Lec 8 竞态和并行
He, Yuxiong, Charles Leiserson, and William Leiserson. “The Cilkview Scalability Analyzer.” Proceedings of the Twenty-Second Annual ACM Symposium on Parallelism in Algorithms and Architectures (2010): 145–156.
总览
- 确定性竞态条件
- 什么是并行?
- 扩展性分析:Cilkscale
- 调度理论
- Cilk运行时系统
确定性竞态条件
NOTE
【定义】确定性竞态条件(determinacy race) 发生在当两个并行逻辑指令访问同一个内存位置,并且至少有一个指令是写操作。
示例
int x = 0;
cilk_for (int i = 0; i < 2; i++) {
x++;
}
assert(x == 2);我们来看错误情况下的依赖图
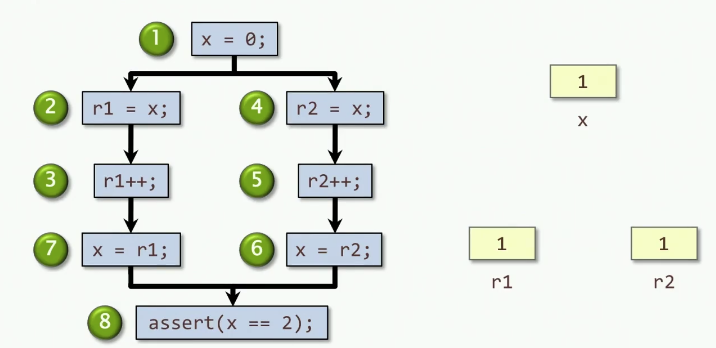
Cilk编码如何避免竞态?
首先什么情况下会发生?就是写后写,读后写,或者写后读。如果这两段代码都是独立的,那么它们之间就不会有的竞态条件。
- cilk_for的每个迭代都应该是独立的
- 在cilk_spawn子函数和对应的cilk_sync之间调用者代码段,应该是相互独立; 另外,对于spawn子函数的参数,应该在在spawn发生之前,父函数中事先生成出来。
- 机器字大小有影响,这取决于编译器的优化等级。
- 示例:
struct { char a; char b; } x同时更新x.a和x.b可能有竞态,
- 示例:
Cilksan 竞态条件检测
- 使用
-fsanitize=cilk编译器选项,会插入检测代码 - 对于给定输入,检测与对应串行代码行为差异,Cilksan可以报告并定位导致问题的数据竞争
- Cilksan 使用回归测试方法(regression-test)方法,这种方法确保在程序的演进过程中,新的更改没有引入新的数据竞争问题
- Cilksan 报告数据竞争,并为此提供详细信息,包括文件名、行数以及与竞争相关的变量。此外,它还提供堆栈跟踪信息
- 要确保 Cilksan 能够检测到所有潜在的问题,程序员需要确保所有的程序文件都被插入了 Cilksan 的检测代码
示例: 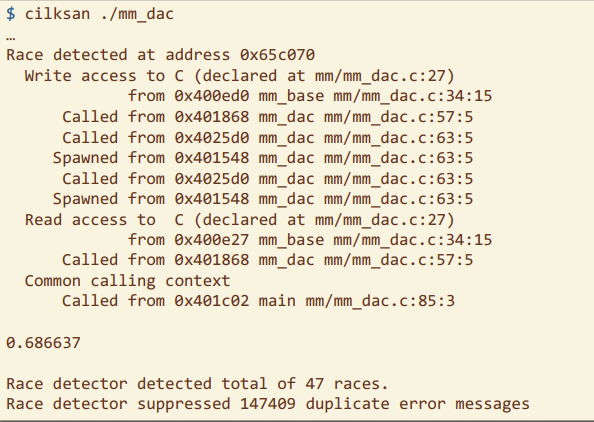
什么是并行?
执行模型
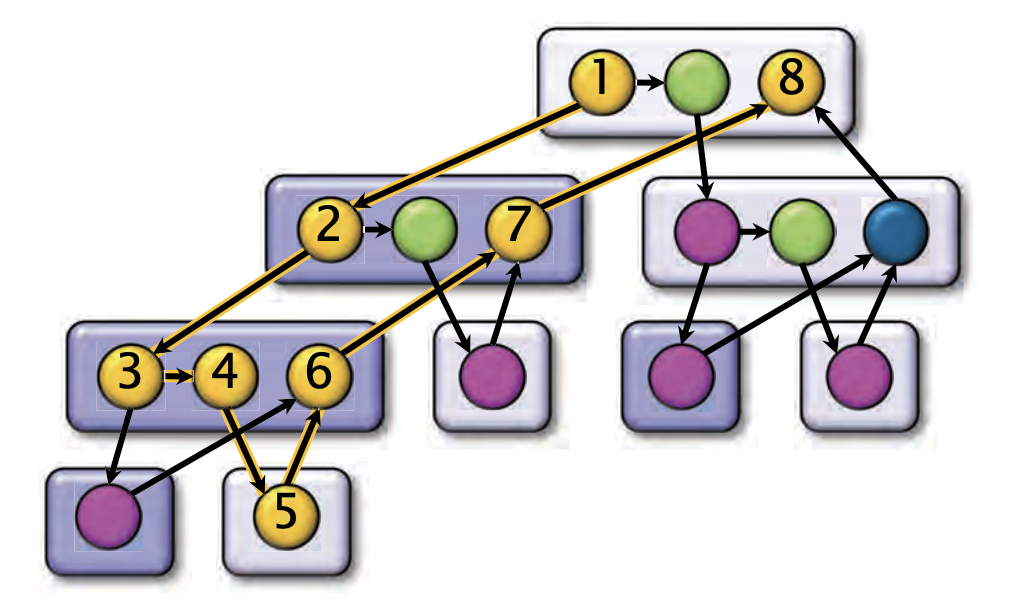
我们先看执行模型的有向图,节点颜色与代码上颜色对应,自上而下箭头是调用边,表示调用关系,自下而上的是返回边,表函数返回关系。这里的有向图是仅考虑单核处理器的情况,多核处理器无需按照这种深度优先顺序执行。
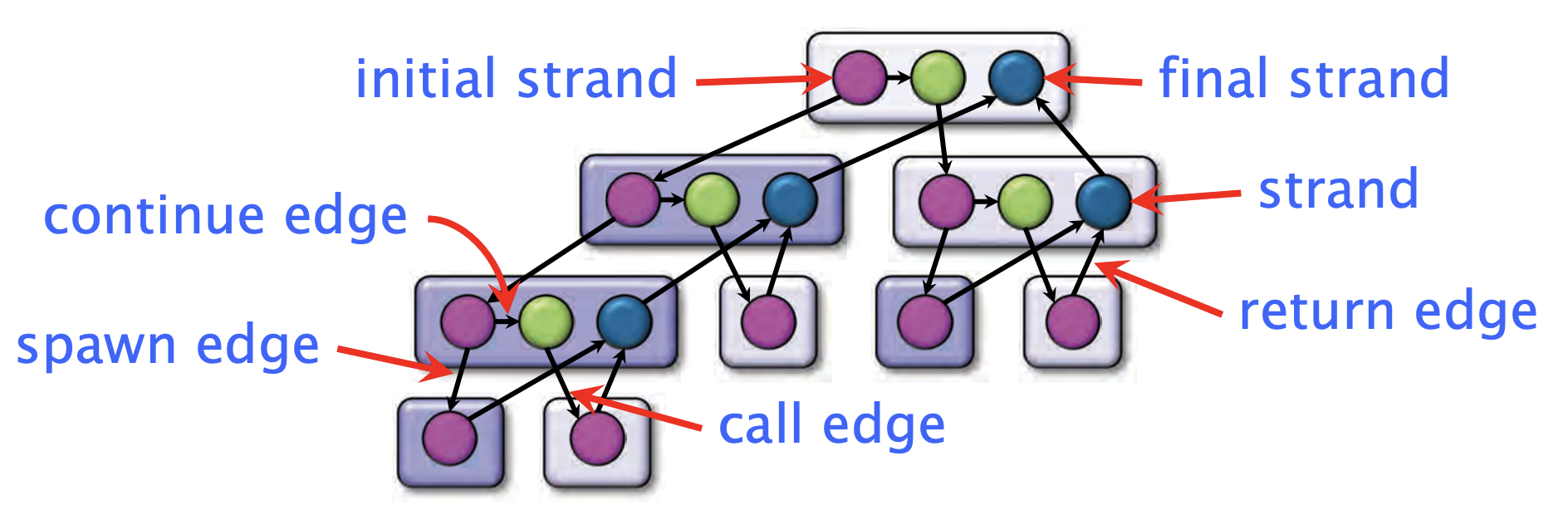
- 并行指令流是一个有向无环图
- 每个顶点都是一组顺序指令组(strand),指的是不包含并发操作(例如
spawn、sync或return语句)的指令序列 - 任何边都是spawn、call、return或者是contine边
- 循环并行(cilk_for)通过递归的分治,被转变为spawn和sync的组合
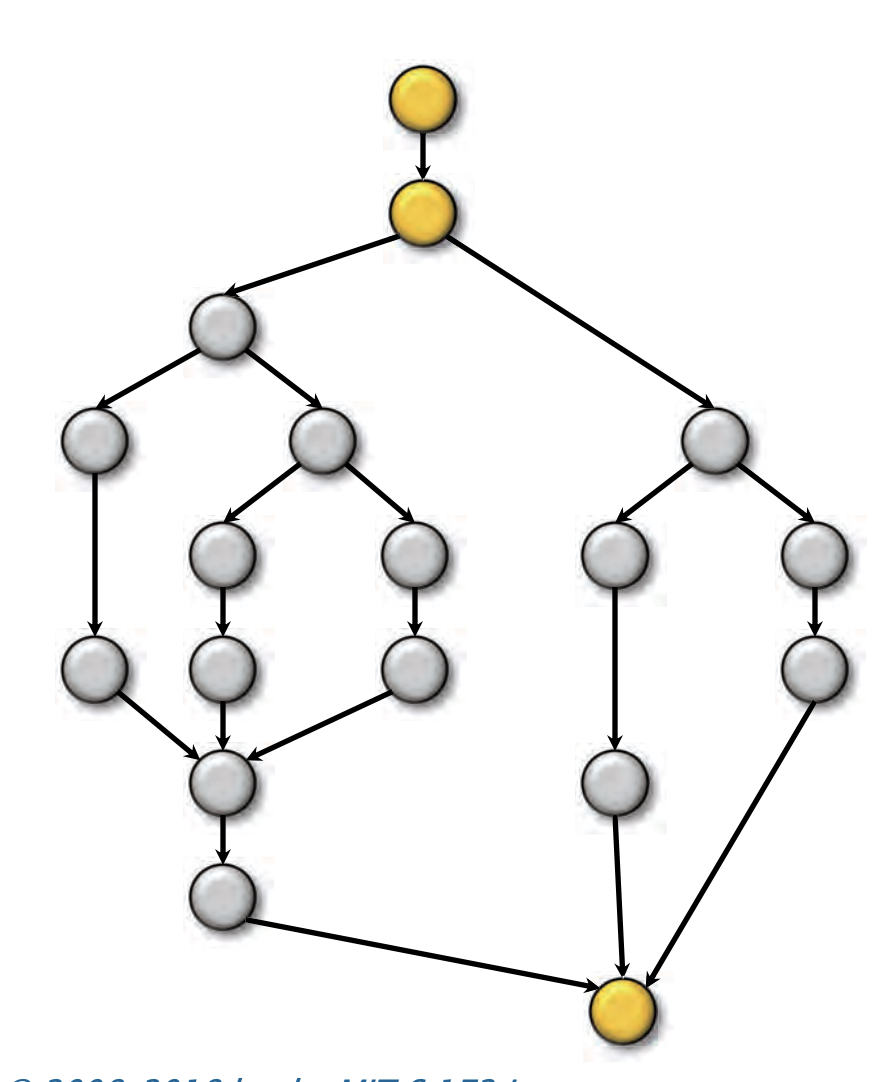
下图是一个展开的计算DAG图
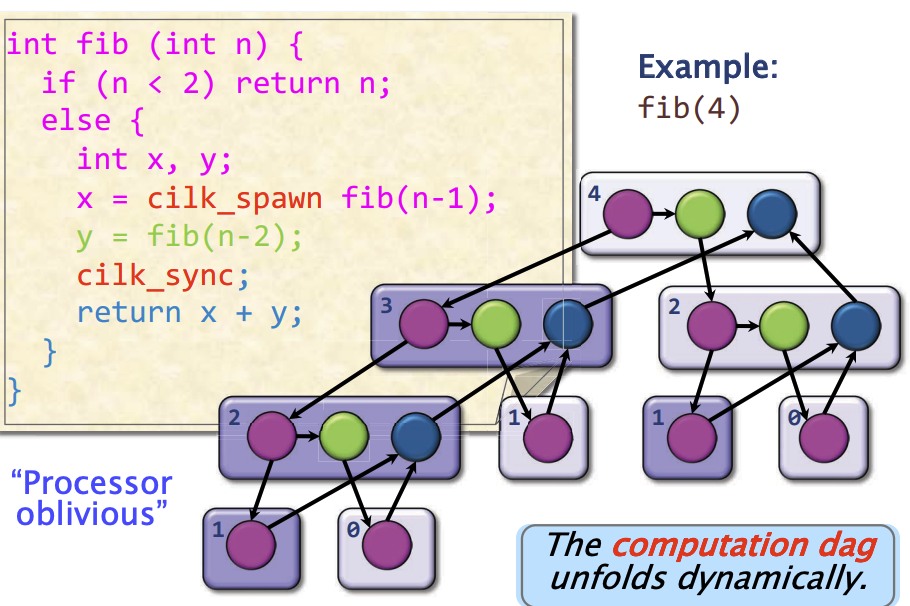
假如每组顺序指令执行时间为单位时间,那么这个程序并行潜力有多大?或者说能提升多大的性能?
这就引出了阿姆达尔法则(Amdahl's Law)
阿姆达尔法则
NOTE
【定义】阿姆达尔法则,它是一种经验法则,如果你的应用有50%是可并行的,另外50%是需要顺序执行的,那么不管你有多少处理器去执行,执行速度的加快将不会超过两倍的。
更通用地,如果应用中有占比为a的顺序执行部分,那么加速比(speedup)不超过1/a。
下面我们将量化并行度。
根据Amdahl's Law,由于顺序执行占比 $3 / 18 = 1 / 6 $,所以加速比的上界是6。
$T_p = \text{exec time on P processes} $
- 工作量法则: $T_p \ge T_1 / P $
- 跨度法则(Span,原意是,跨度,延伸,这里指程序的最长依赖路径):
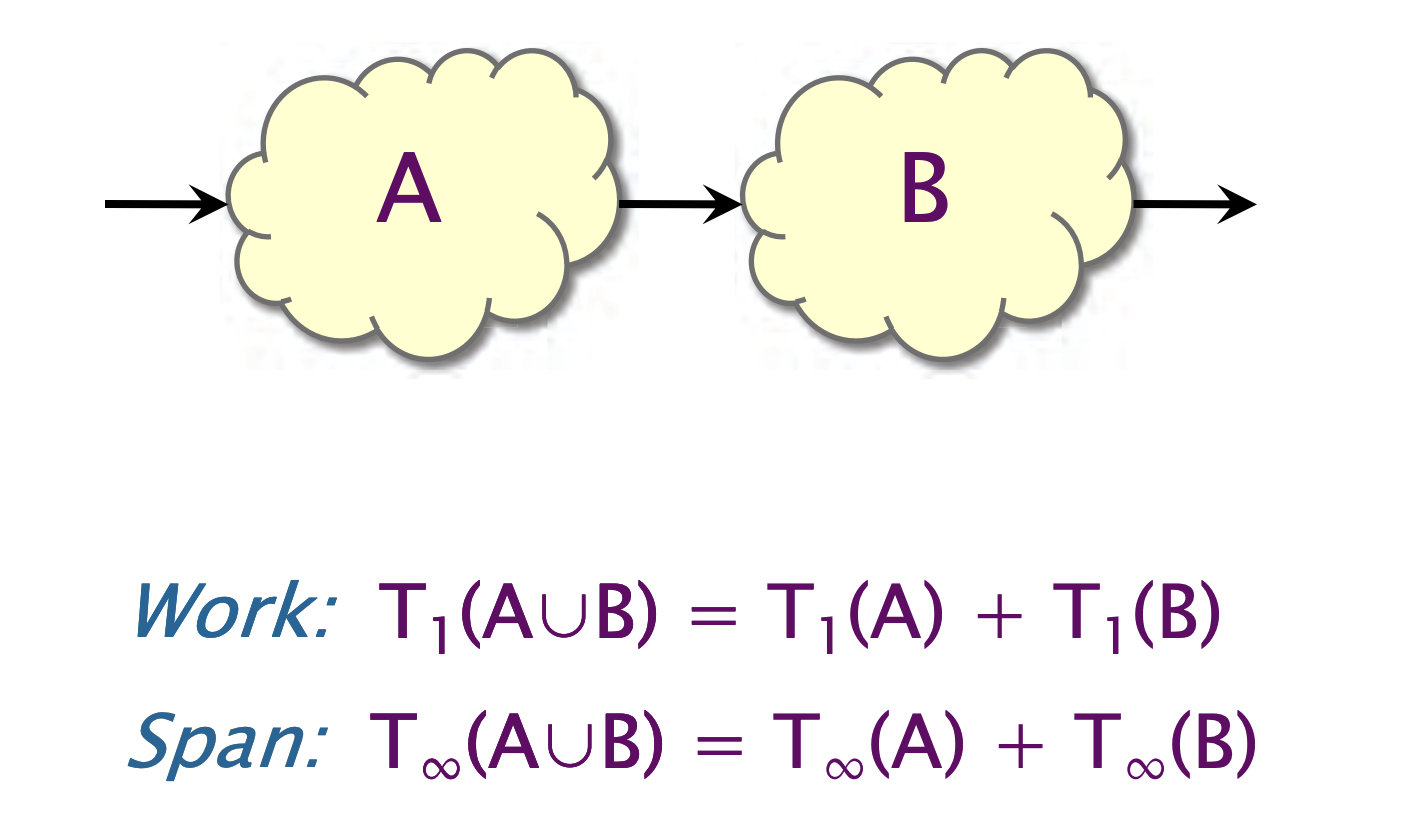
对于线性组合,我们有,
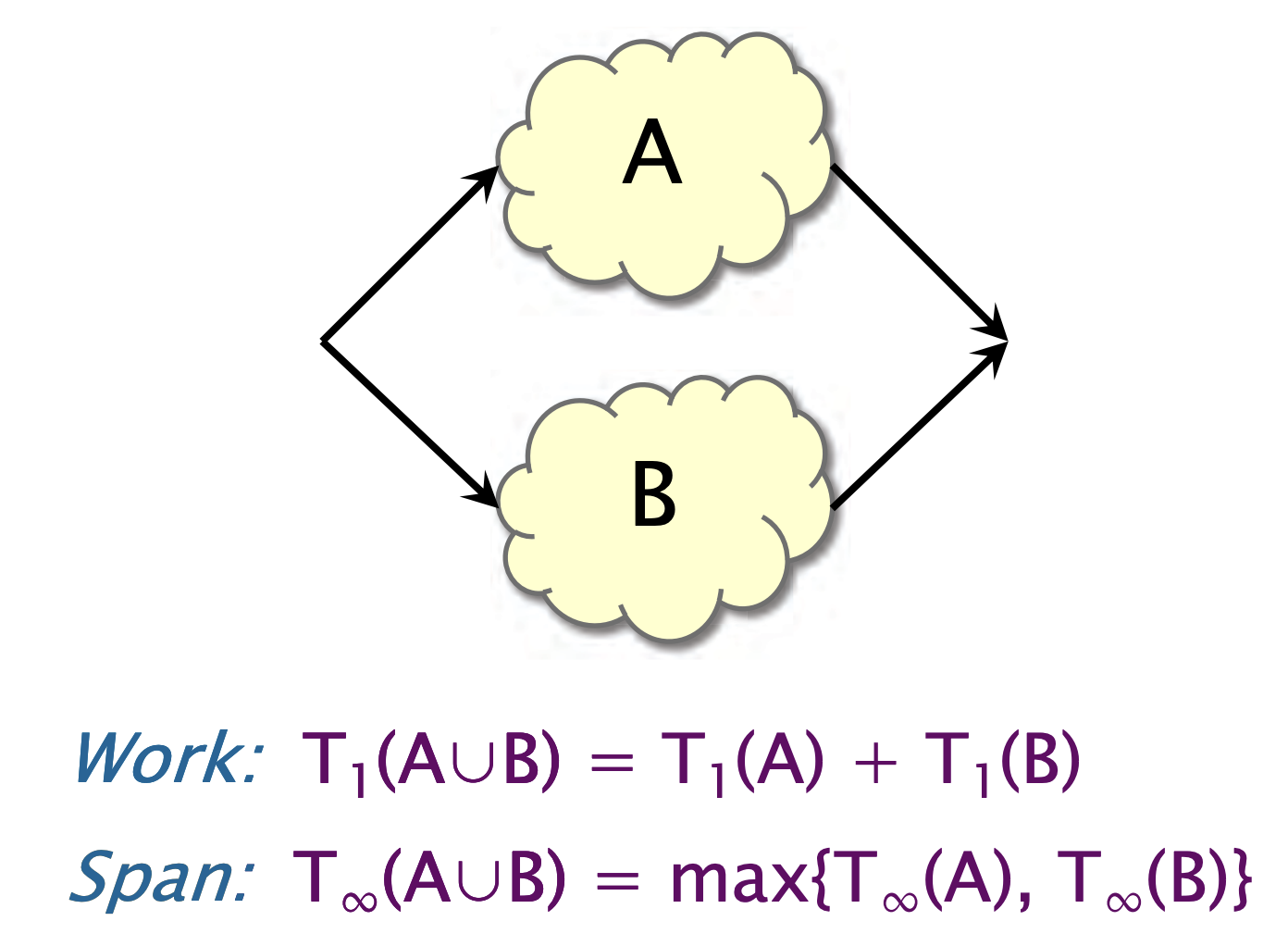
对于并行组合,我们有,
加速比Speedup
NOTE
【定义】加速比(speedup):
如果
如果
如果
并行度Parallelism
NOTE
【定义】并行度(parallelism)
并行度表示计算任务中的并行潜力,数值越大,意味着任务有更多的并行机会。
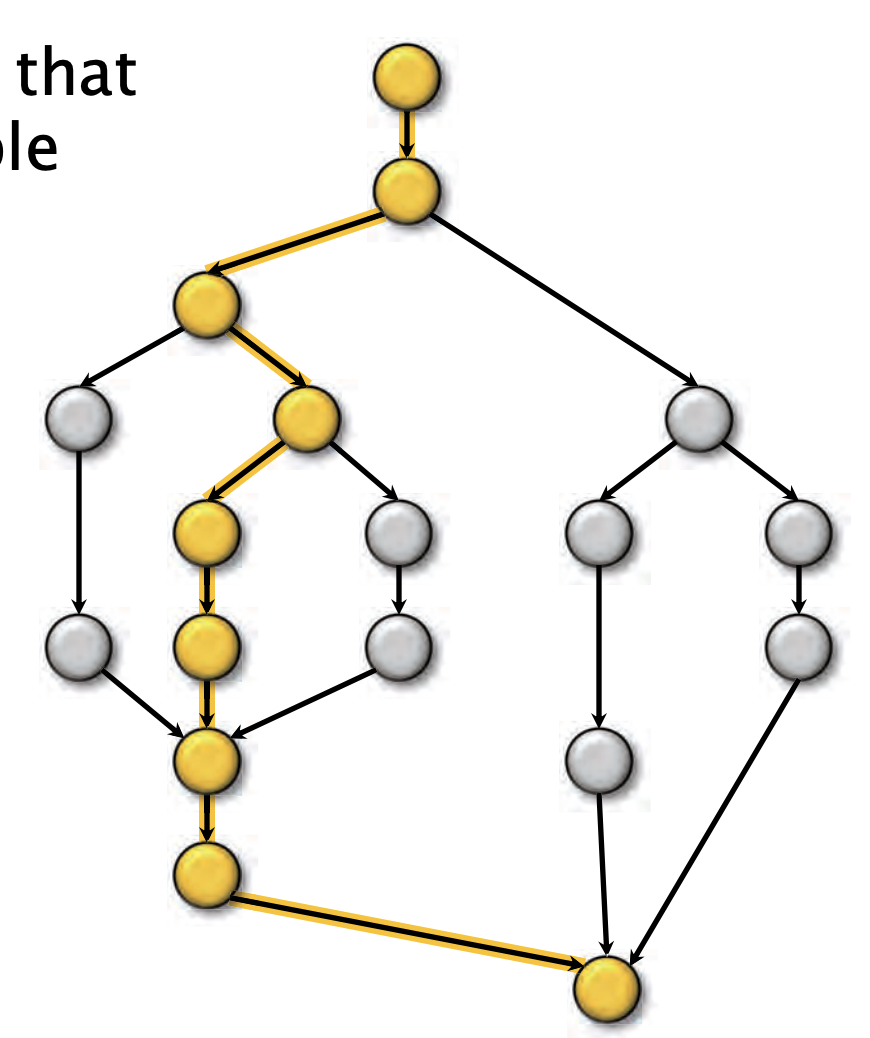
现在我们可以回答示例Fib(4)中的问题了
假如每组顺序指令执行时间为单位时间,那么这个程序并行潜力有多大?或者说能提升多大的性能?
工作量:
关键路径:
并行度: $T_1 / T_{\infty} =2.125 $
这意味着当你使用超过 2 个处理器时,性能提升会变得非常有限
扩展性分析:Clikscale
如果遇到工程量大的情况,可能不太容易画出上图,所以提供了这样的一个工具来辅助你估计并行度。
- Tapir/LLVM 编译器提供了一个名为 Cilkscale 的可扩展性分析器
- 和 Cilksan 数据竞争检测器类似,Cilkscale 使用编译器插装技术来分析程序的串行执行
- Cilkscale 通过计算 工作量 (work) 和 关键路径 (span),推导出并行性能的上限
示例: 快排分析
static void quicksort(int64_t *left, int64_t *right) {
int 64_t *p;
if (left == right) return;
p = partition(left, right);
cilk_spawn quicksort(left, p);
quicksort(p+1, right);
cilk_sync;
}接下来我们将用100万的数字进行排序
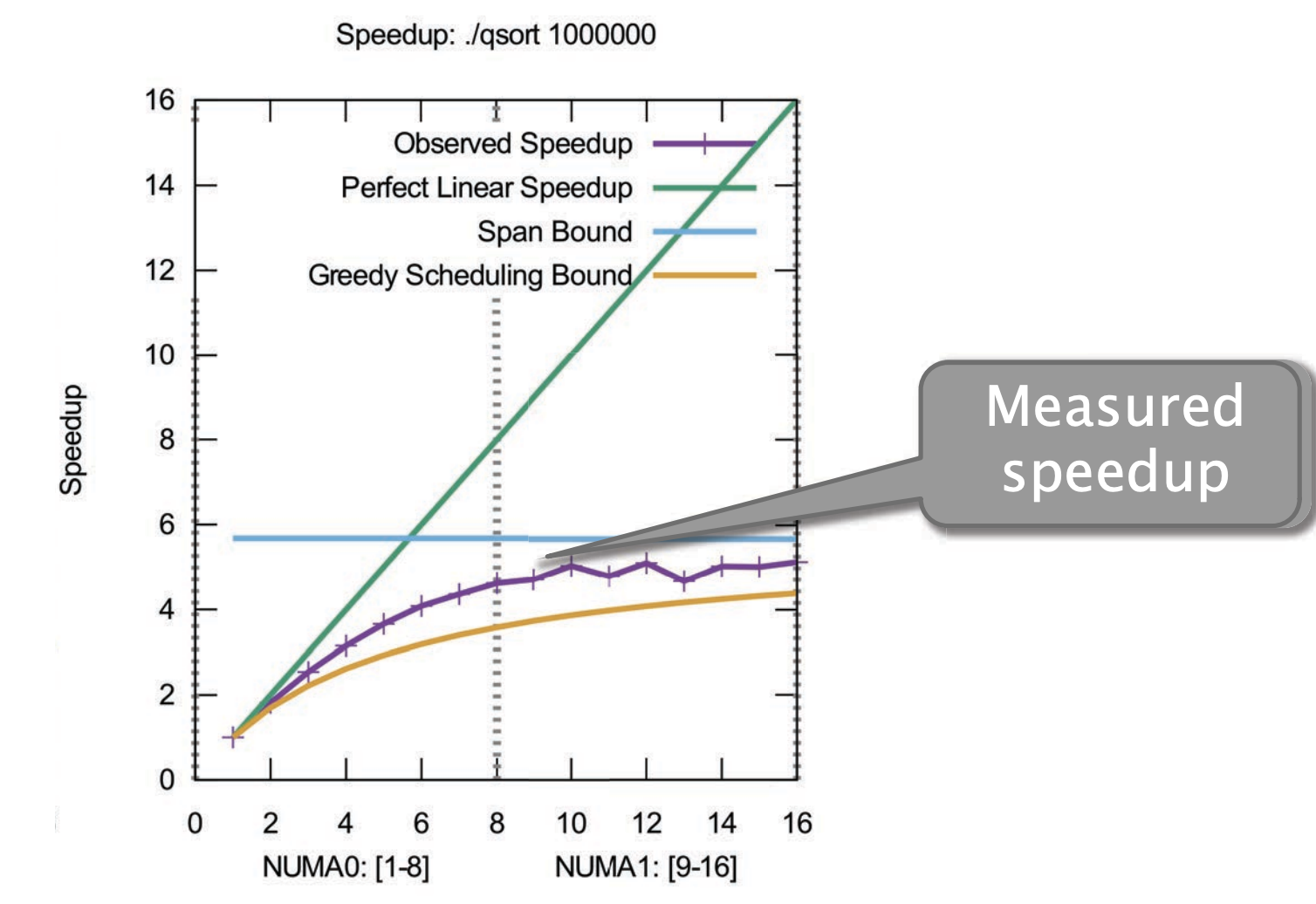
- 蓝色线的是Span Law的限制
- 绿色线的是Work Low限制
用另外一个视角表达就是
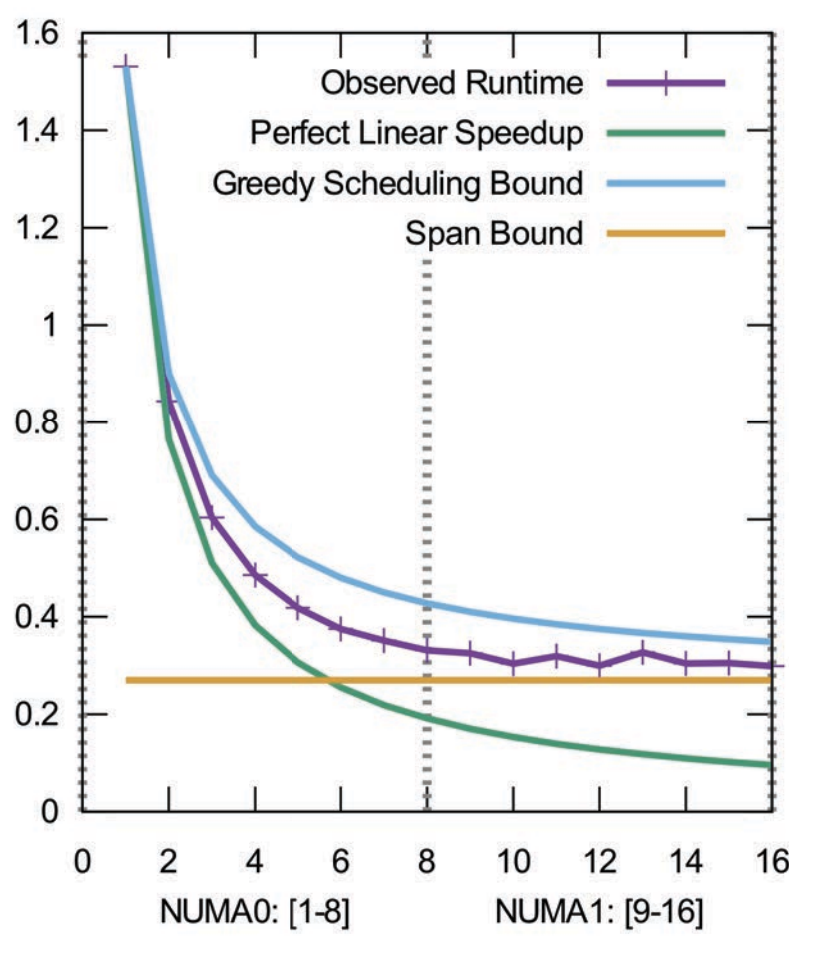
分析:
- 预期的 work =
- 预期 span =
: 因为要处理每个数据项
得出 并行度为
其他算法
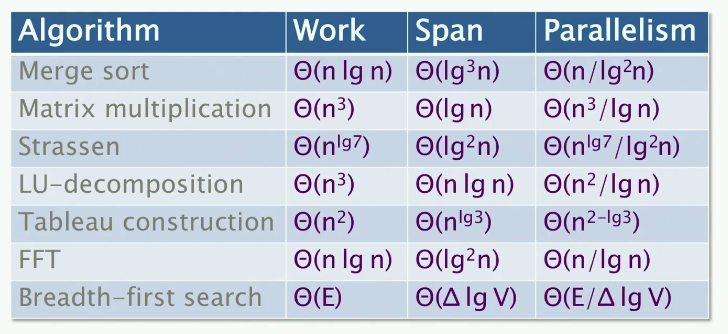
这里的贪心调度界限是什么?
引出下一节内容
调度理论
我们还没有讲这些strand(我理解为工作单元)映射到处理器的。 这里的调度理论不仅限于这个主题,这是一个通用的概念。
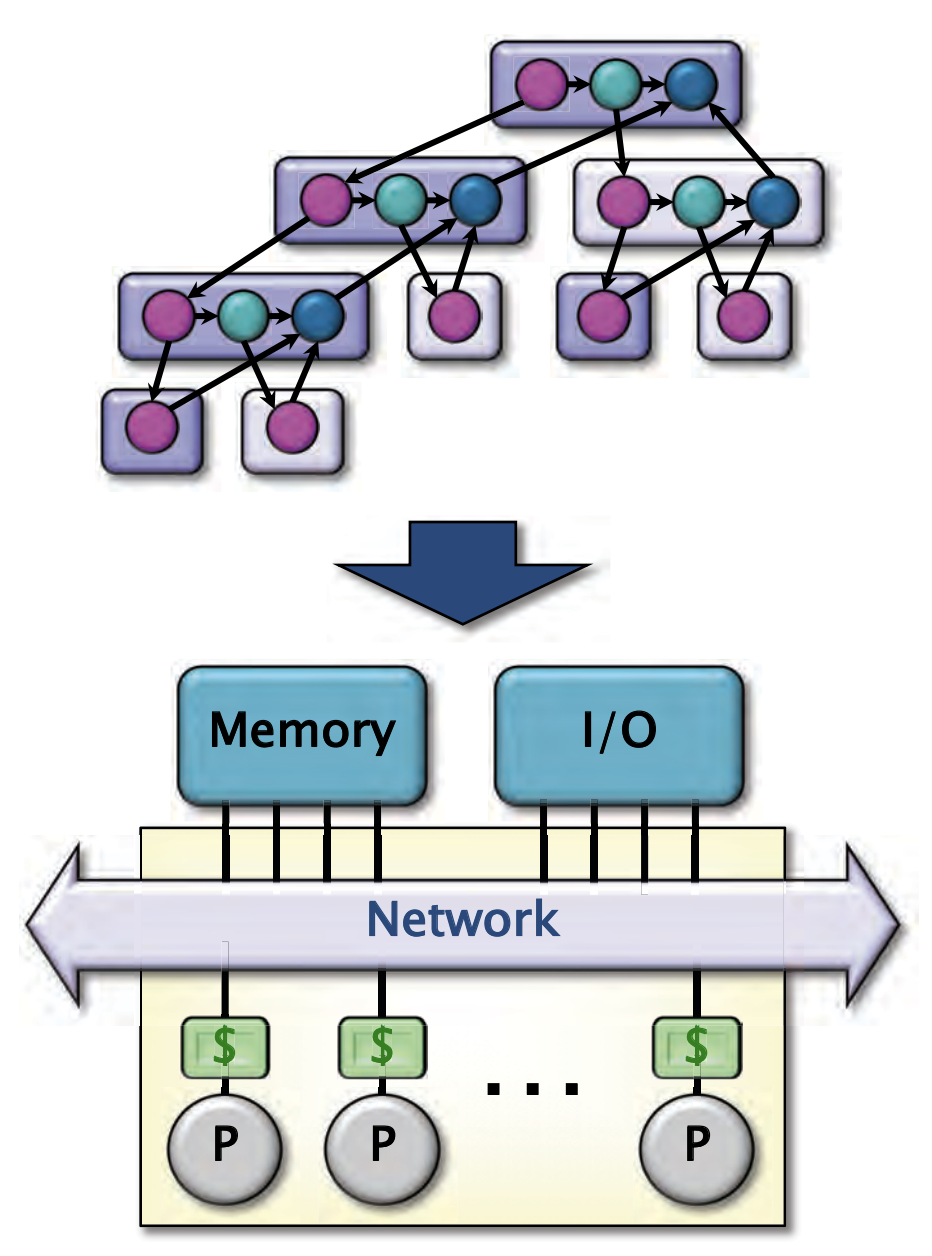
- Cilk 允许程序员在应用程序中表达潜在的并行度
- Cilk 的调度器在运行时动态地将指令序列(strands)映射到处理器上
- 由于分布式调度器的理论较为复杂,我们将通过集中式调度器来探索这些概念
贪心调度
Greedy Schedule 想法: 每一步尽可能多做
NOTE
【定义】贪心调度,如果一个指令序列(strand)的所有前置指令都已执行完毕,则该指令序列是就绪的。
- 完整步骤
- 如果有不小于 P 个就绪的指令序列,可以同时运行任意 P 个指令序列。
- 不完整步骤
- 如果就绪的指令序列少于 P 个,则运行所有就绪的指令序列
IMPORTANT
【定理1】任何贪心调度都能实现
证明:
- 完整步骤:在完整步骤中,能够并行执行 P 单位工作,因此每个完整步骤的时间为
。 - 不完整步骤:在不完整步骤中,每执行一个步骤就会减少有向无环图(DAG)中未执行部分的关键路径长度
的 1 单位,因此总时间包括了这些不完整步骤的影响。
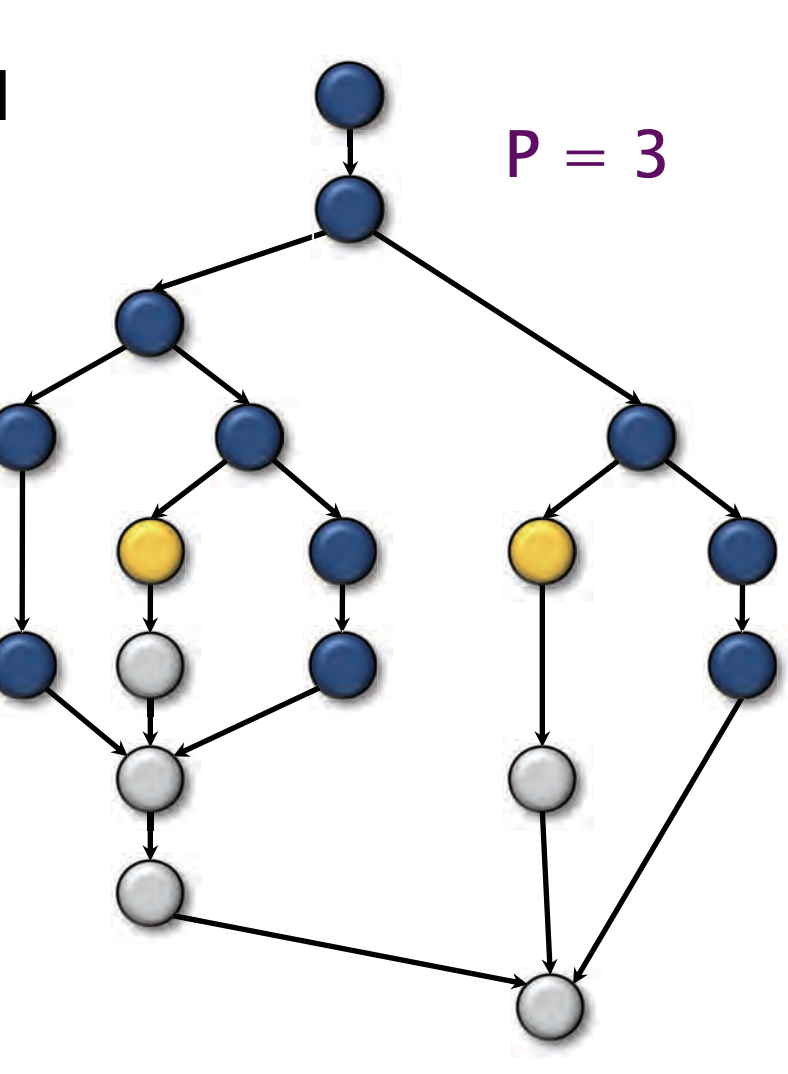
优化后贪心调度
IMPORTANT
【推论】任何贪心调度都能在最优调度的2倍范围内实现
证明: 设
IMPORTANT
【推论】任何贪心调度在 $T_1 / T_{\infty} \gg P $ 时都能实现接近完美的线性加速
证明: $T_p \le T_1 / P + T_{\infty} \approx T_1 / P $
因此加速比为 P
NOTE
【定义】并行宽松度(Parallel Slackness)我们把
根据经验,一般并行宽松度超过10,才需要使用Cilk编程,否则没太大必要。
Clik性能
Cilk 的工作窃取调度器在期望时间上达成$T_P = \frac{T_1}{P} + O(T_{\infty})
T_P \approx \frac{T_1}{P} + T_{\infty}$ - 伪证明:伪证明:一个处理器要么在工作,要么在窃取。所有处理器的工作总时间是
。每次窃取都有$ \frac{1}{P} O(PT_{\infty}) \frac{T_1 + O(PT_{\infty})}{P} = \frac{T_1}{P} + O(T_{\infty})\$。
- 伪证明:伪证明:一个处理器要么在工作,要么在窃取。所有处理器的工作总时间是
当$P \ll \frac{T_1}{T_{\infty}} $时,能够实现近乎完美的线性加速。
Cilkscale 中的工具可以测量$ T_1
T_{\infty}$。
Cilk运行时系统
每个工作者(处理器)维护一个包含就绪线程的工作双端队列,并像操作栈一样操作队列的底部。
当一个工作者发生call / spawn 时,将函数的栈帧从底部入队
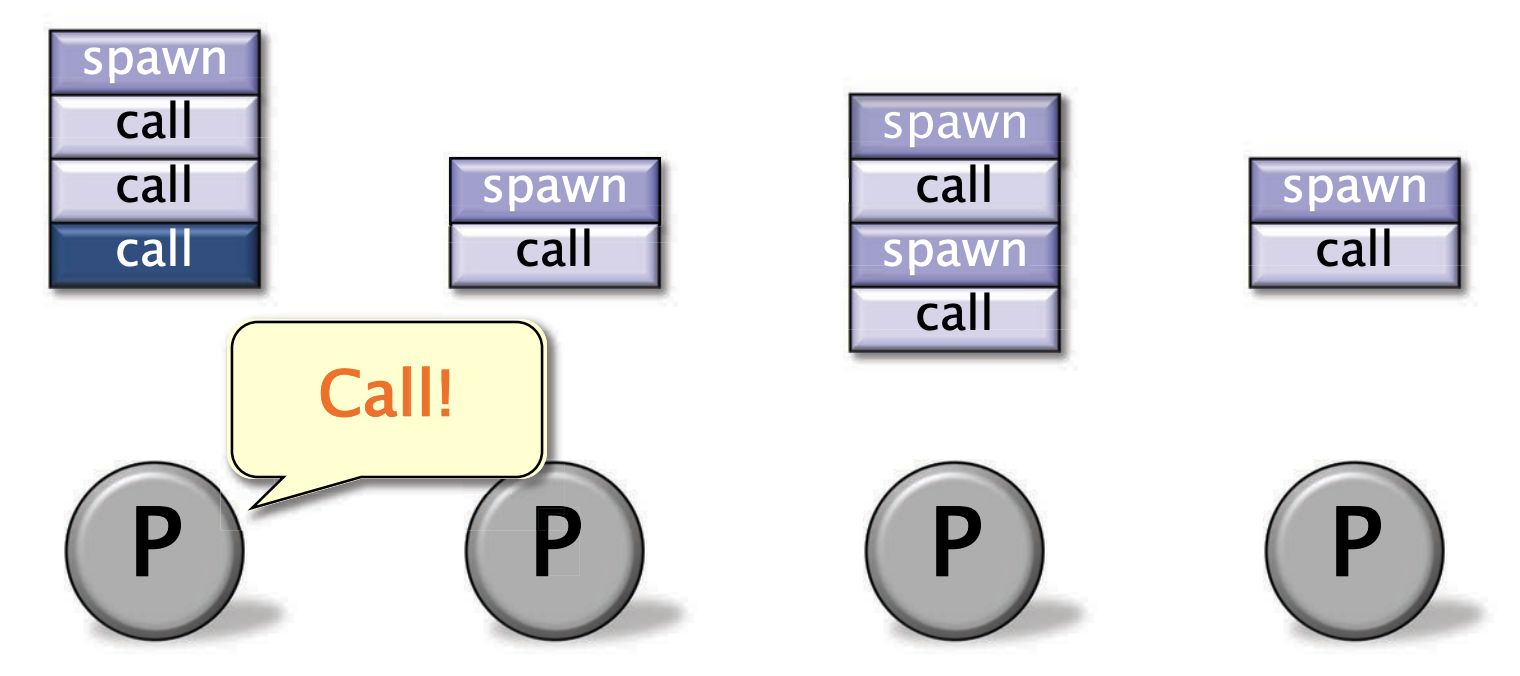
它们是可以并行执行
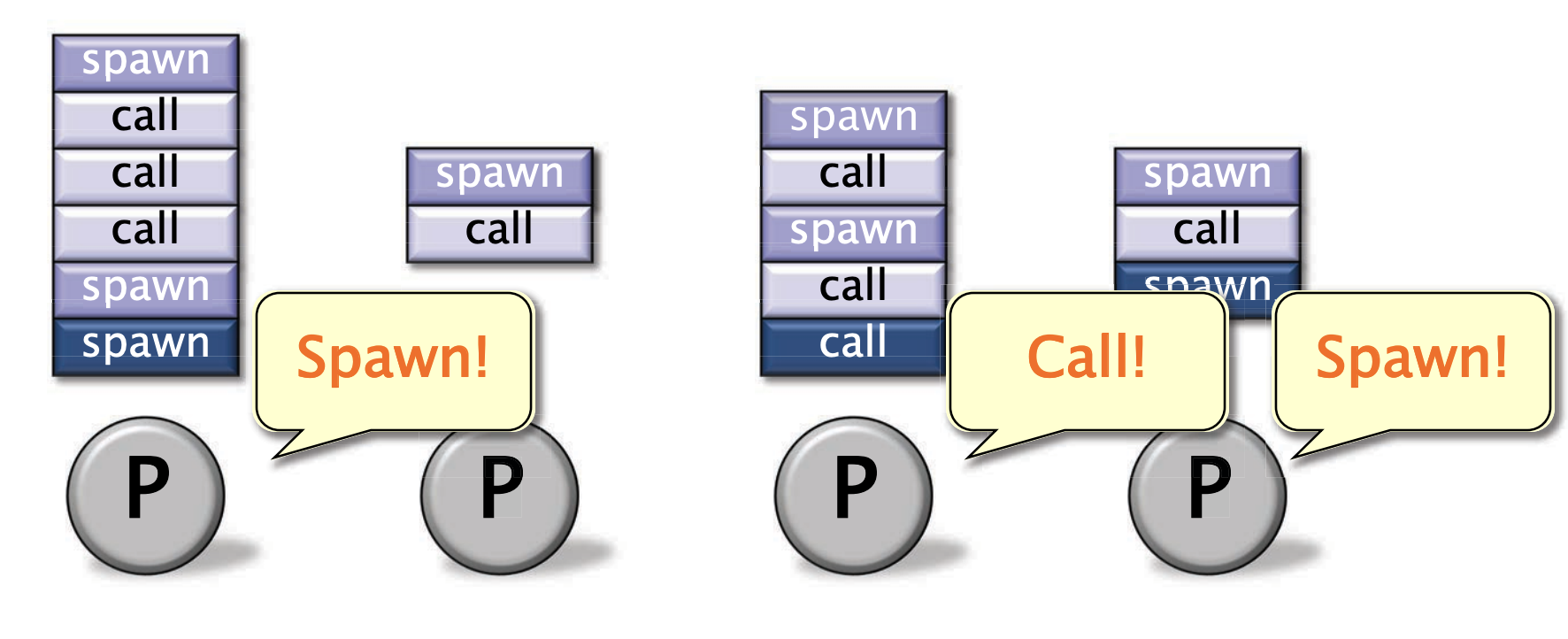
当一个工作者从call / spawn 中return了,直接将其从底部dequeue出去
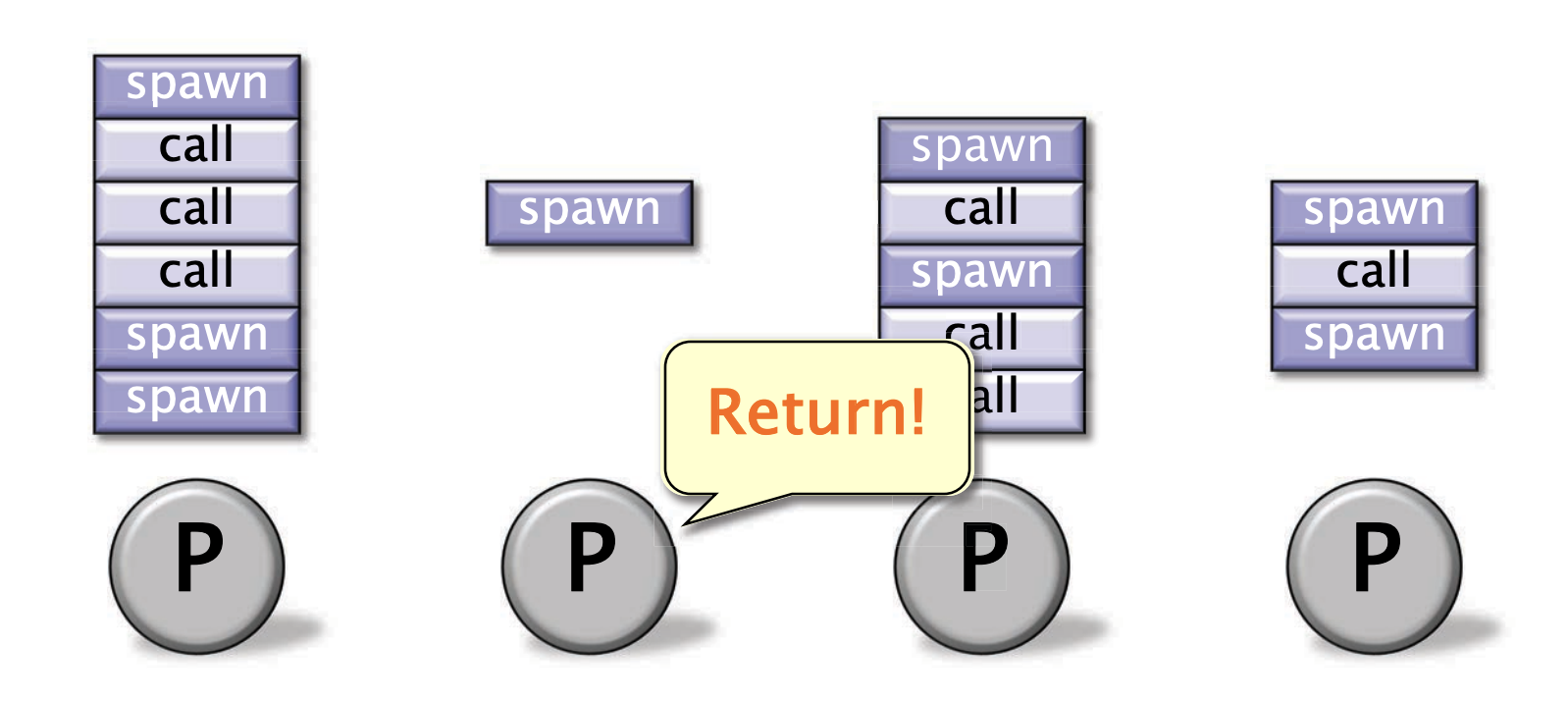
当有个工作者没有工作了,他就会随机挑个受害者的deque的顶部中“偷工作”
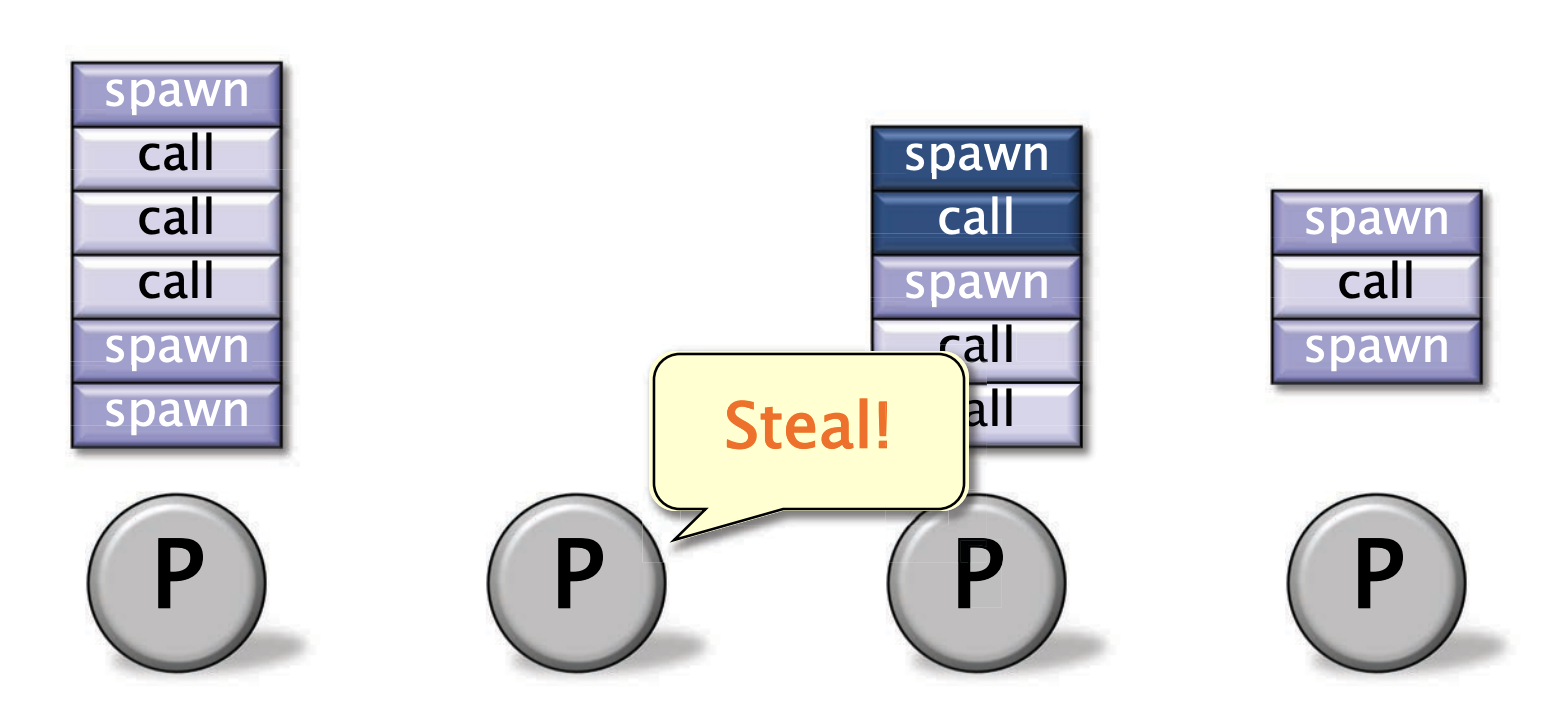
偷完工作后,也可以自己spawn / call 生成更多的工作
IMPORTANT
【著名的定理】如果并行程度足够高,那么worker偷工作的情况会很少发生,越少则越趋近于线性加速