Lec 8 优先队列 & 二叉堆
介绍另外一种类似树的数据结构称为二叉堆,他给了我们排序的另外一种思路
- 优先队列接口
- 优先队列的排序
- 二叉堆
- 堆排序
优先队列接口
Priority Queue 提供了一个用于排序通用的框架,这里将提供三种方式,区别仅仅在实现中的数据结构不同。在这之前,先介绍下优先队列接口。
通过以优先级作为key,对元素进行排序,因此是Set接口(而不是顺序接口)
跟踪所有的元素,快速访问和移除最重要的一个,举几个应用
- 在受限带宽下路由,必须优先处理某种类型的消息
- 在OS内核下调度进程
- 离散事件仿真
- 图算法
优先队列针对集合操作进行了优化
操作 描述 build(X)从可迭代对象 X构建优先队列insert(x)将项 x添加到数据结构中delete_max()移除并返回具有最大键值的存储项 find_max()返回具有最大键值的存储项 优先队列通常针对最大值或最小值进行优化,而不是同时针对两者进行优化。
主要关注insert和delete_max操作:build操作可以重复insert实现;find_max()可以通过insert(delete_min())实现
无序数组
存储元素:在无序的动态数组中存储元素。
插入(insert(x)):将x附加到末尾,摊销时间复杂度为 O(1)。
删除最大值(delete_max()):在 O(n) 时间内找到最大值,将最大值交换到末尾并移除。
插入操作快,但删除最大值操作慢。
优先队列排序是选择排序(加上一些复制操作)
有序数组
存储元素:在有序的动态数组中存储元素。
插入(insert(x)):将x附加到末尾,并在 O(n) 时间内交换到正确的位置。
删除最大值(delete_max()):在摊销 O(1)时间内从末尾删除。
删除最大值操作快,但插入操作慢。
优先队列排序是插入排序(加上一些复制操作)。
AVL树
insert(x),find_min(),find_max(),delete_min()和delete_max()操作能在时间完成 - 因此优先队列排序需要
时间
- 因此优先队列排序需要
- 可以通过子树增强(subtree augmentation)将
find_min()和find_max()的时间复杂度提升至 O(1) - 但是这种数据结构非常复杂,最终的排序不是原地排序
- 有没有更加简单的数据实现优先队列,并且实现原地
排序? - 有的!二叉堆和堆排序
优先队列的排序
- 任何优先级队列数据结构都可以转变为一个排序算法。
Build(A), e.g。, 可以通过一个接一个顺序insert数据项- 重复执行
delete_min()(或者delete_max()) 来确定排序顺序
- 所有复杂的工作都发生在数据结构内部
- 运行时间
- 很多排序算法我们可以看作是优先队列排序。
完全二叉树
思路: 将数组解释为一个完全二叉树,在深度i处最多有2^i个节点,除了在最大深度处,所有节点都是左对齐的
1 d0 ______O____
2 d1 ____O____ __O__
3 d2 __O__ __O O O
4 d3 O O O等价地,完全二叉树按照读取顺序密集填充:从根到叶,从左到右。
视角:数组与完全二叉树之间的双射。
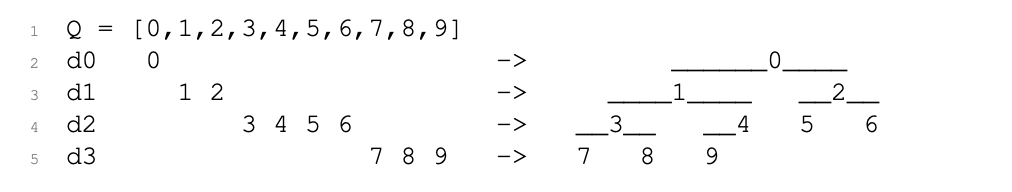
数组n个元素的完全二叉树视角的高度为:
隐式完全二叉树
完全二叉树的结构可以是隐式的,而不是存储指针。
- 根节点在索引0处。
- 通过索引运算计算相邻节点:
- 左子节点:
left(i) = 2i + 1 - 右子节点:
right(i) = 2i + 2 - 父节点:
parent(i) = (i - 1) / 2
- 左子节点:
二叉堆
思路: 将较大的元素保持在树的较高位置,但仅在局部。
- 最大堆性质,在节点i处: 对于
- 最大堆的是一个满足所有节点最大堆性质的数组
- 推断: 在最大堆中,每个节点i, 对于其子树中所有节点j,都满足

插入操作
将新元素 x 附加到数组末尾,摊销时间复杂度为 O(1),使其成为读取顺序中的下一个叶节点 i。
max_heapify_up(i):与父节点交换,直到满足最大堆性质。- 检查
(这是在父节parent(i) 处的最大堆性质的一部分)。 - 如果不满足,则交换 Q[i] 和 Q[parent(i)],并递归地调用
max_heapify_up(parent(i))进行向上堆化。
- 检查
正确性:
最大堆性质保证所有节点都大于等于其后代,除了 Q[i] 可能大于其某些祖先(除非 i 是根节点,这种情况下已经满足)。
如果需要交换,交换后 Q[parent(i)] 代替 Q[i]保证了相同的性质。
运行时间:树的高度,故时间复杂度为
。
删除操作
动态数组只能轻松移除最后一个元素,但最大关键字在树的根节点。
所以将根节点
处的项目与堆数组中最后一个节点 处的项交换。 向下堆化
:与更大的子节点交换,直到满足最大堆性质。
- 检查
对于 (这是在节点 i 处的最大堆性质的一部分)。 - 如果不满足,则将
与关键字最大的子节点 j 交换,并递归地对 j 进行向下堆化。
- 检查
正确性:
- 最大堆性质保证所有节点都大于等于其后代,除了 Q[i]可能小于某些后代(除非 i 是叶节点,这种情况下已经满足)。
- 如果需要交换,交换后 Q[j] 代替 Q[i] 保证了相同的性质。
运行时间:树的高度,故时间复杂度为
构建操作
通过重复的insert实现最大堆优先队列是需要花费时间
def build_max_heap(A):
n = len(A)
for i in range(n // 2, -1, -1): # O(n) loop backward over arry
max_heapify_down(A, n, i) # O(log n - log i) fix max heap通过这样处理能够花费O(n)而不是
堆排序
- 将最大堆插入到优先队列排序中,得到一种新的排序算法。
- 运行时间为
,因为每次插入和删除最大值的操作都需要 时间。 - 但通常包括对该排序算法的两种改进:
原地优先队列排序
- 最大堆 Q 是较大数组 A 的前缀,记住有多少项目|Q| 属于堆。
- |Q|最初为零,最终为|A|(插入完成后),然后再次为零(删除完成后)。
insert()在数组中的索引|Q| 处将下一个项目吸收到堆中。delete max()将最大项目移到末尾,然后通过减少|Q|来放弃它。- 使用数组进行原地优先队列排序就是选择排序。
- 使用有序数组进行原地优先队列排序就是插入排序。
- 使用二叉最大堆进行原地优先队列排序就是堆排序。