也会出现,所以了解它们是有益的。
- 因为它们很有趣!
模加法
问题:
计算 (a + b) mod m,假设 0 ≤ a < m 且 0 ≤ b < m。其核心挑战在于如何有效地进行模运算,尤其是当模数 m 不是 2 的幂时,优化就变得更加复杂。
方法1:
r = (x + y) %n- 除法运算非常耗时,尤其是模运算(
%)的除法。但如果模数m是 2 的幂(例如m = 2^n),除法可以通过位运算实现
- 除法运算非常耗时,尤其是模运算(
方法2:
- c
z = x + y; r = (z < n) ? z: z-n; 分支不可预测,成本很高
方法3:
- c
z = x + y; r = z - (n & -( z >= n));
问题: 计算
, 其中
Solution:
uint64_t n;
...;
--n;
n |= n >> 1;
n |= n >> 2;
n |= n >> 4;
n |= n >> 8;
n |= n >> 16;
n |= n >> 32;
++n;
- --n: 这一操作是为了确保当
n本身是 2 的幂时,能正确处理。并且能够填充右边所有位。
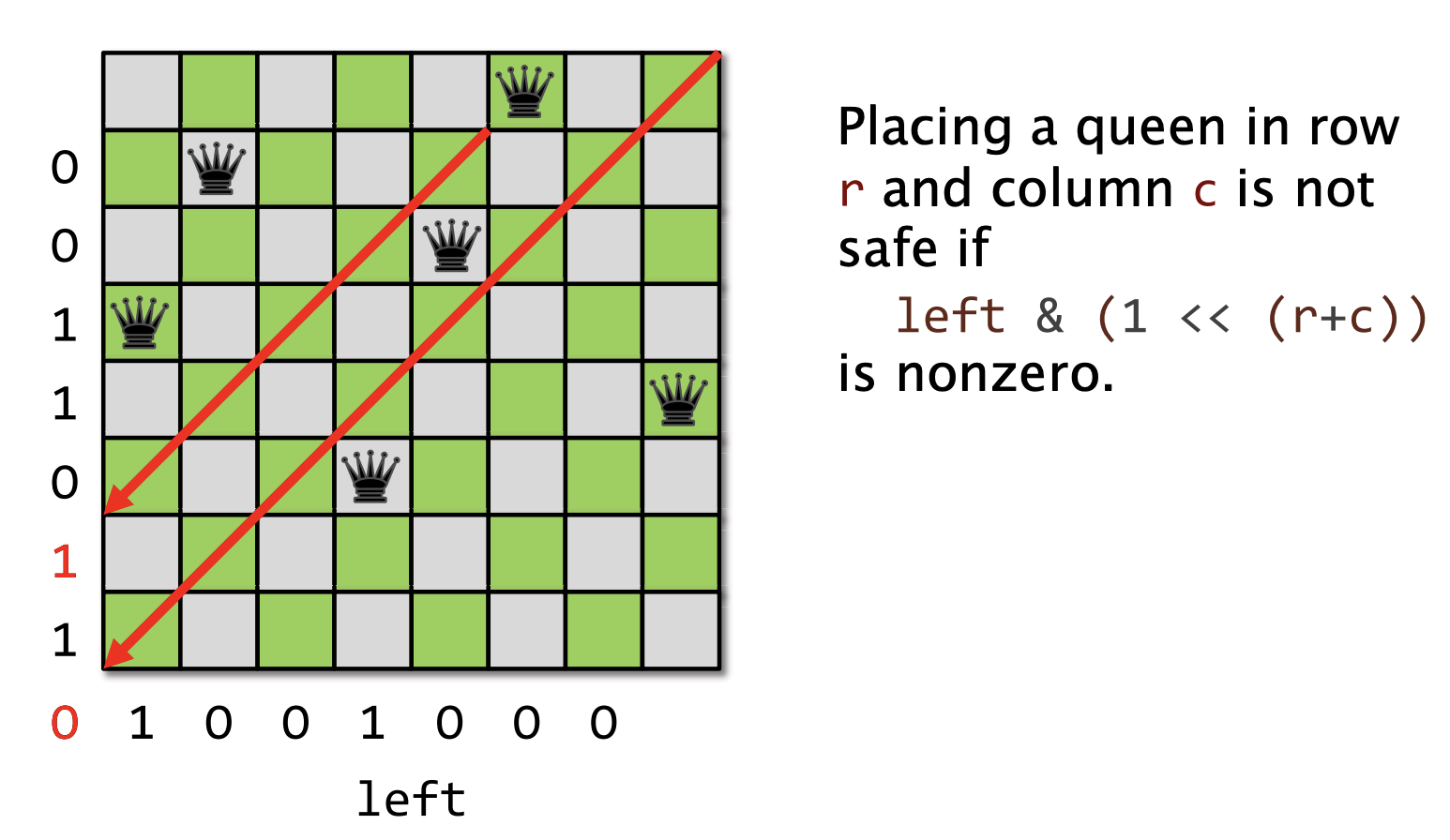
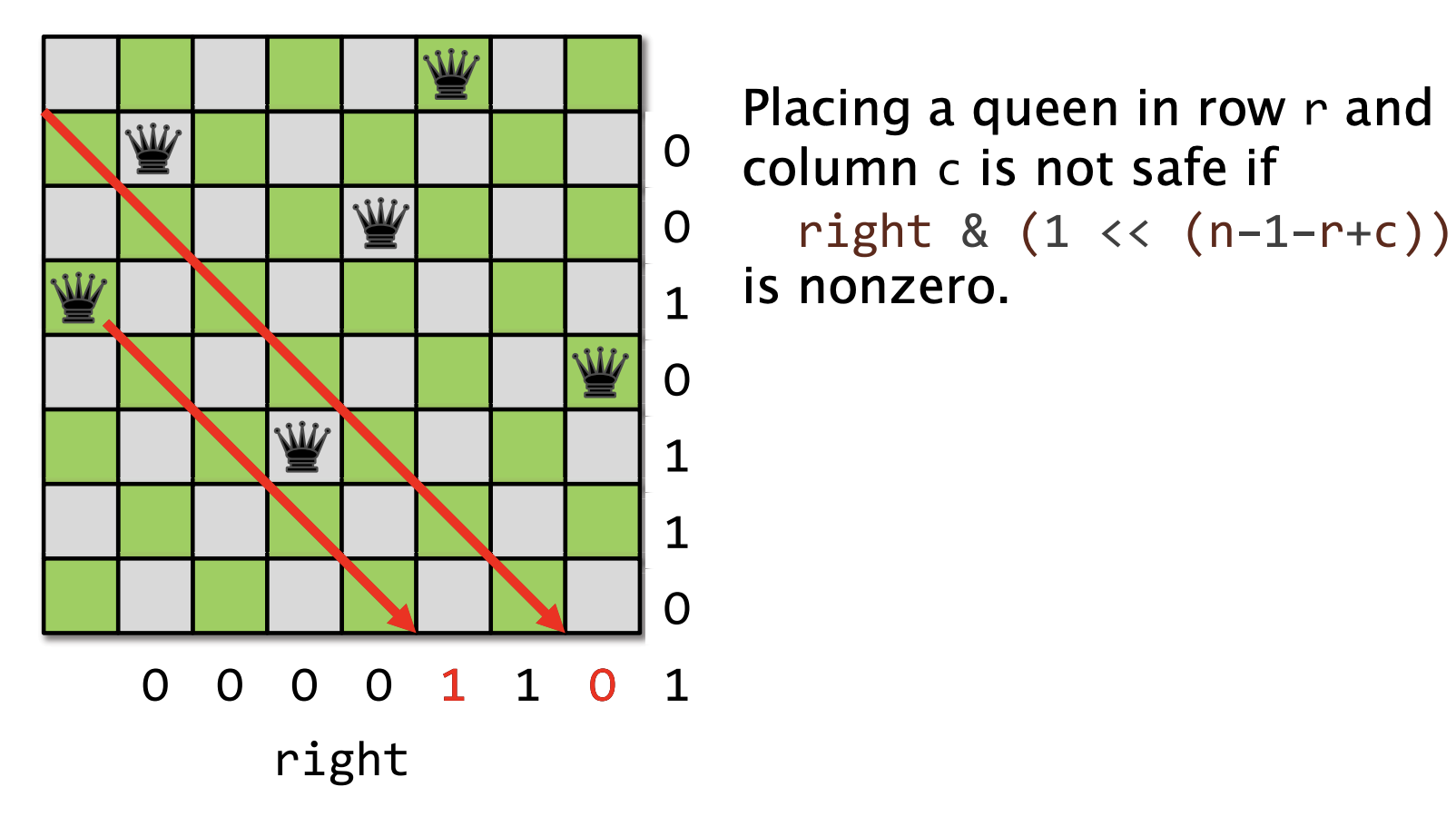
示例: 皇后问题
将n个皇后放置在n * n的棋盘上,要求每个皇后都不会被其他皇后吃掉。也就是说,横竖斜都不会被出现一个以上。
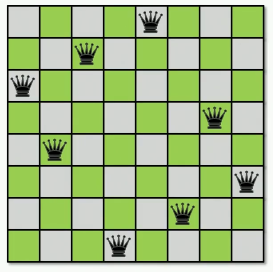
回溯搜索
策略是,将每个皇后一行一行的摆,如果不能在某行摆时候就回溯。
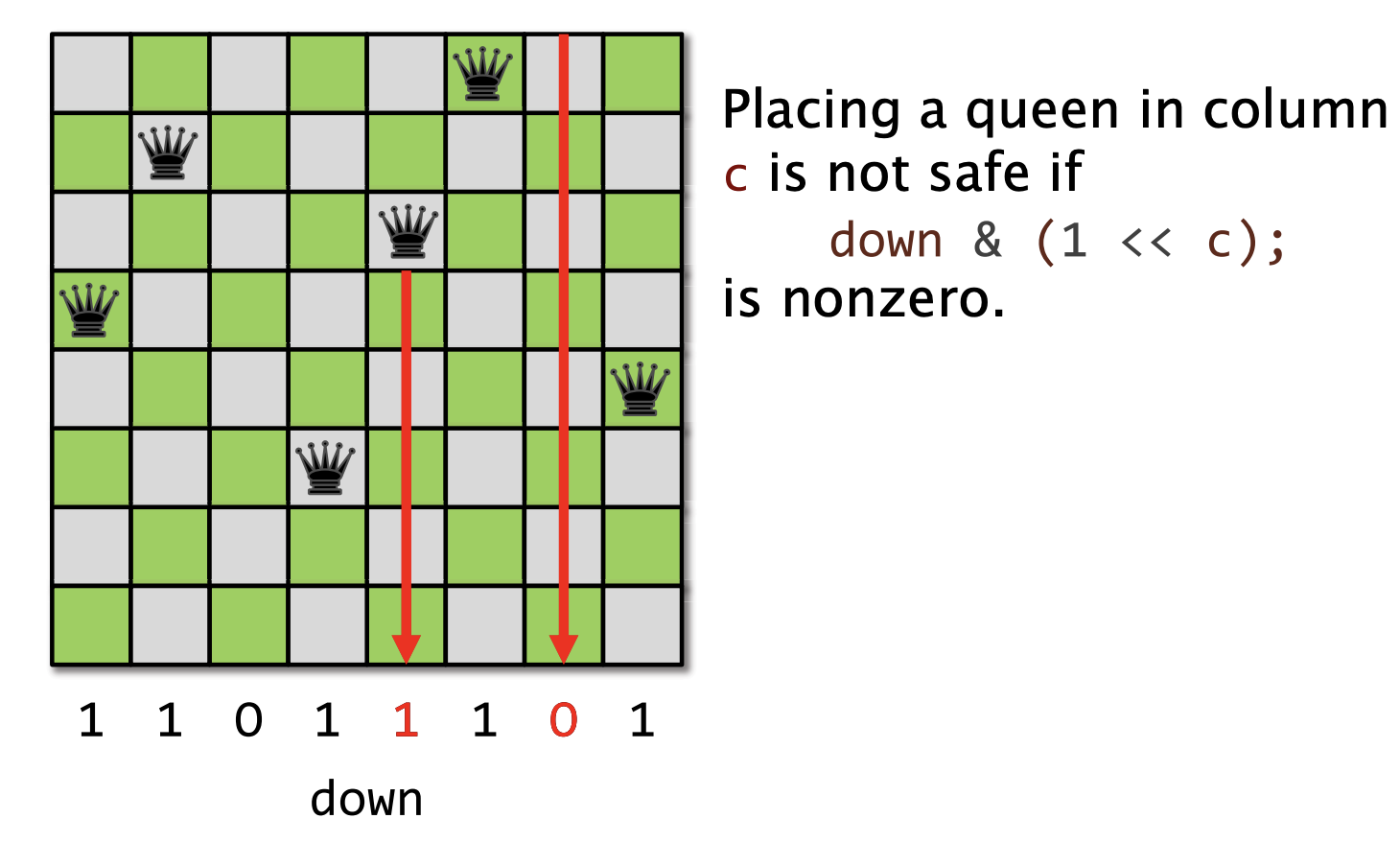
棋盘的表示: 3个位向量,长度分别是n, 2n-1 和 2n-1
示例: 数量统计
问题: 计算一个字x有多少个位为“1”
传统做法,重复消除最低有效位
for (r=0; x != 0; ++r)
x &= x-1;
数字中1的个数较少时,运行速度很快;但在最坏的情况下,运行时间与字中位数的数量成正比
表查询法
static const int count[256] = {0, 1, 1, 2 ,1, 2, 2, 3,1 ,...,8};
for (int r = 0; x != 0; x>>=8)
r += count[x & 0xff];我们创建一个大小为256的表, 存储了8bit字的所有可能,值代表是1的个数。
性能取决于x的大小。
主要瓶颈在内存操作

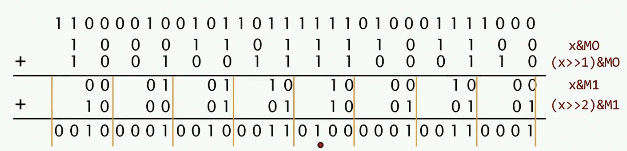
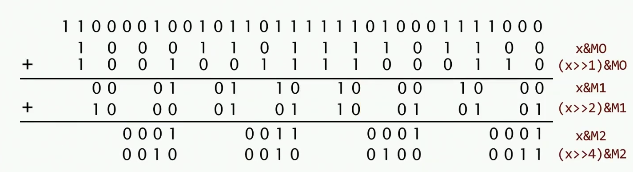
并行分治
这种方法必须去缓存或者DRAM,可以在寄存器中完成所有的操作。首先创建6个掩码

- x & M0 : 获取的偶数位的1的个数
- (x >> 1) & M0 : 获取的奇数位的1的个数

popcount 指令
大多数现代机器提供 popcount 指令,这些指令的运行速度远快于你自己编写的代码。你可以通过编译器内建函数来访问这些指令,例如在 GCC 中可以使用: int __builtin_popcount (unsigned int x); 注意:你可能需要启用某些编译器选项才能访问这些内建函数,而且这样做可能会降低代码的可移植性。