Lec 11 设备驱动 & 中断
阅读 xv6 内核的完整实现代码
kernel/console.ckernel/uart.ckernel/kernelvec.S
阅读 xv6 教材的第6章
阅读 lec https://pdos.csail.mit.edu/6.1810/2025/lec/l-interrupt.txt
本讲定位: CPU需要连接设备: 存储、通信、显示等等,而设备驱动程序(device driver),作为操作系统中的一部分,用来控制这些设备。它的职责包括:
- 配置设备硬件
- 告诉设备执行哪些操作
- 处理设备产生的中断
- 与使用该设备的进程进行交互
驱动代码之所以复杂,是因为它通常是并发执行的,一方面他要和设备本身并发运行,另一方面,它还要和使用设备的进程并发运行。此外,驱动还必须理解设备的硬件接口,而这些接口往往复杂且文档不完善。
那些需要操作系统关注的设备,通常可以被配置为在需要时产生中断(interrupt),而中断是一种 trap,内核的 trap 处理代码会识别出设备发出的中断,并调用对应驱动的中断处理函数。在生产级操作系统中,大部分代码其实是设备驱动。
许多设备驱动的执行分为两个部分(两个上下文):
- 上半部分(top half) 运行在进程的内核线程中,通常由系统调用触发,比如 read、write,它的工作是请求设备开始执行某个操作(例如让磁盘读取一个块),然后等待这个操作完成。 (发请求 + 睡眠)
- 下半部分 在中断发生时执行 判断哪个操作已经完成,如果有进程在等待,就唤醒它;如果还有后续任务,就让设备继续执行下一个操作。 (处理中断 + 唤醒 + 继续干活)
总览
- 内存映射I/O
- 中断I/O
- 示例: 控制台/串口
- DMA
内存映射I/O
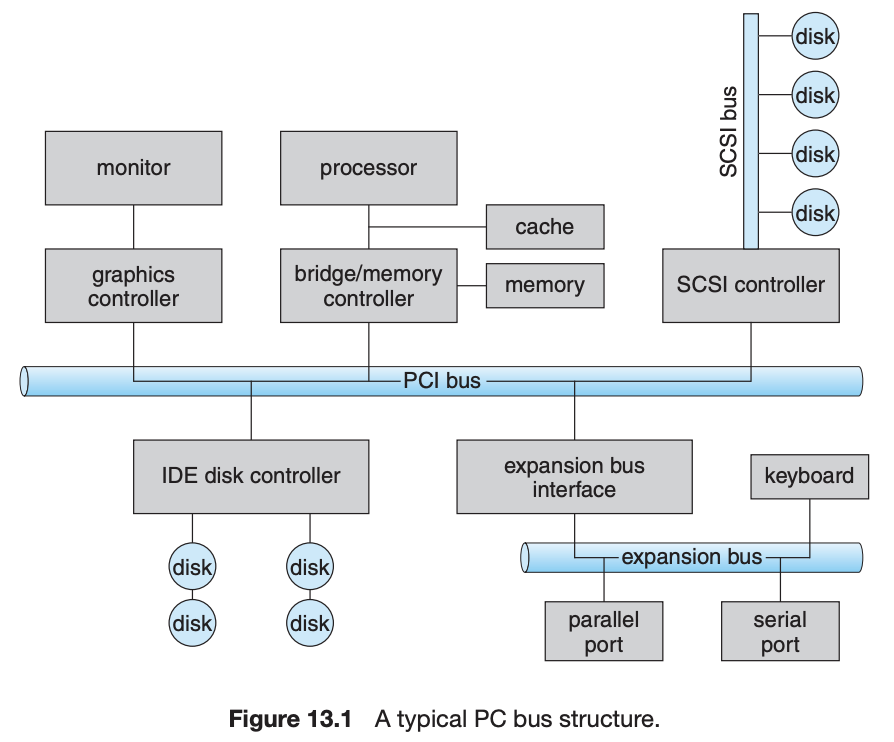
首先设备在哪里?
解决方案:通过总线技术,设备(如磁盘、网络接口、串口等)可以直接或间接地连接到 CPU 和 RAM,实现通信和数据传输。
如何对设备进行编程
内存映射I/O,硬件设备有控制和状态寄存器,这些寄存器”寄宿“在物理"内存"地址上,通过LD/ST指令访存这些地址时,就会读/写这些设备的控制寄存器。硬件平台的设计者决定了这些设备所在的物理地址空间。(而不是内核,内核只是适配这些硬件平台)
示例:URAT
UART全称是通用异步收发传输器(Universal Asynchronous Receiver/Transmitter),串行接口用于输入和输出,通常称为”RS232端口“,例如Qemu控制台,它是通过硬件(晶体管)实现的。
Qemu仿真了常见的16550 UART芯片,芯片手册
工作原理
- 接收部分:通过有线接收数据,依次经过接收移位寄存器(receive shift register)和接收 FIFO 队列(receive FIFO)
- 发送部分:数据从发送 FIFO 队列(transmit FIFO)送入发送移位寄存器(transmit shift register),最终从发送线(tx wire)传出
- 每个FIFO容量为16字节
内存映射8比特的寄存器在物理地址UART0 = 0x10000000:
- 0号寄存器: RHT/THR(接收/发送保持寄存器)
- 用于从FIFO读取或者往FIFO写入数据
- 1号寄存器:IER(中断使能寄存器)
- 0x1代表接收中断使能;0x2代表发送中断使能
- 。。。
- 5号寄存器:LSR(行状态寄存器)
- 0x1表示接受数据已经准备好,可以读取
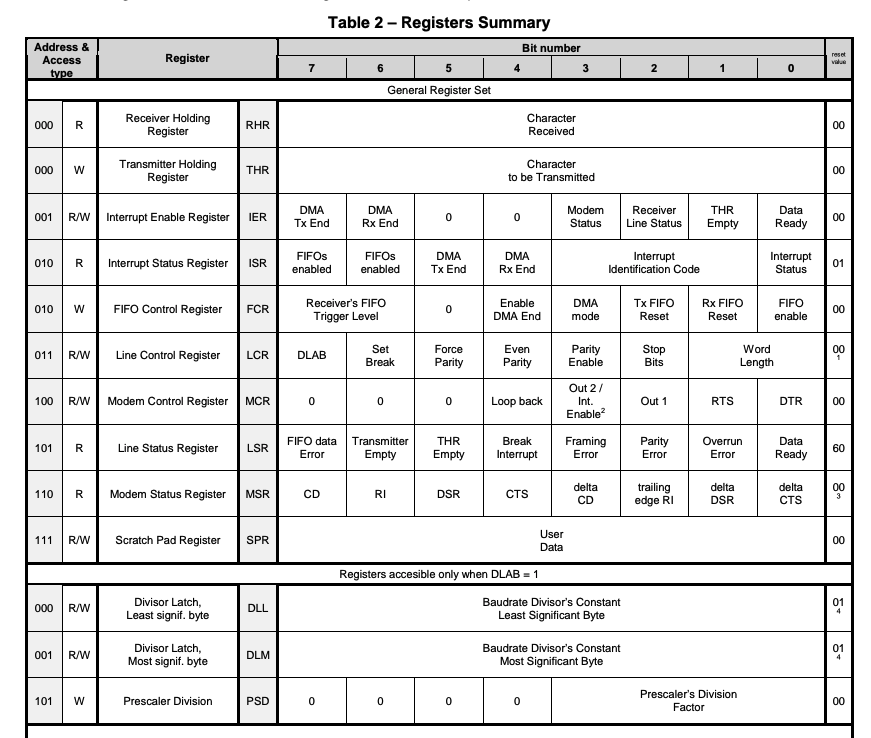
内核的设备驱动如何使用这些寄存器?
Solution:举个简单例子,在 kernel/uart.c 中有 uartgetc() 示例:
#define Reg(reg) ((volatile unsigned char *)(UART0 + reg))
#define ReadReg(reg) (*(Reg(reg)))
int uartgetc(void) {
if(ReadReg(LSR) & 0x01){
// input data is ready.
return ReadReg(RHR);
} else {
return -1;
}
}ReadReg(RHR) 转换为 *(char*)(0x10000000 + 0),即读取寄存器的值,获取从 FIFO 接收到的数据。▯
为什么UART要有FIFO缓冲区?
Solution:
- FIFO缓解了设备和CPU之间速度差异的问题
- 驱动程序需要通过LSR检查FIFO的状态:数据是否准备好 / 发送器是否为空 ▯
设备驱动如何等待设备就绪?
Solution:
轮询(Busy Loop)
while ((LSR & 1) == 0) ; return RHR;对于输入稀少的设备,效率地下,会浪费大量的CPU时间
就是接下来要讲的中断机制
中断驱动 I/O
当设备需要驱动程序响应时,设备会发出中断信号
- 中断只是”提示“
- 设备驱动程序需要进一步检查设备的状态寄存器以决定需要采取的操作。一个中断可能会提示多个操作,例如同时需要读取和写入数据。
对于URAT来说:
- 当rx FIFO 从空变为非空时会触发中断
- 当tx FIFO 从满变为非满时触发中断。
内核处理中断流程
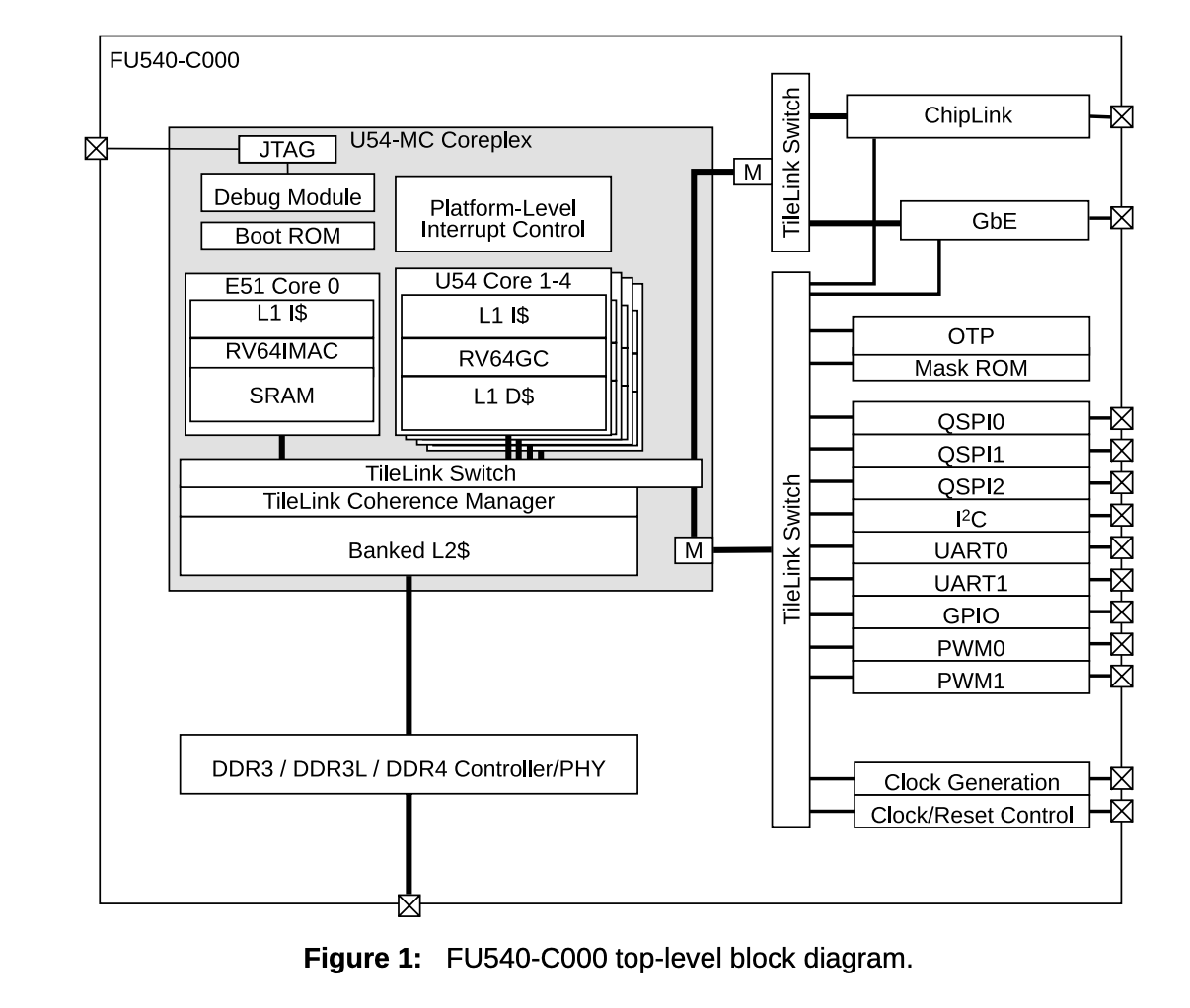
- 上图是Qemu模拟器运行的RISC-V平台在高层次下的架构图
中断路径
设备 --> PLIC(中断控制器) --> CPU --> trap --> usertrap()/kerneltrap() --> devint()- 所有设备的中断信号最终都会传递到处理器,但实际的中断管理由平台级中断控制器(Platform-Level Interrupt Controller,PLIC)负责。PLIC 是片上设备的核心组件,专门用于统一管理和分发外部设备的中断信号。
- (了解)处理器本地中断信号由CLINT(Core Local Interruptor)管理
- 中断号(IRQ):表示哪个设备触发的中断,例如UART的中断号是10(由平台定义,qemu模拟中如此)
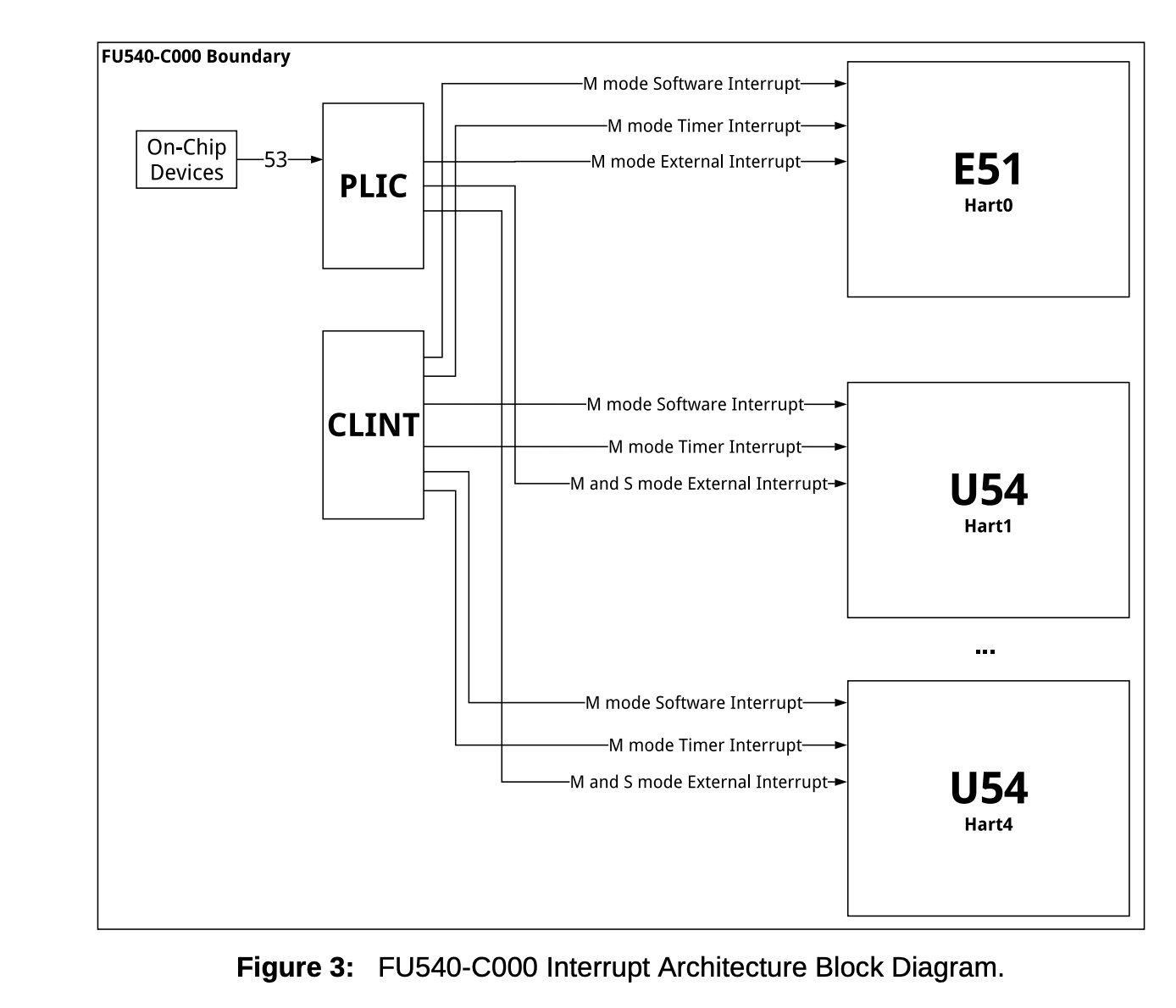
- 上图是RISC-V中断架构图
中断处理方式
- 检查
scause的最高位,判断是否是设备中断 - 从PLIC的寄存器中读取具体的中断号(IRQ)
如果多个设备同时请求中断怎么办?
Solution: PLIC会将终端分配给不同的核心。这样不同的中断就可以并行处理。 结合Xv6,每个中断会由第一个调用plic_cliam()的核心声明;每个设备在任意时刻最多只能有一个中断在处理。PLIC通过plic_complete()知道中断何时完成。 ▯
如果内核禁用了中断,而设备请求中断呢?
内核通过intr_off()调用清除sstatus中的SIE位禁用中断。PLIC和CPU会记住未处理的中断(挂起的中断);当内核重新启用中断时,这些中断将被递送。
Xv6
这里看到,有 53 条中断线路来自不同的设备。可能,中断线路上的设备,进入 PLIC ,然后 PLIC 路由这些中断。在这里,我们运行的是三个核心(core),PLIC 是可以编程的,所以 PLIC 将中断交给这些核心中的一个或者第一个,它可以获得中断,而且有一些灵活性。如果此时没有一个核心可以接受中断,因为他们在处理另一个中断,PLIC 将持有这个中断,直到有处理器可以处理中断。所以 PLIC 有一些内部状态来记录这些。如果你看一下文档,PLIC 中真正发生的是,表示有一个中断,等待其中一个核心,声称拥有它,所以这告诉 PLIC 不要给任何其他核心,一旦核心完全完成,它会说好的,我完成了这个中断,然后 PLIC 会,通知 PLIC 可以忘记这个中断。这是 RISC-V 的内部中断结构。
PLIC 是否有某种执行机制来确保公平?
这一切都取决于内核,以任何它想要的方式对 PLIC 进行编程。PLIC 不是真的选择传送中断服务,而是从是从内核程序获取,将中断传递到哪里等等。内核可以决定哪个中断比另一个中断更重要,这里有很大的灵活性。
让我们从高层次上谈一下软件方面的问题。
中断开销:中断大约需要一微秒:
- 包括触发 CPU 陷阱、保存寄存器、识别设备、中断完成后恢复寄存器并返回的时间。
- “开销”指的是排除实际设备驱动工作外的时间成本。
挑战: 如果说中断频率很频繁怎么办?比如现代网络设备每秒可以传递数百万个数据包,在这种速率下,大量的CPU时间会浪费在中断上的开销上。
思路: 需要找到一种更加高效的事件通知策略,比如一次性处理多个数据包?Polling机制。
设备驱动
驱动程序是操作系统中管理特定设备的代码:它配置设备硬件,指示设备执行操作,处理由此产生的中断,并与可能正在等待设备 I/O 的进程进行交互。驱动程序的代码往往比较复杂,因为驱动程序与它管理的设备同时执行。此外,驱动程序还必须理解设备的硬件接口,这些接口可能很复杂,甚至文档不全。
通常,需要操作系统关注的设备可以配置为生成中断,中断是陷阱(trap)的一种。内核的陷阱处理代码识别设备何时发出了中断,然后调用驱动程序的中断处理程序;在 xv6 中,这一调度在 devintr(位于 kernel/trap.c:185)中发生。
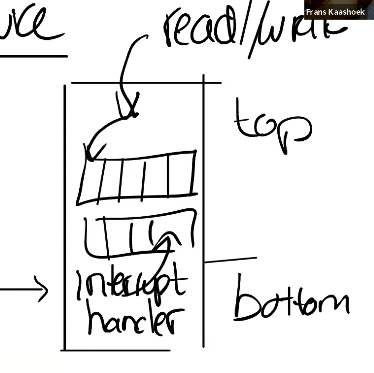
许多设备驱动程序在两种上下文中执行代码:上半部(top half)在进程的内核线程中运行,而下半部(bottom half)在中断时执行。上半部通过系统调用(如 read 和 write)被调用,这些调用希望设备执行 I/O 操作。此代码可能会要求硬件启动某个操作(例如,要求磁盘读取一个块),然后代码等待操作完成。最终,设备完成操作并发出中断。驱动程序的中断处理程序作为下半部执行,它负责确定完成了哪个操作,适时唤醒等待的进程,并告诉硬件开始处理任何等待的下一个操作。
对设备编程
设备编程使用内存映射 IO 。正如我们在 RISC-V 或 SiFive 电路板上看到的,设备出现在物理地址空间的特定地址,这是由设备电路板制造商决定。操作系统需要知道,这些设备位于物理内存空间中的哪个位置,然后对它们进行编程,对这些地址使用普通的加载存储指令。这些加载存储指令所做的是,它们读或写设备的控制寄存器。所以,当你在其中一个控制寄存器中存储某些内容时,发送你的数据包,所以不是读或写内存,这些加载存储指令通常具有副作用,引起设备做某些事。你必须查看设备文档,才能弄清楚这个设备是做什么的。有时候文档非常清楚,有时候文档不太清楚。这里给你一个小的示例。在这里我想给你们看两样东西,在屏幕的右侧,你可以看到 SiFive 电路板的物理内存映射空间,你可以看到特定事物映射的地址是什么,它们出现在物理地址空间中的位置,它们实际出现在物理地址空间的位置。
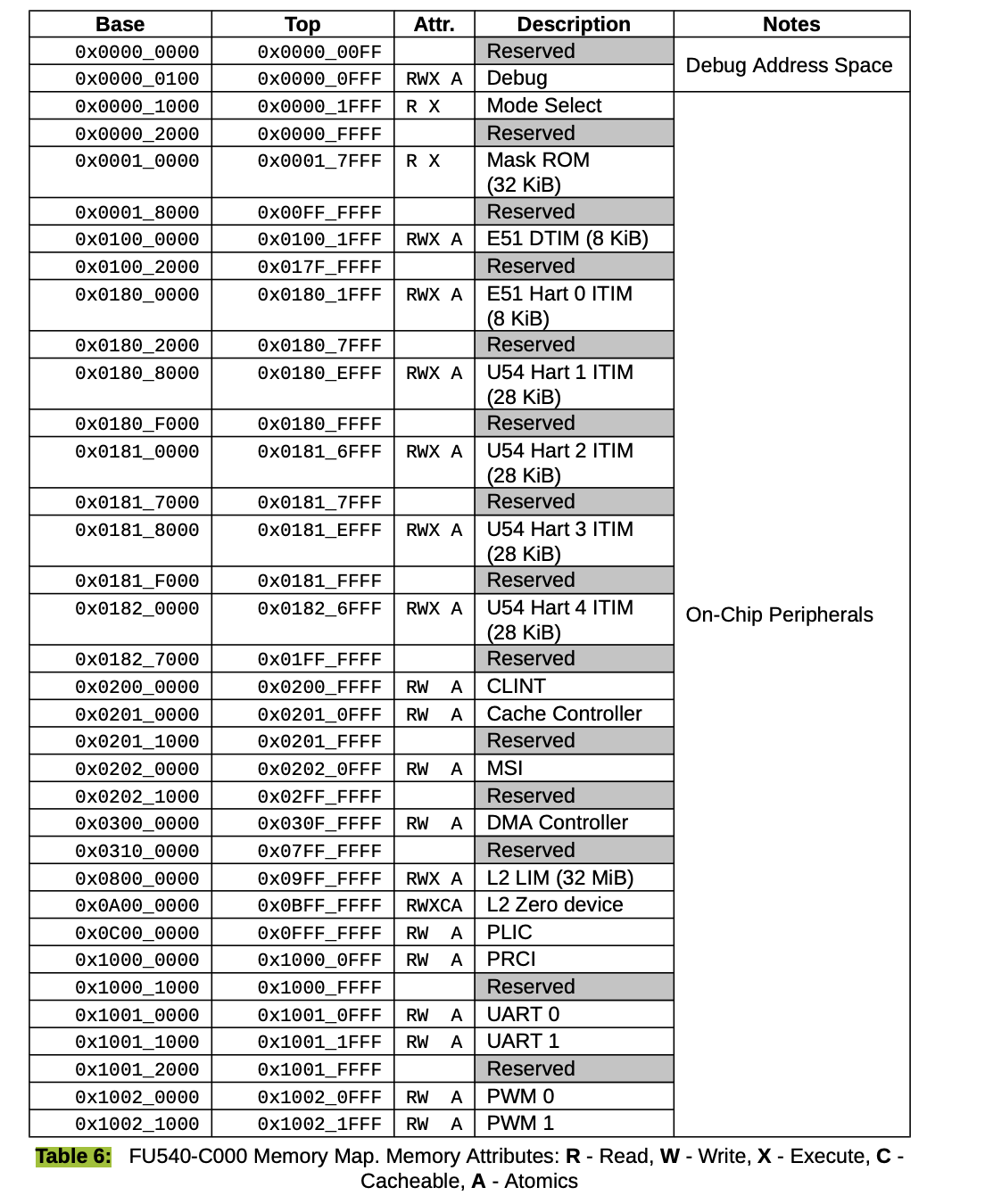
比如, CLINT 在 0x0200 。我们再挑一个。PLIC 也在那里的某个地方,好的,这里是 PLIC ,在 0x0C00 ,这是平台中断控制器,我们看到 UART0 在这个特定地址,实际上,在我们使用的 QEMU 上,UART 实际上在另一个位置。那是因为我们使用 QEMU ,并不是完全模仿 SiFive 电路板,而是跟 SiFive 电路板很相似。好的,这就是内存映射,从物理地址到设备的内存映射。然后,在左边,是 UART 文档的一部分。这是 16550 ,这是位于 QEMU 上模拟的 UART 芯片,我们用来与键盘和控制台交互,这是一个很简单的芯片,这个设备并没有太多的功能,即便如此,它们还是有点复杂。在这张表中,显示了芯片拥有的寄存器,控制器寄存器, 比如,控制寄存器 0 0 0 ,当你执行加载指令时,
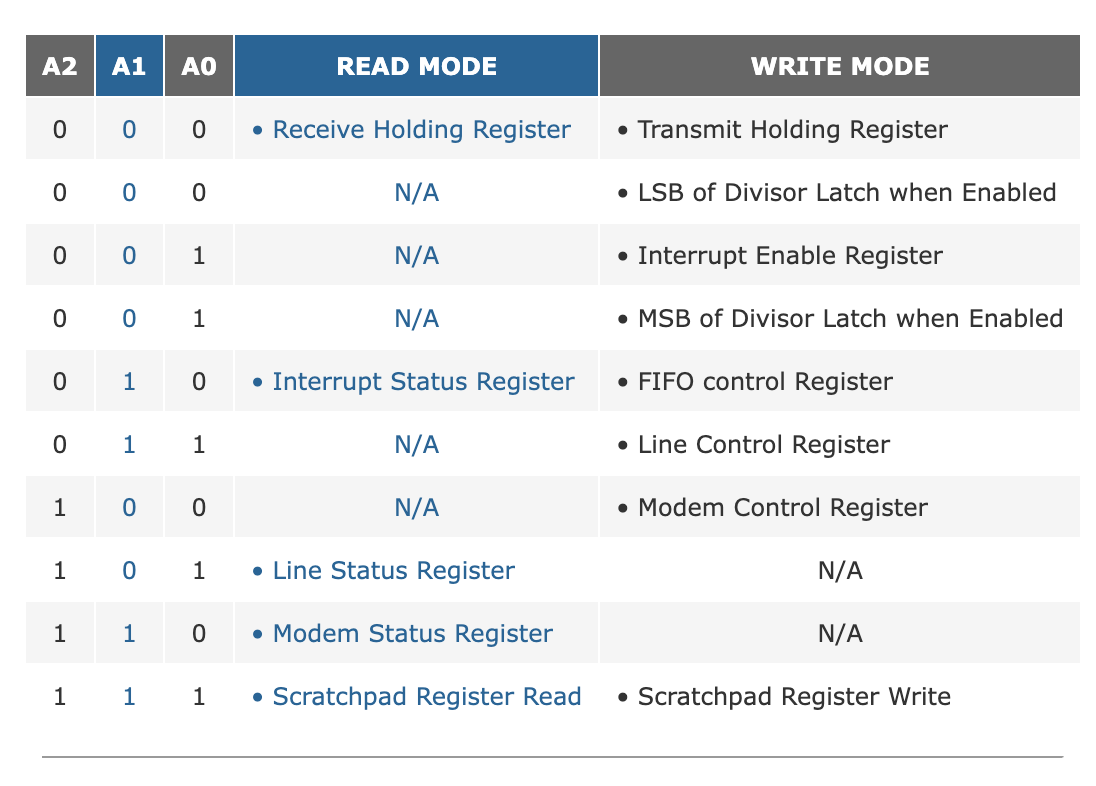
它将持有数据,如果执行存储指令,寄存器会,数据会复制进来,传输到线路之外,UART 是一种允许你通过串行线发送比特的设备,发送是一条线路,接收是另一条线路,基本上,你取一个字节它们在这一条线上是多路复用或串行化的,送到另一边,有一个 UART 芯片在另一边,将比特组装回单个字节。你还可以在这个设备上,控制其他几件事情,你可以一定程度上控制设备的波特率,对我们来说最重要的可能是寄存器 1(A0) ,在这里,是中断启用寄存器,我们可以对它编程,使 UART 生成中断。
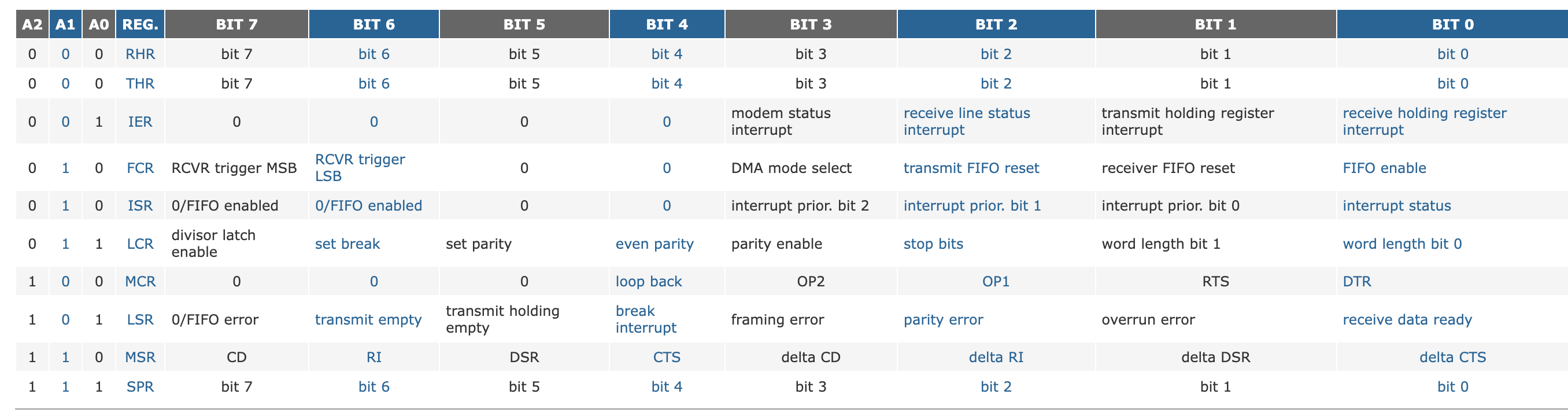
文档更详细地描述了每个寄存器中的每一位的含义,比如,在中断启用寄存器 IER 中,有接收行状态中断,和传输保持状态中断。这是这些位的含义。它还有很多,有更多的文档,如何对启用寄存器等进行编程,等等。这是真实文档的一个简短版本,真正芯片制造商的文档要多得多,有更多的内容和更多的细节,这个对我们谈论 UART 编程足够了。你可以看到,这是最简单的设备之一,即使那份文档,它也相当复杂。
如果你写入,如果你将某些内容写入传输保持寄存器,然后你再写一遍,在那之后,它是不是确保了之前的数字不会被覆盖。
Solution: 是或不是,这是你来决定的,实际上这是我们要关注的一件事,你告诉,加载指令加载一些值,或存储指令将一些值加载到寄存器中,然后, UART 芯片继续,它会把那个字节发送到串行线路上,当它完成时,它将生成一个中断,告诉内核,好了,完成了那个字节,现在你可以给我下一个字节了。因此内核和设备必须遵循一个协议,以确保一切都能顺利解决。这个我们使用的 UART ,16550A 实际上内部有一个 FIFO ,我想它可以缓冲一些字符,我想最多是 16 个字符。但是你仍然要玩这个游戏,你不能放入超过 16 个字符,在设备告诉你已经发送了一个字符之前。
为了解释设备和中断是如何工作的,
是 $ ls,你知道这里发生了什么。实际上是如何打印的,发生的事情是,就像我们刚才讨论的那样,在本例中,基本上就是把 $ 符放入 UART ,实际上,是我们刚看过的寄存器中。然后 UART 产生中断,我们可以设置,当发送字符时产生一个中断。然后在另一边,所以 QEMU 中的事情是这样设置的,QEMU 在一个在发送线上,在发送线路的另一边,通常是另一个 UART 芯片,它连接到控制台,连接到一个虚拟控制台。另一方面,你知道 ls 会发生什么,我们需要使用输入,所以,键盘实际上连接到接收的线路,接收线。基本上就是键盘,你按了键盘上的一个键,在本例中的虚拟键盘,另一边的 UART 芯片,会序列化字符 l ,把它发送给另一边的 UART ,另一边把位放在一起变成一个字节,然后产生中断,生成中断告知处理器,嘿,键盘上有一个字符可用。在中断处理程序中,收到 UART 的字节,
sie: supervisor interrupt enabled register
- One bit per software interrupt, external interrupt, and timer interrupt
寄存器用于控制每个中断源的使能状态
sstatus: supervisor status register
• SIE bit enables or disables interrupts
• Other bits record the mode when interrupt occurred
寄存器用于管理处理器的状态和控制,包括全局中断使能和屏蔽状态
sip: supervisor interrupt pending register
• Which type of interrupts are waiting to be handled
scause: the platform-specific cause of the interrupt
• Also familiar exceptions like page faults are causes
stvec: sets up the interrupt handler (addr in kernel)
好的, RISC-V 有一系列的支持,对中断的支持。我们会更详细地了解一些会使用的寄存器的细节,但是知道有哪些是有用的,这是 SIE(supervisor interrupt enabled register) ,对外部中断(比如 UART ),软件中断(比如从一个 RISC-V 核心向另一个 RISC-V 核心发送中断),定时器中断,各有一位使能位,但我不准备谈论管理者模式的软件中断或计时器中断,而是重点放在外部中断。
还有另一个我们见过的寄存器,SSTATUS(supervisor status register),它有一个位用来禁用和启用特定内核上的中断。所以,每个核心都有这些寄存器,除了这三个位之外,对于每个控制,你有外部中断、软件中断、计时器中断,有一个位可以控制收到的中断,所以,你可以原子地从没有中断切换到可以中断,反之亦然,只需要修改 SSTATUS 寄存器中的这一位。
然后是 SIP ( supervisor interrupt pending register),称为管理程序中断挂起寄存器,基本上进程可以使用它,当中断发生,查看 SIP ,看是什么中断。另外,当中断发生时,
在 SCAUSE ( the platform-specific cause of the interrupt),我们之前已经看过几次,将会出现一个进入的中断的指示
STVEC 寄存器(sets up the interrupt handler (addr in kernel)),保存程序,或处理器切换的地址,当 trap 系统调用,或发生页面错误,产生中断,因为这三种情况都使用相同的机制。
我不会说太多关于 SCAUSE 和 STVEC ,因为我们之前已经详细看过了,基本上以相同的方式运行,与页面错误或其他异常的系统调用一样。
设备驱动初始化
这些东西是如何初始化的,我们不会谈论驱动的实际工作方式,而是看看 xv6 程序是如何对它编程,设置这些寄存器,让我们处于中断的位置。那么让我们来看一下, xv6 如何对寄存器编程。第一件事可能是在 start.c 中,当机器启动时,处理器启动时,start 函数被调用,它以 M 模式运行,它禁用了页表,因为很快,稍后,内核可以设置页表,我们在这里看到,将所有中断和异常交给管理者模式,然后,对管理者中断启用寄存器编程,用来接受软件中断,定时器中断,以及外部中断。然后为了更好的衡量,定时器中断发生在 M 模式,M 模式代码对定时器寄存器编程,然后产生计时器中断。我不想讨论这个,
【top命令的结果分析】
top命令的结果分为两部分:
统计信息:前五行是系统的整体统计信息,包括时间、运行时间、登录用户数、系统负载、进程数、CPU状态、内存状态和交换分区状态等。1 进程信息:从第七行开始,显示了各个进程的状态信息,包括进程ID、用户、优先级、内存占用、CPU占用、运行时间和命令等。1 top命令的各列含义如下:
PID:进程ID USER:进程所有者的用户名 PR:进程优先级,范围为0 - 31,数值越低,优先级越高 NI:nice值。 范围 -20到+ 19 ,用于调整进程优先级,新的进程优先级 PR ( new )=PR (old)+ nice,所以nice负值表示高优先级,正值表示低优先级 VIRT:进程使用的虚拟内存总量,单位 KB。 VIRT=SWAP+RES RES:进程使用的、未被换出的物理内存大小,单位 KB。 RES=CODE+DATA SHR:共享内存大小,单位 KB S:进程状态。 D =不可中断的睡眠状态 R=运行 S=睡眠 T=停止 t=跟踪 Z= 僵尸进程 %CPU:上次更新到现在的 CPU 时间占用百分比。 注意,在多核或多 CPU 环境中,如果进程是多线程的,而 top 不是在线程模式下运行的,该值由多个核的值累加,可能会大于 100 % %MEM:进程使用的物理内存百分比 TIME+:进程使用的 CPU 时间总计,单位 1 / 100 秒
定时器中断
xv6 使用定时器中断来维护对“当前时间”的认知,并在计算密集型进程之间进行切换。定时器中断来自连接在每个 RISC-V CPU 上的时钟硬件。xv6 会对每个 CPU 的时钟硬件进行编程,使其周期性地中断 CPU。
start.c的代码设置了一些控制位,使得用户可以在 supervisor 模式下访问定时器控制寄存器,然后请求第一次定时器中断。时间控制寄存器中包含一个计数值,硬件会以恒定速率递增该计数,这就构成了对“当前时间”的一种表示。
stimecmp 寄存器中保存一个时间点,当 CPU 的当前时间达到该值时,就会触发一次定时器中断。将 stimecmp 设置为“当前时间 + x”,就可以安排在 x 个时间单位之后触发中断。在 QEMU 的 RISC-V 模拟中,1000000 个时间单位大约相当于 0.1 秒。
定时器中断通过 usertrap 或 kerneltrap 以及 devintr 进入系统,就像其他设备中断一样。当 scause 的低位为 5 时,表示这是一个定时器中断;trap.c 中的 devintr 会检测到这种情况并调用 clockintr(3482 行)。clockintr 会增加 ticks,使内核能够追踪时间的流逝。这个递增操作只在一个 CPU 上进行,以避免在多核情况下时间流逝得更快。
clockintr 会唤醒所有在 pause 系统调用中等待的进程,并通过向 stimecmp 写入新的值来安排下一次定时器中断。
对于定时器中断,devintr 返回 2,表示 kerneltrap 或 usertrap 应该调用 yield,从而在可运行进程之间进行 CPU 复用(调度切换)。
内核代码可能会被定时器中断打断,并通过 yield 强制进行上下文切换,这也是 usertrap 一开始就必须小心保存状态(例如 sepc)并在允许中断之前完成这些操作的原因之一。这种上下文切换还意味着:内核代码必须在“可能随时在不同 CPU 之间切换执行”的前提下编写。
现实系统
像 xv6 以及很多操作系统一样,在内核运行时是允许中断发生,甚至发生上下文切换(通过yield),这样做的原因是,为了在执行那些很耗时的系统调用时,仍然保持较好的响应速度。不过,这也带来了复杂性——因为在内核中允许中断,会让并发情况变得更难处理。因此,也有一些操作系统选择:只在用户态运行时才允许中断。
在一台典型计算机上完整支持所有设备是非常复杂的工作,因为设备种类很多、每个设备功能很多、设备和驱动之间的协议复杂且文档不完善。在在很多操作系统中,驱动代码的规模甚至超过了内核核心代码。
UART 驱动是通过一次读取一个字节(从控制寄存器中)来获取数据的,这种方式叫做:程序控制 I/O(programmed I/O),也就是说:数据搬运完全由软件控制,这种方式虽然简单,但是速度太慢。
对于需要高速、大量数据传输的设备,通常使用直接内存访问(DMA, Direct Memory Access),特点是设备可以直接把数据写入内存(RAM)或者直接从内存读取数据。 现代的磁盘和网络设备基本都使用 DMA。对于 DMA 设备的驱动流程通常是,驱动先在内存中准备好数据,然后只需向控制寄存器写一次,设备就会自动处理这些数据。与之相比的UART 驱动,需要从设备 → 内核缓冲区 → 用户空间(两次拷贝)
中断的适用场景,设备在“不可预测的时间”需要 CPU 注意,并且事件发生频率不高。缺点是:CPU 开销较高。因此,高速设备(如网络、磁盘)会用一些优化手段减少中断:批量中断——一次中断处理一批请求; 轮询——驱动主动定期检查设备状态,而不是等中断
控制台(console)在应用看来是一个“普通文件”,可以通过read、write来输入输出,到那时有些设备无法通过标准文件接口表达,例如开关行缓冲(line buffering),Unix提供了ioctl系统调用。
某些应用需要“实时”响应,必须在一个确定的时间上限内完成响应。xv6不适合实时系统,原因是,调度器不考虑 deadline,内核中存在较长时间关闭中断的代码路径。真正的实时操作系统RTOS需要设计成可以分析“最坏情况下的响应时间”(worst-case response time)
源码精读:UART 驱动 / 控制台 / 内核态 trap
三份参考源码
uart.c/console.c/kernelvec.S正好串成「上半部(进程内核线程)发请求并睡眠 ↔ 下半部(中断)唤醒」这套生产者-消费者模型。代码取自 xv6-riscv(rev5)。
1. uart.c:最底层的 16550 驱动
1.1 寄存器宏 & 全局状态
设备寄存器就是 UART0 起始的几个物理地址,用 volatile 指针读写——volatile 告诉编译器每次都真的访存、不要缓存到寄存器(因为这些地址有硬件副作用):
#define Reg(reg) ((volatile unsigned char *)(UART0 + (reg)))
#define ReadReg(reg) (*(Reg(reg)))
#define WriteReg(reg, v) (*(Reg(reg)) = (v))
#define RHR 0 // 读:收到的字节
#define THR 0 // 写:要发送的字节(同一地址,读写含义不同)
#define IER 1 // 中断使能
#define LSR 5 // 行状态:bit0=有数据可读, bit5=THR 空可再发
#define LSR_RX_READY (1<<0)
#define LSR_TX_IDLE (1<<5)
// 发送线程与「发送完成中断」之间的同步三件套:
static struct spinlock tx_lock;
static int tx_busy; // UART 是否正在发送
static int tx_chan; // &tx_chan 作为 sleep/wakeup 的「等待通道」1.2 uartinit:配置硬件、打开中断
void uartinit(void) {
WriteReg(IER, 0x00); // 先关中断
... // 设波特率、8 位字长、使能并清空 FIFO
WriteReg(IER, IER_TX_ENABLE | IER_RX_ENABLE);// ★ 打开收/发中断
initlock(&tx_lock, "uart");
}1.3 上半部:uartwrite(发字节,会睡眠)
这是 write() 系统调用最终落到的发送路径,运行在进程内核线程,可以睡眠:
void uartwrite(char buf[], int n) {
acquire(&tx_lock);
int i = 0;
while (i < n) {
while (tx_busy != 0) {
// UART 还在发上一个字节 → 睡在 tx_chan 上,等发送完成中断唤醒
sleep(&tx_chan, &tx_lock);
}
WriteReg(THR, buf[i]); // 把一个字节塞进发送保持寄存器
i += 1;
tx_busy = 1; // 标记「正在发送」
}
release(&tx_lock);
}tx_busy=1,下一个字节前若设备还忙就 sleep 让出 CPU;真正叫醒它的是下半部的发送完成中断。sleep 会原子地释放 tx_lock 并挂起,醒来时重新持锁——所以下半部能安全地拿同一把锁改 tx_busy。1.4 uartputc_sync:轮询式发送(给 printk / 回显用)
内核 printk 和字符回显不能依赖中断/调度(可能在关中断、panic、早期启动阶段),所以走纯轮询:
void uartputc_sync(int c) {
push_off(); // 关中断(保护临界区)
while ((ReadReg(LSR) & LSR_TX_IDLE) == 0) // 自旋等 THR 空
;
WriteReg(THR, c);
pop_off();
}对比:
uartwrite是中断驱动 + 睡眠(高效、能让出 CPU);uartputc_sync是忙等(简单、不依赖调度,但浪费 CPU)。同一个设备两种用法,体现了「轮询 vs 中断」的取舍。
1.5 下半部:uartintr(中断处理)
由 devintr 在收到 UART 中断(IRQ 10)时调用,运行在中断上下文、没有特定进程,因此绝不能睡眠:
void uartintr(void) {
ReadReg(ISR); // 读 ISR 确认(acknowledge)中断
acquire(&tx_lock);
if (ReadReg(LSR) & LSR_TX_IDLE) { // 发送完成?
tx_busy = 0;
wakeup(&tx_chan); // ★ 唤醒在 uartwrite 里睡着的发送线程
}
release(&tx_lock);
// 把收到的字符全部取出来,逐个交给控制台层
while (1) {
int c = uartgetc(); // 读 LSR.RX_READY,有则读 RHR
if (c == -1) break;
consoleintr(c);
}
}一次中断可能同时意味着「发完了」和「来了新输入」——所以这里既处理 tx(唤醒发送方)又 drain rx(读空接收 FIFO)。这呼应了「中断只是提示,要靠读状态寄存器判断到底发生了什么」。
2. console.c:行编辑 + 生产者/消费者缓冲
控制台在 UART 之上提供「按行读取、支持退格」的终端语义。核心是一个环形输入缓冲 + 三个下标:
struct {
struct spinlock lock;
#define INPUT_BUF_SIZE 128
char buf[INPUT_BUF_SIZE];
uint r; // Read index:consoleread 读到哪了
uint w; // Write index:已成行、可供读取的边界
uint e; // Edit index:正在编辑的位置(退格在 e 和 w 之间移动)
} cons;[r, w) 是「已经成行、可被 read 消费」的字符;[w, e) 是「用户正在敲、还没回车」的一行——按退格能在这区间内删除。只有遇到 \n(或 ^D / 缓冲满)时才把 w 推进到 e,整行一次性放出。这就是 Unix 终端「行缓冲」的实现。2.1 消费者:consoleread(进程上下文,会睡眠)
int consoleread(int user_dst, uint64 dst, int n) {
uint target = n;
acquire(&cons.lock);
while (n > 0) {
while (cons.r == cons.w) { // 缓冲里没有成行的数据
if (killed(myproc())) { release(&cons.lock); return -1; }
sleep(&cons.r, &cons.lock); // ★ 睡在 &cons.r 上,等中断喂数据
}
int c = cons.buf[cons.r++ % INPUT_BUF_SIZE];
if (c == C('D')) { ... break; } // ^D = EOF
either_copyout(user_dst, dst, &cbuf, 1); // 拷到用户缓冲
dst++; --n;
if (c == '\n') break; // 读到一整行就返回
}
release(&cons.lock);
return target - n;
}2.2 生产者:consoleintr(中断上下文,不睡眠)
被 uartintr 对每个输入字符调用一次,做行编辑并在成行时 wakeup:
void consoleintr(int c) {
acquire(&cons.lock);
switch (c) {
case C('U'): // Ctrl-U 杀掉整行:把 e 退回到上一个 \n
while (cons.e != cons.w && cons.buf[(cons.e-1)%INPUT_BUF_SIZE] != '\n') {
cons.e--; consputc(BACKSPACE);
}
break;
case C('H'): case '\x7f': // 退格/删除:e 退一格
if (cons.e != cons.w) { cons.e--; consputc(BACKSPACE); }
break;
default:
if (c != 0 && cons.e - cons.r < INPUT_BUF_SIZE) {
c = (c == '\r') ? '\n' : c;
consputc(c); // 回显给用户
cons.buf[cons.e++ % INPUT_BUF_SIZE] = c; // 存进缓冲
if (c=='\n' || c==C('D') || cons.e-cons.r==INPUT_BUF_SIZE) {
cons.w = cons.e; // ★ 整行就绪:推进 w
wakeup(&cons.r); // ★ 唤醒 consoleread
}
}
break;
}
release(&cons.lock);
}consoleread 睡在 &cons.r,生产者 consoleintr 成行时 wakeup(&cons.r);发送方 uartwrite 睡在 &tx_chan,中断 uartintr 发完时 wakeup(&tx_chan)。两条链都靠同一把锁(cons.lock / tx_lock)保护共享缓冲,避免上下半部并发竞争。2.3 consolewrite & 接线
consolewrite 把用户数据分批 either_copyin 到内核小缓冲,再调 uartwrite 发出。consoleinit 把控制台挂到文件系统的设备表上,使 read/write 落到这里:
void consoleinit(void) {
initlock(&cons.lock, "cons");
uartinit();
devsw[CONSOLE].read = consoleread; // read() → consoleread
devsw[CONSOLE].write = consolewrite; // write() → consolewrite
}3. kernelvec.S:内核态 trap 的入口
用户态 trap 走 trampoline.S 的 uservec(见 Lec 6);但当 CPU 已经在内核态时发生中断/异常,走的是 kernelvec。它简单得多——因为已经在内核页表、用的是当前内核栈,不需要换页表、不需要 trapframe:
kernelvec:
addi sp, sp, -256 # 在「当前内核栈」上腾出空间
# 只保存 caller-saved 寄存器(ra, gp, t0-t6, a0-a7)
sd ra, 0(sp)
# sd sp, 8(sp) # 不保存 sp:就是当前栈,加减自洽
sd gp, 16(sp)
# sd tp, 24(sp) # 不保存 tp:里面是 hartid
sd t0, 32(sp)
...
sd t6, 240(sp)
call kerneltrap # 进入 C 处理(trap.c)
ld ra, 0(sp) # 恢复
...
ld t6, 240(sp)
addi sp, sp, 256
sret # 回到内核里被打断的地方kerneltrap 是个普通 C 函数调用,callee-saved 寄存器(s0–s11)由它自己负责保存/恢复,kernelvec 只需替被打断的代码保住 caller-saved 的那些(ra/gp/t*/a*)。sp 不用存——它就是当前内核栈指针,addi 加减后自然还原;tp 也不存(且返回时不恢复),因为它装着 hartid,万一中途换了核,应保留新核的值。能直接在当前栈上压寄存器的前提是:内核态发生中断时一定有一个有效的内核栈。
kerneltrap之后同样调用devintr来分派设备中断;定时器中断在这里返回 2,触发yield——这也是「内核代码可被抢占」的来源(见 Lec 13)。
4. 一次键盘输入的完整生产者-消费者时序
shell: read(0, buf, n)
└─ consoleread: cons.r == cons.w(空)→ sleep(&cons.r) 让出 CPU ← 消费者睡下
[你按下键盘 'l']
设备 → PLIC(IRQ 10) → CPU trap → kernelvec → kerneltrap → devintr
└─ plic_claim()=10 → uartintr()
├─ uartgetc() 读 RHR 得到 'l'
└─ consoleintr('l'): 回显 + 存入 cons.buf;若是 '\n' 则 cons.w=cons.e + wakeup(&cons.r)
└─ plic_complete(10)
调度器恢复 shell → consoleread 从 sleep 醒来 → 取出字符 copyout 到用户 → read 返回 ← 消费者被唤醒输出方向对称:write → consolewrite → uartwrite(写 THR、置 tx_busy、睡 &tx_chan)↔ 发送完成中断 uartintr(清 tx_busy、wakeup(&tx_chan))。