Lec 6 二叉树
一种几乎优于所有目前我们所了解的数据结构——二叉树
- 二叉树
- 应用: 集合
- 应用: 序列
二叉树
二叉树的每个节点有三个指针,也是一种基于指针的数据结构。节点的表示: Node.{item, parent, left, right}
例子:

性质
在一棵二叉树中,树的根节点没有父节点(例如:<A>),树的叶节点没有子节点(例如:<C>、<E> 和 <F>)
- <R>定义深度<R>(树中某个节点的范畴): 树中以 <R> 为根的节点 <X> 的深度(depth(<X>))为从 <X> 到 <R> 路径的长度 = #祖先的个数
- 比如<A>的深度是0, <B>,<C>的深度是1
- <R>定义高度<R>(树(包括子树)的范畴):定义节点 <X> 的高度(height(<X>))为以 <X> 为根的子树中任何节点的最大深度
- 比如, <C>,<E>,<F>的高度为0, 而<A>的高度为3
<R>关键思想<R>: 我们希望设计的操作在树的高度为 h 时能在 O(h) 时间内完成,并保持 h = O(log n),以保证效率。二叉树具有一种天然的顺序,称为<R>遍历顺序(traversal order)/ 中序遍历<R>节点 <X> 的左子树中的每个节点都在 <X> 之前,节点 <X> 的右子树中的每个节点都在 <X> 之后。这种遍历顺序通过递归实现:先列出左子树,再列出自身,最后列出右子树。每个节点只访问一次,整体运行时间为 O(n),例如,图中这棵树的遍历顺序为(<F>,<D>,<B>,<E>,<A>,<C>)
虽然目前遍历顺序还没有与节点中的数据绑定具体语义,但之后我们会利用它来实现诸如序列或集合等抽象数据接口。
遍历操作
二叉树的节点有一个自然顺序,这基于我们区分一个孩子为左孩子,另一个孩子为右孩子的事实。我们根据以下隐含特征来定义二叉树的遍历顺序:
- 节点 <X> 的左子树中的所有节点都在遍历时出现在 <X> 之前;
- 节点 <X> 的右子树中的所有节点都在遍历时出现在 <X> 之后。
<R>找第一个(Find first)<R>:即找到节点 <X> 子树遍历顺序中的第一个节点(与找最后一个节点是对称的)
- 如果 <X> 有左孩子,递归返回左子树中的第一个节点。
- 否则,<X> 是第一个节点,因此返回它。
- 运行时间为 O(h),其中 h 是树的高度。
- 例如:<A> 子树中的第一个节点是 <F>。
<R>找后继(FInd successor)<R>:找到节点 <X> 在遍历顺序中的后继节点(<R>与找前驱节点是对称的<R>)
- 如果 <X> 有右孩子,返回右子树中的第一个节点。
- 否则,向上遍历树(node = node.parent),直到找到一个祖先节点,<X>是在祖先节点左孩子上(node == node.parent.left)。这个祖先就是 <X> 的后继节点,将其返回。(假如要对一个没有右孩子的节点求后继,那我们说它肯定需要爬上树去找)
- 运行时间为 O(h),其中 h 是树的高度。
- 例如:<B> 的后继是 <E>,<R><E> 的后继是 <A><R>,<C> 的后继是 None。
- 根据对称性, 找前驱节点
- 如果<X>有左孩子,返回左子树的最后一个节点
- 否则,向上遍历树, 向上遍历树(node = node.parent),直到找到一个祖先节点,<X>是在祖先节点右孩子上(node == node.parent.right)。这个祖先就是 <X> 的前驱节点,将其返回。
动态操作
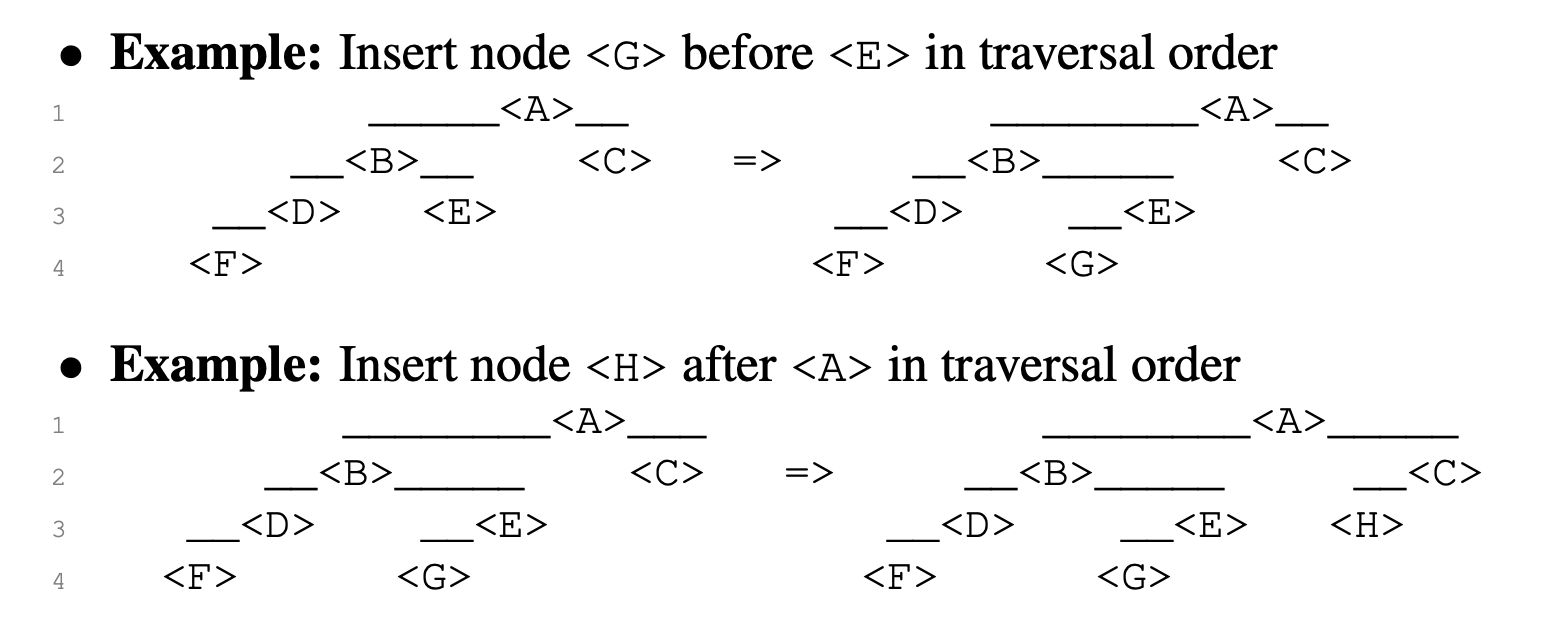
动态操作允许我们通过插入或删除叶子结点来修改二叉树结构,从而保持树的遍历顺序。比如,若要在遍历顺序中将新节点 <Y>插入到节点 <X> 之后(在 <X> 之前插入是对称操作),有两种情况如下。运行时间:O(h),其中 h 是树的高度。
- 如果 <X> 没有右孩子:将 <Y>作为 <X> 的右孩子。
- 如果 <X> 有右孩子:将 <Y>作为 <X> 的后继节点的左孩子(后继节点不能有左孩子)。【就是在右孩子树找第一个,同理,如果是在其之前插入, 就找左子树的最后一个】
从树中删除节点 <X> 的操作会根据 <X> 是否为叶节点而有所不同。如果 <X> 是叶节点,直接将其从父节点中断开即可,操作结束。若 <X> 不是叶节点,说明它至少有一个子节点,此时需借助遍历顺序中的前驱或后继节点来完成删除,有两种情况如下:
- 如果 <X> 有左孩子:与 <X> 的前驱节点交换数据项(node.item),然后递归地从前驱节点的位置继续删除。
- 如果 <X> 没有左子节点但有右子节点,则找到它的后继节点,与其交换数据,然后递归地从后继节点的位置继续删除。
这种方式保证了我们最终删除的是一个叶节点,从而简化结构调整,且整个过程的运行时间为 O(h),其中 h 是树的高度。
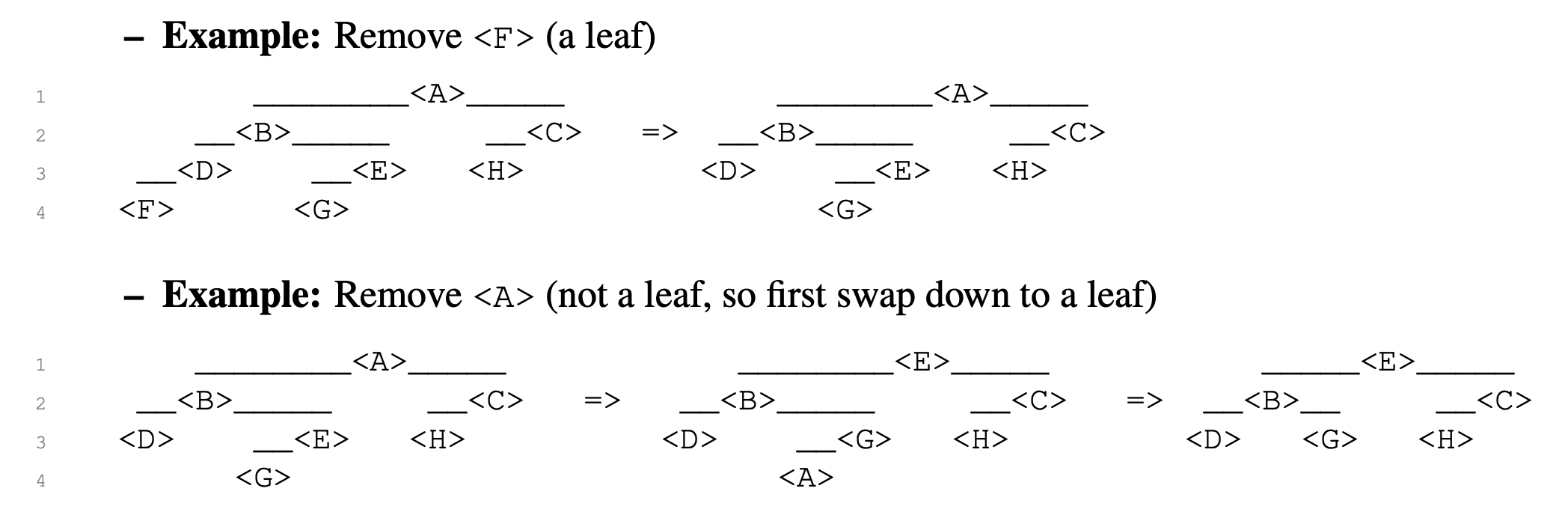
应用:集合
一个关键的想法是使用集合二叉树(也称为二叉搜索树,Binary Search Tree,简称 BST),其核心在于将<R>中序遍历的顺序<R>对应为<R>按键值递增排序的顺序<R>。等价于BST属性:对于每个节点,左子树中的每个键 ≤ 节点的键 ≤ 右子树中的每个键。
借助这个性质,我们可以像二分查找一样然后可以在O(h)时间内像二分查找一样在节点<X>的子树中找到键为k的节subtree_find(k):
- 如果k小于<X>的键,在左子树中递归(或返回None)
- 如果k大于<X>的键,在右子树中递归(或返回None)
- 否则,返回存储在<X>的项
应用:序列
一个核心想法是构建<R>序列二叉树<R>:其遍历顺序对应于序列中的元素顺序。若要在某个子树中查找第 i 个节点(即subtree_at(i) 操作),最直接的方法是顺序遍历整个子树,但这会耗费 O(n) 时间,效率很低。
更高效的做法是:在每个节点维护其子树的大小,使得我们可以通过“大小信息”在 O(h) 时间内定位第 i 个节点。具体步骤如下:
- 假设当前节点的左子树大小为
- 如果i <
,说明第 i 个节点在左子树中,递归进入左子树; - 如果i >
,说明第 i 个节点在右子树中,递归进入右子树,并更新索引为 - 否则,i =
,你已经到达了所需的节点!
为了支持这种查找方式,每个节点通过“增强(augmentation)”方式添加一个 size 字段,记录其子树中节点的总数。在插入叶节点时,沿祖先路径将 size 值加 1;删除时则减 1,两个操作的时间复杂度都是 O(h)。
一旦我们能高效实现 subtree_at(i) 操作,其他序列操作(如插入、删除、切片等)也就能自然地建立在其上。虽然朴素地构建一棵序列树可能需
代码实现
binary_node.py
# binary_node.py
class Binary_Node:
def __init__(self, x): # O(1)
self.item = x
self.left = None
self.right = None
self.parent = None
#self.subtree_update() # lec 7
def subtree_iter(self): # O(n)
if self.left:
yield from self.left.subtree_iter()
yield self
if self.right:
yield from self.right.subtree_iter()
def subtree_first(self): # O(h)
if self.left:
return self.left.subtree_first()
else:
return self
def subtree_last(self): # O(h)
if self.right:
return self.right.subtree_last()
else:
return self
def successor(self): # O(h)
if self.right:
return self.right.subtree_first()
while self.parent and (self is self.parent.right):
self = self.parent
return self.parent
def predecessor(self): # O(h)
if self.left:
return self.left.subtree_first()
while self.parent and (self is self.parent.left):
self = self.parent
return self.parent
def subtree_insert_after(self, B): # O(h)
if not self.right:
self.right = B
B.parent = self
else:
C = self.right.subtree_first()
C.left = B
B.parent = C
self.maintain()
def subtree_insert_before(self, B): # O(h)
if not self.left:
self.left = B
B.parent = self
else:
C = self.left.subtree_last()
C.right = B
B.parent = C
self.maintain()
def subtree_delete(self): # O(h)
if self.left or self.right:
B = None
if self.left:
B = self.predecessor()
else:
B = self.successor()
self.item, B.item = B.item, self.item
return B.subtree_delete()
if self.parent:
if self.parent.left is self:
self.parent.left = None
else:
self.parent.right = None
self.maintain()
return self
def maintain(self):
passbinary_tree.py
from binary_node import Binary_Node
class Binary_Tree:
def __init__(self, Node_Type = Binary_Node):
self.root = None
self.size = 0
self.Node_Type = Node_Type
def __len__(self):
return self.size
def __iter__(self):
if self.root:
for A in self.root.subtree_iter():
yield A.itembst_node.py
"""
用二叉树实现Set的接口,用二叉树的遍历顺序来存储递增的key,
这种性质的树称为二叉搜索树(BST)
下面为二叉搜索树节点数据结构
"""
from binary_node import Binary_Node
class BST_Node(Binary_Node):
def subtree_find(self, k): # O(h)
if k < self.item.key:
if self.left:
return self.left.subtree_find(k)
elif k > self.item.key:
if self.right:
return self.right.subtree_find(k)
else:
return self
return None
def subtree_find_prev(self, k): # O(h)
if k < self.item.key:
if self.left:
return self.left.subtree_find_prev(self, k)
else:
return None
elif self.right:
B = self.right.subtree_find_prev(k)
if B:
return B
return self
def subtree_find_next(self, k): # O(h)
if k > self.item.key:
if self.right:
return self.right.subtree_find_prev(self, k)
else:
return None
elif self.left:
B = self.left.subtree_find_prev(k)
if B:
return B
return self
# 与二叉树的方法略有不同,因此需要重写
def subtree_insert(self, B): # O(h)
if B.item.key < self.item.key:
if self.left:
self.left.subtree_insert(B)
else:
self.subtree_insert_before(B)
elif B.item.key > self.item.key:
if self.right:
self.right.subtree_insert(B)
else:
self.subtree_insert_after(B)
else:
self.item = B.itemset_bst.py
"""
用二叉树实现Set的接口,用二叉树的遍历顺序来存储递增的key,
这种性质的树称为二叉搜索树(BST)
下面为二叉搜索树结构以及接口实现
"""
from binary_tree import Binary_Tree
from bst_node import BST_Node
class Set_Binary_Tree(Binary_Tree): # 二叉搜索树
def __init__(self):
super().__init__(BST_Node)
def iter_order(self):
yield from self
def build(self, X):
for x in X:
self.insert(x)
def find_min(self):
if self.root:
return self.root.subtree_first().item
def find_max(self):
if self.root:
return self.root.subtree_last().item
def find_next(self, k):
if self.root:
node = self.root.subtree_find_next(k)
if node:
return node.item
def find_prev(self, k):
if self.root:
node = self.root.subtree_find_prev(k)
if node:
return node.item
def find(self, k):
if self.root:
node = self.root.subtree_find(k)
if node:
return node.item
def insert(self, x):
new_node = self.Node_Type(x)
if self.root:
self.root.subtree_insert(new_node)
# 检查是否存在相同key值,如果是更新value,并返回false
if new_node.parent is None:
return False
else:
self.root = new_node
self.size += 1
return True
def delete(self, k):
assert self.root
node = self.root.subtree_find(k)
assert node
ext = node.subtree_delete()
if ext.parent is None:
self.root = None
self.size -= 1
return ext.item