Lec 8 页错误
[toc]
本讲定位:上一讲(Lec 5)把页表当成「静态」的地址映射;本讲引入页错误(page fault),让页表变成动态的——内核可以在访问发生的那一刻拦截下来、临时修改页表、再让指令重跑。核心公式:页表(间接层)+ 页错误(拦截点)= 一套强大的透明机制,可用于惰性分配、零填充、写时复制、按需调页、内存映射文件等。
总览
- 虚拟内存的几个视角:从「隔离」到「间接层能做的酷事」
- 页错误的机制:三种 RISC-V 页错误 + 关键寄存器(
stval/scause/sepc) - 页表 + 页错误的组合能力
- 按需分配(lazy allocation):
sbrk只记账、vmfault真分配 - 透明性的关键:
copyin/copyout也会触发vmfault - 按需零填充(zero-fill-on-demand):共享只读零页 + 写时再分配
- 写时复制 fork(COW):只读共享 + 写时复制 + 引用计数
- 按需调页(demand paging):用到哪页才从磁盘读哪页
- 换页到磁盘 / 页面淘汰:局部性、LRU、A/D 位、
madvise/mlock - 内存映射文件(mmap):VMA、按需读入、写回策略
- 源码精读:
sys_sbrk/usertrap/vmfault
虚拟内存的几个视角
最初目标是隔离。虚拟内存允许操作系统,给每个应用程序提供自己的地址空间,使一个应用程序不可能意外地或恶意地修改另一应用程序的地址空间。
也就是说提供了间接层, 让内核有机会做一些很酷的事情
- 共享跳板页(trampoline page)——允许内核将一个页面映射到多个地址空间
- 守护页(guard page)——用户空间和内核空间中保护栈
- upid
- 超级页
在页错误时修改页表
RISC-V CPU 在以下情况下会触发页错误异常,
- 使用了一个页表中没有映射的虚拟内存
- 使用了页表项(PTE)存在但是PTE_V 标志为0(无效)的映射
- 使用了一个映射,但其权限位(PTE_R、PTE_W、PTE_X、PTE_U)不允许当前操作
RISC-V有16种异常,其中3种是页错误类型:
- 指令页错误: 取指令时发生
- 加载页错误:读取数据时发生
- 存储页错误:写数据时发生
需要的信息。那内核需要响应这个页面错误,那么它需要什么信息才能做出回应?
stval(”Store Trap Value“)寄存器:保存无法完成地址转换的虚拟地址scause寄存器: 指示页错误的类型,取指令或者是 ecall 指令(R / W / Interrupt)等等
页表和页错误的组合
页表为内核提供了虚拟地址到物理地址之间的一层“间接性”,使得内核可以控制地址空间的结构和内容。
页错误则允许内核拦截内存访问(load 和 store 操作),并通过动态修改页表来决定这些访问实际对应的数据
内核可以利用这些能力来提升效率,例如:
- 写时复制(copy-on-write fork):内核可以让父进程和子进程共享同一块内存,而不是立即复制。只有当某一方写入时,才真正复制页面,从而避免不必要的开销。
应用程序也可以从中受益,例如:
- 内存映射文件(memory-mapped files):内核通过分页机制,让文件内容直接“映射”到应用程序的地址空间中。 当程序访问这些地址时,页错误会触发内核按需读取文件内容。
- 延迟内存分配(lazy memory allocation):程序可以申请一个很大的虚拟地址空间,但只有在实际访问某些页时,内核才分配对应的物理内存,从而节省资源。
在 xv6 中,页错误目前只用于一个目的——按需分配
按需页分配
xv6 的按需分配包含两个部分:
第一,当应用程序通过调用 sbrk 并带上 SBRK_LAZY 标志来申请内存时,内核只会记录地址空间大小的增加,但不会分配物理内存,也不会为新增加的虚拟地址范围创建页表项
第二,当程序访问这些“新地址”而触发页错误时,内核才会分配一页物理内存,并将其映射到页表中。
这种按需分配对应用程序是完全透明的,应用程序不需要做任何修改,就可以获得性能上的好处。按需分配对应用来说很方便,因为它们不需要精确预测自己需要多少内存,使用按需分配时,程序可以直接申请“最坏情况”的内存,但实际上只会为真正用到的部分分配物理内存
当然,lazy allocation 也有代价,每次访问新页都会触发 page fault,而page fault 需要上下文切换,开销不小。一些操作系统会优化这个问题,一次 page fault 分配多个连续页;专门优化page fault 的内核入口/退出路径。
如果在按需分配出发页错误时,发现内核已经没有足够的物理内存了,内核很难优雅地把out-of-memory错误返回给应用程序。xv6的做法是直接杀死该进程。
在页面错误处理程序(page fault handler)中,
- 判断 fault 地址是不是合法的(属于进程堆范围)。
- 如果合法 → 分配物理页,
- 分配物理页,使用
kalloc() - 置零
- 用
mappages()建立映射,更新页表 - 重新执行刚才的指令
- 分配物理页,使用
- 如果非法 → 杀死进程(segmentation fault)。
首先,在exec.c文件的中的exec()函数为 sh 进程构建用户页表。
用户页表与内核页表的区别:
- 用户页表:只包含用户空间内存映射(代码段、数据段、栈等)
- 内核页表:包含所有物理内存映射(包括UART等硬件设备)
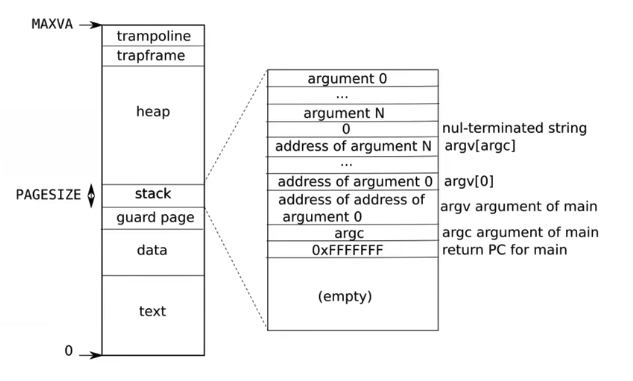
典型的用户进程内存布局
高地址 ┌─────────────┐
│ 栈区 │ (向下增长)
├─────────────┤
│ 保护页 │ (guard page)
├─────────────┤
│ 数据段 │
├─────────────┤
│ 代码段 │
低地址 └─────────────┘内核 trap handler 打印 scause, stval, sepc,你能看到 fault 信息。
修改前内存分配: sbrk()的调用流程
// 用户程序调用 malloc()
malloc(size)
↓
// malloc() 内部调用 sbrk() 系统调用
sbrk(n)
↓
// 内核处理
sys_sbrk() // sysproc.c
↓
growproc() // proc.c - 扩展进程内存
↓
uvmalloc() // vm.c - 为每个新页面分配
↓
kalloc() // 获取物理内存页面
↓
mappages() // 建立虚拟地址到物理地址的映射sbrk(n) 立即分配物理内存(eager allocation),修改的是进程的用户页表,而不是当前活跃的内核页表,此时 satp 寄存器指向内核页表
按需零填充
很多应用程序(比如有大数组的程序)需要大量被零填充的内存,比如全局数组、静态变量(未显式初始化)等。系统要确保这部分内存被清零;在ELF可执行文件中,有一个特殊段——bbs 段,特点是不在文件中存储实际数据,只记录“需要多大空间”,在 exec 时,内核需要把这部分内存填充为 0。传统做法来说,内核同行需要分配一个物理内存,然后调用memset 把整页清零,问题是操作频繁有开销。
优化后的方案是,内核只需要准备一块已经填充好的零页。当进程需要“零页”时,把这个页映射到进程地址空间,设置为只读(不带 PTE_W),多个进程可以共享这一页,不需要重复memset
现实系统:写时复制
许多操作系统内核(虽然 xv6 没有实现)使用页错误来实现写时复制(COW)fork。 fork系统调用的语义是,子进程看到的内存,在fork时刻,与父进程的内存完全相同,一种简单的方式是为子进程分配,然后将父进程的全部内存复制一份过去,但是开销很大。更高效的方法是共享父进程的物理内存。
COW的fork的核心思想是: 通过页表权限+页错误实现安全共享,基本方法是,fork之后父子进程共享所有物理页,但这些页表都被标记为只读(消除PTE_W位),当某个进程尝试写共享页,RISC-V就会触发page fault,支持 COW 的内核会这样处理:
- 分配一页新的物理内存
- 将原来的共享页内容复制到新页
- 修改当前进程的页表项(PTE):
- 指向新页
- 打开写权限(PTE_W)
- 让进程从触发 fault 的指令重新执行
COW 需要额外的“记账机制”,因为一个物理页可能被多个进程共享;引用关系会随着fork、page fault、exec、exit变化,内核需要记录每个物理页被多少个页表引用,这样才能确定什么时候可以释放物理页。
一个重要的优化,如果某次 store page fault 发生时,这个物理页只被当前进程引用,那么则根本不需要复制,一个经典的例子就是 fork + exec,子进程继承的大部分内存从未被使用,exec会直接释放这些内存,从头到尾都不需要复制。
现实系统:按需分页
另一个广泛使用的利用页错误的功能是按需分页(demand paging)。在Xv6的原始版本的exec中,xv6会”急切“加载应用程序的所有文本和数据段到内存中。由于应用程序可能很大,而从磁盘读取的开销很高,这种启动成本对用户可能会有明显影响,当用户从shell启动一个大型应用程序时,可能需要很长时间才能看到响应。
为提高响应速度,现代操作系统的做法是,一开始并不加载可执行文件内容,只创建用户页表,但将这些页的PTE标记为无效(Invalid),然后内核开始执行程序,程序第一次访问某一页时,会触发页错误,内核在 page fault handler 中会从磁盘读取页面内容,并将其映射到用户地址空间中。也就是说:用到哪一页,才加载哪一页。与COW fork和惰性分配类似,内核可以透明地实现此功能。
内存不够用怎么办?
程序总需求内存可能超过物理内存大小。 为了解决这个问题,操作系统可以实现分页到磁盘。基本思想是,只把一部分页面放在RAM中,其他页面存放在磁盘上的一个区域。具体做法,对于“已经被换出到磁盘”的页,内核把对应的 PTE 标记为 invalid。当程序访问这些页时,会触发page fault,内核执行换入(page in)——分配一页物理内存,从磁盘读取数据, 更新页表映射。
如果此时 没有空闲物理内存 怎么办?
内核必须先“腾空间”, 选择一个已有的物理页,把它写回磁盘,并把对应的PTE标记为无效。然后把需要的页换入。
页面淘汰(eviction)是很昂贵的(涉及磁盘 IO),paging 的性能依赖于一个关键性质:局部性(locality of reference),意味着程序在一段时间内,只会访问一小部分页面。如果:所有程序“正在使用的页面集合”可以放进 RAM, 系统性能就会很好
现实系统:内存映射文件
还有一些功能也结合了分页和page fault,例如,自动扩展栈、内存映射文件。所谓“内存映射文件”是指程序通过调用 mmap 系统调用,将一个文件映射到自己的地址空间中,这样一来,程序可以像访问内存一样使用load / store指令直接读写这个文件,这样一来就不需要通过lseek系统调用来修改offset了,背后的机制其实是一开始并不会把整个文件读进内存,页表里只是“标记这个区域对应某个文件”,当程序访问某一页时,触发 page fault,然后内核从文件中读取对应数据到内存。写的时候内核可以选择立刻写回磁盘或者延迟写回。
#include <sys/mman.h>
void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);mmap 的参数包括:
- 虚拟地址(va)
- 映射长度(len)
- 保护位(prot:R/W/X)
- 标志位(flags)
- 文件描述符(fd)
- 文件偏移量(offset)
作用是将“文件的一段内容”映射到进程的虚拟地址空间中。mmap 本身不会立即加载文件内容,也不会建立完整的 PTE 映射,而是建立一段虚拟地址区域Virtual Memory Area,VMA),一个 VMA 通常记录:
- 起始虚拟地址、长度
- 对应的文件(fd / inode)
- 文件偏移(offset)
- 权限(R/W/X)
- flags(是否共享、私有等)
当程序第一次访问 mmap 的某个地址时,会触发page fault,内核查找改地址属于哪个VMA,根据VMA信息计算文件的偏移,从磁盘中读取对应的页内容,接着分配物理页(kalloc),建立页表映射(PTE指向该物理页),映射建立后,程序可以直接用 load/store(LD/ST)访问这段内存,就像普通内存一样;写操作行为取决于flags——MAP_SHARED写入会影响文件(需要写回);MAP_PRIVATE写入走 COW,不影响原文件。
当这段映射不再需要时,应用调用munmap(va, len),接触页表映射,如果是dirty页,则写回文件,释放物理内存。
多个进程映射同一块磁盘上的文件怎么处理? 怎么处理同步问题?
如果两个进程写入文件中的同一块,那么写入可能以某种顺序出现。如果你想做一个更复杂的 Unix 操作系统支持文件锁,在那里你可以锁定文件,然后你就可以正确地同步,默认情况下,这里没有同步机制。需要用户程序自己实现
示例:写时复制
例如,许多内核使用页错误来实现写时复制(Copy-on-Write,COW)的 fork。fork 会导致子进程的初始内存内容与 fork 时父进程的内存内容相同。xv6 通过 uvmcopy(kernel/vm.c:301)来实现 fork,它会为子进程分配物理内存,并将父进程的内存内容复制到子进程中。然而,如果子进程和父进程可以共享父进程的物理内存,效率将会更高。但这种简单的实现方式无法奏效,因为它会导致父进程和子进程由于共享堆栈和堆内存的写操作而干扰彼此的执行。
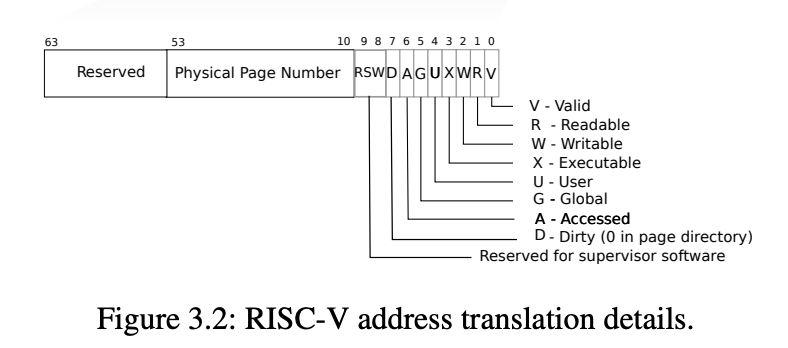
通过恰当使用页表权限和页错误,父进程和子进程可以安全地共享物理内存。当虚拟地址在页表中没有映射,或映射中 PTE_V (Page Table Entry )标志被清除,或者权限位(PTE_R, PTE_W, PTE_X, PTE_U,)禁止当前操作时,CPU 会引发页错误异常。RISC-V 区分三种页错误:加载页错误(当加载指令无法转换其虚拟地址时)、存储页错误(当存储指令无法转换其虚拟地址时)和指令页错误(当程序计数器中的地址无法转换时)。scause 寄存器指示页错误的类型,stval 寄存器包含无法转换的地址。
COW fork的基本思路是,父进程和子进程最初共享所有物理页面,但它们将页面映射为只读(即清除PTE_W标志)。父子进程都可以读取共享的物理内存。如果其中一个进程写入某个页面,RISC-V CPU会引发页错误异常。内核的trap处理程序会执行如下操作:
- 响应时会分配一个新的物理页面,
- 复制原物理页的内容到新分配的页中。
- 更改出错进程页表中的相关PTE,以指向副本,并允许读写操作
- 然后在引发错误的指令处恢复执行。
由于PTE现在允许写入,重新执行的指令将不再导致错误。写时复制需要进行某些记录管理,以帮助决定何时可以释放物理页面,因为每个页面可能会被多个页表引用,这取决于fork、页错误、exec和exit的历史。这个记录管理允许一个重要的优化:如果某个进程遭遇存储页错误,而该物理页面只被该进程的页表引用,则不需要复制。
COW fork使得fork速度更快,因为fork不需要立即复制内存。稍后,某些内存可能需要在写入时复制,但通常大部分内存不需要复制。一个常见的例子是fork之后执行exec:在fork之后可能会写入少量页面,但随后子进程的exec系统调用,它会用一个新的可执行程序替换当前进程的内存空间,从而释放大部分从父进程继承的内存。COW fork进一步优化了, 消除了这种内存复制的需求。此外,COW fork是透明(transparent)的:应用程序无需进行任何修改即可从中受益。
源码精读:lazy allocation 的三段式实现
三个参考文件正好串成「按需分配」的完整链路:
sys_sbrk(只记账不分配)→ 程序访问触发页错误 →usertrap(识别并分派页错误)→vmfault(真正分配物理页并建映射)。代码取自 xv6-riscv(rev5)。
1. sysproc.c:sys_sbrk():eager vs lazy 两条路
xv6 的 sbrk 系统调用带了第二个参数 t,用来选「立即分配(EAGER)」还是「惰性分配(LAZY)」:
uint64
sys_sbrk(void)
{
uint64 addr;
int t;
int n;
argint(0, &n); // 参数0:要增长的字节数 n(可负,表示收缩)
argint(1, &t); // 参数1:SBRK_EAGER 还是 SBRK_LAZY
addr = myproc()->sz; // 返回值是「旧的」堆顶(brk),符合 sbrk 语义
if (t == SBRK_EAGER || n < 0) {
// 立即分配:老路子,真的 kalloc + mappages
if (growproc(n) < 0) {
return -1;
}
} else {
// 惰性分配:只把 p->sz 调大,不碰物理内存,也不建 PTE。
// 等进程真正访问这片新地址时,vmfault() 才去分配。
if (addr + n < addr) // 溢出检查(回绕)
return -1;
if (addr + n > TRAPFRAME) // 不能涨过 TRAPFRAME(用户空间上界)
return -1;
myproc()->sz += n; // 关键:只改这一行!
}
return addr;
}p->sz 就够了?因为 p->sz 是内核判断「某个用户地址是否合法」的唯一依据。把 sz 调大后,[oldsz, sz) 这段地址就成了「合法但尚未映射」——访问它会触发页错误,而 vmfault 正是用 va < p->sz 来区分「该补一页」还是「真非法、杀进程」。注意收缩(n<0)一律走 eager 路径,因为要真的 uvmdealloc 释放物理页。对比「修改前」的 eager 调用链:
malloc → sbrk → sys_sbrk → growproc → uvmalloc → kalloc + mappages,全部在系统调用里同步完成。惰性版把后半段推迟到了页错误时。
2. trap.c:usertrap():识别页错误并分派
所有来自用户态的中断/异常/系统调用都汇聚到 usertrap。页错误在这里被 scause 认出来,并交给 vmfault:
uint64
usertrap(void)
{
int which_dev = 0;
if ((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
w_stvec((uint64)kernelvec); // 进了内核,后续 trap 改走 kernelvec
struct proc *p = myproc();
p->trapframe->epc = r_sepc(); // 保存用户 PC(出错/中断的那条指令地址)
if (r_scause() == 8) {
// —— 系统调用 ——
if (killed(p)) kexit(-1);
p->trapframe->epc += 4; // 跳过 ecall,返回到下一条
intr_on();
syscall();
} else if ((which_dev = devintr()) != 0) {
// —— 设备中断 —— ok
} else if ((r_scause() == 15 || r_scause() == 13) &&
vmfault(p->pagetable, r_stval(), (r_scause() == 13) ? 1 : 0) != 0) {
// —— 页错误,且 vmfault 成功补上了一页 —— 什么都不用做,下面会重跑指令
} else {
// —— 其它无法处理的异常:打印诊断信息并杀进程 ——
printk("usertrap(): unexpected scause 0x%lx pid=%d\n", r_scause(), p->pid);
printk(" sepc=0x%lx stval=0x%lx\n", r_sepc(), r_stval());
setkilled(p);
}
if (killed(p)) kexit(-1);
if (which_dev == 2) yield(); // 定时器中断 → 让出 CPU
prepare_return();
uint64 satp = MAKE_SATP(p->pagetable);
return satp; // 返回用户页表的 satp,交给 trampoline.S 切回用户态
}读这段的几个关键点:
scause == 15是 store page fault,13是 load page fault(还有12instruction page fault)。第三个参数(scause==13)?1:0把「是不是读错误」传给vmfault。- 这一句用了 C 的短路求值:
(scause==15||13) && vmfault(...) != 0。只有「是页错误」且「vmfault 成功」才落进这个分支;若vmfault返回 0(地址非法或没内存),整个条件为假,落到else把进程杀掉。 - 没有任何「重跑指令」的显式代码:因为
usertrap返回后经trampoline.S的sret会回到sepc(= 出错那条指令)。vmfault已经把缺的页补好,所以同一条指令再执行就不会 fault 了——这就是「resume the instruction」。 stval由r_stval()读出,是出错的虚拟地址(无需对齐,vmfault内部会PGROUNDDOWN)。
scause→错误类型(12/13/15);stval→出错的虚拟地址;sepc(存进 trapframe->epc)→出错指令地址,用于返回后重跑;当前进程 myproc() 隐含了「用户态 / 哪个地址空间」。3. vm.c:vmfault():真正分配物理页
vmfault 是 lazy allocation 的「兑现」环节,逻辑非常清爽:
uint64
vmfault(pagetable_t pagetable, uint64 va, int read)
{
uint64 mem;
struct proc *p = myproc();
if (va >= p->sz) // ① 合法性:地址必须落在已申请的范围内
return 0; // 否则返回 0 → usertrap 杀进程
va = PGROUNDDOWN(va); // ② 对齐到页边界
if (ismapped(pagetable, va)) { // ③ 已经映射过了?那不该来这(避免重复分配)
return 0;
}
mem = (uint64)kalloc(); // ④ 分配一页物理内存
if (mem == 0)
return 0; // 内存耗尽 → 返回 0 → 杀进程
memset((void *)mem, 0, PGSIZE); // ⑤ 清零(防泄露上一个使用者的数据)
if (mappages(p->pagetable, va, PGSIZE, mem, PTE_W | PTE_U | PTE_R) != 0) {
kfree((void *)mem); // ⑥ 建映射,失败则回收
return 0;
}
return mem; // ⑦ 成功,返回物理地址(非 0 即「已处理」)
}
// 辅助:这个 va 在页表里是否已有有效 PTE
int
ismapped(pagetable_t pagetable, uint64 va)
{
pte_t *pte = walk(pagetable, va, 0);
if (pte == 0) return 0;
if (*pte & PTE_V) return 1;
return 0;
}对照前面页错误处理程序的三步逻辑,代码一一对应:
| 处理程序逻辑 | vmfault 对应代码 |
|---|---|
| 判断 fault 地址是否合法 | if (va >= p->sz) return 0; |
| 合法 → 分配物理页 | kalloc() |
| 置零 | memset(..., 0, PGSIZE) |
| 建立映射、更新页表 | mappages(..., PTE_W|PTE_U|PTE_R) |
| 非法 / 失败 → 杀进程 | 返回 0,由 usertrap 的 else 分支 setkilled |
| 重新执行指令 | 由 sret 回到 sepc 隐式完成 |
usertrap → vmfault,没问题。但内核替进程读写用户内存时(如 read(fd, buf, n) 把数据 copyout 到还没分配的 buf),内核可不会触发用户态页错误。所以 copyout/copyin 里也内嵌了一手:walkaddr 发现没映射时,主动调用 vmfault 当场补页(见 Lec 5 源码精读 3.7)。正是这一处补丁,才让「内核访问惰性页」也能无感工作,惰性分配对应用才真正完全透明。4. 一次惰性缺页的完整时序
用户: p = sbrk(SBRK_LAZY, 100MB)
└─ sys_sbrk: 只 p->sz += 100MB,不分配 ← 瞬间返回,省了 100MB 物理内存
用户: buf[i] = x // 第一次访问某个新页
└─ CPU 取不到映射 → store page fault (scause=15), stval=&buf[i]
└─ trampoline.S → usertrap()
└─ scause==15 → vmfault(pagetable, stval, 0)
├─ va < p->sz ? 合法
├─ kalloc() + memset(0)
└─ mappages(va, PTE_W|PTE_U|PTE_R) ← 这一页现在有了
└─ return → sret 回到 sepc(buf[i]=x 那条指令)
└─ 指令重跑,这次命中映射,正常写入 ← 全程对用户透明参考资料
阅读xv6内核的实现,
kernel/sysproc.c:sbrk()kernel/trap.c:usertrap()kernel/vm.c:vmfault()
阅读xv6第5章的实现理解页错误。