Lec 4 二进制计算
Outline
- 二进制运算
- 加法器实现优化
二进制表示与算术
补码表示法
看一下例子

当发送overflow时候,通用的做法就是忽略额外bit。可以看成是环绕的,如下图,
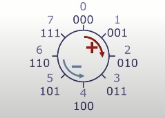
如果只是用最高位作为符号位,其他用无符号的方式表示数字大小,将会导致(+0, -0)都表示为0,电路在对0进行加减法时候就会发现这相当不一样,也会变的很复杂。因此没有采用。
补码表示法(Two's Complement Encoding),环绕图中获取编码灵感。
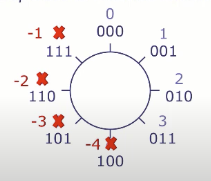
补码表示的算术
取反
先取反,再加一。 原理:
- -A + A = 0 = -1 + 1, 接着移项得到
- -A = (-1 - A) + 1
- 其中-1 是 0b111...1
- -1 - A 就是将A所有比特取反
减法运算
可以很简单的写成 A + (-B)
示例

第二个例子中发生了overflow, 这意味着发生了, zero crossing 导致的高位变化(符号变化), 这是没有意义的,需要忽略,只用剩下的低位来表示结果。
加法器实现优化
硬件设计的算法权衡:同一个功能,可以用很多种不同的实现方法,而且这些方法在速度(delay)、面积(area)、功耗(power)上差异很大。选一个合适的算法,是优化硬件设计(性能、面积、功耗)的关键。如果你一开始就选了一个很低效的算法,后面的综合工具/优化工具也救不了你。如果你用一个 O(n²) 的笨方法解决问题,不管编译器怎么优化,你还是慢。
行波加法器
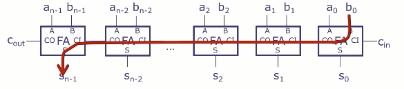
在加法器中,最坏情况下的路径是从最低位(LSB)一路向最高位(MSB)传播进位,比如在将 11...111 和 00...001 相加时。此时的总延迟
选择进位加法器
选择进位加法器(Carry-Select Adder)权衡面积和速度
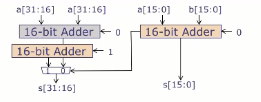
可以将高半部分的加法器复制两份,一份假设进位输入为0,另一份假设进位输入为1。然后根据低半部分的加法器产生的进位输出来选择正确的高半部分结果。其传播延迟为
缺点: 需要比行波加法器花费更大的面积,且位宽大多路复用器显著增加了延迟。
加速进位加法器(超前进位)
加速进位加法器(Carry-Lookahead Adder ,CLA)
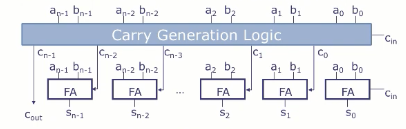
Carry-Lookahead Adders (CLAs) 通过把串行的进位计算链变成树状结构,在
第一步:改写全加器——生成(G)与传播(P)
把全加器的进位输出重写为两项:
- 生成位
:当前位自己就产生进位,无需等待 。 - 传播位
:当前位会把收到的 原样传出去。 - 注意
本可取 (不改变 真值表),但选 XOR 是为了顺便复用它来算和: 。
- 注意
直觉:一个模块产生进位,要么是它自己生成(G),要么是它传播了上一级来的进位(P·C_in)。
第二步:合并相邻模块——G、P 可结合
把高位块 H 和低位块 L 看成一个更大的块,则这个块整体的生成/传播为:
含义:整块要产生进位 = H 自己产生,或 L 产生且被 H 传播;整块要传播进位 = L 和 H 都传播。
关键:
的这个合并运算是可结合的,所以可以像求前缀和一样用树自底向上计算任意宽度块的 。对 位加法器,这棵 GP 树有 个 GP 模块,延迟 。
第三步:自顶向下分发进位(C 模块)
有了各块的
- 低半部分的进位输入 =
(直接传下去); - 高半部分的进位输入 =
。
这一步同样是
结果
向上算 GP、向下分发进位各
这种 generate-propagate 策略是目前最快加法器的基础,进一步可了解 Kogge-Stone 加法器。