Lec 9 可编程机器(ISA 与汇编)
模块一(数字逻辑)让我们能造出固定功能的电路。但通用处理器的魅力在于:同一套硬件能运行 Python/Java/C 等任意高级语言写的程序。本讲建立“可编程机器”的抽象——指令集架构(ISA),并学会用 RISC-V 汇编为它编程。这是 Lec 10 用硬件实现处理器之前必须先搞清楚的“要实现什么”。
Outline
- 通用处理器与机器语言
- 微处理器的组成
- ISA:软硬件契约 & RISC-V
- 寄存器与指令类型
- 算术/逻辑指令、模运算、十六进制
- 控制流:分支与跳转
- 存取指令与数组
- 指令编码限制、大常数、伪指令
- 编译高级语言:表达式 / 条件 / 循环
- 过程调用:调用约定、栈与活动记录
- 内存布局与 MMIO
通用处理器与机器语言
- 我们希望同一套硬件能执行任何高级语言写的程序;
- 但又不可能把每种高级语言的特性都直接做进硬件。
解决办法是引入一个中间层——机器(汇编)语言:高级语言经软件翻译(编译/汇编)变成机器语言,再由微处理器直接硬件执行。机器码就是软硬件之间的接口契约。
| 高级语言 | 汇编/机器语言 |
|---|---|
| 复杂算术/逻辑运算 | 原始(primitive)算术/逻辑运算 |
| 复杂数据类型与结构 | 原始数据:位与整数 |
| 复杂控制结构(if/loop/过程) | 控制转移指令 |
| 不适合直接用硬件实现 | 专为可直接硬件实现而设计 |
代价是:汇编编程很繁琐。
微处理器的组成
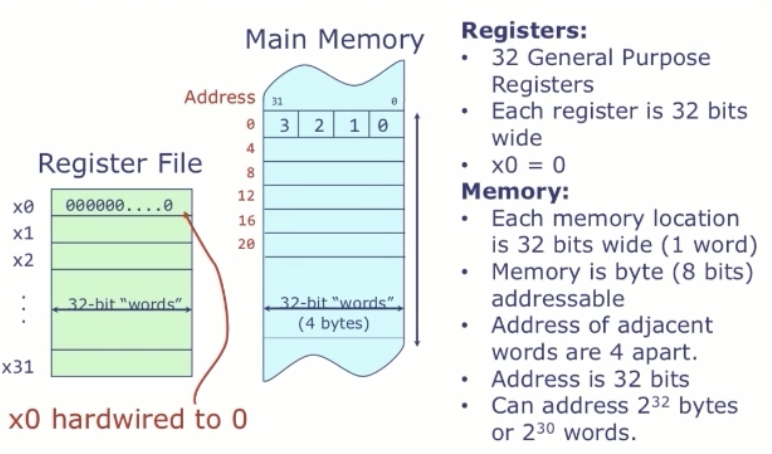
机器语言直接反映了微处理器的结构。三大组件 + 一个特殊寄存器:
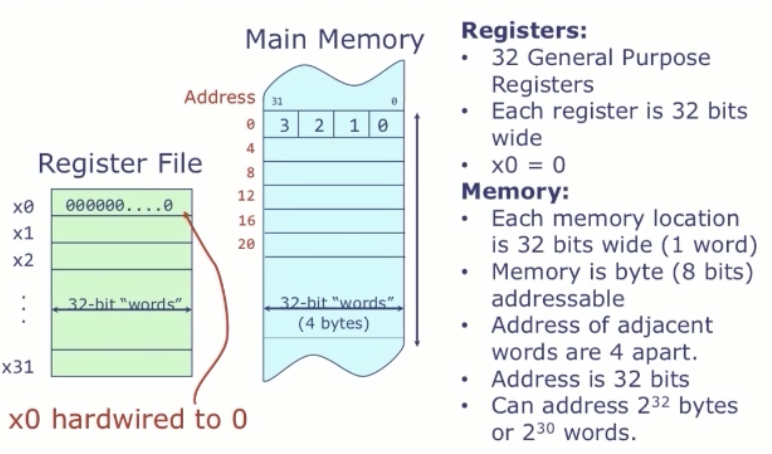
- 寄存器堆(Register File):少量(如 32 个)、定长(如 32 位)寄存器,ALU 直接对它们运算。
- 主存(Main Memory):很大(GB 级),存放程序和数据,以 32 位“字(word)”为单位、按地址访问。
- 算术逻辑单元(ALU):直接对寄存器堆做运算,典型形式
xi ← Op(xj, xk),Op ∈ {+, AND, OR, <, >, …}。 - 程序计数器(PC):一个特殊寄存器(不属于那 32 个),保存当前指令的地址。顺序执行时每条指令后
PC += 4(指令也是 32 位 = 4 字节);控制流指令会改写 PC。
数据通过 load/store 指令在主存与寄存器堆之间搬运。一段汇编程序就是一串指令,默认顺序执行,除非遇到控制转移指令。
ISA:软硬件契约 & RISC-V
指令集架构(ISA)= 软件与硬件之间的契约:
- 对操作和存储位置的功能定义;
- 软件如何调用/访问它们的精确描述。
RISC-V ISA:伯克利开发的、开源免费的现代 ISA,有多种模块化变体:
- 数据宽度:RV32 / RV64 / RV128;
I:基础整数指令;M:乘除;F/D:单/双精度浮点;等等。- 本课使用 RV32I(32 位基础整数版)。
寄存器堆
RV32I 有 32 个 32 位寄存器 x0–x31。
踩坑:
x0被硬连线为常量 0——读它永远得 0,写它相当于什么也没做(常用作丢弃结果或表示 0)。
调用约定给寄存器起了符号名(编程时按用途使用,见后文“过程调用”):zero(x0)、ra(x1)、sp(x2)、gp/tp、t0-t6(临时)、s0-s11(保存)、a0-a7(参数/返回值)。
指令类型
三大类:
- 算术与逻辑操作(由 ALU 执行);
- 存取操作(load/store,主存↔寄存器);
- 控制流操作(分支/跳转)。
算术和逻辑操作
包括算术、比较、逻辑、移位。寄存器-寄存器型:2 个源寄存器 + 1 个目标寄存器,格式 oper dst, src1, src2(即三地址指令)。
| 算术 | 比较 | 逻辑 | 移位 |
|---|---|---|---|
| add, sub | slt, sltu | and, or, xor | sll, srl, sra |
add x3, x1, x2 # x3 <- x1 + x2
slt x3, x1, x2 # if x1 < x2 then x3=1 else x3=0 (set less than)
sll x3, x1, x2 # x3 <- x1 << x2 (shift left logical)
slt= set less than;sll/srl/sra= 逻辑左移 / 逻辑右移 / 算术右移。sltu/bltu等带u的把操作数当无符号数处理。
寄存器-立即数指令
一个源来自寄存器,另一个是小常数,格式 oper dst, src1, const:
addi x3, x1, 3
andi x3, x1, 3
slli x3, x1, 3没有
subi——用负立即数即可:addi x3, x1, -3。
二进制模运算(Modular Arithmetic)
加法等运算溢出时,通用做法是忽略多出来的高位,相当于在模
十六进制表示法
长比特串容易出错,常用 base-16(十六进制):每 4 个比特编码成一个十六进制位,便于和比特串互相还原。如 lui x2, 0x3 把 0x3000 写入 x2(每个十六进制位 = 4 位二进制)。
复合计算(Compound Computation)
指令只支持两源一目标,所以复杂表达式要拆成基本运算(三地址形式)。执行 a = ((b+3) >> c) - 1;,设 a,b,c 在 x1,x2,x3,临时量 t0=x4, t1=x5:
# t0 = b + 3; t1 = t0 >> c; a = t1 - 1;
addi x4, x2, 3
srl x5, x4, x3
addi x1, x5, -1控制流
条件分支
格式 comp src1, src2, label:先比较 src1 comp src2,为真则跳到 label,否则顺序执行。
| 指令 | beq | bne | blt | bge | bltu | bgeu |
|---|---|---|---|---|---|---|
| 含义 | == | != | < | >= | <(无符号) | >=(无符号) |
编译 if (a<b) c=a+1; else c=b+2;(a,b,c=x1,x2,x3):
bge x1, x2, else # 注意:取 a>=b(即 a<b 为假)时跳 else
addi x3, x1, 1
beq x0, x0, end # x0==x0 恒真 → 无条件跳过 else
else:
addi x3, x2, 2
end:踩坑:分支条件常需取反——想在“a<b 为真”执行 if 体,就用
bge(a>=b)跳过它。beq x0,x0,L是恒真分支,可当无条件跳转用。
无条件跳转
jal(jump and link):jal x3, label,跳到 label(编码为相对当前指令的偏移),并把返回地址(link)存入 x3。指令里有 20 位可编码立即数。jalr(jump via register and link):jalr x3, 4(x1),跳到x1 + 4,link 存入 x3。可跳到任意 32 位地址(支持长跳转)。
j label # 伪指令
jal x0, label # 等价:丢弃 link(写 x0)存取指令
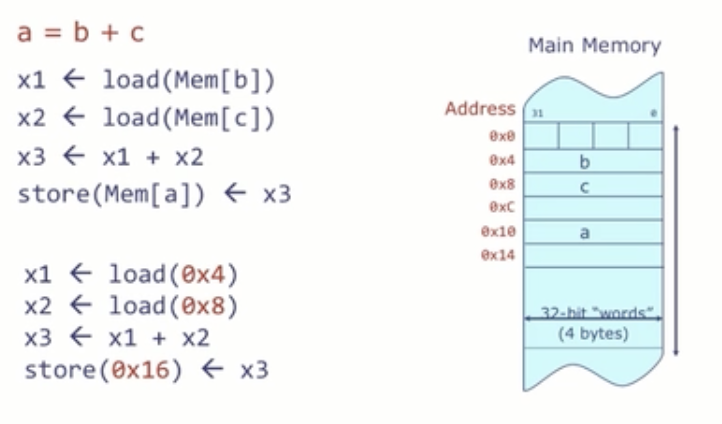
RISC-V 不允许在指令里直接写内存地址(受 32 位编码所限)。地址用 <base, offset> 对表示:base 放在寄存器,offset 是小常数。格式 lw dst, offset(base) / sw src, offset(base):
# x3 = Mem[0x4] + Mem[0x8]; Mem[0x10] = x3
lw x1, 0x4(x0) # load word
lw x2, 0x8(x0)
add x3, x1, x2
sw x3, 0x10(x0) # 注意:sw src, offset(base),src 在前踩坑:
sw的第一个操作数是要存的数据,不是地址;地址是offset(base)。
累加数组元素
sum = a[0] + … + a[n-1],设 x10 存数组基址:
lw x1, 0x0(x10) # x1 = base
lw x2, 0x4(x10) # x2 = n
add x3, x0, x0 # x3 = 0 (sum)
loop:
lw x4, 0x0(x1)
add x3, x3, x4
addi x1, x1, 4 # 指向下一个 word(+4 字节)
addi x2, x2, -1
bnez x2, loop
sw x3, 0x8(x10)指令编码限制、大常数、伪指令
每条指令编码成 32 位,要塞下:操作类型、目标寄存器(5 位,因 32 个寄存器)、两个源寄存器(各 5 位)或一个源 + 一个最多 12 位的常数。
所以指令里的常数限制在 12 位以内(12 位补码范围
,即 0x7FF为最大正数);大常数必须先放进寄存器再用。也正因此不能往内存直接写指令地址。
大常数用 li(load immediate)伪指令:
li x4, 0x123456
# 展开为:
lui x4, 0x123 # load upper immediate:把 20 位立即数放高 20 位,低 12 位清零
addi x4, x4, 0x456小常数时 li x4, 0x12 直接展开为 addi x4, x0, 0x12。汇编器(assembler)负责把指令翻译成 32 位二进制,并自动决定 li 用哪种展开。
常用伪指令(为其他指令提供别名,简化编程):
mv x2, x1 → addi x2, x1, 0
ble x1, x2, L → bge x2, x1, L
beqz x1, L → beq x1, x0, L
bnez x1, L → bne x1, x0, L
j L → jal x0, L
call f → jal ra, f
ret → jr ra (= jalr x0, 0(ra))负数采用补码(two's complement)编码(见 Lec 4)。
编译高级语言
基本流程:① 把变量分配到寄存器;② 把运算翻译成计算指令;③ 小常数用立即数指令、大常数用 li。
例:y = (x+3) | (y+123456); z = (x*4) ^ y;(x,y,z=x10,x11,x12,临时 x13,x14):
addi x13, x10, 3 # x+3
li x14, 123456
add x14, x11, x14 # y+123456
or x11, x13, x14 # y = ...
slli x13, x10, 2 # x*4 = x<<2
xor x12, x13, x11 # z = ...条件语句
if (expr) { body } if (expr){body} else {ebody}
───────────────────── ──────────────────────────
(compile expr → xN) (compile expr → xN)
beqz xN, endif beqz xN, else
(compile body) (compile body)
endif: j endif
else:
(compile ebody)
endif:例 if (x<y) y=y-x;:可直接合并比较与分支为 bge x10,x11,endif,更省指令。
循环
while (expr) { body } 更少分支的写法(每轮只一条控制流指令):
───────────────────── ────────────────────────────────────
while: j compare
(compile expr → xN) loop:
beqz xN, endwhile (compile body)
(compile body) compare:
j while (compile expr → xN)
endwhile: bnez xN, loop综合例 while(x!=y){ if(x>y) x-=y; else y-=x; }(x,y=x10,x11):
j compare
loop:
ble x10, x11, else
sub x10, x10, x11
j endif
else:
sub x11, x11, x10
endif:
compare:
bne x10, x11, loop过程调用:调用约定、栈与活动记录
过程(procedure / function)是可复用代码段:有唯一入口名、零或多个形参、局部存储,执行完返回调用者。
返回地址与调用约定
调用者必须能传参、拿返回值,并知道调用完该回到哪里。RISC-V 用寄存器约定(calling convention)保证大家能安全互调:
- 参数/返回值:
a0–a7(a0、有时a1兼作返回值); - 返回地址
ra:jal ra, label会把调用指令地址+4存入ra;过程结束jr ra(或ret)即返回。
caller-saved vs callee-saved
每个过程都希望能自由使用所有寄存器,但不能破坏调用者还要用的值。于是约定两类:
| 类别 | 寄存器 | 谁负责保存 | 跨调用是否保留 |
|---|---|---|---|
| caller-saved(调用者保存) | ra、a0–a7、t0–t6 | 调用者在 call 前保存(若之后还要用) | 否 |
| callee-saved(被调用者保存) | s0–s11、sp | 被调用者进入时保存、返回前恢复 | 是 |
踩坑:被调用者内部如果要用
s寄存器,必须先存后恢复;调用者如果 call 之后还要用a/t/ra,必须自己在 call 前存到栈。调用者看不到被调用者的实现,所以即使某实现“碰巧”没改某个a寄存器,约定仍要求你按规矩保存。
栈与活动记录
寄存器放不下的东西(局部变量、要保存的寄存器、大数据)放到栈(stack)里的活动记录(activation record):当前过程总在栈顶,返回时释放——后进先出(LIFO)。
RISC-V 约定:栈从高地址向低地址增长,sp 始终指向栈顶。
# push(把 a1 压栈) # pop(弹出到 a1)
addi sp, sp, -4 lw a1, 0(sp)
sw a1, 0(sp) addi sp, sp, 4核心原则:内存随便用,但用完必须照原样还回去(过程退出时
sp必须回到进入时的位置)。
callee 保存 s 寄存器的典型骨架:
f:
addi sp, sp, -8
sw s0, 0(sp)
sw s1, 4(sp)
... # 使用 s0, s1
lw s0, 0(sp)
lw s1, 4(sp)
addi sp, sp, 8
ret大数据结构(数组、字典等)不整个传入,而是传基址 + 大小等引用信息;字典等结构最终都用“内存块 + 指向地址的字”实现。
内存布局与 MMIO
多数语言把内存分成几个区:
- Text:代码本身;
- Static:全局变量(
gp指向,本课不常用); - Heap:动态分配(C 用
malloc/free,Python/Java 自动管理); - Stack:过程调用。
RISC-V 把 text/static/heap 从低地址 0x0 起连续向上排列(heap 向高地址增长),而 stack 从最高地址 0xFF…F 向低地址增长——两者相向而行,给彼此留出弹性空间。
内存映射 I/O(MMIO)
处理器还要和显示器、键盘等外设交互。办法是给外设分配专用地址,用普通的 lw/sw 读写即可——这就是 memory-mapped I/O(MMIO)。这些地址不能当普通存储用,背后是会响应内存请求的 I/O 设备。
本课约定(示例):
| 操作 | 地址 | 含义 |
|---|---|---|
lw | 0x4000_4000 | 从键盘读一个有符号字 |
sw | 0x4000_0000 | 打印一个 ASCII 字符 |
sw | 0x4000_0004 / 0x4000_0008 | 打印十进制 / 十六进制数 |
lw | 0x4000_5000 | 程序启动至今执行的指令数 |
lw | 0x4000_6000 | 性能计数器(由 0x4000_6004 写 0/1 开关) |
例:读两个键盘输入相加并打印:
li t0, 0x40004000 # 读端口
lw a0, 0(t0)
lw a1, 0(t0)
add a0, a0, a1
li t0, 0x40000004 # 写端口(十进制)
sw a0, 0(t0)至此我们已掌握把任意高级程序翻译成 RISC-V 的全部语言要素。接下来 Lec 10 起,我们将从底层用硬件实现这些指令。