Lec 14 缓存和高效缓存算法
深入缓存和介绍如何设计高效缓存的算法。
总览
- 缓存硬件
- 理想的缓存模型
- 矩阵乘法的缓存分析
- 缓存无关算法
缓存硬件
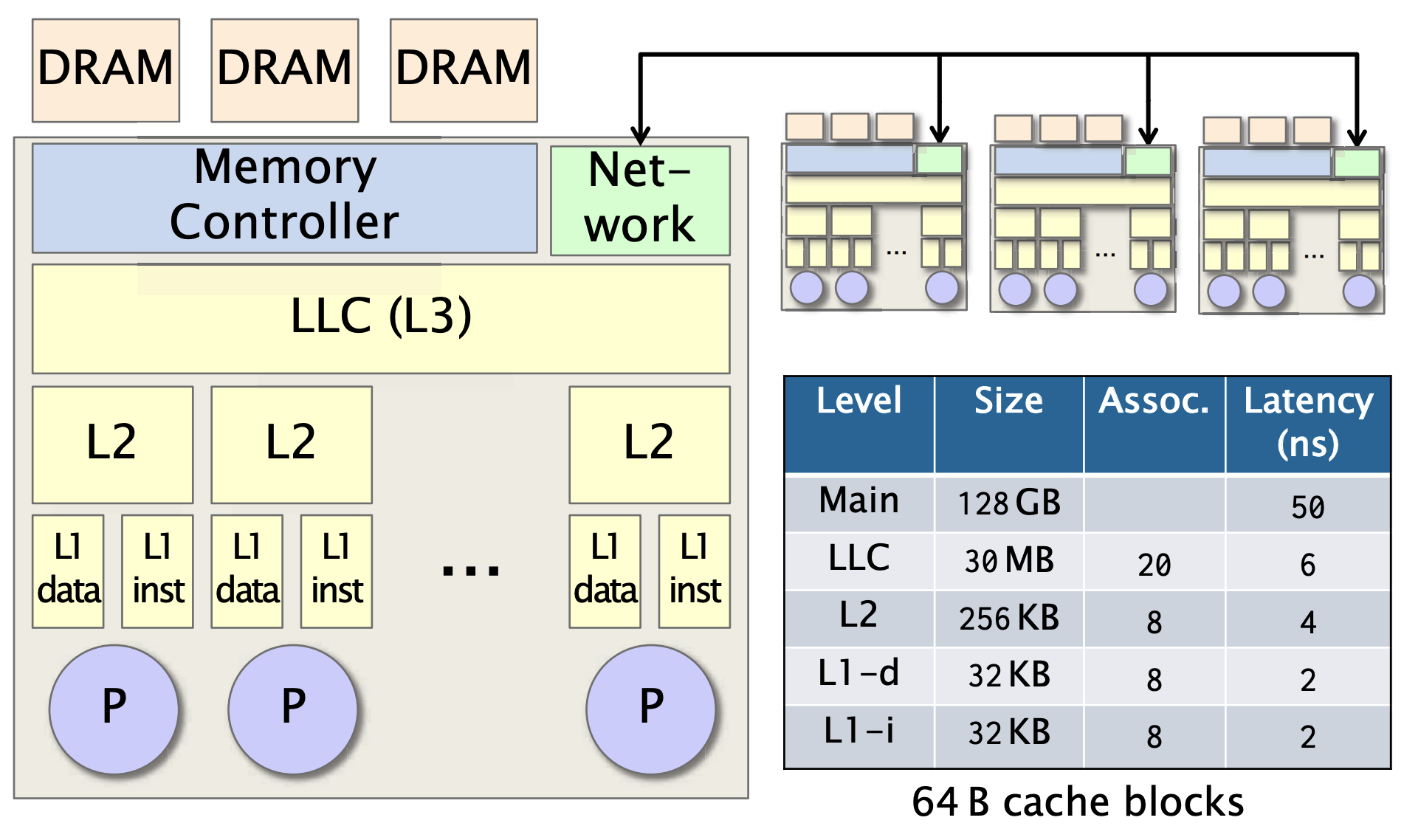
- L1缓存: 每个处理器私有,区分指令和数据的缓存
- L2缓存:同样是处理器私有,不区分
- L3缓存(也称LLC, Last Level Cache),处理器共享,他们都连接到了内存控制器,控制器可以访问DRAM
- 在同一台服务器上,通过网络将一堆多核芯片连接在一起
- Assoc. 是 Associativity(关联度) 的缩写,表示缓存的组相联度。它说明缓存被划分为多少个组(sets),以及每组包含多少个块(blocks)
- 例如,8-way associativity 意味着每个组有8个缓存块。更高的关联度可以减少缓存冲突,从而提高命中率
全相联缓存
全相联缓存Fully Associative Cache,一个缓存块可以驻留在缓存的任何地址。
在下图简化的例子中
- 缓存块(Cache Block)大小 = 4B,字长为4B, 所以每一行地址都对应一个缓存行
- 缓存大小 = 32B
- 每一个缓存行/块都有一个标签,指定了虚拟地址空间的哪一个内存地址。
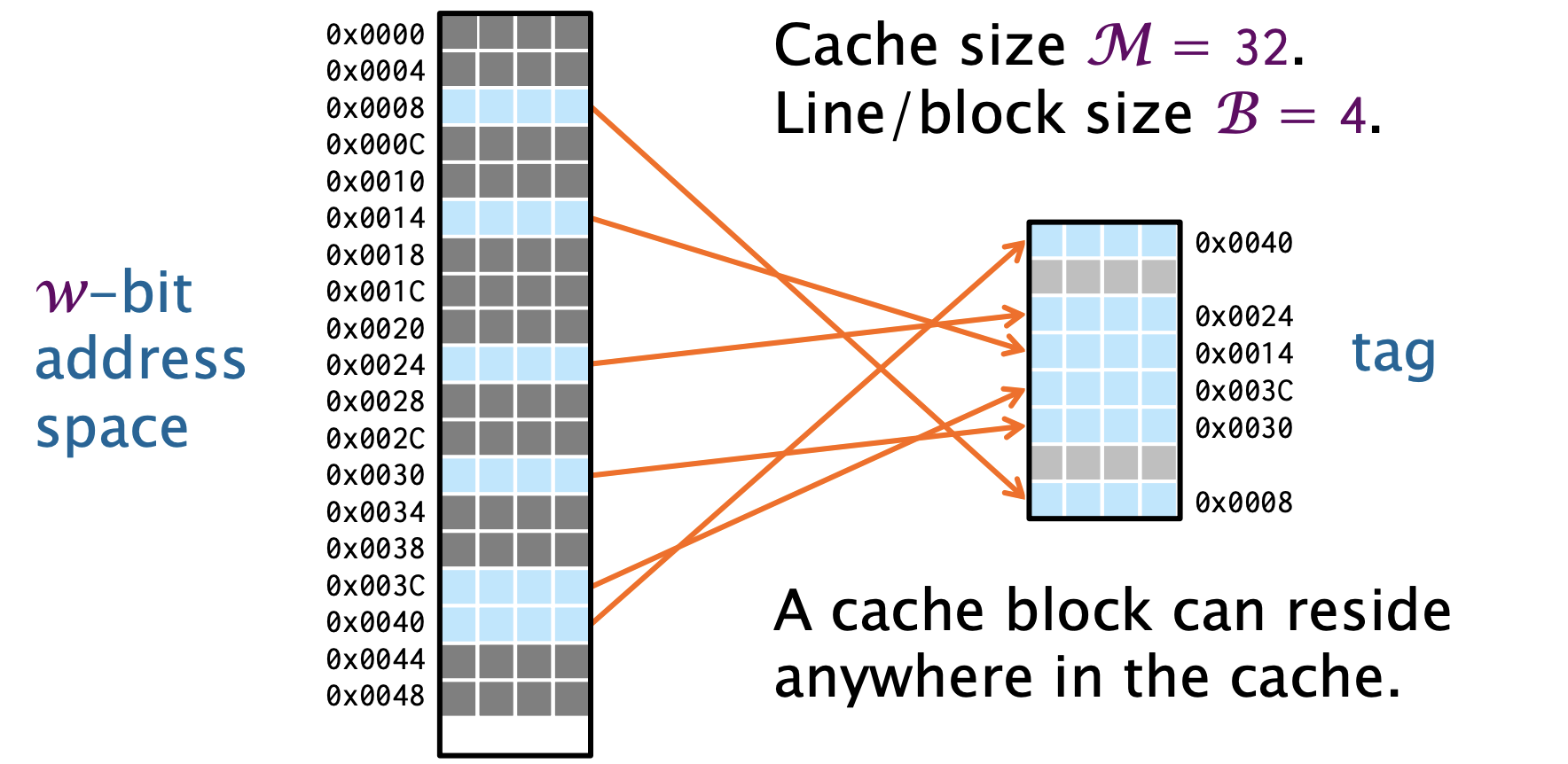
要在缓存中找到一个块,必须搜索整个缓存中的标签。当缓存满时,需要将一个块逐出以为新块腾出空间。替换策略决定要驱逐哪个块。
直接映射缓存
另外一个种, 直接映射缓存Direct Mapped Cache,一个缓存块的set决定了在缓存中的位置
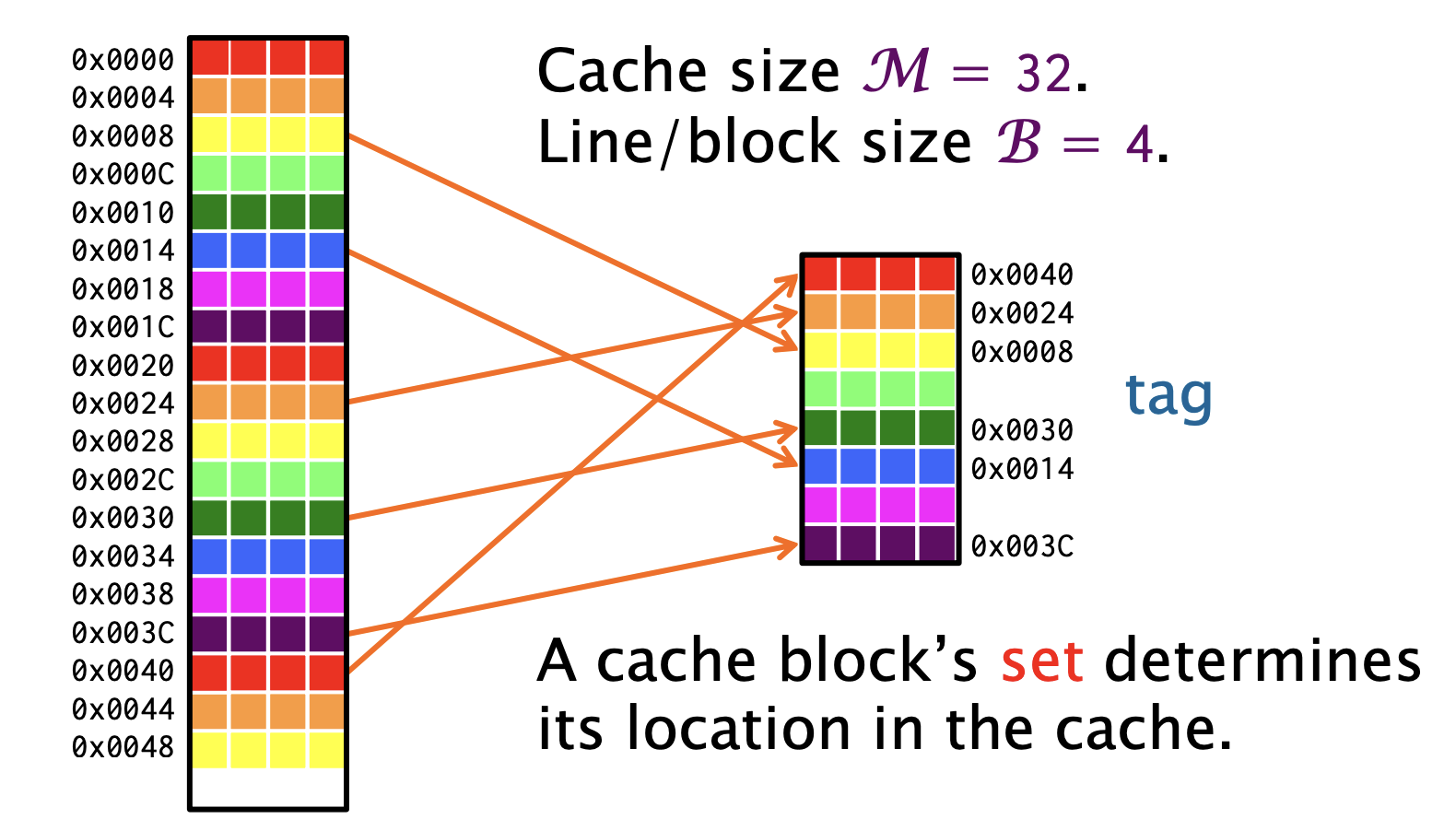
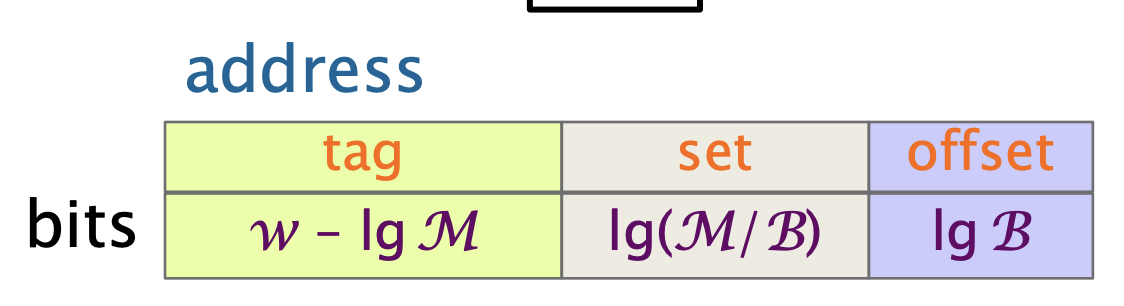
要在缓存中找到一个块,只需要在缓存中的一个位置进行搜索,也就是说每个内存块都会映射到缓存中的唯一一个位置。 这个方法查询速度快, 但是cache miss的概率会很高,即便还有空闲位置,也可能会将其替换。
组相联映射
Set Associative Cache
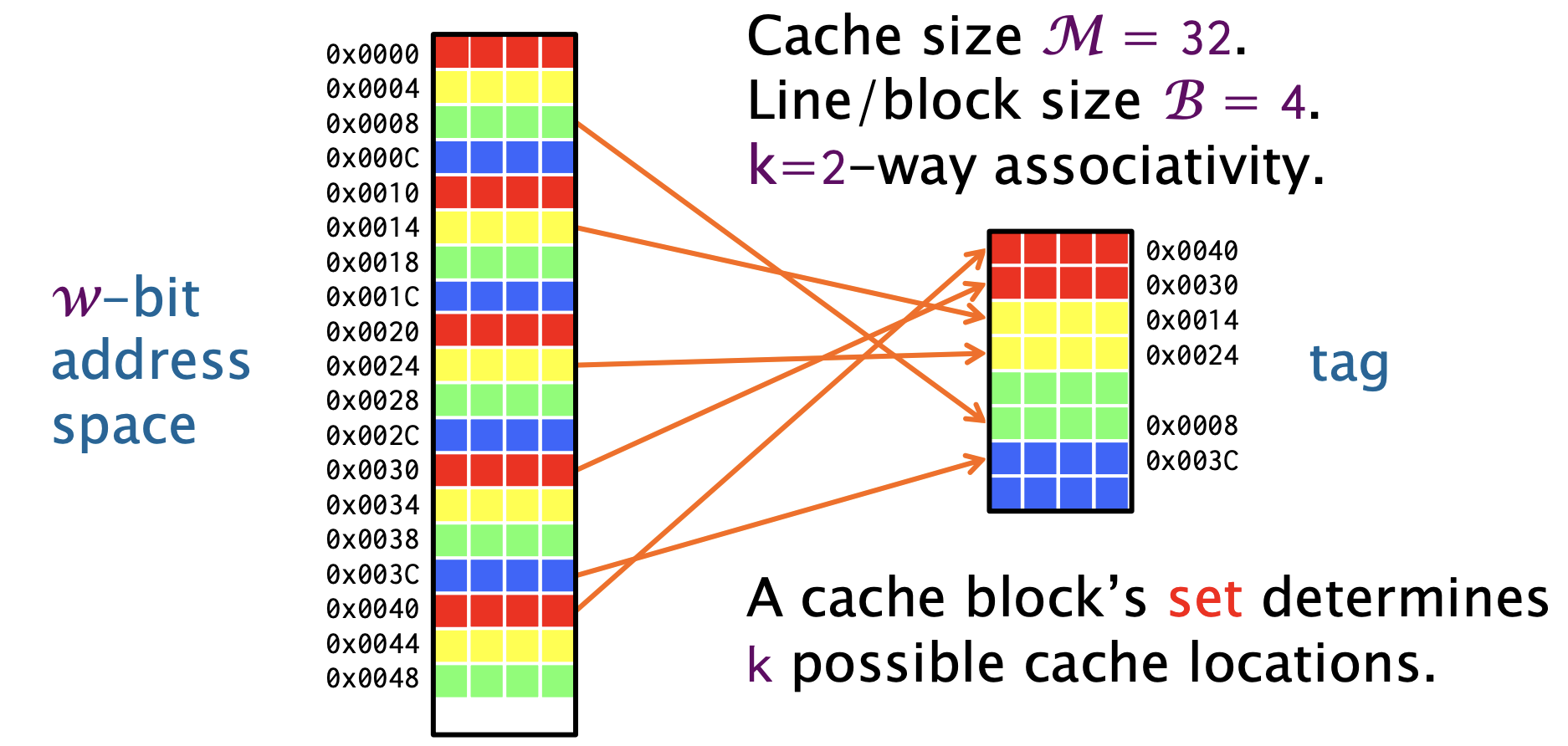
要在缓存中找到一个块,只需要搜索该块所在集合的 k 个位置
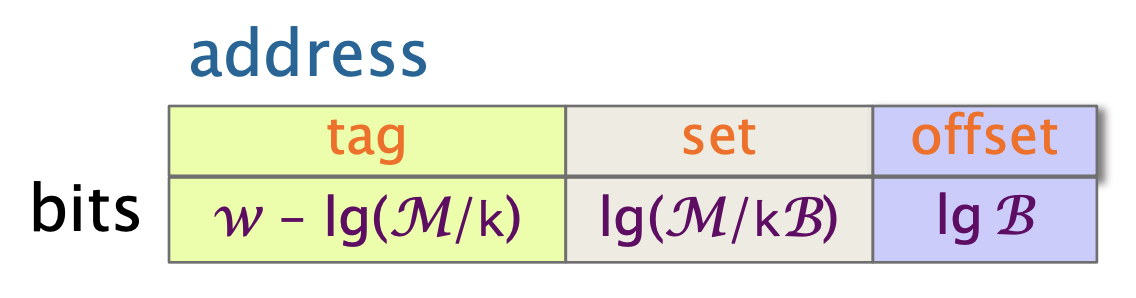
缓存未命中的分类
冷未命中 (Cold miss)
- 缓存块第一次被访问时发生的未命中。
容量未命中 (Capacity miss)
- 即使缓存是全相联的(fully associative),之前缓存的副本也会被驱逐。
冲突未命中 (Conflict miss)
- 缓存中来自同一集合的块太多,导致块被驱逐。如果缓存是全相联的,这种未命中不会发生。
共享未命中 (Sharing miss)
- 另一个处理器获取了该缓存块的独占访问权。
- 真共享未命中 (True-sharing miss):两个处理器访问缓存行上的相同数据。
- 假共享未命中 (False-sharing miss):两个处理器访问的是位于同一缓存行上的不同数据。
示例: 冲突未命中
假设
- 位宽w=64
- 缓存大小M = 32K
- 缓存行大小 B = 64B
- k = 4-路组相联
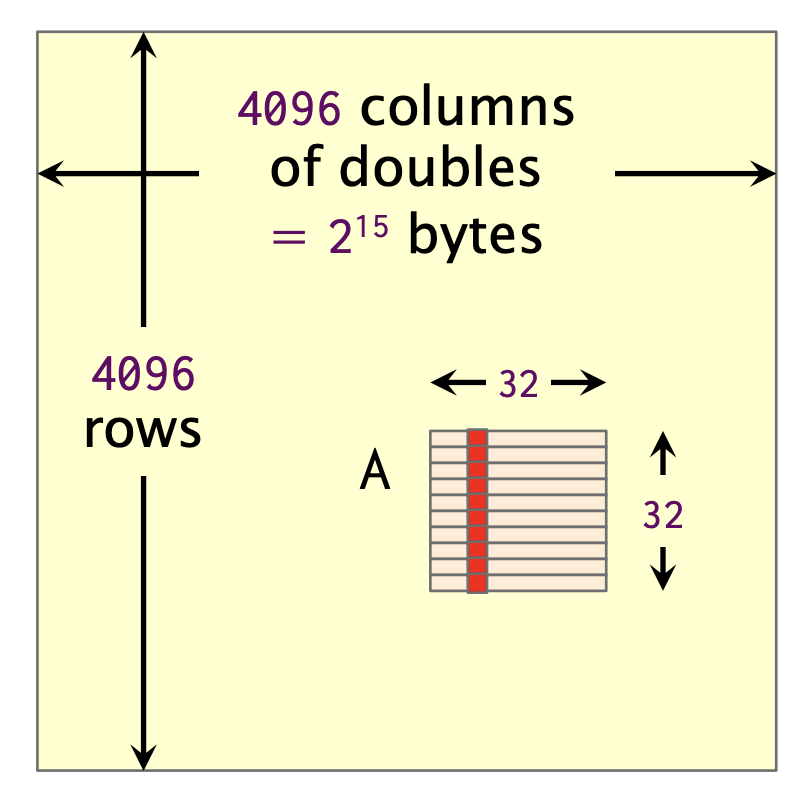
冲突未命中对具有有限相联度的缓存可能是个问题。
分析:
查看子矩阵A的一列。元素的地址为x, x+2¹⁵, x+2·2¹⁵, ...,x+31·2¹⁵。这些地址全部落入同一个集合中!
解决方案
- 将矩阵A复制到一个临时的32×32矩阵中,或为每行添加填充。
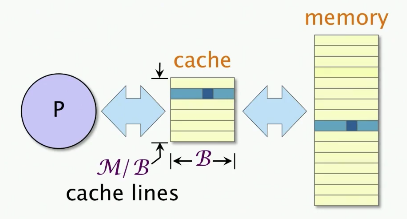
理想模型
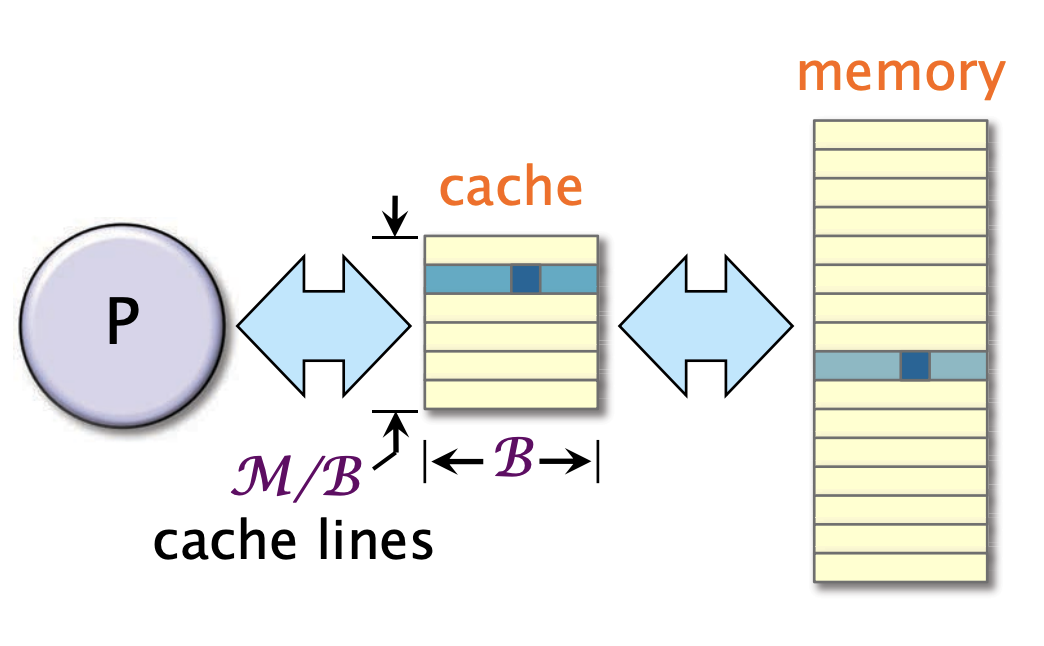
参数
- 2级分层
- 缓存大小为M bytes
- 缓存行大小为B bytes
- 全相联
- 最优的、全知的替换策略
性能测量指标
- 工作量W(一般的运行时间)
- 缓存未命中 Q
理想缓存模型为何理想?
IMPORTANT
【引理】“LRU”引理 [ST85]。假设某个算法在一个大小为 M 的理想缓存中产生了 Q 次缓存未命中。那么,在一个大小为 2M 并使用最近最少使用(LRU)替换策略的全相联缓存中,最多会产生 2Q 次缓存未命中。
含义: 渐进分析下,可以根据需要,假设使用最优替换或 LRU 替换策略。
软件工程:
- 设计一个理论上表现良好的算法。
- 针对细节进行性能优化。
- 实际缓存并不是全相联的。
- 加载和存储在带宽和延迟方面的开销不同。
缓存未命中引理
IMPORTANT
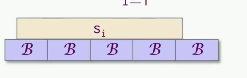
【引理】假设程序读取了一组 r 个数据段,每个数据段 i 包含了
- 这个引理讨论了缓存未命中的上界问题
- 假设缓存容量 M 足够大,可以装下这组数据段的三分之一
- 每个数据段的平均大小N/r,至少为缓存块大小 B,这意味着每个段的大小不会太小,能够充分利用缓存块
- 结论是,表示在最坏情况下,缓存未命中块的数量可能是最优情况的三倍
证明: 一个单一段
高缓存假设
IMPORTANT
【定理】Tall Cache 假设,
示例: Intel Xeon E5-2666 v3
- 缓存行大小 = 64 B
- L1-cache 大小 = 32KB
短缓存的问题是什么?
一个以行优先顺序存储的
即使矩阵的总大小
子矩阵缓存引理
IMPORTANT
【引理】假设一个
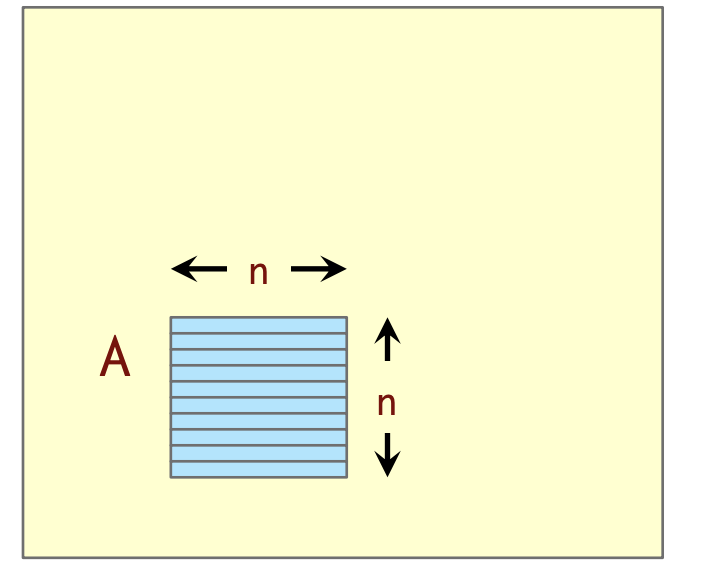
证明:我们有