Lec 18 DSL 和 自动调优
阅读资料
总览
- DSL介绍
- GraphIt
- Halide
- Opentuning
领域特定语言介绍
区别于C++ 、C 、Golang这些通用的编程语言。
- 在更高的抽象层次上捕捉程序员的意图
- 获取多种软件工程的好处,如:清晰性、可移植性、可维护性、可测试性等
- 为编译器提供更多机会以实现更高的性能
- 可以编码领域特定的专家知识进行转换
- 更好地了解执行的计算,而不需要复杂的分析
- 减少程序员做出的低级别决策
Graphlt
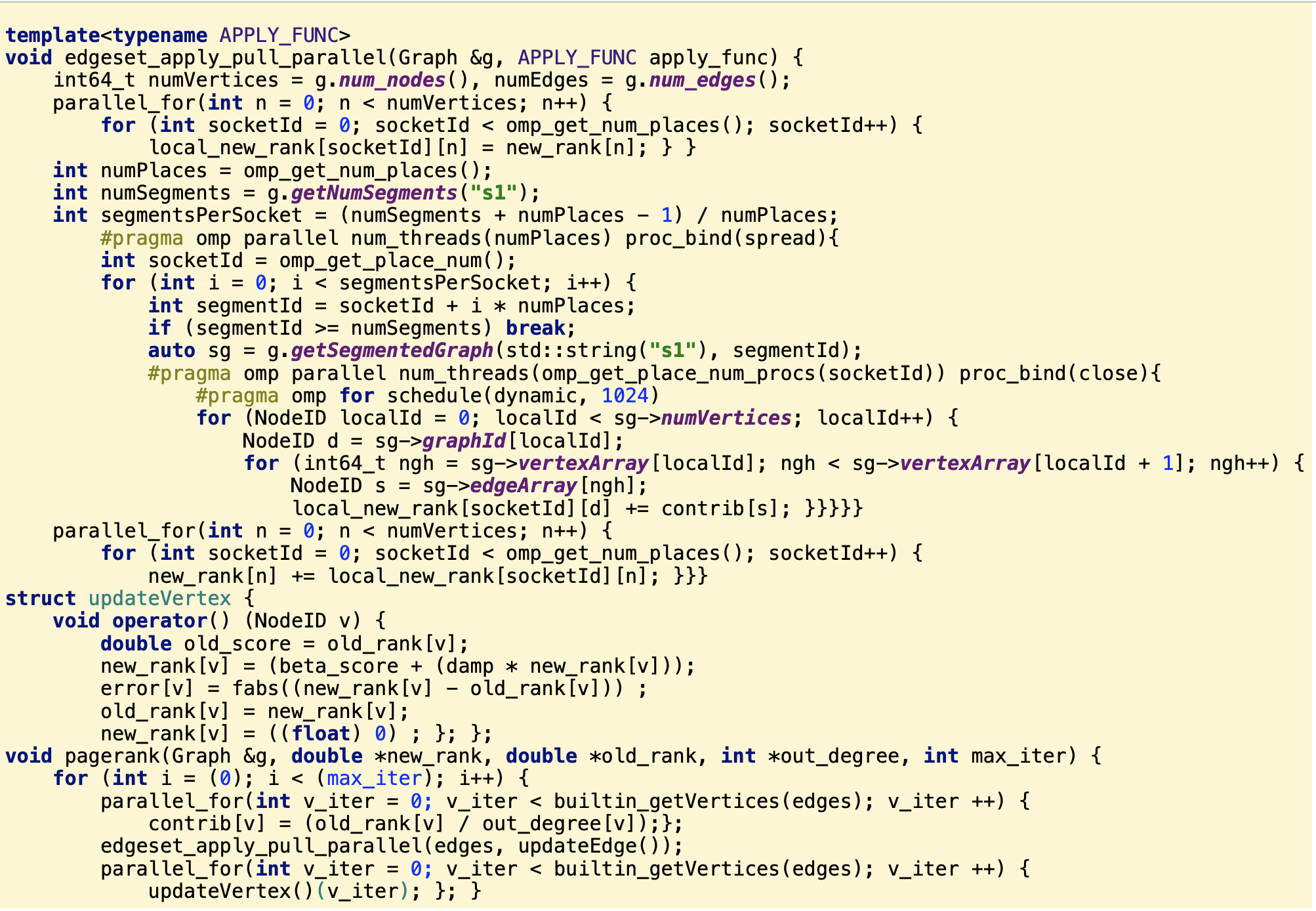
示例: PageRank in Cpp

思路就是看谁被引用了最多,那么这网页就排名越高。当然,上面的算法会比较慢,因为数据量太大,cache miss较多,因此接下来在Intel 一个具体机型上做了优化,能够带来23倍的性能提升。借助如下技术
- 多线程
- 负载均衡
- NUMA优化
- Cache优化等等
但是这里面有个几个挑战
- 很难将代码写对
- 非常难以通过不同的优化组合进行实验——不得不大改代码
所以我们要怎么看待图?用什么表示?
图的算法
拓扑驱动算法
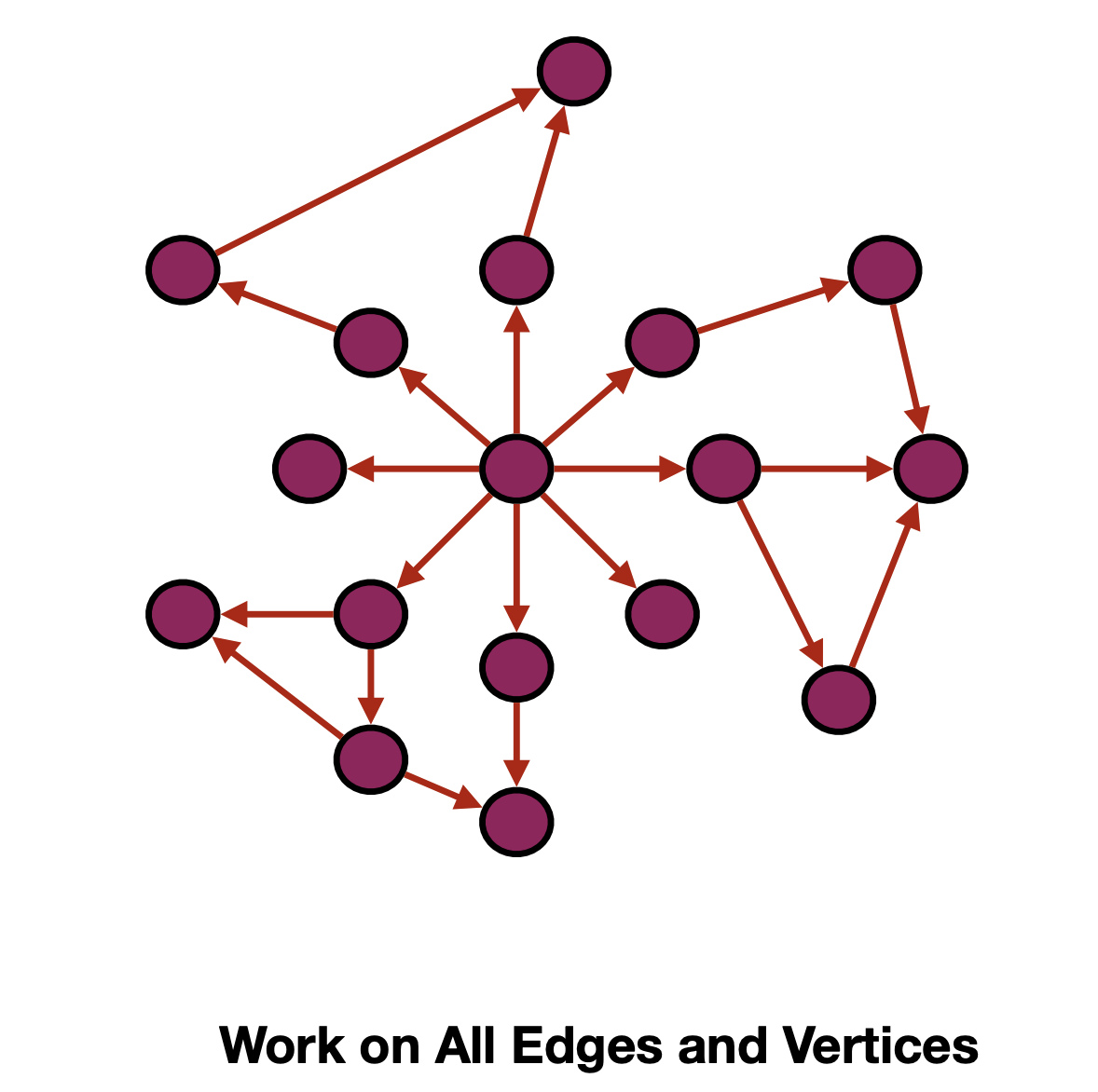
Topology-Driven Algorithms,利用拓扑结构来指导算法的执行。
比如,推荐引擎,google搜索
数据驱动算法
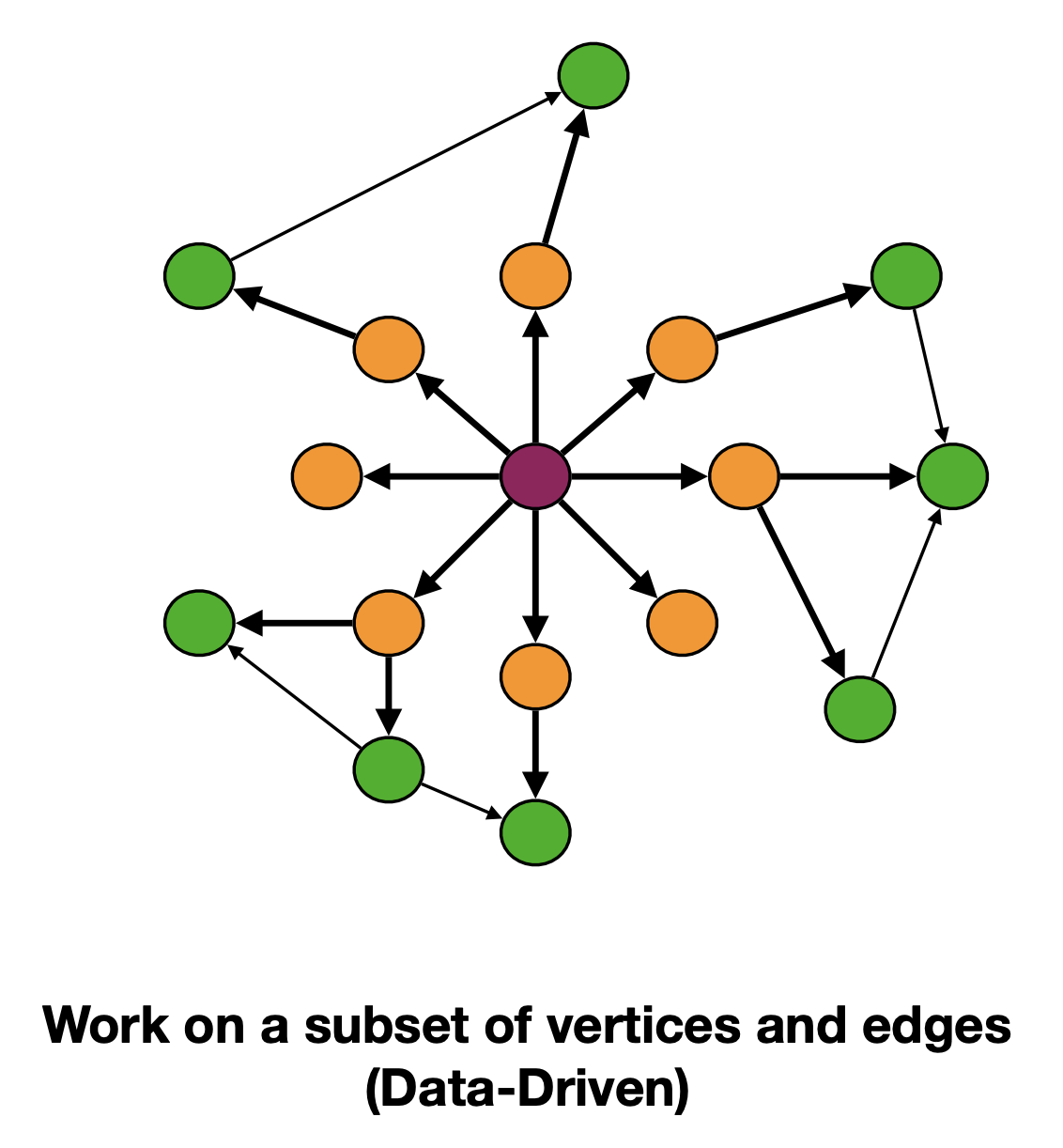
图的操作
遍历
- Pull Traversal 是一种“拉取”式的遍历方法
- 多个线程可能会同时访问同一节点的数据,导致需要使用原子操作来保证数据一致性,从而引入了额外的处理成本
- 不会遍历额外的边。由于每个节点是主动拉取数据,只访问与其有关的必要数据,避免了不必要的边遍历
- Push Traversal 是一种“推送”式的遍历方法
- 不需要原子操作带来的开销("Incurs no overhead from atomics")。在推模式下,节点主动将数据推送给其他节点,因此不涉及多个线程竞争访问同一节点的数据,避免了使用原子操作。
- 会遍历额外的边("Traverses extra edges")。由于推送是主动操作,某些边可能会被重复访问,即使这些数据不需要被更新或已经是最新的。
分区
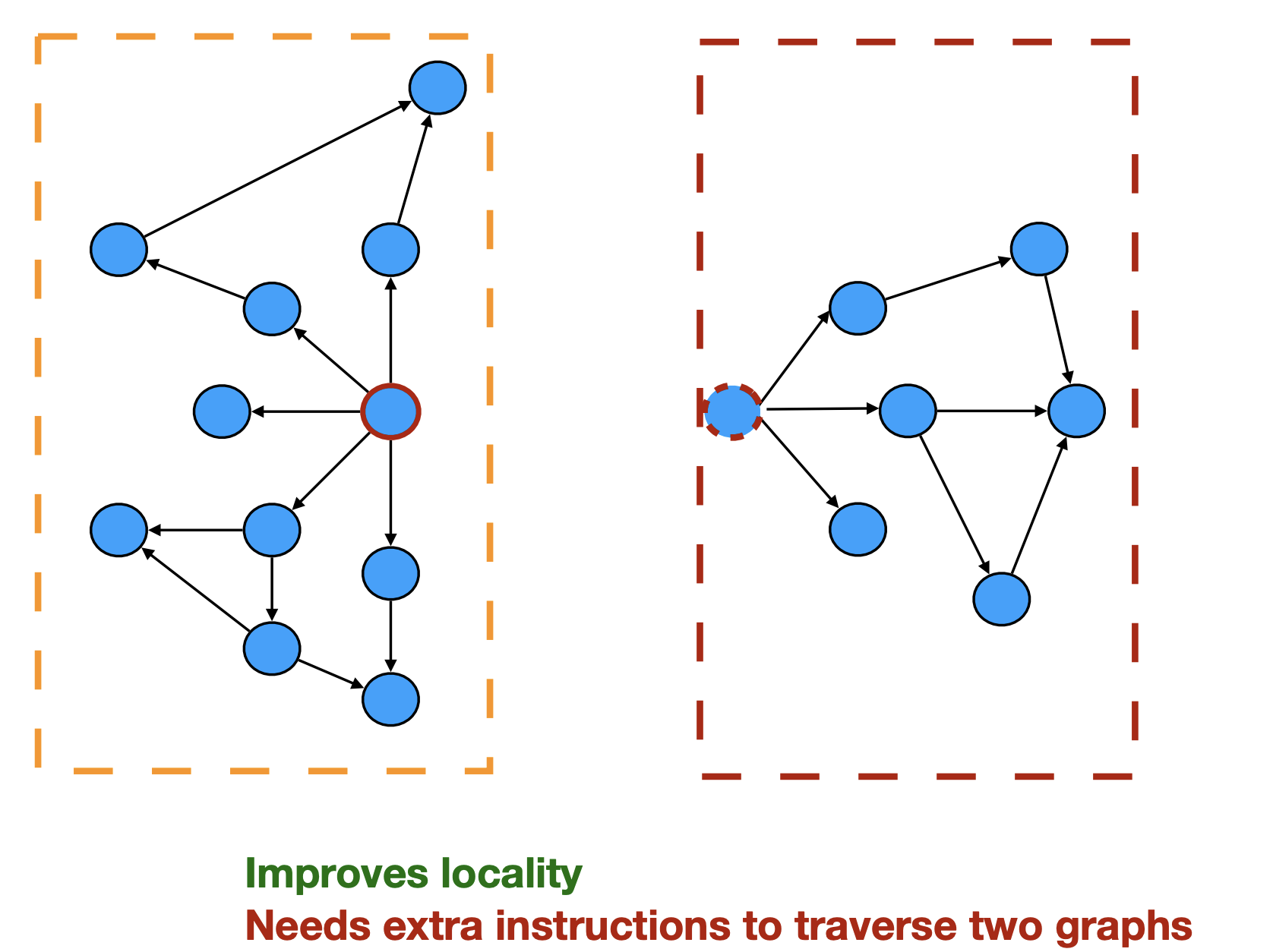
- 好处: 利用局部性原理,可以将相互关联的节点放在一起。这有助于提高缓存局部性/减少跨核的通信量
- 坏处: 需要额外的指令来遍历两个图
图的性质
- 幂律图: 社交网络。 “倾斜”很大 : (
- 有界度数图: 电路设计,地图。 这种图比较讨人喜欢 : )
图的优化权衡空间
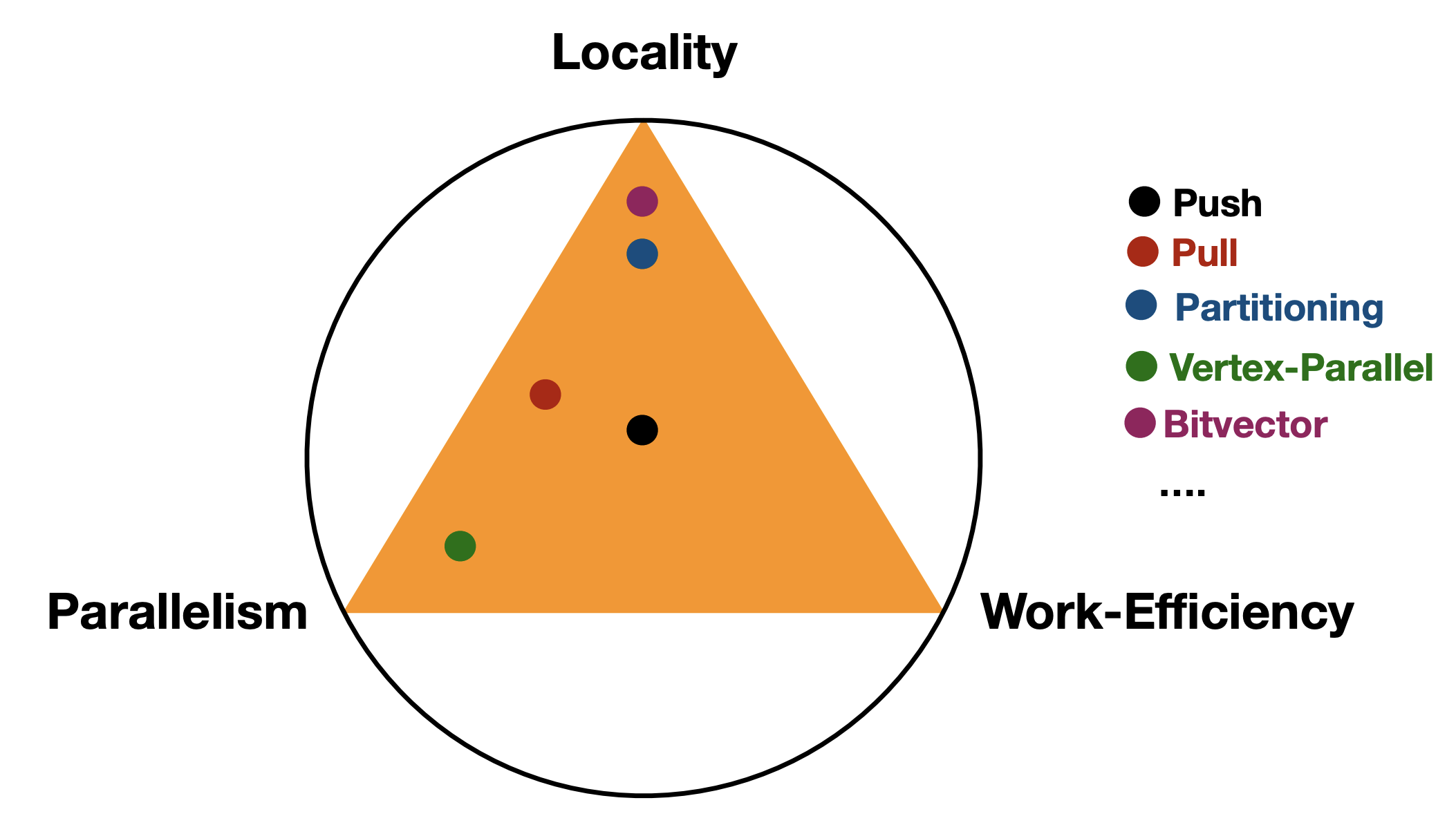
- 局部性:
- 我可能比较喜欢局部性,这样我的缓存就起作用了 ,这样需要将图进行分区,这样我不得不添加数据结构,及其额外的计算开销
- 并行性:
- 我可能不太需要这么大的并行性(核数少),因为我无法利用到它,就没有用
- 工作效率:
- 分区越多,局部性可能越好,但是工作效率会比较低。
对于上述几个点解释一下:
- Push 和 Pull: 因为Pull有竞态条件(可能需要锁),相比之下工作效率较低。
- Push 和 Partitioning: 通过分区,你可以获得较好的局部性,但是你需要做额外的工作,并且会限制并行
用什么方法取决于你的算法,图结构,硬件。如果用了比较差的优化方法,可能导致相差100倍的性能问题
Graphlt 目标
将算法与图应用的优化解耦
算法:要计算什么
- 需要以高层次:忽略所有优化细节
优化(调度):如何计算
- 能容易上手:用户可能会尝试不同的组合
- 足够强大: 能够打败手写优化库
Graphlt 接口
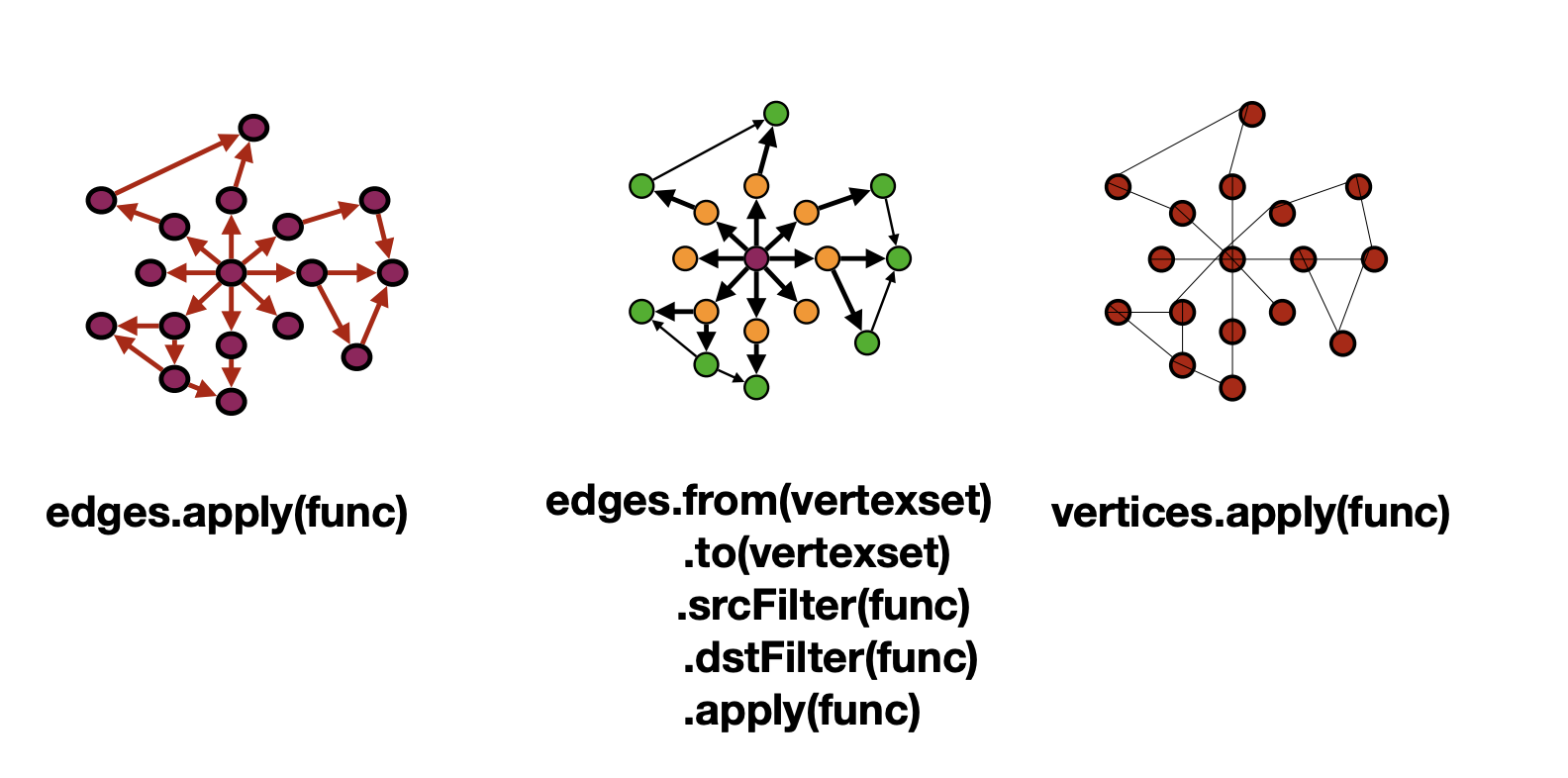

优化方向
方向优化(
configApplyDirection):用于确定在稀疏或稠密的场景中,数据流的方向,如从源到目标或反向。- 稀疏/稠密操作:如稀疏推送(
SparsePush)、稠密推送(DensePush)、稠密拉取(DensePull)、以及混合操作(DensePull-SparsePush、DensePush-SparsePush),这些是针对不同图密度条件下的数据传播策略。
- 稀疏/稠密操作:如稀疏推送(
并行化策略(
configApplyParallelization):包括串行、动态顶点并行、静态顶点并行、面向边的动态顶点并行、以及边并行等策略,用于提高并行计算的效率。缓存优化(
configApplyNumSSG):优化顶点计数,如固定顶点计数或面向边的顶点计数,以提升内存缓存效率。NUMA优化(
configApplyNUMA):处理非统一内存访问的多线程执行,支持串行、静态并行和动态并行模式。数据布局(AoS/SoA):结构数组(AoS)或数组结构(SoA)的选择会影响内存访问的性能。
顶点集数据布局(
configApplyDenseVertexSet):如位向量(bitvector)或布尔数组等不同的顶点集表示方法,影响空间和时间性能。
其他方案的对比
实际上,这种方案已经被英伟达等等采纳。
学术界的东西把关键技术部分搞定了,然后工业界拿去二次开发。
Halide
第一个提出将将调度与算法解耦。
一种新的语言和编译器
最初为图像处理开发
专注于规则网格上的模板操作
处理复杂的模板核流水线
支持其他操作,如归约和扫描
主要目标:
在每种架构上达到或超越手工优化性能
减少编写高度优化代码的重复劳动
提高代码的可移植性而不损失性能
示例:

如果你想手动优化,会得到

与传统方法对比
局部拉普拉斯滤波器(Local Laplacian Filters)在不同开发平台上的性能对比如下:
- 参考实现:C++代码约300行,作为基准。
- Adobe实现:用于Photoshop Camera Raw/Lightroom,代码量为1500行,耗时3个月开发,性能比参考实现快10倍。
- Halide实现:仅用60行代码,由实习生在一天内完成,性能提升20倍(相对于参考实现),并比Adobe实现快2倍。
- GPU实现:使用GPU版本的Halide,性能比参考实现快90倍,比Adobe实现快9倍
关键思想
将算法从调度中解耦
- 算法: 要计算什么
- 算法定义管道为纯函数
- 管道的各阶段是从坐标到值的映射函数
- 执行顺序和存储方式未被明确指定
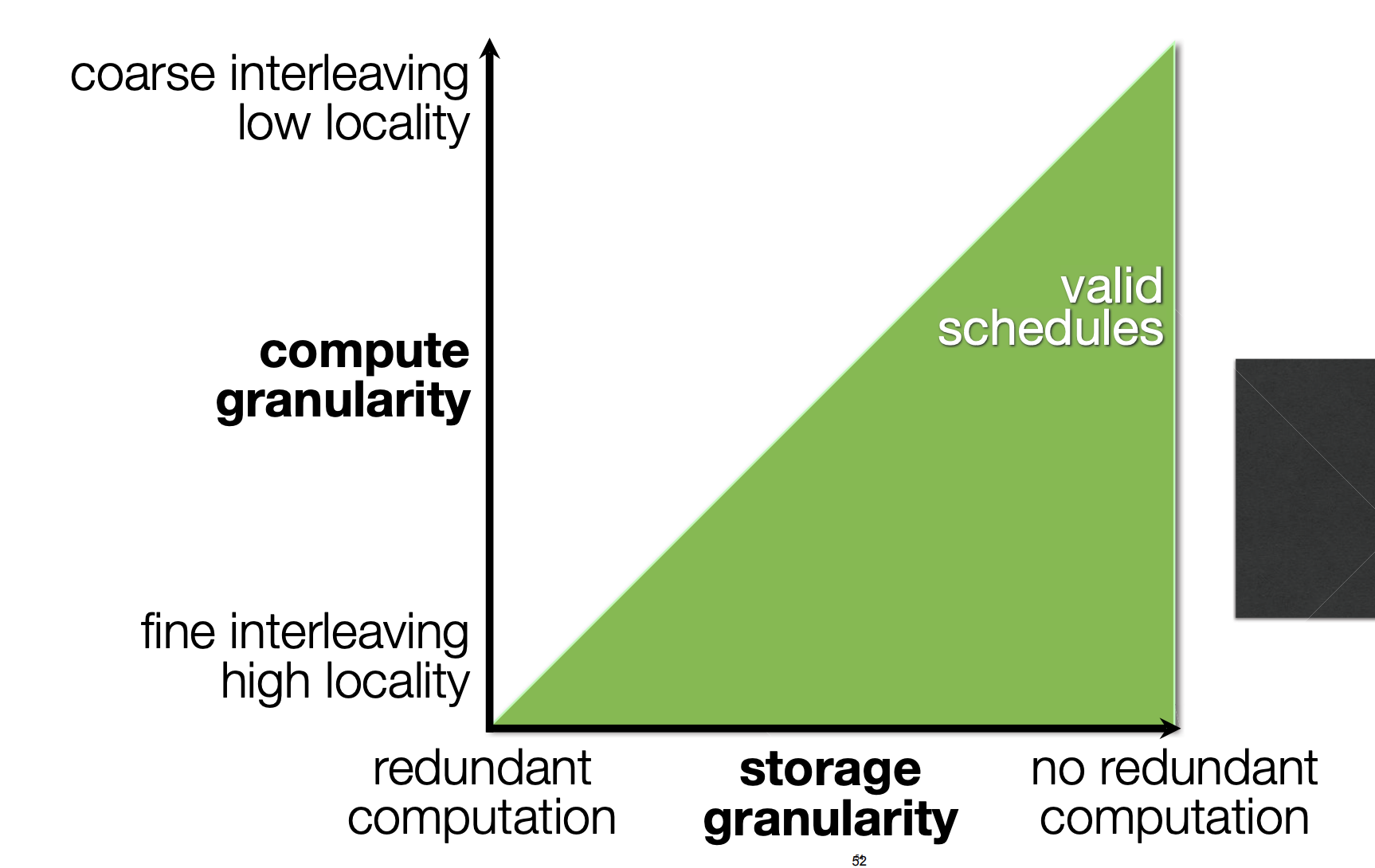
- 调度:在哪里,何时计算
- 针对具体的体系结构
- 单一的同一模型适用于所有调度
- 足够简单,便于搜索和暴露给用户
- 同时足够强大,能够超越专家的调优代码
自动调优:OpenTuner
性能工程的核心在于找到合适的参数和策略来优化系统或程序。具体包括:
- 矩阵乘法中的块大小(即“巫术参数”)
- 动态内存分配项目中的策略
- 调用GCC编译器优化程序时的标志
- GCC有400多个flag
- Halide中的调度
- GraphIt中的调度
如何找到正确的值
基于建模:构建全面的模型
- 优点: 能够解释给定参数;
- 缺点,难以建模;并不是所有东西都可建模;模型可能缺少一些关键组件
启发式:基于经验法则,可能需要硬编码
- 优点:简单可行
- 缺点:始终是次优性能;可能某些情况下非常糟糕
穷举搜索:经验性评估所有可能的值,例如对于S的所有可能整数值。
- 优点:可以找到最优
- 缺点: 只适用于评估过的输入;耗时长(可以通过剪枝来缩小搜索空间)
自动调优,方法如下
- 定义可接受值的空阿金
- 随机选择其中一个
- 评估给定性能
- 设置时间限制
- 根据反馈选择新的值
- 返回步骤3
OpenTuner
开源的自动调优框架
论文阅读: Graphlt
摘要
这篇文章介绍了 GraphIt,一种专为图计算设计的新领域特定语言(DSL)。它能够针对不同规模和结构的图以及具有不同性能特征的算法,生成高效的实现。文中指出,图应用的性能瓶颈不仅依赖于算法和底层硬件,还依赖于输入图的大小和结构。因此,程序员需要尝试多种技术组合,权衡局部性、工作效率和并行性,才能为特定的算法和图类型开发最佳实现。
GraphIt 通过将算法的“计算内容”和“如何计算”分开,使程序员可以更容易地在优化选项中进行探索。算法部分通过算法语言描述,而性能优化通过调度语言来指定。该设计使得程序员在编写算法时能够更简单地表达,同时暴露出更多优化的机会。
主要优化包括边遍历方向、数据布局、并行化、缓存、NUMA(非一致性内存访问架构)和内核融合等。调度语言允许程序员通过组合大量的优化方法,轻松地搜索这个复杂的优化权衡空间。此外,算法和调度的分离使得 GraphIt 能够在其上构建一个自动调优器,自动发现高性能的调度方式。
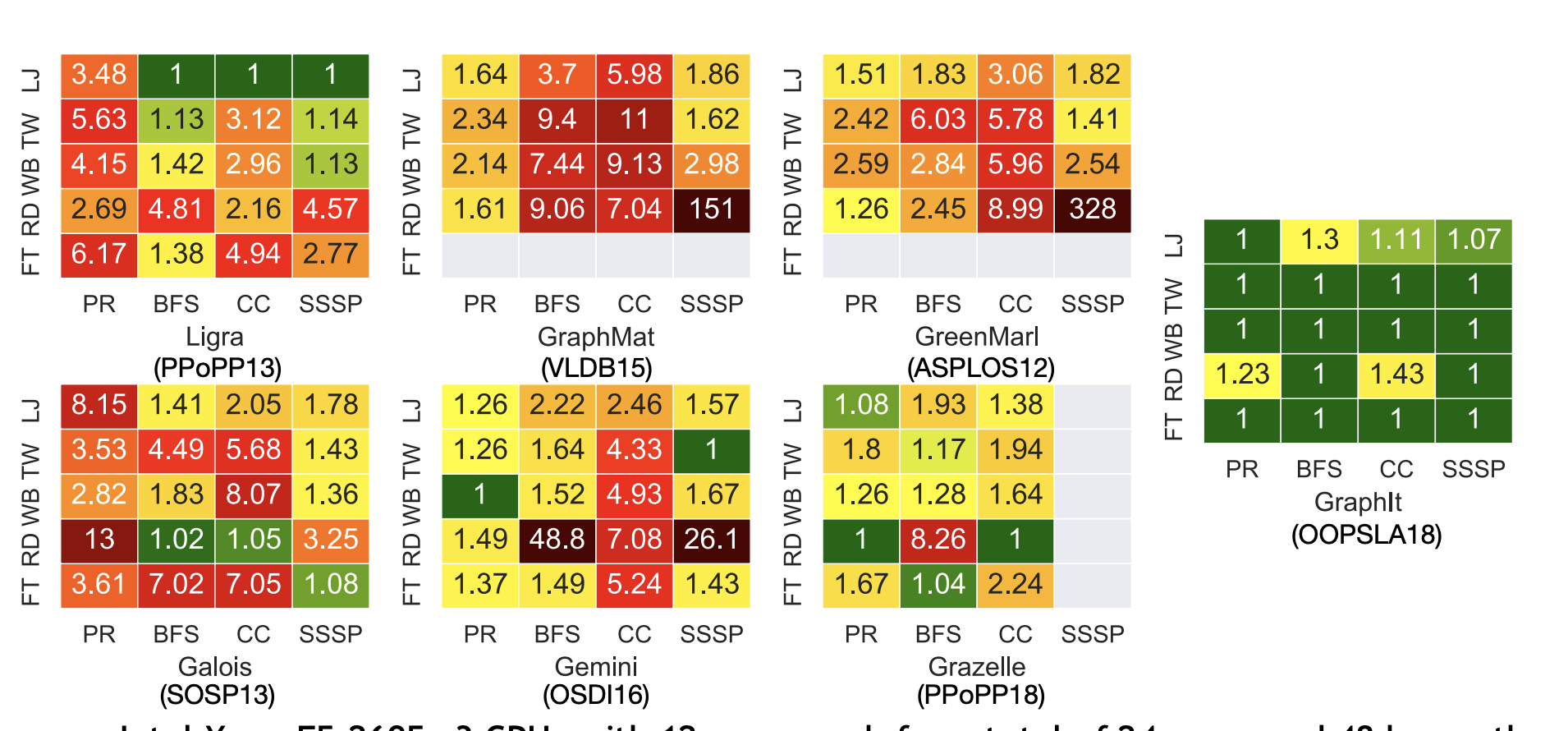
通过引入图迭代空间(Graph Iteration Space)来表示、组合和验证大量优化,编译器可以确保优化的有效性。实验表明,GraphIt 在 32 项实验中有 24 项性能优于现有的 6 种主流共享内存框架(如 Ligra、Green-Marl 等),并且在其他实验中,性能下降不超过 43%。
总结而言,GraphIt 能够通过减少代码量、自动优化,提供比其他框架更快的性能表现
1. 介绍
近年来,许多领域(如社交网络分析、机器学习和生物学)出现了拥有数十亿个顶点和数万亿条边的大型图。提取信息通常需要运行算法以识别重要顶点、查找顶点之间的连接和检测感兴趣的社区。加速这些算法可以提高数据分析应用的效率,改善网络服务质量。
为每种算法和输入类型编写手工优化代码是不可行的。因此,使用编译器方法从高级规范生成高效实现是一个不错的选择。然而,现有的图领域特定语言(DSL)不支持优化组合,也没有向程序员提供全面的性能调优能力。
我们引入了GraphIt,一种新的图DSL,能够为不同大小和结构的图上的多种算法生成高效实现,性能与最先进的框架相当或更快。GraphIt通过使程序员能够轻松找到特定算法和输入图的最佳优化组合来实现良好的性能。本文重点提供机制,使得轻松和高效地探索优化空间成为可能。
GraphIt将算法规范与性能优化的选择分开。程序员使用基于顶点和边集的高层运算符的算法语言来指定算法。性能优化则使用单独的调度语言来指定。算法语言简化了算法的表达,并通过将边处理逻辑与边遍历、边过滤、顶点去重和同步逻辑分离,揭示了优化机会。我们将图优化公式化,包括边遍历方向、数据布局、并行化、缓存、NUMA和内核融合优化,作为局部性、并行性和工作效率之间的权衡。调度语言使程序员能够通过组合大量边遍历、顶点数据布局和程序结构优化,轻松搜索复杂的权衡空间。
GraphIt引入了边遍历、顶点数据布局和程序结构优化的新调度表示。受密集循环的迭代空间理论启发,我们引入了一个抽象图迭代空间模型来表示、组合并确保边遍历优化的有效性。我们将图迭代空间编码到编译器的中间表示中,以指导程序分析和代码生成。算法与调度的分离还使GraphIt能够自动搜索高性能调度。由于调度空间大且应用程序运行时间长,因此进行全面搜索成本高昂。我们表明,通过自动调优,能够在更少的时间内发现具有良好性能的调度。熟悉图优化的程序员可以直接利用调度语言调优性能
论文作出了以下贡献:
- 系统分析图优化中的局部性、工作效率和并行性之间的基本权衡(第2节)。
- 高层算法语言,将边处理逻辑与边遍历、同步、更新顶点跟踪和去重逻辑分离(第3节)
- 新的调度语言,允许程序员通过组合边遍历、顶点数据布局和程序结构优化来探索权衡空间(第4节)。
- 新颖的调度表示,即图迭代空间模型,能够表示、组合并推理各种边遍历优化的有效性(第5节)。
- 一个编译器,利用算法语言上的程序分析和编码图迭代空间的中间表示,以生成不同优化组合的高效有效实现(第6节)。
- 对GraphIt的全面评估,表明在32个实验中,其性能在24个实验中超过次快的最先进框架,提升幅度最高可达4.8倍,并且在其他实验中从未比最快框架慢超过43%(第7节)。
6. 编译器的实现
这部分描述了GraphIt编译器,该编译器从算法和调度生成优化后的C++代码。我们还在编译器的基础上构建了一个自动调优器,以自动找到高性能的调度
8. 相关工作
GraphIt通过组合大量有效的优化显著扩展了优化空间,支持比现有框架多两个数量级的优化组合。GraphIt还通过解放程序员免于指定低级实现细节(如更新顶点跟踪和原子同步)来简化编程。
很多框架也引入了NUMA和缓存优化来改善局部性。通过图分区来改善图应用的缓存性能。然而,这两种技术尚未在通用编程模型中集成或与方向优化结合。
其他共享内存系统采用以顶点为中心的模型,挖掘顶点之间的数据并行性。程序员指定每个(活动)顶点迭代执行的逻辑。
关于运用子GPU上的论文。gpu-graphit.pdf (intimeand.space)
外存图处理框架。同样是集中在改善访问的局部性、并行性和工作效率上。但是当优化的方向从DRAM/Cache的边界,到Disk/DRAM的边界时,用到的权衡空间非常的不一样。GraphIt仅仅关注内存而已。
分布式图处理框架。由于更大的网络通信开销和更强的负载均衡需求,分布式图处理系统的权衡空间也不同。GraphIt使用的技术,如方向优化和增强局部性的图划分,也可以应用于分布式领域。这些系统在单台机器上运行时,通常无法超越共享内存框架
调度语言。GraphIt引入了一种表达性强的调度语言。现有调度语言的例子包括Halide。这些语言主要关注于操作密集数组的应用中的循环嵌套优化。与这些调度语言不同,GraphIt的调度语言是为图应用而设计的。它是第一种旨在解决图应用、图数据结构和图优化挑战的调度语言。它允许程序员进行数据布局转换,并允许算法与调度的完全分离。
物理模拟DSL。GraphIt受物理模拟的DSL。然而,Simit和Liszt不支持在顶点和边上的高效过滤,也没有调度语言。