Lec 13 Cilk运行时系统
大纲
Cilk回顾
功能分析
性能分析
双端工作队列的实现
Spawning 计算
Stealing 计算
synchronizing 计算
Cilk回顾
Cilk编程
// 顺序执行矩阵乘法, 运行时间T_S
for (int i = 0; i < n; i++) {
for (int k =0; k < n; k++) {
for (int j = 0; j < n; j++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
// Cilk 矩阵惩罚, 在P个处理器的运行时间T_P
cilk_for(int = 0; i < n; i++)
for (int k = 0; k < n; k++)
for (int j = 0; j < n; j++)
C[i][j] += A[i][k] * B[k][j];Cilk 调度
- Cilk并发平台允许程序员表达逻辑并行
- Cilk调度器在运行时动态地将执行程序映射到各个处理器核
- Cilk的work-stealing(随机工作偷窃)调度算法可证明是高效的
int64_t fib(int64_t n) {
if (n < 2) {
return n;
} else {
int64_t x, y;
x = cilk_spawn fib(n-1);
y = fib(n-2);
cilk_sync;
return (x + y);
}
}Cilk 平台
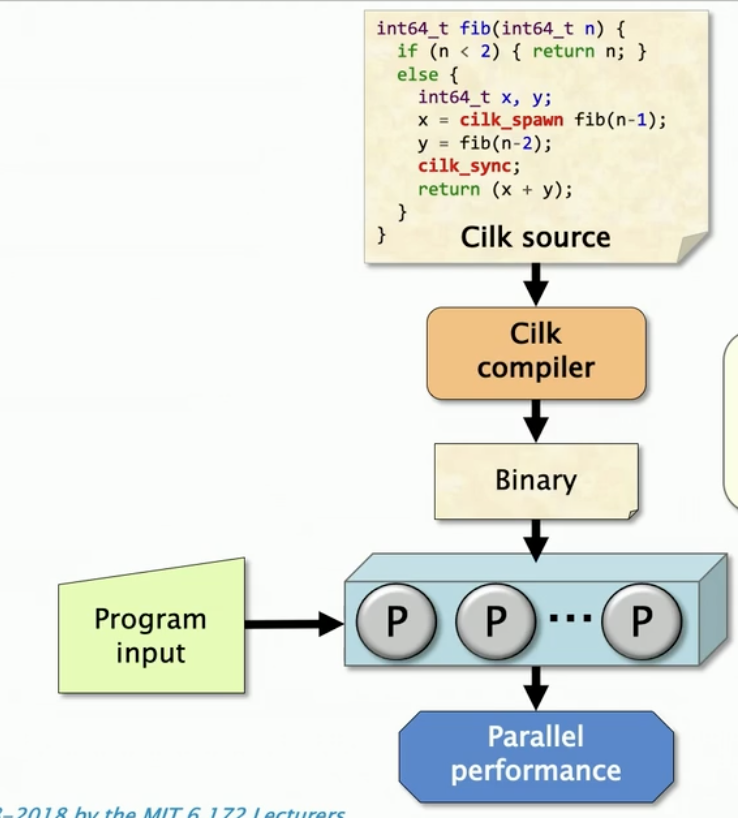
编译器和运行时库(libcilkrts.so)一起实现了Cilk运行时系统
编译器生成了什么?
后面我们将自顶向下学习Cilk运行时系统
功能分析
探讨下面这个例子
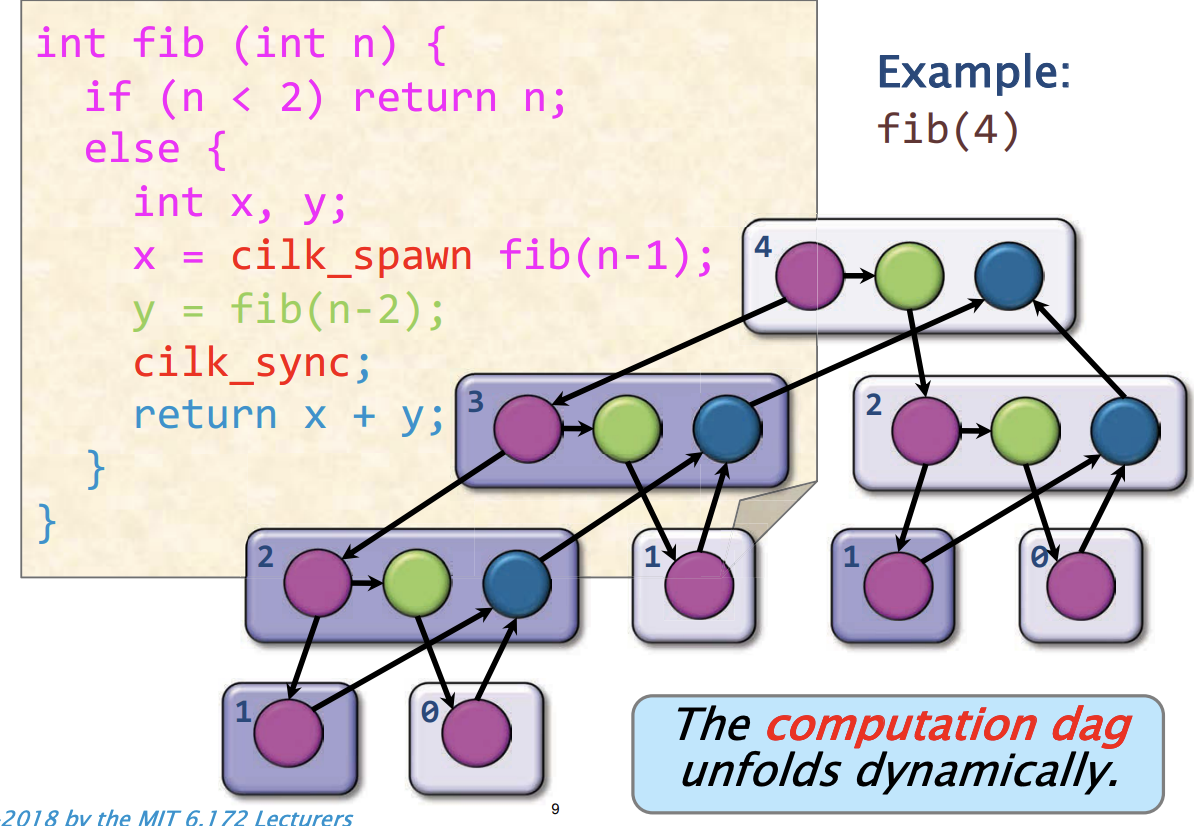
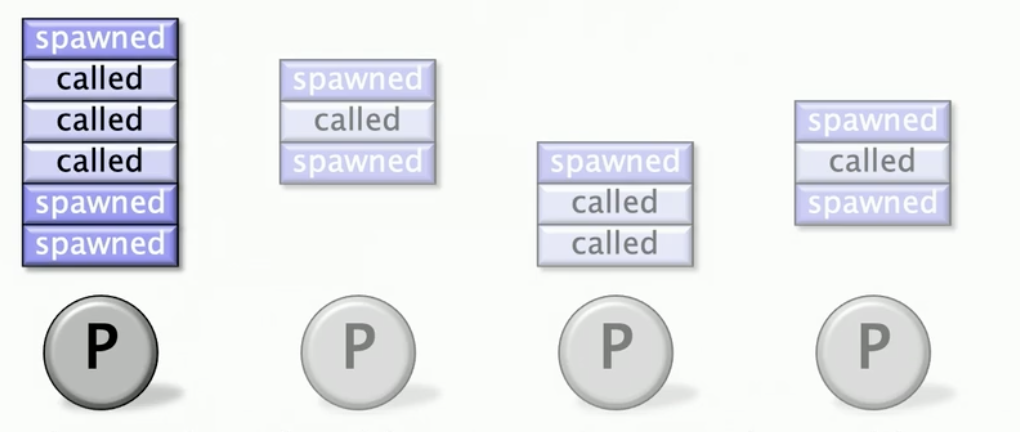
该程序的执行可以看作一种计算有向图模型, 随着程序的运行,计算有向图动态地展开。
顺序执行(单处理器)
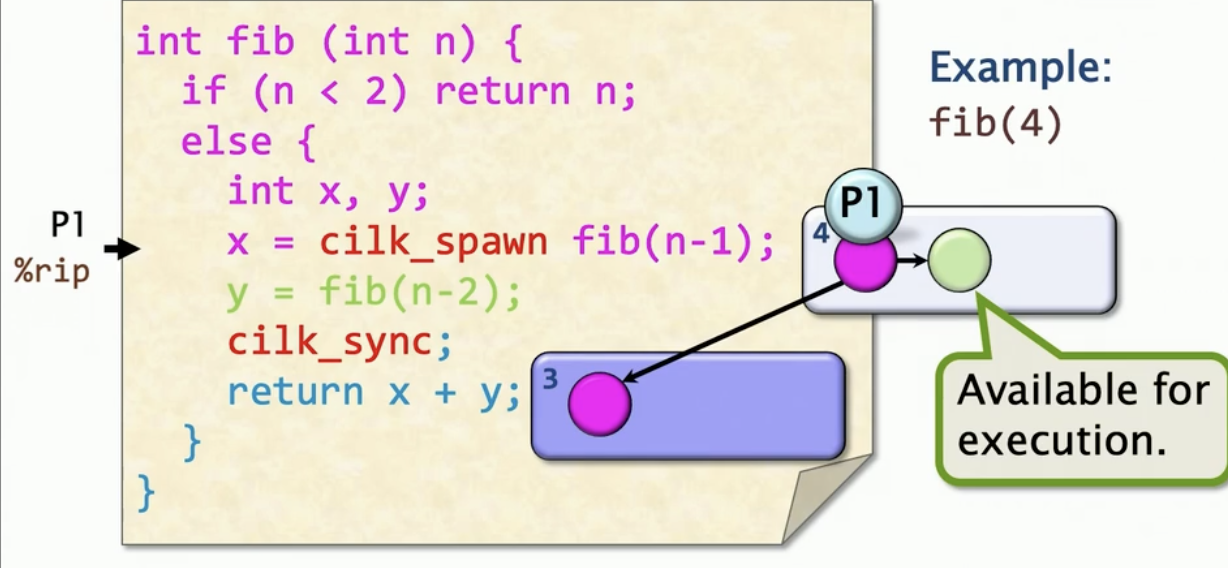 执行到cilk_spawn时, 就像是调用普通函数一样,我们会得到一个执行fib(3)的新帧, 然后我们有可执行的链路,并且有一个绿色链路,在fib(4)帧中。此时处理器会怎么做呢? 下潜到fib(3), 最终得到
执行到cilk_spawn时, 就像是调用普通函数一样,我们会得到一个执行fib(3)的新帧, 然后我们有可执行的链路,并且有一个绿色链路,在fib(4)帧中。此时处理器会怎么做呢? 下潜到fib(3), 最终得到
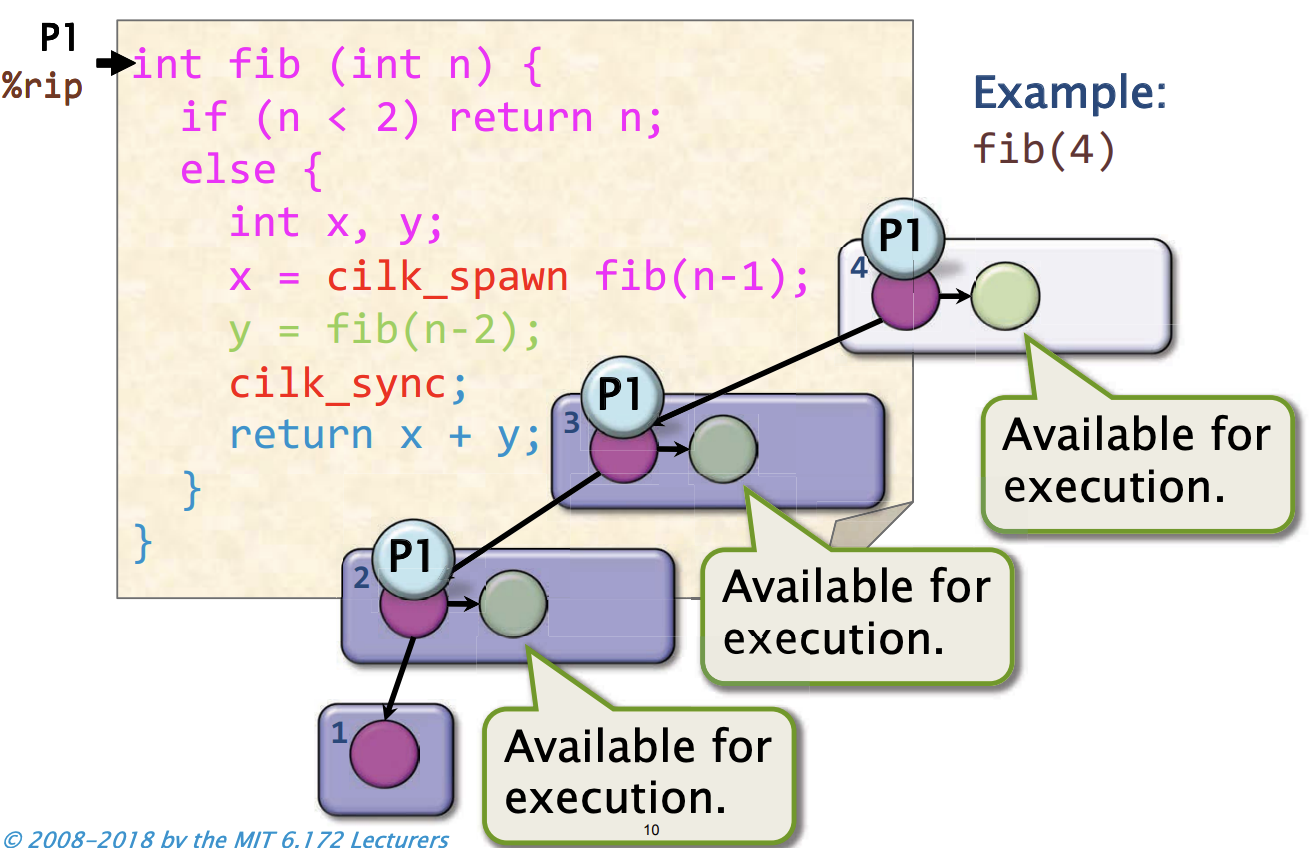
并行执行:Steal
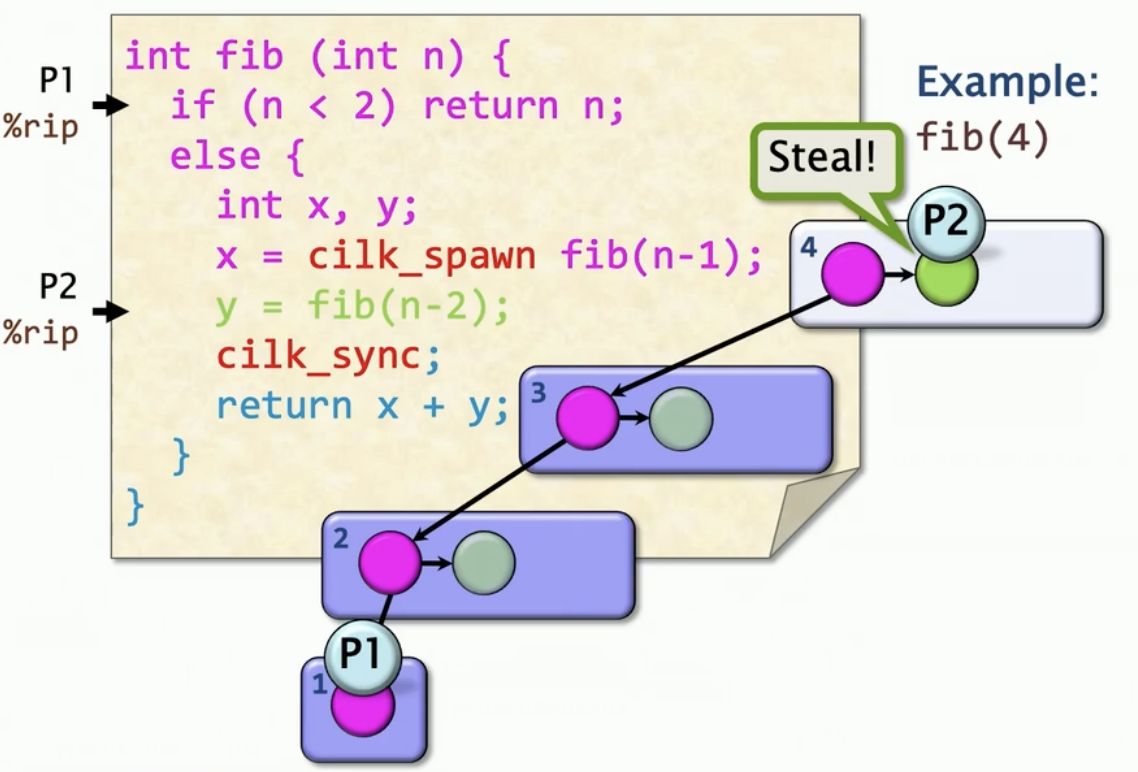
假设还有一个处理器P2,无事可做它就会在帧fib(4)中偷取任务,而P1还在下潜的可用执行链中,此时P2就跳出来,帮P1执行。P2只是设置了指令指针,指向绿色的,此时就像执行普通函数一样,继续下潜调用fib(2)。此时也可能出现另外一处理器P3偷窃另一块计算
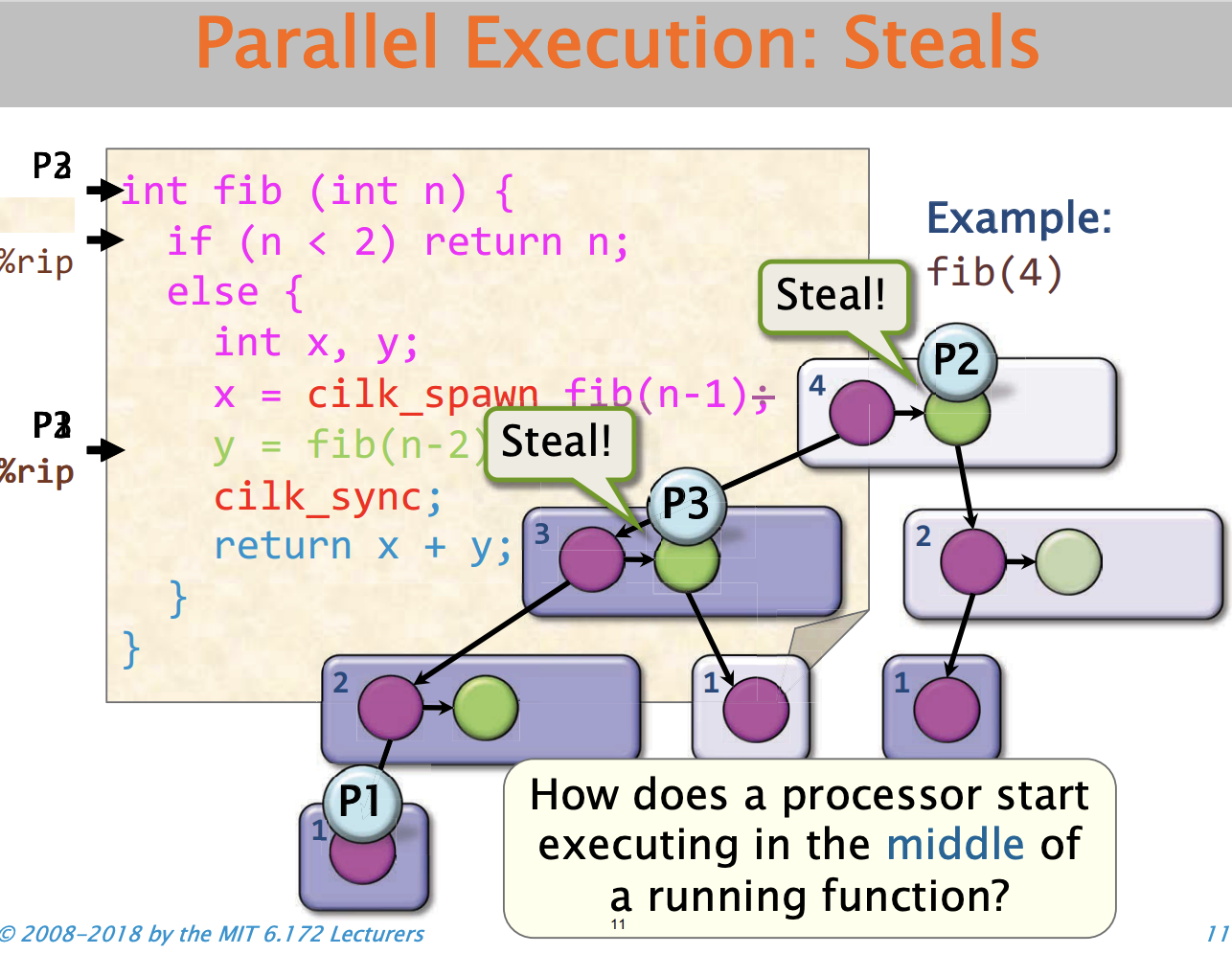
问题1:
一个处理器如何在一个运行的函数中间开始执行呢?
并行执行: Sync
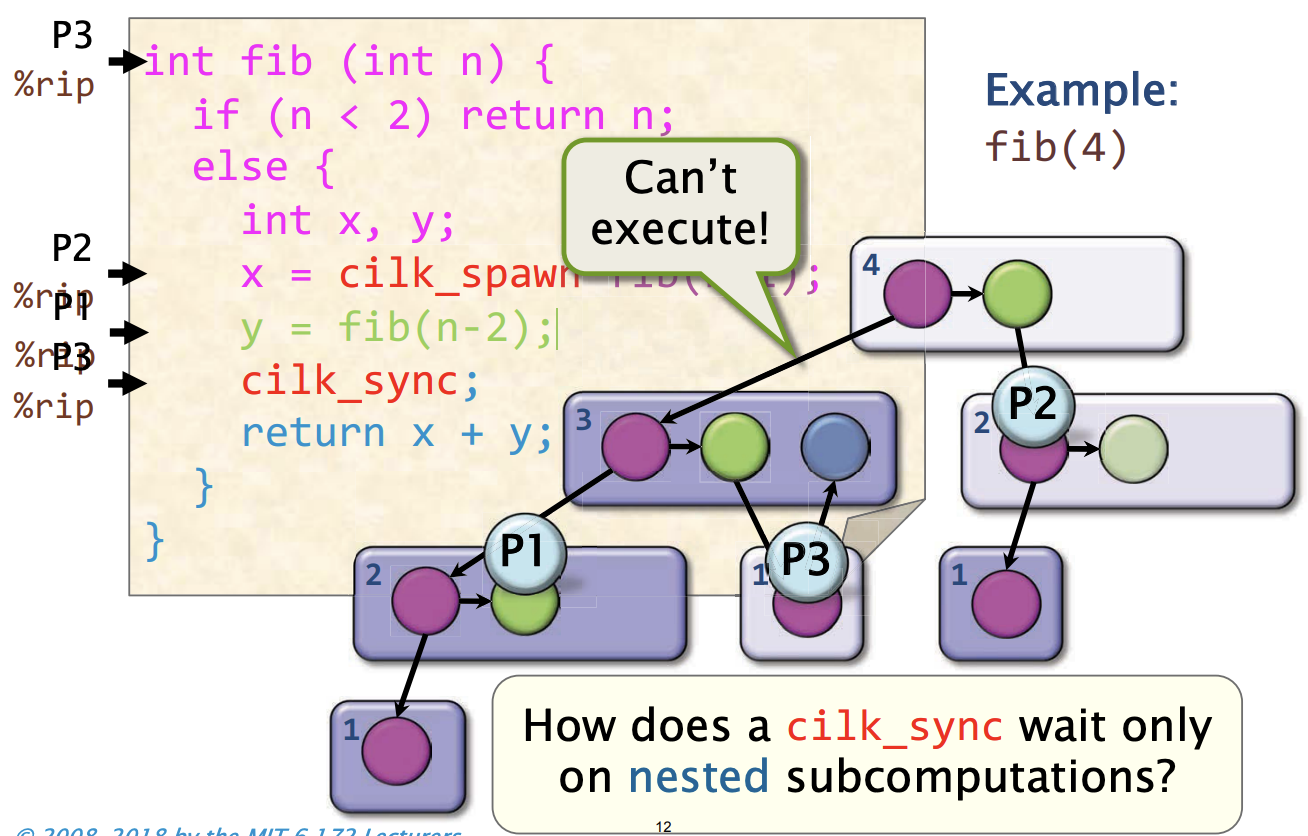
我们假设P3决定返回给帧fib(3),执行到cilk_sync时, P3不能执行sync, 因为P1的计算尚未完成, 并且它并不需要管P2,他在另树的另外一遍进行计算,它只需要等待P1
问题2:
cilk_sync 如何只等待嵌套的子计算?怎么实现的呢?
在 Cilk 语言中,
cilk_sync用于等待所有由当前函数直接生成的子计算(即子任务)完成。这意味着,当执行cilk_sync时,它只会等待那些在当前函数作用域内直接生成的子任务完成,而不会等待其他更外层或同级生成的任务。
初步功能分析
单个工作线程必须能够像普通串行计算一样独立执行计算。
窃取者必须能够跳入正在执行的函数中,窃取其后续操作。
同步操作必须能够暂停一个函数的执行,直到子计算完成。
我们还需要什么功能才能实现呢?
回顾一下: Cilk实现了仙人掌栈
Cilk支持C的指针规则: 一个指向栈空间的指针能够从父(线程)到子(线程),而不能从子(线程)到父(线程)
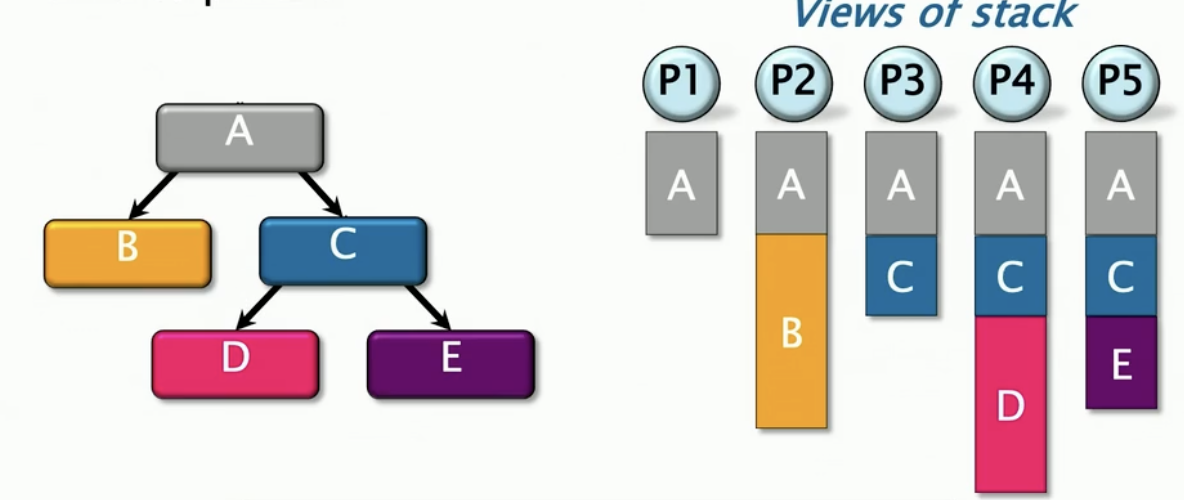
更细节地探讨: 工作偷窃
假设每个工人(处理器)维护着一个工作双端队列,用来存储准备执行的任务("ready strands"),这些任务等待被分配到处理器上运行。像堆栈一样操作队列底部,意味着新任务添加到队列尾部,处理器也会优先从队列底部取出任务来执行。每个双端队列包含着spawned帧和调用帧。
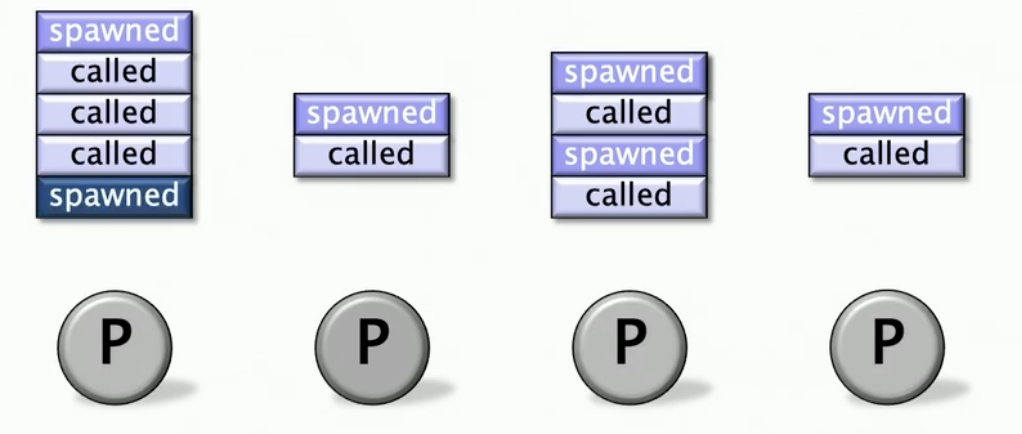
当有个家伙已经把他自己工作做完后,他回去随机找个其他家伙去偷工作,具体而言,从它的队列顶部偷,而且是偷一堆工作。
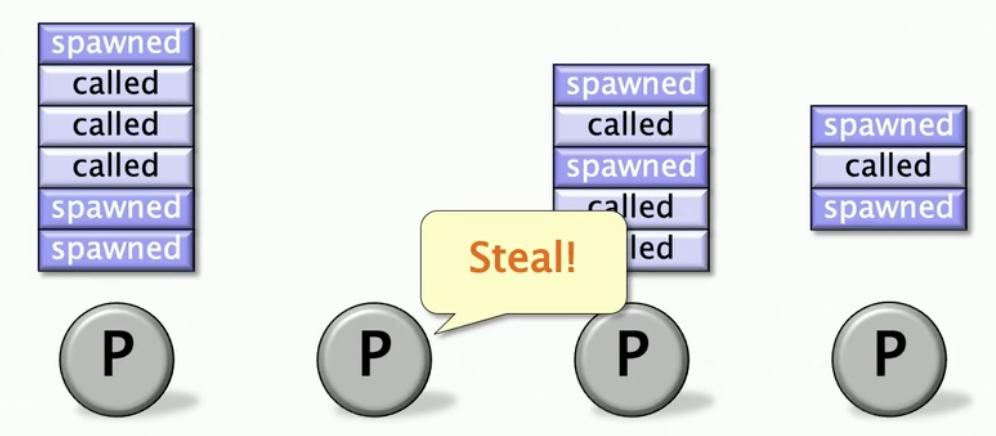
具体例子,假如他挑选了P3这个家伙,他会偷到下一个spawned为止
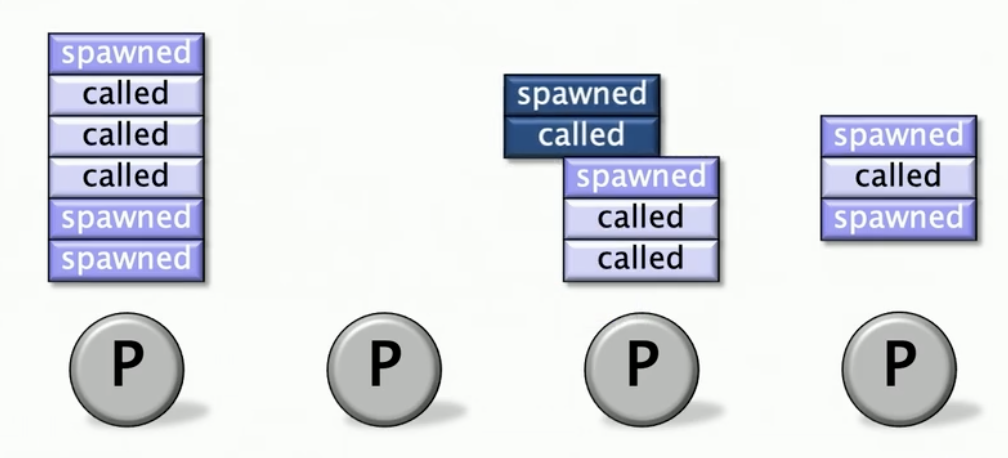
这种偷帧(stealing frame)的会涉及到
- 需要什么同步机制?
- 栈会发生什么?
- 效率怎么样?
最终功能分析
单个工作线程必须能够像普通串行计算一样独立执行计算。
窃取者必须能够跳入正在执行的函数中,窃取其后续操作。
同步操作必须能够暂停一个函数的执行,直到子计算完成。
运行时必须为其并行工作线程实现一种仙人掌栈(cactus stack)
窃取者必须能够处理混合调用和生成的函数。
性能分析
IMPORTANT
Cilk的工作偷窃调度器实现的在P个处理器的期望运行时间 Tp ≈ T_1 / P + O(T∞)
T_1/P,工人花费在工作的时间,
O(T∞), 工人花费在偷工作的时间
如果我们提供更多的处理器执行, 且程序执行时间能够随着P数量线性减小,那么意味着工人花费在工作上的占据绝大多数
看看这个例子

理想状态下,我们希望将一个顺序代码放到P个处理器的机器执行,能够有P倍的加速.
我们做个正式的定义:
TS:串行程序的工作量,即串行程序完成所有任务所需的时间。
T1:并行化做个串行程序的总工作量,即所有处理器完成所有任务所需的总时间。假设只有一个处理器时,并行程序需要的时间。
T∞:并行程序的跨度(span),即完成所有任务的最长路径所需的时间
TP:P个处理器上并行程序的执行时间
要在P个处理器上实现线性加速,即:
为了实现这个目标,并行程序必须具备以下两个条件:
足够的并行性
高工作效率
工作优先原则
为了优化具有足够并行性的程序执行,Cilk运行时系统的实现通过遵守工作优先原则来保持高工作效率: 为了普通的串行执行进行优化,即使代价是增加偷取时的一些额外计算。
工作优先原则指导了Cilk运行时系统在编译器和运行时库之间的分工。
编译器
- 使用少量小数据结构,例如,工作者和栈帧。
- 实现了在没有发生任务窃取时函数执行的优化快速路径。
运行时库
- 使用较大的数据结构。
- 处理执行的慢路径,例如,当发生任务窃取时
双端工作队列的实现
基本概念
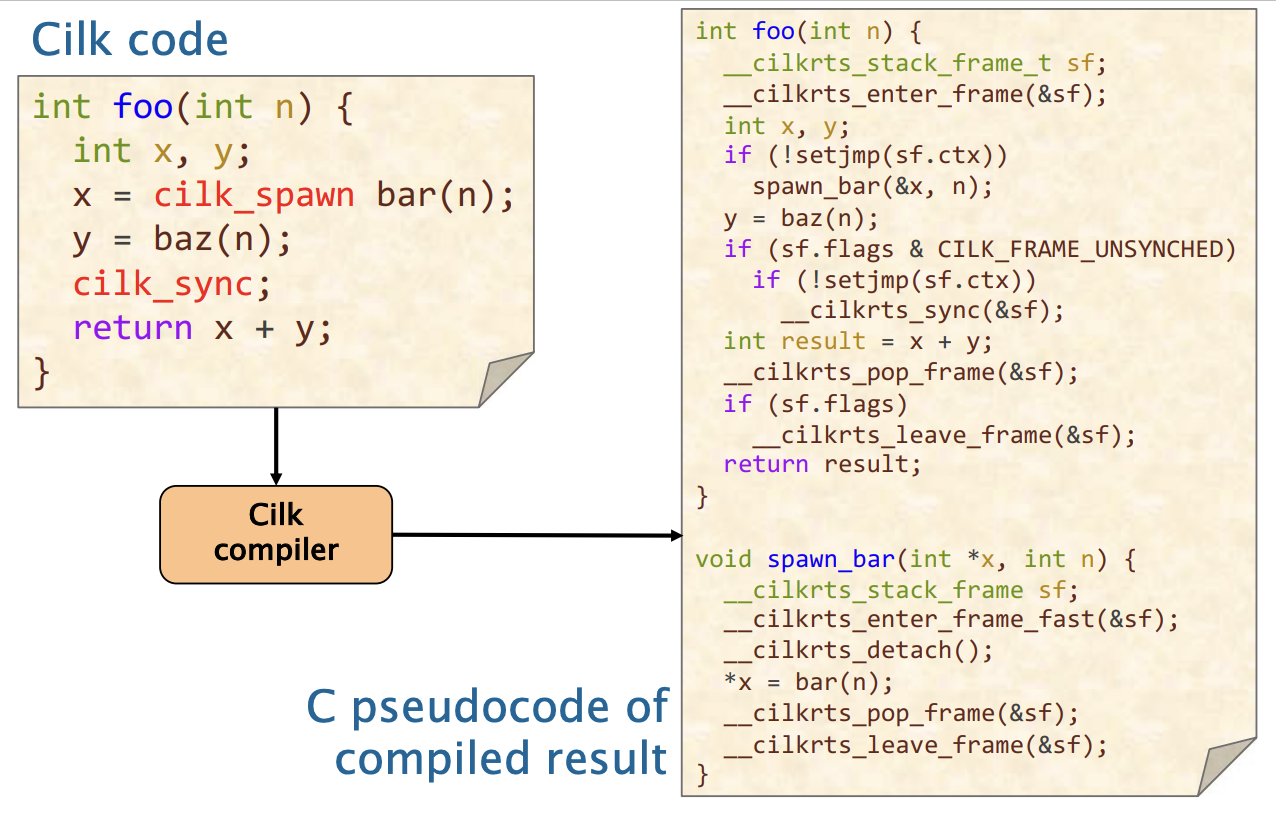
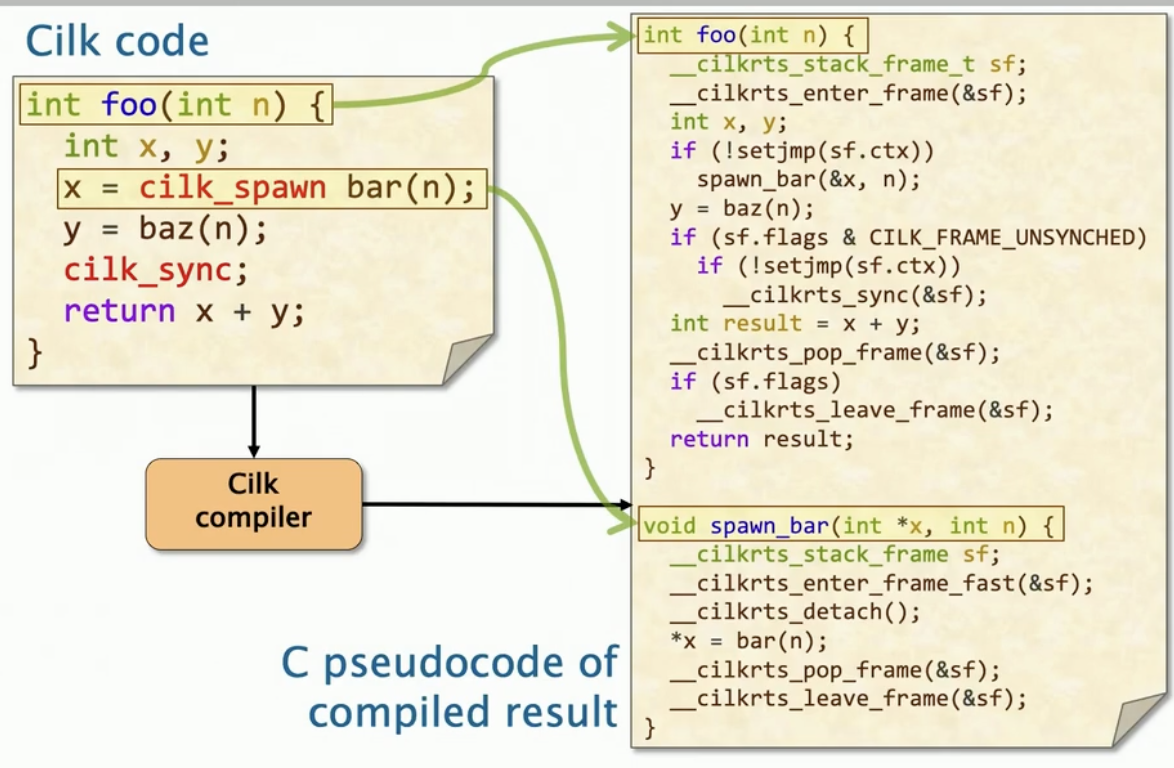
int foo(int n) {
int x, y;
x = cilk_spawn bar(n);
y = baz(n);
cilk_sync;
return x + y;
}- 函数foo是spawning函数,意思是foo包含了silk_spawn语句
- bar 由 foo 生成(spawned)
- 如果有baz的调用, 则这个调用会发生在生成的任务执行(spawn)完毕后
工作双端队列的需求
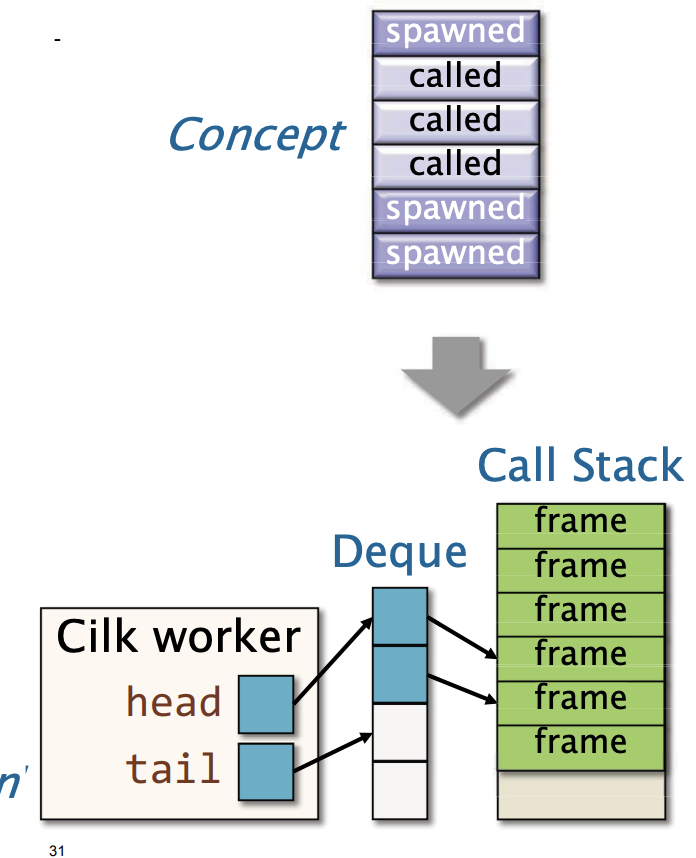
- 偷窃者应该像堆栈一样操作自己的双端队列。
- 一个偷窃操作需要将连续的多个帧的所有权转移给偷窃者。
- 抢劫者需要能够恢复继续执行点
一个思路: 工人的双端队列是一个外部结构,其中包含指向栈帧的指针。
- Cilk工人维护双端队列的头部和尾部指针。
- 可窃取的栈帧额外维护一个结构,用于存储偷窃该栈帧所需的信息
实现细节
Intel Cilk Plus运行时如何实现并行计算的基本思路:
- 每个生成的子计算都在自己的spawn-helper函数中运行。
- 运行时系统维护三种基本的数据结构,这些结构在工作线程执行任务时被使用:
- 每个工作线程使用的工作线程结构(worker structure)。
- 每个生成函数实例都对应一个Cilk栈帧结构(Cilk stack-frame structure)。
- 每个cilk_spawn实例都对应的spawn-helper栈帧(spawn-helper stack frame)。
┌─────────────────────────┐
│ Worker 1 │
│ │
│ ┌─────────────────┐ │
│ │ Cilk Stack Frame │ │
│ │ (Function A) │ │
│ └─────────────────┘ │
│ │
│ ┌─────────────────┐ │
│ │ Spawn-Helper │ │
│ │ Stack Frame │ │
│ │ (cilk_spawn B) │ │
│ └─────────────────┘ │
│ │
└─────────────────────────┘
┌─────────────────────────┐
│ Worker 2 │
│ │
│ ┌─────────────────┐ │
│ │ Cilk Stack Frame │ │
│ │ (Function C) │ │
│ └─────────────────┘ │
│ │
│ ┌─────────────────┐ │
│ │ Spawn-Helper │ │
│ │ Stack Frame │ │
│ │ (cilk_spawn D) │ │
│ └─────────────────┘ │
│ │
└─────────────────────────┘Spawn-Helper函数
Stack-Frame 结构
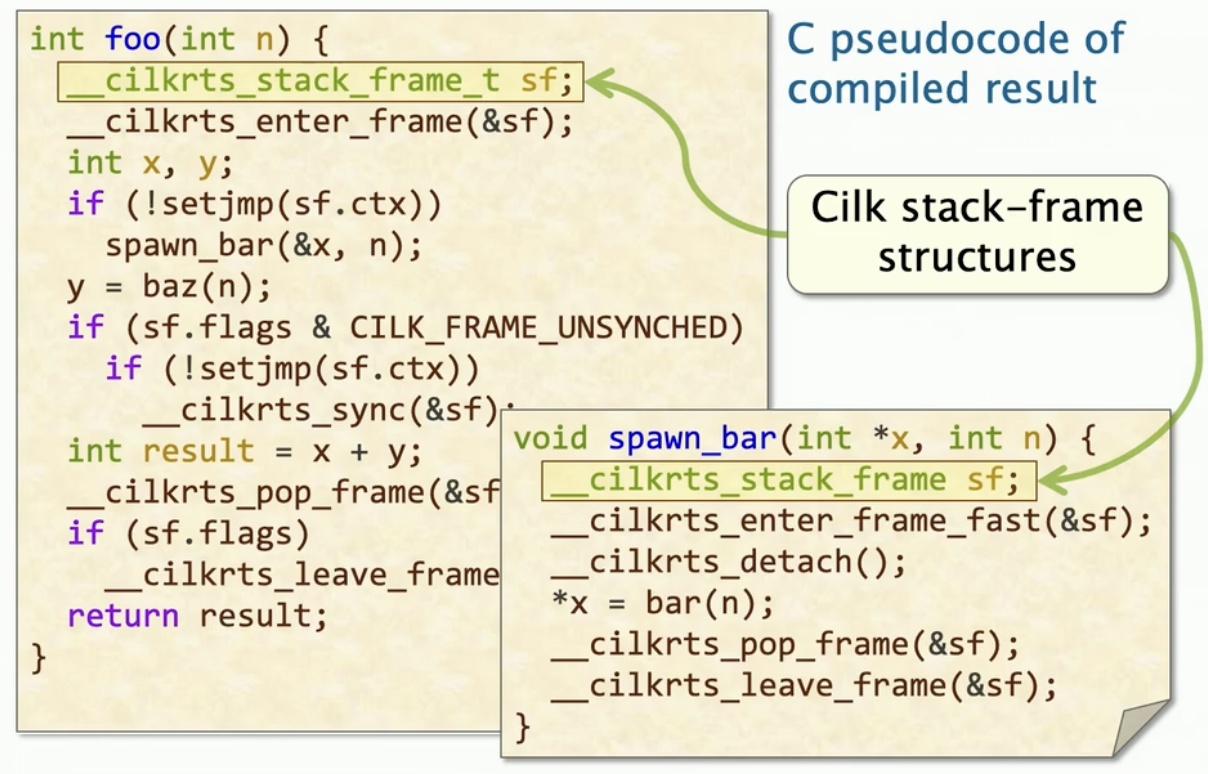
每个Cilk栈帧存储内容:
- context buffer, ctx, 存储者足够的信息在继续点 恢复函数的执行,比如cilk_spawn 或者 cilk_sync.
- flag ,标记状态
- parent,标记它的父帧栈
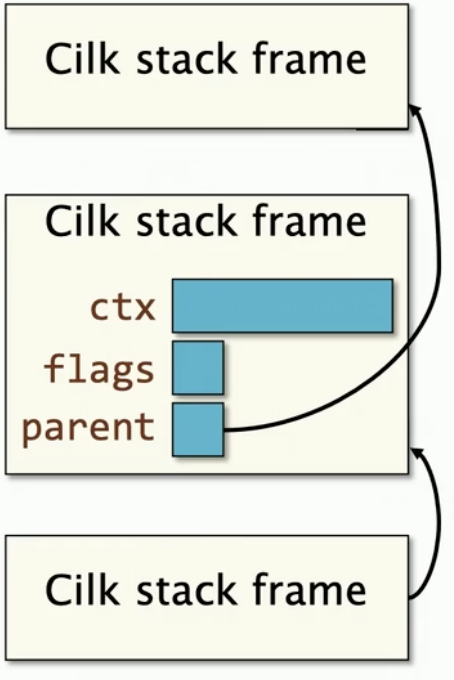
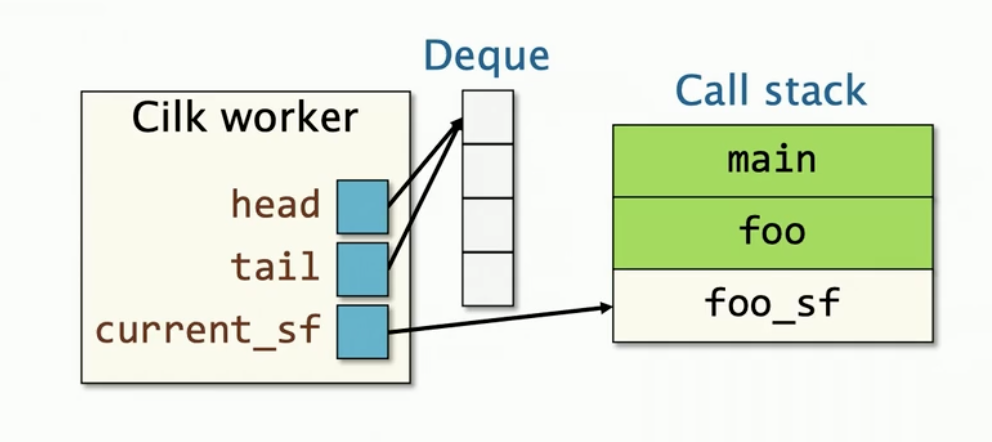
Cilk Worker结构(简化版)
每个Cilk工作线程包含
- 能够被偷窃的双端队列,在调用栈的外部
- 指向当前帧栈道指针
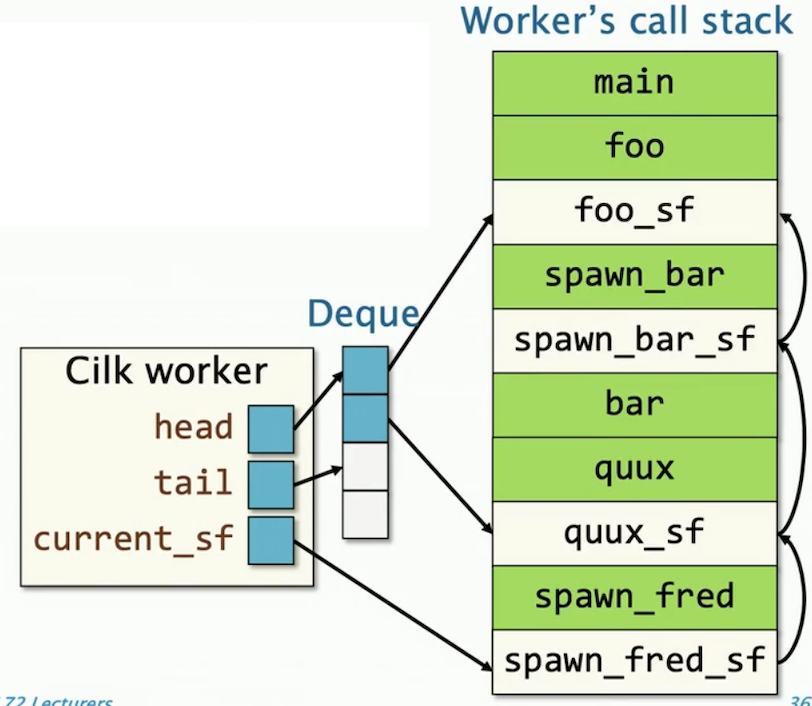
函数对象是绿色部分,本地变量是米色部分,foo_sf是foo实例内的CilkRTS帧栈
Spawning 计算
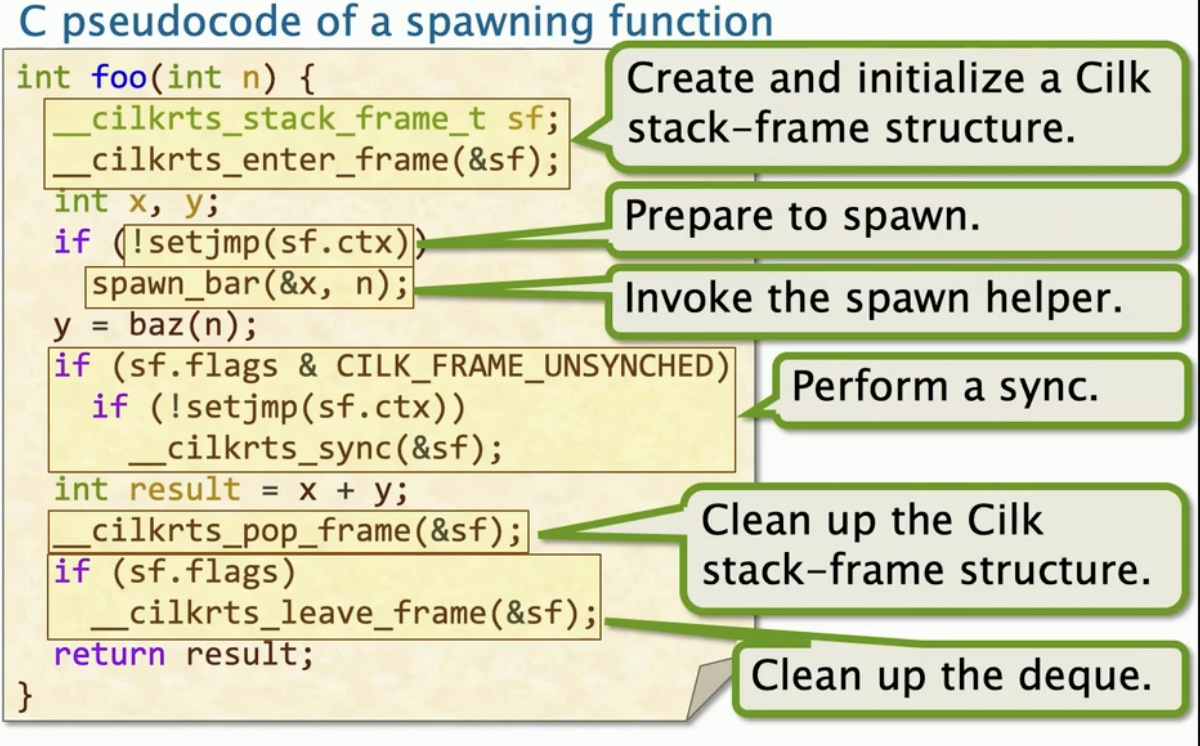
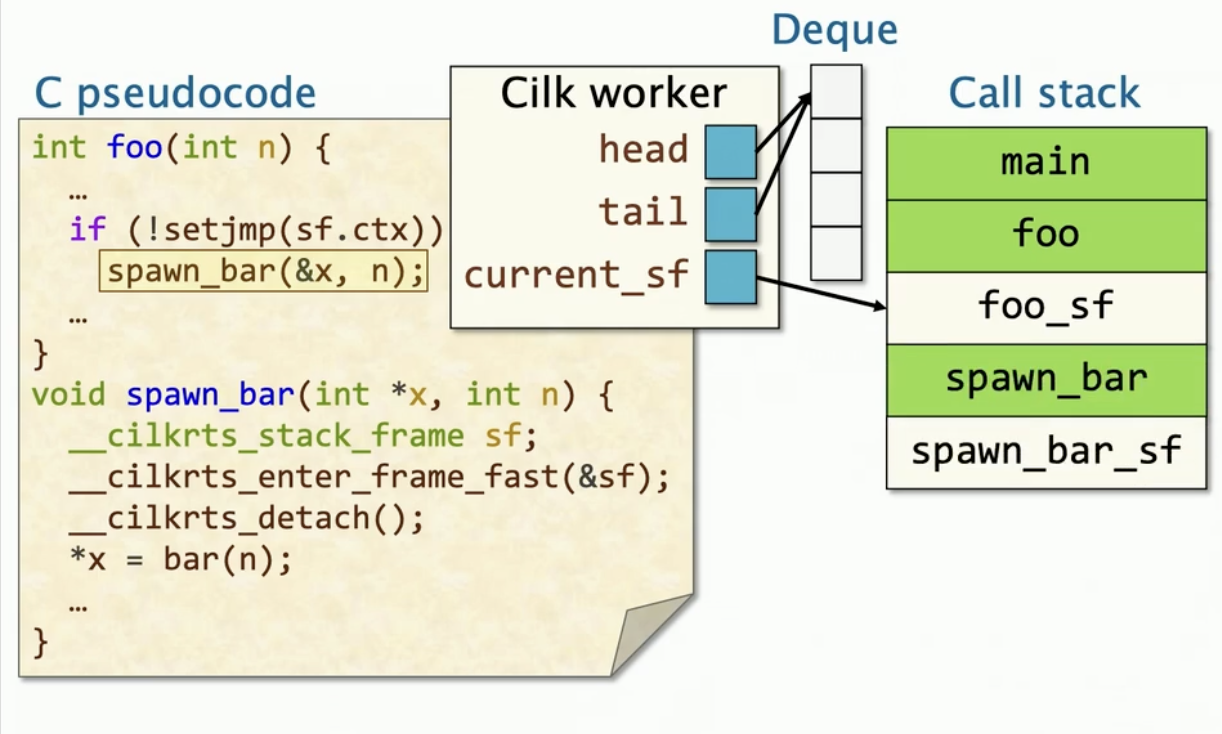
一个spawn函数的伪代码
所有框选的代码都与运行时有关
一个spawn_helper函数的伪代码
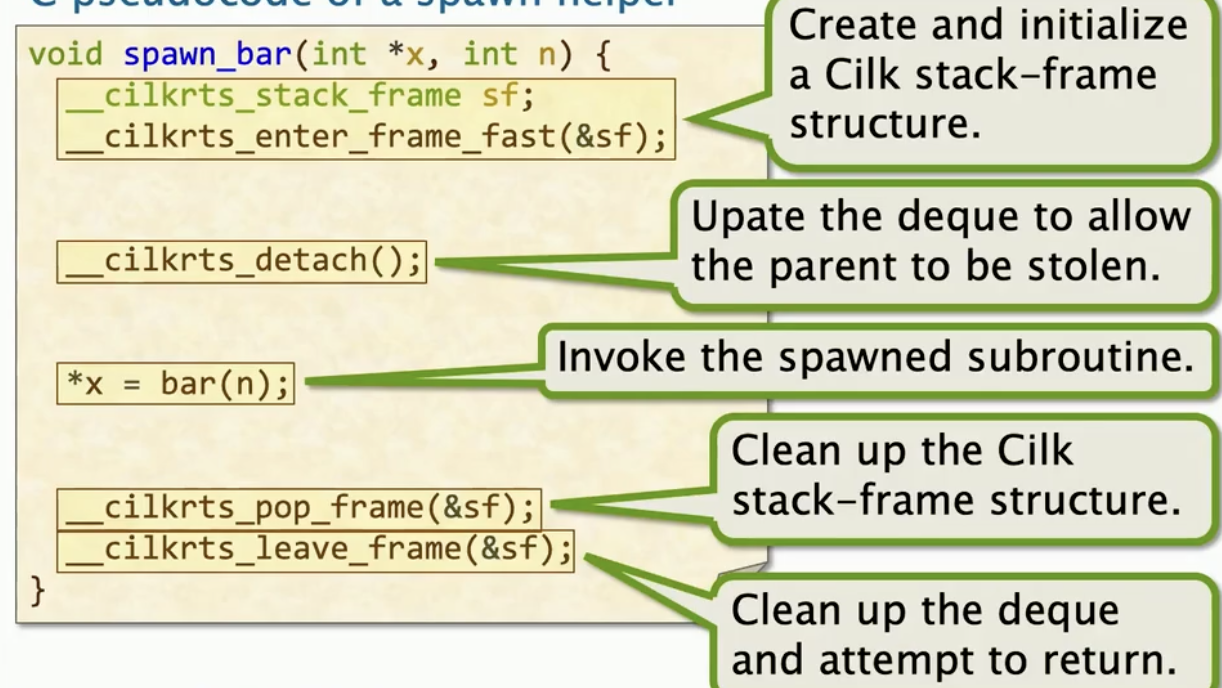
同样的,他也对初始化栈帧;__cilkrts_detect(),会对双端队列进行更新,然后是实际的调用,最后是清除操作
1、 进入一个Spawning函数时,Cilk worker当前的帧栈就更新了
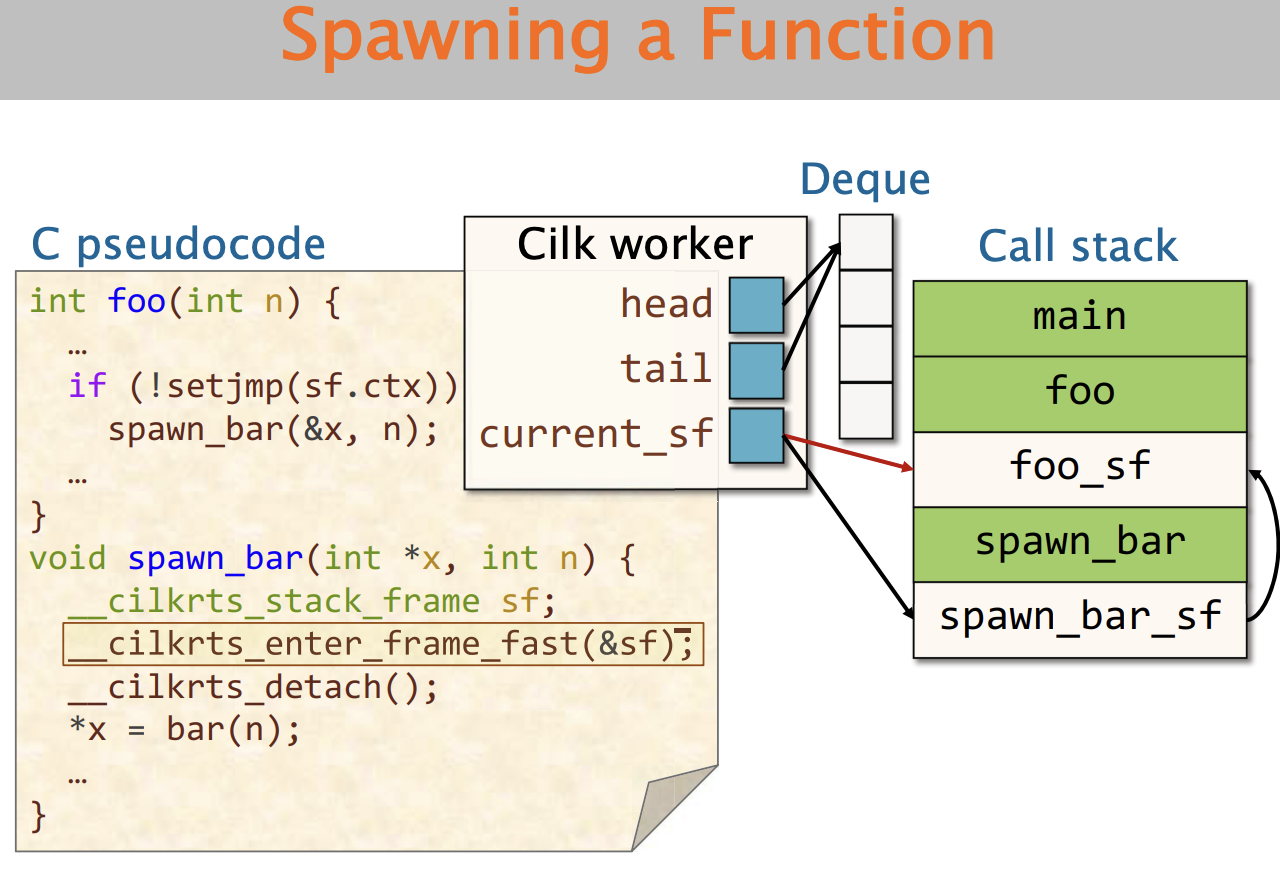
2、 准备Spawn

Cilk使用setjmp函数用来允许偷窃者偷窃继续执行点。
setjmp的参数接受一个buffer(ctx buffer),这个buffer存在于Cilkrts的帧栈中,setjmp函数会存储恢复函数所需要执行函数所必要的信息存到ctx buffer中。
那setjmp到底需要存储什么信息呢?
- Callee-saved register 被调用方保存的寄存器(负责保存和恢复的寄存器),即foo函数需要负责保存的
- %rip
- %rbp
- %rsp
然后我们添加了父指针,已经更新
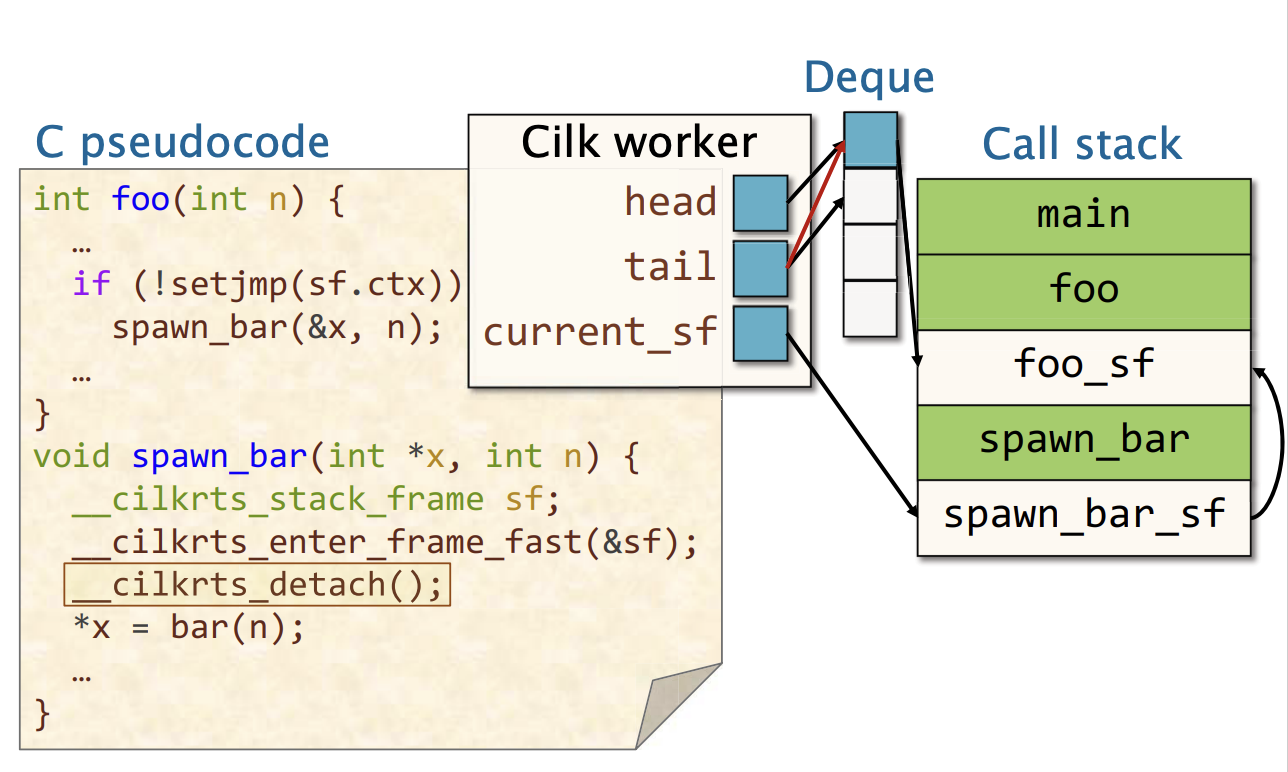
从Spawn返回
从双端队列出列
在__cilkrts_leave_frame,工作线程尝试从双端队列尾部pop一个栈帧。此时有两种可能:
- 如果pop成功了, 则一如既往的正常执行
- 如果pop失败了,则工作线程把工作都做完了,他会成为一个偷窃者,然后参数从其他受害者的deque的顶部偷取工作。
那种情况更值得优化
情况1
Stealing 计算
如何偷取一个帧
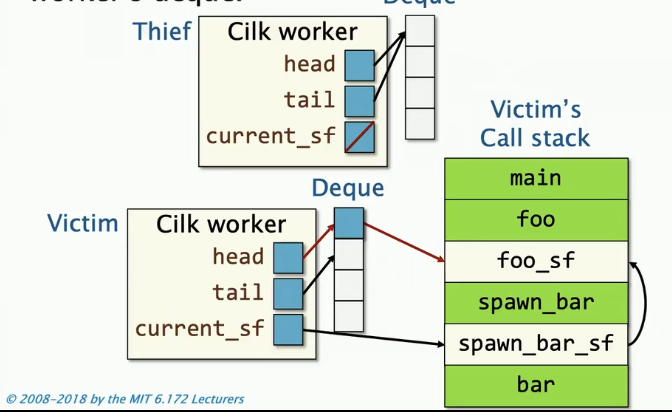
偷窃者的current_sf最终指向双端队列的顶部
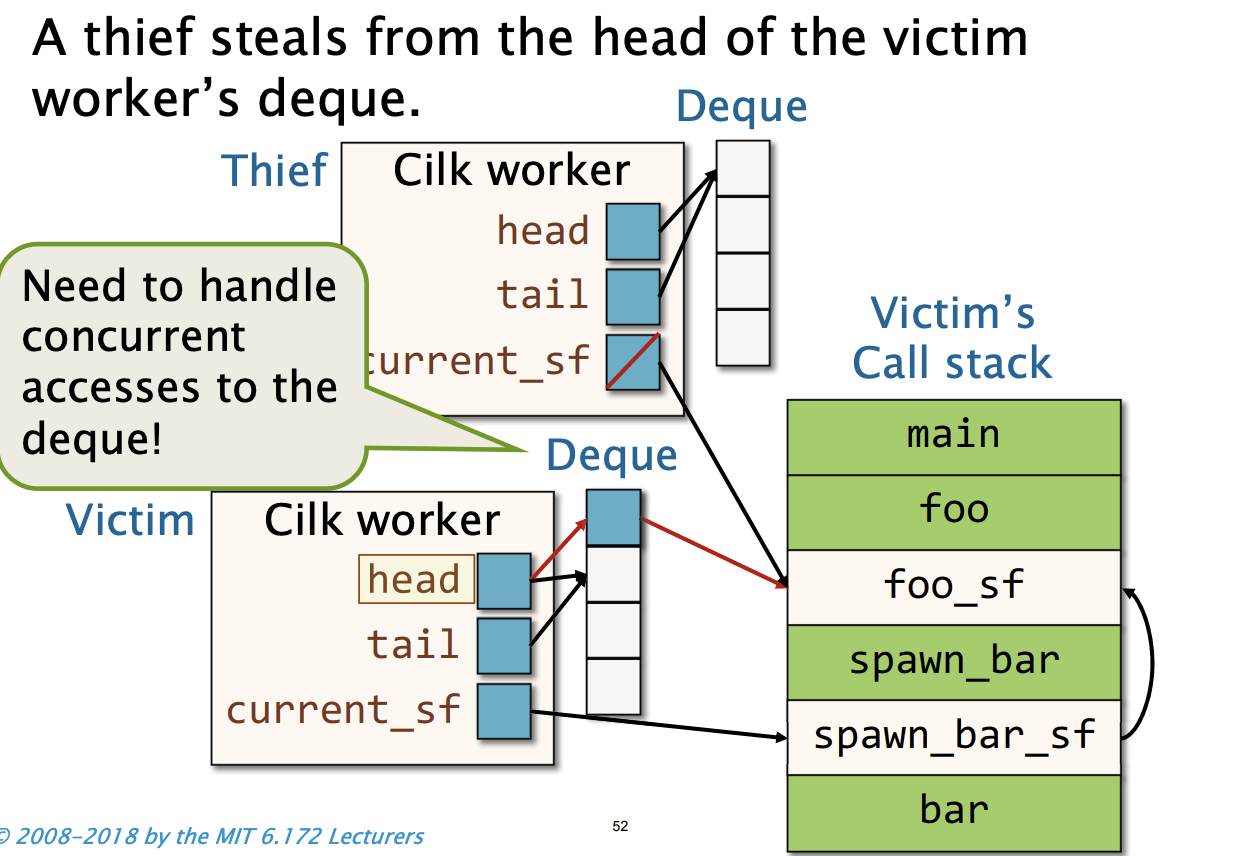
这里需要对双端队列并发访问进行处理
以下是同步访问双端队列的协议
// worker协议
void push() {
tail++;
}
bool pop() {
tail--;
if (head > tail) {
tail++;
lock(L);
tail--;
if (head > tail) {
tail++;
unlock(L);
return FAILURE;
}
unlock(L);
}
return SUCCESS;
}
// worker(工作线程)和 thief(偷窃线程)使用 THE 协议(THE protocol)来协调对双端队列(deque)的操作。THE 协议是一个锁自由(lock-free)的协议
bool steal() {
lock(L);
head++;
if (head > tail) {
head--;
unlock(L);
}
return FAILURE;
unlock(L);
return SUCCESS;
}从高的层次理解, 小偷在进行任何操作之前始终会抓住双端队列的锁。worker线程会做的是,乐观地从双端队列pop工作出来,只有当deque看起来是空的时候才会去抓住锁。
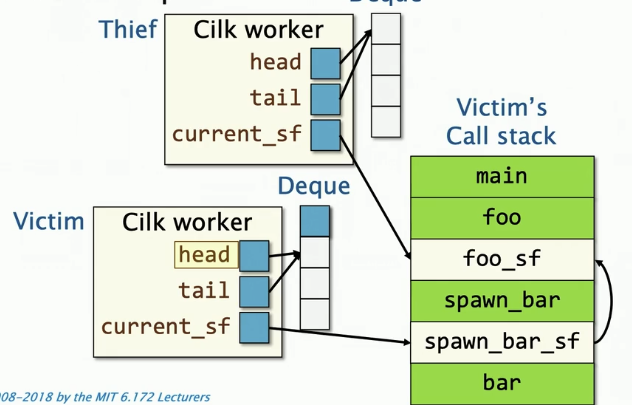
恢复继续执行点
Clik使用longjmp函数来恢复一个被偷窃的继续执行点
int foo(int n) {
...;
if (!setjmp(sf.ctx)) // 受害者提前执行setjmp来存储寄存器(将特定的帧栈buffer作为入参)状态到foo_sf.ctx
spawn_bar(&x, n);
...;
}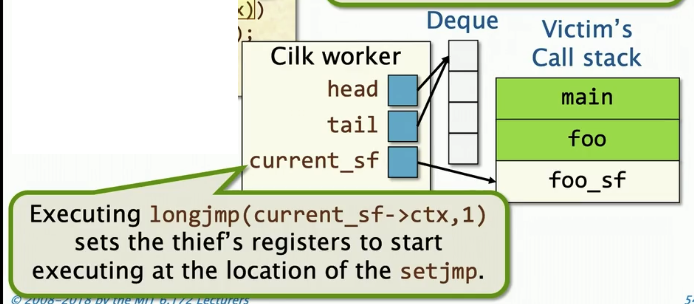
偷窃者的工作线程执行longjmp() 来设置偷窃者的寄存器,恢复被盗的继续执行点,并且把当前帧栈指针指向foo_st。
longjmp返回后发生什么呢?
setjmp 和 longjmp 函数之间的契约,确保了在并行计算中,一个“盗贼”(thief)能够正确地恢复执行上下文(continuation)。具体来说:
当你直接调用
setjmp时,它返回0,并将当前的执行状态保存到传入的缓冲区中当你调用
longjmp(buffer, x)时,程序的执行会跳转回之前调用setjmp的地方。此时,
setjmp不再返回0,而是返回x,即longjmp传递的第二个参数
int foo(int n) {
...;
if (!setjmp(sf.ctx)) // // 因为“盗贼”通过调用 longjmp(current_sf->ctx, 1) 到达这个点,条件判断为假,盗贼跳转到继续执行部分(continuation)。
spawn_bar(&x, n);
...;
}实现仙人掌 Stack
偷窃者维护者们他们的调用栈,并使用指针技巧来实现仙人掌栈。
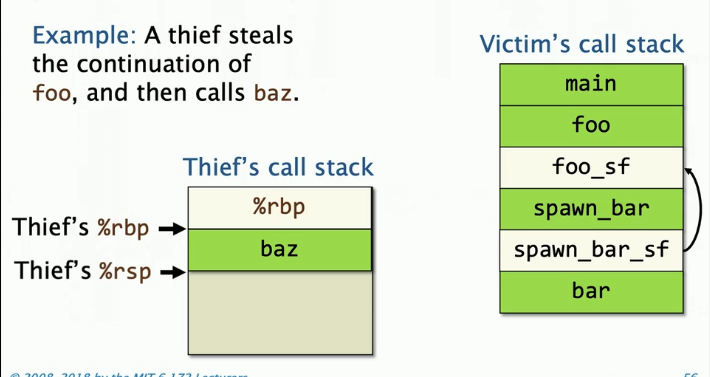
这样偷窃者就可以通过使用受害者的%rbp访问foo函数中所有状态。 通过保存%rbp和更新%rsp来执行调用
Synchronizing 计算
高度的概括下如何运作的。
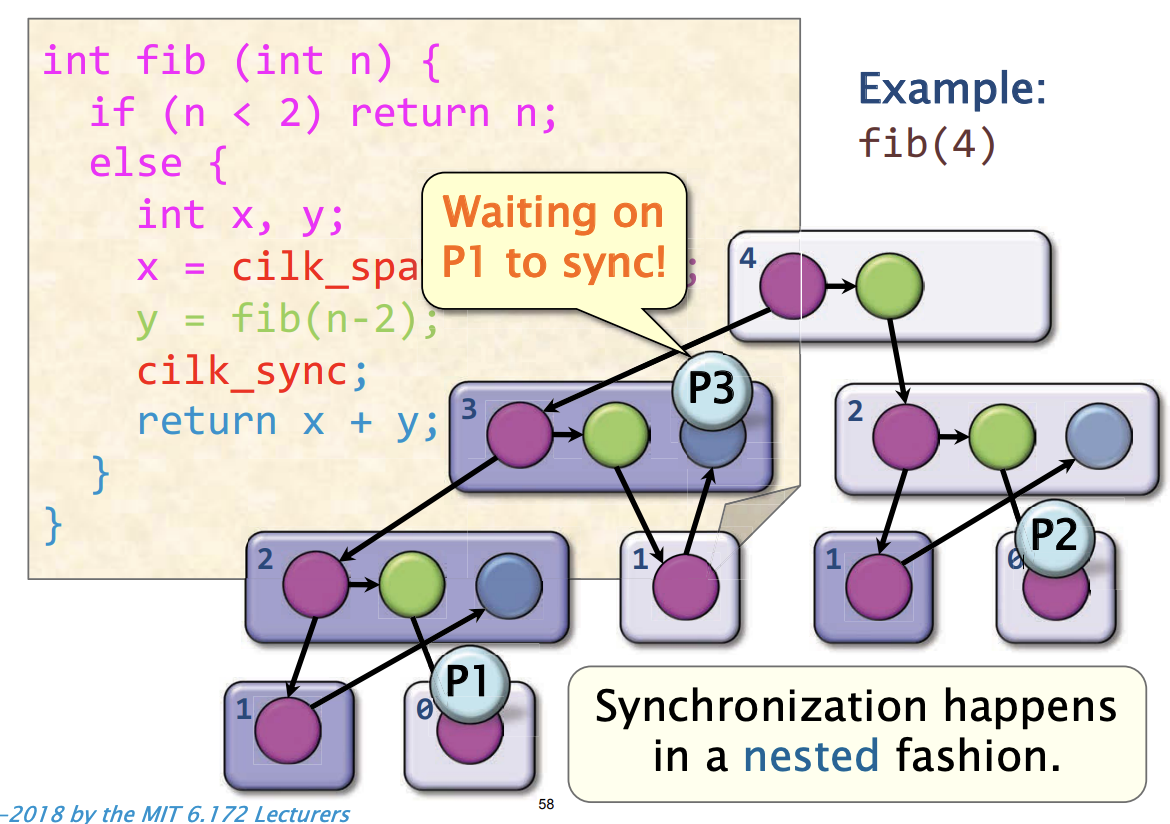
同步的关心的问题
如果一个工作线程在所有生成的子计算完成之前到达了cilk_sync,那么该工作线程应该成为一个盗贼,但工作线程当前的函数帧不应该消失!
- 现有的子计算可能会访问该帧中的状态,因为这是它们的父帧。
- 未来,另一个工作线程必须恢复该帧并执行cilk_sync。
- cilk_sync只适用于该帧的嵌套子计算,而不是所有的子计算或工作线程。
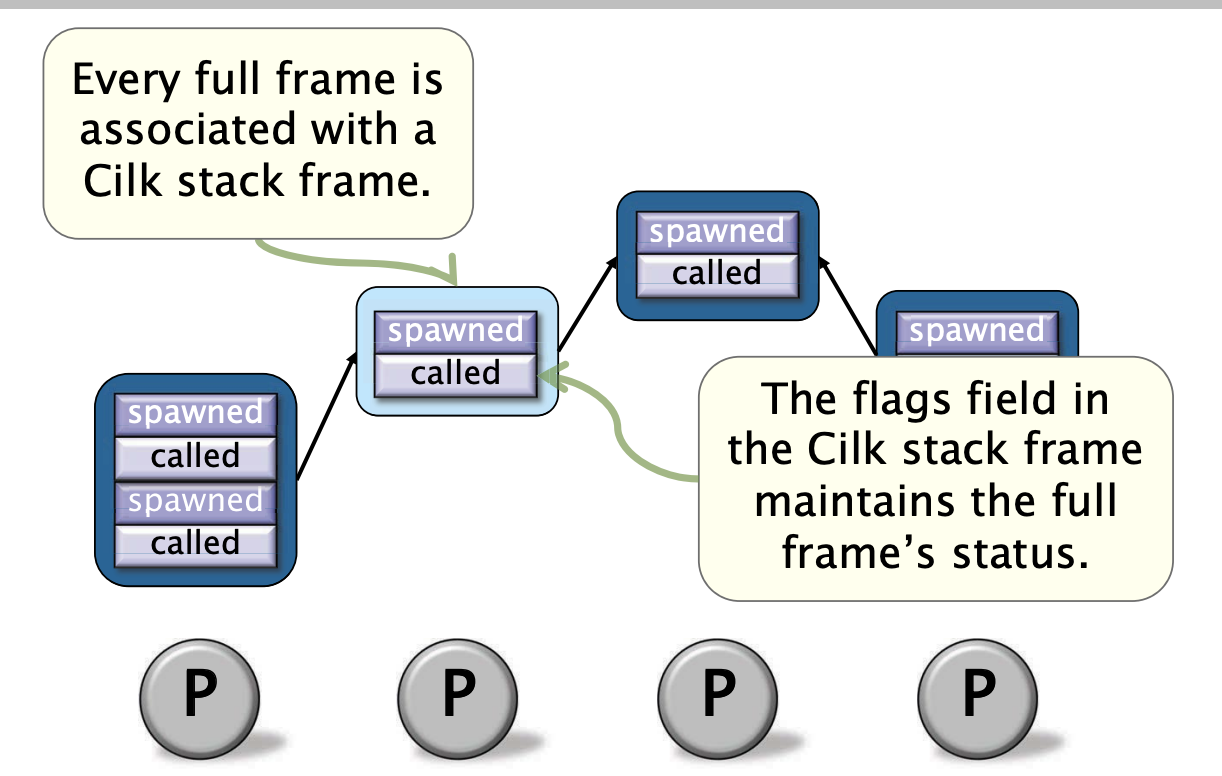
实现原理——全帧树(Full-Frame Tree)
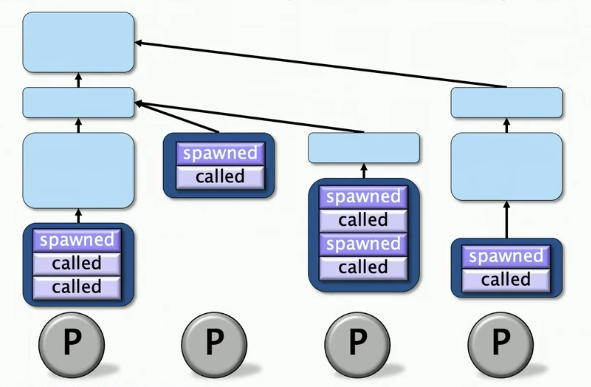
全帧树为所有的并行子计算维护着状态,比如他们的定位以及于其他子计算的关系。
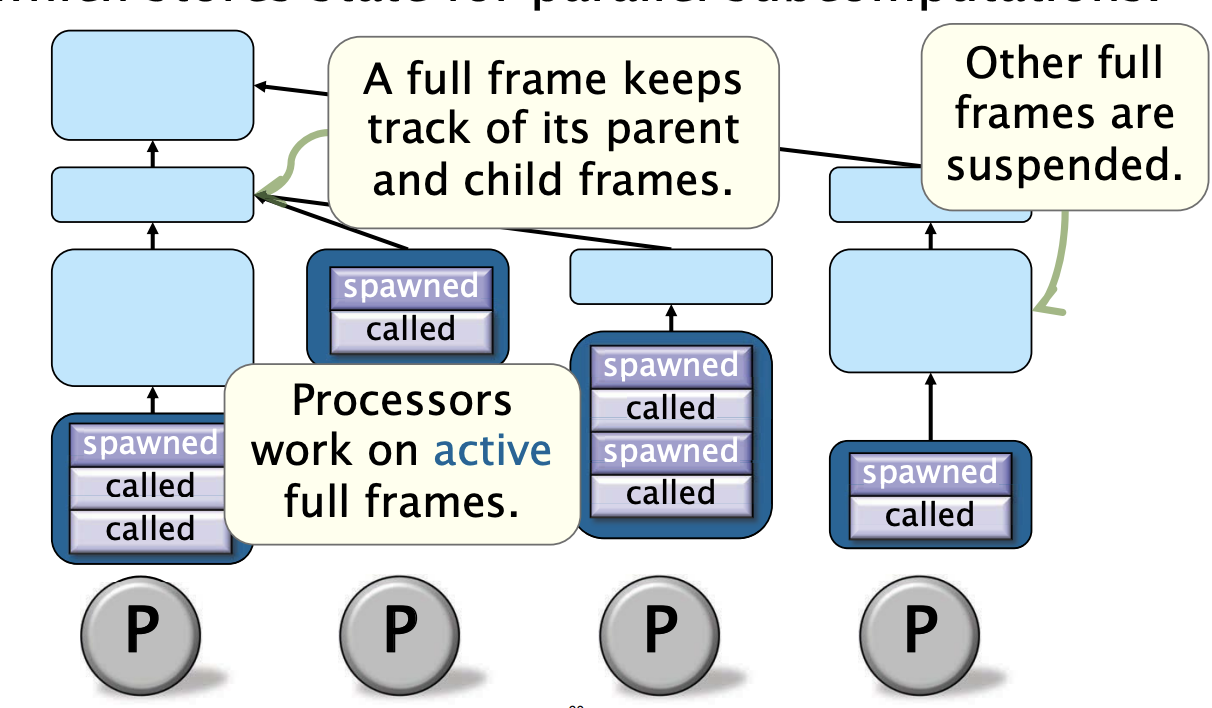
全帧树如何形成
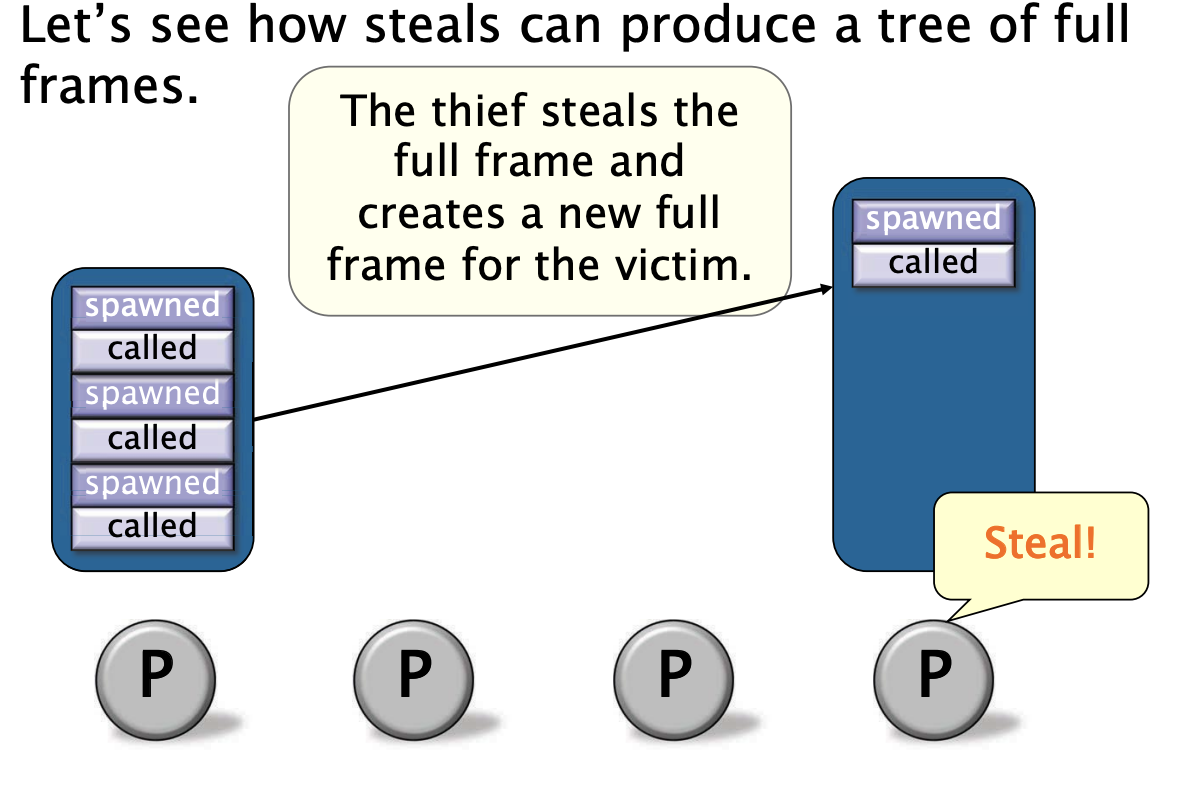
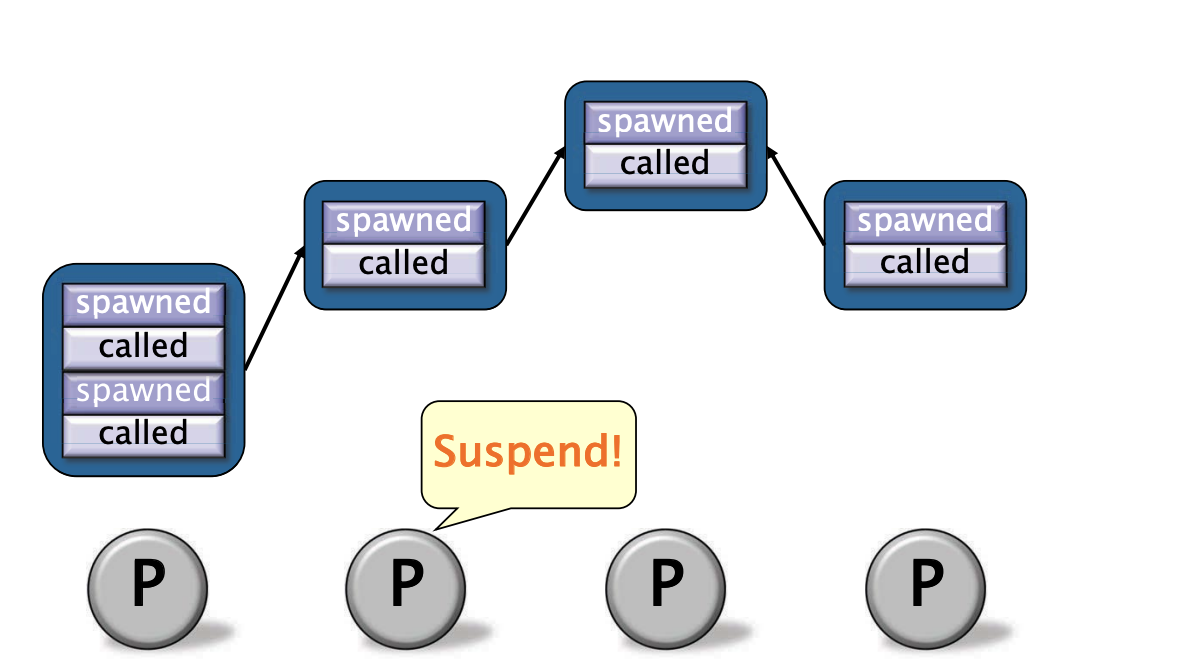
如果程序具有充足的并行性,当程序执行到达cilk_sync时,我们通常期望会发生什么?
答案:执行的函数不包含未完成的生成子计算。
运行时系统如何优化这种情况?
Sync的编译代码
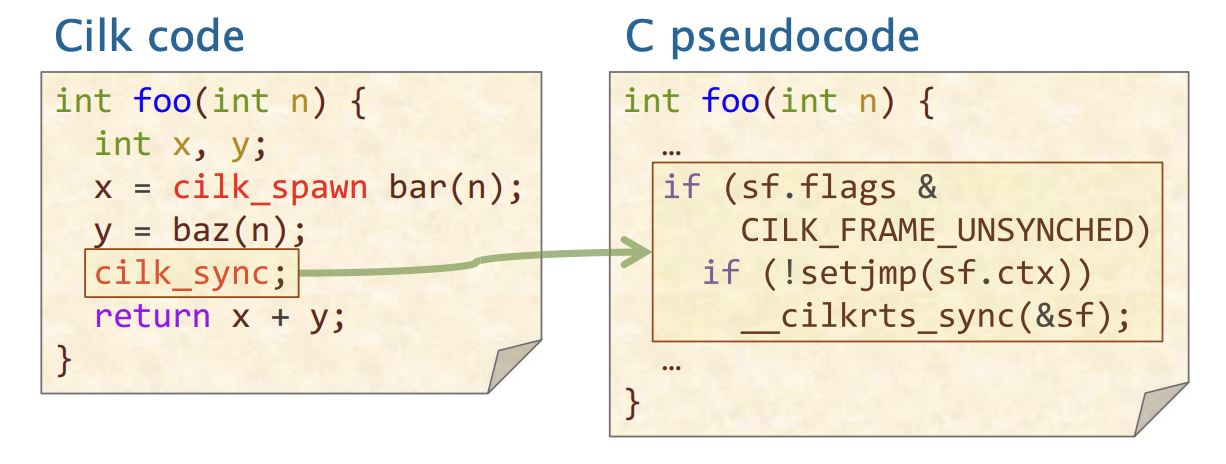
编译用于实现cilkrts_sync的代码在执行一个昂贵的对Cilk运行时库中的__cilkrts_sync E的调用之前,会先检查flags字段。 这是一种优化,如果你不需要同步,则不要做任何计算,否则会发生
运行时其他特性
Cilk运行时系统实现了许多其他功能和优化:
- 简化和易于维护全帧树的方案。
- 支持C++异常的数据结构和协议增强。
- 支持归约器超对象的全帧之间的兄弟指针。
- 谱系,用于在并行中高效地为每个链分配唯一的、确定的ID。