Lec 9 广度优先搜索
- 图的定义
- 图的表示
- 图的路径问题
- 练习题
图的定义

- G = (V, E) 是一组定点和一组定点对
的集合 - 有向(Directed)边是有序对,例如
,其中$ u, v \in V$ - 无向边(Undirected)是无序对,例如{u, v}
V,即(u, v)和(v, u) - 在这门课我所说的图都是简单图
- 边是唯一的,例如(u, v)在E中值出现一次,并且
- 边是不同顶点对,即对于(u, v)
E, - 简单图意味着
,因为对于无向图来说 , 对于有向图来说
例子:
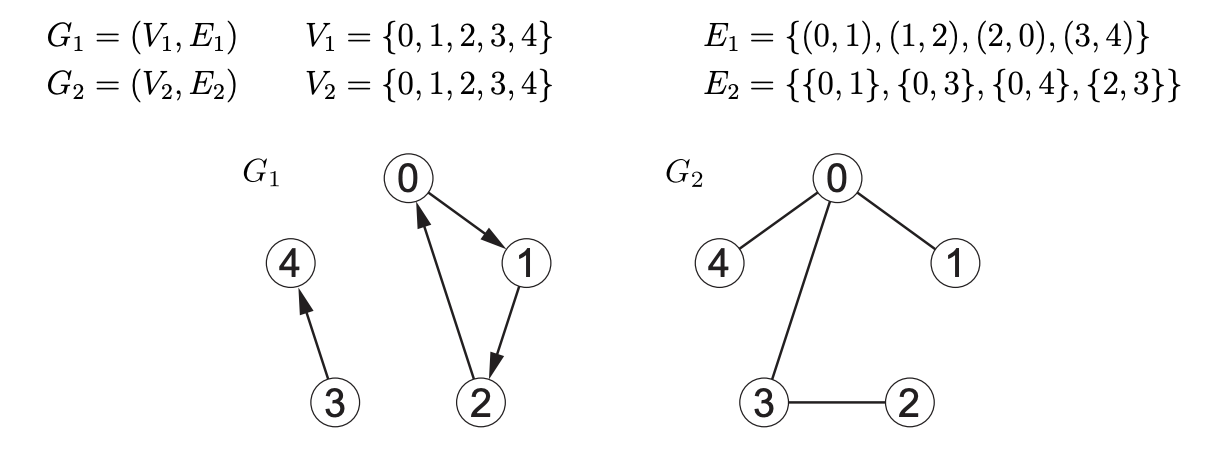
邻接集合
- 顶点
的出邻居集合是 - 顶点
的入邻居集合是 - 顶点
的出度是 - 顶点
的入度是 - 对于无向图而言,出度等于入度, 出邻居集合等于入邻居集合,我们一般会忽略+,比如
图的表示
- 要存储一个图 G=(V,E),我们需要存储所有顶点 u∈V 的出边
。 - 首先,通常来说需要一个Set数据结构
将每个顶点 u 映射到 ,里面存储着邻接顶点。 - 然后对于每个 u,需要在另一个称为邻接表的数据结构中存储
。我们并没有显式存储顶点对,而只是存储邻接顶点。 - 当顶点被唯一打上标签0到|V|-1, 常用大小为|V|直接访问数组(direct access array),每个槽指向标签对应标签的顶点的邻接表。否则,如果不是用这种方式打标签,则通常用哈希表来存储
,然后,通常将每个邻接表 Adj(u) 存储为一个简单的无序数组,数组中的元素是顶点 u 的出边。 - 对于常见表示法,
的大小是 ,而每个 的大小是 。 - 由于根据握手引理,
,图可以用 的空间存储。 - 因此,对于图上的算法,线性时间将意味着
(相对于图的大小来说是线性的) - 以下是使用直接访问数组作为顶层集合并用数组表示每个邻接表的图 G1 和 G2 的邻接表表示

总的来说有几种方法表示
- 边的列表
- 邻接矩阵
- 邻接表法
使用数组作为邻接表是一种非常合适的数据结构,如果你只需要循环遍历与一个顶点相关的边(这将是我们在本课程中讨论的所有算法的情况,因此这是我们默认的实现方式)。每条边在任何邻接表中出现的次数最多为两次,因此使用数组实现的邻接表表示的大小是 Θ(|V| + |E|)。
这种表示的一个缺点是,确定图中是否包含给定的边(u, v)可能需要 Ω(|V|) 的时间来遍历表示顶点 u 或 v 的邻接表数组。我们可以通过使用哈希表来存储邻接表来克服这个问题,哈希表能够在期望的 O(1) 时间内支持边的检查,仍然只使用 Θ(|V| + |E|) 的空间。然而,我们的算法不需要这种操作,因此我们将假设使用更简单的基于无序数组的邻接表表示。以下是使用 Python 字典的 G1 和 G2 的表示,它们为外层 Adj 集合和内层邻接表 Adj(u) 都使用了哈希表

路径
我们研究图的主要目的就是想要研究图的路径问题。
路径问题定义
- 路径是关于点的序列
, 其中每一对有序顶点都满足 $(v_i, v_{i+1}) \in E $,对于所有的 成立 - 如果路径中没有重复定点,则路径是简单路径
- 路径的长度
是路径中边的数量。 - 从顶点u到顶点v的距离
是u到v的所有路径中最短路径的长度 - 强连通性:如果每个节点到图中的其他节点都存在路径,则称该图为强连通图。
- 每个连通的无向图也是强连通图,因为每个无向边同时也是出边
- (连通分量: 其实就是一个图里面并查集集合数量的多少,相当于一个图中有多少个连通图。)
图的路径问题
- 可达性问题,SINGLE_PAIR_REACHABILITY(G, s,t): 图G中是否存在
到 的路径? - 单对最短路径问题, SINGLE_PAIR_SHORTEST_PATH(G, s, t): 返回距离
和图G=(V, E)中s到t的最短路径。 - 单源最短路径问题,SINGLE_SOURCE_SHORTEST_PATH(G, s):返回所有的v的
和包括从s到每个v的最短路径的最短路径树。 - 我们不会展示解决所有这些问题的算法,而是展示一种O(|V|+|E|)时间内解决最难问题(sP)算法。
最短路径树
如何返回从源顶点s到图中每个顶点的最短路径?
- 许多路径的长度可能是
, 因此返回每条路径可能需要 时间 - 相反, 对于所有
,存储其父节点P(v): 从s到v的最短路径上的倒数数第二个顶点 - 设P(s)为空(从s 到 s的最短路径上没有倒数第二个顶点)
- 父节点集合构成了一棵最短路径属大小仅为O(|V|)!(即,从每个s可达的顶点逆向回溯到s的最路径)
BFS
如何计算所有
的 和 ?
- 存储
和 P(v) 到Set数据结构中,并将顶点 v 映射 距离 和 父节点 。 - 如果从 s 到 v 没有路径,不在 P 中存储 v,并将
设为 。
思路
- 按距离递增的顺序探索图的节点。
- 目标:计算层级集合(Level Set) $$L_i$$={v|v∈V 且 d(s,v)=i }(即,所有距离为 i 的顶点)。
- 声明: 每个
必须与 相邻(即 )。 - 声明: 任何出现在
中的顶点 j < i 不会出现在 中。
- 声明: 每个
- 不变量:对于所有 j < i,
和 P(v) 已经正确计算。
基础情况(i=1):
归纳步骤:计算
对于每个
对于每个顶点
将 v 加入
重复计算
设置
广度优先搜索通过归纳正确计算所有
这里简单表述一下,给定一个图,一个常见的查询是找到从查询顶点 s 出发通过路径可达的所有顶点。从 s 开始的广度优先搜索(BFS)会发现 s 的层次集合(Level Set),层次集合
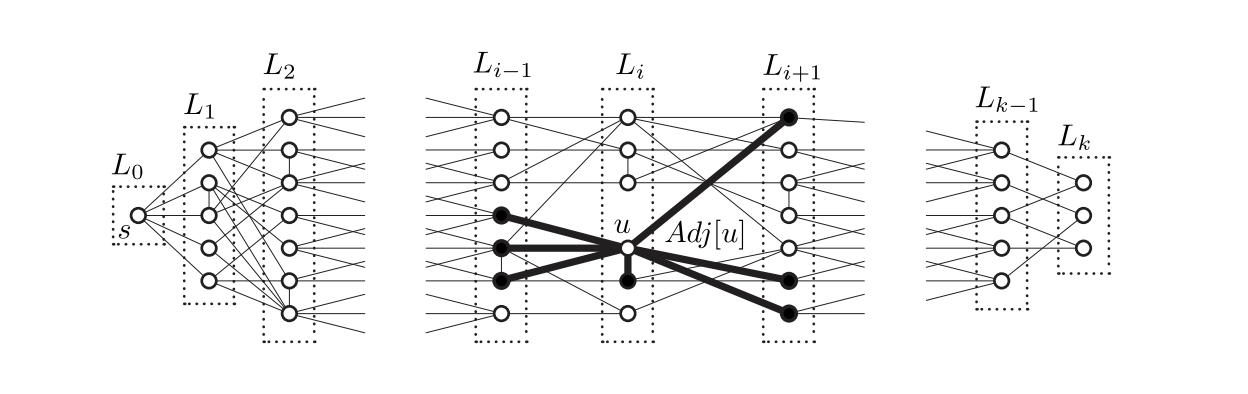
运行时间分析:
- 存储每个
在可以 L_i 时间迭代和 O(1) 时间插入的数据结构中(即动态数组或链表中) - 检查顶点 v 是否出现在任何 j < i 的
中可以通过检查 P 中的 v 实现。 - 维护
和 P 在支持字典操作的 O(1) 时间集合数据结构中(即直接访问数组或哈希表中)。 - 算法将每个顶点 u 添加到至多 1 个层级,并为每个
花费 O(1) 时间。 - 上界通过握手引理为
。 - 最后花费
时间为从 s 不可达的顶点 设置 。 - 因此广度优先搜索运行时间为线性时间
。
def bfs(Adj, s): # Adj: adjacency list, s: starting vertex
parent = [None for v in Adj] # O(V) (use hash if unlabeled)
parent[s] = s # O(1) root
level = [[s]] # O(1) initialize levels
while 0 < len(level[-1]): # O(?) last level contains vertices
level.append([]) # O(1) amortized, make new level
for u in level[-2]: # 第7行, O(?) loop over last full level
for v in Adj[u]: # O(Adj[u]) loop over neighbors
if parent[v] is None: # O(1) parent not yet assigned
parent[v] = u # O(1) assign parent from level[-2]
level[-1].append(v) # 第11行, O(1) amortized, add to border
return parent这里结合实际python代码实现表述一下时间复杂度。特别是,内层循环(第9行到第11行)可以执行多少次?一个顶点在第11行中最多被添加到任何层次一次,因此第7行的循环最多处理每个顶点v一次。第8行的循环遍历了顶点v的所有出边 deg(v)。因此,内层循环最多重复
最短路径问题
对于图 G1 和 G2,从顶点 v0 进行广度优先搜索得到以下父节点标签和层级集。
1 P1 = [0, L1 = [[0], 2 0, [1], 3 1, [2], 4 None, []] 5 None] 1 P2 = [0, L2 = [[0], 2 0, [1, 3, 4], 3 3, [2], 4 0, []] 5 0] []我们可以使用广度优先搜索返回的父节点标签,通过从 t 向后沿着父节点指针到达 s,来构建从顶点 s 到顶点 t 的最短路径。下面是用于计算从 s 到 t 的最短路径的 Python 代码,该代码在最坏情况下的运行时间也是 O(|V| + |E|)。
def unweighted_shortest_path(Adj, s, t):
parent = bfs(Adj, s) #O(V+E)
if parent(t) is None:
return None
i = t
path = [t]
while i != s: # O(V)
i = parent[i]
path.append(i)
return path[::-1] # O(V)练习题
给定一个无权图 G=(V,E),找到从节点 s 到节点 t 的一条边数为奇数的最短路径。
Solution:
构建一个新图G'=(V', E'),对于所有的顶点