Lec 22 图优化
总览
- 什么是图?
- 图的表示
- BFS的实现
- 优化方法
- 并行计算
- 图的压缩和重排序
什么是图
- 顶点代表对象
- 顶点代表对象之间的关系
- 顶点和边都可以有类型和元数据
图的应用
示例
跟你同个高中的所有朋友
找到与某些人共同的朋友
社交网络推荐一些可能你认识的朋友
产品推荐
聚类,知识图谱
连接学——一种神经网络结构
图像分割
图的表示
- 给定点标记为0到n-1
邻接矩阵和邻接表
表示m条边和n个顶点需要多少空间要求呢?
邻接矩阵:n*n 邻接表: O(n + m)
压缩稀疏行格式
Compressed Sparse Row,CSR
思路是两个数组,一个是Offsets 一个 Edges
Offsets[i]数组存储顶点、
i的起始边, Edges 数组中开始的位置。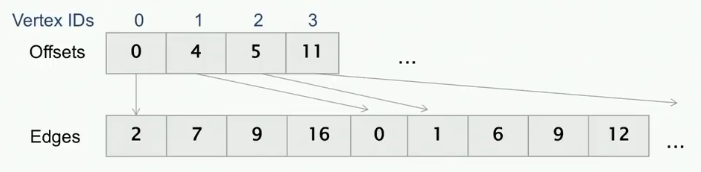
我们如何知道一个顶点的度?
通过比较下一个offset和自己的offset(做减法即可),比如顶点0有4个(出)边
空间要求呢?
O(m+n)
权值怎么存储?
可以通过额外的数组或与 Edges 数组交错存储(可以提高局部性,即缓存命中)来存储边上的权值
图表示的权衡
对于不同表示方法, 他们的操作的成本是多少
| 操作 | 邻接表 | 边列表 | 邻接表 | CSR |
|---|---|---|---|---|
| 存储成本/扫描整个图 | O( | O(m) | O(m+n) | O(m+n) |
| 添加一条边 | O(1) | O(1) | O(1) / O(deg(v)) ,取决于用数组还是链表表示边 | O(m+n) |
| 从某个顶点删除一条边 | O(1) | O(m) | O(deg(v)) | O(m+n) |
| 找到某个顶点v所有邻接顶点 | O(n) | O(m) | O(deg(v)) | O(deg(v)) |
| 判断w是否是v的邻接顶点 | O(1) | O(m) | O(deg(v)) | O(deg(v)) |
剩下部分,我们会用CSR表示法来介绍图的实现
- CSR格式特别适合用于稀疏图
- CSR格式适用于静态算法——不会对图进行更新
- CSR非常适合用来执行遍历,给定某些顶点的邻居:
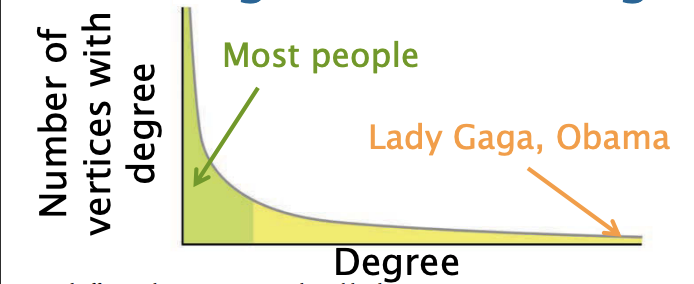
当今世界的图的性质
- 非常大(但是也不会太大)

- 稀疏图(m <<
) - 顶点的度倾斜严重
- 这种现象称为幂律分布(power low degree distribution)
实现图的BFS算法
给定一个顶点s,按照距离大小顺序访问其他所有的顶点
需要的输出(包括中间结果)
顶点访问顺序
- D, B, C, E, A
每个顶点到起始点D的距离
A B C D E 2 1 1 0 1 BFS树,每个顶点都有一个父节点,这个父节点是它在前一层的邻居

顺序BFS算法
假设是一个CSR表示
- 两个列表,Offset和Edges
- n个顶点,m条边(假设Offset[n] = m)
int* parent = (int*) malloc(sizeof(int) * n);
int* queue = (int*)malloc(sizeof(int) * n);
for (int i = 0; i < n; i++) {
parent[i] = -1;
}
queue[0] = source;
parent[source] = source;
int q_front = 0; q_back = 1;
while (q_front != q_back) {
int current = queue[q_front++]; // dequeue
int degree = Offset[current+1]-Offset[current];
for (int i = 0; i < degree; i++) {
int ngh = Edges[Offsets[current] + i];
// check if neightbor has been visited
if (parent[ngh] == -1) {
parent[ngh] = current;
//enqueue neighbor
queue[q_back++] = ngh;
}
}
}这个代码中,成本最高的代码部分发生在哪里?
Solution: 这里有m次的随机访问,如果父数组并不能fit我们的缓存,就会导致经常性的缓存未命中
if (parent[ngh] == -1) {
....
}分析程序(粗略地)
我们来分析一下冷缓存下,发生缓存未命中的次数。(假设cache size << n(顶点数); 缓存行大小64字节,4字节int),下面列举各个阶段的次数
- 初始化: n/16。 解释: 每个缓存行容纳16个整数,遍历parent时每16次赋值,就会导致一次缓存未命中
- 入队:n/16,每个节点都会被顺序地访问。
- 访问Offset数组:n。 解释,主循环中,每次访问一个节点,都会视为缓存未命中,因为这里是随机访问,因为current的值我们并不能预测,可以是任何值
- 访问Edges数组:
。解释:m/16是因为会邻居数组被顺序访问。至于2n,因为每当我们访问特定顶点的边时( Edges[Offset[current] + i]),第一条缓存行可能不仅仅只包含该顶点的边,同理,最后一行缓存行。最坏的情况下,加载一个顶点的所有邻居可能会浪费两条缓存行。 - 访问parent数组:m。 解释每次发现一个新邻居时,都会检查并更新
parent数组 - 出队: n/16
因此综合以上,未命中的总数为
优化思路
如果我们可以在缓存中适配一个大小为 n 的位向量(bitvector)?
- 可以减少缓存未命中
- 需要对bit做计算
比如, 在我们的高成本代码那里,访问parent数组之前,用位向量判断。
- m次的缓存未命中,就变成了n次

int nv = 1 + n/32表示的是位向量所需的整数个数。1是为了处理可能有的额外整数,即在n不是 32 的倍数时,最后一个整数可能会包含不完全的 32 位
性能优化方法
并行实现BFS(TODO)
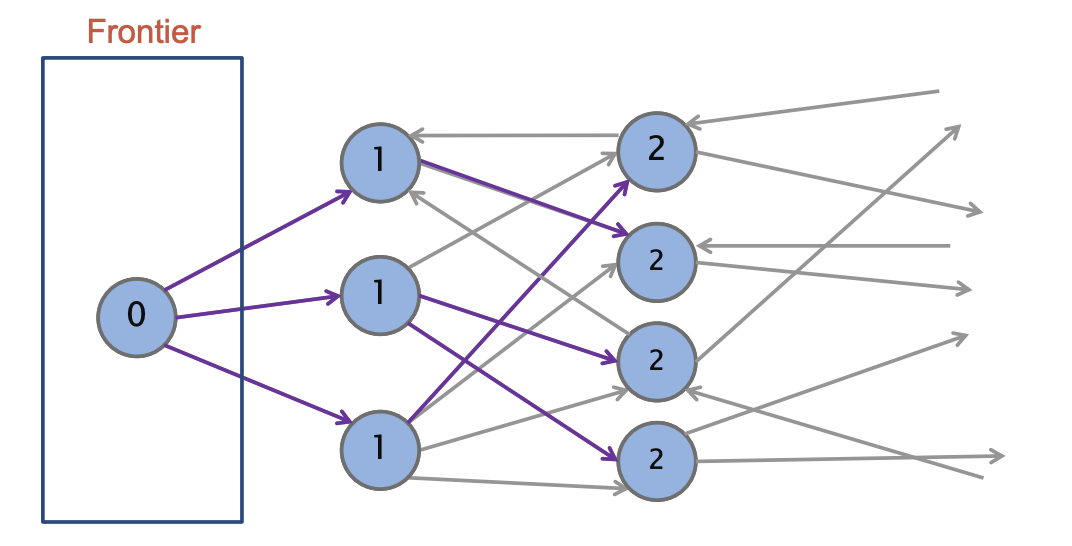
- 并行处理前沿顶点: BFS的每一层可以看作是一个前沿(frontier),其中包含了当前层的所有顶点。对于每一层的顶点,我们可以并行地处理这些顶点的邻居。
- 并行处理顶点的出边: 在每个顶点
v的邻居的处理上,我们可以进一步并行化。例如,对于顶点v,可以并行地处理v的所有出边,将邻居顶点加入到下一层前沿。
难点
- 竞争条件(Races)。
- 负载均衡(Load Balancing),在并行处理中,顶点的出边数量可能会有所不同,导致一些线程的工作负载较重。(要是用cilk的话,因为有工作窃取,可能不是个问题)
BFS(Offsets, Edges, source) {
// parent, frontier, frontierNext, and degrees 都是数组
// 初始化
cilk_for(int i = 0; i < n; i++ ) parent[-1] = -1;
frontier[0] = source;
frontierSize = 1;
parent[source] = source;
// loop
while(frontierSize > 0) {
cilk_for(int i = 0; i < frontierSize; i++)
degrees[i] = Offsets[frontier[i]+1] – Offsets[frontier[i]];
// 在degress数组上做前缀和操作,
cilk_for(int i = 0; i < frontierSize; i++) {
v = frontier[i];
index = degrees[i];
d = Offsets[v+1] - offsest[v];
for (int j = 0; j < d; j++) { // 也可以并行 (为什么要这一步?后面有解答)
ngh = Edges[Offset[v] + j];
if(parent[ngh] == -1 && CAS(&parent[ngh], -1, v)) {
frontierNext[index+j] = ngh;
} else {
frontierNext[index+j] = -1;
}
}
}
// filter out “-1” from frontierNext, store in frontier, and update frontierSize to be the size of frontier (all done using prefix sum)
} // end while
}- 前缀和的例子

- 《算法导论》 27-4问题
frontierNext 怎么组织的
i是开始的偏移量,j则是第j个邻居
图的压缩和重排序
这是一种基于减少内存使用的优化方式,代价是消耗部分CPU资源
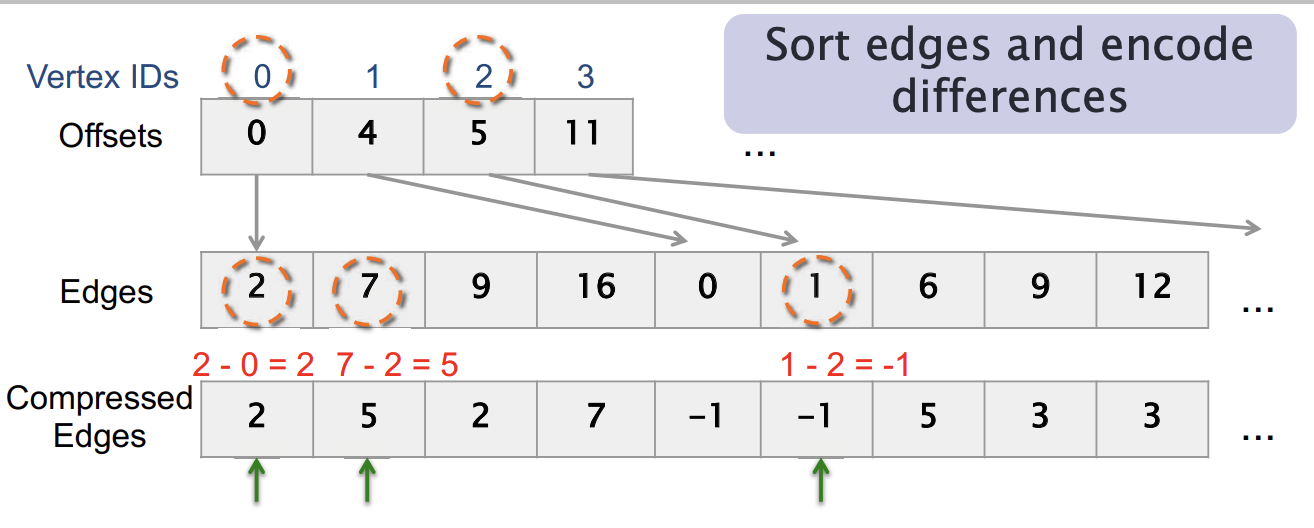
- 将边数组进行排序,并编码差值
- 对于每个顶点v:
- 第一条边: Edges[Offset[v]] - v
- 其他边: Edges[Offsets[v]+i] - Edges[Offsets[v]+i-1]
我们能不能尝试用小于32bit或者是64bit来存储每个值?
思想①: 可变长度码
k-bit(可变长度)码
- 将一个值编码为k-bit块(chunk)
- 用 k-1 比特用于数据,而1bit用于”连续“位
比如编码”401“用1个字节编码, 在二进制中是, 0b110010001
- 编码成两块
- 0b10010001 , 第一个是连续位标志,表示后面还有
- 0b00000011
- 编码成两块
解码只是编码的"回溯"
- 读chunk,直到连续位为0
- 左移数据值,拼接起来
缺点:
- 分支预测很难做出正确的选择
思想②: 不要连续位
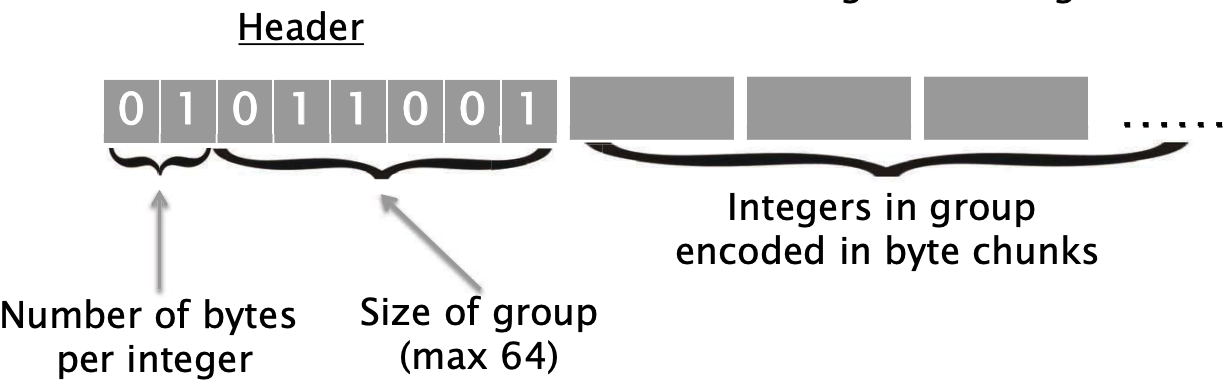
- 缺点:增加空间成本,但是让解码更加便宜(没有分支预测错误)
即时解码(Decoding on-the-fly)技术(TODO, 结合上面例子)
将数据分隔成一个个块(chunks)
在解码端,当数据块被接收时,它们可以同时被解码,而不是等待所有数据块到达后再进行解码
- 而不是等待所有数据块到达后再进行解码,这样就不会节省任何空间!
每块都能并行解码
图的重排序
重新分配顶点的 ID 以提高局部性
- 目标:使顶点的 ID 接近其邻居的 ID,并且邻居的 ID 也彼此接近
- 可以由于较小的“差异”提高压缩率
- 可以由于更高的缓存命中率提高性能
- 各种方法:广度优先搜索(BFS)、深度优先搜索(DFS)、METIS、按度排序等
总结
- 真实世界的图是幂律分布的
- 很多图算法都是不规则的,涉及到很多的随机内存访问,这将称为算法性能的瓶颈
- 你可以通过并行化计算和探索局部性原理(比如位图)
- 针对图的优化可能对某些图效果很好,但对其他没啥效果