lec 15 动态规划 I: SRTBOT
Outline
- 复习
- 概念
- 示例:归并排序
- 示例:Fibonacci数列
- 示例:DAG最短路径问题
- 示例:保龄球得分问题
- 练习题
复习
如何解决一个算法问题?
Solution:
- 将问题规约(reduce)到你已经熟悉的问题上(用数据结构或者算法)
| 搜索数据结构 | 排序算法 | 图算法 |
|---|---|---|
| 列表 | 插入排序 | BFS |
| 链表 | 选择排序 | DAG松弛(DFS+Topo) |
| 动态数组 | 归并排序 | Dijkstra |
| 直接访问数组 | 计数排序 | Bellman-Ford |
| 哈希表 | 基数排序 | Johnson |
| AVL树 | 堆排序 | |
| 二叉堆 |
设计你自己的递归算法
- 固定大小的程序解决任意输入
- 需要循环或递归,通过归纳分析
- 递归函数调用:图中的顶点,如果B调用A,则从A → B有有向边
- 递归调用的依赖图必须是无环的(如果能终止)
- 根据图的形状分类
类型 图 暴力解法 星型(枚举所有可能) 减而治之 链 分而治之 树 动态规划 DAG 贪心/增量 子图
□
概念
动态规划(Dynamic Programming )在子问题依赖形成有向无环图而不是树的情况下,推广了分治类型的递归。动态规划通常应用于优化问题,在这些问题中,您要最大化或最小化一个标量值,或者计数问题,在这些问题中,您需要计数所有可能性。
递归算法范式
SRTBOT,这其实是MIT教授给这种范式取的名字,将每个步骤的第一个字母单独拎出来拼凑而成。用于如何通过递归解决问题,大致步骤如下。
- Subproblem definition——定义子问题
, 定义参数描述子问题的含义 - 比如输入的子集:前缀、后缀,连续子序列
- 比如记录部分状态:通过递增一些辅助变量来添加子问题
- Relate subproblem solutions recursively——递归关联子问题
- 比如
- 比如
- Topological order on subproblems(=> subproblem DAG)——论证子问题构成了一个DAG
- Base cases of relation——关系基本情况
- Original problem solution via subproblem(s) ——从子问题的解中计算原始问题的解
- 可能使用父指针来恢复实际解,而不仅仅是目标函数。
- Time Analysis——时间复杂度分析
, 或者如果 对于所有 成立,那么|X|·O(W),work(x) 衡量关系中的非递归部分
一旦选择了子问题并找到依赖关系的有向无环图(DAG),解决问题有两种主要方法,这两种方法在功能上是等效的,但实现方式不同。
- 自顶向下的方法从根节点(没有入边的顶点)开始评估递归。在每次递归调用结束时,将计算出的子问题的解记录到备忘录中,而在每次递归调用开始时,检查备忘录以查看该子问题是否已被解决。
- 自底向上的方法根据子问题依赖的有向无环图的拓扑排序顺序计算每个子问题,同时记录每个子问题的解,以便用于解决后续子问题。
通常,正确构造的子问题,其拓扑排序顺序是显而易见的,特别是当子问题仅依赖于参数较小的子问题时,因此,无需使用深度优先搜索来查找这种顺序。
自顶向下是一种递归视图,而自底向上则展开了递归。这两种实现都是有效的,且经常被使用。两种实现都使用备忘录来记住先前子问题的计算。虽然通常会备忘所有已评估的子问题,但在子问题按“轮次”出现时,也可以备忘更少的子问题
示例:归并排序
问题描述以及思路
问题描述: 将一个无序的数组或列表按照特定顺序(通常是从小到大)重新排列。
💡关键思想:它将数组分成两半,递归的对两个子区间进行归并排序,最后将两个已排序的子区间合并成一个有序区间。
对大小为n的数组A进行归并排序Merge_Sort(A),用SRTBOT的表达如下:
Subproblem:
Relation:
Topo order: 子数组的长度,不断增加(即
不断增大) Base case: S(i, i) = []
Original problem: S(0, n)
TIme:
在这个例子中,子问题DAG是一棵树(用分治法)
代码实现
示例:斐波那契数列
Fibonacci numbers: given n, compute
Suburbs:
, Relate:
Topo order: 增长i, for i = 1, 2, ..., n
Base case:
Orignial:
Time:
指数增长
复用子问题解
思路: Memoization备忘录
记录和复用子问题的解
- 通过维护一个map,子问题规模 --> 解
两个方法
- 至顶向下: 记录子问题的解并记录
- 至底向上: 通过拓扑顺序排序的顺序解除子问题
对于Fibonacci, n+1个子问题(顶点)以及 小于2n个依赖(边)
每个F(i)都需要做一次加法,因此,总的时间复杂度是O(n)
# 递归解(至顶向下)
def fib(n):
memo = []
def F(i):
if i < 2: return i
if i not in memo:
memo[i] = F(i-1) + F(i-2)
return memo[i]
return F(n)# 递归解(至底向上)
def fib(n):
F = {}
F[0], F[1] = 0, 1
for i in range(2, n+1):
F[i] = F[i-1] + F[i-2]
return F[n]一个潜在的问题是,Fib数可能增长到
位这么长,也就是说>> 机器字长w,也就是说需要多个字来表示一个数字。 - 这样一来加法操作需要分成多次按位加法来完成,每次加法的时间复杂度是
- 这样一来加法操作需要分成多次按位加法来完成,每次加法的时间复杂度是
非递归次数 *(标准加法 + 额外位操作) = 总的时间复杂度为
总的来说:
- 如果数值较小(在机器的字长 w 范围内),则时间复杂度主要由迭代次数 n 决定,即O(n)
- 如果斐波那契数值很大,每次加法需要按位操作,导致计算时间变为
示例:DAG最短路径问题
DAG SSSP(单源最短路径)问题: 给定一个DAG 和 源顶点s, 计算𝛿(s, v) for all v ∊ V
Subproblems: 𝛿(s, v) for each v ∊ V
Relate:
- 如果没有前驱节点,则路径长度为无穷大
Topo order:图G的拓扑排序
Base case:
Original: 𝛿(s, v) for all v ∊ V
Time:
- 每个顶点 vvv 的计算时间与其前驱顶点数量相关
DAG 最短路径问题也可以通过 边松弛算法 来求解。松弛算法的思想是:
- 这个过程是从边的起点 u 出发,检查所有指向 u 的边是否可以通过更新来找到更短路径。
- 边松弛的过程是逐步完成的,与动态规划的思想本质上是相同的,都是通过前驱节点的信息来更新当前节点的最短路径值
动态规划的计算可以理解为从顶点v的前驱集合
示例:保龄球得分问题
保龄球例子: 给定n个保龄球,0, 1, ... , n-1
- 保龄球
i有一个值 - 撞倒一个保龄球
i,会获得分 - 撞到2个保龄球
i和i+1,你将得到分 - 问题: 投掷0次或多次,使得目标是得到最大的分数
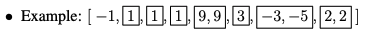
基于分治算法的SRTBOT框架分析
- Subproblems: B(i, j) = 从第i, i + 1 ... j - 1个保龄球最大总得分
- Relation:
- 要么m和m+1同时被击中,要么没有
- Topo order: 使
j-i增长 - Base Case:
- Original: B(0, n)
- Time =
这个算法效率不是太高,也不够通用,但是通过简单的改造实现同时击中3个球的情况
基于后缀的SRTBOT框架分析
Subprobs: B(i) = max score possible with starting pins
, for Relate:
- 暴力解法: 对于第一个保龄球,要么跳过,要么被单独击中,要么被连带击中
- 规约到更小的后缀和,要么是B(i+1) 或者是 B(i+2)
Topo: decreasing i for i = n, n-1, ..., 0
Base: B(n) = B(n+1) = 0
Original: B(0)
Time: θ(n) = θ(1) work * θ(n) #subprobs

# Bottom-up (iterative solution)
def bowl(v):
B = {}
B[len(v)] = 0
B[len(v) + 1] = 0
for i in reversed(range(len(v))):
B[i] = max(B[i+1], v[i] + B[i+1], v[i] * v[i+1] + B[i+2])
return B[0]
# Top-down (recursive down)
def bowl(v):
memo = {}
def B(i):
if i >= len(v): return 0
if i not in memo:
memo[i] = max(B(i+1), v[i] + B(i+1), v[i] * v[i+1] + B(i+2))
return memo[i]
return B(0)练习题
简化版二十一点(Blackjack)
我们定义一种简化的二十一点游戏,玩家与庄家之间进行。牌堆是一个包含 n 张牌的有序序列
,其中每张牌 是 1 到 10 之间的整数(与真实的二十一点不同,A 始终被视为 1 点)。二十一点是以轮次进行的。在每一轮中,庄家将从牌堆中抽取前两张牌(最初为 c1 和 c2),然后玩家将抽取接下来的两张牌(最初为 c3 和 c4),之后玩家可以选择是否再抽一张牌(称为“加牌”)。 如果玩家的手牌(即本轮玩家抽取的牌的总和)的值 ≤ 21 并且超过庄家的手牌值,则玩家赢得这一轮;否则,玩家输掉这一轮。当牌堆中剩余的牌少于 5 张时,游戏结束。
给定一个已知顺序的 n 张牌的牌堆,描述一个 O(n) 时间复杂度的算法,以确定玩家通过与庄家进行简化二十一点游戏可以赢得的最大轮数。
文本对齐
文本对齐是将一系列 n 个用空格分隔的单词放入固定宽度 s 的列中,以最小化单词之间的空白量的问题。每个单词可以用其宽度 (w_i < s) 表示。最小化一行的空白量的一个好方法是最小化该行的“坏度”。假设一行包含从 (w_i) 到 (w_j) 的单词,该行的坏度定义为:
良好的文本对齐应该将单词分成多行,以最小化包含单词的所有行的坏度总和。立方权重会对行中的大空白量进行严重惩罚。Microsoft Word 使用贪婪算法来对齐文本,该算法在移动到下一行之前,尽可能多地将单词放入一行。这种算法可能导致一些非常糟糕的行。相反,LATEX 使用动态规划格式化文本,以最小化这种空白量度量。
描述一个 (O(n^2)) 的算法,将 n 个单词适配到宽度为 s 的列中,以最小化所有行的坏度总和。