Lec 17 内存模型和无锁同步
阅读资料
- Leiserson, Charles. “A Simple Deterministic Algorithm for Guaranteeing the Forward Progress of Transactions.” Information Systems 57 (2016): 69–74.
总览
顺序一致性
互斥的无锁实现
宽松内存一致性
指令重排序
硬件重排序
重排序的影响
内存屏障
CAS
无锁算法(LOCK-FREE ALGORITHMS)
ABA问题
内存模型
顺序一致性
示例, 一开始 a = b = 0;
; 处理器0
mov 1, a ; Store
mov b, %ebx ; Load; 处理器1
mov 1, b ; Store
mov a, %eax ; Load有没有一种可能,就是在这些处理器都执行完他们的代码后,处理器0的%ebx和处理器1的%eax都包含0值,
这取决于内存模型,即在并行计算机系统上内存操作行为是怎么样的。
NOTE
顺序一致性是是一致性的最标准的的一种
任何执行的结果 都与所有处理器的操作按某个顺序执行的结果相同,并且每个处理器的操作按其程序指定的顺序出现在这个序列中 by Leslie Lamport [1979]
进一步的解释:
- 一个处理器程序定义的指令序列与其他处理器程序定义的相应序列交错,以生成所有指令的全局线性顺序。
- 根据该线性顺序,LOAD指令接收的值,来源于由最近的、且在LOAD指令之前的STORE指令存储到某个地址的
- 硬件可以执行任何操作,但为了使执行保持顺序一致性,LOAD和STORE应该遵循某种全局线性顺序。
回到刚刚的例子,我们把四个语句标号,他们的交错结果,以及最终产生的值的比较如图
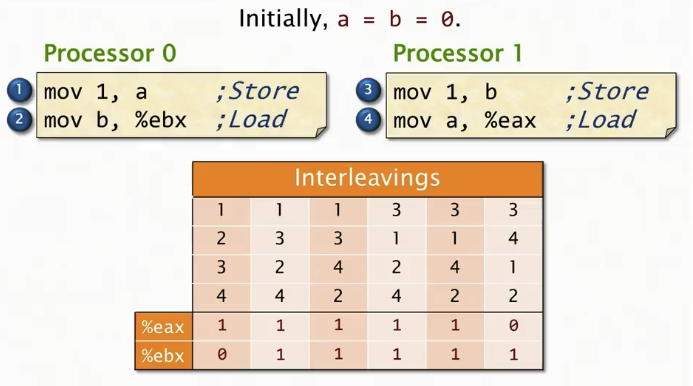
顺序一致性揭示了没有一种执行结果是 %eax = %ebx = 0
IMPORTANT
现实中,没有一个计算机系统会实现成顺序一致性的。它太简单粗暴了,严重限制性能
形式化顺序一致性
指令的执行会带来了一种“发生在之前”(happens before) 的关系,我们可以用
->表示->的关系是是线性的,意味着对于两个不同的指令x, y要么是x->y要么是y->x->的关系遵循处理器顺序,即每个处理器中指令的顺序内存中的某个位置的 LOAD 操作读取的值, 来自
->关系最近 STORE 操作写入的值要使执行后的内存达到顺序一致性,必须存在这样的
->的线性顺序,使得内存状态成立
互斥的无锁实现
并发理论早期最著名成果之一,无需锁也能实现互斥。
回顾
临界区是访问共享数据结构的代码片段,这些数据结构不允许同时被两个或多个线程访问(互斥访问)。 互斥锁大部分实现会利用原子操作指令,确保对锁的获取(加锁)和释放(解锁)是原子的、不可分割的操作。例如
- xchg:交换操作,可以原子地交换寄存器和内存中的值
- test-and-set:测试并设置操作,用于原子地设置锁的状态
- compare-and-swap:比较并交换操作,原子地比较内存中的值与预期值,如果相等则交换
- Load-link/store-conditional:加载链接-存储条件操作,用于实现乐观锁(optimistic locking)
虽然锁能解决临界区的问题,但是引入了一些问题——死锁,护航效应(convoying)
互斥可以仅仅通过使用LOAD和STORE这些内存操作来实现?
Theodorus J. Dekker 和 Edsgar Dijkstra 展示了这是可以做到的,只要计算机系统是顺序一致的。
但是这里不讲解,因为它足够复杂。我们该用比较简单且优雅的方法表达他们的想法。用Peterson'算法。
Alice想玩弄这个称为x小物件,而Bob想将它放好,但是小物件并不能同时满足,所以他们是互斥。他们将重复不断执行各自的代码。
直觉上看,
- 如果Alice和Bob都试图进入临界区域,那么最后写入的那个会自旋,而另一个会继续执行
- 如果只有Alice试图进入临界区域,那么她会继续执行,因为B_wants为false
- 如果只有Bob试图进入临界区域,那么他会继续执行,因为B_wants为false
IMPORTANT
Perterson's 算法实现了临界区的互斥
证明方法:
- 假设为了反证,Alice和Bob都同时进入了临界区域。
- 考虑他们进入临界区域之前各自的最新时间点(the most-recent time)
- 我们将推导出一个矛盾。
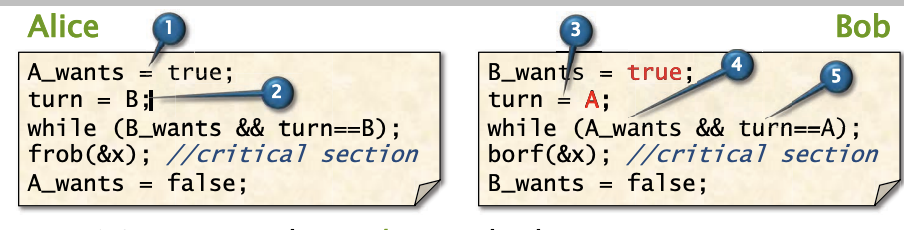
- 不失一般性, 假设Bob是最后写入turn的: write_A(turn = B) -> write_B(turn = A)
- Alice的程序顺序是:write_A(A_wants = true) -> write_A(turn = B)
- Bob的程序顺序是:write_B(turn = A) -> read_B(A_wants) -> read_B(turn)
- Bob实际读到了什么?
- A_wants: A; turn: A => Bob应该自旋。
与前提矛盾,证毕。
IMPORTANT
Peterson's算法保证了饥饿自由: 当Alice想要执行临界区,Bob不能重复在临界区执行两次,反之亦然。
顺序一致性的唯一问题是什么?
到目前为为止, 没有机器支持顺序一致性。
宽松的内存一致性模型
IMPORTANT
Never synchronize through memory. 千万不要用内存来同步
(因为很难做到正确)
当代内存模型现状
- 当代的处理器没有实现顺序一致性。
- 所有处理器都实现了某种形式的宽松一致性。
- 硬件会主动重新排序指令。
- 编译器也可能重新排序指令。
指令(编译器)重排序
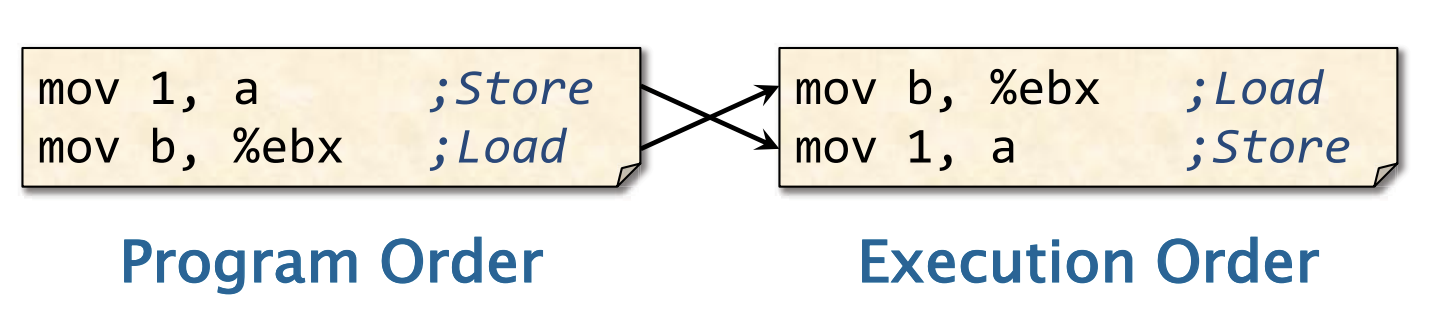
为什么硬件和编译器决定重排序这些指令?为什么硬件更喜欢先做load操作?
Solution:为了通过掩饰加载延迟(load latency)来获得更高的性能——提高指令级并行性。(这种优化可以使处理器在等待某些指令的执行结果时,不必闲置,而是继续执行其他不依赖于这些结果的指令)
对于硬件或者编译器而言,什么 情况下进行的指令重排序可视为安全的
- 当 a != b
- 指令之间不存在数据依赖
- 并且没有并发访问
- 线程之间不会有数据竞争
硬件重排序
在内存总线上,处理器可以非常快速地发出(issue)存储指令,速度超过总线(网络),因此使用了存储缓冲区(store buffer)来解决存储指令和网络速度不匹配的问题,以防止出现停顿(stall)
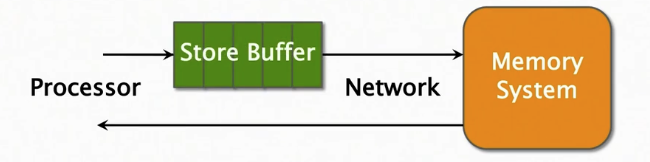
由于加载(LOAD)指令可能会使处理器停顿(stall)直到加载完成(每当你执行LOAD指令时,如果这个数据不在处理器的缓存中,处理器将不得不等待内存子系统返回数据) ,因此LOAD指令优先于STORE指令,通过LOAD旁路技术在实现。
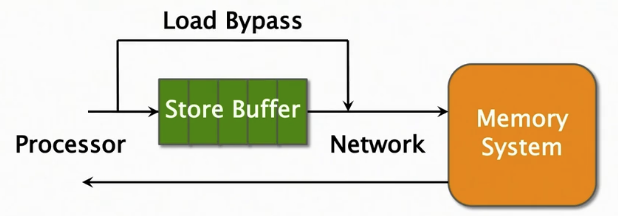
如果LOAD的地址刚好是在STORE缓冲区的怎么办?
SOLUTION: 从存储缓冲区找到该地址的结果并返回。
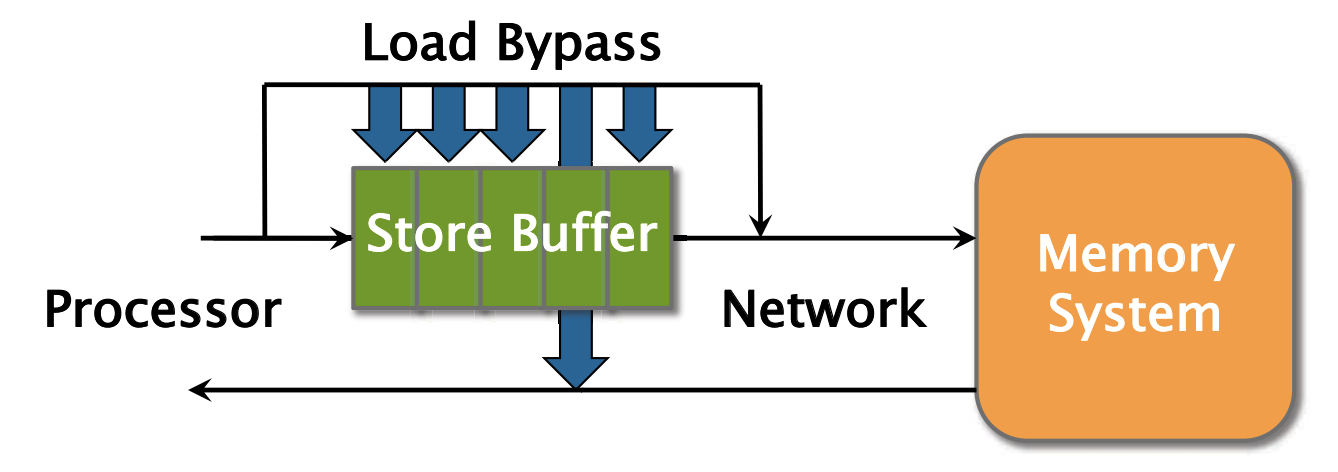
因此,总的来说加载指令可以Bypass不同地址的存储指令.
x86-64 完全存储定序
完全存储定序(TSO, Total Store Order) ,硬件实现的
NOTE
【定理】House rule
LOAD指令不会与其他LOAD指令重排序
STORE指令不会与其他STORE指令重排序
STORE指令不会与前面的 LOAD 指令重排序
LOAD 指令可以与之前的 STORE 指令重排序,但有一种情况一定不能重排序,就是当与两者的存储位置(location)相同时。 前面例子中 A != B
LOAD 和 STORE 指令都不会与 LOCK 指令重排序。
对相同存储位置的STORE指令遵循全局总顺序(global total order)。
LOCK指令遵循全局总顺序。
内存排序保留传递可见性(因果性)。
TSO一致性比顺序一致性要更弱一些
重排序的影响
回到最开始的例子 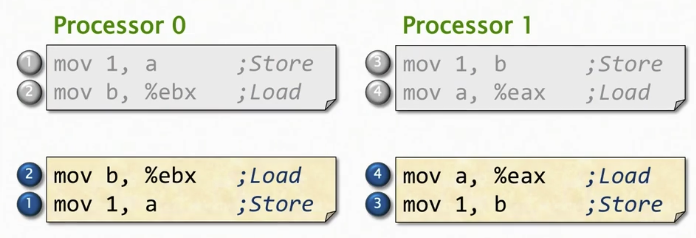
,如果按照<2, 4, 1, 3>的顺序,将产生 %eax = %ebx = 0,我们说指令重排序违背了顺序一致性, 这不仅会发生在硬件重排序,还有可能发生在编译重排序上。这就要求我们
IMPORTANT
Nerver write non-determisitic code
永远不要写不确定的代码
重排序对Perterson‘s 算法的影响

B_wants和A_wants的LOAD指令可能重排序到A_wants和B_wants的Store指令前面,最终可能导致Alice和Bob同时进入临界区!
内存屏障
内存栅栏(或内存屏障, Memory fence/Memory barrier)是一种硬件操作,它强制要求在它前后的指令按一定的顺序执行
内存栅栏,可以通过特定的指令来显式地发出Issue(例如x86架构中的mfence指令),用于确保栅栏之前和之后的内存操作的顺序关系。或者隐式地由某些同步指令(如locking、cas等)执行内存栅栏操作。
Tapir/LLVM编译器通过在C语言头文件stdatomic.h中定义的atomic_thread_fence()函数实现内存栅栏
内存栅栏的典型成本与L2缓存访问的成本相当。
我们要知道,系统都是人类做的,人们通过benchmark代码跑出的结果来判断并行计算的性能,那我也可以将锁的性能做的比内存屏障还要好。
恢复示例的一致性

这样一来,内存屏障前后的指令能保持相对的顺序一致性了。
但是!!! 你还需要确保编译器不会把你搞砸。
过去的解决方案

过去在使用内存屏障(memory fence)时的额外注意事项
- 在过去,为了防止编译器优化掉内存引用,必须将变量声明为
volatile。volatile关键字告诉编译器,该变量的值可能随时会被外部因素改变,因此每次引用都必须从内存中读取,而不是依赖于寄存器中的缓存值。 - 你需要在
frob()和borf()放置编译器屏障来阻止被编译器重排序
用C11恢复一致性
C11语言标准定义了自己的弱内存模型,通过以下方式可以控制硬件和编译器对内存操作的重新排序:
- 声明变量为_Atomic:在C11标准中,可以通过声明变量为
_Atomic类型来指示编译器该变量是原子类型,需要进行原子操作。原子类型的变量可以保证在多线程或并发环境中,其操作是原子的,即不会被中断或重排序。 - 使用原子函数:C11标准提供了一系列的原子操作函数,例如
atomic_load()、atomic_store()等。这些函数能够确保对原子类型变量的读取和写入是原子性的,不会被硬件或编译器进行重新排序或优化。

实现通用的锁
IMPORTANT
Thm1 [Burns-Lynch]
任何仅使用LOAD和STORE内存操作的n线程不发生死锁的互斥算法都需要Ω(n)的空间。(这个定理突显了使用简单的内存操作来实现复杂的并发控制是非常昂贵的)
The2 [Attiya et al.]
在现代计算机上,任何n线程不发生死锁的互斥算法必须使用类似内存屏障或原子的CAS这样昂贵的操作。
因此,硬件设计者在支持这些特殊操作时是合理的。这些操作不仅确保了程序在并发执行时的正确性和可靠性
CAS(比较-交换法)
无锁的内存操作
- LOAD
- STORE
- CAS(compare-and-swap)
介绍
由 x86-64 架构上的 cmpchg 指令提供。C 语言的头文件 stdatomic.h 通过内置函数 atomic_compare_exchange_strong() 提供了 CAS(Compare-And-Swap),该函数可以对各种整数类型进行操作。CAS做的事情是,检查下该内存地址上的值与旧值相同,相同则将内存地址的值改成新值返回true,否则直接返回false;
// 规范
bool CAS(T *x, T old, T new) {
if (*x == old) {
*x = new;
return ture
}
return false;
}它是,原子执行, 因为有隐式屏障,他们的执行顺序不会重排序。硬件操作将不会中间插入到他们
用CAS实现互斥锁
IMPORTANT
【定理】用CAS实现n线程无死锁的互斥算法,能在
证明:
void lock(int *lock_var) {
while (!CAS(*lock_var, false, true)) // 自旋锁
}
void unlock(int *lock_var) {
*lock_var = false;
}只需要给锁本身提供空间即可。
示例:累加问题
int compute(const X& v);
int main() {
const int n = 1000000;
extern X myArray[n];
// ...
int result = 0;
cilk_for(int i = 0; i < n; ++i) {
result += compute(myArray[i]); // note: 这里有竞态数据
}
printf("The result is: %f\n", result);
return 0;
}常规的互斥锁解法
int compute(const X& v);
int main() {
const int n = 1000000;
extern X myArray[n];
mutex L; // new add
// ...
int result = 0;
cilk_for(int i = 0; i < n; ++i) {
L.lock(); // new add
result += compute(myArray[i]);
L.unlock(); // new add
}
printf("The result is: %f\n", result);
return 0;
}一个循环获取了锁以后,如果OS此时将循环迭代换出了,会发生什么?
所有的循环迭代都必须等待。在这个例子中,我们想要的达到的效果是,执行完对x的LOAD操作后自动执行STORE操作。
CAS的解决方案
int result = 0;
clik_for(int i = 0; i < n; i++) {
int temp = compute(myArray[i]);
int old, new;
do {
old = result;
new = old + temp;
} while (!CAS(&result, old, new));
}一个循环获取了锁以后,如果OS此时一个循环迭代的线程交换了,会发生什么?
没有其他循环迭代需要等待。算法是非阻塞的
无锁算法TODO
无锁栈
struct Node {
Node* next;
int data;
};
struct Stack {
Node* head
}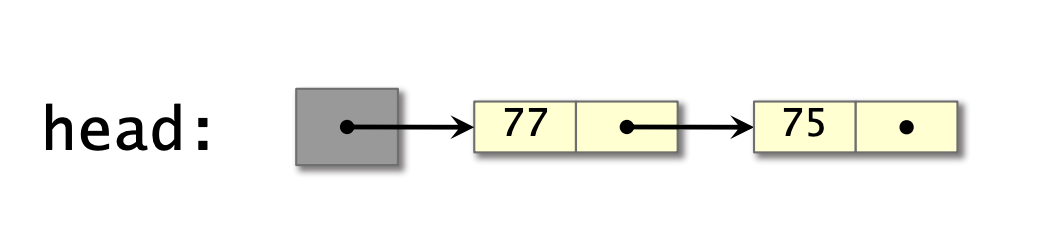 无锁push
无锁push
void push(Node* node) {
do {
node->next = head;
} while (!CAS(&head, node->next, node))
}CAS异常: ABA问题
示例:
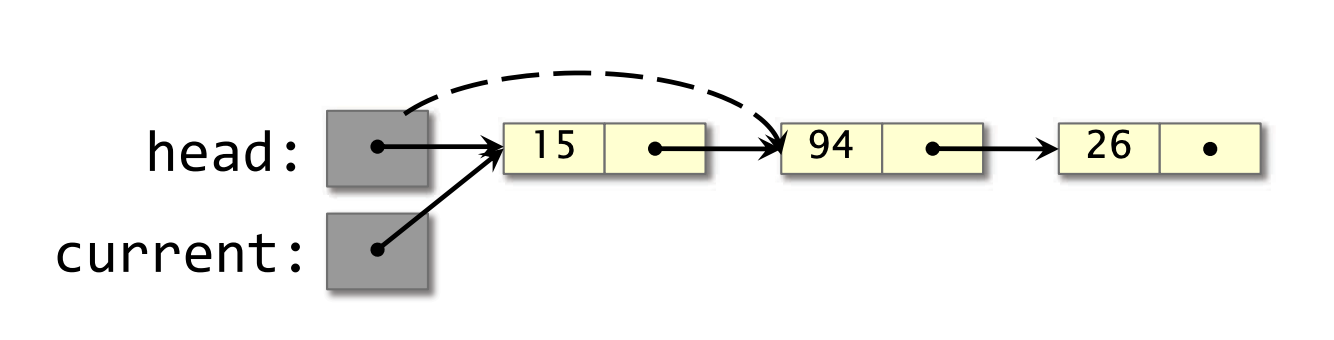
- 线程 1 开始弹出包含 15 的节点,但在读取到
current->next之后停顿(stall)。
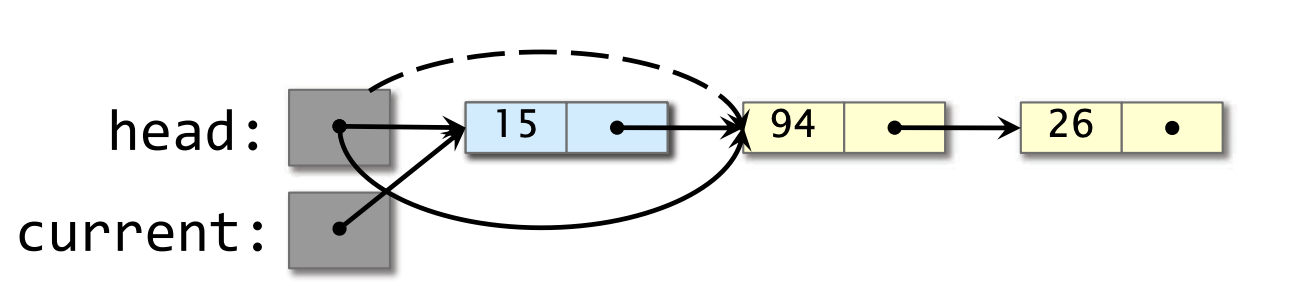
- 线程 2 弹出包含 15 的节点。
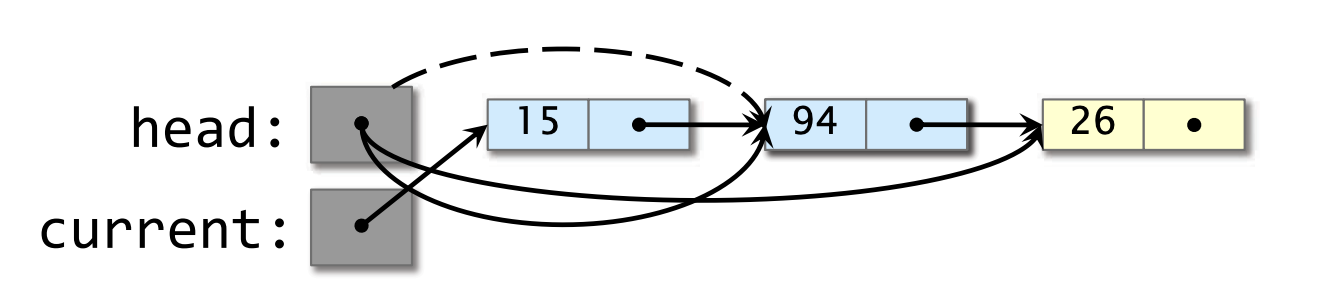
- 线程 2 弹出包含 94 的节点。
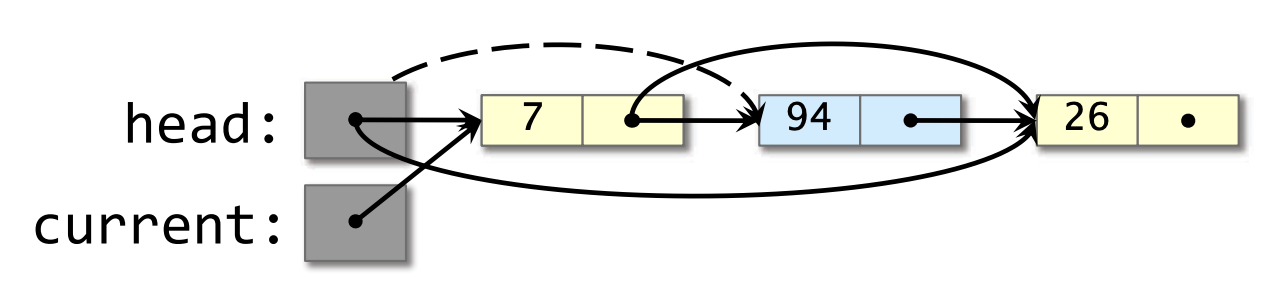
- 线程 2 推入节点 7,重用包含 15 的节点。
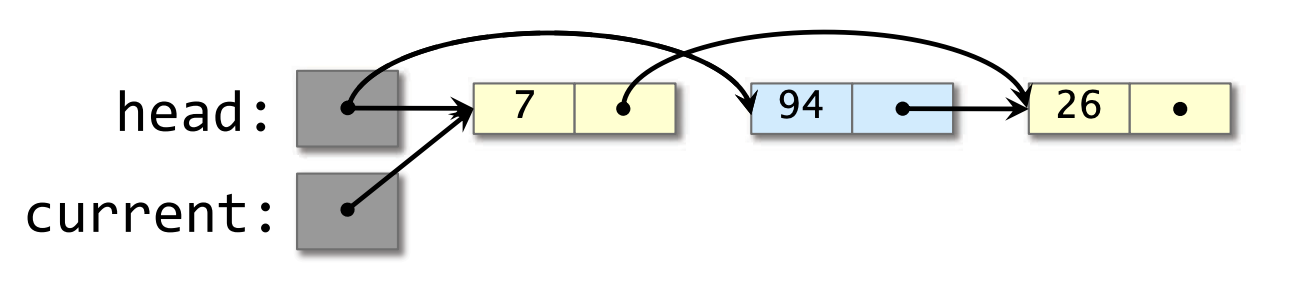
- 线程 1 恢复(resume),且它的CAS成功,移除 7,但将垃圾放回列表中。
解决方案
版本控制
将版本号与每个指针一起打包:在每个原子可更新的字中,包含一个版本号。
每次更改指针时递增版本号:每次对指针进行修改时,相应的版本号也要增加。
原子操作的比较和交换:将指针和版本号作为一个原子操作进行比较和交换。
问题
- 版本号可能需要非常大:随着指针频繁更改,版本号可能变得非常大,导致存储和管理上的挑战。
回收机制
- 防止在请求未完成时重用节点:确保在某个线程执行时,不允许节点(例如节点15)被重用为其他节点(如节点7)。
- 示例:例如,当线程1仍在执行时,防止节点15被其他线程重用为节点7,以确保数据的一致性和正确性。