Lec 16 不确定性并行编程
Leiserson, Charles. “A Simple Deterministic Algorithm for Guaranteeing the Forward Progress of Transactions.” Information Systems 57 (2016): 69–74.
不确定性并行编程非常恶心,相比并行编程而言(就是工作量和关键路径的把握)。不确定性就是因为多线程环境由于资源竞争,导致的数据争用,导致程序的不确定性。
总览
- 确定性程序概念
- 互斥&原子性
- 锁的实现
- 锁的异常:死锁
- 事务性内存(TD)
确定性程序概念
一个程序在给定输入下如果每个内存位置在每次执行中都以相同的顺序更新相同的值,那么我们说这个程序是确定性的。 关键点:
- 程序总是以相同的方式运行。
- 两个不同的内存位置可能以不同的顺序更新,但每个位置总是看到相同的更新序列。
但是实际非常难实现,因为你有多个处理器在并行计算。
确定性程序最大的好处是?
Debugging.
IMPORTANT
【定理】 并行编程金牌规则:永远不要写不确定性的并行程序
【定理】并行编程银牌规则:永远不要写不确定性的并行程序,但是如果你必须要这么做,建议给出管理这些不确定性的测试策略。
典型测试策略包括:
- 关闭不确定性
- 封装不确定性
- 用确定性方案替代
- 使用分析工具
即便是最牛的大师,也会写不确定性并行程序。是什么让他们铤而走险?
最大的原因: 性能
内存随机化:为了安全考虑,内存分配有时会使用随机化技术(例如地址空间布局随机化,ASLR),以防止某些类型的攻击(例如缓冲区溢出攻击)。通过随机化内存地址,使得攻击者难以预测内存布局,从而提高安全性
互斥&原子性
示例: 并发哈希表
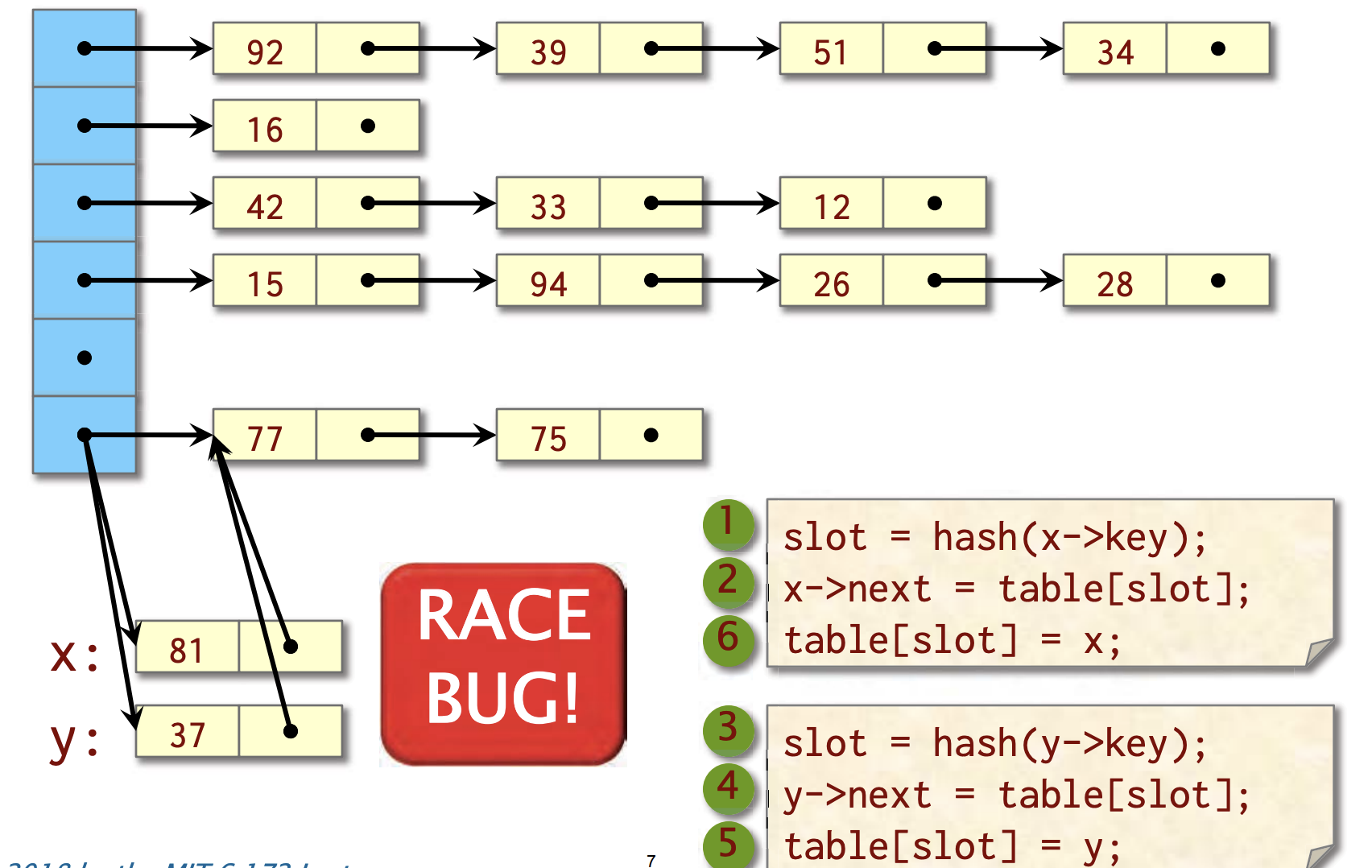
这里我们有两个线程,一个是插入x, 一个插入y,其中一个线程执行了x插入操作的前两个表达式后,另外一个线程也开始执行y的插入,假如顺序如图所示。 竞态条件BUG 出现了
原子操作
标准方法: 一个通用的策略是将一些指令看作是原子的。
NOTE
【定义】如果系统在任何时刻都无法将它们视为部分执行,则一系列指令是原子的。此时,要么该序列中的指令没有执行,要么所有指令都已执行
【定义】临界区是访问共享数据结构的一段代码,该数据结构必须不被两个或多个线程同时访问(互斥)
【定义】锁(mutex)是一个具有lock和unlock成员函数的对象。当一个线程试图锁定一个已经被锁定的互斥锁时,该线程会被阻塞(即等待),直到该锁被解锁。
上述的例子,修改后的代码
slot = hash(x->key);
lock(&table[slot].L);
x->next = table[slot].head; // 临界区
table[slot].head = x; // 临界区
unlock(&table[slot].L);IMPORTANT
用锁能实现原子性
数据竞态条件
NOTE
【定义】确定性竞态条件(determinacy race)发生在两个逻辑上并行的指令访问同一个内存位置,并且至少有一个指令执行写操作时
如果程序执行中没有确定性竞态条件,则给定相同输入,该程序是确定性的。无论程序如何调度和执行,在该输入上的行为总是相同的。
如果在一个表面上确定性的程序(例如,一个没有锁的程序)中存在确定性竞争,Cilksan保证能够发现这样的竞态条件
所以关闭不确定性就能够检测出潜在的问题。
NOTE
【定义】数据竞态条件(data race)发生在两个逻辑上并行的指令在没有共同持有的锁的情况下访问同一个内存位置,并且至少有一个指令执行写操作时
即使一个程序没有数据竞态,遵循原子性约束,它仍然可能表现为非确定性的。因为获取锁的操作可能会引发确定性竞态
警告:Cilksan是一个工具,用于检测Cilk程序中的确定性竞争。如果代码使用锁,Cilksan就无法保证检测到所有的竞争情况,因为锁的使用本身会引入不确定性
没有数据竞争不代表没有bug
示例,这里我们没有数据竞争,但是我们违反了原子性。
slot = hash(x->key);
lock(&table[slot].L);
x->next = table[slot].head;
unlock(&table[slot].L);
lock(&table[slot].L);
table[slot].head = x;
unlock(&table[slot].L);使用互斥锁(mutexes)并且没有数据竞态(data races)是一个积极的信号
良性竞争条件
定义一个数组,元素为0~9的整数, A: 4, 1, 0, 4, 3, 3, 4, 6, 1, 9, 1, 9, 6, 6, 6, 3, 4
for (int = 0; i < 10; i++) {
digit[i] = 0;
}
clik_for(int i = 0; i < N; i++) {
digits[A[i]] = 1; // 开始竞争
}digit: 1 1 0 1 1 1 0 0 1
这里我们可以看到虽然发生了数据竞争,但是我们最终都是想将A[6] = 1,我们并不需要关注这场竞争。
这段代码只在硬件以原子方式写入数组元素时才能正常工作 — 例如,在某些架构上会发生字节值的竞争,比如Intel架构, x86-64。 很恶心对吧
Cilksan 允许你关闭对有意的竞争的检测,这虽然危险但也是实用的。更好的解决方案存在,例如 Intel 的 Cilkscreen 中的虚假锁(fake locks)(请参阅 Intel Cilk Plus 工具用户指南)。
锁的实现
锁的性质
让步/自旋
Yielding(让步)的互斥锁在阻塞时将控制权交还给操作系统。
Spinning(自旋)的互斥锁在阻塞时会消耗处理器周期。
可重入/不可重入
Reentrant(可重入)的互斥锁允许一个已经持有锁的线程再次获取该锁。Nonreentrant(不可重入)的互斥锁如果线程试图再次获取已经持有的锁,会造成死锁。
公平/非公平
Fair(公平)的互斥锁将阻塞的线程放在先进先出(FIFO)队列中,解锁操作会释放等待时间最长的线程。
Unfair(非公平)的互斥锁允许任何一个被阻塞的线程下一个获取锁。
在并行编程里面,通用和用非公平的自旋锁,因为他们是最便宜的。
简单的自旋的互斥锁
Spin_Mutex:
cmp 0, mutex ;Check if mutex is free
je Get_Mutex;
pause ; x86 hack to unconfuse pipeline
jmp Spin_Mutex;
Get_Mutex:
mov 1, %eax
xchg mutex, %eax ; try to get mutex,xchg is an atomic exange
cmp 0, %eax ; Test if successful
jne Spin_Mutex
Critical_Section:
<critical-section code>
mov 0, mutex ; Relase mutex为什么我需要在Spin_Mutex和Get_Mutex之间需要一些代码?
如果没有,那我就只是检查下能不能获取,如果可以,当然很好;假如不行,不断的xchg mutex 会带来很大的性能问题,与CPU的缓存一致性有关,xchg是一个写操作, 他会invalidate这个缓存行,而cmp只是在shared 状态下进行读取
简单的让步互斥锁
一个更好的方法是不使用pause
Spin_Mutex:
cmp 0, mutex ;Check if mutex is free
je Get_Mutex;
call phtread_yield ; Yield quantum
jmp Spin_Mutex;
Get_Mutex:
mov 1, %eax
xchg mutex, %eax ; try to get mutex
cmp 0, %eax ; Test if successful
jne Spin_Mutex
Critical_Section:
<critical-section code>
mov 0, mutex ; Relase mutexyield 作用是将控制权返回给OS,当轮到你时,从恢复点返回
竞争型互斥锁
Competitive Mutex 竞争目标:
- 尽快在互斥锁释放后获取它。
- 行为良好,尽量少消耗处理器周期。
如何实现 ?
思路:自旋一段时间,然后让步。
自旋多久?
- 自旋的时间应该不超过一次上下文切换的时间(10ms)。这样,你永远不会等待的时间超过最优时间的两倍。
- 如果在自旋期间互斥锁被释放,是最优的情况。
- 如果在让步后互斥锁被释放,等待时间最多是最优时间的两倍。
- 这就是所谓的滑雪租赁的问题
缓存未命中(访问DRAM)需要多少? 磁盘访问呢?
150个cycle, 和5-10毫秒
随机化算法 [KMMO94]
- 一种聪明的随机化算法可以实现竞争比率 e/(e–1) ≈ 1.58。
锁的异常:死锁
持有超过一把锁时会很危险,我们看一下下面的例子
// 线程1
lock(&A);
lock(&B);
<critical section>;
lock(&B);
lock(&A);
// 线程2
lock(&B);
lock(&A);
<critical section>;
lock(&A);
lock(&B);死锁的条件
互斥 — 每个线程对其持有的资源进行独占控制。
不可抢占 — 每个线程在完成对所持有资源的使用之前,不会释放这些资源。
循环等待 — 存在一个线程循环,其中每个线程都阻塞在等待由下一个线程持有的资源。
示例: 哲学家问题
有n个哲学家, 每个人都需要用他的旁边的筷子来吃他碗里的面条
// 哲学家i
while(1) {
think();
lock(&chopstick[i].L);
lock(&choptick[(i+1)%n].L);
eat();
unlock(&chopstick[i].L);
unlock(&choptick[(i+1)%n].L);
}有一天他们同时拿起了左边的筷子,此时就完全卡住了。
阻止死锁
IMPORTANT
【定理】定理。假设我们可以对互斥锁进行线性排序$ L_1 ⋖ L_2 ⋖ ⋯ ⋖ L_n$, 以便每当一个线程持有互斥锁 $L_i $并尝试锁定另一个互斥锁 $L_j $时,满足
证明(反证法):假设存在一个等待循环。考虑在循环中持有排序中“最大”互斥锁
// 哲学家i
while (1) {
think();
lock(&chopstick[min(i, (i+1)%n)].L);
lock(&choptick[max(i, (i+1)%n)].L);
eat();
unlock(&chopstick[i].L);
unlock(&choptick[(i+1)%n].L);
}Cilk 死锁
考虑你想要Cilk使用锁,你需要知道的是,Cilk虽然使用了锁,但是它是被封装起来了, Cilk的运行时试将不确定性进行封装, 看不到他们。
示例
下面例子中,加锁的位置位于图中中括号,foo内部的锁在下面的中括号。容易分析出这里发生了死锁。
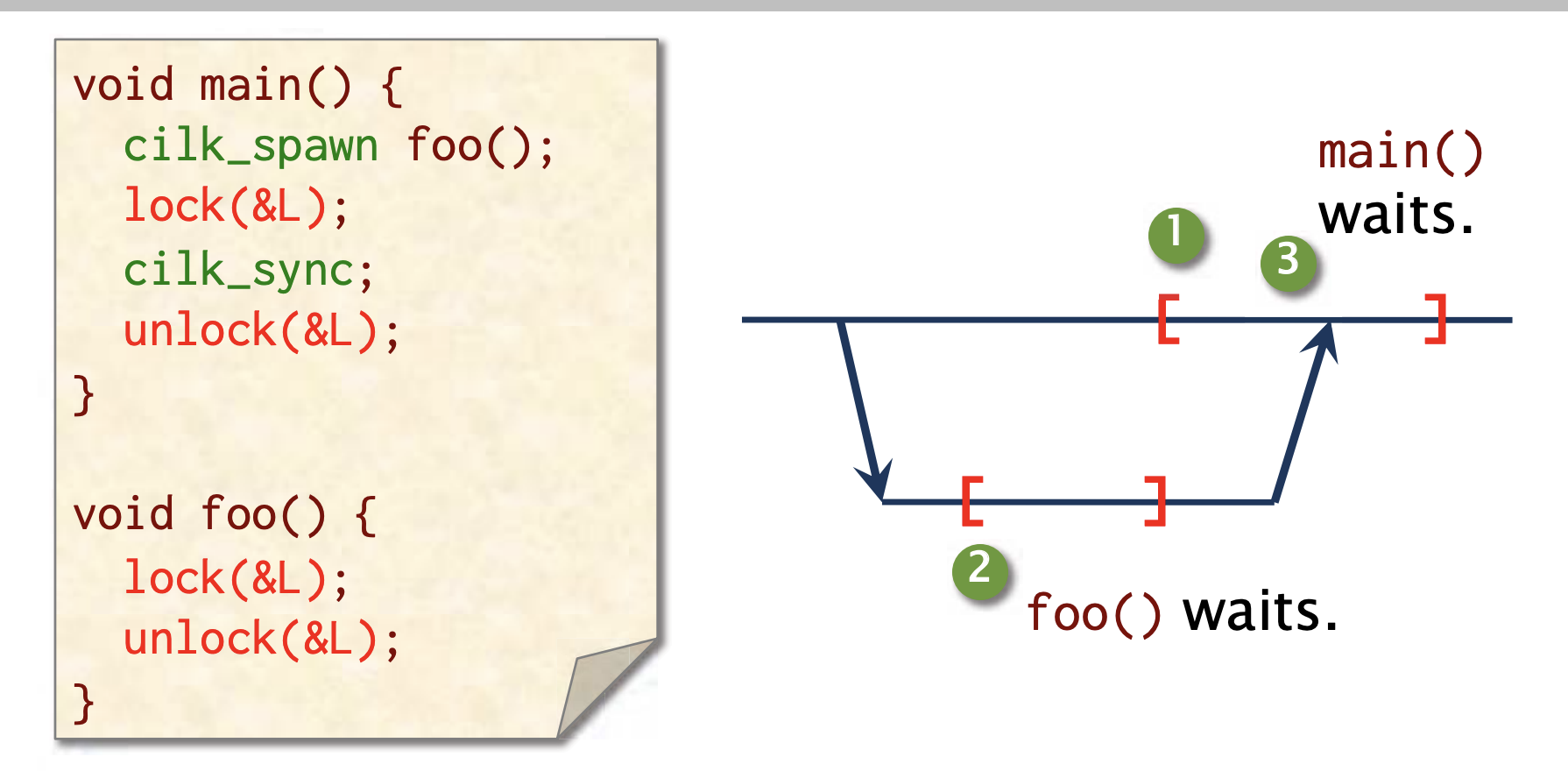
- 不要再cilk_sync期间持有互斥锁
- 仅在顺序指令链(strands)中持有互斥锁
事务性内存(TD)
事务性内存Transaction memory,这是借鉴数据库的思想,不需要锁,只是告诉OS,在我执行临界区时候不要来烦我。 : )
- 这是比较前沿的方法,工业界少有应用
事务提交:当一个事务成功完成并提交时,事务中的所有内存更新操作会以原子方式生效,给人的感觉是这些更新操作同时发生,保证数据一致性。
事务中止:如果事务在执行过程中遇到问题而中止,所有的内存更新操作都不会生效。这意味着事务的任何部分更改都不会被保留,系统状态将回到事务开始前的状态。事务需要重新启动以再次尝试完成任务。
重新开始的事务:当事务重新开始时,由于并发环境的变化或其他条件的不同,重新开始的事务可能会采取不同的执行路径。这可能会导致不同的操作序列,从而影响最终结果。
Gaussian_Eliminate(G, v) {
atomic {
S = neighbors[v];
for u ∊ S {
E(G) = E(G) – {(u, v)};
E(G) = E(G) – {(v, u)};
}
V(G) = V(G) – {v};
for u ∊ S
for u' ∊ S – {u}
E(G) = E(G) ! {(u, u')};
}
}NOTE
【定义】冲突(Conflict):在事务内存系统中,如果多个事务同时尝试访问同一个内存位置,就会产生冲突。这需要协调,以确保数据的一致性和系统的稳定性。
【定义】竞争解决(Contention resolution):当发生冲突时,系统必须决定如何处理竞争。例如,可以选择让其中一个事务等待,或者中止一个事务并重新开始。这个决策过程通常依赖于特定的条件和策略,以最小化系统性能的影响。
【定义】前进进展(Forward progress):确保系统能够持续向前推进,而不会陷入死锁(事务相互等待,无法继续)、活锁(事务不断进行但没有实际进展)或饥饿(某些事务始终无法获得资源)的状态。这对于维持系统的稳定性和效率至关重要。
【定义】吞吐量(Throughout):最大化系统同时运行的事务数量,以提高整体性能和资源利用率。通过优化并发事务的处理,可以提升系统的吞吐量。
实现:算法L
假设Transactional-Memory系统提供以下机制:
- 记录读写操作,
- 中止并回滚事务,
- 重新启动事务。
算法 L 采用基于锁的方法,结合了两个概念:
- 有限所有权数组 [HF03]
- 释放-排序-重新获取 [L95, RFF06]