Lec 5 虚拟内存 & 页表
本讲定位:假设我们在扁平的物理空间,0 到
我们希望每个进程都有自己的地址空间,要求可以读写自己的内存,但不能访问其他进程和内核的内存。核心挑战是,如何把多个虚拟地址空间映射到同一块物理内存上,同时保证隔离性?
页面管理
针对开头问题, OS给出解决方案——分页(Paging)。 Xv6 通过使用RISC-V的分页硬件来实现地址空间。具体机制:
页表提供了一种间接寻址的机制 $CPU \xrightarrow{VA} MMU \xrightarrow{PA} RAM $, MMU 是独立于CPU的硬件
软件只能LD(Load)、ST(Store)虚拟地址(Virtual Address),而不是物理地址(Physical Address)。内核告诉MMU如何将虚拟地址映射成物理地址。MMU本质上维护了一个表,由虚拟地址索引到物理地址,而用户代码只能使用在页表中有映射的地址
va | pa ------- x | y我们希望每个进程都有不同的地址空间,因此我们需要不止一个页表——并且需要进行切换, MMU有一个satp寄存器(Supervisor Address Translation and Protection Register),内核通过它来切换页表, satp保存当前页表的物理地址(也就是当前进程的“根”地址),MMU从内存中加载页表项,内核可以通过写入内存来修改页表。
由图3.1所示(简化视角),分页硬件MMU通过虚拟地址的低位偏移量加上页表项从而找到物理地址。
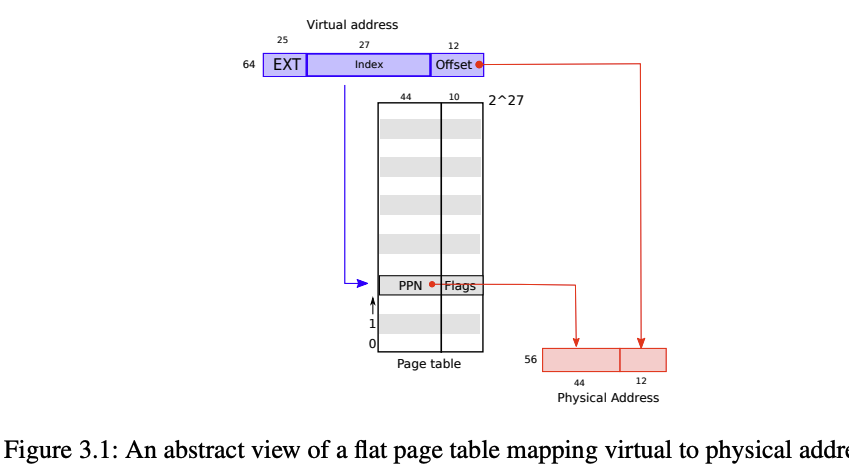
Solution: 理论总共有
RISC-V使用4KB的页进行映射,因此每一个页面在页表上都有一个对应条目。由于4KB = 12比特,而RISC-V为64位字,因此页表索引是虚拟地址的高52位。不过实际上还是太多了, RISC-V Sv39 限制了地址空间位512GB(39bit),也就是说页表项数目为27bit(最高的 25 位是未使用)。如果APP想要使用超过512GB的地址空间,则需要更改硬件(Sv48, Sv57)
Sol:由图3.2底部所示,一个PTE = 10位保留位 + 44位PPN(物理页号) + 10位标志位(flags)。 也就是说每个PTE实际上是是64位,但实际只用了54位,前44位的PPN是56位物理地址的高位,后10位则是标记位, 比如Valid、Writeable等等,
| 保留 | PPN | Flag |
|---|---|---|
| 10位 | 44位 | 10位 |
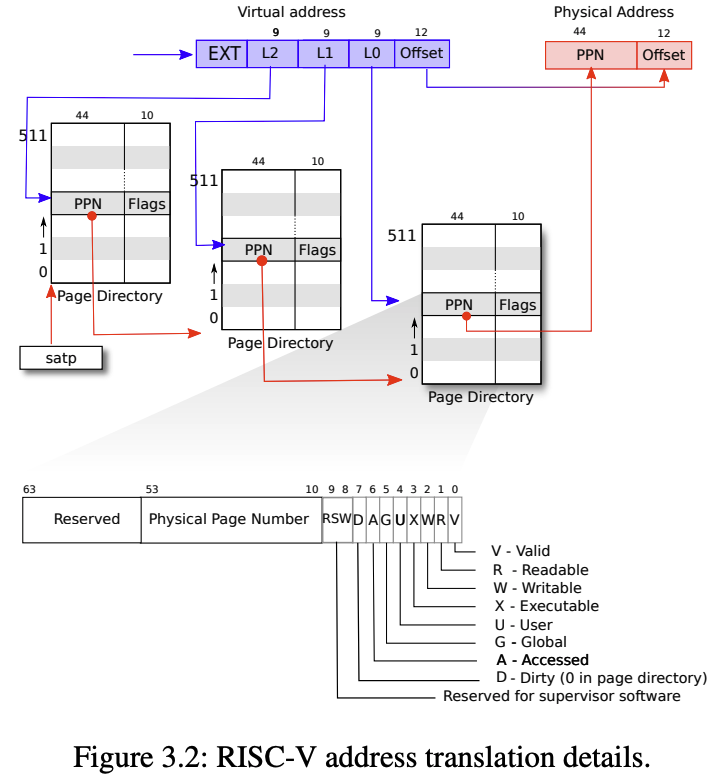
两套地址的拆分是不对称的:
虚拟地址 VA(39 位) 物理地址 PA(56 位)
+--------+--------+--------+ +----------------+
| VPN[2] | VPN[1] | VPN[0] | | PPN |
| 9bit | 9bit | 9bit | | 44 bit |
+--------+--------+--------+ +----------------+
| offset 12 位 | | offset 12 位 |
+--------------------------+ +----------------+
27 位索引 + 12 位偏移 = 39 44 位页号 + 12 位偏移 = 56为什么要让物理地址比虚拟地址大? 因为页表的作用是把「每个进程的小虚拟窗口」映射进「全机器共享的大物理空间」,两者本就不需要一样大:
- VA 决定「一个进程能看到多大」:一个进程用不满 512GB,39 位足够,再大反而徒增页表层级。
- PA 决定「整台机器能装多少」:要容纳所有进程的内存 + 内核 + 大量 MMIO 设备。若 PPN 也只有 27 位,物理空间就被锁死在
27+12=39位 = 512GB;给到 44 位 PPN(56 位 PA)后,硬件理论上可寻址2^56 = 64PB,远超任何单进程的虚拟窗口。多个进程各自的 39 位虚拟空间,通过各自的页表,最终都映射进同一个 56 位的大物理空间里——所以 PPN(44 位)比 VPN(27 位)大是设计的必然。这也是为什么后来的 Sv48 / Sv57 扩大的是虚拟地址(48/57 位),而那 44 位 PPN 在这几档里基本不变:两者各自独立演进。
Solution: 索引位数为27 位,即
为了解决这个问题,xv6使用多级页表。关注点在于,只为用到的虚拟地址区域分配页表,如图3.2所示,虚拟地址的最高 9 位索引到索引第一级页目录,第一级中的 PTE 包含第二级页目录的物理地址,然后用VA 的第二个 9 位去索引第二级页目录,第三个 9 位用来索引第三级页目录,得到一个 PTE,这个 PTE 指向目标内存页。实际上是一个树结构。
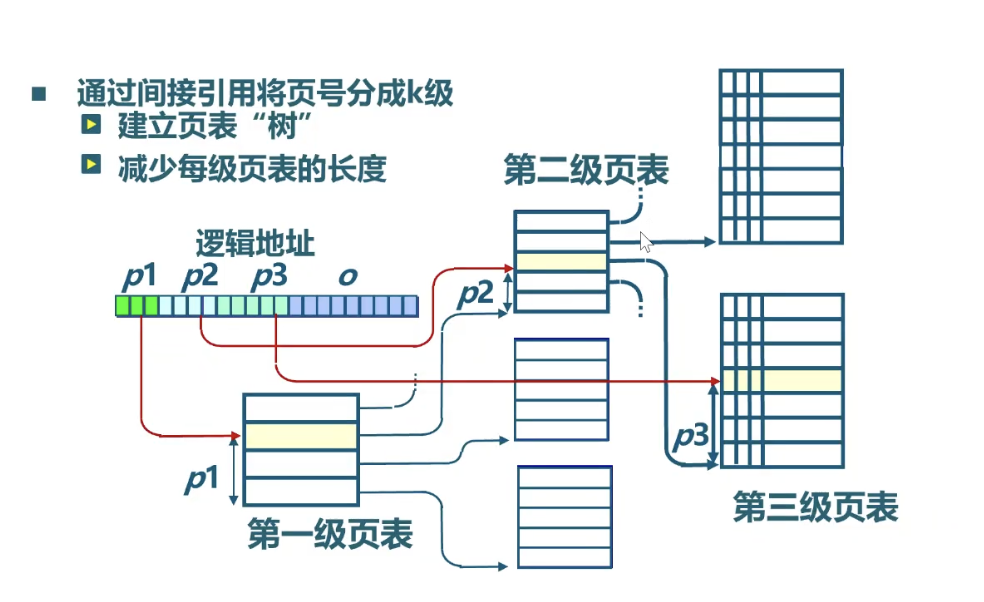
Sol: 一句话——单级页表必须为整个虚拟地址空间预先分配整张表,而树状页表只为「真正用到的那部分」分配子表。省的就是真实地址空间里那些没用到的大片空洞。
(1)扁平表为什么浪费:硬件靠「用 VPN 直接索引数组」定位 PTE,所以这张数组必须完整存在,哪怕进程只用了几页 —— 2^27 项 × 8 字节 = 1GB/进程,固定开销,与实际用量无关。而真实进程的地址空间是两头用、中间全空的:
0 ┌──────────┐ text/data/heap(底部一小块)
│██████ │
│ …… │ ← 巨大的未使用空洞(占 99.99%)
│ ████│ stack(顶部一小块)
└──────────┘ MAXVA扁平表却要为那片空洞也留满 PTE,于是 1GB 几乎全浪费。
(2)树状表怎么省:关键在于上层一个「无效 PTE」就能代表下面一整片不存在的子树,无效区域根本不分配低层页表。Sv39 里每级覆盖范围:
| 层级 | 一个 PTE 覆盖 | 一整页目录(512项)覆盖 |
|---|---|---|
| L2(根) | 1 GB | 512 GB |
| L1 | 2 MB | 1 GB |
| L0(叶子) | 4 KB | 2 MB |
那片空洞在 L2 里只是几条 PTE_V=0 的条目(0 额外开销),下面的 L1/L0 页根本不创建。
(3)算一笔账(这就是 3 × 2^9 项 代替 2^27 项 的含义):假设进程只映射 1 个页:
- 扁平表:
2^27项 = 1GB(雷打不动) - 树状表:沿路径每级一张页目录 → L2 + L1 + L0 = 3 张页表页 = 3×512 项 = 12KB
即「翻译一个地址只需碰 3 × 2^9 个条目,而不是一整个 2^27 的数组」。开销随实际用量增长,而非一上来顶满;连续映射还能共享低层表(连续 512 页 = 2MB 共用一张 L0)。
代价:每次翻译要走 3 级访存(比一次索引慢),但有 TLB 缓存命中后即直达,所以实际不慢——典型的用时间换空间。
9 位决定了页目录的大小 9 位 —> 512 个 PTE —> 64 位 / PTE -> 4096 字节 = 1页大小; 也就是说,9 位意味着一个目录可以正好放入一页内存。
是的,即使在硬件中。 但实际并不慢,因为CPU的MMU通常会缓存最近的转换这个缓存叫做地址转换旁路缓冲(Translation Look-aside Buffer,TLB),中国业界俗称快表。 VA → PA不需要走页表,直接得到物理地址,接近寄存器访问,只有TLB未命中才需要由硬件遍历页表树,然后把结果放入TLB。 并且, 为了让TLB更加有效,页表可以超页(巨页),一个 PTE 映射更大的内存范围来降低miss率
PTE中的标志位含义
- Valid:表示页表项是否有效。
- Referenced:表示该页是否被访问过
- Writable:表示该页是否可写
- X(Executable):表示该页是否可执行
- U(User-mode accessible):表示该页是否可以被用户态访问。
- A(Accessed): 表示该页是否已被访问过。
- D(Dirty): 表示该页是否已被修改(写过)
- G(Global):表示该页是否全局有效,不因进程切换而失效。
- Reserved:保留位
与 L1,L2缓存的关系
题外话,有兴趣的话可以了解下。
结论先行:L1 一般是 VIPT(虚拟索引、物理标签),L2/L3 一般是 PIPT(全物理)。
缓存查一次要做两件事:用索引(index)找到 cache line 所在的 set,用标签(tag)确认是不是要的那块。索引和标签各自可用虚拟或物理地址,于是有四种组合,实际常用三种:
| 类型 | 索引 | 标签 | 谁在用 |
|---|---|---|---|
| VIVT | 虚拟 | 虚拟 | 几乎淘汰 |
| VIPT | 虚拟 | 物理 | 现代 L1 |
| PIPT | 物理 | 物理 | 现代 L2/L3 |
L1:通常 VIPT(虚拟索引 + 物理标签)。L1 在关键延迟路径上,必须快,它的把戏是:用虚拟地址里「翻译前后不变」的那部分(页内偏移低 12 位)去做索引,和 TLB 翻译并行进行;等 TLB 给出物理地址后,再用物理 tag 去比对。
VA
┌────┴────┐
高位(VPN) 低位(offset 12位)
│ │
▼ ▼
[TLB] 用 offset 位并行索引 L1
│ │
▼ ▼
物理 tag ──比对──> 命中?- 索引为何用虚拟地址:不用等 TLB,省时间;而页内偏移位在 VA/PA 里相同(翻译只换高位页号、不动低 12 位),拿它当索引完全安全。
- tag 为何用物理地址:避免下面的「别名/同名」问题,并让多核缓存一致性好做。
- 约束:只有当「索引所需的位 ≤ 页内偏移位」时这套才成立,即
L1容量 / 路数 ≤ 页大小。 - 这正是 Lec 23 Meltdown 里那句「Intel L1 是 VIPT」的由来。
纯 VIVT(虚拟索引+虚拟标签)虽然最快,但几乎不用,因为有两个老毛病:
- 同名(homonym):同一 VA 在不同进程指向不同 PA → 切换地址空间必须 flush 整个缓存;
- 别名(alias/synonym):不同 VA 映射到同一 PA → 同一份数据在缓存里存多份,写一份另一份变脏。
L2 / L3:几乎都是 PIPT(物理索引 + 物理标签)。它们不在最紧的延迟路径上——能到 L2 说明 L1 已 miss,地址翻译早就做完了,手里已是物理地址,直接物理索引+标签最简单;物理寻址天然无别名/同名问题,且多核之间的缓存一致性(MESI 等)都按物理地址协调,所以共享的 L2/L3 用 PIPT 是必然。
和 MMU / TLB 的关系:
- MMU 负责 VA→PA(走页表),TLB 是 MMU 里缓存翻译结果的快表。
- L1(VIPT):索引阶段不依赖 TLB(直接用 VA 低位),但 tag 比对依赖 TLB 给出的物理地址——两者并行,所以快。
- L2/L3(PIPT):完全工作在物理地址上,MMU 翻译这一步在到达它们之前就已完成。
Xv6的虚拟内存
XV6内核页表布局如图,左边是虚拟地址,右边是物理地址。
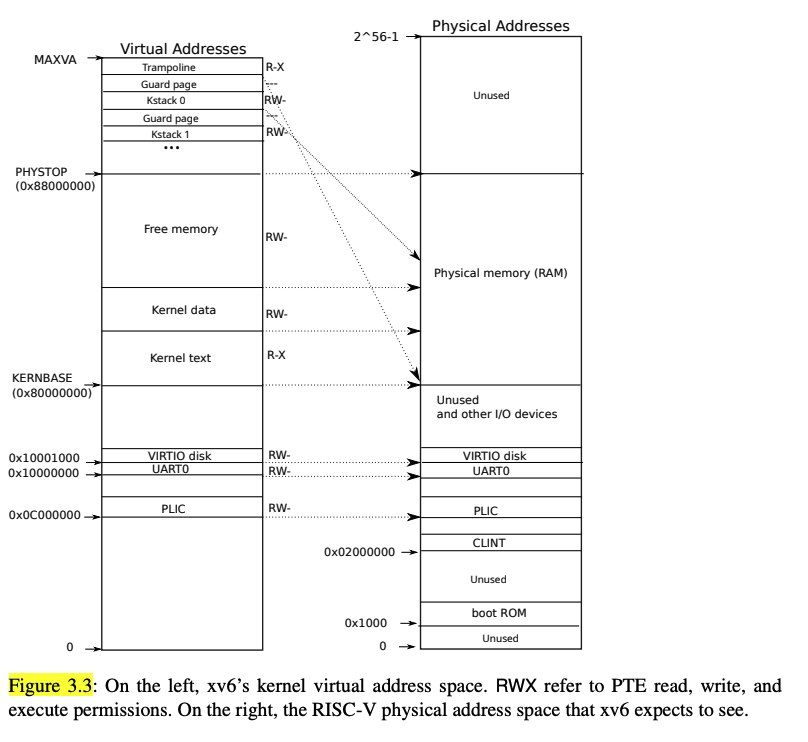
Solution: 通常由硬件(主板/平台)决定,包括RAM和内存映射的设备寄存器(memory-mapped I/O)。我们使用的是 QEMU 来模拟硬件平台, 物理地址布局由 QEMU 决定,在源码hw/riscv/virt.c指定。
而左边由内核页表(kernel page table)定义,这个页表实在内核boot过程中建立的,在大多数情况下VA ≈ PA, 内核可以把物理地址当作虚拟地址使用, 可以直接用 C 指针访问*(char*)pa,编程很方便。
在权限位设计上,内核代码段(text),无写权限防止代码被修改; 在内核数据段(data)没有执行权限,防止数据被当作代码执行。
上图中假设RAM的大小为128MB,从0x80000000开始(地址映射是由内核页表决定),则物理地址最大为0x88000000,现代系统应动态检测内存大小,而不是依赖固定值。
高地址区域(最顶部),包含了跳板页(trampoline)和内核栈(Kernel stacks)。不管是内核还是每个进程的页表中, 跳板页都映射在物理地址, 这是切换页表(user ↔ kernel)时执行代码。因为在切换页表的瞬间,原页表失效,新的页表未完全生效,CPU 需要一个固定的虚拟地址可以始终访问。内核在切换页表时在trampoline运行,而用户程序可以通过它切换到内核态,再回到用户态。 注意trampoline 页没有设置 U 位,即用户态不能访问。
一句话:为了能在每个内核栈下面留一个不映射的「守护页(guard page)」来抓栈溢出,而紧贴数据段的「直接映射区」做不到这件事。关键在内核页表有两类映射:
- 直接映射区(
[KERNBASE, PHYSTOP),即 text/data/空闲 RAM)——kvmmap(etext, etext, PHYSTOP-etext, PTE_R|PTE_W)把整段物理 RAM 一对一、连续、全部 RW 映射进来,中间没有任何空洞(这样内核才能拿kalloc的物理地址当指针直接用,VA≈PA)。 - 高地址区(trampoline + 内核栈)——这是一段独立于直接映射、可以自由布局的虚拟地址。
看 KSTACK(p) = TRAMPOLINE - (p+1)*2*PGSIZE 里的 *2:每个栈占 2 页地址跨度、但只映射 1 页,另一页故意留空不映射当守护页:
高地址 TRAMPOLINE
┌──────────┐
│ kstack 0 │ ← 映射 1 页
├──────────┤
│ guard │ ← ❌ 不映射(PTE_V=0)
├──────────┤
│ kstack 1 │ ← 映射 1 页
├──────────┤
│ guard │ ← ❌ 不映射
└──────────┘于是某个内核栈溢出往下越界时,会撞到守护页 → 无 PTE → page fault → panic,问题当场暴露。
而若紧贴数据段(塞进直接映射区):那段区域是连续 RW、无空洞的,没法在里面挖一个不映射的守护页(挖了就破坏「物理 RAM 一对一直接映射」的前提);结果栈溢出不会触发 fault,而是悄悄踩坏隔壁进程的内核栈或内核数据,变成极难排查的隐性 bug。注意栈用的物理页仍是从普通 RAM
kalloc出来的,只是被映射到高 VA(给同一块物理内存又开一个高地址映射),目的就是腾出守护页的空间——用「位置」换来「栈溢出能被硬件当场抓住」。
Solution: 如上面所说,为了抓栈溢出;同时也不可设置成只读,因为这不只是不能写的问题,也不能窥探其他进程的内核栈。
Solution: 内核不能直接使用,内核必须查当前进程的页表,将USER VA → 转换为内核可访问的地址
TLB管理
CPU 为了加速地址翻译,会缓存会缓存 VA → PA 映射,这个缓存叫TLB(Translation Lookaside Buffer)。
xv6在 user/kernel 切换时会清空整个TLB,TLB 中缓存的是旧进程的地址映射,切换进程后, 页表已经变了。如果不清空,可能使用错误的映射。
RISC-V 支持更高级的优化, 现实系统会用以下优化:
PTE_G(global),表示这个映射是全局,不属于特定进程,用于内核映射,所有进程都一样,在切换进程时不需要刷新这些TLB- ASID(地址空间标识符),每个进程一个 ASID,TLB entry 带有 ASID 标签。不同进程的 TLB 项可以共存,切换进程时不需要flush全部
- 使用更大的页,比如2MB、1GB。一个 PTE 覆盖更多内存,覆盖范围更大,减少miss
物理内存的分配
内核在运行时需要动态分配和释放物理内存,用于:
- 页表
- 用户内存
- 内核栈
- 管道缓冲区等等
xv6 使用[ kernel_end , PHYSTOP ) 的物理内存区域进行动态分配,即从内核结束为止到物理内存上限。
其分配方式有几个特点:
- 每次分配/释放一个页(4KB)
- 用一个链表管理空闲页
- 这个链表“嵌在页本身里”
具体操作方式,分配时从链表中取出一个页;释放时把页重新加入链表。物理内存分配器实现在kernel/kalloc.c,
数据结构上,分配器维护一个空闲页链表(free list),每个空闲页中都有一个结构
struct run {
struct run *next;
};关键点:
next指针就存放在 这个空闲页本身的内存里- 因为空闲页没有其他用途,可以“复用”它的空间
- free list 由 自旋锁保护,锁和链表被封装在一个 struct 中
初始化时,main会调用kinit(),作用是初始化空闲链表,把所有可用物理内存加入分配器中?
简短回答:xv6 内核没有用户态那种「堆段」(brk/sbrk 撑大的连续区 + malloc 任意大小分配),但它确实有运行时动态内存——只是粒度是「整页」。
(1)xv6:没有 heap 段,只有「页池」。用户进程的堆是一段连续、能向上长的虚拟区(sbrk 抬高 brk、malloc 在其中切小块)。xv6 内核没有这个东西,它的动态内存全靠上面的 kalloc:把 [kernel_end, PHYSTOP) 串成空闲页链表,每次取/还一整页(4KB)。
| 用户堆 | xv6 kalloc 池 | |
|---|---|---|
| 粒度 | 任意字节(malloc) | 整页 4KB |
| 形态 | 连续、可增长的段 | 一堆物理页的空闲链表 |
| 增长方式 | brk 抬高上界 | 没有「界」,从池里取页 |
所以 xv6 内核没有
malloc:需要内存要么静态分配(编译期定大小的全局数组,如proc[NPROC]、bcache.buf[NBUF]),要么干脆占整页。为什么不搞 brk 式的堆? 因为内核不是「一个有干净线性地址空间的进程」——它的地址基本是物理内存的直接映射(VA≈PA),把空闲 RAM 当成页的资源池来管,而非「会长大的连续段」,自然没有「堆顶」概念。
(2)真实内核(Linux):有堆,分三套:
- 页分配器(buddy):
alloc_pages——给整页(相当于kalloc的升级版); - 对象分配器(slab/slub):
kmalloc/kfree——建在页分配器之上,给任意大小的小对象,是最像用户态 malloc 的东西,物理连续(适合 DMA); vmalloc区:内核 VA 里专门划的一段区域,分配虚拟连续、物理可分散的大块——这才是内核 VA 布局里实打实的一块「堆区」。
一句话:栈,内核有(每进程一个、很小,所以避免大局部变量和深递归);堆,xv6 没有真正的堆(只有 kalloc 页池 + 静态数组),Linux 有(buddy + kmalloc/slab + vmalloc 三套)。
每进程的地址空间及权限
每个进程都有自己的页表,当 xv6 在不同进程之间切换时,不仅切换 CPU 状态还会切换页表(通过satp寄存器),一个进程的用户空间从0开始,理论上到MAXVA(0x4 000 000 000),但实际上只有一小部分虚拟地址会被映射到物理内存。
一个进程的地址空间包括:
- 代码段(text):权限为可读、可执行、用户可访问,但不可写。如果text可写,程序可能错误地修改自己的指令
- 已初始化的数据段(data)
- 栈(stack)
- 堆(heap)
数据 / 栈 / 堆权限为可读、可写、用户可访问,但不可执行。如果 data 可执行,程序可能跳到数据区执行,也是安全机制,攻击者利用程序 bug(如缓冲区溢出),试图执行注入的数据。
PTE_R | PTE_W | PTE_U现代系统的页表
和大多数操作系统一样,xv6使用分页硬件来实现内存保护和地址映射,但是真实OS使用分页的方式更加复杂和强大,通常也会结合页表和页错误来实现更多功能。
xv6的方式是内核虚拟地址
RISC-V 支持
- 基于物理地址的保护、
- 超级页(Super pages,例如4MB),优点是减少页表开销,提高性能,适用于大内存机器;以及
- TLB优化——当我们在切换页表时需要清空TLB、这个过程很慢,解决方法是通过ASID(Address Space Identifier),每个进程一个ID、TLB可以区分不同进程,只需要清除特定进程的TLB项。
但以上xv6没有使用这些特性,另外xv6没有类似 malloc 的灵活分配器,只分配固定大小4KB(一个页)
参考资料源码精读
下面把五份参考源码(
riscv.h、memlayout.h、kalloc.c、vm.c、exec.c)逐函数拆开,配合实际代码深入理解“地址空间是怎么一步步搭起来、用起来、拆掉的”。所有代码取自 xv6-riscv(rev5)。
Xv6代码走读
在内核刚启动时,分页机制还没有开启,所有地址都是物理地址,内核被编译/链接到地址0x80 000 000,这是RAM起始位置。内核首先必须创建自己的页表,在在 vm.c 中的 kvmmake() 构建图3.3所示的内核页表,UART0位于物理地址0x10000000,是直接映射VA = PA,而kvmmap() 向正在构建的页表中添加PTE,注意此时还没有启用,只是内存中的数据结构。
页表页通过kalloc()分配,因为kinit()的初始化方式为顺序分配。
在页目录中哪些项是为了UART0填充的?
Sol:
UART0 = 0x10000000
## L2
(gdb) p/x 0x10000000 >> 12 >> 9 >> 9
$1 = 0x0
## L1
(gdb) p/x 0x10000000 >> 12 >> 9
$2 = 0x80
## L0
(gdb) p/x 0x10000000 >> 12
$3 = 0x10000
# 取低9位
(gdb) p/x (0x10000000 >> 12) & 0x1ff
$4 = 0x0
## Offset within page
(gdb) p/x 0x10000000 & 0xfff
$5 = 0x0
(gdb)PTE 低位的 "7" 是什么?
Sol: 权限位的组合: PTE_V(Valid)、PTE_R(Read)、PTE_W(write)
如果映射多个页?
Sol: 把vmprint()放到 VIRTIO0 映射之后,页表树会扩展(增加节点)
kvmmap() 调用了谁?
Sol:
mappages(root, va, size, pa, perm)对于每一页, 调用walk()找到对应PTE地址,如果中间页表不存在则通过kalloc创建并写入PTE,填入物理地址,设置有效位PTE_V,walk 模拟硬件页表遍历,返回的是 PTE 的地址(指针),因为我们要修改它。
kvminithart()的作用是什么? 这个地址是虚拟地址还是物理地址?
Sol: 将页表根地址加载到寄存器 satp; 物理地址(否则会形成“鸡生蛋问题”)
0. riscv.h:地址与 PTE 的位操作宏
整套虚拟内存代码的“原子操作”都建立在这几条宏上,先吃透它们,后面的函数就是搭积木。
#define PGSIZE 4096 // 一页 4096 字节
#define PGSHIFT 12 // 页内偏移占 12 位
// 向上/向下取整到页边界
#define PGROUNDUP(sz) (((sz) + PGSIZE - 1) & ~(PGSIZE - 1))
#define PGROUNDDOWN(a) (((a)) & ~(PGSIZE - 1))
// PTE 标志位(低 10 位中用到的 5 位)
#define PTE_V (1L << 0) // Valid:该 PTE 是否有效
#define PTE_R (1L << 1) // 可读
#define PTE_W (1L << 2) // 可写
#define PTE_X (1L << 3) // 可执行
#define PTE_U (1L << 4) // 用户态可访问
// 物理地址 <-> PTE 的互转:核心是 PPN 在 PTE 里从第 10 位开始放
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10) // 去掉低 12 位偏移,左移 10 位让出标志位
#define PTE2PA(pte) (((pte) >> 10) << 12) // 反向:取出 44 位 PPN,再补 12 位 0 当物理页基址
#define PTE_FLAGS(pte) ((pte) & 0x3FF) // 取低 10 位标志
// 从虚拟地址里抽取某一级的 9 位页目录索引
#define PXMASK 0x1FF // 9 个 1
#define PXSHIFT(level) (PGSHIFT + (9 * (level))) // level0→12, level1→21, level2→30
#define PX(level, va) ((((uint64)(va)) >> PXSHIFT(level)) & PXMASK)>>12 得到 44 位物理页号 PPN;而 PTE 的低 10 位要留给标志位(V/R/W/X/U/...),所以 PPN 要从第 10 位开始放,于是再 <<10。两步合起来等价于“把 PPN 摆到 PTE 的 [53:10] 区间”。PX(level, va) 把 Sv39 的三级索引拆出来。以 va 为例,从高到低:
38 30 29 21 20 12 11 0
+----------+----------+----------+-----------+
| L2 (9位) | L1 (9位) | L0 (9位) | offset(12)|
+----------+----------+----------+-----------+
PX(2,va) PX(1,va) PX(0,va)还有切换页表用的 satp 封装:
#define SATP_SV39 (8L << 60) // 模式字段 = 8 表示启用 Sv39
#define MAKE_SATP(pagetable) (SATP_SV39 | (((uint64)pagetable) >> 12))即 satp = 模式位 + 根页表的物理页号。kvminithart() 就是把这个值写进 satp 来“开启分页”。
1. memlayout.h:物理/虚拟地址布局常量
#define UART0 0x10000000L // 串口寄存器(MMIO)
#define VIRTIO0 0x10001000 // 虚拟磁盘(MMIO)
#define PLIC 0x0c000000L // 中断控制器
#define KERNBASE 0x80000000L // 内核(和 RAM)起始物理地址
#define PHYSTOP (KERNBASE + 128*1024*1024) // 内核可用 RAM 的上限(这里假设 128MB)
#define TRAMPOLINE (MAXVA - PGSIZE) // 跳板页:映射到最高虚拟地址
#define KSTACK(p) (TRAMPOLINE - ((p)+1) * 2*PGSIZE) // 第 p 个进程的内核栈
#define TRAPFRAME (TRAMPOLINE - PGSIZE) // trapframe 紧贴跳板页下方KSTACK(p) 里的 * 2 是什么意思?每个内核栈分配 2 页的“地址跨度”,但只映射其中 1 页,另 1 页故意留空当守护页(guard page)。所以相邻两个进程的内核栈之间一定隔着一个未映射的页:一旦某个内核栈溢出,就会写到 guard page 触发 page fault,而不是悄悄踩坏隔壁进程的内核栈。2. kalloc.c:物理页分配器(全代码)
xv6 的物理内存分配器极简:一条空闲页链表,每个空闲页里嵌一个 next 指针。
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void *)PHYSTOP); // end 是内核镜像结束地址(kernel.ld 定义)
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char *)PGROUNDUP((uint64)pa_start); // 从第一个页边界开始
for (; p + PGSIZE <= (char *)pa_end; p += PGSIZE)
kfree(p); // 逐页“释放”,等于把全部 RAM 串进链表
}注意
kinit用kfree来初始化链表——这是kfree注释里提到的“唯一例外”:正常情况下kfree只接受曾由kalloc返回的页。
void
kfree(void *pa)
{
struct run *r;
// 三重检查:必须页对齐、不能落在内核镜像里、不能越过物理上限
if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
memset(pa, 1, PGSIZE); // 填垃圾值,让“释放后仍被使用”的悬空引用尽早暴露
r = (struct run *)pa; // 直接把这页本身当作链表结点
acquire(&kmem.lock);
r->next = kmem.freelist; // 头插
kmem.freelist = r;
release(&kmem.lock);
}
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if (r)
kmem.freelist = r->next; // 摘下表头
release(&kmem.lock);
if (r)
memset((char *)r, 5, PGSIZE); // 同样填垃圾值,避免泄露上一个使用者的数据
return (void *)r;
}next 存在“空闲页自己”里,会不会有问题?不会——页空闲时它没有别的用途,正好复用它的前 8 字节当链表指针,零额外元数据开销。一旦被 kalloc 分出去,使用者会覆盖这块内存,而那时它已不在链表里了。代价是分配器只能整页粒度(4096B),没有 malloc 那种任意大小分配。3. vm.c:页表的建立、查询、增删
3.1 walk:软件模拟硬件的三级页表遍历
walk 是整个文件的心脏:给定 va,返回它对应最底层 PTE 的地址(指针,方便修改)。alloc=1 时会按需创建中间页目录。
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if (va >= MAXVA)
panic("walk");
for (int level = 2; level > 0; level--) { // 走 L2、L1 两级
pte_t *pte = &pagetable[PX(level, va)]; // 用该级 9 位索引定位 PTE
if (*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte); // 已存在:顺着 PPN 下到下一级页目录
} else {
if (!alloc || (pagetable = (pde_t *)kalloc()) == 0)
return 0; // 不允许分配 / 内存不足 → 失败
memset(pagetable, 0, PGSIZE); // 新页目录清零(全部 PTE_V=0)
*pte = PA2PTE(pagetable) | PTE_V; // 在上一级写入指向新页目录的 PTE
}
}
return &pagetable[PX(0, va)]; // 返回 L0 中那条叶子 PTE 的地址
}要点:
- 循环只到
level>0,因为最后一级(L0)不再下钻,而是把叶子 PTE 的地址返回给调用者去读/写。 - 中间级的 PTE 只有 PTE_V、没有 R/W/X——这正是
freewalk区分“中间目录”和“叶子映射”的依据。 walk完美复刻了 MMU 在 TLB miss 时做的事,只不过用 C 写、可以顺便kalloc建目录。
3.2 mappages:批量建立映射
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if ((va % PGSIZE) != 0) panic("mappages: va not aligned");
if ((size % PGSIZE) != 0) panic("mappages: size not aligned");
if (size == 0) panic("mappages: size");
a = va;
last = va + size - PGSIZE;
for (;;) {
if ((pte = walk(pagetable, a, 1)) == 0) // 找到(必要时创建)叶子 PTE
return -1;
if (*pte & PTE_V)
panic("mappages: remap"); // 重复映射是 bug
*pte = PA2PTE(pa) | perm | PTE_V; // 写入:物理页号 + 权限 + 有效位
if (a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}kvmmap 只是它的“出错就 panic”封装(内核启动期建表,失败无法恢复):
void
kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)
{
if (mappages(kpgtbl, va, sz, pa, perm) != 0)
panic("kvmmap");
}3.3 walkaddr:把用户 VA 翻成 PA(内核访问用户内存的基础)
uint64
walkaddr(pagetable_t pagetable, uint64 va)
{
pte_t *pte;
uint64 pa;
if (va >= MAXVA) return 0;
pte = walk(pagetable, va, 0); // 注意 alloc=0:只查不建
if (pte == 0) return 0;
if ((*pte & PTE_V) == 0) return 0;
if ((*pte & PTE_U) == 0) return 0; // 关键:必须是“用户可访问”的页才认
pa = PTE2PA(*pte);
return pa;
}这条
PTE_U检查是隔离的护栏:内核拿用户传来的指针时走walkaddr,于是用户无法通过系统调用参数诱骗内核去读写一个没有PTE_U的内核页。
3.4 内核页表的搭建:kvmmake → kvminit → kvminithart
pagetable_t
kvmmake(void)
{
pagetable_t kpgtbl = (pagetable_t)kalloc();
memset(kpgtbl, 0, PGSIZE);
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W); // 串口 MMIO,直接映射
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); // 磁盘 MMIO
kvmmap(kpgtbl, PLIC, PLIC, 0x4000000, PTE_R | PTE_W); // 中断控制器
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext - KERNBASE, PTE_R | PTE_X); // 内核代码:可读可执行、不可写
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP - (uint64)etext, PTE_R | PTE_W); // 内核数据+空闲RAM:可读可写、不可执行
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); // 跳板页(无 PTE_U)
proc_mapstacks(kpgtbl); // 给每个进程预映射内核栈
return kpgtbl;
}
void kvminit(void) { kernel_pagetable = kvmmake(); } // 启动早期建表(此时分页未开)
void
kvminithart()
{
sfence_vma(); // 等待之前对页表内存的写入落地
w_satp(MAKE_SATP(kernel_pagetable)); // 写 satp:从这条指令之后,分页正式生效
sfence_vma(); // 刷掉 TLB 里可能的陈旧项
}PTE_R|PTE_X(不可写,防篡改指令);内核数据段 PTE_R|PTE_W(不可执行,防把数据当代码跑)。这就是 W^X(写与执行互斥)原则在内核页表里的落地。3.5 用户地址空间的“增长 / 收缩 / 释放”
创建空页表:
pagetable_t
uvmcreate()
{
pagetable_t pagetable = (pagetable_t)kalloc();
if (pagetable == 0) return 0;
memset(pagetable, 0, PGSIZE);
return pagetable;
}增长(sbrk/exec 用)——uvmalloc 逐页 kalloc + mappages,任何一步失败都回滚:
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz, int xperm)
{
char *mem;
uint64 a;
if (newsz < oldsz) return oldsz;
oldsz = PGROUNDUP(oldsz);
for (a = oldsz; a < newsz; a += PGSIZE) {
mem = kalloc();
if (mem == 0) { uvmdealloc(pagetable, a, oldsz); return 0; } // 失败:把已分的退回去
memset(mem, 0, PGSIZE);
if (mappages(pagetable, a, PGSIZE, (uint64)mem,
PTE_R | PTE_U | xperm) != 0) { // 用户页必带 PTE_U
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}收缩——uvmdealloc 计算要砍掉多少页,交给 uvmunmap 真正解除映射并释放物理页:
uint64
uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
if (newsz >= oldsz) return oldsz;
if (PGROUNDUP(newsz) < PGROUNDUP(oldsz)) {
int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE;
uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1); // do_free=1:连物理页一起释放
}
return newsz;
}
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
if ((va % PGSIZE) != 0) panic("uvmunmap: not aligned");
for (a = va; a < va + npages * PGSIZE; a += PGSIZE) {
if ((pte = walk(pagetable, a, 0)) == 0) continue; // 这段地址连页表都没建,跳过
if ((*pte & PTE_V) == 0) continue; // 没映射物理页,跳过(懒分配会出现)
if (do_free) {
uint64 pa = PTE2PA(*pte);
kfree((void *)pa); // 释放物理页
}
*pte = 0; // 清空 PTE,解除映射
}
}彻底释放整个地址空间——先释放所有叶子物理页,再递归释放页目录页本身:
void
freewalk(pagetable_t pagetable)
{
for (int i = 0; i < 512; i++) { // 一页 512 个 PTE
pte_t pte = pagetable[i];
if ((pte & PTE_V) && (pte & (PTE_R | PTE_W | PTE_X)) == 0) {
// 没有 R/W/X → 是“指向下一级页目录”的中间 PTE
uint64 child = PTE2PA(pte);
freewalk((pagetable_t)child); // 递归下钻释放子目录
pagetable[i] = 0;
} else if (pte & PTE_V) {
panic("freewalk: leaf"); // 还有叶子映射没清,是调用者的 bug
}
}
kfree((void *)pagetable); // 最后释放本级页目录页
}
void
uvmfree(pagetable_t pagetable, uint64 sz)
{
if (sz > 0)
uvmunmap(pagetable, 0, PGROUNDUP(sz) / PGSIZE, 1); // 第一步:释放所有用户物理页
freewalk(pagetable); // 第二步:释放三级页目录
}walk 建中间页目录时只写了 PTE_V(见 3.1),而真正映射物理页的叶子 PTE 至少带一个 R/W/X。于是 PTE_V && (R|W|X)==0 唯一地标识“这是个还需继续下钻的中间目录”。如果此时遇到带 R/W/X 的叶子,说明 uvmunmap 没清干净,直接 panic。3.6 uvmcopy:fork 时复制父进程地址空间
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for (i = 0; i < sz; i += PGSIZE) {
if ((pte = walk(old, i, 0)) == 0) continue;
if ((*pte & PTE_V) == 0) continue;
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte); // 连权限一起拷
if ((mem = kalloc()) == 0) goto err;
memmove(mem, (char *)pa, PGSIZE); // 真正复制一整页内容(不是 COW)
if (mappages(new, i, PGSIZE, (uint64)mem, flags) != 0) {
kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1); // 失败回滚:把已经拷好的页全释放
return -1;
}这是饿汉式深拷贝:父子各持一份独立物理页。这正是后续“写时复制 fork(COW lab)”要优化的地方——先共享、写时才复制。
3.7 跨越用户/内核边界:copyout / copyin / copyinstr
内核不能直接解引用用户指针(用户页在用户页表里,且内核需要做权限和缺页检查),必须经由这三个函数。它们的共同套路:按页 walkaddr 翻地址,再 memmove,处理跨页拼接。
// 内核 → 用户(如把系统调用结果写回用户 buf)
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
pte_t *pte;
while (len > 0) {
va0 = PGROUNDDOWN(dstva);
if (va0 >= MAXVA) return -1;
pa0 = walkaddr(pagetable, va0);
if (pa0 == 0) { // 没映射?可能是懒分配的页
if ((pa0 = vmfault(pagetable, va0, 0)) == 0) // 当场按需补一页
return -1;
}
pte = walk(pagetable, va0, 0);
if ((*pte & PTE_W) == 0) // 禁止往只读用户页(如 text)写
return -1;
n = PGSIZE - (dstva - va0); // 本页还能写多少
if (n > len) n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n); // 用物理地址直接搬
len -= n; src += n; dstva = va0 + PGSIZE; // 推进到下一页
}
return 0;
}copyin 是反方向(用户 → 内核),结构对称;copyinstr 则多了“遇到 '\0' 提前停止”的逻辑,用于安全地拷贝用户传来的路径字符串:
int
copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max)
{
uint64 n, va0, pa0;
int got_null = 0;
while (got_null == 0 && max > 0) {
va0 = PGROUNDDOWN(srcva);
pa0 = walkaddr(pagetable, va0);
if (pa0 == 0) return -1;
n = PGSIZE - (srcva - va0);
if (n > max) n = max;
char *p = (char *)(pa0 + (srcva - va0));
while (n > 0) {
if (*p == '\0') { *dst = '\0'; got_null = 1; break; } // 字符串结束
else { *dst = *p; }
--n; --max; p++; dst++;
}
srcva = va0 + PGSIZE;
}
return got_null ? 0 : -1;
}守护页的设置——uvmclear 只清 PTE_U,让该页对用户态不可访问(仍在页表里,但一访问就 fault):
void
uvmclear(pagetable_t pagetable, uint64 va)
{
pte_t *pte = walk(pagetable, va, 0);
if (pte == 0) panic("uvmclear");
*pte &= ~PTE_U; // 去掉用户访问位 → 用户栈溢出撞到它即触发 page fault
}4. exec.c:把上面所有积木拼成一次 exec()
kexec 是“地址空间从无到有”的总装现场,串起了 proc_pagetable、uvmalloc、loadseg、copyout、uvmclear。流程:
int
kexec(char *path, char **argv)
{
// ... 省略声明 ...
begin_op();
if ((ip = namei(path)) == 0) { end_op(); return -1; } // ① 按路径找到可执行文件 inode
ilock(ip);
if (readi(ip, 0, (uint64)&elf, 0, sizeof(elf)) != sizeof(elf)) goto bad;
if (elf.magic != ELF_MAGIC) goto bad; // ② 读 ELF 头并校验魔数
if ((pagetable = proc_pagetable(p)) == 0) goto bad; // ③ 建一张全新的用户页表(含 trampoline/trapframe)
// ④ 逐个 program header,把每个 LOAD 段映射并从磁盘读入
for (i = 0, off = elf.phoff; i < elf.phnum; i++, off += sizeof(ph)) {
if (readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph)) goto bad;
if (ph.type != ELF_PROG_LOAD) continue;
if (ph.memsz < ph.filesz) goto bad; // 防御性检查
if (ph.vaddr + ph.memsz < ph.vaddr) goto bad; // 防溢出回绕
if (ph.vaddr % PGSIZE != 0) goto bad;
uint64 sz1;
if ((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz,
flags2perm(ph.flags))) == 0) goto bad; // 按 ELF 段权限分配
sz = sz1;
if (loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0) goto bad; // 从磁盘读入
}
iunlockput(ip); end_op(); ip = 0;
p = myproc();
uint64 oldsz = p->sz;
// ⑤ 在镜像上方建用户栈:先留一页当 guard,再给 USERSTACK 页栈
sz = PGROUNDUP(sz);
uint64 sz1;
if ((sz1 = uvmalloc(pagetable, sz, sz + (USERSTACK + 1) * PGSIZE, PTE_W)) == 0) goto bad;
sz = sz1;
uvmclear(pagetable, sz - (USERSTACK + 1) * PGSIZE); // 最低那页清 PTE_U → 栈守护页
sp = sz;
stackbase = sp - USERSTACK * PGSIZE;
// ⑥ 把 argv 字符串逐个 copyout 到新栈顶,记录指针
for (argc = 0; argv[argc]; argc++) {
if (argc >= MAXARG) goto bad;
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // RISC-V 要求 sp 16 字节对齐
if (sp < stackbase) goto bad;
if (copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0) goto bad;
ustack[argc] = sp;
}
ustack[argc] = 0;
// ⑦ 再把 argv 指针数组本身 copyout 到栈上,地址放进 a1
sp -= (argc + 1) * sizeof(uint64);
sp -= sp % 16;
if (sp < stackbase) goto bad;
if (copyout(pagetable, sp, (char *)ustack, (argc + 1) * sizeof(uint64)) < 0) goto bad;
p->trapframe->a1 = sp;
// ⑧ 保存程序名(调试用)
for (last = s = path; *s; s++) if (*s == '/') last = s + 1;
safestrcpy(p->name, last, sizeof(p->name));
// ⑨ 提交:换上新页表,设置入口 PC 和 SP,释放旧地址空间
oldpagetable = p->pagetable;
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->epc = elf.entry; // 用户态从 ELF 入口开始执行
p->trapframe->sp = sp;
proc_freepagetable(oldpagetable, oldsz); // 旧的连页表带物理页一起释放
return argc; // 落在 a0 → 成为 main(argc, argv) 的第一个参数
bad:
if (pagetable) proc_freepagetable(pagetable, sz); // 任何中途失败都不动旧地址空间
if (ip) { iunlockput(ip); end_op(); }
return -1;
}pagetable 上,只有走到第 ⑨ 步、确认万事俱备,才用 p->pagetable = pagetable 一次性切换。任何一步失败都跳到 bad,释放的是新页表,旧地址空间原封不动——于是 exec 失败时进程能继续正常运行(比如 shell 找不到命令时不会崩)。这就是“准备-提交-回滚”在内核里的经典实现。配套的 flags2perm 把 ELF 段标志翻成 PTE 权限,loadseg 用 walkaddr 拿到物理页后 readi 从磁盘直接填进去:
int
flags2perm(int flags)
{
int perm = 0;
if (flags & 0x1) perm = PTE_X; // ELF 可执行段 → PTE_X
if (flags & 0x2) perm |= PTE_W; // ELF 可写段 → PTE_W
return perm;
}
static int
loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz)
{
uint i, n;
uint64 pa;
for (i = 0; i < sz; i += PGSIZE) {
pa = walkaddr(pagetable, va + i); // 段页此前已由 uvmalloc 映射
if (pa == 0) panic("loadseg: address should exist");
n = (sz - i < PGSIZE) ? sz - i : PGSIZE;
if (readi(ip, 0, (uint64)pa, offset + i, n) != n) // 直接读到物理页
return -1;
}
return 0;
}5. 一张图把调用关系串起来
启动期: kvminit → kvmmake → kvmmap → mappages → walk(alloc=1)
kvminithart → w_satp(MAKE_SATP(...)) // 开启分页
物理页: kinit → freerange → kfree ──┐
├── 空闲页链表 kmem.freelist
kalloc ─────────────────────┘
建用户空间: exec/sbrk → uvmalloc → kalloc + mappages → walk
拆用户空间: uvmdealloc/uvmfree → uvmunmap(+kfree) / freewalk(+kfree)
fork 复制 : uvmcopy → walk + kalloc + memmove + mappages
跨界访存 : copyout/copyin/copyinstr → walkaddr → walk(alloc=0)参考资料
- 课件
- xv6 教材的第3章
- xv6 kernel
kernel/memlayout.hkernel/vm.ckernel/kalloc.ckernel/riscv.hkernel/exec.c