Lec 12 并行存储分配
阅读资料
Hoard: A Scalable Memory Allocator for Multithreaded Applications,ASPLOS'00
SuperMalloc: A Super Fast Multithreaded Malloc for 64-bit Machines, ISMM'15
总览
- C语言的内存分配
- 仙人掌栈
C语言内存分配
内存分配
void *malloc(size_t s)作用: 返回一个指向分配了至少s字节的内存块区域的指针
内存对齐分配
void *memalign(size_t a, size_t s);
分配并返回一个指向内存块的指针,该内存块至少包含
s字节,且对齐到a的倍数,其中a必须是 2 的整数次幂即
0 == ((size_t) metaling(a, s)) % a内存释放
void free(void *p);作用释放由malloc或者memalign()返回的指针指向的内存块区域
分配虚拟内存
mmap()首先,它是系统调用,用于磁盘上的某些文件,将它写入到内存cvoid *p = mmap(0, // Don't care where,实际是起始位置的意思 size, // #bytes PORT_READ | PORT_WRITE, // READ / WRITE MAP_PRIVATE | MAP_ANON, // Private anonymous -1, // no backing file 0); // offset of file(N/A)Linux 内核会在应用程序的地址空间中找到一个足够大、连续且未使用的区域来容纳指定大小的字节数,修改页表,并在操作系统内部创建必要的虚拟内存管理结构,以使用户对该区域的访问“合法”,从而避免访问时发生段错误(segfault)
mmap 性质
mmap()是惰性的。它不会立即为请求的内存分配物理内存。相反,它会将页表中的条目指向一个特殊的零页,并将该页标记为只读。- 当首次写入该页时,会触发页面错误(page fault)。在此时,操作系统会分配一个物理页,修改页表,并重新开始执行指令。
- 你可以在只有几GB内存的机器上映射一个TB的虚拟内存。
- 进程可能在
mmap()调用后很久才因为耗尽物理内存而崩溃。
- 进程可能在
mmap vs. malloc ?
malloc() 和 free() 是C库中堆管理代码的一部分,负责内存分配接口
堆管理代码使用可用的系统功能,包括
mmap(),从内核获取内存(虚拟地址空间)malloc()中的堆管理代码尝试通过重用已释放的内存来满足用户对堆存储的请求- 重用内存,减少碎片;而mmap更多的是找OS要内存空间
必要时,
malloc()的实现会调用mmap()和其他系统调用来扩展用户堆存储的大小总得来说,对于程序员,对于小的内存分配,用malloc因为它帮你做了重用的事情;对于分配大内存区域用mmap,如果小内存区域也用mmap会带来比较大的性能问题,cache miss问题等等
仙人掌栈
传统的线性栈
C、C++程序的执行可视为调用树。
指针规则:父进程可以将指向其栈变量的指针传递给子进程,但反之则不行。
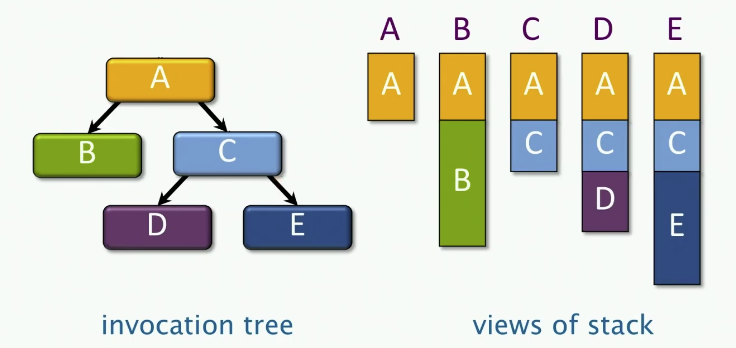
以上的串行的情况,那并行的情况呢?
仙人掌栈
它允许通过在堆上分配栈帧来管理函数调用。这种设计允许更灵活的内存管理。 早期的并行系统都是用这种方式。
- 每个对应的虚拟地址每个函数的视角下都是相同的。
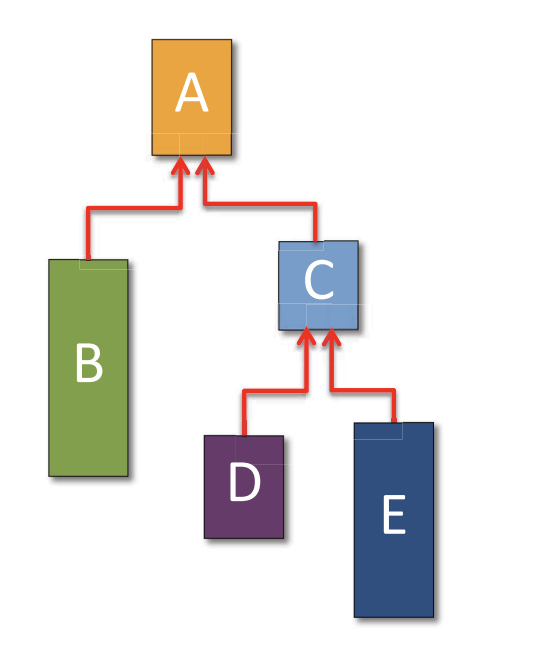
但是这里面会有比较大的性能问题,你知道是什么吗?
Solution:会有”interoperablity,相互操作性"问题。除非将编译器重新实现成的完全基于仙人掌栈的方式,如果只是想在传统的堆栈进行的优化,可能很难与旧代码兼容。或许你可以用"local thread memory mapping"解决,但是这依赖OS的支持,通用OS可能无法实现。
空间复杂度分析
定理:设$S $ 为串行执行 Cilk 程序所需的栈空间。使用基于堆的仙人掌栈的$P
证明:Cilk 的工作窃取算法维持了繁忙叶子属性(Busy-leaves):每个活动的叶子帧都有一个工作线程在执行。
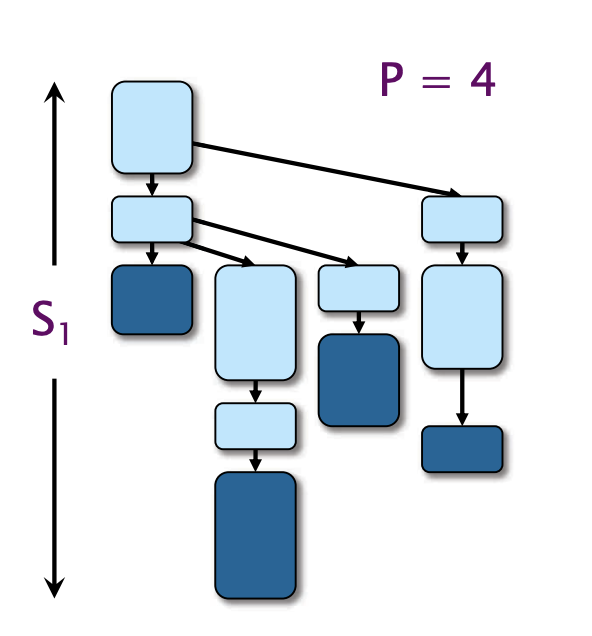
示例: 分治矩阵惩罚

分析:
Work:
Span:
Space:
根据Busy-leaves性质,可知$$
并行分配
Baker‘s 算法
并行和并发GC
- Based on Nettles-O'Toole algorithm
- High-level idea
- Use per-processor local stacks for search
- Maintain a shared stack for load balancing
- Processors periodically transfer objects between local and shared stack
- Use synchronization primitives(test-and-set and fetch-and-add) to manage concurrent accesses