Lec 5 从C到汇编语言
Frigo, Matteo, Charles Leiserson, and Keith Randall. “The Implementation of the Cilk-5 Multithreaded Language.” Proceedings of the 1998 ACM Sigplan Conference on Programming Language Design and Implementation (PLDI) (1998).
“The Cilkview Scalability Analyzer.” Proceedings of the Twenty-Second Annual ACM Symposium on Parallelism in Algorithms and Architectures (2010): 145–156.
总览
复习
LLVM 概述
C到LLVM IR
- 直线型 C 代码到 LLVM IR
- C 函数到 LLVM IR
- C 条件语句 到 LLVM IR
- C 循环语句到 LLVM IR
- LLVM IR 属性
LLVM IR 到 汇编
- Linux x86-64调用约定
示例: Fib
复习
为什么要关注汇编(assembly)?
- 汇编比C代码更加准确揭示了程序的细节,比如类型转化操作,寄存器和内存的用法。
- 汇编揭示了编译器做了什么,以及没有做什么。比如优化基本操作
- 在低级语言下BUG可能会出现, 一些代码问题可能只在特定优化级别(例如
-O3)下显现,或者甚至是编译器本身引入的错误。查看汇编代码帮助我们发现问题 - 可以通过直接修改汇编代码来优化运行速度
- 逆向工程Reverse engineering: 当只能访问二进制文件时,通过分析汇编代码可以解析第三方程序程序的工作原理和实现。
上节课主要是介绍x86-64的汇编语言: 指令,通用寄存器,数据类型,内存寻址方式,以及RFLAGS寄存器,以及条件码。
这节课我们专注于 C 代码如何实现x86-64的汇编。
C代码怎么变成汇编语言的?
- 选择汇编指令来实现C语言的操作
- 通过跳转和分支指令实现C代码的条件和循环语句
- 选择寄存器和内存位置来存储数据
- 在寄存器和内存之间移动数据以满足依赖关系
- 协调函数调用
- 尽可能使生成的汇编代码运行得更快
$bit.c \xrightarrow{预处理器} bit.i \xrightarrow{编译器} bit.s $
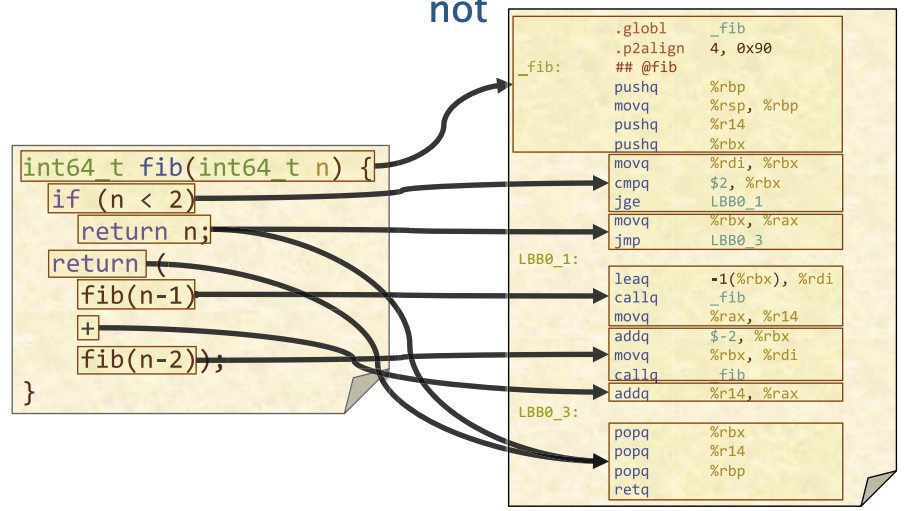
示例: fib.s
从 C 到 汇编的对应关系不总是明显的。
LLVM IR 基础知识
Clang/LLVM 编译流水线
$bit.c \xrightarrow{Clang预处理器} bit.i \xrightarrow{Clang代码生成器} bit.ll \text{(llvm IR)} \ \xrightarrow{LLVM 优化器} bit.ll(优化后的llvm IR) \xrightarrow{LLVM代码生成器} bit.s(汇编) $
- LLVM IR ——理解为"伪汇编" (LLVM: 底层编译器名称 IR: intermediate representation)
查看 LLVM IR
# -S 生成汇编
# -S -emit-llvm 生成LLVM IR
clang -O3 fib.c -S -emit-llvm// 示例 fib.c
int64_t fib(int64_t n) {
if (n < 2) return n;
return (fib(n-1) + fib(n-2));
}
LLVM IR 可以直接转变成汇编语言通过命令
clang fib.ll -S
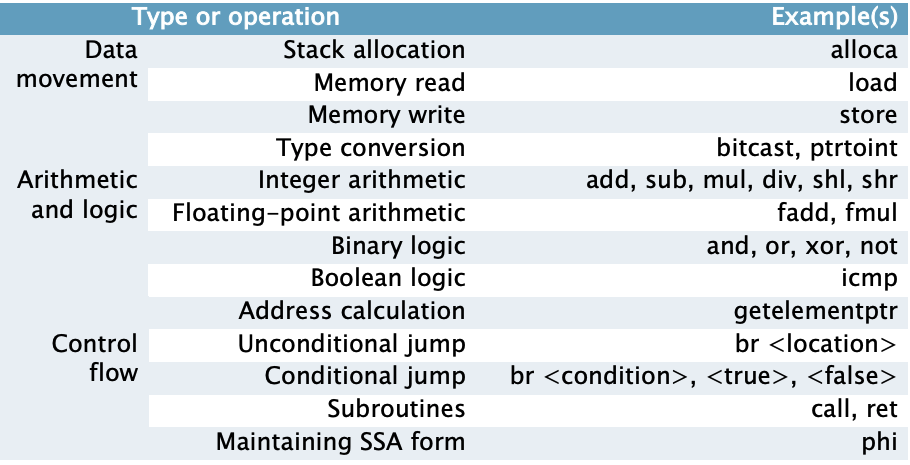
LLVM IR 组成
与汇编语言非常相似,但是比汇编更加简单
- 函数
- 控制流使用条件或无条件分支实现
- LLVM IR 寄存器
- 有点类似变量,数量无限制
- 没有隐式的FLAGS寄存器或者条件码
- 没有显式的栈指针或者帧指针
- 指令
- 指令集更小
- <dst operand> = <opcode> <src operands>
- 数据类型
- 显式的数据类型
LLVM IR 寄存器

语法: %<name>
类似C变量:通过名称来区分,并且数量无限制
寄存器名称是函数的局部变量
LLVM IR使用寄存器的语法(如
%name)不仅仅表示寄存器,还用来指代基本块
LLVM IR指令
- LLVM-IR 代码被组织成了指令
- 生成一个值的指令的语法
- %<name> = <opcode> <operand list>
- 其他指令语法
- <opcode> <operand list>
- 操作数可能是寄存器,常数值 或者是"基本块"
LLVM IR 数据类型
整数: i<num>
- ex:
i64,i1
- ex:
浮点数:
- ex:
double,float
- ex:
数组: [ <num> x <type>]
- ex: 5个int类型数组:
[5 x i32]
- ex: 5个int类型数组:
结构体: { <type>, ... }
向量vector: < <num> x <type> >
- 不一定作用与SEC,AVX;它更像是个普通操作
指针: <type>*
- 指向8bit整数的指针:
i8*
- 指向8bit整数的指针:
标签(基本块):label:
C 到 LLVM IR
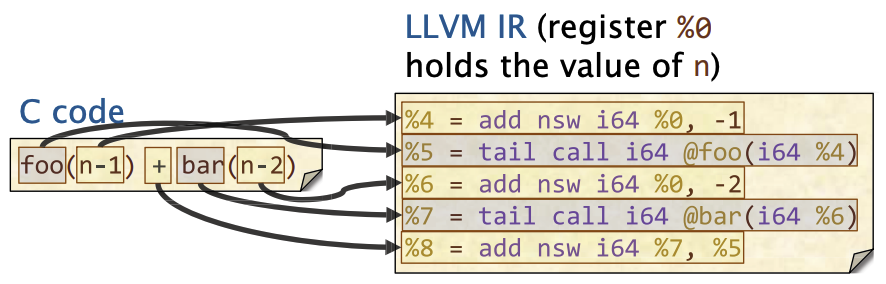
顺序C代码到IR
指的是没有条件或者循环的语句,这部分代码会被转成LLVM IR 指令的序列
- 任何参与运算的参数都会先被计算,得到实际的值
- 中间结果将会被存储到寄存器中
聚合结构的变量一般会存储在内存中,访问聚合类型变量需要计算地址,然后读/写内存。

getelementptr指令从索引的列表(list of indices)和一个指针中计算出一个内存地址
示例: 计算地址 %2 + 0 + %4
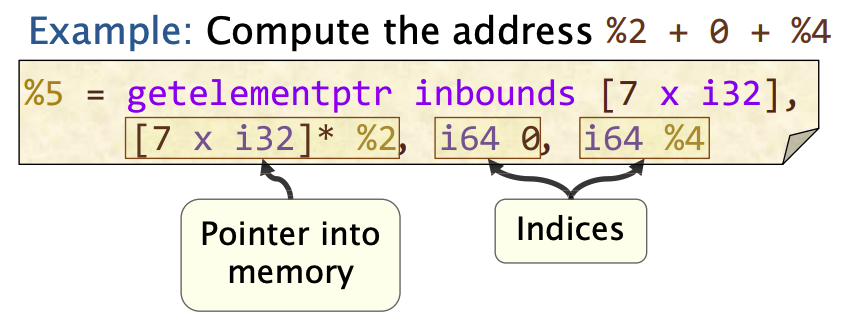
%5 = getelementptr inbounds [7 x i32],
[7 x i32] * %2, i64 0, i64 %4C 函数到 IR
示例
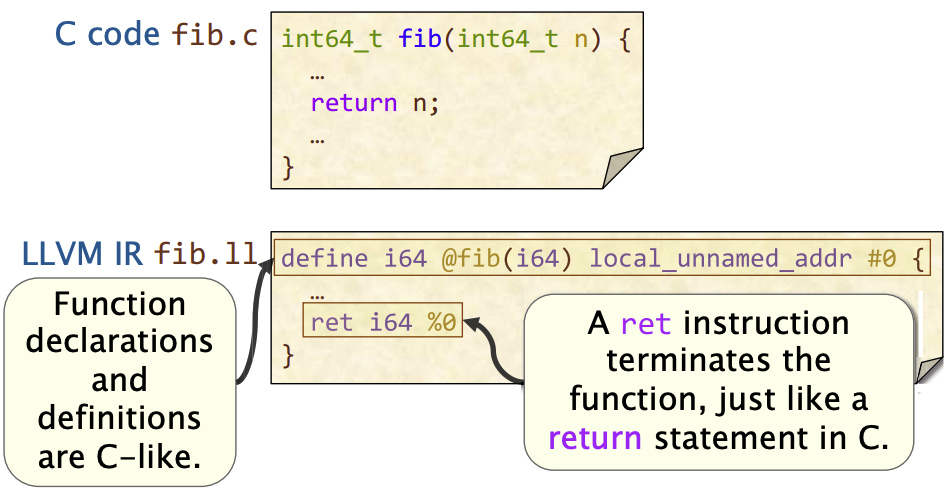
形式参数的处理自动被命名为 %0, %1, %2等——(看起来就是谭浩强写的代码一样 : ( )
基本块
函数定义的主体被划分为基本块:每个基本块是一系列指令(即直线代码),其中控制流只能通过第一条指令进入,并只能通过最后一条指令退出
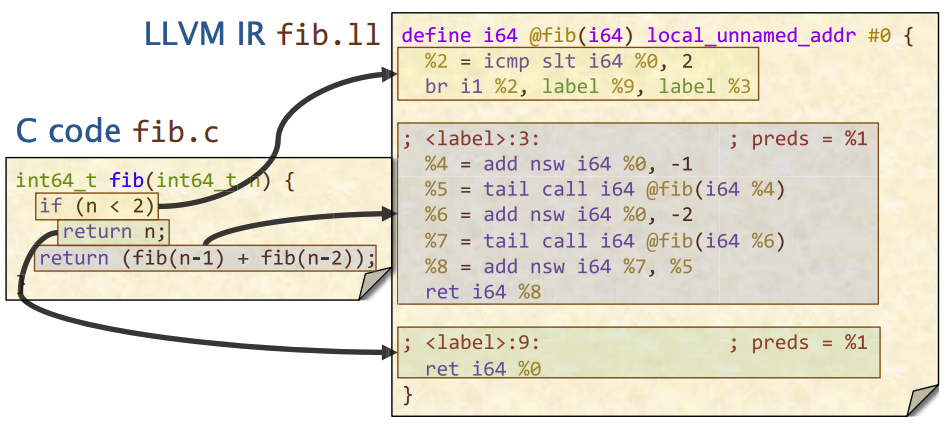
控制流图
控制流指令(比如 br 指令),在函数的基本块之间产生控制流边,从而创建一个控制流图 (CFG, Control-Flow Graph)。这意味着程序执行的路径通过这些指令进行转移,不再只是顺序执行。控制流图展示了函数中可能的执行路径,以及基本块之间的跳转关系。

C 条件语句到IR
C代码的条件语句会被转成br指令
条件跳转
无条件跳转指令
- 无条件分支结束当前基本块,并生成一条向外的控制流边
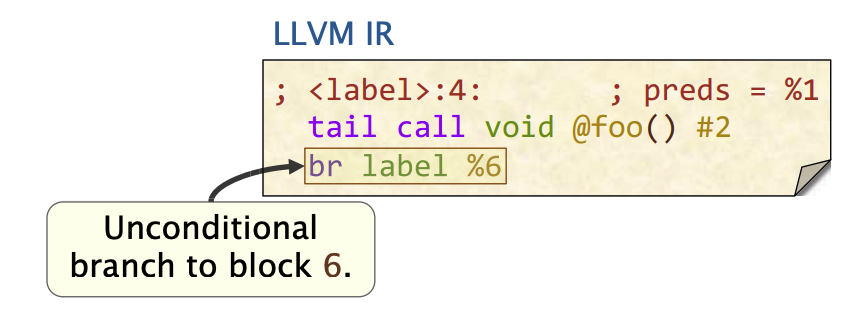
C 循环语句到IR
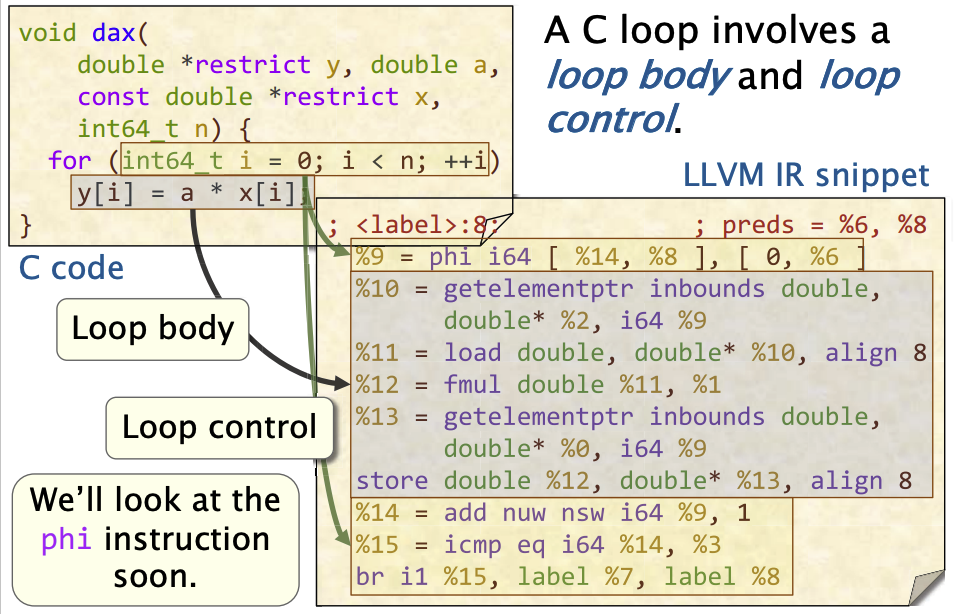
phi指令有点费解,我们先看循环语句的控制流图,从而了解phi指令要解决什么问题。
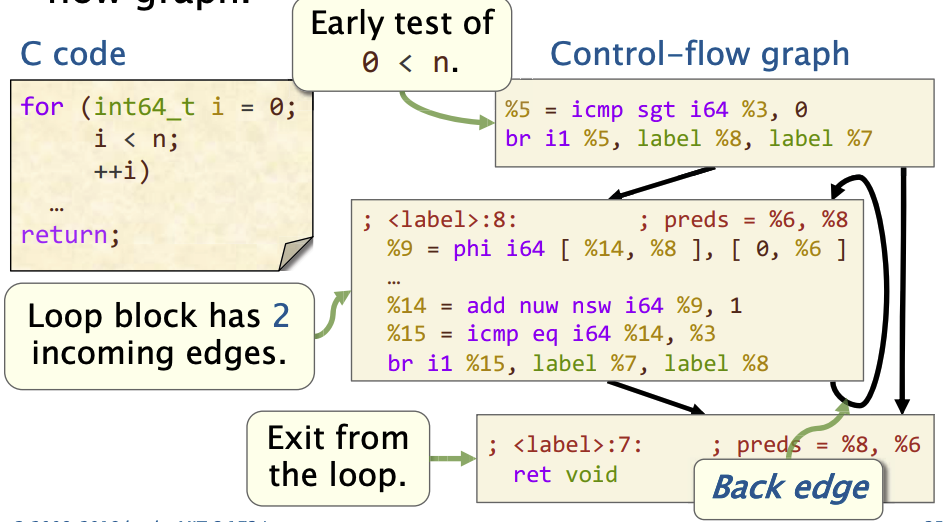
- 在循环块内部,我们有两条入边
- 一个是来自循环的入口点
- 另外一个是重复循环——back edge
- 循环控制包含4个部分
- 引导变量:通常用于控制迭代的次数
- 初始值:诱导变量的起始值
- 条件:决定循环是否继续执行的测试
- 增量:每次迭代中更新诱导变量的操作
在LLVM IR中引导变量在哪里?
在LLVM寄存器上, 当循环运行时,引导变量的值在每次迭代中被重新定义。在优化编译环境(如LLVM)中,跟踪每个变量的定义和修改方式是很重要的。
有一个不变量(叫做SSA,static single assignment),一个寄存器在一个函数中最多由一个指令定义,设计避免了变量在代码中被多次赋值。
phi 指令
phi指令为基本块B的每一个前驱P指定了,控制流通过 P 进入 B 时目标寄存器的值。以这个为例,如果你是由基本块6(前驱),进入基本块8的,那么寄存器的值,会被指定为0;同理,如果来自基本块8,那么会被指定为%14。phi i64 [%14, %8], [ 0, %6 ]
需要注意的是:
- 如果这个循环基本块有很多入边,那么可能会有多条
phi指令 - 这并不是一个真正的指令,而是一种技巧。

LLVM IR 属性
除了前面提到的组成,可能还会装饰一些属性,它传达了一些信息。下面介绍几个常见的属性。
- align 内存的对齐
- 下面例子中
%5 = load i32, i32 * %4, align 4, !tbaa !2load i32表示从内存中读取一个32位整数。i32 * %4表示从%4指向的地址进行读取。align 4指定了对齐要求,意味着这个整数在内存中的地址应该是4的倍数,确保访问内存时的效率。!tbaa !2是一个元数据(metadata),与类型别名分析(type-based alias analysis)相关。它帮助编译器理解某个指针的类型和相关信息,以优化内存访问。
- 下面例子中
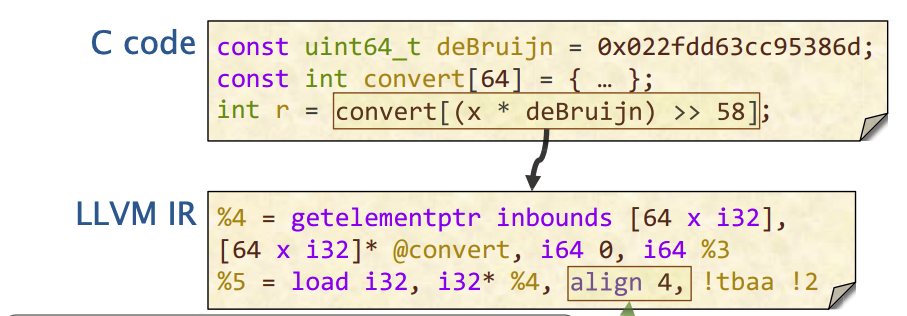
- readonly:由const派生出来

总结LLVM IR
LLVM IR 类似于汇编语言,但更简单。
- 所有计算值都存储在寄存器中。
- 静态单赋值(SSA):每个寄存器名称在IR中最多只写在一行。
- 一个函数被建模为控制流图,节点是基本块,边表示基本块之间的控制流。
- 与C语言相比,所有操作都是显式的。
- 所有整数大小都是明确的
- 没有隐式操作,例如类型转换
LLVM IR 到汇编语言

编译器必须做3个任务才能将LLVM IR 转换到x86-64的汇编语言中
- 选择汇编指令来实现LLVM IR的指令
- 分配x86-64的通用寄存器来保存值
- 协调函数调用(我们的目标!)
Linux x86-64的调用约定
内存中进程的布局
当进程执行的时候,虚拟内存会被组织成段(segment)。
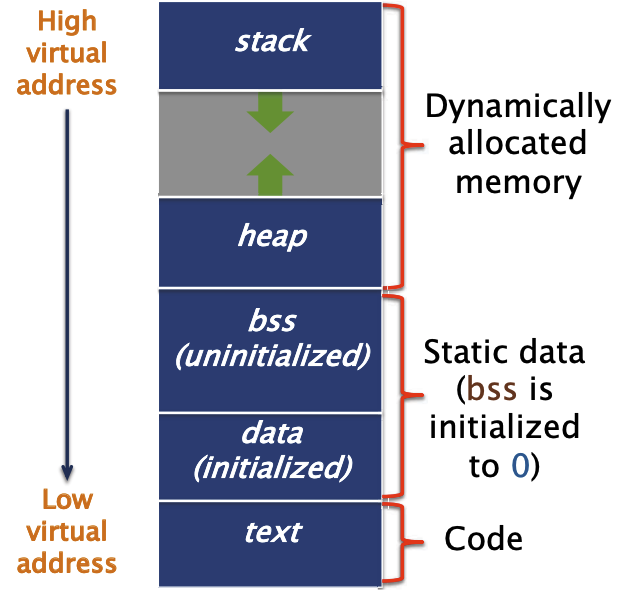
汇编指令
汇编代码包含了特殊的命令,称为汇编指令( Assembler Directive)。用于指导汇编程序的行为(操作和引用不同的程序段(比如bss, data段等等),而不是直接生成代码。
- 段指令(Segment directives),组织汇编文件的内容到段(segment中)
- ".text": 预示是text段
- ".bss":预示是bss段
- ".data":预示是data段
- 存储指令(Storage directives),存储内容到当前段(segment)。Ex:
- x: .space 20 在位置x出分配20字节
- y: .long 172 在位置y存储常数172L
- z: asciz "6.172" .align 8
- 在位置z存储字符串"6.172\0"
- 用8字节对齐
- 作用域和链接指令(Scope and Linkage Directives):控制符号的作用域和链接方式。Ex
- ".global fib": 声明一个全局符号,允许在其他模块中访问
- ".local":声明一个局部符号,只在当前模块中可见。
调用栈
我们从最大地址——栈段开始看,栈段通过在内存中保存,管理函数调用和返回所需的数据。
什么数据应该保存在栈上?
- 函数调用的返回地址
- 寄存器状态,这样不同的函数可以使用相同的寄存器
- 无法fit in 寄存器的函数参数和局部变量。
协调函数调用
不同对象文件的函数如何协调栈和寄存器状态的使用?
Solution:函数遵循调用约定(calling convention)
Linux x86-64 调用约定
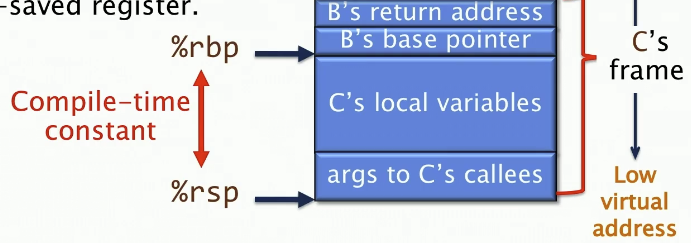
Linux x86-64 调用约定将栈组织成帧,每个函数的实例都有其自己的栈帧。
%rbp寄存器指向当前栈帧的顶部。%rsp寄存器指向当前栈帧的底部
call 和 ret 指令使用栈和指令指针 %rip 来管理每次函数调用的返回地址
- 在 x86-64 架构中,
call指令将%rip压入栈中,然后跳转到操作数(即函数的地址)。 - 在 x86-64 架构中,
ret指令从栈中弹出%rip,并返回到调用方。
谁负责在函数调用和返回时保存寄存器的状态?
- 调用者(caller)可能会浪费时间保存被被调用者(callee)没有使用的寄存器状态。
- 被调用者可能会浪费时间保存调用者没有使用的寄存器状态
Solution: 两边都保留一部分。具体如下
- 被调用者保留的寄存器: %rbx, %rbp, %r12~r15
- 其他所有的寄存器由调用者保存
C链接器定义了调用约定——x86-64 GPR's 寄存器由谁保留
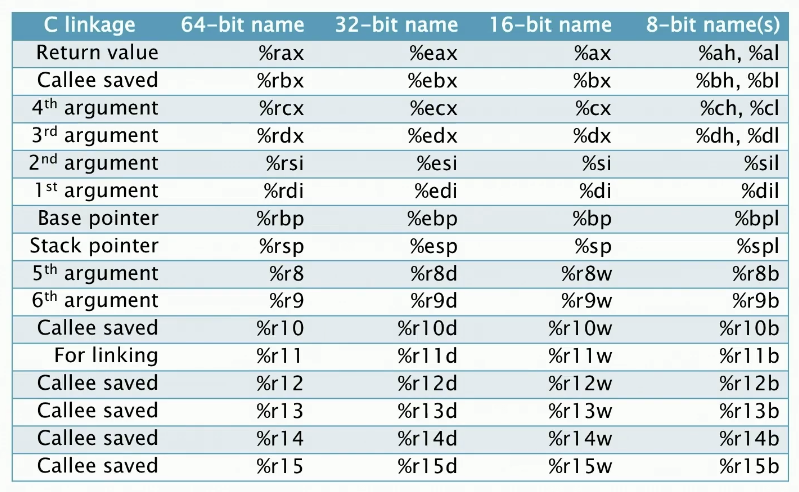
NOTE
上图没有标注寄存器 %xmm0-%xmm7 用来传递浮点数参数,
示例
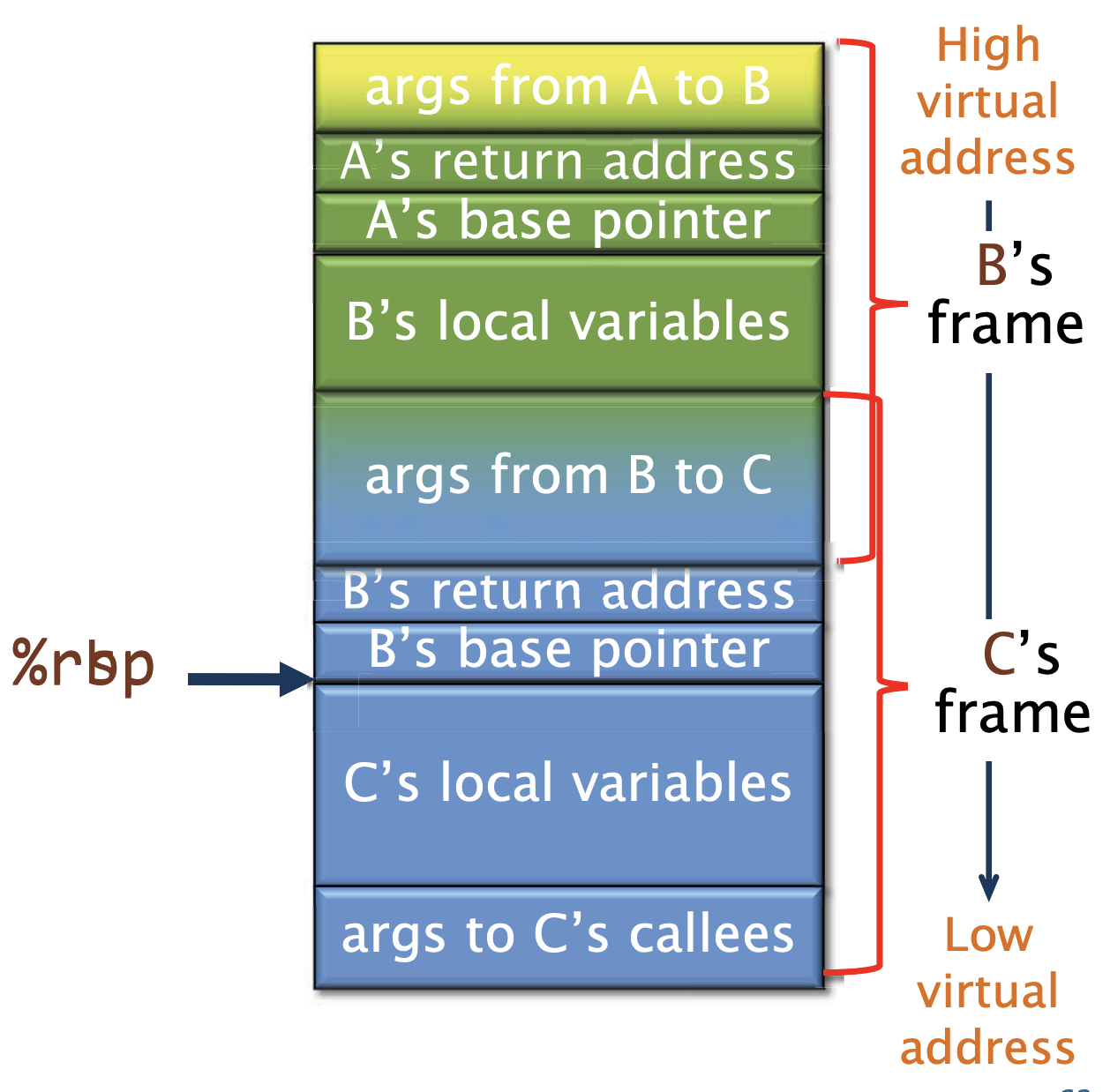
函数A调用了函数B,并且在函数B中,准备调用函数C。
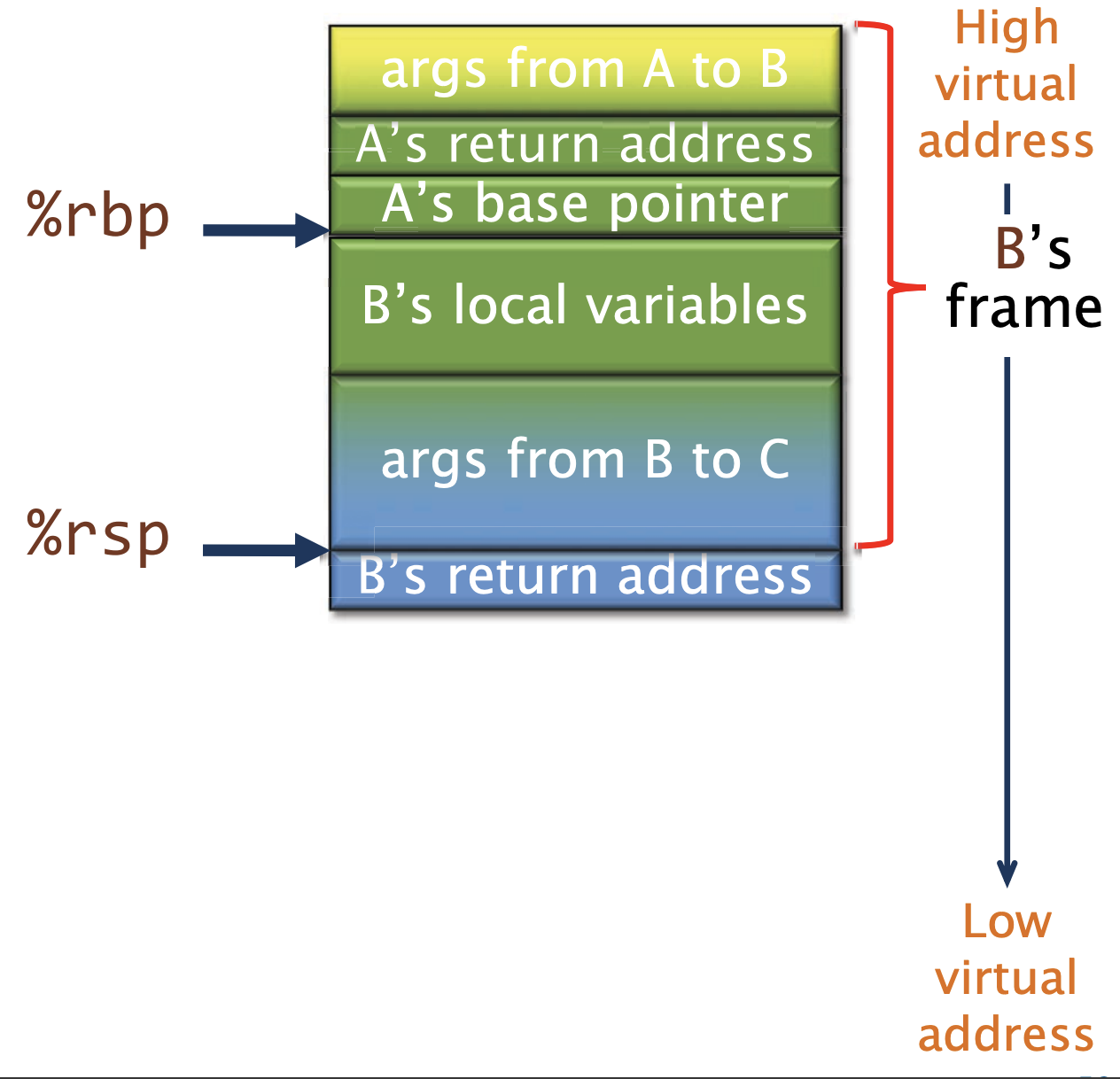
我们从顶往下看,是如何组织的
- 链接块(Linkage block):
args from a to B。这个区域里面放着函数B会从调用者访问的(非寄存器)参数,他们可以通过%rbp的正偏移来获取 - A的返回地址和基地址指针
- 函数B的本地变量则是通过
%rbp的负偏移获取 - B函数的链接块: 在调用C之前,B会将非寄存器的参数放入保留链接块,并将于C共享,B通过使用负偏移来访问链接块
接着 B calls C,这个指令会保存B的返回地址到栈上,并将控制权交给C
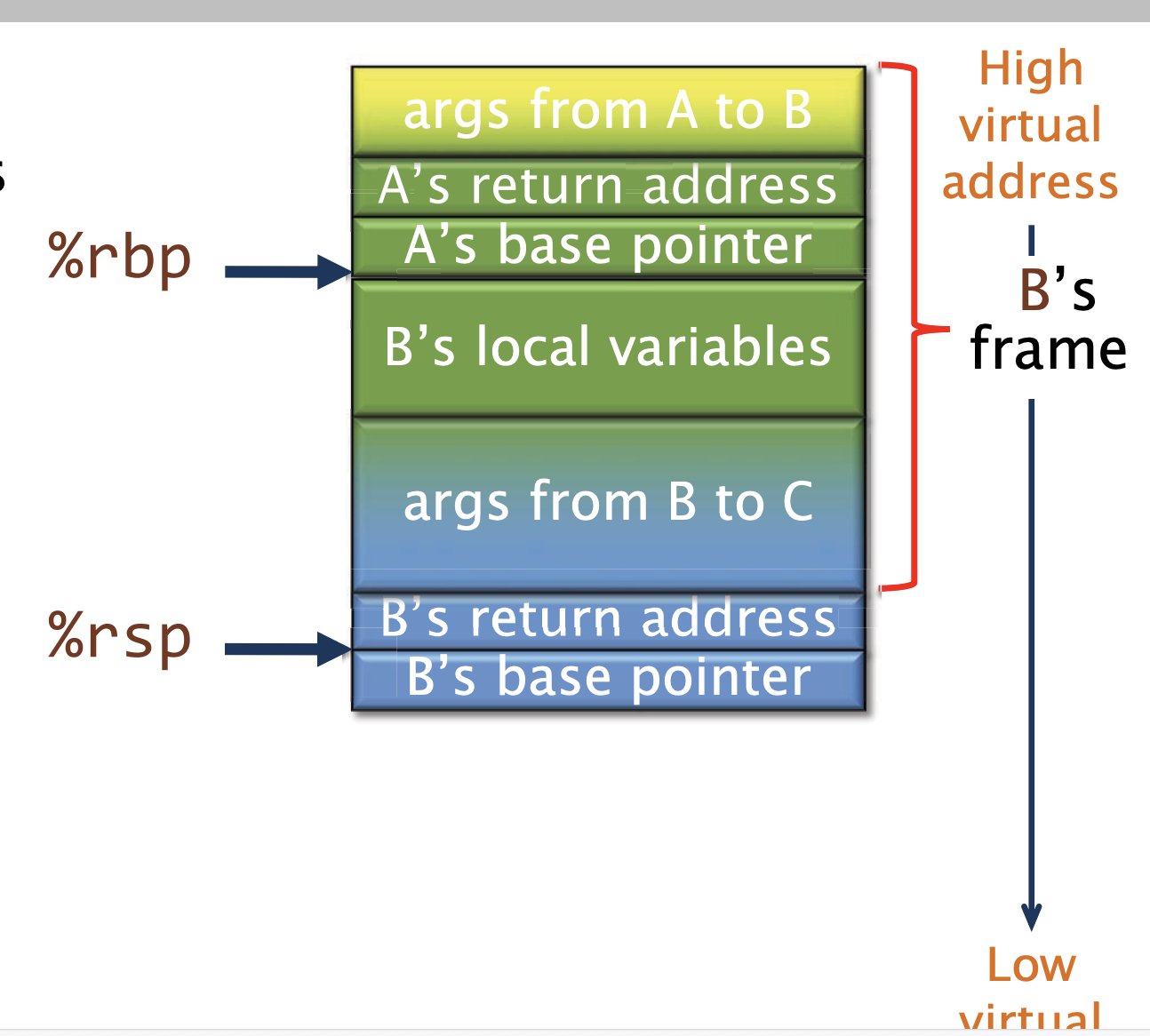
当C函数开始执行的时候,它执行一个函数序言(function prologue):
- 保存B的基地址指针到栈上
- 设置
%rbp = %rsp - 为C的局部变量和链接块分配空间
优化:如果一个函数除了在函数调用时进行栈分配外,从不进行其他栈分配(即,%rsp - %rbp 是一个编译时常量),那么可以直接使用 %rsp 进行索引,而 %rbp 可以作为普通的被调用者保存的寄存器来使用。