Lec 13 缓存
缓存概述
我们的分层内存系统中的SRAM组件称为缓存(cache),缓存位于CPU和主存之间,它能够快速访问最近访问过的数据块。如果请求的数据在缓存中,我们称之为缓存命中(cache hits),数据将由SRAM提供。如果请求的数据不在缓存中,我们称之为缓存未命中(Cache miss),这时需要将包含请求位置的数据块从DRAM移到缓存中。局部性原理告诉我们,缓存命中应该比缓存未命中更为频繁。
现代计算机系统通常使用多级SRAM缓存。离CPU最近的缓存级别较小但速度非常快,而离CPU较远的级别则容量更大,因此速度较慢。某一级缓存未命中时,会触发对下一级缓存的访问,依此类推,直到需要访问DRAM以满足最初的请求。
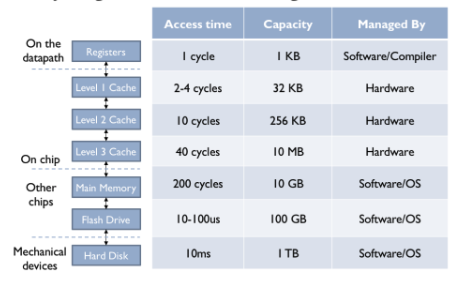
这是一个现代计算机上可能出现的内存层次结构示例。系统中有三级片上SRAM缓存,接下来是DRAM主存储器,以及用于硬盘驱动器的闪存缓存。编译器负责决定哪些数据值保留在CPU寄存器中,哪些值需要通过LD(加载)和ST(存储)指令来操作。三级缓存和对DRAM的访问由内存系统中的电路管理。在此之后,访问时间变得足够长(需要数百个指令周期),因此管理数据在内存层次结构中较低层之间移动的任务转交给软件处理。
缓存的概念广泛用于许多应用中,以加快对频繁访问数据的响应速度。例如,浏览器会维护一个频繁访问网页的缓存,并在确认数据仍然有效的情况下,使用本地副本的网页,避免了通过互联网传输数据的延迟。
缓存访问
处理器通过向缓存发送地址来启动访问。如果缓存中保存了所请求地址的数据,它会快速返回给CPU。如果我们请求的数据不在缓存中,就会发生缓存未命中,因此缓存必须向主存储器发出请求以获取数据,然后将其返回给处理器。通常,缓存会记住新取回的数据,可能会替换缓存中的一些旧数据。
假设一次缓存访问需要4纳秒,而一次主存储器访问需要40纳秒。那么缓存命中时的访问延迟为4纳秒,但缓存未命中时的访问延迟为44纳秒。处理器必须处理这种可变的内存访问时间,可能只是简单地等待访问完成,或者在现代超线程处理器中,它可能会执行另一线程中的一两条指令。
局部性原理
缓存之所以有效,全靠程序的局部性(locality):
- 时间局部性(temporal):刚访问过的地址,不久后很可能再访问(如循环变量、循环体指令)。
- 空间局部性(spatial):访问了某地址,附近的地址不久后很可能被访问(如顺序执行的指令、数组遍历)。
缓存据此把“最近用过的及其邻近的数据”留在快速的 SRAM 里,从而伪装出一个又大又快的内存。
缓存指标
设命中
衡量缓存好坏的核心是平均访存时间(AMAT, Average Memory Access Time):
其中“未命中代价(miss penalty)”是从下一级取数据的时间。多级缓存时,把“未命中代价”递归替换为下一级的 AMAT 即可。
例(盈亏平衡):主存 100 周期、缓存 4 周期。要让缓存“不亏”:
这个命中率轻松可达——实际常达 90%+。若
,则 周期,远好于 100 周期。这就是“又大又快内存”的错觉来源。
缓存的基本原理:标签(tag)
缓存同时存数据和与之关联的标签(tag)。访问 Mem[X] 时:查 tag X 是否在缓存里 → 在则命中、返回对应行数据;否则未命中,从主存取 Mem[X],选一行 k 放进去(设 Tag(k)=X, Data(k)=Mem[X])以备将来。
核心设计问题:如何高效查找(比顺序扫描快)?答案是按地址的某些位直接索引——见下面的直接映射缓存。
直接映射缓存(Direct-Mapped)
最简单的缓存:每个地址只能映射到唯一一条缓存行,查找极快。若缓存有
把一个 32 位地址切成三段(自低位起):
| tag (剩余高位) | index (W 位) | byte offset (2 位) |- byte offset(最低 2 位):因为按字节编址、但每次取一个字(4 字节),这 2 位恒为 0,不使用。
- index:选哪一行。
- tag:存进缓存行,用于确认“这行装的确实是我要的地址”。
判命中:① 该行有效位 valid = 1(开机时缓存是垃圾,需要 valid 区分);② 该行 tag 与地址的 tag 相等。两者都满足才命中。
Fact:只存 tag 而非整个地址即可——因为剩余地址位可由“它在第几行(index)”反推出来。这既省空间又省时间。
为什么用低位做 index? 因为程序常访问连续地址;若用高位做 index,相邻数据会全挤进同一行而互相冲突。用低位正是利用局部性。
例:8 行直接映射缓存,32 位地址 → 2 位 byte offset + 3 位 index(Mem[0x400C]:0x400C = 0b...1100,byte offset=00、index=0x3、tag=0x40;若第 3 行 valid=1 且 tag=0x40 则命中。读 Mem[0x4008]:index=0x2,若该行 tag 不匹配则未命中。
块大小的权衡
为充分利用空间局部性,未命中时一次从主存搬多个字进来(它们共享一个 tag,还省了 tag 空间)。这样缓存行变“宽”,地址多出一段 block offset(块内选字):
| tag | index | block offset | byte offset |例:4 行、每行 4 字(16 字)的直接映射缓存,32 位地址 → 2 位 byte offset + 2 位 block offset(4 字)+ 2 位 index(4 行)+ 26 位 tag。
块大小的权衡:
- 块越大 → 越能利用空间局部性,未命中率先下降;
- 但固定总容量下,块越大 → 行数越少 → 冲突增多,过大反而未命中率回升;
- 块越大 → 每次搬运数据越多 → 未命中代价略增(但相比首次访存的固定开销,多搬一点代价不大)。
经验上,对典型缓存,使 AMAT 最优的块大小约为 64 字节(16 字/块)。
关于组相联、替换策略、写策略、缺失类型及大量对比例题,见 Lec 14 缓存实现。