Lec 1 介绍&矩阵乘法
这节课主要介绍性能工程相关的背景,以及快速入门: 从一个简单的矩阵乘法出发,启发式地通过各种性能优化方向,最终获取每种方法的优化结果。
总览
- 介绍
- 快速入门:矩阵乘法
介绍
性能的重要性
性能很重要吗? 但是我们也会为了实现某些性质而牺牲性能,比如
- 可调试性
- 鲁棒性
- 安全性
- 模块化
- 可维护性
等等。 如果我们给你2美元,和价值两美元的水你会选哪个? 一般来说你会选择2美元,性能就如同这2美元,就是你的资本,你可以用这两美元来购买某些性质。
摩尔定律已经失效了
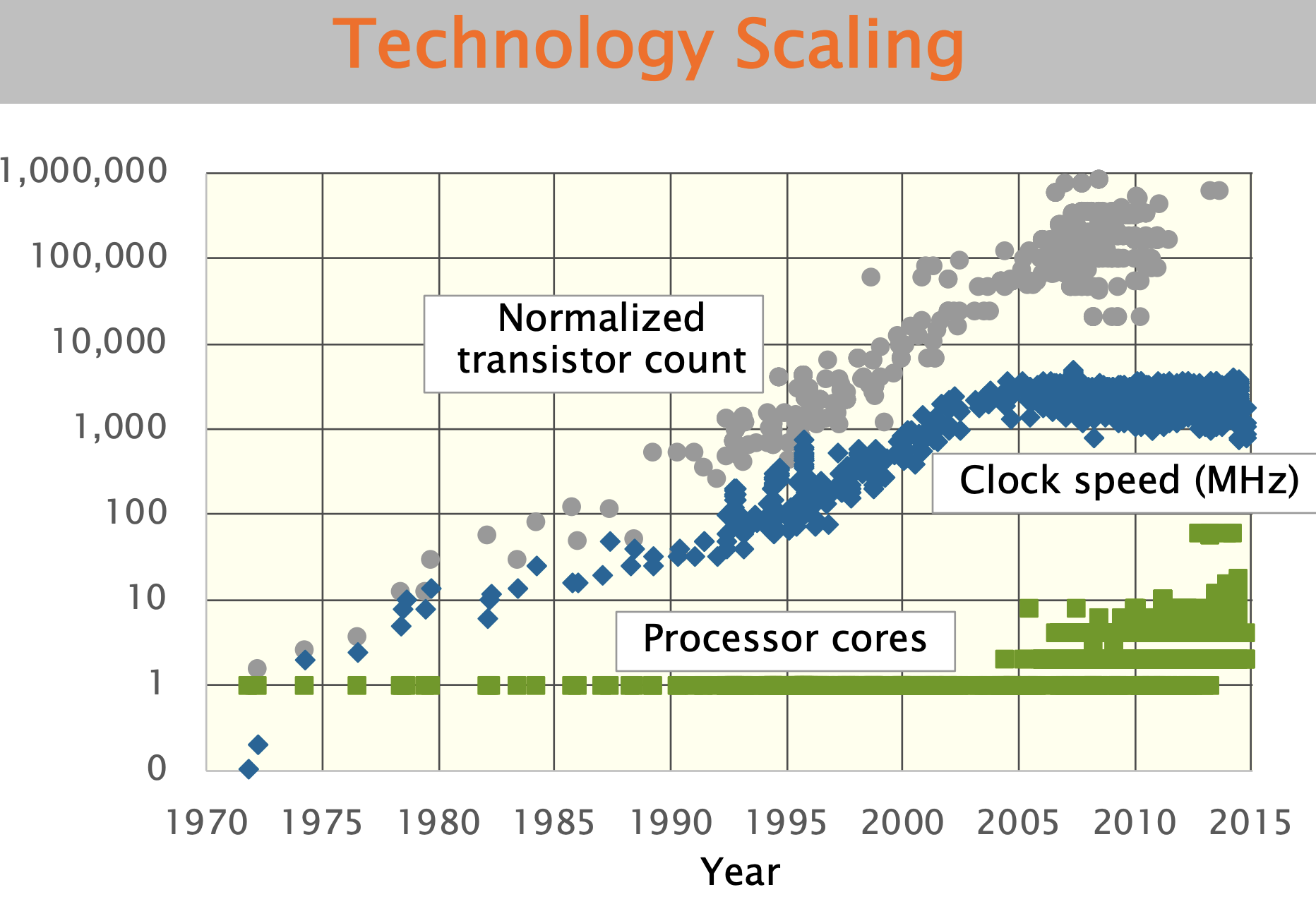
1965年摩尔提出,“每隔大约 18~24 个月,集成电路上的晶体管数量将翻一倍,性能提高,成本下降。”,在2004年以前,摩尔定律基本有效。
但从2004年开始,主频瓶颈出现,在3-4GHz难以提升,虽然在晶体管数量上继续有效,但性能不再线性增长。供应商的解决方案💡:转向多核架构。
虽然摩尔定律持续提升计算机性能。 但现在,这种性能可以通过配备复杂缓存、矢量单元、 GPU、FPGA 等的多核处理器实现。也就是说,性能已经不再免费的了。软件必须适应和高效利用硬件资源。
从现在看,我们说,摩尔定律已经结束了。英特尔在 2014 年实现了 14 纳米工艺,根据摩尔定律,英特尔应该在:F
- 2016 年实现 10 纳米工艺
- 2018 年实现 7 纳米工艺
- 2020 年实现 5 纳米工艺
- 但英特尔直到 2019 年才发布 10 纳米工艺!
半导体技术将不再能为应用程序提供免费的性能。这场Party 已经结束了~

现代桌面CPU

现代多核桌面处理器包含:
- 并行处理核心
- 向量单元(vector)
- 缓存
- 预取器(prefetchers)
- GPU
- 超线程
- 动态频率调节
这些特性的利用可能颇具挑战性。在本课程中,您将学习编写快速运行代码的原则和实践。
示例:矩阵乘法
运行设备
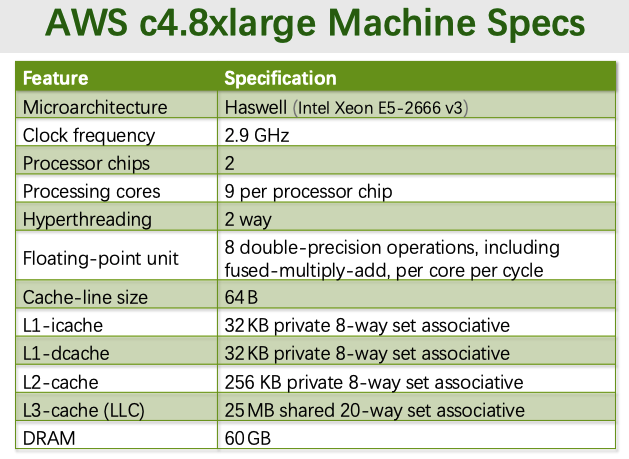
FPU上面的是什么意思?
Solution: 每个核心每个周期能执行 8 个双精度 FLOP,包含FMA,意味着一个指令可以完成两个FLOP(乘加和),每个核心每周期可以发射 2 条 FMA 指令。AVX 指令集(后面会学习到)
计算峰值双精度浮点性能(GFLOPS)能达到多少?
Solution: $(2.9 * 10^9) * 2 * 9 $ =$ \approx 836 $GFLOPS
NOTE
笔者用的是2020款的Macbook M1,GFLOPS 大概只有 160 GFLOPS
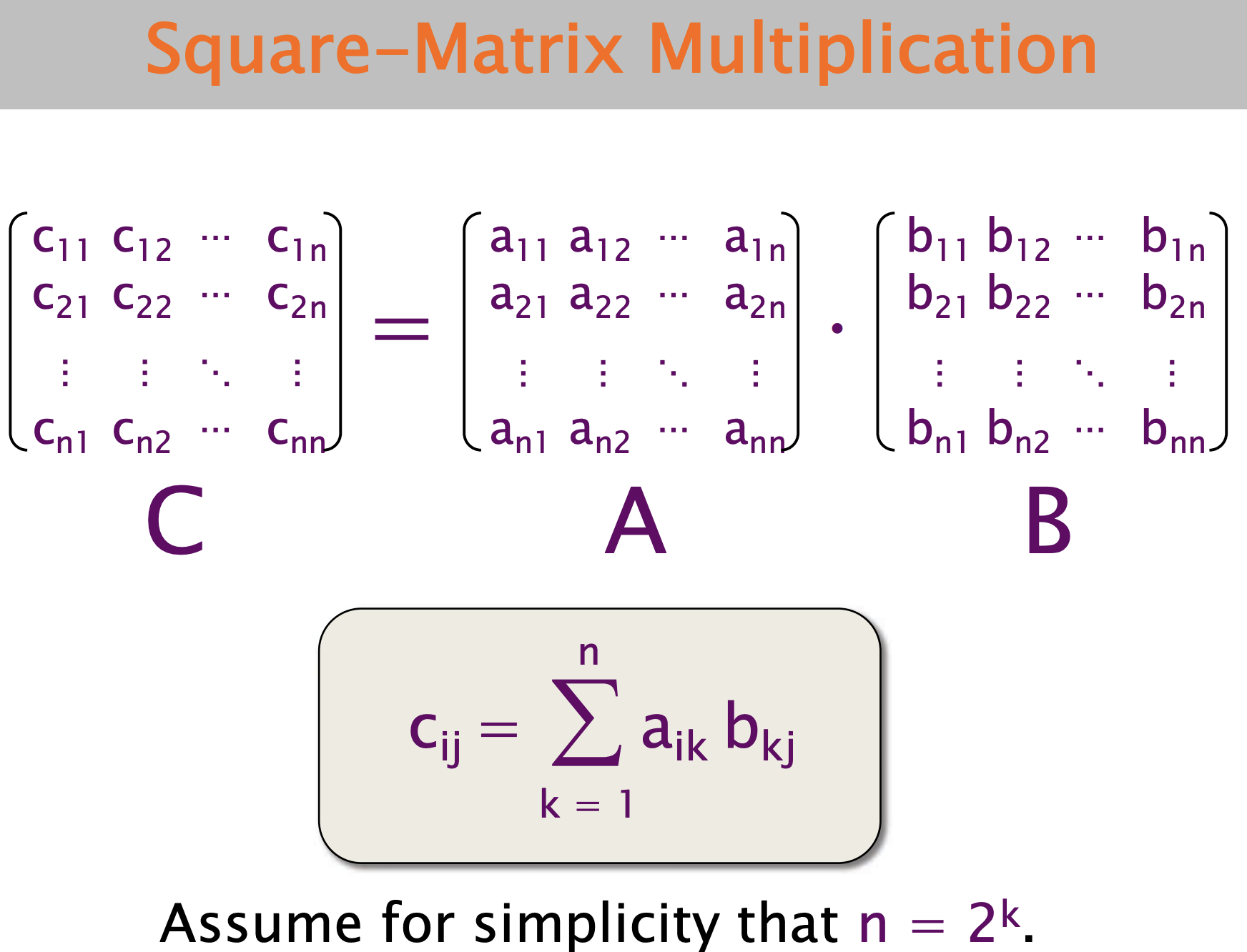
版本0:初始代码
Python实现第一个版本
import random
import time
# n = 4096
n = 1024
# 初始化矩阵 A、B、C
A = [[random.random() for _ in range(n)] for _ in range(n)]
B = [[random.random() for _ in range(n)] for _ in range(n)]
C = [[0 for _ in range(n)] for _ in range(n)]
# 记录开始时间
start = time.time()
# 矩阵乘法:C = A × B
for i in range(n):
for j in range(n):
for k in range(n):
C[i][j] += A[i][k] * B[k][j]
# 记录结束时间
end = time.time()
# 输出运行时间(秒)
print('版本1——python嵌套耗时: %.6f' % (end - start)) # 结果137秒分析计算的背后数据:
次浮点数操作 MFLOPS:
峰值
版本1:采用C语言
/*
* version1: 用C语言实现
*/
#include <stdlib.h>
#include <stdio.h>
#include <sys/time.h>
#define n 1024
double A[n][n];
double B[n][n];
double C[n][n];
float tdiff(struct timeval *start, struct timeval *end) {
return (end->tv_sec - start->tv_sec) +
1e-6 * (end->tv_usec - start->tv_usec);
}
int main(int argc, const char *argv[]) {
// 初始化矩阵 A、B、C
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
A[i][j] = (double)rand() / (double)RAND_MAX;
B[i][j] = (double)rand() / (double)RAND_MAX;
C[i][j] = 0;
}
}
struct timeval start, end;
gettimeofday(&start, NULL);
// 矩阵乘法
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
for (int k = 0; k < n; ++k) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
gettimeofday(&end, NULL);
printf("%0.6f\n", tdiff(&start, &end));
// 结果4.2秒
return 0;
}| 版本 | 实现 | 运行时间(s) | 绝对加速比 | GFLOPS | 占峰值比(%) |
|---|---|---|---|---|---|
| 0 | Python | 137 | 1 | 0.015 | 0.001 |
| 1 | C | 4.2 | 32 | 0.051 | 0.031 |
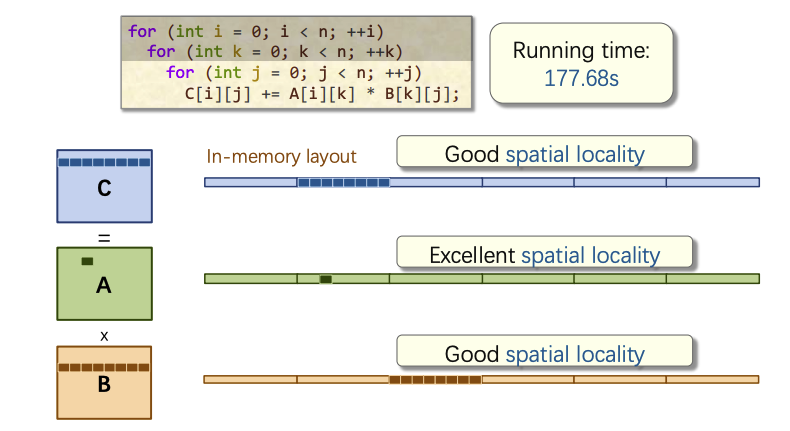
版本2: 更改遍历顺序
这个代码中,行优先存储

初始方案 i, j , k顺序的访问模式为
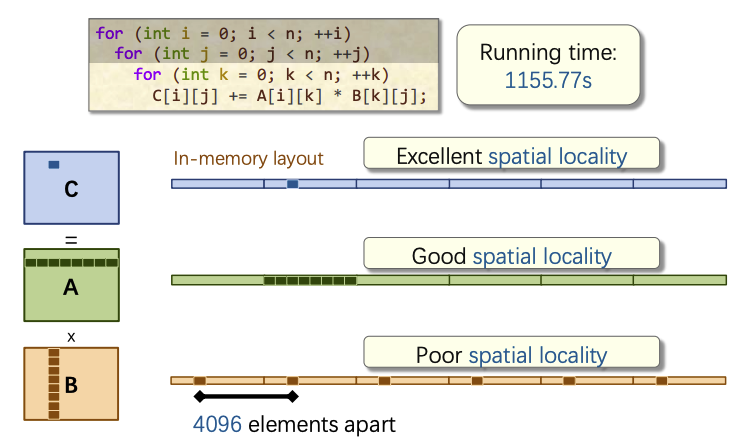
调整顺序后
/*
* version2: 更改遍历顺序,利用局部性
*/
#include <stdlib.h>
#include <stdio.h>
#include <sys/time.h>
#define n 1024
double A[n][n];
double B[n][n];
double C[n][n];
float tdiff(struct timeval *start, struct timeval *end) {
return (end->tv_sec - start->tv_sec) +
1e-6 * (end->tv_usec - start->tv_usec);
}
int main(int argc, const char *argv[]) {
// 初始化矩阵 A、B、C
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
A[i][j] = (double)rand() / (double)RAND_MAX;
B[i][j] = (double)rand() / (double)RAND_MAX;
C[i][j] = 0;
}
}
struct timeval start, end;
gettimeofday(&start, NULL);
// 矩阵乘法
for (int i = 0; i < n; ++i) {
for (int k = 0; k < n; ++k) {
for (int j = 0; j < n; ++j) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
gettimeofday(&end, NULL);
printf("%0.6f\n", tdiff(&start, &end));
// 执行时间为1.38s
return 0;
}到目前为止
| 版本 | 实现 | 运行时间(s) | 绝对加速比 | GFLOPS | 占峰值比(%) |
|---|---|---|---|---|---|
| 0 | Python | 137 | 1 | 0.015 | 0.001 |
| 1 | C | 4.2 | 32 | 0.051 | 0.031 |
| 2 | 更改遍历顺序 | 1.38 | 100 | 1.556 | 0.1 |
版本3: 编译优化级别调整
| 优化级别 | 含义 | 时间(s) |
|---|---|---|
| -O0 | 不优化 | 1.4 |
| -O1 | 开启优化 | 0.37 |
| -O2 | 深度优化 | 0.19 |
| -O3 | 最高优化 | 0.18 |
到目前为止
| 版本 | 实现 | 运行时间(s) | 绝对加速比 | GFLOPS | 占峰值比(%) |
|---|---|---|---|---|---|
| 0 | Python | 137 | 1 | 0.015 | 0.001 |
| 1 | C | 4.2 | 32 | 0.051 | 0.031 |
| 2 | 更改遍历顺序 | 1.38 | 100 | 1.556 | 0.1 |
| 3 | 编译器优化 | 0.19 | 721 | 11.3 | 1.41 |
| 4 | 并行遍历 |