Lec 3 排序
在Lec2 的练习题上,我们提前用序列接口实现了集合接口,发现时间复杂度比较高
- 排序
- 递归
排序
排序问题定义
- 输入: (静态)数组A,包含n个数字
- 输出:(静态)数组B,它是A的已排序的排序
- 排列: 数组B中的元素与数组A中的元素相同,但是顺序不同
- 排序:对于i=1,...,n 满足
- 排序的分类
- 破坏性排序: 如果排序操作覆盖了A,(而不是生成新的数组B作为A的已排序版本)
- 原地排序:如果排序操作使用
O(1)额外空间
排列排序
Permutation Sort,暴力解法
排列数量: 对于一个数组
A,存在n!种排列,其中至少有一种排列是已排序的。检查排序: 对于每一个排列,检查是否已排序的时间复杂度为 Θ(n)。
示例: 对于数组
[2, 3, 1],所有的排列有: [2, 3, 1] → {[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]}
def permutation_sort(A):
'''对 A 进行排序'''
for B in permutations(A): # O(n!)
if is_sorted(B): # O(n)
return B # O(1)排列排序分析:
- 正确性分析: 通过穷举所有可能性来证明正确性(暴力法)。
- 运行时间: Ω(n! · n),这是指数级的 😦
选择排序
在前缀A[: i+1]中找到一个最大值,与A[i]交换(找到最大值对应的索引,索引
),也就是说,也就是前i个数中找到最大值然后交换第i个数交换。 递归地对前缀A[:i]进行排序(递归交换)
- Ex: [8, 2, 4, 9, 3], [8, 2, 4, 3, 9], [3, 2, 4, 8, 9], [3, 2, 4, 8, 9], [2, 3, 4, 8, 9]
def selection_sort(A, i = None): # T(i)
"""Sort A[:i+1]"""
if i is None:
i = len(A) - 1
if i > 0:
j = prefix_max(A, i) # S(i)
A[i], A[j] = A[j], A[i] # O(1)
selection_sort(A, i-1) # T(i-1)
def prefix_max(A, i): # S(i)
"""return index of maxmum in A[:i+1]"""
if i > 0:
j = prefix_max(A, i-1) # S(i-1)
if A[i] < A[j]: # O(1)
return j
return i
# Non-recursive version
def selection_sort(A): # Selection sort array A
for i in range(len(A) - 1, 0, -1): # O(n) loop over array
m = i # O(1) initial index of max
for j in range(i): # O(i) search for max in A[:i]
if A[m] < A[j]: # O(1) check for larger value
m = j # O(1) new max found
A[m], A[i] = A[i], A[m] # O(1) swap分析
- prefix_max 分析:(找到最大值的前缀)
- 基本情况,对于i=0,数组只有一个元素,因此最大值的索引是i
- 归纳步骤,假设对于前 i 个元素的分析是正确的,即
prefix_max(A, i - 1)能正确返回 A[:i] 中最大值的索引,如果在 A[i] 中有更大的值,函数会返回 i;否则,返回之前的最大值索引 - S(n) = S(n-1) +
=> S(n) = cn
- selection_sort 分析: (找到0和i之间最大的元素,然后将它换位)
- 基本情况:对于i=0,数组只有一个元素,因此它是有序的
- 归纳步骤:假设对于前 i 个元素的排序是正确的,即
selection_sort(A, i - 1)能够将 A[:i] 排序。选择排序算法将当前未排序的部分中最大(或最小)的元素放置到正确的位置,确保最后一个元素是数组中最大的一个。然后,剩下的前 i 个元素仍然是有序的,由归纳法可知 - T(1) =
, T(n) = T(n-1) + - 代换(猜测): T(n) =
, ,满足,猜对了。 - 根据递归树: n个节点链,每个节点工作量为
,
- 代换(猜测): T(n) =
插入排序
跟选择排序是相反的动作,一个是把要排的东西放在右边(选择排序),一个是放在左边(小的往前挪)。
递归对前缀A[:i]进行排序
假设前缀A[:i]已经排好序,通过重复swap来对A[:i+1]进行排序
- Ex: [8, 2, 4, 9, 3], [2, 8, 4, 9, 3], [2, 4, 8, 9, 3], [2, 4, 8, 9, 3], [2, 3, 4, 8, 9]
def insertion_sort(A, i = None):
"""Sort A[:i+1]"""
if i is None: i = len(A) - 1
if i > 0:
insertion_sort(A, i-1)
insert_last(A, i)
def insert_last(A, i):
"""Sort A[:i+1] assuming sorted A[:i]"""
if i > 0 and A[i-1] > A[i]:
A[i], A[i-1] = A[i-1], A[i]
insert_last(A, i-1)insert_last分析:基本情况, 对于i=0,只有一个元素,因此是有序的
归纳步骤: 假设对于某个位置i,数组的前i个元素已经是有序的。如果当前元素A[i] > A[i-1],则数组仍然是有序的;否则,交换两者,确保前i个元素仍然有序
insertion_sort分析:- 基本情况,对于i=0时, 数组只有一个元素,因此已经是有序的。
- 归纳步骤,假设对i是正确的,算法通过归纳排序A[:i],然后
insert_last正确地排序剩下的部分(如上所证明)
归并排序
这是一种用于排序大量项目的渐近更快的算法。该算法递归地对数组的左半部分和右半部分进行排序,然后在线性时间内合并这两部分。因此,归并排序的递推关系为 T(n) = 2T(n/2) + Θ(n),其解为 T(n) = Θ(n log n)
- 递归地对数组的前半部分和后半部分进行排序(假设数组长度是2的幂)
- 将排序后的两部分合并成一个排序好的数组(使用双指针算法)。
def merge_sort(A, a = 0, b = None): # T(b - a = n)
'''Sort A[a:b]'''
if b is None:
b = len(A) # O(1)
if 1 < b - a: # O(1)
c = (a + b + 1) // 2 # O(1)
merge_sort(A, a, c) # T(n / 2)
merge_sort(A, c, b) # T(n / 2)
L, R = A[a:c], A[c:b] # O(n)
merge(L, R, A, len(L), len(R), a, b) # S(n)
def merge(L, R, A, i, j, a, b): # S(b - a = n)
'''Merge sorted L[:i] and R[:j] into A[a:b]'''
if a < b: # O(1)
if (j <= 0) or (i > 0 and L[i - 1] > R[j - 1]): # O(1)
A[b - 1] = L[i - 1] # O(1)
i = i - 1 # O(1)
else: # O(1)
A[b - 1] = R[j - 1] # O(1)
j = j - 1 # O(1)
merge(L, R, A, i, j, a, b - 1) # S(n - 1)分析
merge分析
- 基本情况: 当n=0,数组是空的,所以显然正确
- 归纳,假设对于n是正确的,数组A[r]中的元素必须是L和R剩余前缀中的最大元素,并且他们是排序的,取最后一个元素中的最大值就足够了;其余部分通过归纳进行合并
- S(0) =
,
merge_sort分析
- 基本情况n = 1时,数组有一个元素,因此是有序的
- 归纳: 假设对于k < n是正确的,算法通过归纳法对较小部分进行排序, 然后通过上述证明的合并函数将其合并成一个有序数组
- 代入法: 假设
- 递归树: 深度
的完全二叉树有n个叶子,每一层i都2^i个节点,每个节点的工作量为 ,总工作量为
- 代入法: 假设
总结
插入排序和选择排序是常见的排序算法,适用于排序小数量的项,因为它们易于理解和实现。这两种算法都是增量式的,即它们维护并扩展一个已排序的子集,直到所有项都被排序。它们之间的区别很微妙:
- 选择排序 维护并扩展一个已排序的子集,其中包含最大的 i 项。
- 插入排序 维护并扩展一个已排序的子集,其中包含前 i个输入项。
插入排序和选择排序都是原地算法,意味着它们可以在额外空间上使用最多一个常数单位。对数组执行的唯一操作是对元素对进行比较和交换。插入排序是稳定的,意味着具有相同值的项在排序后的数组中将保持与输入数组中相同的顺序。相比之下,这种选择排序的实现是不稳定的。例如,输入 (2, 1, 1’) 会产生输出 (1‘, 1, 2)
归并排序在合并两个部分时使用了线性量的临时存储(temp),因此它不是原地算法。虽然存在一些不使用额外空间进行合并的算法,但这些实现比归并排序算法复杂得多。归并排序是否稳定取决于实现如何在合并时处理相同值。
递归
求解递归关系
- 替代法(Substitution): 猜测一个解,然后用代表函数替换,验证递推关系是否成立。
- 递推树(Recurrence Tree): 画出表示递归调用的树形图,并在节点上求和计算。
- 主定理(Master Theorem): 用于求解许多递推关系的公式
主定理
主定理提供了一种解决递归关系的方法,其中递归调用通过一个常数因子减少问题规模。给定一个形式为 T(n) = aT(n/b) + f(n) 且 T(1) = Θ(1) 的递归关系,其中分支因子 a ≥ 1,问题规模缩减因子 b > 1,以及渐近非负函数 f(n),主定理通过比较 f(n) 和
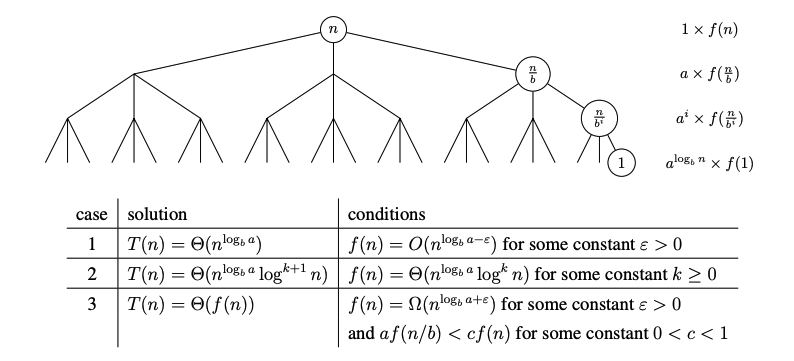
当f(n)是一个多项式时,主定理变得更加简洁,此时地推关系为

练习题
根据递推式给出时间复杂度
给出二分搜索的递归式,并求解
Solution: T(n) = T(n/2) + O(1) 因此T(n) = O(log n) 根据主定理的Case 2
T(n) = T(n-1) + O(1)
Solution: T(n) = O(n),长度为n的链表,每个节点O(1)的工作量
T(n) = T(n-1) + O(n)
Solution: T(n) = O(n^2), 长度为n的链表,每个节点O(k)的工作量,其中k是节点所在高度
T(n) = 2T(n-1) + O(1)
Solution: T(n) = O(2^n) ,高度为n的二叉树,每个节点O(1)的工作量
T(n) = T(2n/3) + O(1)
Solution: T(n) = O(log n), 长度为
T(n) = T(n/2) + O(n)
Solution: T(n) = O(n), 长度为
T(n) = 2T(n/2) + O(nlog n)
Solution: T(n) = O(
T(n) = 4T(n/2) + O(n)
Solution: T(n) = O(