Lec 9 磁盘分页 & 超级页
本讲分两大块:(1)磁盘分页(paging to disk)——把 RAM 当作磁盘的缓存,内存不够时把页换出到磁盘,靠 LRU/工作集等策略选择淘汰谁;(2)超级页(superpages)——用单个 PTE 映射一大块(如 2MB)连续物理内存,提升 TLB 覆盖率。两者都建立在「页表 + 页错误」这套间接层之上(承接 Lec 8)。
总览
- 磁盘分页
- 惰性分配回顾 & 磁盘分页的动机(RAM 作为磁盘缓存)
- 页面淘汰:理想策略 vs LRU;A 位的作用
- FreeBSD 三链表(Active / Inactive / Cache)与 clean/dirty 页
- 工作集(working set)与抖动(thrashing)
- 超级页
- TLB 覆盖率(TLB reach)问题——超级页的根本动机
- 超级页是什么 & 硬件约束(大小/连续/对齐/单组标志位)
- 三个核心设计问题:①何时分配 ②如何找到连续内存(预留式分配)③何时/如何降级
- 碎片控制与连续性感知的页守护进程
- A/D 位粒度丢失与「读保护 + 写时降级」
- 实验结果 & Linux 透明大页(THP)
- 论文重点图 & 思考题
思考题
论文第4.5节提到,只有当一个进程已经访问了某个superpage地址范围内的每一个基础页之后,才会把superpage映射插入到该进程的页表中。而第 4.1 节又说,当进程第一次访问该 superpage 地址范围内任意一个 base page 时,就会为整个 superpage 预留对应的物理内存。既然采用了后一种策略——在第一次访问任意 base page 时,就已经为整个 superpage 预留了物理内存。为什么设计上不在那个时刻就同时插入 superpage 映射,而要等到进程访问完整个 superpage 的所有 base pages 之后才插入?
关键要区分两个动作:
- 预留(reservation):只是「圈下」一块 2MB 连续对齐的物理帧,并不真正分配、也不清零它们;这些被预留的帧此刻仍保留着原来的缓存内容,一旦内存紧张还能被抢占回收。所以预留是可撤销、低成本的。
- 插入 superpage 映射(promotion):意味着用一个 PTE 把整个 2MB 当作「已分配、已初始化、可直接访问」的整体暴露给进程。
为什么不能在「第一次访问」就插入 superpage?两条理由:
正确性:superpage 内部不再产生页错误。superpage 用一条 PTE 覆盖全部 2MB,对它范围内任何地址的访问都不会再触发 page fault。这就要求所有 base 帧必须在 promotion 之前就已经被分配并正确初始化(清零或从文件载入)。但预留并没有初始化这些帧——只有当某个 base page 被单独访问、触发缺页时,才会真正
kalloc + 清零那一页。若在只访问了一页时就插入 superpage,那么对其余「尚未初始化」帧的读会读到垃圾数据、写也无法被捕获。因此必须等到所有 base page 都被逐一访问、逐一初始化之后,才能安全合并。避免浪费 / 过早承诺。promotion 是「把 2MB 全部坐实为已用物理内存」。如果进程其实只用到其中几页,过早 promotion 就白白分配并清零了其余大片内存,而且 superpage 单组 A/D 位、没有内部粒度,无法再回收那些没用到的页。「等全部 base page 都被访问过」恰好证明了这 2MB 会被 100% 使用,此时 promotion 零浪费。相比之下,预留即使最后用不上也能被抢占,代价小得多。
一句话:预留是赌注(可反悔),promotion 是兑现(不可反悔且要求全部就绪)。所以要把 promotion 推迟到「全部 base page 都已实际分配并初始化」的那一刻。
磁盘分页(Paging to Disk)
这一半是纯课件内容(论文不涉及),讲「内存不够时怎么办」。
惰性分配回顾 & 动机
承接 Lec 8:页表一开始是空的,物理页在首次访问时才分配(page fault)——好处是启动快、程序能申请远大于实际所需的内存。磁盘分页把这个思想推得更远:把 RAM 当成磁盘的缓存。
- 历史动机:让程序能用比 RAM 更大的内存
- 现代动机:数据中心里内存依然昂贵(常比 CPU 还贵),且文件缓存、超大内存映射文件都依赖它
工作机制:
- 缺页时:内核分配物理页,初始化(清零或从文件读),填入 PTE
- RAM 满时:选一页换出(evict)到磁盘,把它的 PTE 置无效,并记住它在磁盘上的位置
- 再次访问被换出的页 → 触发缺页 → 换入(page in):分配物理页、从磁盘读回、更新映射
页面淘汰策略
- 理想策略(不可实现):淘汰「下一次使用时间最远」的那一页(需要预知未来)。
- 实用策略:LRU(Least Recently Used),假设「最近用过的页,很快还会再用」:
- 内核维护一个所有物理页的 LRU 链表
- 周期性扫描每页的 A(Accessed)位:若被访问过 → 移到链表头并清 A 位;分配新页时从链表尾取
- 弱点:顺序扫描大数组时表现糟糕——刚扫过、最不会马上再用的页恰恰排在最该被淘汰的位置,而它其实马上还要用(被反复踢出又读回)。
FreeBSD 三链表 & clean/dirty 页
论文 5.1 节用的更精细的 LRU 变体——三条链表:
| 链表 | 含义 |
|---|---|
| Active | 频繁访问的页 |
| Inactive | 不常访问的页 |
| Cache | 干净页(自上次写盘后未改动,磁盘上已有相同副本) |
- 扫描时:任何链表里被访问过的页都移到 Active 头
- 内存压力下:Active 尾 → Inactive;把 Inactive 里的脏页写回磁盘;干净的 Inactive 尾 → Cache
- 关键洞察:缺页要分配新页时,从 Cache 链表取——因为这些是干净页,无需写盘,分配开销最小
工作集与抖动
- 工作集(working set):程序在某段时间内真正活跃使用的那部分内存。
- 运行良好的条件:程序同一时刻只用到所分配内存的一小部分、局部性好——工作集能放进 RAM,性能就好。
- 抖动(thrashing):工作集太大,或进程太多,导致几乎每次访问都缺页、不停换入换出,系统急剧变慢。paging 的性能完全依赖「工作集装得下 RAM」这个前提。
论文阅读:超级页(Superpages)
摘要
大多数通用处理器都支持较大页尺寸的内存页,称为 superpages(超级页)。超级页使得 转换后备缓冲区(TLB) 中的每一个表项,都能够把一个较大的物理内存区域映射到虚拟地址空间中。显著提高命中率和覆盖范围。
然而,支持大页也会给操作系统带来一些挑战。例如如何分配超级页、何时将小页提升为超级页,如何控制内存碎片。本文分析了这些问题,并提出了一种有效的大页管理系统设计,该设计被实现在FreeBSD OS、Alpha CPU平台上,在很多情况下,性能提升超过30%,即使在复杂负载下,性能受益仍然能够保持。
1. 引言
现代通用处理器提供虚拟内存支持,并使用页表(page tables)进行地址转换。大多数处理器会把页表中的虚拟地址到物理地址映射缓存在TLB中,
核心设计思想:
- 为了未来可能的超级页需求, 预留连续物理内存,
论文贡献:
- 为支持多种superpage大小,进一步研究了基于预留机制的方法
- 首次将碎片问题纳入超级页的研究
- 提出新的页面替换算法
- 解决了超级降级,脏页回收等实际的系统问题
论文结构:
- 第 2 节:问题动机与复杂性
- 第 3 节:相关工作
- 第 4、5 节:设计与实现
- 第 6 节:实验结果
- 第 7 节:总结
2. 超级页的问题
动机
主存容量呈指数增长,而TLB覆盖率却没有跟上,因为TLB通常是全相联,比较所有的entry看哪个匹配虚拟页号,同时每次访问内存都要经过TLB,这就要求TLB要快,不能做太大。典型地,TLB通常只有128项或者更少,对应的覆盖范围约1MB或更小(4KB * 128项),现代应用的工作集远大于TLB覆盖,导致TLB miss 导致性能下降,30%–60%(现代应用)。另外一个重要原因,现代CPU的L2/L3 cache 可以达到数十MB,远大于TLB覆盖,这就出现数据已经在cache,但是TLB没有命中的问题。
因此我们希望找到一种方法, 在不成比例增大 TLB 大小的情况下,提高 TLB 覆盖率。一个直观做法就是把基础页变大,比如64KB、4MB。但这种方法导致内部碎片增加,导致内存浪费,以及I/O开销增加,页越大一次换入/换出数据越多,导致磁盘I/O成本更高。因此更好的方法是支持多种页大小,既能提高TLB覆盖率(用超级页),降低磁盘I/O(按需用小页)。但是这也带来新的问题,如果选择页大小?如何管理碎片?如何动态调整?
硬件限制
大多数处理器中的 TLB 硬件设计,对超级页的使用施加了一系列的限制。
- 页大小必须是硬件支持的
- 必须是连续的
- 必须对齐
- TLB中的超级页目录项只包含一个引用位、一个脏位、一组权限位
这些带来两个重要限制
- 组成 superpage 的所有小页必须具有相同的权限
- 无法区分内部小页状态
问题与权衡
管理 superpage 的任务,可以被拆分为多个步骤,每一步都有不同的权衡,且这些不依赖与具体CPU架构,也不依赖具体OS。
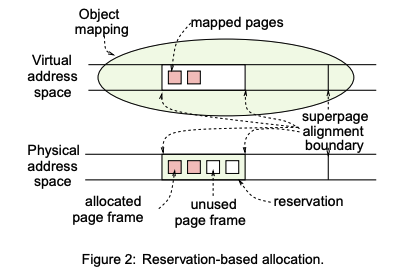
我们假设每个进程的虚拟地址空间都包含一组虚拟内存对象。如图2所示,一个内存对象占据了一个连续的虚拟地址空间,并包含了应用层数据。 内存对象就包含了进程中的内存映射文件(memory mapped files)、代码段、数据段、栈和堆。 这些对象的物理内存,是在第一次访问时才分配的(lazy allocation)。
关于分配 当程序第一次访问某一页,OS 分配一个物理页框并建立映射。 传统的做法可以分配任意页框(不要求连续),但如果以后想做超级页,需要把这些页搬到一起(物理拷贝),这样做的话拷贝成本很高。 本文给出的方案是 预留分配(reservation-based allocation), OS尝试分配一个连续的大块物理内存,大小和对齐满足超级页要求。当进程访问这些页时,再逐个分配实际页框,解决了前面的问题,但是代价是需要决定预留多大的超级页,但此时并不知道未来访问模式。 可以采用的策略,或根据当前内存情况保守选择,也就形成了一个tradeoff, 大页带来的性能受益 vs 保留连续内存用于未来更重要用途。
关于碎片控制 当连续内存充足时,OS 可以很好使用 superpage获得最佳性能,但是因为预留问题,很快导致物理碎片化问题。 OS的策略可以 1)主动释放之前分配但不活跃的连续区域,或者 2)抢占使用的reservation,这些这些区域可能永远不会变成超级页。
关于升级(promotion) 当一个 superpage 范围内的 base page 被逐渐访问、逐个真正分配后,OS 在合适时机把这些小页合并(promote)为一个 superpage:填一个覆盖整段的超级页 PTE,原来的小页 PTE 失效。论文采取保守策略:等到该范围内所有 base page 都被访问过(证明 2MB 会被 100% 使用)才 promote——理由见本讲开头的思考题。
关于降级(demotion) 反向操作:把一个 superpage 拆回若干 base page。触发场景:
- 内存压力:小页粒度更细,便于回收没用到的部分、减少浪费;
- 需要细粒度的 A/D 信息:superpage 只有一组 A/D 位(见下文)。
超级页:课件视角(设计要点串讲)
论文 2 节给了「问题与权衡」的框架,课件把它讲成更清晰的一个动机 + 三个设计问题,下面按课件组织补全。
TLB 覆盖率(TLB reach)—— 超级页的根本动机
TLB 是 CPU 缓存「VA→PA 翻译」的地方,每次取指/load/store 都要查它,必须快,所以做不大(典型 L1 约 128 项、L2 约 1024 项)。
| 配置 | TLB reach |
|---|---|
| 128 项 × 4KB | 512 KB |
| 1024 项 × 4KB | 4 MB |
| 128 项 × 2MB(超级页) | 256 MB |
现代机器动辄 16GB+ RAM,4KB 页的 reach 小得可怜,大工作集程序会频繁 TLB miss。一次 TLB miss 要硬件遍历多级页表、多次 ~100ns 访存,CPU 停顿,开销约百倍于一条指令。把页变大(2MB)就能用同样的 TLB 项数覆盖更大内存——这就是超级页的全部意义。
超级页是什么 & 硬件约束(小结)
一个 PTE 映射一整块(如 2MB)连续、对齐的物理内存。硬件约束(呼应上文「硬件限制」):
- 大小必须是硬件支持的档位;物理连续;2MB 对齐到 2MB 边界
- 整块只有一个 A 位、一个 D 位、一组权限位 → 丢失内部粒度
核心张力:TLB reach ↑ vs 内存浪费——如果 2MB 只用了一小块,其余全是被浪费的 RAM。
三个核心设计问题
① 何时分配 superpage?
- 在
sbrk()时?——难,无法预知会不会真用(sbrk(2MB)可能不用;sbrk(4KB)可能是大分配的第一页)。 - 首次缺页就分配(Linux 风格):确认「至少会用一点」,应用立刻享受 TLB 红利;缺点是只用一小块时浪费 RAM。
- 等整段都缺页过才分配(论文风格):保守,确认 100% 会用,零浪费;缺点是迟迟享受不到红利。
② 如何找到合适的 2MB 连续内存?
物理内存天然碎片化——空闲/已用的 4KB 页交错,自然出现 2MB 连续块很难,同时造 4KB 和 2MB 页会加剧碎片。
- 预分配(lab 简化):启动时预留若干 2MB 区,问题是不知道要留多少。
- 压缩/整理(Linux):搬移物理页 + 改它们的 PTE,慢、耗 CPU。
- 论文的预留式分配(4.1 节,巧妙):
- 某 2MB 区首次缺页时:建一个普通 PTE、只分配并初始化一页,同时从 LRU Cache 链表预留 2MB的帧;
- 预留 ≠ 分配/初始化——被留的帧仍保留缓存内容,需要时可被抢占回收;
- 随着该区更多缺页,逐个把预留帧分配、初始化;全部 base page 都缺页过后 → promote;
- 好处:不强制内存压缩(省 CPU)、不立即承诺内存、尊重现有页缓存、分配成本摊到多次缺页、用前先证明会用。
③ 何时/如何降级 superpage?(见上文「关于降级」)核心手段是读保护 + 写时降级,见下。
碎片控制 & 连续性感知的页守护进程
- 系统要持续维护一批「空闲且 2MB 对齐连续」的区域备用。
- 页守护进程(page daemon)负责平衡分配与淘汰,淘汰时刻意让被释放的页凑成连续块(contiguity-aware eviction),且优先从 Cache 链表(干净页)取用以拼出对齐连续的 2MB。
A/D 位粒度丢失 与「读保护 + 写时降级」
superpage 只有一个 A 位、一个 D 位覆盖整 2MB:
- A 位粒度丢失:分不清 2MB 内哪些 4KB 页真被访问 → 干扰细粒度 LRU。
- D 位粒度丢失:对 2MB 内任意一处的写都会把整块标脏 → 换出时哪怕只改了一页也得把整 2MB 写回磁盘,代价高。
实验结果 & Linux 透明大页(THP)
- 论文 Table 1:大量真实程序基准,典型提升约 10%(多数),部分应用提升很大;前提是内存充足,内存有压力时结论可能大不相同。
- 收益高度依赖:工作集大小、访问模式、内存压力、每个 superpage 实际用了多少。
- Linux「透明大页(THP)」:被广泛采用但有争议——只用一小部分时的内存浪费是大问题;收益常只有 10–15%,而代价(浪费)可能很大,行为高度依赖负载。许多应用干脆显式申请大页,而不依赖透明机制。TLB 效率 vs 内存效率的张力至今没有彻底解决。
论文重点图
按整理惯例,论文部分只记录图中最重点的内容。
- 图 2(虚拟内存对象布局):进程地址空间由若干虚拟内存对象组成(内存映射文件、代码段、数据段、栈、堆),每个对象占一段连续虚拟地址,其物理内存按需(lazy)分配。这是「在对象内部尝试做 superpage 预留」的出发点。
- 预留式分配示意(4.1 节配图):首次缺页 → 建普通 PTE + 预留 2MB 连续帧 → 随访问逐页落实 → 全部落实后 promote 成一个超级页 PTE。要点是「先预留连续区、再逐页兑现、最后合并」。
- Table 1(性能结果):横轴是各类基准程序,关键结论是「内存充足时多数提升约 10%、个别很高」。
参考资料
- Practical, Transparent Operating System Support for Superpages, osdi'02
- 内容上,讲解了为什么 superpage 有用?实现的难点在哪里?
- lec