Lec 16 处理器流水线: 数据和控制冒险
Outline
- 回顾
- 数据冒险
- 控制冒险
- 总结
回顾
性能铁律
性能铁律(Iron Law) :处理器性能 = Time / Program = (指令数 / 程序) · (平均时钟周期 / 指令) · (时间 / 时钟周期)
我们知道要降低对一个程序的执行时间。有三种方法,(1)减少我们需要执行的指令数;(2)降低CPI;(3)减少周期时间。其中,(1)需要我们给每个指令做更多的工作,也就是说需要支持更复杂的指令,即更改ISA,(2)一般不可能做到,除非平行处理。而(3)是我们将通过流水线技术做到这点。
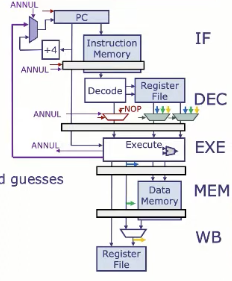
经典5阶段流水线
回顾一下经典的5阶段RISC流水线
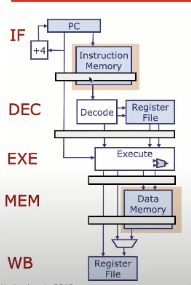
- 每两个相邻的流水段之间都会插入一组称为流水寄存器的寄存器
- 每个时钟周期内,每个阶段服务一条指令
- 目前来说,下一个PC = PC + 4(也就是说没有分支和跳转)
- 对指令存储器和数据存储器的读取操作是时钟触发的。也就是说,读取的数据不会立即返回,而是要等到下一个时钟沿(通常是上升沿)才返回结果。
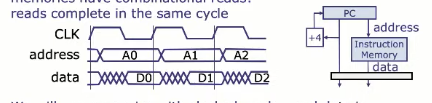
组合逻辑读存储器 vs 时钟触发读存储器
组合逻辑读存储器(Combinational Read Memory)的行为是,你给一个地址,他理解返回对应的数据:无需时钟,读取逻辑是组合逻辑,通常用在寄存器堆读取。
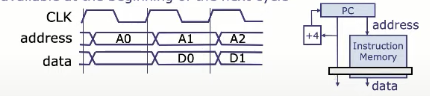
时钟触发读存储器( Clocked Read Memory)的行为是,你给出地址后,必须等到下一个时钟沿(如上升沿),数据才会被“输出”。使用的是同步存储器(SRAM、主存)
流水线执行
lw x11, 4(x12)
lw x13, 8(×14)
sub x15, x16, x17
xor x19, x20, x21
add X22, X23, X24
addi x25, x26, 1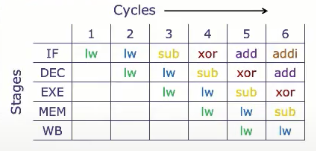
寄存器的读写发生在什么时候?
Solution: 读操作发生在Dec阶段,而写操作发生在WB阶段
冒险的解决策略
- 策略1: 插入停顿(stall),即当所需数据尚未准备好时,暂停流水线中早期的阶段,等待数据就绪后再继续执行。
- 策略2: 旁路/转发(Bypass aka Forward),当数据一经计算完成(如 ALU 输出),立即将其直接传递到需要的早期流水阶段,而不是等它写回寄存器。
- 策略3: 推测执行(Speculate),对尚未知的数据或控制流结果做出猜测并继续执行;当真实值出现后,如果猜对了则继续执行无须更改,若猜错了则终止错误路径上的指令,并从正确路径重新开始执行。
数据冒险
考虑下面的指令序列:
addi x11, x10, 2
xor x13, x11, x12
sub x17, x15, x16
xori x19, x18, 0xF
xor在时钟周期3时候读取了寄存器x11,但是addi在周期5结束前还没更新,此时x11读取的是旧数据。
数据冒险策略:停顿

在addi执行WB后(即寄存器x11更新后),紧接着xor才能执行DEC阶段(读取x11。
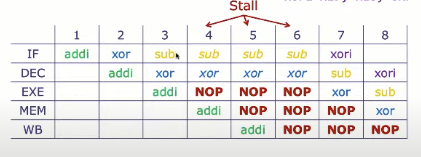
因此停顿会增加CPI 。
原理
从硬件角度来说,需要在流水线中添加什么。
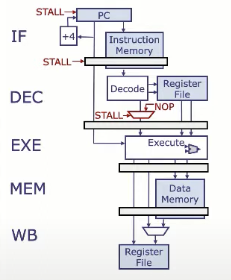
- 在处理器控制逻辑中增加一个新信号:STALL,用于判断是否需要停顿流水线。
- 当 STALL 等于 1 时,代表当前周期需要“阻塞”流水线,防止错误的数据传递。
- 禁止更新程序计数器(PC)和取指阶段的流水线寄存器(IF),从而冻结 IF 和 DEC 阶段
- 向执行阶段(EXE)注入一个 NOP 指令,比如
addi x0, x0, 0
如果当前解码阶段(DEC)的指令使用的源寄存器与执行(EXE)、访存(MEM)或写回(WB)阶段的目的寄存器冲突(除非是 x0),控制逻辑就会将 STALL 置为 1
Load & Store 造成的数据冒险
st x11, 8(x10) // 将 x11 的值写入地址 x10 + 8
ld x13, 4(x12) // 从地址 x12 + 4 加载到 x13reg[10] + 8 == reg[12] + 4, 如果两个地址相等怎么办?
我们的流水线对内存没有 hazard,是因为写操作在一个周期内完成,但在更复杂的处理器中,这种情况是个大问题。一般来说,load 和 store 之间的冒险可以在流水线或内存系统中解决
数据冒险策略: 旁路
addi x11, x10, 2
xor x13, x11, x12 // 用到了上一个指令的x11
sub x13, x15, x16
xori x19, x18, 0xF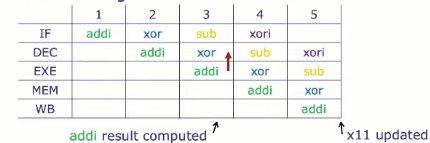
原理
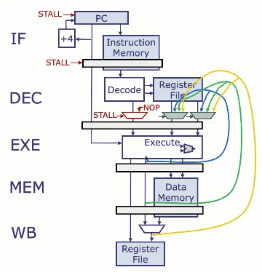
- 在DEC阶段的输出加入旁路多路选择器(bypass muxes)
- 将 EXE、MEM、WB 阶段的输出连接到这些 mux 的输入
- 如果DEC阶段的指令,其源寄存器与 EXE、MEM、WB 的目的寄存器相同,就旁路最新值给 DEC
- 寄存器
x0不需要旁路
- 寄存器
- 如果多个阶段都匹配(比如 x1 同时出现在 EXE 和 WB),选择最新的值,优先级为 EXE > MEM > WB, 这是因为: EXE 产生的是“最早/最近”执行完成的值;WB 是最晚的写回。
全旁路 vs 部分旁路
旁路机制是昂贵的(在硬件资源上),包括:
- 需要很多额外的数据通路(wires)
- 要在多个阶段传值
- 控制逻辑也更复杂
但我们不一定要做全旁路!我们可以选择 stall来解决某些 hazard,实现部分旁路(比如只从 EXE 和 WB 转发),其他情况直接STALL
如果已经实现了完全旁路的流水线,还需要 STALL 信号吗?
Solution: 是的,还需要!
加载-使用型停顿
一条 load 指令 读取内存后,紧随其后的指令立即使用这个加载的结果。这是一种典型的数据冒险,旁路机制不能完全避免它。旁路机制无法消除 load 指令的延迟,因为其数据直到 WB 阶段才可用。
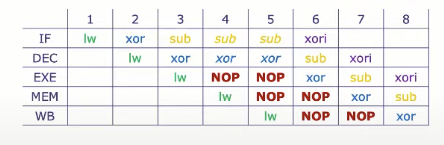
对于上面的例子
lw x11, 0(x10)
add x13, x11, x12
sub x17, x15, x16
xori x19, x18, 0xF对于 lw x1, 0(x2) 这样的指令, 数据要从 内存(MEM 阶段) 读取出来,通常直到 WB阶段 才能把这个数据提供给下一条指令。也就是说,所以如果下一条指令在 EXE 阶段 就需要 x1 的值,那它还没准备好!
从 WB 阶段进行旁路(bypass)仍然能节省一个周期。解释:如果你 没有 WB → EX 的 bypass,那么你必须等 lw 完整写回之后,下一条指令再解码。如果你 有 WB 旁路 ,那么只需 stall 一拍,下一条指令就能直接从 WB 拿到数据,不用再等一个周期读寄存器。
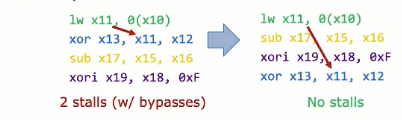
编译器也能帮忙
实际编译器也能帮点忙,如果编译器知道不相关的指令,那么他会将前后依赖的指令隔离远一些。
控制冒险
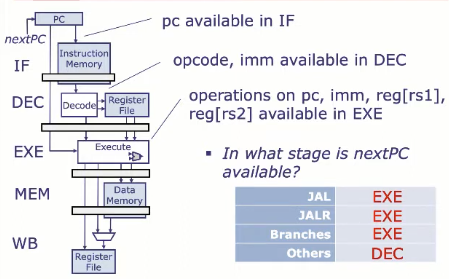
要计算下一条指令地址(nextPC),我们需要什么信息?
- 指令类型(opcode),因为不同的跳转方式 nextPC 算法不一样
- JAL:跳转并链接。nextPC = PC + immJ, 立即数是偏移量,目标地址是固定可算的。在 EXE阶段 就可以算出 nextPC
- JALR:寄存器跳转。nextPC = { (reg[rs1] + immI)[31:1], 0 },目标地址依赖于寄存器 rs1 的值,必须等到 EXE 阶段 才能确定 nextPC
- 分支指令: nextPC = brFun(reg[rs1], reg[rs2]) ? pc + immB : pc +4。分支条件需要比较 rs1 和 rs2 的值, 通常在 EXE 阶段 执行比较(brFun)
- 其他指令(非跳转): nextPC = PC + 4,在DEC阶段可以确定。
控制冒险策略: 停顿
loop:
addi x13, x11, -1
sub x14, x15, x16
bne x13, x0, loop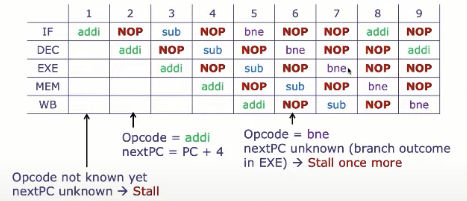
CPI = 7 cycles / 3 instructions !!!
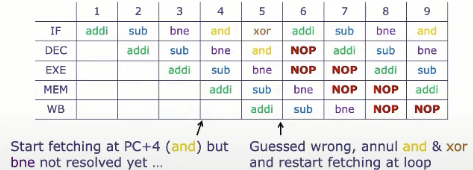
控制冒险策略: 推测执行
loop:
addi x13, x11, -1
sub x14, x15, x16
bne x13, x0, loop
and x16, x17, x18
xor x19, x20, x21假设bne没有采纳

假设bne被采纳
原理
分支取消(branch annulment)
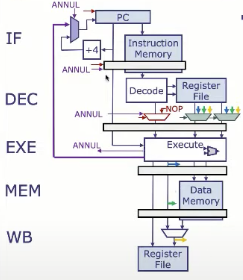
当 EXE 阶段检测到当前指令是跳转指令或分支条件成立时,此时流水线才真正知道应该跳转到案例,所以EXE阶段会计算出正确的nextPC,同时发出一个控制信号ANNUL=1,表示之前的IF和DEC阶段的指令无效。向 IF/DEC 和 DEC/EXE 的流水线寄存器写入 NOP(空操作),取消当前处于 IF 和 DEC 阶段的指令。将正确的跳转目标地址(nextPC)写入程序计数器 PC, 流水线就重新“对齐”到正确的执行路径。
停顿与推测执行的交互
假设在同个周期,由于控制冒险EXE想要取消DEC和IF,而由于数据冒险DEC想要停顿。举个例子,假设bne被采纳
loop:
addi x13, x11, -1
lw x14, 0(x15)
bne x13, x0, loop
and x16, x14, x18
xor x19, x20, x21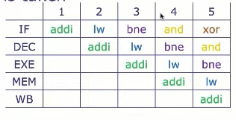
and想要停顿,而bne想要取消;那么谁的优先级高? ANNUL还是STALL?
答案是:ANNUL,因为bne是更早的指令。
总结
我们将所有的策略放在一起的例子

在流水线处理器中,暂停(stalling) 是一种通用的方法,可以应对所有类型的流水线冒险(data/control hazards),虽然实现简单,但会降低每条指令的平均周期数(CPI)。为提升性能,我们通常采用更高效的机制:
- 旁路(bypassing) 用于处理数据冒险,减少不必要的暂停,从而改善 CPI;
- 推测执行(speculation) 用于应对控制冒险(如分支),通过预测控制流方向提前取指令,也有助于降低 CPI。
不过,推测只有在预测准确时才有效。掌握暂停、旁路和推测三种机制,基本就能分析一般的流水线处理器的冒险处理策略了。