Lec 12 锁
这节课,我们将关注内核和操作系统中的锁。
阅读xv6内核的实现,
kernel/spinlock.hkernel/spinlock.c
阅读xv6第7章的实现理解锁
总览
- 为什么要使用锁?
- 锁的抽象
- 不同角度理解锁
- 什么时候需要用锁?
- 锁是否可以自动的?
- 锁的问题
- 死锁
- 模块化
- 性能
- 示例:URAT, CAS
为什么使用锁?
应用程序希望使用多核处理器来实现并行加速,因此内核必须处理并行的系统调用,从而需要并行访问内核数据(如缓冲区缓存、进程等)。锁可以帮助正确共享数据,但也可能限制并行加速。
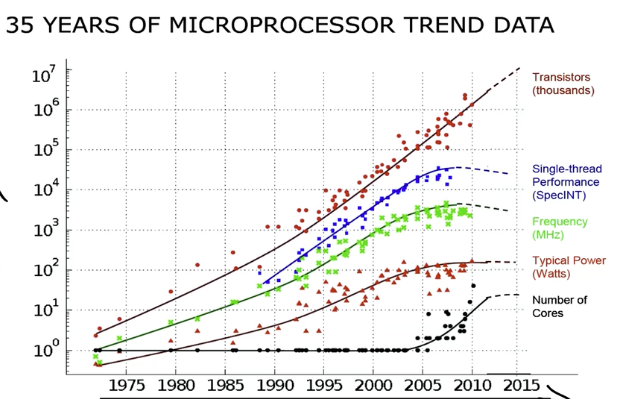
从 2000 年开始,时钟频率并没有继续增加。基本上是停滞不前(3.3GHz左右)。所以,核心的单线程性能,也基本达到了极限,停滞不前。而另一方面,晶体管数量还在随时间增长,所以,如果你不能使用晶体管使单个核心运行得更快,唯一的选择是使用多个处理器核,处理器核的数量越来越多。所以,应用程序需要更高的性能,就需要避免竞态条件,这正是锁的作用。
锁的抽象
锁可以序列化进程的执行,两个进入临界区间的进程,只有一个可以成功,另一个在第一个完成后运行临界区间,所以这里没有并行。
典型地, 锁是一个对象,结构体struct lock,提供了acquire(lock)和release(lock),每个锁保护一个共享数据结构,因此一般程序而言,会有很多锁。
如果多个线程同时调用
acquire(l),只有一个线程会立刻返回,其他线程会等待release()才能继续执行。一个程序通常有大量数据和大量锁。如果不同的线程使用不同的数据,它们可能会持有不同的锁,这样就可以并行执行,完成更多工作。
需要注意的是,锁
l并不专门与数据x绑定,程序员需要为锁与数据之间的对应关系制定计划。
大内核锁 vs. 细粒度锁
如果内核只有一个锁,通常称为大内核锁,那么内核中每个系统调用都会被串行化,系统调用 1 获取大内核锁,做它想做的事情,然后释放大内核锁,然后返回用户空间。然后第二个系统调用运行,所以我们有并行运行的程序,并行运行大量的系统调用,所有的系统调用都是串行运行的。而如果两个系统调用使用两个不同的锁,我们说细粒度锁,那么它们实际上可以完全并行运行,没有任何串行化。
IMPORTANT
锁并不是自动完成的,一切都由开发者决定的,将锁与数据结构关联,并确保适当的 acquire release 在那里
什么时候需要用锁?
一条保守的指导原则
你有两个进程,两个进程访问一个共享数据结构。其中一个是写入者,这意味着它对共享数据结构做修改。那么你需要对这个数据结构使用锁。
所以这是一条保守的规则,或者说这是一个严格的规则。有一种编程风格称为无锁编程(Lock-Free Programming),比如RCU等,难度很大。
锁是否可以自动的?
如果我们每次共享数据结构,那么共享数据结构中的操作就需要锁,我们应该在每个操作中把锁和数据结构关联起来,实际上,它在数据结构上执行,来获取或释放锁。也许编程语言可以为每个数据对象关联一个锁,编译器在每次使用时自动添加 acquire/release,这样程序员就不会忘记加锁。
但是这种方法通常太过死板。例如:
if present(table1, key1):
add(table2, key1)另一个线程可能会在当前线程有机会向 table2 添加之前,移除 key1,这个故事告诉我们,需要显式控制锁的持有时间段,以避免在中间状态时出现问题
示例: rename系统调用
假设rename("d1/x", "d2/y")
如果我们遵循严格的规则,我们对 d1 加锁,删除 x ,然后释放 d1 的锁。然后,我们做数据的第二部分,对 d2 加锁,添加 y ,然后释放 d2 。然后我们就完成了。这是一种假设的方案。假如我们已经完成了第一步,还没有完成第二步。另一个进程会观察到文件丢失了。所以正确的解决方案是,我们需要的是,在重命名开始前,先锁定 d1 和 d2 ,然后擦除并添加,然后释放 d1 和 d2 的锁。这是一种方法。另外一种就是大内核锁。
锁的三种角度解释
你可以用其中一种解释来构建思考问题的方式。
- 避免更新丢失。一种非常低级的方式
- 使多步操作成为原子操作。
- (真正的作用)维护一个不变量。不变量共享它在保护的数据结构。我们在
acquire之前,视为持有不变量。当我们获得锁,并进行一些操作时,暂时违反不变量,直到我们release锁。- 考虑一下 freelist 的例子,不变量是空闲指针指向下一个指针,并且所有的空闲页面都在一个列表上
锁的问题
死锁
如果我们获取锁顺序不当会导致死锁。
解决方案是,如果你有多把锁,那你就得对锁排序,所有操作都必须按照这个顺序来获取锁。所以如果你是一名系统设计师,你必须决定所有锁对象的全局顺序,比如,在这种情况下,你可能会说 d1 应该总是在 d2 之前,这就意味着,当我们执行rename时,规则是我们总是先获取更小数字的目录,在获取更高数字的目录之前。这将确保全局顺序,这种情况就不会发生。
模块化
考虑一下锁的顺序,一定是全局的。所以,如果我们有一个模块 m1 调用了模块 m2 的方法。根据遵守我们的锁规则,从 f 和 g 获取的所有锁,需要是在某种全局顺序,m1和m2的调用关系,意味着,就锁而言, m2 的内部部件必须对 m1 可见。所以 m1 可以确保,以适当的方式调用 m2 。在某种程度上,它会违背一些抽象的理念。如果做的好的话, m1 不需要知道关于 m2 实现的任何信息。因此,当你设计一个更大的系统时,、模块化变得更加复杂。
性能
我们想要性能,你需要拆分数据结构,所以如果你有一个大内核锁,这将使你的性能限于在单个 CPU 上,如果你想要具有多个 CPU 扩展的性能,你就得拆分。你需要拆分数据结构。最好的拆分,它并不明显,或者是一个挑战。比如,如果你将锁与每个目录相关联,如果你将锁与每个 inode 相关联,是否将锁与每个进程相关联。如果你需要修改,重新设计锁规则,你必须确保,你仍然保持着不变量,是内核想要保持的。
如果你拆分锁,你还必须重写代码。你也可能需要重写代码。所以事实证明,你应该重构内核的一部分,或者你的程序的一部分,为了获得更好的性能,通过拆分数据结构或引入更多的锁,有很多工作要做,你要仔细考虑,想要维持的范围,你必须要写代码,一般说来,这是一项繁重的工作,它们并不容易。所以这是比较负面的观点,因为我们想要更好的性能,这需要更多的锁。但这是一项繁重的工作。
对于这个问题,有一种普遍的做法是,从粗粒度的锁开始逐步细分,然后测量。不管是什么应用程序运行在内核上,如果它们利用了多个核心,观察得到了加速,你就完成了,你的锁设计已经够好了,如果没有加快速度,这意味着某些锁被争用,多个进程尝试获取相同的锁,因此它们被串行化了,所以,得不到加速。
这里的重点是,你要以这些测量来指导,因为可能是这种情况,一些使用粗粒度锁的模块不是经常并行调用,所以,没有必要对它重新设计,因为重新设计有很多工作要做,这也会使代码的条理变得复杂,不重新设计这些是一个更好的选择。所以,一般说来,一条好的规则是,从粗粒度的锁开始,测量这些锁中的一个是否出现争用,然后重新设计系统的这一部分,你就会得到更好的并行性。
指令与内存顺序
我们通常会认为,程序是按照代码书写顺序执行的。这个模型在单线程中基本成立,但是在多线程+共享内存的情况下,这个模型是错误的。为什么顺序会被打乱?有两个主要原因:1)编译器优化,编译器可能改变 load/store 的顺序、把便来那个缓存到寄存器(不再访问内存)、甚至删除某些内存的访问。2)CPU乱序执行(Out-of-order execution),CPU为了性能,会改变指令执行顺序,例如,指令 A 和 B 没有依赖关系,CPU可以先执行 B,再执行 A。
下面看一个危险的例子,push链表
l = malloc(sizeof *l); // 分配一个新节点
l->data = data; // 填入数据
acquire(&listlock); // 加锁(进入临界区)
l->next = list; // 新节点指向旧链表头
list = l; // 更新链表头为新节点
release(&listlock);// 解锁如果发生重排,第 4 行(l->next = list)被移动到 release 之后。这个时间窗口中,CPU0更新了list = l,释放锁。CPU1获取锁,看到了新的list,但是l->next还没有初始化,结果链表损坏(严重bug)
编译器和 CPU 并不是完全随意乱排,它们遵循内存模型(memory model),并提供机制让程序员控制顺序,解决方法就是内存屏障。xv6 使用 __sync_synchronize()禁止编译器和 CPU 在该点前后重排内存访问。在acquire()和release()都使用了内存屏障,保证acquire 之后的操作不会跑到 acquire 之前,release 之前的操作不会跑到 release 之后
Sleep锁
有些情况下,xv6 需要长时间持有锁。例如,文件系统在读写磁盘时可能需要几十毫秒。如果用 spinlock,其他进程想获取锁时,只能一直“自旋”(busy waiting),白白浪费CPU。自旋锁还有一个重要限制,持有锁时不能让出CPU(yield)。为什么? 如果允许,持有锁的线程A → yield, 线程B尝试acquire一直自旋,不会yield,因此占着CPU,线程A没法运行,无法释放锁,最终就是导致死锁。spinlock 要求在持锁期间关闭中断,如果 yield,会违反这个约束。
我们需要一种新的锁满足:等待锁时可以让出CPU、持有锁时也允许yield/中断。解决方案:sleep-lock。sleep-lock 内部有一个locked字段,用一个 spinlock 来保护它。acquiresleep 的行为,如果锁不可用,调用sleep,原子地释放内部spinlock,让出CPU,接着等待被唤醒。如此,在等待期间,当前线程不会占用CPU、其他线程可以运行。 但是sleep锁有两个关键限制,不能在中断处理函数中使用,因为 sleep-lock 会开启中断;不能在 spinlock 临界区中使用,因为 acquiresleep 可能 yield,但是反过来是可以的, 可以在 sleep-lock 内使用 spinlock
现代系统的锁实现
使用锁进行编程,即使经过多年对并发原语和并行性的研究,仍然是一个具有挑战性的事情。通常,更好的做法是, 将锁封装在更高层的抽象中(例如线程安全队列)。不过 xv6 并没有这样做。如果你需要直接使用锁编程,那么最好能够检测数据竞争的工具,因为很容易遗漏加锁的约束。
大多数操作系统都支持POSIX线程(Pthread)——允许一个用户进程包含多个线程,这些线程可以在不同CPU上并发运行。Pthread提供用户态锁、屏障等同步机制,还支持一种特性,可重入锁(re-entrant lock)。要在用户态支持 Pthreads,操作系统必须提供配合,例如,如果某个线程在系统调用中阻塞,同一进程的其他线程应该还能在该 CPU 上运行。如果某个线程修改了进程的地址空间,内核必须确保在其他CPU上运行该进程线程的页表(硬件状态)也要同更新。
虽然可以在没有原子指令的情况下实现锁,但是代价非常高,因此大多数OS都会使用原子指令。锁在高竞争情况下会很昂贵,例如,一个CPU持有锁(在本地cache中),另一个想获取锁,此时,锁所在的 cache line 必须从一个 CPU 的缓存移动到另一个 CPU,并且可能需要使其他 CPU 上的缓存副本失效。为了避免锁的开销,许多OS使用“无锁(lock-free)”数据结构和算法,例如,可以实现一种链表,查找时不需要锁,插入只需要一个原子操作。但是问题是无锁编程更加复杂,需要考虑指令重排(instruction reordering)和内存重排(memory reordering)
源码精读:spinlock 与 sleeplock
两份参考源码
spinlock.h/spinlock.c把前面所有概念(原子指令、内存屏障、关中断防死锁)落到几十行代码里;sleeplock.c则展示「长时间持锁」如何用 spinlock + sleep/wakeup 搭出来。代码取自 xv6-riscv(rev5)。
1. spinlock.h:锁的结构
struct spinlock {
uint locked; // 锁是否被持有(0/1)——真正的同步状态
// 以下仅供调试:
char *name; // 锁名
struct cpu *cpu; // 当前持锁的 CPU
};
locked是唯一参与同步的字段;name/cpu只为holding()判定和 panic 调试服务。
2. spinlock.c:acquire():拿锁
void
acquire(struct spinlock *lk)
{
push_off(); // ★ 先关中断(防死锁,见下)
if (holding(lk))
panic("acquire"); // 同一 CPU 重复拿同一把锁 = bug
// 原子交换:把 1 写进 lk->locked,并返回它的旧值。
// 旧值为 0 → 之前没人持有,本次抢到 → 退出循环;
// 旧值为 1 → 已被别人持有 → 自旋重试。
while (__atomic_exchange_n(&lk->locked, 1, __ATOMIC_ACQUIRE) != 0)
;
lk->cpu = mycpu(); // 记录持锁者(调试 + holding 判定)
}while(lk->locked); lk->locked=1; 是两步,两个 CPU 可能同时读到 0、都以为抢到——竞态。__atomic_exchange_n 在 RISC-V 上编译成单条 amoswap.w.aq,把「读旧值 + 写新值」做成一条不可分割的硬件指令,从而只有一个 CPU 能拿到旧值 0。这就是 test-and-set 的精髓。__ATOMIC_ACQUIRE 是一道内存屏障:禁止编译器/CPU 把临界区里的 load/store 重排到拿锁之前,保证「先拿到锁,再访问被保护的数据」。
3. spinlock.c:release():放锁
void
release(struct spinlock *lk)
{
if (!holding(lk))
panic("release");
lk->cpu = 0;
// 等价于 lk->locked = 0,但用原子 store。
// 不用普通 C 赋值,因为标准允许它被拆成多条 store 指令。
// RISC-V 上生成:先 fence rw,w 再 sw zero,0(s1)
__atomic_store_n(&lk->locked, 0, __ATOMIC_RELEASE);
pop_off(); // ★ 恢复中断
}__ATOMIC_RELEASE 屏障禁止把临界区里的 load/store 重排到放锁之后,保证「临界区的所有修改对其他 CPU 可见之后,锁才被释放」。
这正对应前文「push 链表」那个 bug:屏障确保
l->next = list不会被挪到release之后。acquire的 ACQUIRE 屏障 +release的 RELEASE 屏障,一头一尾把临界区「封”在里面。
4. holding():是不是本 CPU 持有
int
holding(struct spinlock *lk)
{
return (lk->locked && lk->cpu == mycpu()); // 中断必须已关闭
}5. push_off / pop_off:可嵌套的关中断
void push_off(void) {
int old = intr_get(); // 记下进入时中断是开还是关
intr_off(); // 立即关中断
if (mycpu()->noff == 0)
mycpu()->intena = old; // 只在最外层记住「最初」的状态
mycpu()->noff += 1; // 关中断嵌套计数 +1
}
void pop_off(void) {
struct cpu *c = mycpu();
if (intr_get()) panic("pop_off - interruptible"); // 此刻中断本就该是关的
if (c->noff < 1) panic("pop_off");
c->noff -= 1;
if (c->noff == 0 && c->intena) // 退到最外层、且最初是开的 → 才真正开中断
intr_on();
}acquire 同一把锁 → 自旋等待自己释放 → 永远死锁。关中断杜绝了这种「自己等自己」。noff 计数:两次 push_off 要两次 pop_off 才抵消,只有退回最外层、且记录的最初状态 intena 是开的,才真正恢复中断。这保证「最初中断是关的,则 push/pop 之后仍是关的」。6. sleeplock.c:长时间持锁靠 spinlock + sleep/wakeup 搭出来
spinlock 持锁时关中断、不能 yield,不适合磁盘 I/O 这种长等待。sleep-lock 让等待者睡眠让出 CPU,其内部用一把 spinlock 保护自己的 locked 字段:
void acquiresleep(struct sleeplock *lk) {
acquire(&lk->lk); // 用内部 spinlock 保护 lk->locked
while (lk->locked) {
sleep(lk, &lk->lk); // ★ 原子地:释放 lk->lk + 睡眠;醒来时重新持有 lk->lk
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
void releasesleep(struct sleeplock *lk) {
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk); // 唤醒在该 sleep-lock 上等待的进程
release(&lk->lk);
}7. 一张图看清两层锁
spinlock: acquire ──amoswap(test&set)+关中断──> 临界区(极短,不睡) ──release+开中断──>
│
└── sleeplock 借它保护自己的 locked 字段:
sleeplock: acquiresleep ─ acquire(内部spinlock) ─ while(locked) sleep(让出CPU) ─ locked=1 ─ release(内部spinlock)
▲
releasesleep: locked=0; wakeup ─┘