Lec 2 数据结构
- 序列接口
- 序列接口的实现
- 集合接口
- 集合接口的实现
数据结构 是用于存储数据的方式,并提供对数据的操作的算法。
接口(interface),也称ADT(抽象数据类型,API是一组操作的集合。接口定义了哪些操作是支持的(或者说适合什么问题),而数据结构则是如何支持这些操作的表示方式(即解决方案)
这节课主要关注两个接口:序列(Sequence)和集合(Set)
序列接口
序列维护按外部顺序排列的数据项集合,其中每个存储的项在序列中都有一个位置(rank),包括第一个项和最后一个项。所谓的外部顺序,我们的意思是,第一个项之所以是“第一个”,不是因为该项本身的特性,而是因为某个外部因素将其放在了那里。序列是堆栈和队列的泛化,它们支持一组序列操作的子集
序列的容器操作
| 操作 | 描述 |
|---|---|
build(X) | 根据给定的可迭代对象 X 从中构建序列 |
len() | 返回存储的项的数量 |
序列的静态操作
| 操作 | 描述 |
|---|---|
iter_seq() | 逐个按顺序返回存储的项 |
get_at(i) | 返回第 i 个项 |
set_at(i, x) | 替换第 i 个项为 x |
序列的动态操作
以下是按照您的要求整理的表格,展示了与数据结构接口相关的操作:
| 操作 | 描述 |
|---|---|
insert_at(i, x) | 在第 i 个位置插入 x |
delete_at(i) | 删除并返回第 i 个项 |
insert_first(x) | 将 x 插入为第一个项 |
delete_first() | 删除并返回第一个项 |
insert_last(x) | 将 x 插入为最后一个项 |
delete_last() | 删除并返回最后一个项 |
会发现,如果中间插入或者删除元素,会触发后续的元素的移动。
序列接口的解决方案
链表
Linked List Sequence
- 指针数据结构(这与Python中的“列表”无关)
- 每个项存储在一个节点中,该节点包含一个指向序列中下一个节点的指针
- 每个节点有两个字段:
node.item和node.next - 通过重新链接指针可以简单地操作节点!
- 维护指向序列中第一个节点的指针(称为头节点)
- 现在可以在Θ(1)时间内从前面插入和删除!太棒了!
- 但现在
get at(i)和set at(i, x)都需要O(n)时间... 😦 - 我们能兼顾两者的优点吗?可以!(某种程度上...)

静态数组
- 数组非常适合静态操作! 每次get_at/set_at/len 都用O(1)
- 每次build/iter_seq()则需要O(n), 内存分配模型而言,分配大小为n的数组需要花费O(n)的时间
关键: Word RAM的计算模型
- 内存 = w-位的机器字的列表
- 数组 = 内存中连续的块
- array[i]
memory[address(array) + i] - 访问数组的任何位置都是用O(1)的时间
- 但在动态操作方面不太理想...
- (为了保持一致性,我们保持数组已满的不变量)
- 然后插入和移除项需要:
- 重新分配数组
- 移动修改项之后的所有项

动态数组
数组的动态序列操作需要与数组长度成线性时间的关系。
插入操作
是否有其他方法可以在不支付每次添加元素时的线性开销的情况下向数组中添加元素呢?
思路:预分配额外的空间,以便每次动态操作时不需要重新分配空间。这样,插入一个新元素就可以简单地将其复制到下一个空槽中。这种妥协以额外的空间换取了常量时间的插入操作。但这种额外的分配是有界的;随着插入操作的重复进行,额外的空间最终会被填满,数组将需要重新分配并复制
- 定义填充率:
表示数据项与空间的比例 - 每当数组满时(r=1),分配
额外的空间以达到填充率 (e.g., 1/2),使得在下一次重新分配前必须插入 项 - 单次操作可能需要
时间进行重新分配 - 但是,任意
次操作序列都需要花费 时间 - 因此每次操作平均需要
时间
参考Python列表的做法,我们假设n = 列表大小,
从空列表开始insert_last(),假如我们调用了n次,则会在n = 1, 2, 4, 8, 16...时重新分配空间
则重新分配空间花销 = insert_last()只需要O(1)的时间复杂度
摊销分析
- 一种数据结构分析技术,用于将成本分摊到多次操作中
- 如果 k 次操作的成本至多为 kT(n),则操作的摊销成本为 T(n)
- “T(n) 摊销”大致意味着在多次操作中“平均” T(n) 时间
- 插入动态数组的操作需要 Θ(1) 摊销时间
删除操作
如果我们还想从数组末尾移除元素呢?从末尾弹出最后一个元素可以在常量时间 Θ(1) 内完成,只需减少存储的数组长度(Python 确实这么做)。然而,如果从大型列表中移除大量元素,未使用的额外分配可能会占用大量的内存,这部分内存将无法用于其他用途。当数组的长度变得足够小时,我们可以将数组的内容转移到一个新的、更小的内存分配中,以便释放较大的内存分配。
这个新的分配应该有多大呢?
思路:当 r <
Python 列表的 append 和 pop 操作的摊销时间复杂度为 O(1),其他操作可能为 O(n)!
总结

集合接口
| 操作 | 描述 | |
|---|---|---|
| 容器操作 | build(X) | 给定一个可迭代对象 X,从 X 中的项目构建集合。 |
len() | 返回存储的项目数量。 | |
| 静态操作 | find(k) | 返回键为 k 的存储项目。 |
| 动态操作 | insert(x) | 将 x 添加到集合中(如果已经存在键为 x.key 的项目,则替换该项目)。 |
delete(k) | 删除并返回键为 k 的存储项目。 | |
| 顺序操作 | iter ord() | 按键顺序一个接一个地返回存储项目。 |
find min() | 返回键最小的存储项目。 | |
find max() | 返回键最大的存储项目。 | |
find next(k) | 返回键大于 k 的最小存储项目。 | |
find prev(k) | 返回键小于 k 的最大存储项目。 |
集合接口的解决方案
无序数组
在Lec2的练习题中,我们用序列接口实现了集合接口,将数据项以任意顺序存储在数组中可以实现一个(效率不是很高的)集合。我们会在接下来的5讲来优化这个时间复杂度。其中最简单的一个就是有序数组
有序数组
按键递增顺序存储数据项的优势:
- 更快的查找最小值/最大值(在数组的第一个和最后一个索引处)
- 通过二分查找实现更快的查找:O(logn)
但是这个方法在动态操作上仍然不是很好(在数组中间操作,数据项仍然需要移动)
总结
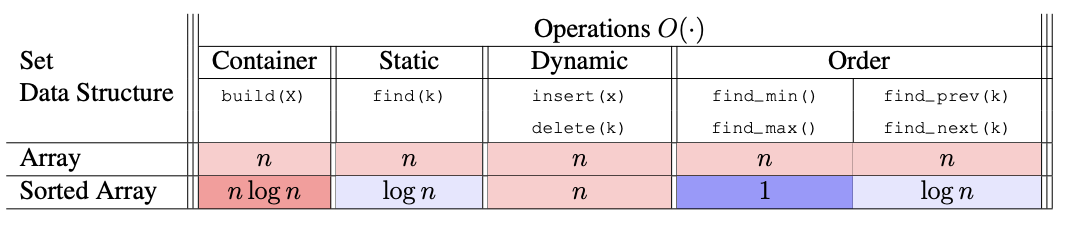
思考下,有序数组容器操作复杂度为nlogn, 如何进行构建的?
练习题
假设一个链表的最后一个节点的 next 指针指向链表中的某个较早节点,形成一个循环。给定一个指向链表头的指针(不知道链表的大小),描述一个线性时间算法来找出循环中的节点数。你能否在仅使用链表原有数据结构之外的常量附加空间的情况下完成这个任务?
Solution: 从链表头开始使用两个指针:一个慢指针和一个快指针。这两个指针交替遍历链表的节点,从快指针开始。在慢指针移动时走一步;在快指针移动时走两步,每次移动结束前检查当前节点。每次快指针访问一个节点时,检查它是否与慢指针指向的节点相同。如果它们相同,那么快指针一定是绕循环一圈,在循环中的某个节点 v 处与慢指针相遇。现在,为了找到循环的长度,只需让快指针继续遍历链表,直到返回到 v,同时计算沿途访问的节点数。
证明算法的线性时间复杂度:
- 在最坏情况下,找到相遇点需要遍历链表的每个节点,这个过程是线性的。
- 一旦相遇点找到,再次遍历循环节点的过程同样是线性的。
- 因此,整个算法的时间复杂度是线性的,即 O(n),其中 n 是链表中节点的总数。
给定一个数据结构实现了序列的接口,如何用这些序列接口实现集合接口呢(不管效率)
Solution:
def Set_from_Seq(seq):
class set_from_seq:
def __init__(self):
self.S = seq()
def __len__(self):
return len(self.S)
def __iter__(self):
yield from self.S
def build(self, A):
self.S.build(A)
def insert(self, x):
for i in range(len(self.S)):
if self.S.get_at(i).key == x.key:
self.S.set_at(i, x)
return
self.S.insert_last(x)
def delete(self, k):
for i in range(len(self.S)):
if self.S.get_at(i).key == k:
return self.S.delete_at(i)
def find(self, k):
for x in self:
if x.key == k:
return x
return None
def find_min(self):
out = None
for x in self:
if (out is None) or (x.key < out.key):
out = x
return out
def find_max(self):
out = None
for x in self:
if (out is None) or (x.key > out.key):
out = x
return out
def find_next(self, k):
out = None
for x in self:
if x.key > k:
if (out is None) or (x.key < out.key):
out = x
return out
def find_prev(self, k):
out = None
for x in self:
if x.key < k:
if (out is None) or (x.key > out.key):
out = x
return out
def iter_ord(self):
x = self.find_min()
while x:
yield x
x = self.find_next(x.key)
return set_from_seq习题课(1)
设 XXX 是一个随机变量,表示在抛掷三次公平硬币后得到的正面数。设 YYY 是一个随机变量,表示抛掷两个公平六面骰子的结果,并将它们的值相乘。请计算以下期望值。
(a) E [X] (b) E [Y ] (c) E [X + Y ]
Solution: (a) 3/2 = 1.5, (b)
令A=600/6, B = 60 mod 42,判断下面的表达式
(a) A ≡ B (mod 2) (b) A ≡ B (mod 3) (c) A ≡ B (mod 4)
(a)A mod 2 = 100 mod 2 = 0, B mod 2 = 18 mod 2 = 0 由于 A mod 2 = B mod 2 所以 A ≡ B (mod 2),其他不成立
用归纳法证明
成立
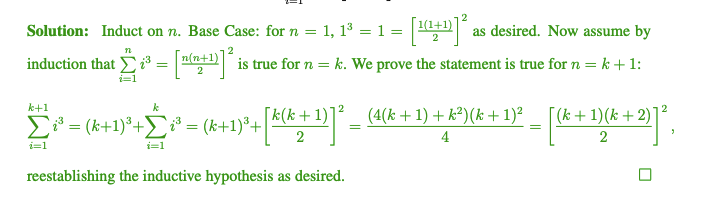
通过归纳法证明每个连通的无向图 G=(V,E) 其中|E| = |V| - 1 是无环的。
Solution: 对顶点数k进行归纳。基本情况:k = 1, 一个包含一个顶点和零条边的图显然是无环的。现在假设对于任何有 k 个顶点和 k - 1条边的连通图,这一命题成立,并考虑一个包含k+1个顶点和k条边的连通图G。因为G是连通的,所以每个顶点至少连接一条边。由于每条边都连接两个顶点,所以G中的顶点平均度数是
函数行为的渐进性
按照复杂度一下函数进行排序,如果是紧确界的内用集合表示
比如 f1 = n; f2=
, f3 = , 答案为{f2, {f1, f3}} 或者是{f2, {f3, f1}}
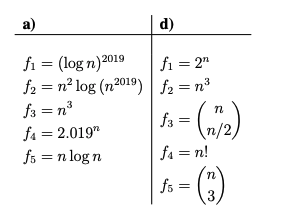
Solution:
b) ({f2, f5}, f3, f1, f4), 由
将k = n/2 代入最终得到
给定一个数据结构 D,支持以下四种基本的序列操作,每种操作的时间复杂度为 O(1)
D.insert_first(), D.delete_first(), D.insert_last(), D.delete_last(),描述用这几个低级别操作实现高级别操作的算法。
(a) swap_ends(D):交换序列中第一个元素和最后一个元素的操作,并且时间复杂度为 O(1)\。
(b) shift_left(D, k):将序列中前 k个元素移动到序列的末尾,并且时间复杂度为 O(k)。在操作后,第 k 个元素应该成为最后一个元素,第 (k+1)个元素应该成为第一个元素。
solution:
# (a)
def swap_ends(D):
x_first = D.delete_first()
x_last = D.delete_last()
D.insert_first(x_last)
D.insert_last(x_first)为了实现 shift_left(D, 1),我们可以删除第一个元素,并将其插入到序列的末尾,这样操作的时间复杂度为 O(1)。这样,序列中所有元素的相对顺序保持不变,除了第一个元素被移动到所有其他元素之后。因此,shift_left(D, 1) 是正确的。
然后,为了实现 shift_left(D, k),我们可以如上所述将第一个元素移动到末尾,然后递归调用 shift_left(D, k - 1),直到达到基本情况 shift_left(D, 1)。
通过归纳法,如果 shift_left(D, k - 1) 是正确的,那么将第一个元素移动到末尾会恢复正确性。shift_left(D, k) 的时间复杂度为 O(k),因为它会进行 O(k) 次递归调用,直到达到基本情况,每次调用执行常数时间的工作。
# (b)
def shift_left(D, k):
if (k < 1) or (k >len(D) - 1):
return
x = D.delete_first()
D.insert_last(x)
shift_left(D, k-1)问题 1-3:双端序列操作
动态数组可以实现一个支持最坏情况 O(1)时间复杂度的索引操作,以及在数组末尾进行插入和删除操作的接口,插入和删除操作的摊销时间复杂度为常数。然而,在动态数组的开头进行插入和删除操作效率较低,因为每个条目都必须被移动以保持顺序,这需要线性时间。
另一方面,链表数据结构可以支持在两端进行插入和删除操作,且在最坏情况下时间复杂度为 O(1),但代价是线性时间的索引操作。
证明我们可以兼得两者的优势:设计一个数据结构来存储项序列,支持最坏情况 O(1)时间复杂度的索引查找,同时在两端进行插入和删除操作的摊销时间复杂度为 O(1)。你的数据结构应使用 O(n) 的空间来存储 n 个项。
Sulution:
- 使用两个栈实现双端队列(deque)
- 一个简单的解决方案是使用两个栈来实现双端队列。
- 需要注意在从空栈弹出或向满栈压入时的处理。
- 在数组中间存储队列元素
- 另一种解决方案是在数组中间存储队列元素,而不是在数组开头。
- 当需要重新分配空间时,数组的开始和结束各保留一定数量的空槽,以保证线性时间的重建操作在每 Ω(n)次操作中只发生一次。
具体步骤
- 重新分配空间时:
- 例如,每次重新分配空间存储 n个元素时,将它们复制到长度为 m=3n 的数组的中间。
- 这样,可以在常数时间内在序列的开始或结束插入或删除元素。
- 插入操作:
- 如果在插入时没有空槽,至少有线性数量的插入操作发生自上次重建以来,因此可以负担得起重新构建数组。
- 删除操作:
- 如果删除一个元素使得数组中元素与数组大小的比率 n/m 低于 1/6,至少有 m/6=Ω(n) 次删除操作发生自上次重建以来,因此也可以负担得起重新构建数组。
这种方法保证了在每次线性时间重建之间有线性数量的操作,从而确保每个动态操作的摊销时间至多为 O(1)。
- 支持数组索引的常数时间:
- 维护数组中最左边的元素的索引位置 i 和存储在数组中的元素数量 n。
- 这两个变量可以在每次更新中以最坏情况的常数时间维护。
- 使用零索引访问队列序列中的第 j个元素时,确认 i + j < n,并在最坏情况下常数时间内返回数组容器中索引为 i+j的元素。
问题 1-4:Jen 和 Berry 的冰淇淋车
Jen 把她的冰淇淋车开到当地的小学,正值课间休息。所有的孩子都急忙排队到她的车前。Jen 被学生的数量(有 2n 个学生)弄得不知所措,于是她打电话给她的助手 Berry,让他开着冰淇淋车来帮忙。Berry 很快就到达并把车停在学生队伍的另一端。他提议卖冰淇淋给队伍最后一个学生,但其他学生反对:“最后一个学生还是最后一个!这不公平!”
学生们决定,最公平的解决方法是让队伍后半部分的学生(离 Jen 最远的 n 个孩子)反转顺序,排到 Berry 的车前,这样原队伍最后一个学生就变成 Berry 队伍最后一个学生,原队伍第 n+1 个学生变成 Berry 的第一个顾客。
(a) 给定一个包含 2n 个孩子名字的链表,按原始队伍顺序排列(链表的第一个节点包含队伍第一个孩子的名字),描述一个时间复杂度为 O(n)的算法来修改链表,反转链表后半部分的顺序。你的算法在操作过程中不应该创建任何新的链表节点或实例化任何新的非常量大小的数据结构。
(b) 编写一个 Python 函数
reorder_students(L)来实现你的算法。
Solution: (a)
将链表的后半部分节点的顺序反转分为三个阶段:
- 找到序列中的第 n 个节点 a(Jen 队伍的结束)。
- 对于从第 n+1 个节点 b 到第 2n 个节点 c 的每个节点 x,将 x 的 next 指针指向它在原始序列中的前一个节点。
- 将 a 的 next 指针指向 c,将 b 的 next 指针指向空。
找到第 n 个节点需要从链表头部开始遍历 next 指针 n−1 次,可以通过简单的循环在 O(n) 时间内完成。我们可以通过将链表的大小除以二来计算 n(链表的大小保证是偶数)。
为了改变序列后半部分的 next 指针,我们可以维护指向当前节点 x 和前一个节点 xp 的指针,初始值分别为 b 和 a。然后,记录当前节点 x 之后的节点 xn,将 x 重新链接到 xp(即 x 在 O(1) 时间内指向它之前的节点)。然后我们可以将当前节点改为 xn,并将前一个节点改为 x,保持下一个重新链接节点所需的属性。重复 n 次,将序列后半部分的所有 n 个节点重新链接,在 O(n) 时间内完成。
最后,在算法遍历链表时记住节点 a、b 和c,意味着在后半部分链表的前部和后部改变特殊的 next 指针只需 O(1) 时间,从而使整个算法的时间复杂度为 O(n)。
(b)
def reorder_students(L):
n = len(L) // 2 # find the n-th node
a = L.head
for _ in range(n - 1):
a = a.next
b = a.next # relink next pointers of last half
x_p, x, x_p = a, b
for _ in range(n):
x_n = x.next
x.next = x_p
x_p, x = x, x_n
c = x_p
a.next = c # relink front and back of last half
b.next = None
return