Lec 15 流水线基础
这节lec我们开始新的内容,流水线技术(pipelining),可以帮助提高我们的电路性能。在设计系统时有两个指标比较重要,一个是延迟,一个是吞吐量。
- 延迟(latency):从输入进入系统到相关的输出被制造出来所需的时间。
- 吞吐量(throughput): at what rate can we produce valid inputs or outputs?
比如,安全气囊展开系统应优先优化延迟,而通用处理器则应主要优化吞吐量,其目标是每秒执行大量的计算。
Outline
- 流水线引例
- 流水线阶段划分
- 单周期处理器流水线
引例
常规
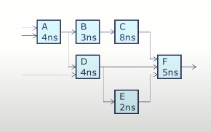
下面看组合逻辑性能的例子,假设F、G和H的传播延迟为15,20,25ns以下组合逻辑电路: 延迟 =
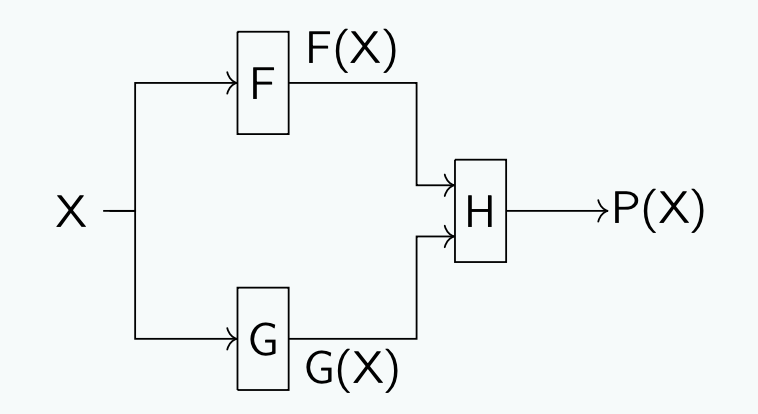
问题是,硬件资源没有被充分利用。整个电路的传播延迟是 tPD= 45ns,吞吐量是1/45 当某个输入 X 到来时,F 和 G 很快就完成了工作(比如在前 20ns), 然后 H 在后面 25ns 进行计算。
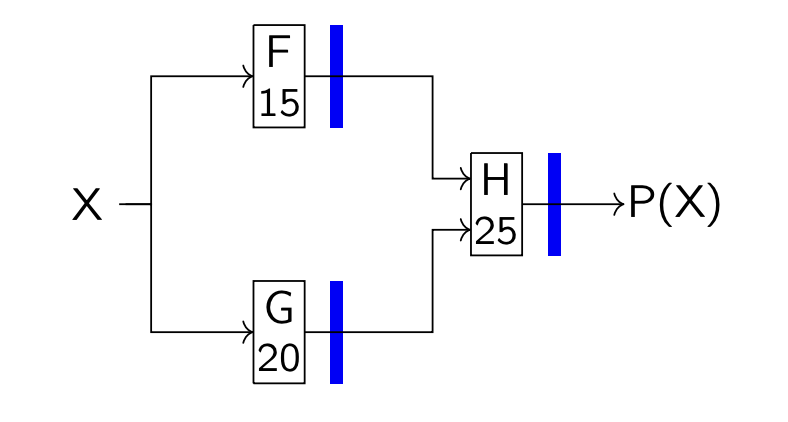
解决方案: 使用寄存器引入流水线(在图中蓝色标记处加入寄存器以保存中间结果)。现在,F 和 G 可以同时处理输入
此时限制时钟周期的因素是最慢的电路部分,也就是 H 模块的工作。因此,我们可以采用 25 纳秒的时钟周期来满足时序要求,这样虽然总延迟变成了 50 纳秒(略微变差),但吞吐量提高到了 1/25(显著提升)。
一种分析流水线的行为可以用流水线图表示。
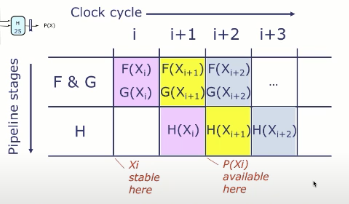
IMPORTANT
一个 k 阶流水线是一个无环电路,在从输入到输出的每条路径上都包含 k 个寄存器(组合电路就是一个 0 阶流水线)
在结构设计中,我们默认每个流水线阶段的寄存器放在其输出端。流水线的时钟周期
- 延迟= k ·
- 吞吐量 = 1 /
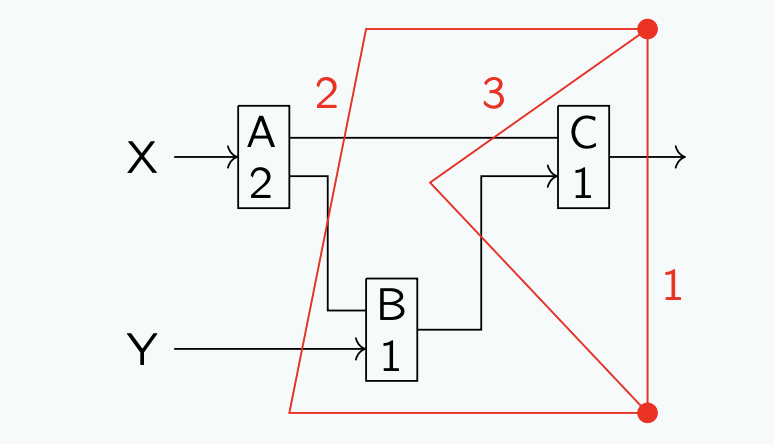
病态
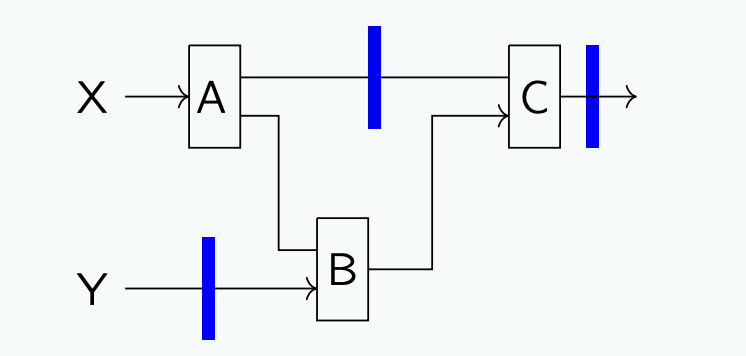
该电路的问题在于,从X出发经A和C的路径,以及从Y出发经B和C的路径,各自都经过2个寄存器。但A-B-C路径仅包含一个寄存器,这将导致不同时钟周期内的计算结果被混淆!具体来说,我们需要注意A(
流水线划分
现在让我们讨论一个成功的流水线设计方案:
- 在电路中绘制一条穿过每个输出端的直线,并将两端标记为终端点
- 继续在终端点之间绘制新直线,穿过电路中的每个连接,确保每条直线与前一条直线在同一方向上穿过每个连接点。这些直线划分出流水线阶段, 在每个划分线与连接线相交的点添加一个流水线寄存器,将生成一个有效的流水线。
在设计流水线电路时总的策略就是,应优先在最慢的电路部分(也就是“瓶颈”)前后放置寄存器,以提升整体性能
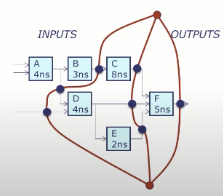
为什么不在左上角的A和B电路元件之间添加另一条线?
是多少?
Solution: 原因是由于元件C的存在,
回到前面的病态例子。如果我们需要再输出端添加一个寄存器,我们在C的输出段添加1级流水线,实际上并不会改善延迟或者吞吐量(我们只是对电路进行了时钟同步,将其转换为顺序电路,而未带来性能上的变化)。第二个流水线阶段,可以将组件A放在自己的阶段,其他电路元件放在各自的阶段,从而得到2 ns的时钟时间。通过将B和C分成第三个流水线阶段并不会提升性能,因为性能瓶颈仍然是A。以下是计算结果的表格:
| 延迟 | 吞吐量 | |
|---|---|---|
| 0阶流水线 | 4 | 1/4 |
| 1阶流水线 | 4 | 1/4 |
| 2阶流水线 | 4 | 1/2 |
| 3阶流水线 | 6 | 1/2 |
有以下几点观察:
- 1阶流水线并不会优化延迟和吞吐量
- 吞吐量是通过打破长路径提高的。
- 随意添加流水线阶段是不可取的,可能只会增加延迟,而不会提高吞吐量
- 有时候为了保持流水线的良构,背对背的寄存器可能是需要的,这是合理的
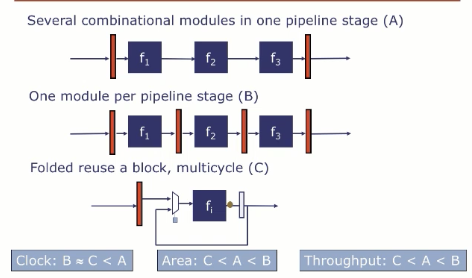
单周期处理器
性能铁律(Iron Law) :处理器性能 = Time / Program = (指令数 / 程序) · (平均时钟周期 / 指令) · (时间 / 时钟周期)
要降低执行时间,可以采用:
- 降低执行指令数
- 降低每指令的时钟周期数(CPI)
- 时钟周期(也就是增加频率)
如果CPI = 1, 我们称这个为单周期处理器。当前,执行一个时钟周期所需的时间为时钟周期
OOh, 这样太慢了!
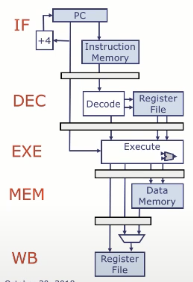
我们将借鉴之前讲座中的一个想法:我们将数据通路划分为多个流水线阶段,这意味着每个指令需要多个时钟周期来执行,但通过指令重叠,我们可以保持吞吐量约为每周期1条指令,并显著降低tCLK
经典的5级流水线
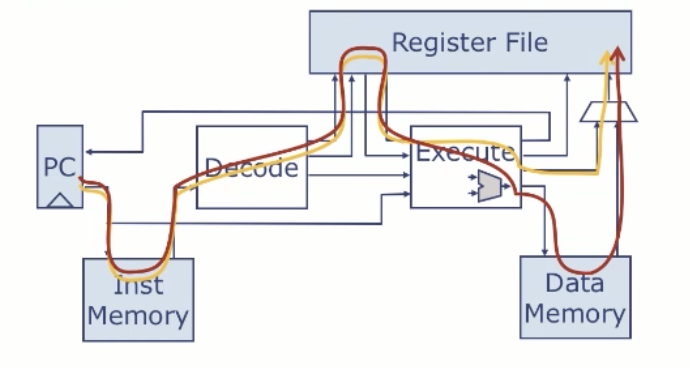
- IF(取指阶段): 维护程序计数器(PC),从指令存储器中取出指令,并将其传递给下一个阶段。
- DEC(译码与读寄存器阶段):对指令进行译码,并从寄存器堆中读取源操作数。
- EXE(执行阶段):由 ALU 执行运算操作,例如加法、位移等,计算结果传给下一阶段;
- MEM(访存阶段):若指令是加载(load),则使用执行阶段的结果作为内存地址读取数据;否则直接传递 ALU 结果
- WB(写回阶段):将最终结果写回寄存器堆。
此时,
But,而且我们之前已经知道如何对组合逻辑电路进行流水线设计。但这个过程其实并不像表面上看起来那么简单:
- 处理器有多个状态: PC、寄存器堆和内存。这意味着我们需要更多地考虑现有状态与寄存器堆之间的交互。
- 我们的电路中存在无法立即打破的循环,比如
- 计算下一个PC
- 将结果写入到寄存器堆的操作
- 不能生成一个良构的流水线
下图重新绘制了单周期处理器,更明确了各个阶段。
NOTE
关于流水线冒险
流水线尝试重叠多条指令的执行,但是一条指令可能取决于上一条指令的结果。如果涉及到数据值,则是数据冒险;而涉及到PC则是控制冒险。