Lec 21 处理器流水线
简介
流水线处理器在计算机架构中提供了终极挑战。
- 严格的正确性要求
- 为了实现流水线处理,需要进行指令的推测执行
- 需要处理各种反馈
- 目标是在给定面积和功耗的预算内实现最高性能
回想下单指令的处理器
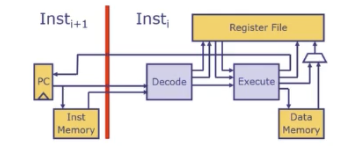
- 对于非加载型指令,我们只需要fetch和Execute两个阶段
- 对于加载型指令的,除上面以为还需要Loadwait(执行和写回阶段之间增加一个等待周期,等待内存操作完成)
假设20%的是加载指令,内存延时是1个周期,那么平均CPI是多少?
A:2 * .8 + 3 * .2 = 2.2;如果内存操作延时比较大,结果会更加糟糕。
流水线指令问题
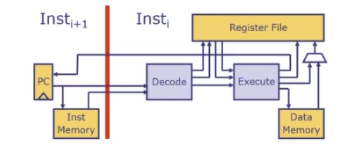
控制冒险:
i+1的指令在需要解码到i指令时候才知道,所以我们需要取哪条指令呢?- 解决思路: 通过推测,假如预测失败则进行恢复。如果跳转指令不超过25%,意味着至少75%的几率你是对的。比如指令是0x100大胆推测下一条指令是0x104
数据冒险:
i指令可能独立于i-1指令,因此他必须等到i-1指令的所有效果,比如PC和内存,寄存器上面的状态等才能执行- 解决思路: 停顿
i指令直到依赖被解决。 - 有些停顿能够通过旁路技术节省掉,但这个方法需要提供额外的数据通路。
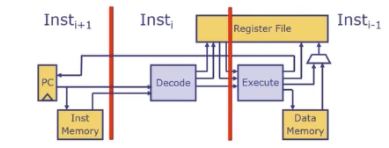
- 解决思路: 停顿
IMPORTANT
数据冒险是当指令数据值有依赖时出现;二控制冒险是PC有依赖时出现。
后面的计划
- 通过提供控制冒险的解决方案,开发一个2阶段流水线
- 通过提供数据冒险的解决方案,开发一个3阶段的流水线
控制冒险
我们想提供而处理器性能,要么减小每个程序的执行指令数目,要么减少每条指令的时钟周期,或者是提升时钟频率。因为我们构建了一个单周期处理器(single-cycle processor),并且我们不想要改变ISA,所以能够更改的只有时钟频率。如何做到呢? 就是通过将我们的处理器进行流水线化成多个阶段,并且尽量保持CPI接近1。
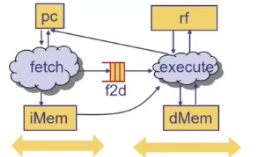
fetch阶段工作
- 从指令存储器(iMem)中读取当前程序计数器(PC)所指向的指令
- 投机性更新PC值:PC <- PC+4
- 将获取的指令发送到Exec阶段,这通常通过一个称为f2d(fetch-to-decode)的信号或者总线完成。
执行阶段工作
- 从f2d中挑选指令并执行,可能需要一个或者多个周期执行
这两个阶段是独立工作的除非有分支预测失败,执行重定向PC到正确的PC值。
我们需要提供一种解决方法,能够独立于每个阶段花费多少周期
用 FIFO 连接两阶段(弹性接口)
让 fetch 与 execute 通过一个 FIFO(f2d) 连接,而不是用裸寄存器硬连。这样两阶段各自是独立的模块、靠 FIFO 的 enq/deq 守卫握手(见 Lec 7 弹性流水线):
- fetch 规则:
f2d不满时,取 PC 处指令、投机地PC <- PC+4、把指令enq进f2d; - execute 规则:
f2d非空时,deq取出指令执行(可能多周期)。
好处是两阶段的耦合被 FIFO 解开——某一阶段慢一拍不会立刻破坏另一阶段的正确性,这正是“独立于每阶段花多少周期”的实现手段。
时序图与气泡(bubble)
把每周期各阶段在处理哪条指令画成时序图,会出现两类气泡(某阶段空转的空格):
- 多周期执行造成的气泡:若 execute 对某条指令要花多拍(如 load 等访存),fetch 的输出 FIFO 会被堵住、被迫等待,下游出现气泡——平均吞吐受最慢阶段限制(见 Lec 7 时序模块流水线)。
- 分支预测失败造成的气泡:fetch 投机地按
PC+4继续取指;当 execute 算出这是 taken 分支/跳转、需要重定向 PC 时,已经投机取入的错误指令必须作废(annul),对应周期变成气泡(见 Lec 16 分支取消)。
CPI 直觉:每次预测失败浪费的周期数 = 错误指令被作废前已占用的流水级数。预测越准、流水级越浅,气泡越少。降低分支气泡正是 Lec 22 分支预测要解决的问题;消除数据冒险气泡则靠 Lec 23 的旁路 + EHR。
后续:3 阶段与数据冒险
把 execute 进一步拆出 decode/register-read 等,得到更深的流水线后,数据冒险开始出现:后一条指令在前一条写回寄存器之前就读了它。解决办法是停顿(stall)+ 旁路(bypass)。旁路要在阶段间“同一周期既读又写”地传值,这需要 Lec 23 介绍的 EHR(Ephemeral History Register) 来精确控制寄存器在一个周期内的读写顺序。