Lec 4 汇编语言和计算机架构
如果你想写出更高效的代码,就必须了解计算机底层的工作原理。通过深入理解底层机制,你可以更好地利用计算机架构的优势。汇编语言提供了直接访问和控制计算机硬件的接口。掌握汇编语言不仅能让你编写出更高效的代码,还能帮助你理解高级语言在底层的实现方式,从而提升你的编程能力和效率。
大纲
- x86-64 ISA 技术
- 浮点数和矢量硬件
- 计算机架构总览
背景知识
汇编语言是复杂的,你不需要记住所有体系结构手册内容。以下是一些期望:
- 理解编译器如何使用x86指令实现C语言构造(第5讲)。
- 能够在阅读架构手册的帮助下熟练阅读x86汇编语言。
- 理解常见汇编模式对高级性能的影响。
- 能够对编译器生成的x86汇编语言进行简单修改。
- 掌握编译器内置函数,使用C语言中不可直接用的汇编指令。
- 知道如何在需要时从头开始编写自己的汇编代码。
- 小米雷总在他大学毕业工作时候主要就是用汇编语言的,不要想的怎么糟糕,当然高级语言用起来相当容易,但是汇编不会很难。
从源代码到执行
// fib.c
#include <inttypes.h>
int64_t fib(int64_t n) {
if (n<2) return n;
return (fib(n-1) + fib(n-2));
}
int main() {
fib(1000);
return 0;
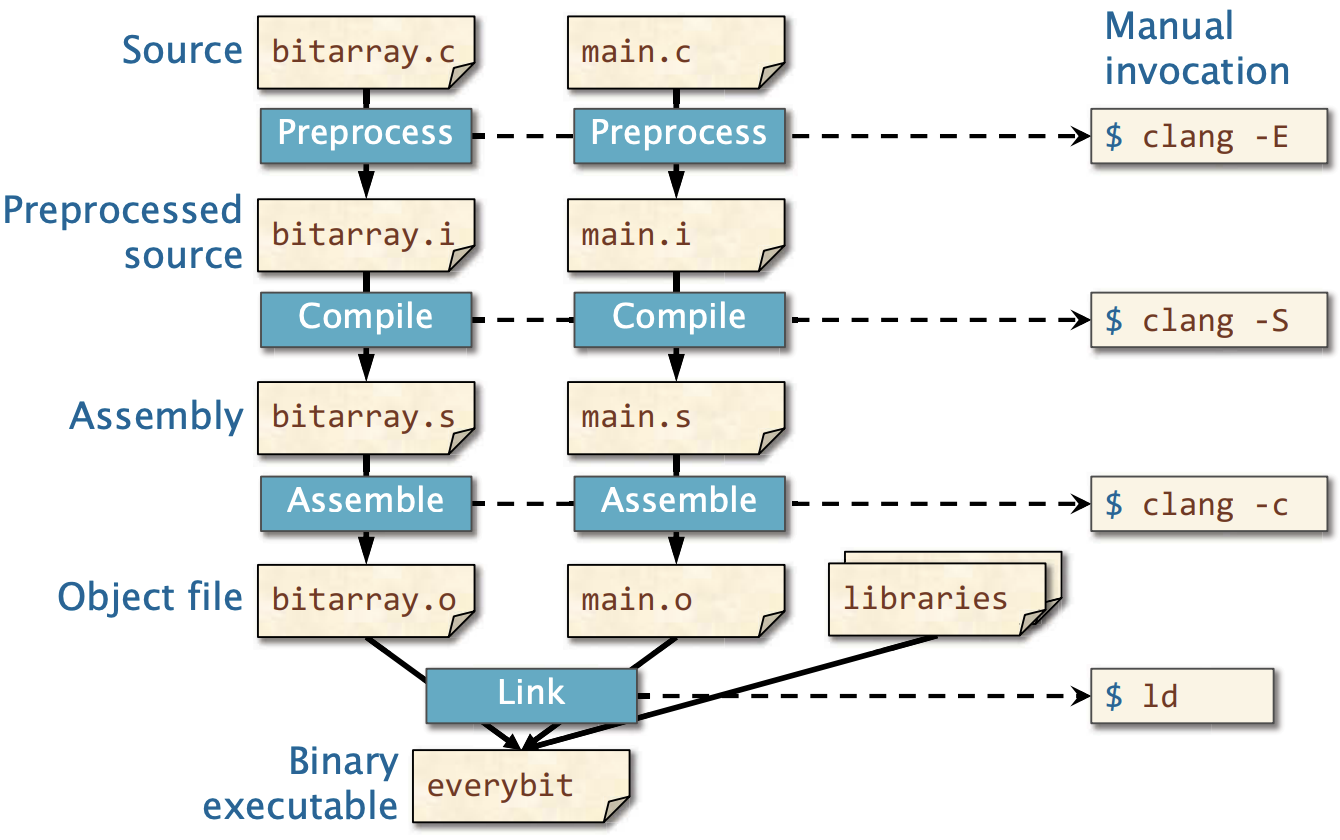
}从源程序到可执行文件经历了4个阶段,通过clang fib.c -o fib可生成可执行文件。但是我们也可以通过手动执行每个阶段。
- 预处理(Processing)
- 执行命令为
clang -E fib.c -o fib.i,由预处理器处理,产生预处理文件
- 执行命令为
- 编译(Compiling)
- 执行命令为
clang -S fib.i -o fib.s,由编译器处理,产生汇编代码文件
- 执行命令为
- 汇编(Assembling)
- 执行命令为
clang -c fib.s -o fib.o,由汇编器处理,产生目标文件 - GNU的汇编器,称为as, 执行命令为
as fib.s -o fib.o
- 执行命令为
- 链接(Linking)
- 执行命令为
ld fib.o -o fib -lc -dynamic-linker /lib64/ld-linux-x86-64.so.2 省略其他,由链接器处理,生成可执行文件
- 执行命令为
如何分析目标文件(.o文件)和可执行文件呢?
对于目标文件我们可以通过objdump -d fib.o来反汇编并查看其中的机器码和相应的汇编指令。 对于可执行文件我们可以通过objdump -S fib来反汇编机器码,查看源代码和对应的汇编代码, 但是这里有个前提,可执行文件在编译器加了-g的选型
汇编语言(assembly language) 提供了机器码的助记符,比机器码更具可读性。
机器码(Machine language)是计算机可以直接执行的指令集代码,它由二进制数(0和1)组成
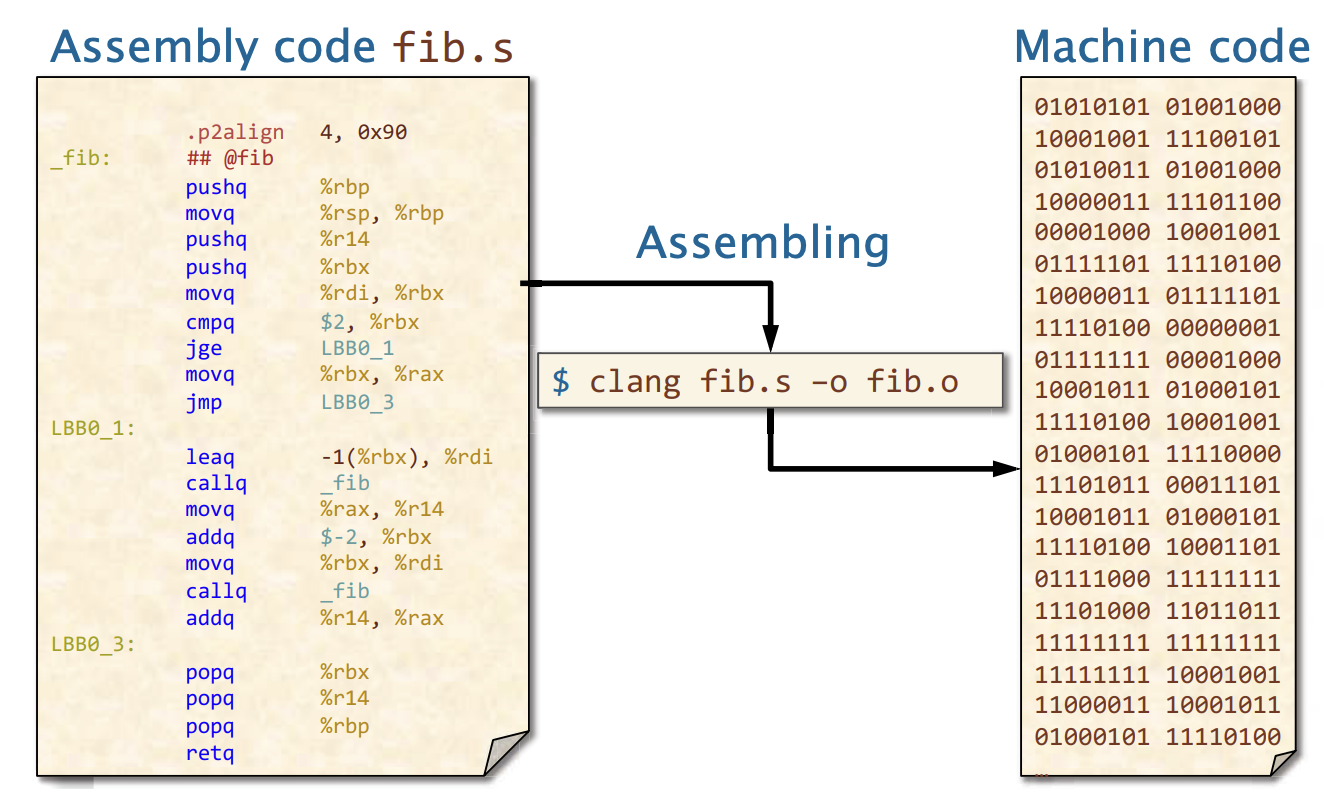
汇编语言和机器码之间关系,虽然不是完全的1对1的关系,但是非常接近。
x86-64 ISA入门
指令集架构(ISA, instruction set architecture)规定了汇编代码的语法和语义。包括
- 寄存器
- 指令
- 数据类型
- 内存寻址方式
x86-64 寄存器
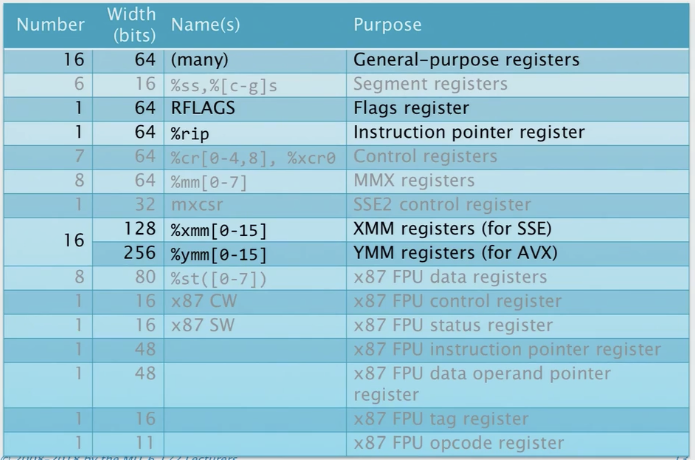
注意: SSE, AVX为向量寄存器。
x86-64 寄存器别称
早期的80-86处理器确立了x86架构的基本特征, 对于8086机器而言的字宽(word)是16位, 字宽(word size)通常指的是寄存器和数据总线的宽度,为16位。
16位字能代表多少种东西呢?如何将这个信息用于机器?
答案: 2^16 = 65536个,意味着我们可以寻址65535个地址或者字节。对于字节寻址,我们可以寻址65K字节的数据,这就是这台机器有多少内存。
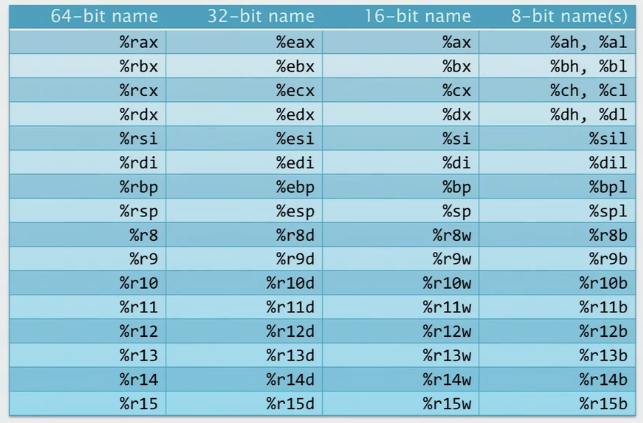
随着摩尔定律的发展,我们有越来越多的内存,字宽必须变得更大才能进行索引了 。在16位到32位, 32位到64位字宽的,他们采用了看起来非常奇怪的做法。就是给通用寄存器取别名,在每次扩展字宽时,Intel保留了旧的寄存器名称,同时引入了新的名称,以便访问寄存器寄存器中重叠的字节部分。

16位到32位:
- 8086(16位):使用的通用寄存器如
AX(16位),其低8位为AL,高8位为AH。 - 80386(32位):引入了32位寄存器,如
EAX,其中EAX的低16位仍然可以通过AX访问
32位到64位:
- x86(32位):使用的通用寄存器如
EAX(32位)。 - x86-64(64位):引入了64位寄存器,如
RAX,其中RAX的低32位可以通过EAX访问,低16位通过AX访问,AX的低8位和高8位分别通过AL和AH访问。
NOTE
在 x86-64 架构中,确实只有 %rax, %rbx, %rcx, 和 %rdx 这四个寄存器有专门用于访问它们的高8位字节(Byte 1)的寄存器名。这些寄存器分别是 %ah, %bh, %ch, 和 %dh。其余的通用寄存器如 %rsi, %rdi, %rbp 等则没有对应的高字节寄存器名
如果当下设计一套ISA的话,你不会采用别名的方法,这就是历史遗留问题,没有长期设计到值。 则不是设计。
x86-64 通用寄存器
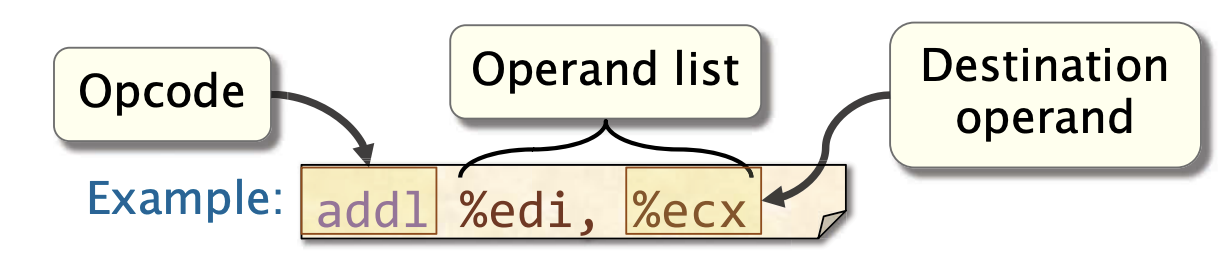
x86-64指令格式
格式: <操作码> <操作数_列表>
- 操作码是, 一个短的助记符,用于标识指令的类型。
- 操作列表,是 0、1、2 或(很少见的)3 个操作数,用逗号分隔
- 通常,所有操作数都是源操作数,其中一个操作数可能也是目标操作数
AT&T vs. Intel 语法
"<op> A B" 意味着什么?

主要差别在于,AT&T 会将最后一个操作数视为目标操作数,而Intel 则是将第一个操作数视为目标操作数。 除了Intel以外,大部分工具都会采用AT&T的语法。会有很搞笑的情况,当我们用Intel手册时候,可能会是AT&T的语法,不要见怪。
通用的x86-64的操作码
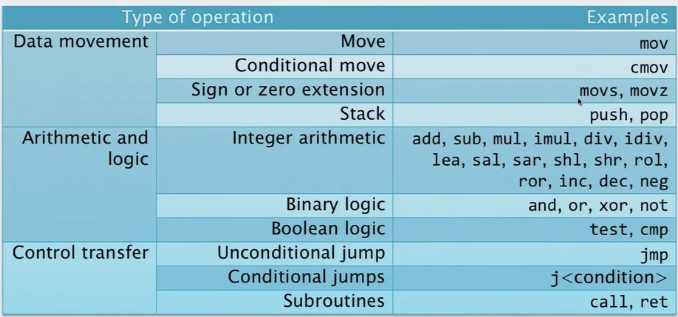
移位操作可以扩展数值,具体方式有两种:零填充或符号扩展。零填充是将空出的位用0填充,而符号扩展是将最左边的1位(最高位)的值复制到空出的高位位置。这种符号扩展确保了负数在移位操作后仍然保持其符号特性。
操作码后缀
操作码(Opcode)可能会带有一个后缀,描述操作的数据类型或条件码。
- 数据移动、算术或逻辑操作的操作码可使用单字符后缀来指示数据类型
- 如果没有后缀,通常可以从操作数寄存器的大小推断出来

x86-64 数据类型
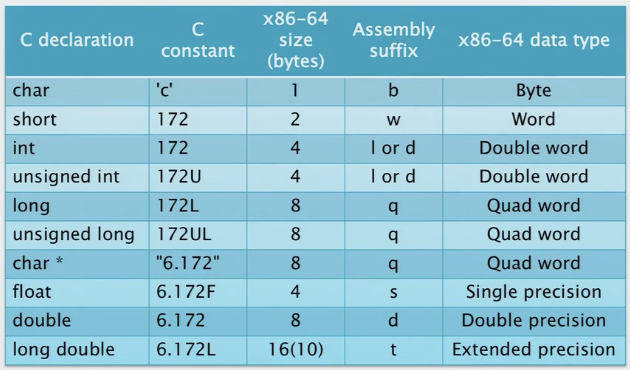
操作码的符号扩展后缀
符号扩展或者零扩展操作码使用两种数据类型后缀
movzbl %al, %edx ; 我们将用零扩展移位,第一个操作数是一个字节,第二个是long类型
movslq %eax, %rdx ; 我们将用符号扩展移位, 第一个操作数是32位,第二个是64位IMPORTANT
要小心! 32位的操作的结果会隐式用零扩展到64的值,不像8位和16位到结果。
条件操作
条件跳转和条件移动指令使用一个或两个字符的后缀来表示条件码。在x86汇编语言中,条件跳转指令如 JE(Jump if Equal)和 JNE(Jump if Not Equal)中的 E 和 NE 就是条件码后缀,分别表示“等于”和“不等于”的条件。同样,条件移动指令如 CMOVZ(Conditional Move if Zero)和 CMOVNZ(Conditional Move if Not Zero)中的 Z 和 NZ 也是条件码后缀,表示“为零”和“非零”的条件。
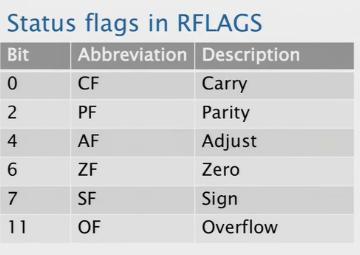
标志寄存器
算术和逻辑操作会更新RFLAGS寄存器的状态标志。
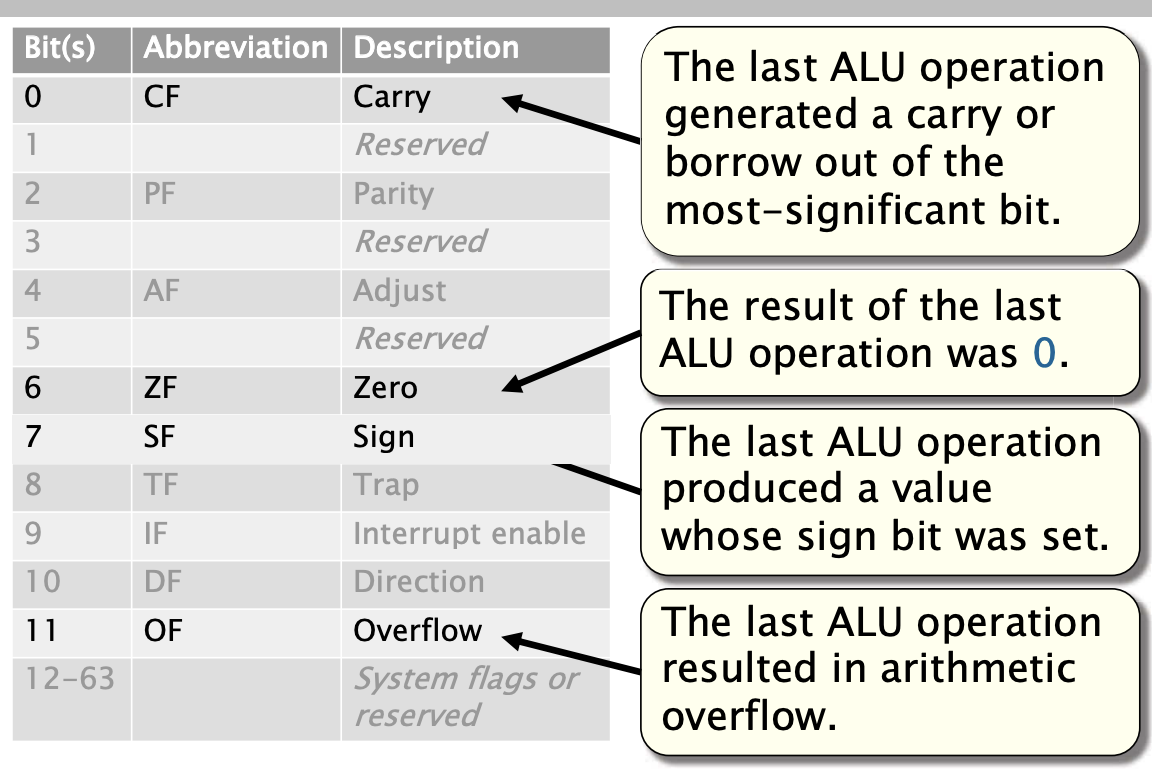
条件码
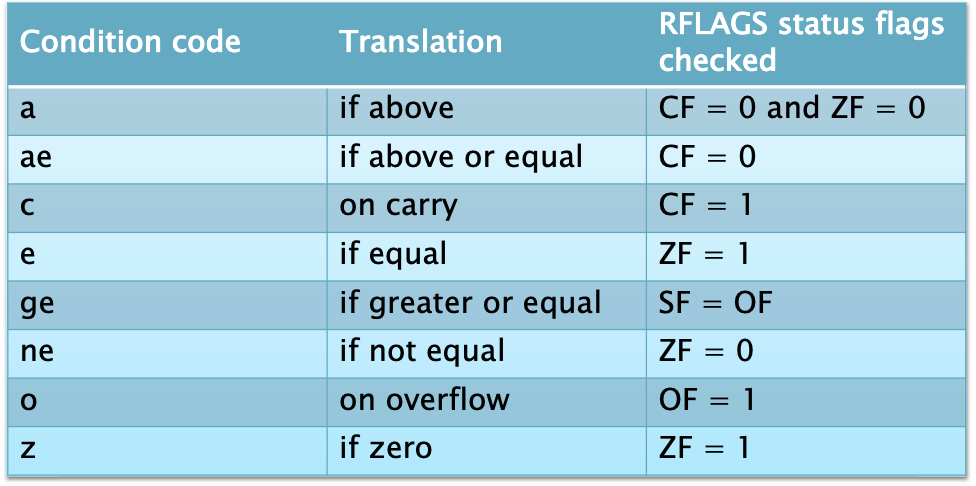
为什么条件码
e和ne需要检查零标志?
因为硬件通常使用减法来比较整数操作数大小。虽然分支操作通常是与比较指令分开的,但实际上并不总是需要专门的比较指令。分支可以基于上一次算术操作的结果,而不仅仅是通过比较指令来设置标志位。如果上一次的算术操作结果为零,零标志(ZF)会被设置,那么程序可以直接使用条件跳转指令来根据这个标志位进行跳转,而不需要额外的比较指令。
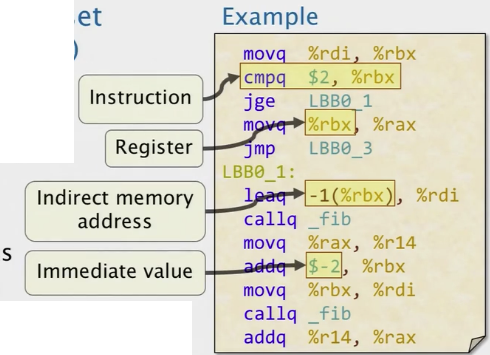
x86-64 直接寻址方式
指令的操作数使用多种寻址模式来指定值,最多一个操作数可以指定地址。
直接寻址模式
- 立即数(immediate): 使用指定的值
- 寄存器:使用指定寄存器中的值
- 直接内存(Direct memory): 使用指定内存地址中的值
- 例子:
move $172, %rdi,movq %rcx, %rdi,movq 0x172, %rdi
间接寻址模式:通过某种计算来指定内存地址。
- 寄存器间接:地址存储在指定的寄存器中。
- 寄存器索引:地址是指定寄存器中的值加上一个常量偏移量。
- 指令指针相对:地址相对于指令指针(%rip)进行索引。
- 例子
movq (%rax), %rdi,movq 172(%rax), %rdi,movq 172(%rip), %rdi
基址-索引-比例-位移 x86-64 支持的最通用的间接寻址模式是基址-索引-比例-位移模式。该模式指的是地址
Base + Index*Scale + Displacement。 如果未指定,索引和位移默认值为 0,比例默认值为 1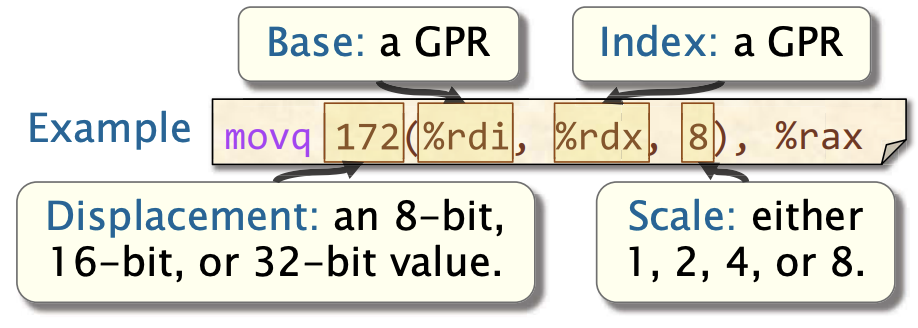
如果未命中缓存,需要从内存取回(fetch)该值,需要几个机器周期
数百个
跳转指令
x86-64 的跳转指令 (jmp 和 j<condition>),以标签作为操作数,这些标签标识代码中的某个位置。
- 标签可以是符号、确切地址或相对地址。
- 间接跳转 使用间接地址作为操作数,指令会跳转到由该地址指示的位置。
jmp *%eax
- 直接跳转 使用明确的标签作为操作数,指令会跳转到标签指示的代码位置
jmp my_label
汇编惯用法
惯用法1: XOR操作码, xor A, B 按位异或。
xor %rax, %rax ; 这个汇编会做什么
将寄存器 %rax 中的内容设置为0
惯用法2: test操作码, test A, B 计算 A 和 B 的按位与(AND),然后丢弃结果,但保留 RFLAGS 寄存器的状态。
test %rcx, %rcx
je 400c0a <mm+0xda>
test %rax, %rax
cmovne %rax, %r8
; 上述两个汇编想做什么
A: 检查寄存器是否位0
惯用法3: 无操作(no-op)指令,包括 nop、nop A(带参数的无操作指令)和 data16。它执行时对处理器状态和内存没有任何影响。主要是为了优化指令内存(例如,代码大小,对齐)
data16 data16 data16 now %cs:0x0(%rax, %rax, 1)
; 该指令的影响是什么?
没有任何影响。 可能是想从下一个缓存行的开始执行下一条指令
浮点数和向量硬件
浮点数指令集
现代 x86-64 架构通过几种不同的指令集支持标量(非向量)浮点运算。
- SSE 和 AVX 指令集支持单精度和双精度标量浮点运算,即“float”和“double”。
- x87 指令集支持单精度、双精度和扩展精度的标量浮点运算,即“float”、“double”和“long double”。
- SSE 和 AVX 指令集还包括向量指令。
SSE 用于标量浮点运算
编译器更倾向于使用 SSE 指令而不是 x87 指令,因为 SSE 指令更容易编译和优化。
- SSE 操作码在处理浮点值时类似于 x86_64 操作码
- SSE 操作数使用 XMM 寄存器和浮点类型

SSE操作码后缀
SSE指令使用了两字母后缀来编码数据类型

s: single ; p: packed(i.e., vector)
s: single-precision 单精度;d: double-precision双精度
矢量硬件
现代微处理器通常包含矢量硬件,以单指令流、多数据流(SIMD)的方式处理数据。
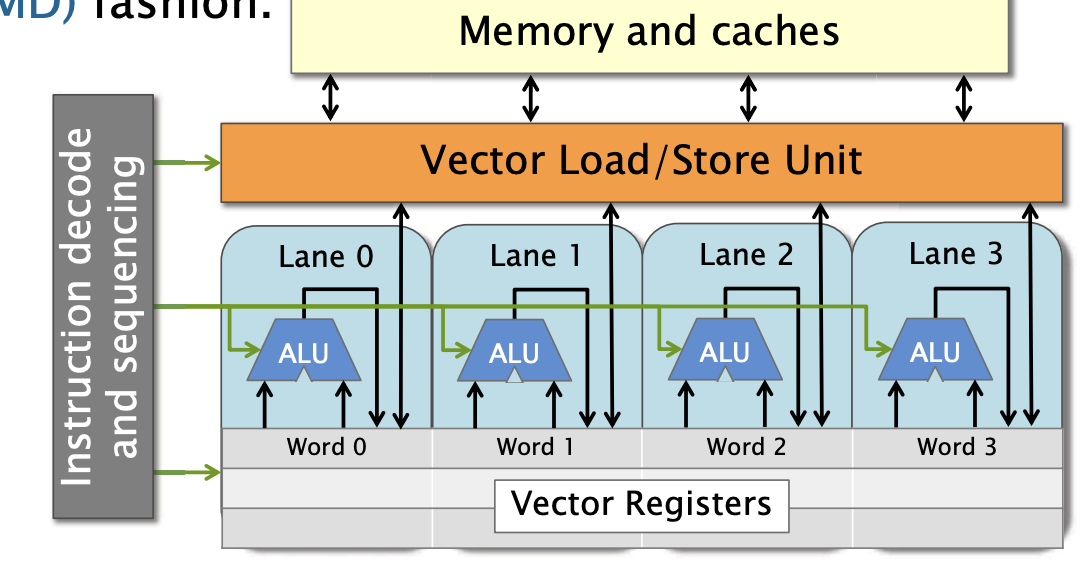
一次指令执行中处理多个数据元素(vector unit)
令k为向量宽度
- 每个矢量寄存器可以存储k个标量整数或浮点值
- 矢量处理单元包含 kkk 个矢量通道(vector lanes),每个通道都有处理标量整数或浮点运算的硬件
每个向量单元我们称其为车道(lane), 当一条指令给到所有的向量单元时,他们都会在自己的本地寄存器副本上进行操作, 你可以认为寄存器是一个非常宽且被分割成几个字(word),当我说把两个向量相加时,他们会把4个字加在一起并存储回去。
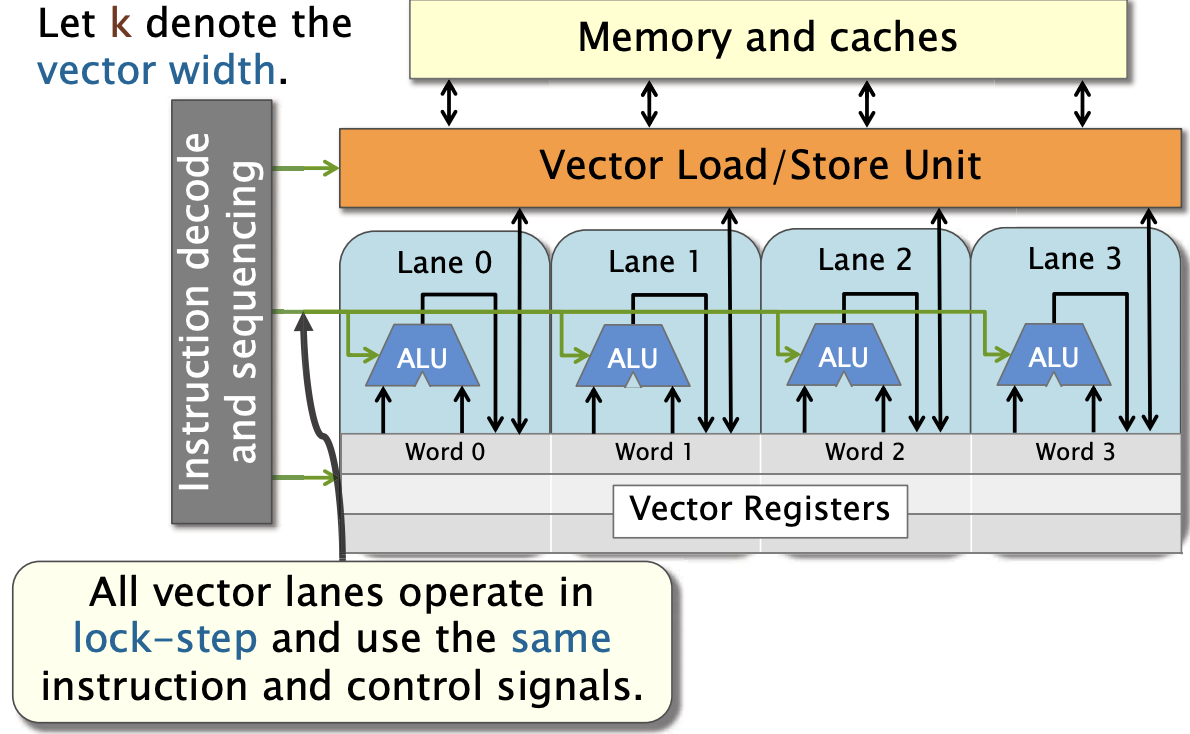
所有的矢量通道(vector lanes)以锁步(lock-step)的方式运行,并使用相同的指令和控制信号。这意味着每个矢量通道在每个时钟周期都执行相同的操作,但作用于不同的数据元素,矢量操作的高效性和一致性。
矢量指令
矢量指令通常以逐个元素的方式进行操作
- 每个矢量寄存器的第i个元素只能与其他矢量寄存器的第i个元素一起操作
- 所有的车道执行完全相同的操作
- 根据架构不同,矢量内存操作数可能需要对齐,意味着他们的地址必须是矢量宽度的倍数
- 一些架构支持跨通道操作,例如插入或提取矢量元素的子集、置换(也称为重新排列)矢量、散射(scatter)或聚集(gather)操作
很多SSE和AVX的操作码跟x86-64的操作码很相似

上面是用于添加64位数值的操作码
- 前缀p代表是integer vector instruction
- 前缀v代表是AVX/AVX2的指令
矢量指令集
在现代 x86-64 架构中,支持多种矢量指令集。
SSE(Streaming SIMD Extensions)指令集:支持整数、单精度和双精度浮点数的向量操作。
AVX(Advanced Vector Extensions)指令集:支持单精度和双精度浮点数的向量操作。
AVX2 指令集:在 AVX 的基础上增加了整数向量操作。
AVX-512(AVX3)指令集:将寄存器长度增加到 512 位,并提供新的矢量操作,包括 popcount(一种计算位中置位数的操作)。不适用于 Haswell 架构。
**SSE vs. AVX 和 AVX2 **
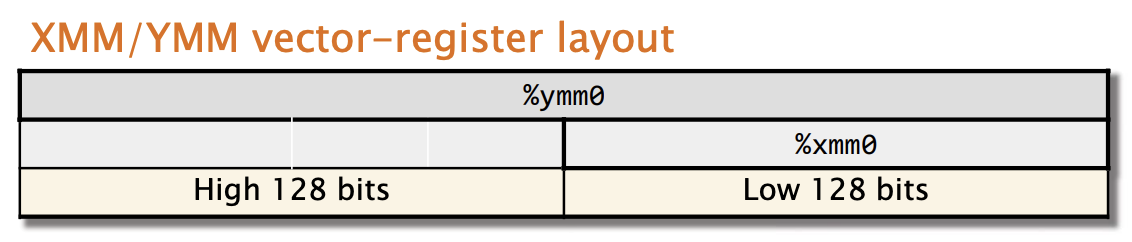
SSE 指令集使用 128 位的 XMM 矢量寄存器,一次最多操作两个操作数。
AVX 指令可以选择使用 256 位的 YMM 矢量寄存器,并且可以同时操作三个操作数:两个源操作数和一个独立的目标操作数。
vaddpd %ymm0, %ymm1, %ymm2; AVX的指令例子指令寄存器别称
计算机架构总览
背景
这里涉及到计算机组成原理的部分,并不是我们的重点。之所以提这个内容,是想弥合差距。 实现从简单的5级流水线处理器与现代处理器核心的跨越,用到了一些设计特性。
- 矢量硬件
- 超标量处理器
- 乱序执行
- 分支预测等
简单5阶段处理器
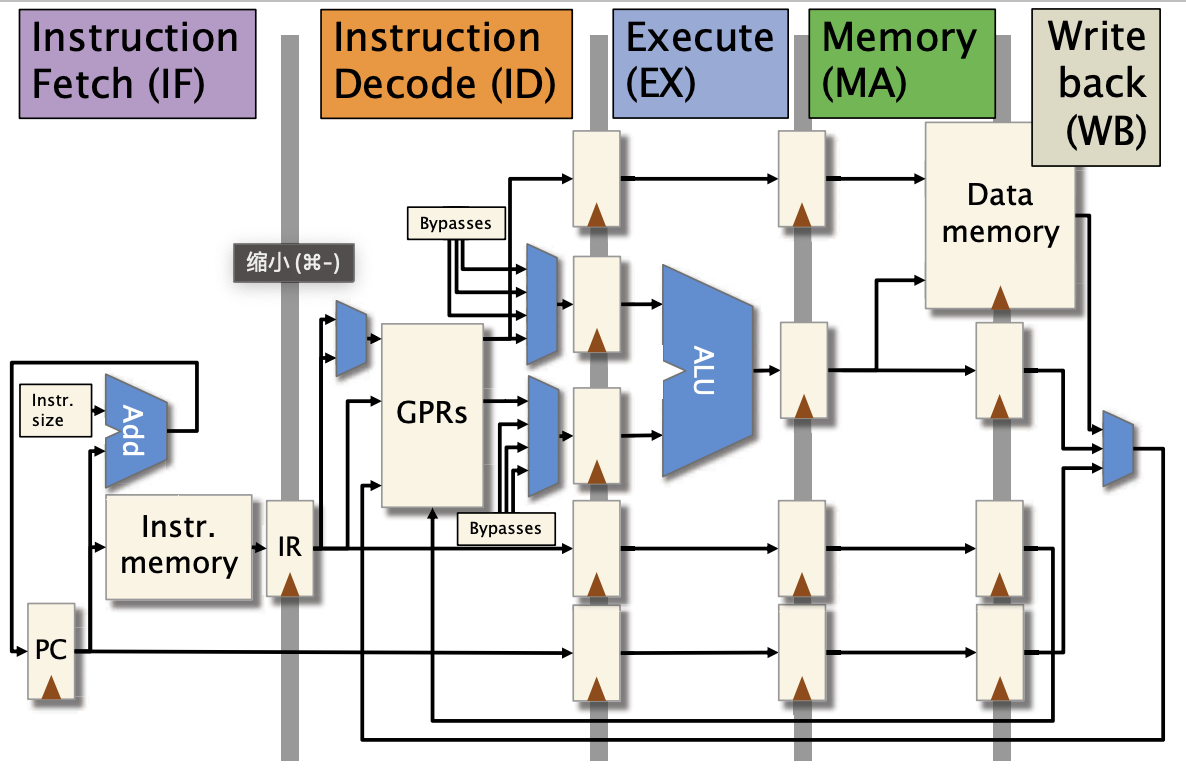
用块状图表示5阶段处理器
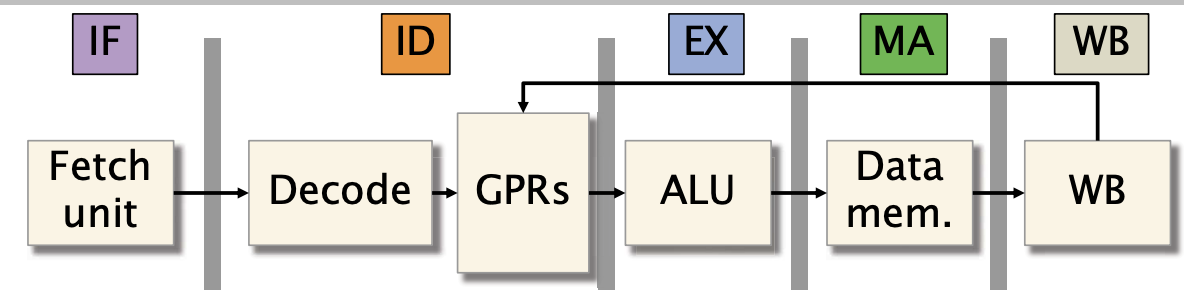
- 指令获取(IF):从内存中读取指令。
- 指令解码(ID):确定使用哪些单元来执行指令,并提取寄存器参数。
- 执行(EX):执行算术逻辑单元(ALU)操作。
- 存储器访问(MA):读取或写入数据到内存。
- 写回(WB):将结果存储回寄存器。
Intel Haswell 微架构
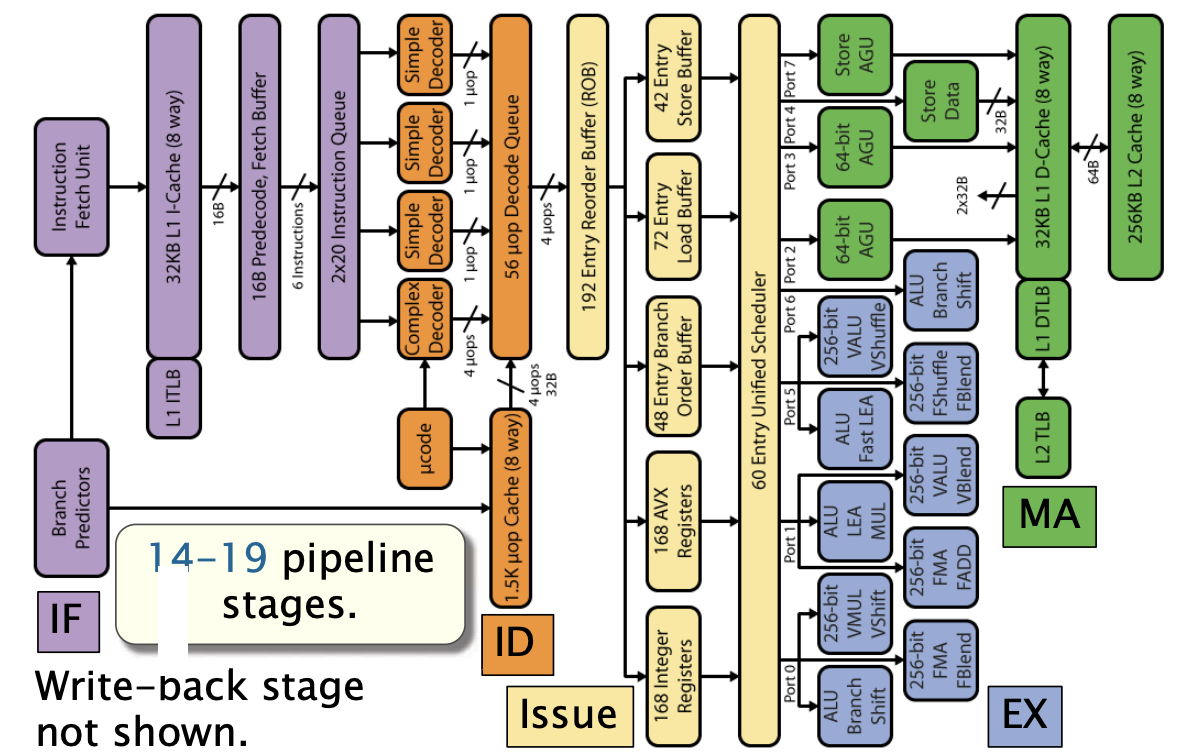
架构提升
从历史上看,为了提升处理器性能,计算机架构有两种方向:
- 利用并行性同时执行多条指令
- 指令级并行(Instructioin-level parallelism, ILP)、向量化、多核处理
- 利用局部性最小化数据移动
- 比如缓存
超标量处理
流水线指令执行
处理器硬件通过寻找机会在不同的流水线阶段同时执行多条指令来利用指令级并行性。理想状态下的流水线执行
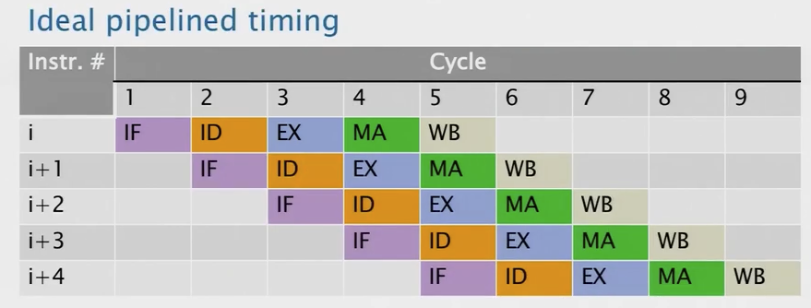
实际中的流水线执行
在实际操作中,各种问题可能会阻止一条指令在其指定的周期内执行,导致处理器流水线停顿(stall)。
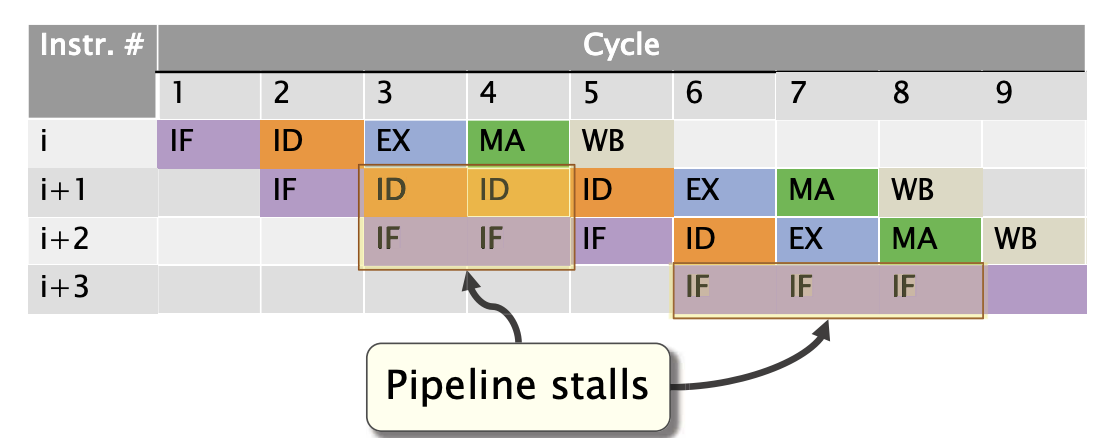
流水线停顿的来源
有三种类型的风险(Hazards)可能会阻止指令在其指定的时钟周期内执行:
- 结构性冒险:两条指令尝试在同一时间使用相同的功能单元。
- 数据冒险:一条指令依赖于流水线中前一条指令的结果。
- 控制冒险:由于控制流(例如条件跳转)的决策,获取和解码下一条指令的过程被延迟。
数据冒险
指令 i和稍后的指令 j 之间由于存在依赖关系,可能会产生数据风险:
真实依赖(RAW):指令 i 写入一个位置,而指令 j 读取该位置。
- asm
addq %rbx, %rax subq %rax, %rcx
反依赖(WAR):如果指令 i 需要读取一个值,然后指令 j 再写入这个位置,i 必须在 j 写入之前完成。
- asm
addq %rbx, %rax subq %rcx, %rbx
输出依赖(WAW):指令 i 和指令 j 都写入同一个位置。
示例:如果指令 i 和 j 都试图写入同一个寄存器,处理器必须确保这些写操作按正确顺序完成,以避免数据冲突
- asm
movq 0x0, %rax movq 0x1, %rax
复杂操作
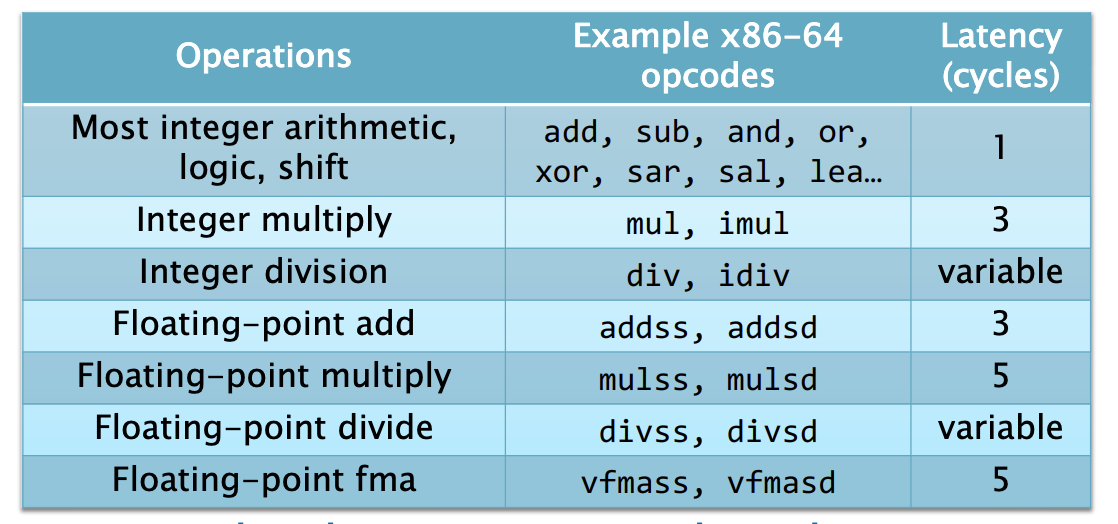 一些算数操作在硬件实现上很复杂,并且有很长的延迟。硬件如何完成上面的操作的呢?
一些算数操作在硬件实现上很复杂,并且有很长的延迟。硬件如何完成上面的操作的呢?
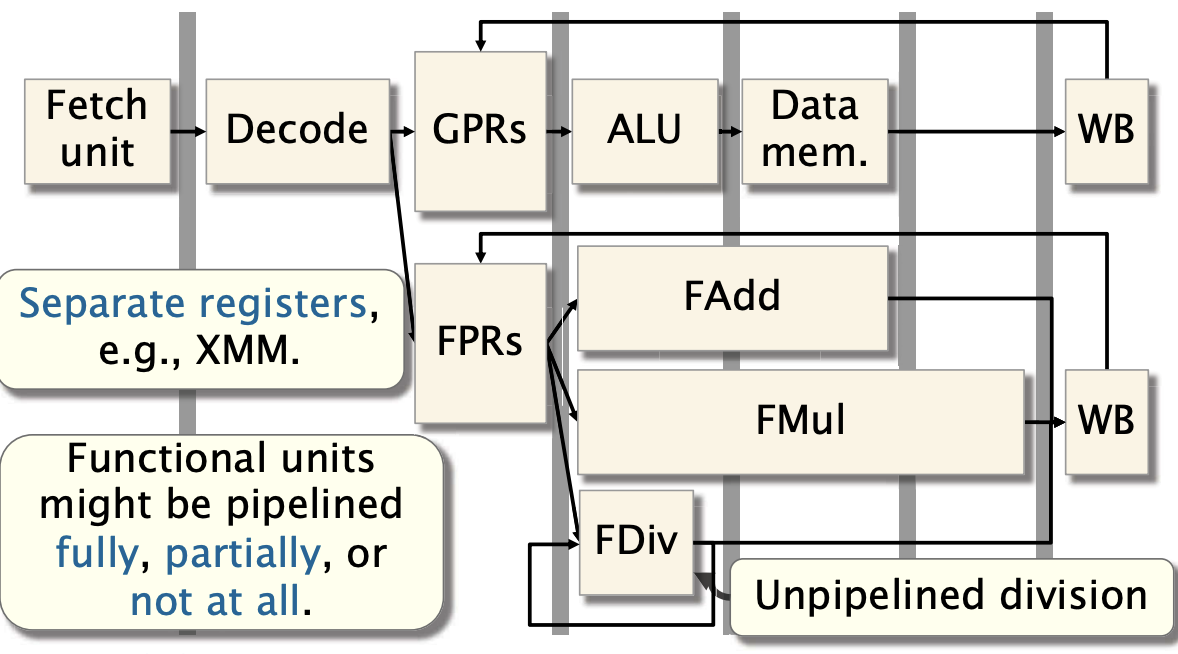
方法:用使用独立的功能单元来完成复杂操作。比如浮点计算,他们有单独的寄存器,XMM,或者用浮点运算单元(FPU)专门处理浮点数的加减乘除。将这些操作分配给专门的功能单元,可以避免它们与其他简单操作竞争资源,从而减少流水线停顿。这些功能单元可能被完全、部分流水线化,或者完全不用。
在已经给定了额外的功能单元,处理器如何更好的利用ILP呢?
办法: 在一个机器周期内,取出并发射多个指令来提升功能单元的利用。
这就是超标量(Superscalar)
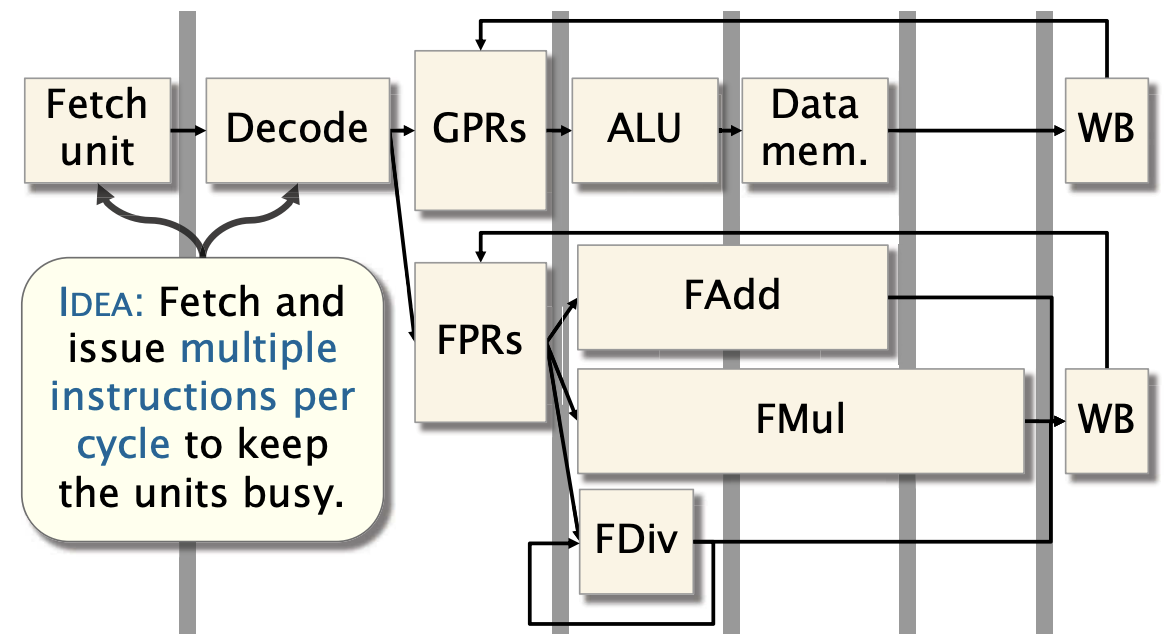
Intel Haswell的取指和解码
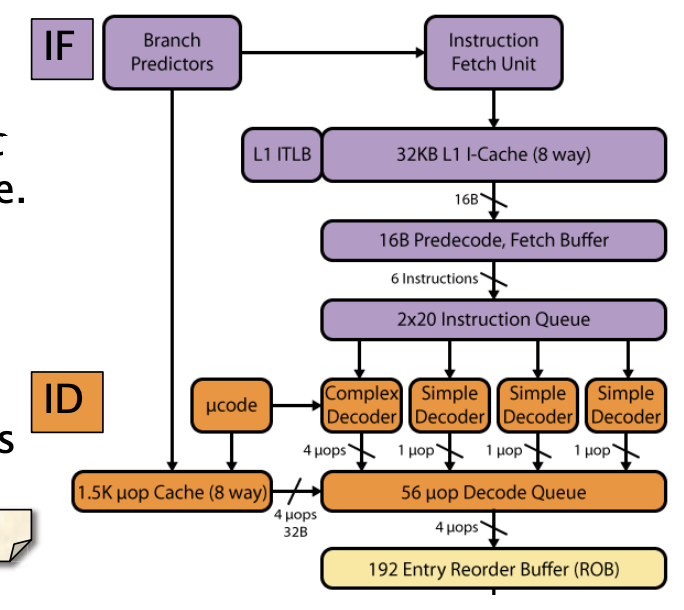
x86-64 指令集复杂且多样,为了提高处理效率,Haswell 处理器将这些复杂的指令分解为更简单的操作,称为微操作(micro-ops)。
- 每个周期可以发出 4 个微操作:在处理器的取指和解码阶段,每个时钟周期可以向流水线的其余部分发送多达 4 个微操作
- Haswell 处理器在取指和解码阶段对微操作的处理进行了多种优化。这包括针对常见模式的特殊处理
乱序执行
超标量流水块状图
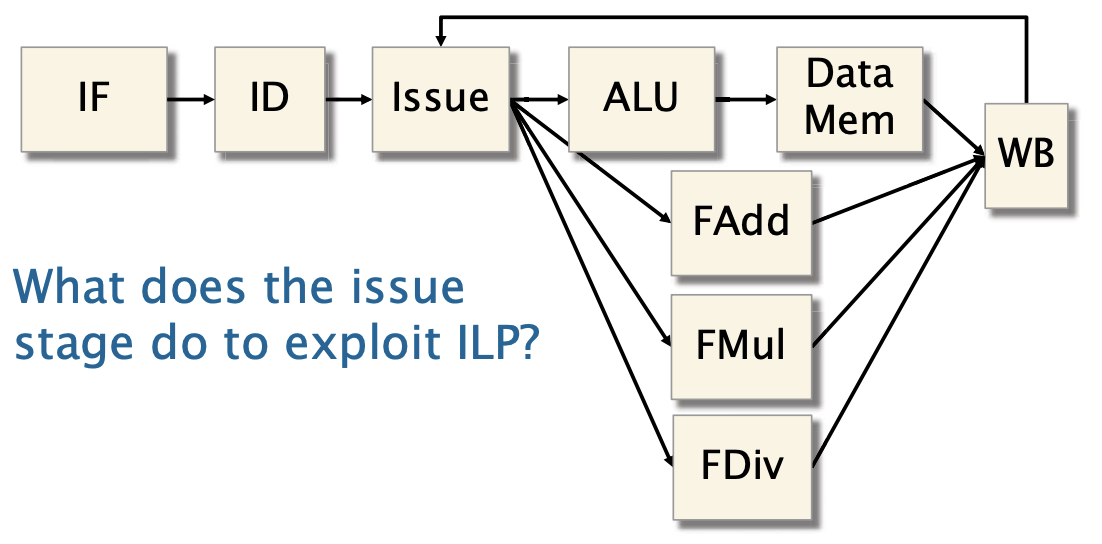
流水线中的发射阶段管理功能单元并处理指令调度。 为了利用ILP,在发射阶段做了什么?
旁路技术允许一条指令在其参数被存储到通用寄存器(GPR)之前读取这些参数。
例子:
addq %rbx, %rax
subq %rax, %rcx没有旁路技术情况

在cycle5 to 6之间,会发生停顿,为了等待%rax写到一个寄存器内。
使用旁路技术情况
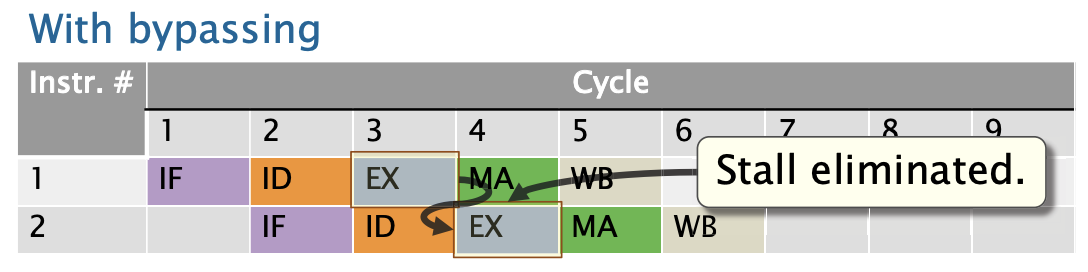
硬件还可以利用ILP做什么呢?
我们来看下面的代码
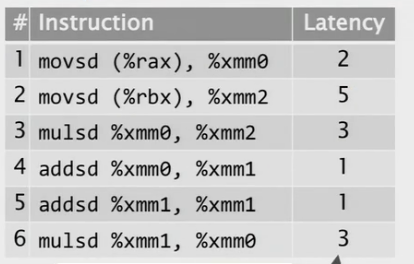
我们发现这里存在真实依赖,
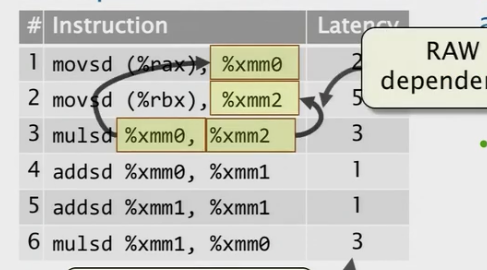
反依赖

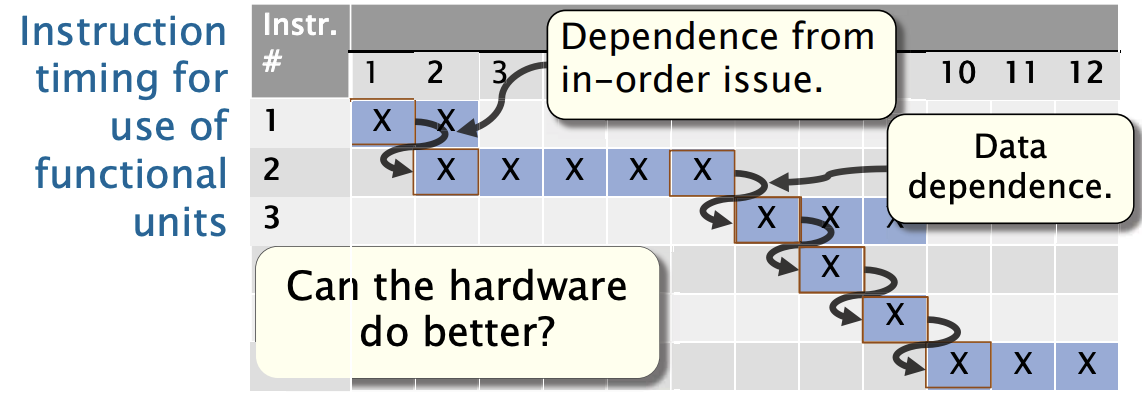
如果硬件必须按顺序发布所有指令,执行需要多长时间?
有序发射
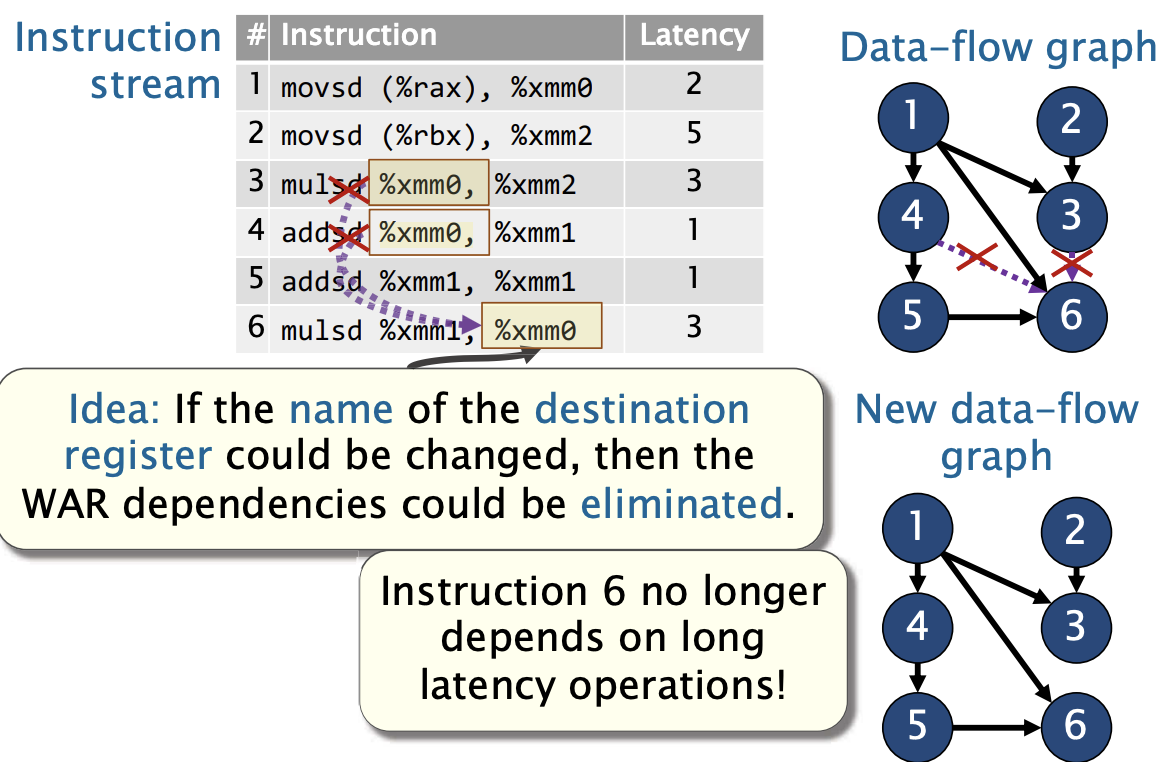
数据流图
我们可以将数据依赖建模称数据流图
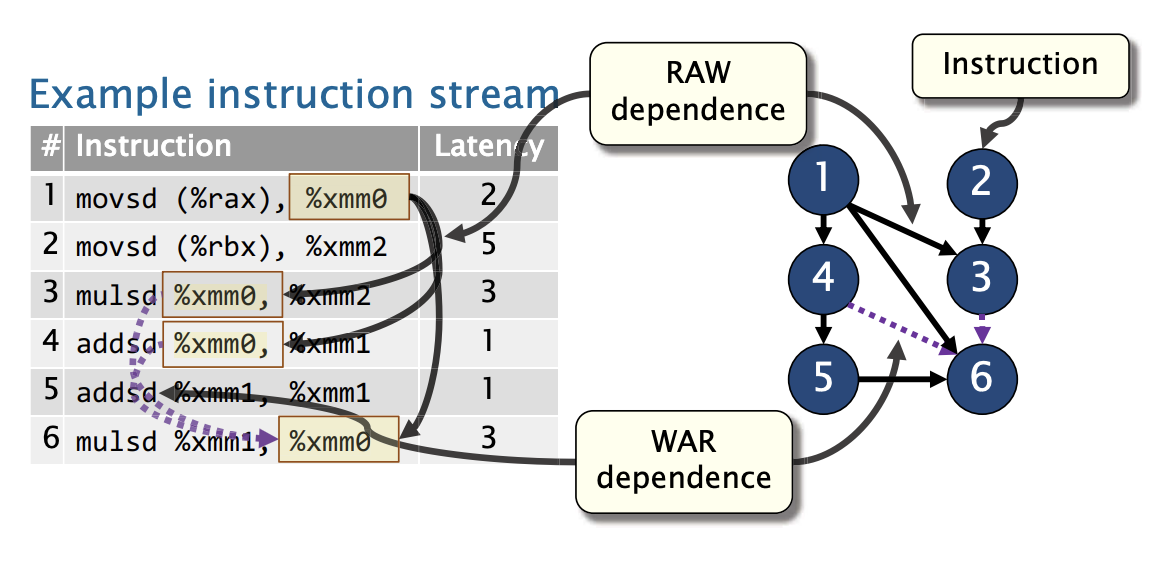
你会发现机器周期1-2, 6-7, 7-8的依赖都是错误的依赖,因为指令4并不依赖指令2,和指令3。
乱序执行
办法: 一旦数据依赖满足了, 就让硬件发生一条指令。
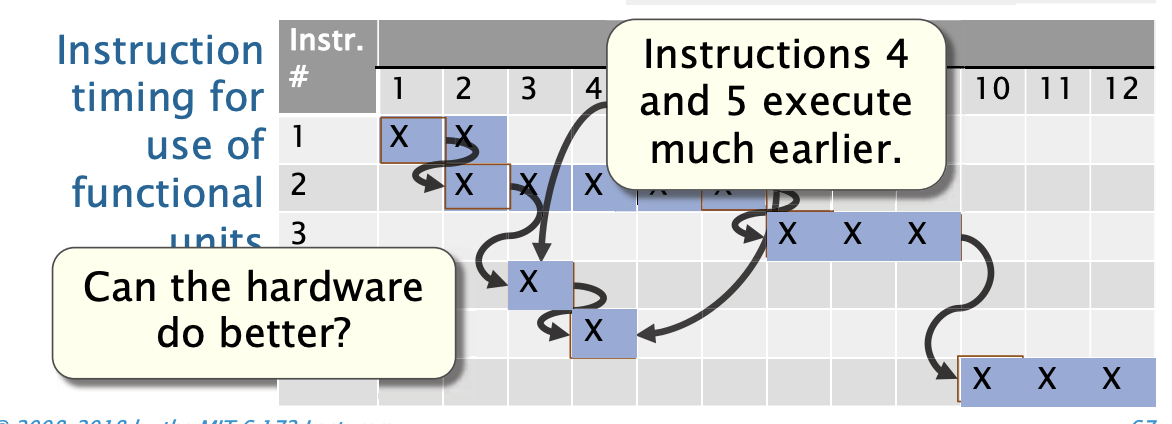
对于WAR, 我们可以通过重命名寄存器。重命名寄存器的主要思想是将逻辑寄存器映射到物理寄存器,以确保每条指令有自己独立的物理寄存器, 从而消除依赖关系