Lec 19 文件系统性能 & 快速崩溃恢复
这节的主题是崩溃恢复。 崩溃会导致磁盘文件系统的不一致性,解决方法就是通过预写(write-ahead logging, WAL)
- 为什么需要崩溃恢复
- 基于日志记录的崩溃恢复
- Xv6的日志记录机制
- 挑战
- 总结
1. 为什么需要崩溃恢复?
崩溃恢复(Crash recovery) 是指,你正在向文件系统写文件,然后发生了断电等原因导致了crash,当你重启文件系统后,你的文件在文件系统中仍然可用吗?
问题核心是: 发生崩溃时,你可能进行了多步操作。这可能会导致文件系统违背不变性(比如,每个文件inode只能分配给一个文件等等)。重启后:
- 糟糕的情况: 再一次崩溃因为文件系统损坏。
- 更糟糕的情况: 没有崩溃,但是继续读写错误的数据。
示例
下面展示什么情况下会发生上面的情况
create
$ echo hi > x
# 如果我们创建了trace bwrite 的话
bwrite: block 33 by ialloc # allocate inode in inode block 33
bwrite: block 33 by iupdate # update inode (e.g., set nlink)
bwrite: block 46 by writei # write directory entry, adding "x" by dirlink()
bwrite: block 32 by iupdate # update directory inode, because inode may have changed假如崩溃发生在
iupdate和writei之间
Solution:为文件分配了inode,崩溃时候没有释放也米有被使用——这不算太糟糕
如果崩溃发生在
writei和iupdate之间,会发生什么?
Solution:目录指向了一个"自由"inode ——这是个灾难! 要么重启后再次崩溃,要么更糟糕地,inode分配给其他。
write
写入包含的步骤如下:(非顺序)
inode addrs[] and len:更新 inode 的地址数组(
addrs[])和文件的长度。addrs[]保存了文件内容所在的磁盘块地址,len是文件的长度。indirect block:如果文件内容占用的块数超过了直接块的数量,文件系统会使用间接块来存储额外的块地址。
block content:写入实际的数据块内容到磁盘。
block free bitmap:更新自由块位图,标记哪些块已经被分配并使用。
文件系统崩溃发生在 更新
inode和数据块位图的中间阶段,会发生什么?
Solution: 这意味着 inode 指向了一个仍然标记为“自由”的块,因为没有更新bitmap —— 灾难级错误
文件系统崩溃发生在 更新数据块位图和
inode addrs[]的中间阶段,会发生什么?
Solution:数据块已分配并写入内容,块分配位图也已更新,标记该块为“已占用”,但是inode addr[]尚未更新——造成”孤块“,影响较小
unlink
删除包含的步骤如下:(非顺序)
- block free bitmaps:释放文件数据块,并更新自由块位图,标记这些块为可用。
- free inode:释放文件的 inode,并将其标记为可用,以便未来可以分配给其他文件。
- erase dirent:从目录中删除文件名和对应的 inode,目录项不再引用该文
期望的结果是什么?
我们期望在重启并运行恢复代码后:
文件系统的内部不变量保持不变。例如,没有任何块既在空闲列表中又属于某个文件。
除了最后几次操作,其他操作都保存在磁盘上 例如,我昨天写入的数据都得到了保存,但崩溃时正在写入的数据可能没有被保存。 因此,用户可能需要检查最后几次操作的情况。
没有顺序异常 例如:
bashecho 99 > result echo done > status
正确性和性能的权衡
正确性和性能常常相互冲突,在系统设计中要进行权衡。
- 磁盘写入速度很慢!
- 为了安全性 => 尽快写入磁盘
- 为了速度 => 尽量不写入磁盘(可以通过批量处理、写回缓存、按磁道排序等方式来优化)
崩溃恢复是一个反复出现的问题,它
- 存在于所有存储系统中,例如数据库
- 过去几十年间,已经有很多工作投入到解决这一问题上
- 有许多巧妙的性能与正确性权衡方案
2. 基于日志记录的崩溃恢复
最流行的解决方案:日志记录(logging,journaling),最初来自数据库世界,但是现在有很多文件系统使用日志。
设计的目标:
- 确保系统调用在崩溃时具有原子性(对于崩溃而言,系统调用具有原子性)
- 快恢复(传统地,需要花数个小时运行
fsck(文件系统检查工具)来检查和修复不一致)
我们介绍Xv6的日志系统,提供了数据安全性和快速恢复;然后介绍Linux的 EXT3 文件系统,他在正常操作中同样具有较高的速度。
基本思想
- 目标是实现原子操作:系统调用的所有写操作要么全部完成,要么完全不执行。
- 我们称这样的原子操作为”事务“
- 将系统调用要执行的所有写操作记录到磁盘上的日志
- 然后再磁盘上记录”done“标记(即提交,commit)
- 最后执行文件系统的磁盘写入操作(install)
- 在崩溃 + 恢复:
- 如果日志有”完成“的标记,则重放日志中所有的写操作
- 如果没有“完成”的标记,则忽略日志内容
- 这就是一种预写日志(WAL)
- 预写日志规则:只有当所有的写操作日志在磁盘上,并且被标记为已提交之后,才能安装事务的写操作到磁盘上。
日志记录是个奇迹:
- 复杂的、可变的数据结构的崩溃恢复通常非常困难。
- 日志记录往往可以基于现有的存储系统进行分层实现。
- 它与高性能存储系统兼容,能够同时提供可靠性和效率
怎么支持一个提交里面的多个写入?
由于扇区的写入是原子。 当我们涉及到多个扇区的写入,我们可以将其中一个扇区作为关键扇区,最终的提交以这个扇区为准。这样就能够实现原子性。
3. Xv6的日志记录机制
xv6的日志结构
在磁盘中
| header | data | data.... |
|---|---|---|
| $b_n0, bn1 ... bn-1 | D | D{bn1} .... |
- 磁盘上日志头部信息中
n值代表着提交点- 非零意味着已提交,日志内容合法,并且是个完整的事务
- 零则意味着未提交,恢复时候应该忽略掉这条日志
- 磁盘上的布局是按照块号的(上一节已经提到过)
- 2:日志头
- 3:日志块
- 32:inode 块
- 45:位图
- 46:内容块
在内存中
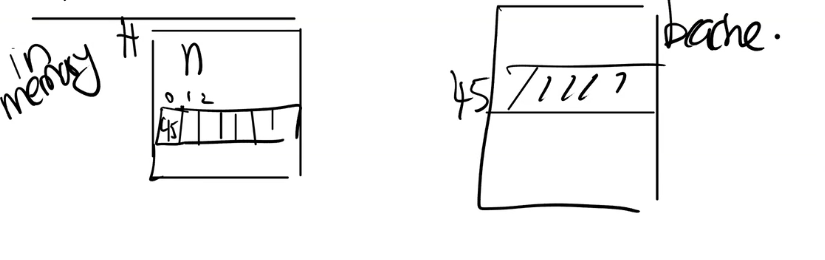
日志记录过程
write:
- 将块号添加到内存中的日志块号数组
- 将实际数据保存在缓冲区缓存中(被pinned,不允许被替换)
on commit:
- 将缓冲区写入磁盘上的日志
- 等待磁盘完成写入(“同步”)
- 将日志头扇区写入磁盘包括块号
after commit:
- 将日志中的块安装(写入)到文件系统中的它们原本的位置
- 解除块的固定
- 将磁盘上日志头中的“n”值写为零
示例:echo a > x
我修改了 bwrite() 以打印低级别的磁盘写操作,即事务提交期间发生的磁盘写操作。
$ echo a > x
// create
bwrite 3 // inode, 33
bwrite 4 // directory content, 46
bwrite 5 // directory inode, 32
bwrite 2 // commit (block #s and n)
bwrite 33 // install inode for x
bwrite 46 // install directory content
bwrite 32 // install dir inode
bwrite 2 // mark log "empty"
// write
bwrite 3
bwrite 4
bwrite 5
bwrite 2
bwrite 45 // bitmap
bwrite 595 // a (note: bzero was absorbed)
bwrite 33 // inode (file size)
bwrite 2
// write
bwrite 3
bwrite 4
bwrite 2
bwrite 595 // \n
bwrite 33 // inode
bwrite 2让我们看看第二次事务,一个 write()
file.c:filewrite:
- 计算在日志满之前可以写入多少块
- 在一个事务中写入这些块
结合 fs.c:writei():
begin_op();
bmap(); // can write bitmap, indirect block
log_write(); // to bzero new block
bread();
modify bp->data;
log_write();
... // absorbs bzero
iupdate() // writes inode
end_op();在结合 log.c: begin_op():
- 需要指示哪组的写入需要原子的
- 需要检查日志是否被提交
- 检查写入能够装入日志的剩余部分
log.c: log_write:
- 添加扇区 到内存数组
bpin()会把块"pin"到缓冲区缓存,因此bio.c 不会驱逐它
log.c: end_op()
- 如果没有未完成的操作,
commit
commit():
将更新的块从缓存复制到磁盘上的日志
在磁盘日志头部中记录扇区号和“已完成”
安装写入 —— 将日志中的内容复制到磁盘上的文件系统中
bunpin()将解除缓存中的固定 —— 现在它可以被驱逐
从日志中擦除“已完成”
如果在事务过程中崩溃会发生什么?
内存会丢失,只有崩溃时的磁盘数据会保留下来
在启动期间,内核会在使用文件系统之前调用
recover_from_log()- 如果日志头信息显示“已完成”:将日志中的块复制到磁盘上的实际位置
磁盘中的日志有什么内容
- 提交前崩溃
- 提交期间崩溃 —— 提交点?
- install_trans()期间崩溃
- 刚重启时崩溃,在执行
recover_from_log()时崩溃
注意:可以多次重放日志,只要没有其他活动介入。
xv6 假设磁盘是“故障停止”模型:
- 要么正确完成写入,要么未写入
- 比如可能由于断电无法完成最后一次写入
- 因此:
- 没有部分写入(每次扇区写入是原子的)
- 没有任意写入
- 没有扇区衰退(没有读取错误)
- 没有读取错误扇区
4. 挑战
挑战1:阻止从缓存中写回
一个系统能够调用可以安全地更新一个缓存块,但是这个块不能写回FS直到完成事务提交。因为,缓存可能会消耗掉空间,以及可能会被临时驱逐,为了读取和缓存其他数据。
考虑 create 例子
- 写脏inode到日志
- 写目录块到日志
- 驱逐脏inode
- 提交
Xv6的解决办法: 保证缓冲区缓存足够大, 将脏的块pin(钉)住不让驱逐,commit 完再unpin
挑战2: 允许并发系统调用
系统需要处理多个并发调用的写操作,将它们记录到日志中。但在提交操作时,日志中不应包含未完成事务的数据,以保证日志的原子性和一致性。
Xv6的解决方案:
- 计算每个系统调用写操作的上界
- 将一些系统调用分成多个小的事务。这样,尽管大文件的写入操作可能不是原子的,但即使在崩溃时,日志也会保留写入操作的前缀(即已经完成的部分),保证数据一致性
挑战3:允许并发系统调用
必须支持多个系统调用的写操作同时写入日志。
在提交时, 必须将它们记录到日志中,但日志中不应包含未完成的事务数据。
Xv6的解决方案:
- 限制新系统调用的启动
- 如果当前日志中可能没有足够的空间容纳新调用的数据,则不允许新调用开始执行
- 或者等待当前的并发调用提交日志后释放空间,再允许新调用执行
- 当所有进行中的调用结束时
- 提交日志、释放日志空间
- 唤醒等待的调用,使其能够继续运行。
挑战4:一个事务中可能对同一个块多次写入
log_write() 只会影响内存中的缓存块,因此,内存中的缓存块反映多个未提交事务的写入,但是日志安装(install)操作仅在没有”正在处理“的事务发生,这确保了磁盘上更新的块只包含已提交事务的数据。
性能优化点:写入吸收(write absortion)
总结
Xv6的日志记录设计好的方面有哪些?
- 写前日志确保了正确性
- 良好的磁盘吞吐量: 通过日志很自然地批量写入
- 但是数据磁盘块被写入了两次
- 支持并发
Xv6的日志记录设计差的方面有哪些?
- 不是很高效
- 每个块需要写入两次(日志记录 + 安装)
- 日志记录整个块,即便只是几个字节的变动
- 同步地逐个写入日志块
- 可以批量写入并且只同步写入头部信息
- 日志的写入和安装的写入太着急
- 这两个可以惰性写入,但是必须首先写入日志。
- 当操作不能装入日志时会发生麻烦
- unlink 中的 truncating 文件步骤,可能会弄脏很多块。
阅读资料: Journaling the Linux ext2fs Filesystem, 1997
相关阅读:
Stephen Tweedie 2000年的演讲《EXT3, Journaling Filesystem》
北美首席Linux 文件系统开发者Theodore Ts’o 的 关于Linux文件系统的访谈
在讲文件系统时, 我们会大量篇幅讲解日志记录(logging, aka. journal),它为磁盘上的文件系统的数据结构提供崩溃恢复, 性能和正确性方面有很多值得。
Logging背后的思想(ext3和Xv6亦是如此)是让系统调用保持原子性。
要确保无论何时崩溃都能得到一致的文件系统状态,需要满足两条关键的规则:
- 预写规则:在所有的日志写入操作提交到磁盘之前,不要开始对主文件系统(home FS)进行写入操作
- 释放规则:只有当所有 home FS 写都真正落盘后,日志才可以安全清除
1. 背景与目标
多年来,ext3 一直都是Linux的主要文件系统,现在的ext4和ext3很相似。
日志机制的目标:1)确保FS操作原子性;2)提供高性能
在Xv6的日志系统中,系统调用正常执行时的流程:
- 系统调用期间
- 不直接写日磁盘
- 只修改内存中的缓存块
- 把这些改动标记为dirty
- 系统调用结束时(commit阶段)
- 把所有更新后的缓存块写入磁盘上的 log 区域
- 在 log 区域里写一个 “commit record” 标记 —— 表示日志完整
- 把日志中的内容(即更新后的块)拷贝到真正的文件系统位置;即把 log 应用(或者说生效,apply)到 FS。
若系统崩溃。 如果日志标记为已提交,把 log 的内容复制到 FS 区域;否则丢弃Log。
ext3相比Xv6的改进
ext3比Xv6性能更高,具有更好的异步性与批处理。因为,1)ext3可以将多个系统调用的修改合并到同一个事务中,系统调用通常不必等待日志写入;2)批处理使得多次对同一块的修改可以被“吸收”(write absorption),从而减少写盘次数;3)ext3 不将文件内容(data blocks)写入日志,只记录元数据(i-node、目录项、位图等)。 因此文件内容只写一次,效率更高。
NOTE
Linux 主要的默认的文件系统是ext3 或者 ext4,Windows用的是NTFS, FAT过时但非常简单文件系统。本节主要讲ext3。 ext3 是 ext2 的直接后继者,旨在解决 ext2 最大的痛点——崩溃恢复慢。重点关注性能和实际设计细节。
2. ext3数据结构
内存结构
- 写回缓存(write-back block cache)
- 当前事务信息:
- 序列号
- 待写入日志的块号列表
- 活跃的系统调用handles
- 前一个事务
磁盘结构
- 文件系统
- 循环日志——位于一个固定大小的预分配文件中
事务提交过程(后台进行):
- 阻塞新系统调用
- 等待当前活跃的系统调用全部
stop() - 打开新事务(允许新系统调用继续)
- 写日志描述块
- 将缓存中修改的数据写入日志
- 等待数据写完
- 写提交块
- 等待提交块完成
- 允许这些修改写入主文件系统(但不强制立即写)
论文阅读: Journaling the Linux ext2fs Filesystem
Journaling the Linux ext2fs Filesystem, 1997
摘要
这篇论文旨在为Linux的ext2fs文件系统设计并实现一个事务性元数据日志。我们回顾了系统崩溃后恢复文件系统的问题,并介绍了一种设计,该设计旨在通过向文件系统添加事务性日志来提高ext2fs在崩溃恢复过程中的速度和可靠性。
介绍
文件系统是现代操作系统的核心,既要求快速,又要求极高的可靠性。在意外重启后,传统的文件系统检查技术可能需要一段时间(数小时)才能将文件系统恢复到一致状态。磁盘容量翻倍,则恢复时间也翻倍。需要一种机制来避免每次机器重启时都需要经历繁重的恢复阶段。
文件系统里面有什么?
我们对文件系统有哪些功能需求?文件系统呈现给应用程序的方式是操作系统的一部分——通常要求文件名遵循一定的规则,并且文件具有特定的属性,这些属性以特定方式进行解释。
然而,文件系统在内部并没受到如此多的限制,文件系统实现者可以有一定的自由度进行设计。比如数据在磁盘上的布局(或者,如果文件系统不是本地的,可能是其网络协议)、内部缓存的细节以及用于调度磁盘I/O的算法都是可以更改的,而不会违反文件系统应用接口的规范。
我们选择一种设计的原因有很多。对旧的FS的兼容性也许是个问题。当我们在解决FS恢复时间长的问题时,会考虑如下因素。
- 性能不应因使用新文件系统而受到严重影响;
- 必须保持与现有应用程序的兼容性;
- 文件系统的可靠性不能以任何方式受到损害。
文件系统的可靠性
filesystem reliability,有几个要点
- 保全性。在系统崩溃之前已经存储在磁盘上的数据必须始终安全。即,那些已经稳定存储在磁盘上的文件不应因恢复操作而受到损害
- 可预测性。就是说文件系统发生(过)故障,需要有标志能证明。这样才能有针对性的应对。
- 原子性。许多文件系统操作需要多个独立的 I/O 操作完成。例如,将文件从一个目录重命名到另一个目录。原子性要求,在恢复操作完成后,这些文件系统操作要么被完全写入磁盘,要么完全撤销。
现有实现
ext2fs文件系统提供了保全性,但非原子性且不可预测。
延迟有序写入
延迟有序写入的策略是在内存中维护写入顺序,然后按这个顺序将数据批量写入磁盘,而不必等待每次写操作的完成。这提高了性能,同时保证了数据按正确的顺序写入磁盘。但也存在
1. 性能问题;
2. 循环引用问题: 如果多个文件或目录的写操作相互依赖,就会出现循环依赖,即两个数据块互相依赖,导致无法同时写入。
软更新机制
它的原理是,在写入磁盘时,如果某个块仍有未解决的依赖关系,系统可以回滚部分更新,等依赖关系解除后再恢复这些更新。这种方式允许在某些情况下打破循环依赖,使系统可以在任何顺序下写入数据,从而提高写入效率。软更新机制解决了延迟有序写入中的循环依赖问题。
日志文件系统
通过引入一个日志区域来记录所有元数据的更新,从而确保文件系统更新的原子性。原子性:一个文件系统操作要么完全完成,要么完全不做,避免了操作进行到一半时系统崩溃导致的数据不一致问题。
这种方式有效地避免了系统崩溃时文件系统处于不一致状态,同时加快了恢复过程。恢复不需要扫描整个磁盘,只需根据日志来回滚或重新执行操作。
设计一个新的文件系统
基本动机是为了消除系统崩溃后文件系统长时间恢复的问题,我们选择了文件系统日志方案作为设计的基础。日志记录能够实现快速文件系统恢复,是因为在任何时候,所有可能在磁盘上不一致的数据同时也被记录在日志中。因此,文件系统恢复只需扫描日志并将所有已提交的数据复制回主文件系统区域即可。
选择日志记录还有另一个重要的好处。与传统文件系统不同,日志文件系统将临时数据保存在一个新的位置,独立于磁盘上的永久数据和元数据。因此,这样的文件系统不会要求永久数据必须以任何特定方式存储。因此,我们实际上并不是为Linux设计一个全新的文件系统,而是为现有的ext2fs添加了一个新功能——事务性文件系统日志。
剖析事务
在日志文件系统中,事务是一个中心概念,它对应于文件系统的单次更新。每次应用程序向文件系统发出的请求都会产生一个事务,事务包含所有与该请求相关的元数据更改。例如,向文件写入数据会更新磁盘上文件的inode中的修改时间戳,还可能更新文件长度信息和块映射信息(如果写操作扩展了文件)。如果为文件分配了新块,配额信息、可用磁盘空间和使用的块位图也必须更新,这些都必须记录在事务中。
事务中还有一个隐含的操作我们需要注意。事务还涉及读取文件系统的现有内容,这在事务之间建立了依赖关系。如果一个事务修改了磁盘上的某个块,另一个基于此数据的事务在修改磁盘之前不能提交。这种依赖关系即使在两个事务不尝试写回相同的块时也会存在。例如,一个事务删除目录中某个块的文件名,另一个事务在不同的块中插入相同的文件名。这两个操作可能不会覆盖相同的写入块,但第二个操作只有在第一个成功之后才有效(否则会导致目录中出现重复的条目)。
文件系统必须严格遵循事务中 数据块写入先于元数据提交 的规则。在我们能够提交一个为文件分配新块的事务之前,必须绝对确保事务创建的所有数据块已经实际写入磁盘(我们称这些数据块为依赖数据)。如果忽略这一要求,虽然不会破坏文件系统元数据的完整性,但可能导致在崩溃恢复后,新文件仍然包含先前文件的内容。这不仅是一个安全风险,同时也是一个一致性问题。
合并事务
许多日志文件系统中的术语和技术来源于数据库领域,日志是确保复杂事务原子性提交的标准机制。然而,数据库事务与文件系统有许多不同之处,这些差异使我们能够极大地简化事务处理。
两个最大的不同是文件系统没有事务中止,且所有文件系统事务的生命周期都相对较短。在数据库中,我们有时希望在事务中途中止并丢弃已进行的更改,但在ext2fs中并不存在这种情况——当我们开始对文件系统进行任何更改时,已经确认更改可以合法完成。在开始写入更改之前中止事务(例如,如果发现同名文件存在则中止创建文件操作)不会有问题,因为我们可以在没有更改的情况下提交事务,达到同样的效果。
第二个不同点是文件系统事务的短生命周期。这意味着我们可以大大简化事务之间的依赖关系。如果我们必须处理一些生命周期很长的事务,那么需要允许它们在不冲突的情况下独立提交,以避免单个事务阻塞整个系统。然而,如果所有事务都足够短,那么我们可以要求事务按严格的顺序提交到磁盘,而不会显著影响性能。
基于这个观察,我们可以对事务模型进行简化,从而大幅减少实现的复杂性,同时提高性能。与其为每次文件系统更新创建一个独立的事务,我们可以定期创建一个新事务,并允许所有文件系统服务调用将其更新添加到这个全系统范围的复合事务中。
这种机制有一个很大的优势。因为复合事务中的所有操作将一起提交到日志中,因此我们不必为那些频繁更新的元数据块写入单独的副本。特别是在创建新文件时,这很有帮助,通常每次写入文件都会导致文件扩展,从而不断更新配额、位图块和inode块。在复合事务的生命周期内,任何被多次更新的块只需提交到磁盘一次。
何时提交当前的复合事务并开始新的事务是一个策略性决策,应该由用户控制,因为这涉及到影响系统性能的权衡。提交等待的时间越长,可以合并到日志中的文件系统操作越多,因此从长远来看所需的IO操作就越少。然而,较长的提交时间会占用更多的内存和磁盘空间,并在发生崩溃时增加丢失更新的可能性。这也可能导致磁盘活动的突然增加,使文件系统的响应时间变得难以预测。
在磁盘上的表示
完全兼容现有的ext2fs内核,传统Unix系统通过将每个文件与磁盘上的唯一编号inode向关联来将数据存储到磁盘上。