Lec 10 测量和计时
本节探讨如何可靠地测量软件的性能
Outline
- 性能工程基本工作流
- 动态电压和频率调节
- 测量的指标和统计数据
- 测量软件性能的工具
- 静默系统(Quiescing System)
性能工程基本工作流
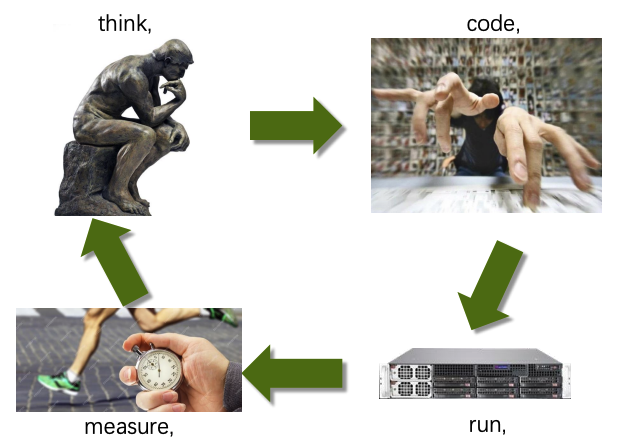
- 测量程序A的性能表现
- 对程序A进行修改,生成预期更快的改进版程序A′
- 测量程序A′的性能表现
- 若A′优于A,则将A更新为A′版本
- 若当前程序A仍未达到性能要求,则跳转至步骤2继续优化
动态电压和频率调节
有个同学写了这样的一个测量排序算法代码
#include <stdio.h>
#include <time.h> // clock_gettime()
void my_sort(double *A, int n);
void fill(double *A, int n); // 填充随机数
struct timespec star, end;
int main() {
int max = 4 * 1000 * 1000;
int min = 1;
int step = 20 * 1000;
double A[max];
struct timespec start, end;
for (int n = min; n < max; n += step) {
fill(A, n);
clock_gettime(CLOCK_MONOTONIC, &start);
my_sort(A, n);
clock_gettime(CLOCK_MONOTONIC, &end);
double tdiff = (end.tv_sec - start.tv_sec) + 1e-9 * (end.tv.nsec - star.tv.nsec);
printf("size %d, time %f\n", n, tdiff);
}
return 0;
}得到的测量结果如下图,其中红绿线表示理论数值,x为实际测量结果
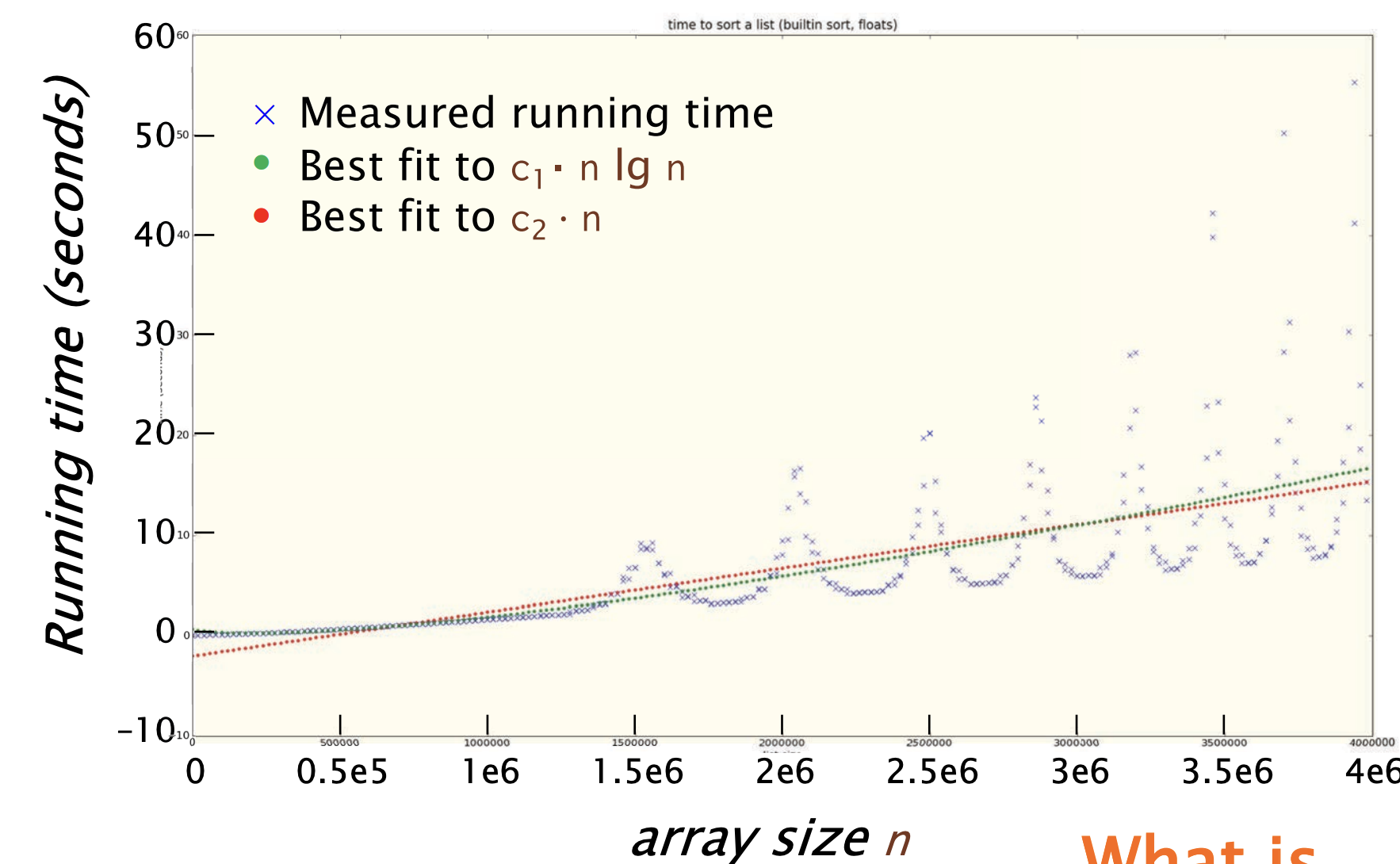
为什么会呈现这样的变化?
Solution: 由于动态电压和频率调节(Dynamic Voltage and Frequency Scaling, DVFS), 这是一种通过调整晶体管的时钟频率和供电电压来降低功耗的技术。如果芯片过热或为了节省电力(尤其是电池电量),可以降低工作频率。如果降低了频率,则可以同时降低电压。
- C = 动态电容 $\approx $ 大致面积 * 活动(芯片中有多少位(bit)在每个时钟周期中切换状态(从 0 切换为 1 或从 1 切换为 0))
- V = 供电电压
- f = 时钟频率,芯片每秒执行的操作次数
降低频率和电压会导致功耗和热量呈立方减少,但它会对性能测量造成严重破坏!
测量指标和统计数据
简单来说,我们首先要知道系统关注哪些点,不同的场景就意味着有不同的统计量,一个论断通过假设检验的方法作为判断依据,有了一个假设后,我们需要测量程序的真实性能。
比较两个程序
你想比较两个程序 A 和 A' 的性能(哪个更快),但你的计算机存在轻微噪声(测量结果可能波动)。你会采取什么策略?
Solution: 进行多次A vs A' 的直接对比测试,并用统计学方法评估结果。考虑假设检验(Null Hypothesis Testing)的方法,默认假设A比A'快(零假设,Null Hypothesis)计算P值,P值越低,越能拒绝零假设(A'确实比A快)。
测量指标 / 统计量
假设你在有一些干扰背景噪音的电脑上对一个确定性程序进行了100次性能测量(统计量是耗时时间)。以下什么统计量最能代表这个软件的原始性能呢?
- 算术平均值
- 几何平均
- 中位数
- 最大值
- 最小值
Solution: 最小值; 最小值反映出在噪音抑制方面做得最好,因为我们期望任何高于最小值的测量都是由噪音引起的
结论: 程序B的性能是A的三倍以上。这个结论对不对?
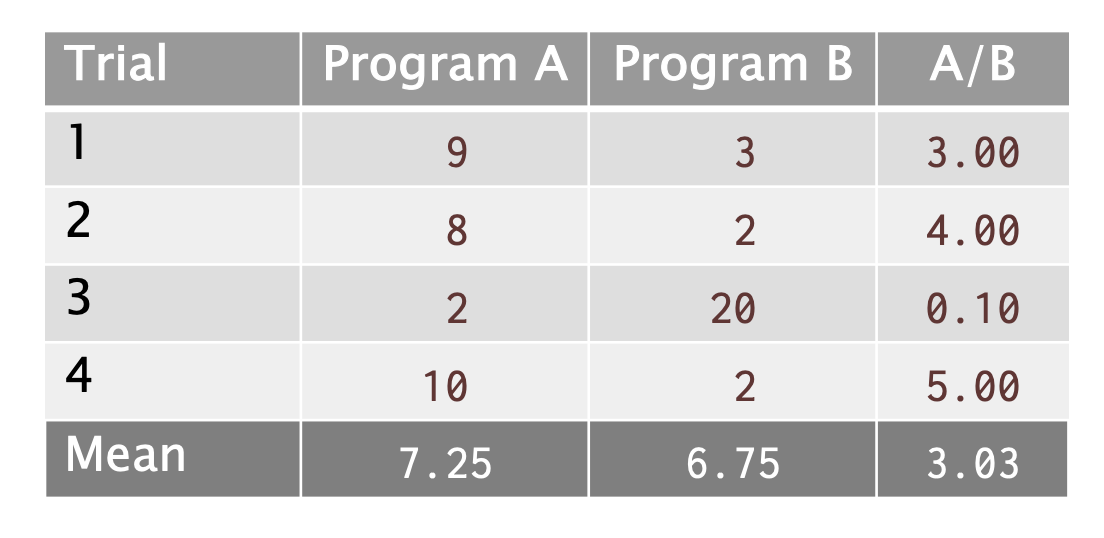
Solution:
❌错! s如果我们看B/A的比率,那么A比B几乎好3倍。观察: A/B的算术平均值并不是B/A算术平均值的倒数。即使A/B和B/A是同样的值互为倒数,但它们的算术平均值却不是倒数关系
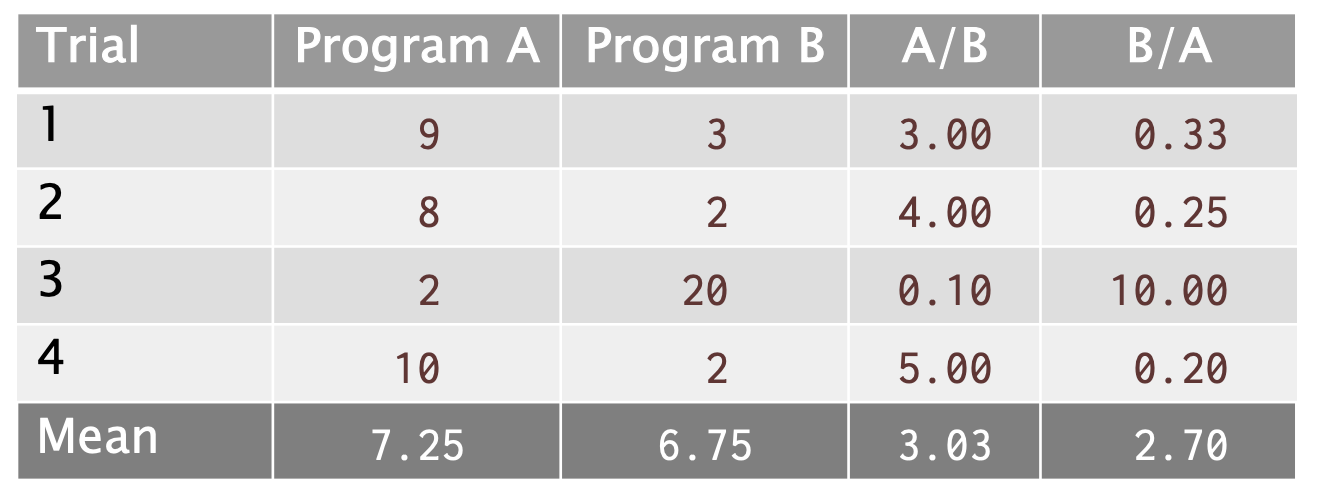
✅正确的方法: 几何平均值
💡观察: 平均值的比率 = 比率的平均值。
其他场景
场景:给定一个服务器,尽可能多地服务请求
- 算术平均值下的CPU利用率
场景: 满足大多数云服务请求在 100ms 内完成
- 用 90 分位数(90th percentile) 或 真实时间(wall-clock time) 来评估尾部延迟表现(tail latency)
场景: 判断AI 玩游戏的表现最好
- 可以使用 算术平均值(如得分) 或 胜率来衡量其能
场景:程序在100MB内存内的机器运行
- 内存使用的峰值
场景:适用于移动设备的高频使用场景
- 算术平均值下的能耗或CPU利用率
场景:最环保的设计目标
- 算术平均值下碳足迹
场景:满足客户服务级别协议(SLA)
- 通常需要多个指标的的加权组合
测量软件性能的工具
用于测量整个程序,比如
/usr/bin/timeperf stat、cachegrind,strace
测量程序的我们关心的一部分,一般会在程序中插入计时函数,比如
gettimeofday(),clock_gettime(),rdtsc()
创建一个程序的profile,比如
- gdb、Poor man‘s Profiler、gprof
- 使用
perf record/report,基于OS和硬件支持的硬件计数器 - 使用采用技术
计时器
/usr/bin/time
time 命令可以测量整个程序的消耗时间(elapsed time)、用户时间和系统时间
$ /usr/bin/time my-program arg1 arg2
real 0m3.502s
user 0m0.023s
sys 0m0.005s- real 时间时程序开始到结束消耗时间(wall-clock time)
- user 时间是处理器专门用于运行用户态代码的时间(在内核之外)
- sys 时间是处理器用于与OS交互的时间,比如系统调用
clock_gettime
#include <time.h>
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
function_to_measure();
clock_gettime(CLOCK_MONOTONIC, &end);
double tdiff = (end.tv_sec - start.tv_sec) + 1e-9*(end.tv_nsec - start.tv_nsec);- 在我的笔记本电脑上,
clock_gettime(CLOCK_MONOTONIC, …)大约耗时 83 纳秒,这比通常的系统调用快了大约两个数量级。 - 可保证时间不会倒退
- 但它并非总是很快运行
rdtsc()
x86 处理器在硬件中提供了一个时间戳计数器(TSC)
// 对于老的编译器
static __inline__ unsigned long long rdtsc(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));
return ( ((unsigned long long)lo) | (((unsigned long long)hi)<<32));
}
// 对于新版编译器
__builtin_readcyclecounter();- 返回的时间是“自boot以来的时钟周期数”。
rdtsc()大约在 32 纳秒内运行完成
TSC的问题
- 不要使用
rdtsc()!rdtsc()在同一台机器上的不同核心可能会给出不同的结果。 - TSC 有时会倒退(时间变得不连续)。
- 计数器的进度可能不是匀速的。
- 将时钟周期转换为秒可能会很复杂。
- 也不要使用
gettimeofday(),因为它有类似的问题!- 能提供微秒级的准确性,提供不了纳秒级的,虽然它写是这样写
中断
IDEA:在 gdb 下运行你的程序,并在随机时间按下 Control-C。
- 每次查看堆栈,确定通常正在执行哪些函数。
- 谁还需要复杂的性能分析器?
- 有些人称这种策略为“穷人的性能分析器”。
pmprof和gprof自动化了这种策略,提供所有函数的性能分析信息。- 如果采样不足,两者都不准确。(
gprof每秒仅采样 100 次。)
硬件计数器
用于监测处理器的低级行为,如缓存命中率、分支预测失误等,不过,硬件计数器非常复杂,理解每个计数器所测量的具体内容可能需要深入了解硬件的工作原理。
libpfm4虚拟化了所有硬件计数器。- 现代内核使得像
libpfm4这样的库可以按进程测量所有提供的硬件事件计数器。 perf stat使用了libpfm4。- 注意:你可能无法同时测量超过 4 或 5 个计数器,否则可能会在性能或准确性上付出代价。
仿真法
- 仿真器,如
cachegrind,通常运行速度比实际时间慢得多。 - 但是它们可以提供准确且可重复的性能数据。
- 如果你想获得特定的统计数据,可以在不干扰仿真的情况下进行收集。
静默系统
Genichi Taguchi的质量管理理念
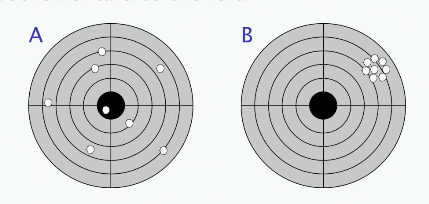
问题:“如果你是一个奥运会手枪教练,你会招募哪位射手加入你的团队?”
答案:“B,因为你只需要教B瞄准得更低一些并往左打。”
这个故事告诉我们: 如果你能减少波动性,你就可以补偿系统性和随机测量误差
波动的来源
- 守护进程和后台作业
- 中断
- 代码和数据对齐
- 如果不完全在一个缓存行,可能会有所不同
- 如果跨页边界,TLB同样
- 线程位置
- 事实表明,OS很喜欢用core0,尽可能不要用core 0
- 运行时调度器
- 超线程技术
- 租户
- DVFS
- Turbo Boost技术
- 网络流量
未静默 vs. 静默系统对比实验
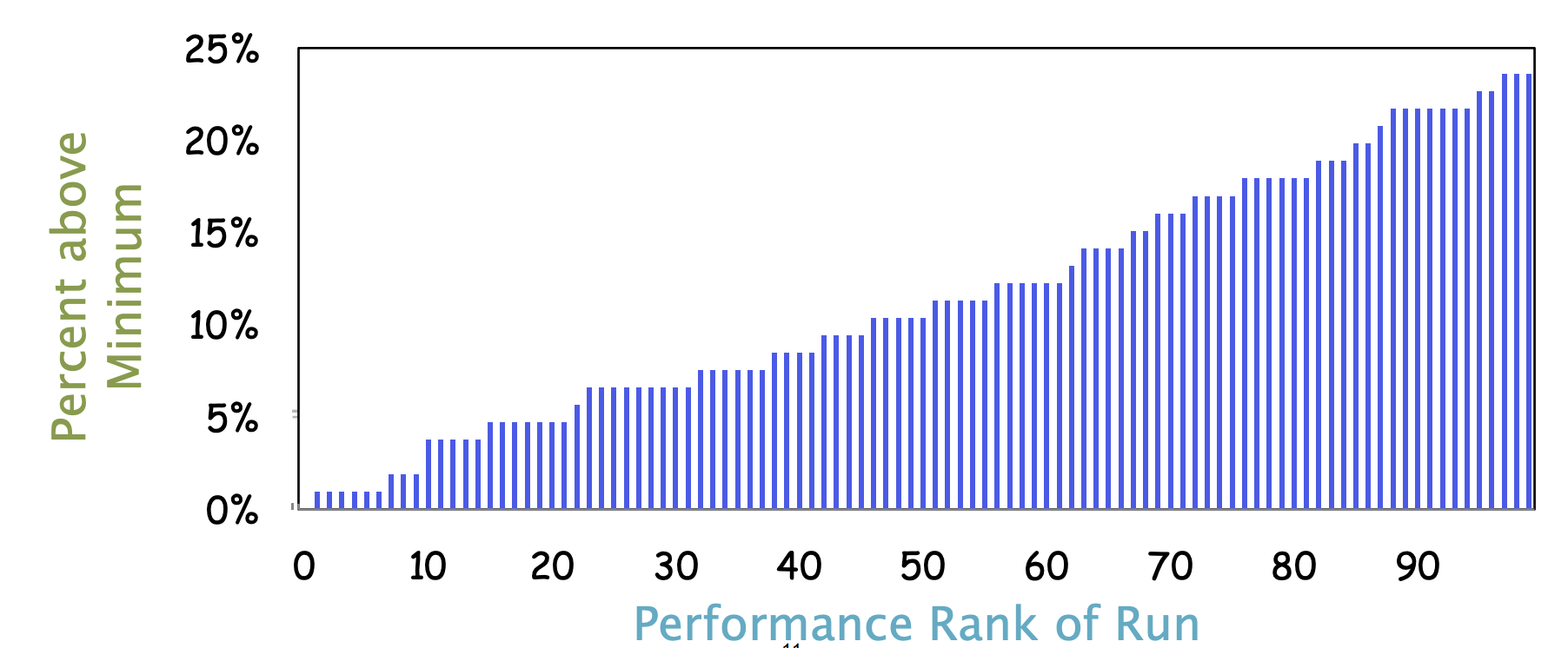
未静默系统实验
AWS c4 实例(18 个核心)
启用 2 路超线程和 Turbo Boost
18 个 Cilk 工作线程
进行了 100 次运行,每次大约 1 秒
图中描述了,每次运行时的百分比
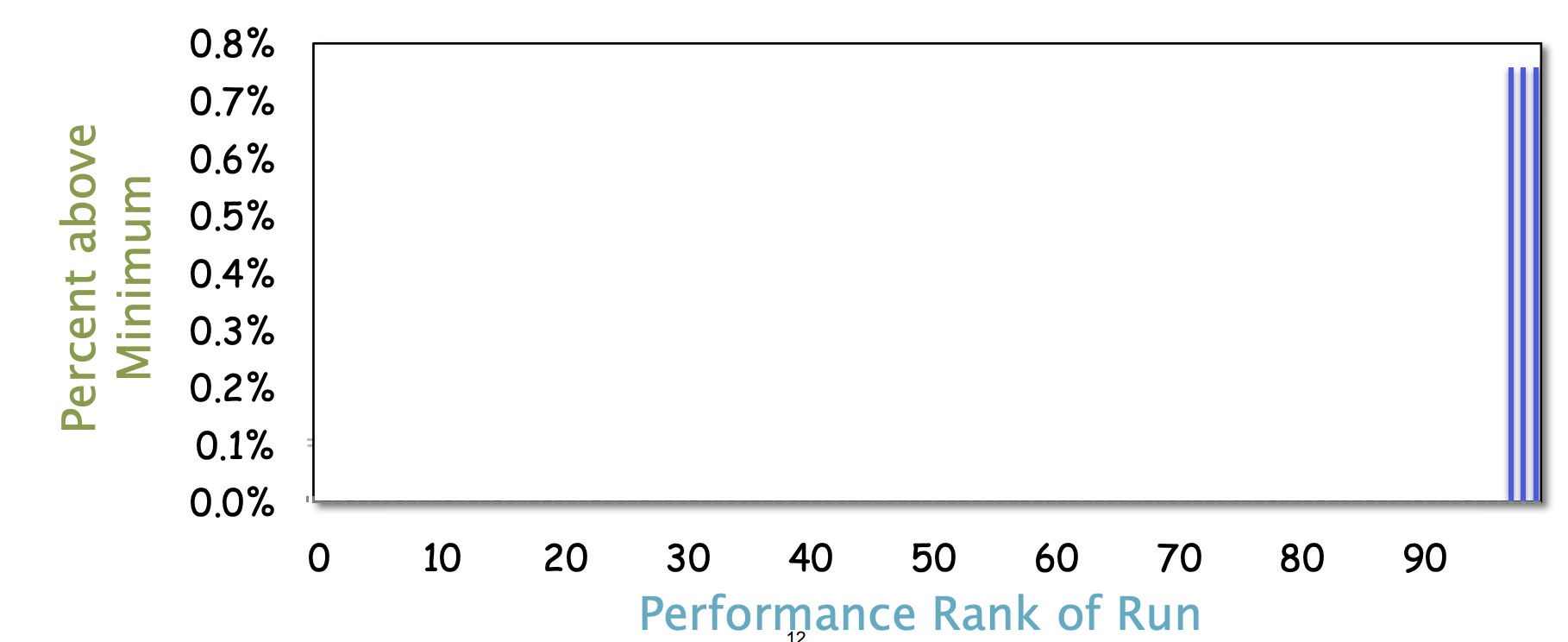
静默系统实验
- 使用 Cilk 程序计算区间内的质数
- AWS c4 实例(18 个核心)
- 关闭 2 路超线程和 Turbo Boost
- 18 个 Cilk 工作线程
- 进行了 100 次运行,每次大约 1 秒
静默系统的方法
- 确保没有其他守护进程和定时任务
- 断开网络连接
- 不要动鼠标
- 对于串行任务,不要在core 0上运行,因为中断程序通常在该核心运行
- 关闭超线程
- 关闭DVFS
- 关闭Turbo Boost
- 使用
taskset将cilk工作线程绑定到特定核心
代码对齐的影响
特别提这点,只是想深入理解下为什么代码对齐会影响到性能.
源代码中某处的一个小改动,可能导致大量生成的机器代码改变位置。性能可能会因为缓存对齐和页面对齐的变化而有所不同。类似地:改变 *.o 文件在链接器命令行中的顺序,可能会对性能产生比从 -O2 到 -O3 优化级别更大的影响。
LLVM通常会对函数进行缓存对齐,但它也提供了几种控制对齐的编译器选项:
-align-all-functions=<uint>强制对所有函数进行对齐。-align-all-blocks=<uint>强制对函数中的所有基本块进行对齐。-align-all-nofallthru-blocks=<uint>强制对所有没有后续跳转的基本块进行对齐(即不在执行路径中添加nop指令)。
对齐的代码更有可能避免性能异常(能得到比较稳定的测量结果),但有时也可能导致速度变慢。
数据对齐
程序的名称可能会影响它的速度!
- [Mytkowicz, Diwan, Hauswirth 和 Sweeney,《Producing wrong data without doing anything obviously wrong》,2009]
- 可执行文件的名称会出现在环境变量中。
- 环境变量最终会被放置在调用栈上。
- 名称的长度会影响栈的对齐方式。
- 当数据访问跨越页面边界时,访问速度会变慢。