Lec 10 单周期处理器
我们知道计算机的性能是由三个关键因素决定: 指令总数、时钟频率和每条指令的周期数(CPI)。编译器和指令集能够决定一个程序的指令总数,而处理器的实现却能决定CPI和时钟频率。
微处理器
每个微处理器都有三个组成部分:
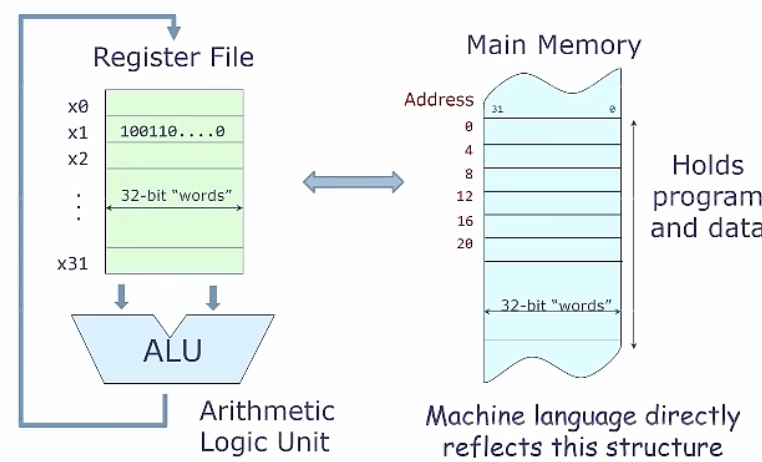
- 寄存器堆(Register File): 一组寄存器,x0~0x31, each have 32-bit wide( "words" )
- 算术逻辑单元(Arithmetic Logic Unit ,ALU): 典型的操作就是从寄存器堆里面读出两个东西然后做一些计算,然后将其放回寄存器。
- 主存(Main Memory): 比寄存器堆更多的存储空间,可以看作是无限大,存储程序和数据(指令)。但是数据传送ALU,只能经由Register File。
我们之所以同时拥有寄存器堆和主存,是因为寄存器文件只用于保存少量、立即需要用的数据,这样做的好处是访问速度快、便于计算操作。因此我们需要一种方式来在寄存器和主存之间传输信息,我们需要以一种适配寄存器和主存结构的方式来设计机器语言(指令集)。
微处理器结构/汇编语言
每个寄存器的大小都是固定的,为32-bit
寄存器的数目很少,一般是32个
ALU直接在寄存器堆上进行操作
数据能够在主存和寄存器堆来回搬运
- Ld x M[a]: 将内存某个地址的数据放到寄存器
- St M[a] x:寄存器的数据你想存到内存
汇编语言程序就是一系列的顺序执行的指令,除非说是控制转移指令。总结说,无非是这几个
- ALU or Reg-to-Reg operation
- Ld
- St
- Control transfer Ops: e.g., xi < xj to lebel L
举个例子
sum = a[0] + a[1] + a[2] + ... + a[n-1]
base: 我的知道数组开始的位置在哪里,我们称其为基地址(base address)
n:告诉我们存储了多少个元素
sum: 存储结果
x1 <- load(Mem[x10]) # x1 = base(数组首地址)
x2 <- load(Mem[x10 + 4]) # x2 = n
x3 <- load(Mem[x10 + 8]) # x3 = sum 初值
loop:
x4 <- load(Mem[x1]) # 加载 x1 指向的当前元素
add x3, x3, x4
addi x1, x1, 4 # 指向下一个元素(+4 字节)—— 别漏了这一步!
addi x2, x2, -1
bnez x2, loop
store(Mem[x10+8]) <- x3踩坑:循环里必须递增
x1(addi x1, x1, 4),否则每轮都读同一个元素,死循环式地把a[0]加 n 次。
高级语言 vs. 汇编语言
高级语言特性
- 原始的算术和逻辑操作
- 复杂的数据结构和数据类型
- 复杂的控制结构,循环,条件语句,and 过程调用(RPC)
汇编语言
- 原始的算术和逻辑运算
- 原始的数据结构——bits 和 integers
- 控制转移指令
- 为直接实现在硬件上而设计的
实现基本RISC-V指令集
我们将解释如下的RISC-V指令(本课为 RV32I,字长 32 位,故用 lw/sw 而非 COD 教材里 RV64 的 ld/sd):
- 内存引用指令。load word(lw) 和 store word(sw)
- 算术逻辑指令。add、sub、and 和 or
- 条件分支指令。 branch if equal(beq)
借着解释实现,我们将会看到不同的实现策略如何影响时钟频率和CPI的。
总览实现
对于每条指令,首先需要做的两个步骤都是相同的
- 将PC发送到内存,并从该内存中fetch指令
- 读取一个或两个寄存器,根据指令的field决定选择需要读取寄存器。对于ld指令,我们只需要读一个,而大多数而言需要两个寄存器。
在这两步之后,根据指令的类型而异,幸运的是,在三种类型指令中,执行动作大体一致(受益于RISC-V的简单性的设计原则)。举个例子,所有指令在读取寄存器后会使用算术逻辑单元(ALU),其中内存引用指令用ALU来计算地址,算术逻辑指令用于计算执行,而条件分支用于 equality test。而使用完ALU后,内存引用指令需要访问内存,要么读取要么加载数据;而算术逻辑则必须将数据从ALU或者内存中写回到一个寄存器上;而条件分支指令决定PC是加4还是改成其他下一条指令地址。
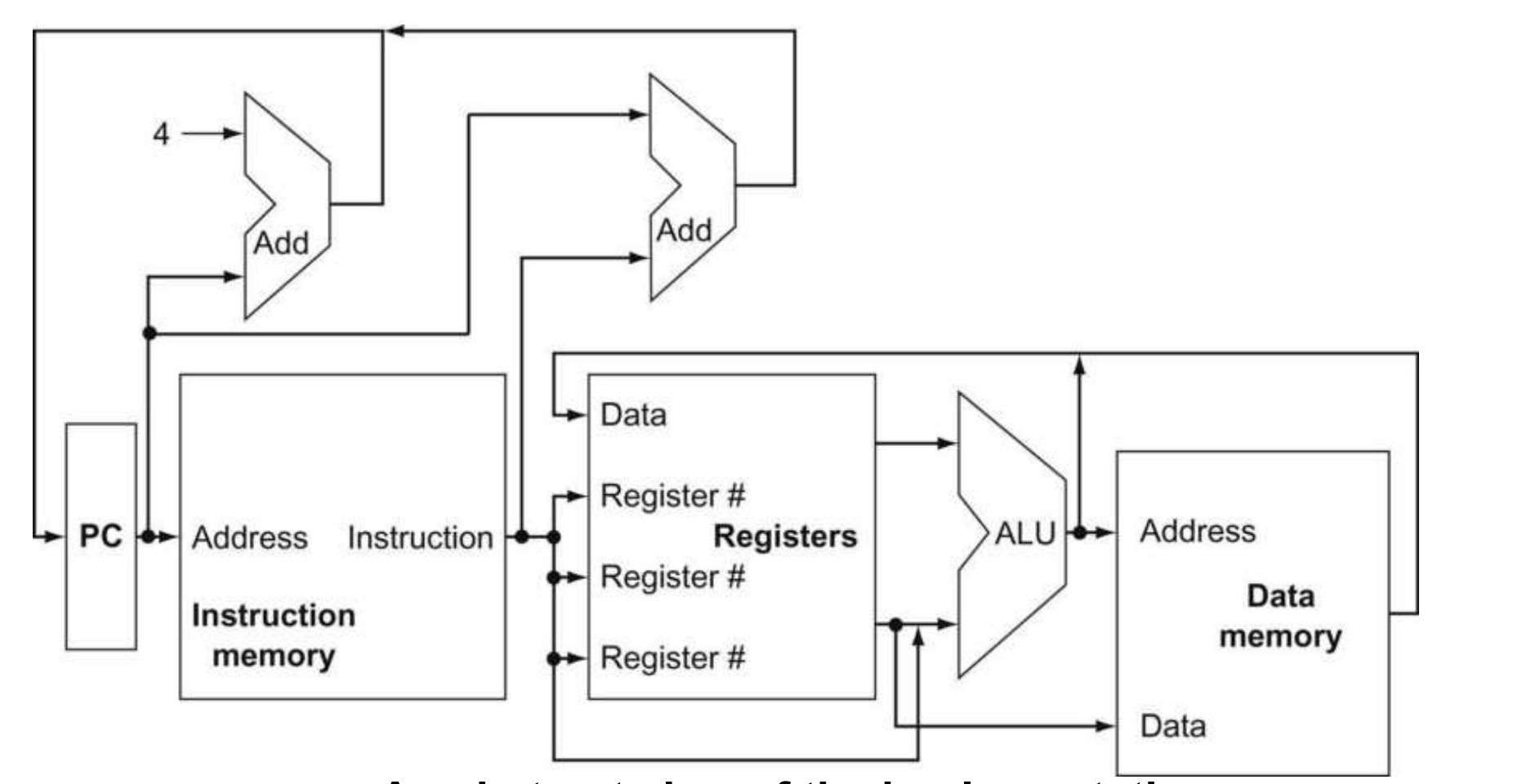
上图10.1是RISC-V子集实现的概要图,展示了主要的功能单元和连接关系。所有的指令都由PC提供的指令地址开始,当fetch指令后,指令使用的寄存器操作数由指令的field(字段)指定。对于算术指令,从ALU得到的结果必须写回寄存器;对于内存引用指令,ALU 的结果被用作地址,要么把寄存器里的值存到这个地址(即:写内存),要么从这个地址加载一个值到寄存器里(即:读内存)。
图10.1 显示某个功能单元接收的数据可能来自两个不同的来源。例如,写入程序计数器(PC)的值可能来自两个加法器之一;写入寄存器文件的数据可能来自 ALU 或数据内存;ALU 的第二个输入可以来自某个寄存器,也可以来自指令中的立即数字段(immediate field)。在实际硬件中,这些数据线不能简单地直接连接在一起;我们必须添加一个逻辑元件,用来在多个来源中选择一个,并将它引导到目标位置。第二个省略之处在于:多个功能单元的行为必须根据指令类型进行控制。例如,数据内存在执行 load 指令时要读取,在执行 store 指令时要写入。只有在执行 load 指令或算术逻辑指令时,寄存器文件才会被写入。
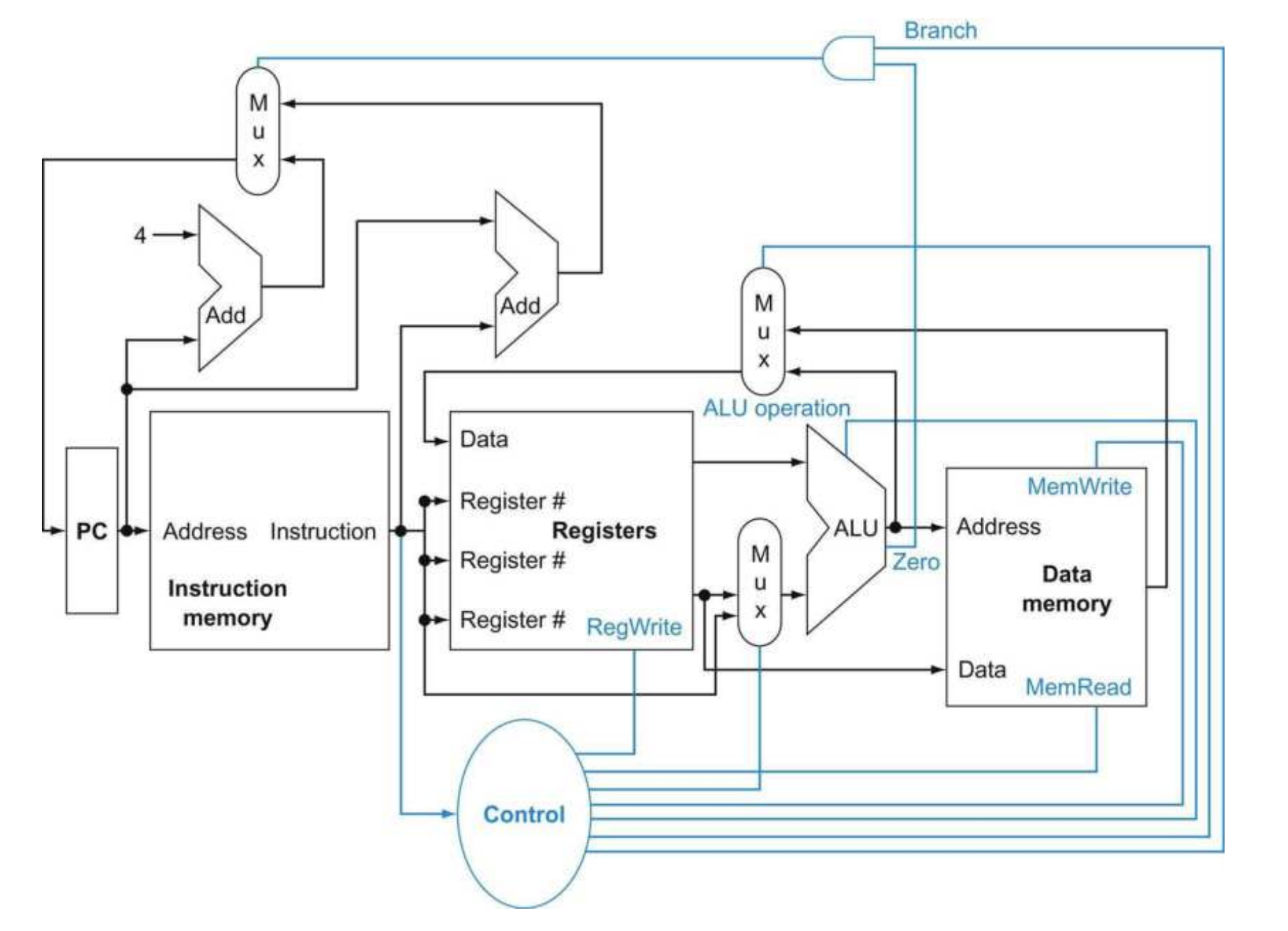
图10.2展示了基本RISC-V数据通路的实现。新增了多路选择器和控制信号。控制单元以指令作为输入,用于决定如何设置功能单元和其中两个多路选择器的控制线。最上方的多路选择器决定写入 PC 的值是 PC + 4 还是分支目标地址。它的控制依据是 ALU 的 Zero 输出位(用于执行 beq 指令时的比较结果)。中间的多路选择器,其输出回写到寄存器文件,用于在算术逻辑指令中选择 ALU 的输出,或者在 load 指令中选择从内存读取的数据作为写入寄存器的值。最后,最底部的多路选择器用于决定 ALU 的第二个输入是来自寄存器(用于算术逻辑或分支指令),还是来自指令中的偏移字段(用于 load 或 store)。
在这种初始设计中,每条指令在一个时钟上升沿开始执行,并在下一个时钟上升沿完成执行。当前实现使用 单周期,即每条指令一个长时钟周期,虽简单但效率不高;
逻辑设计约定
要讨论一台计算机的设计,我们必须确定实现该计算机的硬件逻辑如何工作,以及计算机如何通过时钟控制运行。数据通路的元件分两类:
- 组合元件(combinational):输出只取决于当前输入,无内部存储。如 ALU、加法器、多路选择器、符号扩展、指令存储器(只读,可当组合逻辑看)。
- 状态元件(state element):含内部存储,能“记住”值。如寄存器堆、数据存储器、PC。状态元件至少有“数据输入 + 时钟”两个输入和一个输出;任何时候都能读,但只在时钟边沿按写使能写入。它们完整刻画了机器的状态——断电后只要恢复这些状态元件就能精确重启。
时钟方法学(clocking methodology)规定信号何时可读、何时可写,目的是让硬件可预测——避免“同一信号在被读的同时被写,读到旧值/新值/二者混合”这种不确定性。本课采用边沿触发(edge-triggered):所有状态更新只发生在时钟(上升)沿。于是任一块组合逻辑的输入都来自状态元件、输出都写入状态元件;一个时钟周期内信号从“状态元件1 →组合逻辑→状态元件2”,这段最长传播路径决定了时钟周期长度(见 Lec 6 的寄存器到寄存器路径约束)。
- 控制信号 vs 数据信号:控制信号用于选择 mux 或指挥功能单元的操作;数据信号是被运算的数据。每周期都写的状态元件不画写使能;不是每周期都写的(如寄存器堆、数据存储器)则需要显式写使能,只有写使能有效且时钟沿到来时才写入。
- 断言(asserted)= 逻辑高/真,撤销(deasserted)= 逻辑低/假。
- 边沿触发的好处:同一周期内可以先读一个寄存器、过组合逻辑、再写回这个寄存器——读到的是上周期写入的旧值,本周期写入的新值供下周期读。单周期内无组合反馈,逻辑正确。
构建数据通路
自底向上,先看每类指令需要哪些数据通路元件,再拼成一条通路。
取指与 PC(所有指令共用)
需要三件:指令存储器(按地址供出指令,只读)、PC 寄存器(存当前指令地址,每周期末更新,无需写使能)、一个加法器(算 PC+4,由 ALU 固定为 add 得到)。每条指令都从“用 PC 取指 + 算 PC+4”开始。
R 型(算术逻辑)指令
add x1, x2, x3:读两个寄存器、ALU 运算、写回一个寄存器。需要:
- 寄存器堆(register file):两个读端口 + 一个写端口。读端口输入是 5 位寄存器号(因 32 = 2⁵),输出是 32 位数据;读无需控制信号(总是输出所指寄存器内容)。写则需 RegWrite 写使能,且写入是边沿触发的(写号、写数据、写使能都须在时钟沿前稳定)。
- ALU:两个 32 位输入、一个 32 位结果,外加一个 Zero 输出(结果为 0 时为 1);由 4 位 ALU 操作信号控制做哪种运算。
load / store 指令
lw x1, offset(x2) / sw x1, offset(x2):用 base 寄存器 + 12 位有符号 offset 算地址。在寄存器堆和 ALU 之外,还需要:
- 符号扩展单元(ImmGen):把指令中 12 位立即数符号扩展成 32 位(复制最高符号位)。
- 数据存储器(data memory):有地址输入、写数据输入、读数据输出,以及独立的读/写控制信号(同一周期只能断言其一)。读也需要读信号——因为读非法地址可能出问题(见 Lec 13)。
ALU 在这里用来算地址(base + 符号扩展的 offset)。
beq 分支指令
beq x1, x2, offset:① 用 ALU 做减法比较两寄存器,看 Zero 是否为 1(相等则分支“taken”);② 用另一个加法器算分支目标地址 = PC + (符号扩展 offset 左移 1 位)。
“左移 1 位”只是布线时在低位接一个 0(offset 是半字偏移),无需真正的移位硬件;控制逻辑据 Zero 决定 PC 取
PC+4还是分支目标。
拼成单条数据通路
把各段合并时,同一个目标可能有多个数据来源,必须插入 mux + 控制信号来选择:
- 写回寄存器堆的数据:来自 ALU 结果(R 型)或数据存储器读出(lw)——由
MemtoReg选。 - ALU 第二个输入:来自寄存器(R 型/分支)或符号扩展立即数(load/store)——由
ALUSrc选。 - 写入 PC 的值:
PC+4或分支目标——由分支条件(Branch与 ALU 的Zero)选。
控制单元以指令(的 opcode/funct 字段)为输入,产生上述所有控制线(RegWrite、ALUSrc、MemRead、MemWrite、MemtoReg、Branch、ALU 操作等),指挥各功能单元和 mux。
得益于 RISC-V 的简单规整,三类指令前两步(取指、读寄存器)完全一致,之后也都要用 ALU(算地址 / 做运算 / 比较),差异只在“ALU 之后做什么”,因此一套数据通路 + 一组控制信号即可覆盖。
单周期实现及其局限
在这种初始设计中,每条指令在一个时钟上升沿开始、在下一个上升沿完成——单周期:每条指令一个长时钟周期。它简单,但时钟周期必须迁就最慢的指令(如 lw 要走完“取指→读寄存器→ALU 算地址→访存→写回”整条路径),于是
被拉得很长、效率低下。改进方向是流水线——把这条长路径切成多级、让多条指令重叠执行,从而大幅缩短