Lec 8 一致性
课件:Consistency and Linearizability (l-linearizability.txt);论文:Linearizability (Herlihy & Wing)(读到 §3.1);FAQ
课件精讲:一致性模型与线性一致性
它禁止的异常:脑裂(多 leader)、崩溃恢复后忘记已完成的写、读到滞后副本/过期缓存、重传导致重复执行。线性一致只管单个对象的单个操作,不支持跨对象的事务。
FAQ(线性一致性 答疑整理)
来自
linearizability-faq.txt。
- 线性一致解决什么问题? 给联网服务(并发请求、延迟、复制、故障、分片)一个明确的正确性规约,指导应用编写与架构决策。
- 定义是什么? 看"历史"(带 start/finish 的操作迹);若能给每个操作指定落在其时间窗内的线性化点、按点顺序执行的结果与实际一致,则线性一致。
- 为何它是理想模型? 较强、避免许多令程序员困惑的异常;强一致一般比弱模型更易推理。
- 为何不用客户端发送时刻当线性化点? 网络延迟使到达顺序≠发送顺序;放宽到 [invoke,response] 之间任意点以兼顾性能。
- 服务如何实现线性一致? 单机按收到顺序串行执行(小心去重);复制系统更复杂但可在保持 happens-before 的前提下重排并发操作。
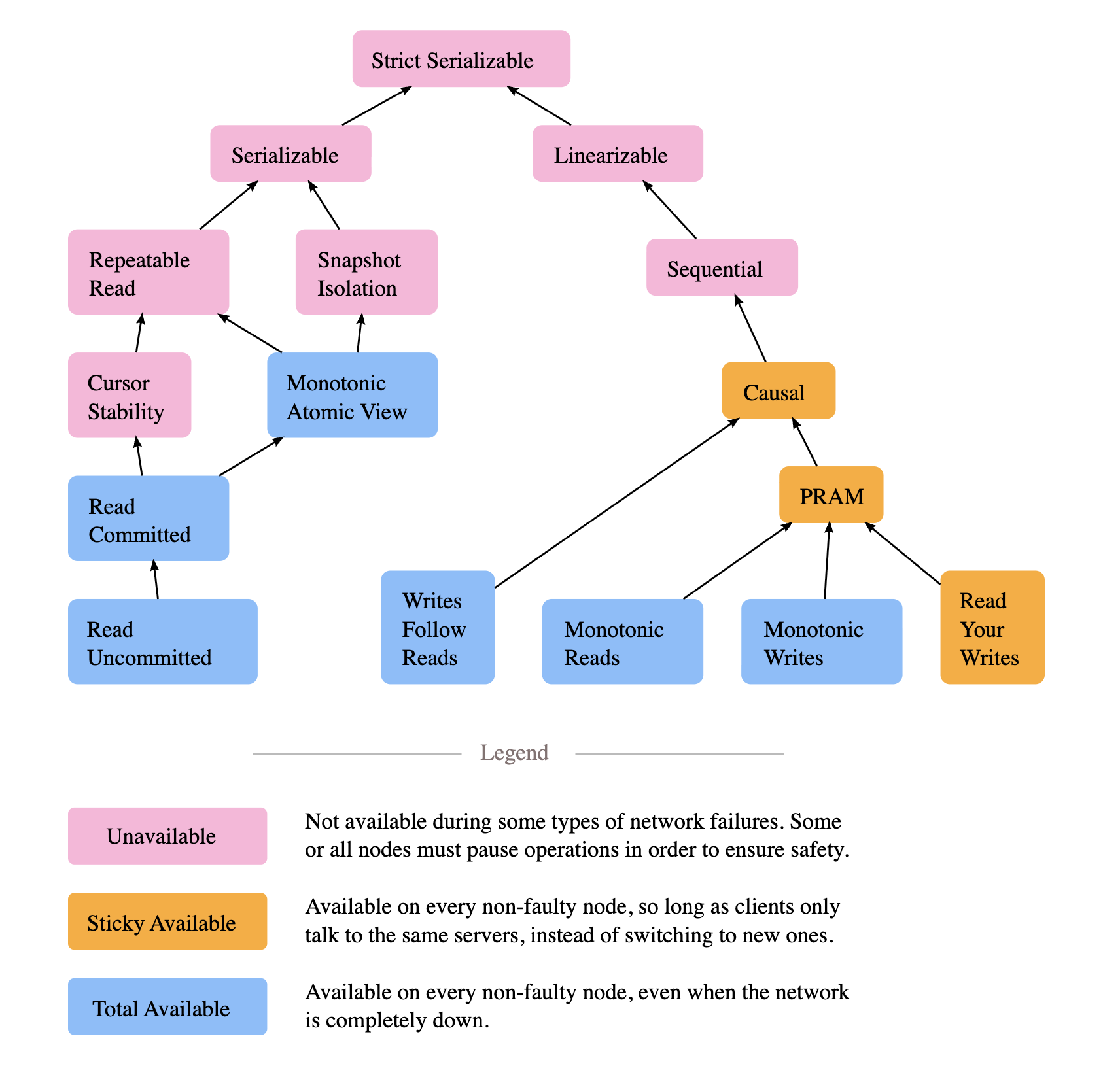
- 其他一致性模型? 最终一致、因果一致、fork 一致、可串行化、顺序一致、timeline 一致等。
- 并发读看到不同值,是不是说明它很弱? 没错,有更强的(数据库事务),但带容错时复杂得多、慢得多。
- 并发 put 时并发 get 看到不同值有问题吗? 通常没有,类似多核内存行为(如头像,并发观察者看到不同版本是合理的)。
- 哪些真实系统提供线性一致 vs 更弱? Spanner、S3 线性一致;GFS、Dynamo、Cassandra 最终一致。
- 怎么确保分布式系统正确? 用 Porcupine 这类线性一致性检查器大量测试 + 形式化方法;Jepsen 常态化测试各存储系统。
- 检查器怎么工作? 高效搜索可能的线性化点指派,剪掉不可能的顺序、分解历史、用启发式优先尝试。
本节的主题是一致性模型(Consistency Module),特别是可线性化(linearizability)。
背景 一个非常非常常见做法是将存储作为单独的服务,这样一来,计算和存储是分开的,两者通过RPC进行通信。我们需要推测分布式存储具备正确的行为,即判断逻辑上是否可行?比如,应用程序员期望从GFS返回什么,单个请求的行为要清晰。 另外,并发客户端应该如何交互?
于是我们需要一致性模型。 一致性模型是一种规范,描述了客户端对服务的不同视图之间的关系。为了方便理解,本节我们会用,多个客户端访问的K/V存储服务为例,给定一些put(k, v),get(k)调用,得到的结果如何。
如果是传统的过程式编程,就没什么好讲的,因为,我们读到的数据是最近一次写入的,无可厚非 😃
线性一致性
我们刚提到,一致性模型是一个规范,让客户端能够推测出服务的行为,更好的配合来满足对方的需求。 从服务端角度想,如果没有规范,那么很难去做设计/实现/优化,例如客户端从GFS副本读到从节点落后的数据,是否可以接受?
下一步怎么制定通用的规范?或者说有哪些一致性模型?
- 有时候为了简化应用程序开发人员的工作
- 有时是为了提升存储性能
- 有时是为了方便实现
- 不同领域(文件系统、数据库、CPU内存)的一致性定义有很多重叠的地方。
我们主要讨论线性一致性(linearizability),还会介绍最终一致性(eventual consistency)、因果一致性(causal consistency)、分支一致性(fork consistency)和串行一致性(serializability)
驱动因素: 性能、易用性和容错性之间的权衡。
引例
我们现在假设有一个单个操作的顺序(serial)规范。这里顺序是指,单个服务器在一次只能执行一个操作(One-by-One),这种行为很容易理解,也没啥问题。
db=dict()
def put(k, v):
db[k] = v
def get(k):
return db[k]现实世界是分布式的、并发的。这就引出了核心问题:多个客户端会同时向服务器发送请求。一个请求的生命周期:1. 花时间在网络上传输;2. 服务器收到后开始计算,可能需要与其他副本通信;3. 服务器发送回复,同样需要花时间在网络传输;4. 客户端最终收到回复。 在这个期间,其他客户端可能在发送/接受/等待,整个世界不再是一次只做一件事。
我们需要一个方法来描述并发的场景。我们可以通过论述哪些结果是允许/不允许的。
历史
我们可以定义历史 (History),用于描述一个可能包含并发操作的时间线。考虑每个操作都有客户端开始和结束时间,及参数和返回值
举个例子
C1: |-Wx1-| |-Wx2-|
C2: |---Rx2---|横向表示真实事件,用 |表示某个时刻,Wx1表示put(x, 1), Rx2表示get(x)->2
为什么? 一段历史是一次实际执行中客户端所观察到情况的追踪(trace)记录。它用于检查该次执行是否满足线性一致性。设计者通过思考"这种情况可以接受吗?"来进行想法实验。
IMPORTANT
一段历史是可线性化的,如果同时满足:
- 你能为每个操作在其开始和结束时间之间找到一个时间点(线性化点)
- 该历史产生的结果值,与所有操作按照这些时间点的顺序进行串行执行所得到的结果相同
给几个例子:
# 例子1
|--Wx1--| |--Wx2--|
|----Rx2----|
|--Rx1--| 答案是:可串行化的线性一致性通常允许多种不同的结果,所以我们常常无法提前预测结果,但可以事后进行检查。但是注意,服务内部很可能并不是按照我们选定的那些时间点操作的,但是我们并不关心服务内部如何运作,只关心客户端看到的结果,是否满足我们的期望。
为什么 用线性一致性定义的用途,
- 对于设计者而言,这个优化会导致非线性的结果吗?
- 对于程序员:作为客户端,我可以假设/期望什么?
- 对于测试:生成请求,检查观测到的历史记录是否符合。
# 例子2
|-Wx1-| |----Wx2----|
|---Rx2---|
|-Rx1-|
答案是不能这个故事告诉我们,如果我们想要线性一致性:
- 一旦任何读取操作看到了某次写入的结果,所有严格在其之后的读取操作也必须看到这次写入
- 不能“忘记”一个已经暴露出去的写入
# 例子3
|--Wx0--| |--Wx1--|
|--Wx2--|
|-Rx2-| |-Rx1-|
答案是可以这个故事告诉我们,服务可以为并发的写入选择任意顺序。
# 例子4
|--Wx0--| |--Wx1--|
|--Wx2--|
C1: |-Rx2-| |-Rx1-|
C2: |-Rx1-| |-Rx2-|
答案是不能这个故事告诉我们, 服务可以为并发写入选择任意顺序,但所有客户端必须看到相同的写入顺序!当存在副本或缓存时,这一点非常重要——它们都必须以相同的顺序执行操作。
# 例子5
|-Wx1-|
|-Wx2-|
|-Rx1-|这个故事告诉我们,读取必须返回最新的数据,即使读取者不知道最新的写入(例如从落后的副本读),但时间要求上, 它需要读取最新的数据。
线性一致性排除了许多错误:
- 脑裂
- 崩溃后重启忘记已完成的写入
- 从滞后的副本换货过时的缓存中读取数据
# 例子6:
C1发送了 put(x, 1)
C2发送了 put(x, 2)
服务收到了C1的请求
- 网络丢失了响应;
- C1的RPC库重新发送了请求服务执行C1的两个请求消息是合法的吗?
如果C3进行了三次读取,我们可能会看到
C1: |--------Wx1---------| (由于重传,执行了两次)
C2: |-Wx2-|
C3: |-Rx1-| |-Rx2-| |-Rx1-| (假设x初始为0,三次读取分别返回1, 2, 1)
这段历史不是线性一致性。这个故事告诉我们,如果想要线性一致性:
- 必须抑制(supress)重传带来的重复请求!(幂等性)
线性一致的系统并不局限于简单的读取和写入操作。它还可以支持:
- 递增
- 追加
- CAS(实现锁)
- 任何对服务状态的操作
应用程序员喜欢线性一致性——因为它相对易于使用:
- 读取能看到最新数据
- 所有客户端看到的数据都是一样的
- 所有客户端都以相同的顺序看到数据的变更
当我们研究更弱的一致性模型时, 这些好处会更加清晰。
如何实现线性一致性
这取决于我们想要多少复制、缓存和容错能力。
最简单的实现,一个不会崩溃、串行执行的单服务器。 服务器为并发到达的客户端请求选择一个顺序。按照这个顺序一次一个地执行它们,在开始下一个操作之前,先回复前一个操作。再加上重复请求抑制(机制)。
注意: 服务器本身并不需要去推理历史记录、线性化点或并发性。它只需要简单地按序执行操作即可。线性一致性是这个简单执行模型自然而然产生的结果。
是否存在比线性一致性更强的一致性?
比如说,让get操作一定能看到最近已完成的put操作。
下面的例子中,
C1: |---Wx1---|
C2: |---Wx2---|
C3: |--Rx2--| // 必须在Wx2完成后,所以必须读到2
而在下面的例子中,我们又必须保证 Rx1,绝不能是 Rx2
C1: |---Wx1---|
C2: |---Wx2---|
C3: |--Rx1--| // 在Wx2完成前,Wx1完成后,所以必须读到1这样的保证将非常困难,服务器很难准确地知道操作在客户端看来是何时完成的。线性一致性对服务器而言是友好的,它允许在并发操作排序上有一定的自由度。
我们还想要高可用性怎么办?
Solution: 主备复制。
- 所有请求都发给主节点
- 主节点选择一个串行顺序
- 将操作转发给所有备份节点
- 主节点只有在所有备份节点执行完成后,才恢复客户端。
因此,如果客户端收到了响应,则保证所有备份节点都已执行了该操作。这一点在主节点故障时至关重要,可以避免已完成的请求被遗忘。需要一个外部角色来决定何时应由备份节点接管(成为新的主节点),这是为了避免脑裂。
线性一致性系统的性能怎么样?
Solution:
- 坏消息:其串行特性可能使其难以获得并行加速(难以通过增加机器来线性提升性能)。
- 坏消息:如果采用复制,则需要大量的通信和等待(延迟高)。
- 坏消息:如果采用复制,副本必须能够被访问到(在线),这限制了容错能力(例如,如果要求所有副本都必须确认,那么任何一个副本宕机都会导致系统不可用)。
- 好消息:你可以通过按键分片(shard by key) 来提升性能。(即不同键的操作可以并行处理在不同的服务器组上)。
最终一致性
数据有多个副本(例如,为了速度,放在不同的数据中心),读操作可以查询任何一个副本(例如,最近的)。写操作可以更新任何一个副本(例如,最近的)。副本在后台同步更新,最终,其他副本将会看到我的更新。
最终一致性也很流行,因为比线性一致性更快。尤其是当副本为了容错二分部在不同的城市时(无需等待远程副本确认)。可用性更高——任何副本都可以处理请求。
但是,最终一致性将一些异常情况暴露给了应用程序员:
- 读取可能看不到最近的写入——读取可能会看到过时的数据。
- 写入可能以乱序出现。
- 不同的客户端可能看到不同的数据。
- 需要对同一项的并发写入进行冲突解决!
最终一致性无法支持像 test-and-set 这样的操作。
FQA
Q:为什么不使用客户端发送命令的时间作为线性化点呢?也就是说,让系统按照客户端发送的顺序执行操作?
A: 确保这种行为是很困难的——开始时间是客户端代码发出请求的时间,但由于网络延迟,服务可能直到很久以后才收到请求。也就是说,请求可能以与开始时间顺序相差很大的顺序到达服务端。原则上,服务端可以延迟执行每个到达的请求,以防止稍后到达的请求比较早发出,但可能会大大增加延迟。尽管如此,Spanner,使用了一种相关的技术。
Q: 那么,服务是如何实现线性一致性的呢?
如果服务是作为单个服务器实现的,没有复制、缓存或内部并行处理,那么服务几乎可以按照它们到达的顺序逐个执行客户端请求。主要的复杂性来自于客户端因为认为网络丢失了消息而重新发送请求:服务必须小心确保不要执行同一个客户端请求超过一次(幂等性)。如果服务涉及复制或缓存,则需要更复杂的设计。
Q: 为什么线性一致性被认为是一种强一致性
A:这段内容强调了线性一致性的强大之处在于禁止了许多可能令应用程序员感到惊讶的情况。
举例来说,如果我调用了 put(x, 22),并且我的 put 操作完成了,而且没有其他人写入了 x,随后你调用 get(x),你将会保证看到的值除了 22 之外没有其他值。换句话说,读操作看到的是新鲜的数据。
另一个例子,如果没有人写入 x,而我调用了 get(x),而你也调用了 get(x),我们只会看到相同值。
这些特性在一些其他的一致性模型中并不成立,比如最终一致性和因果一致性。这些后者的模型通常被称为“弱一致性”。
Q:实际中人们如何保证它们的分布式是系统是正确的
A:我猜想,彻底的测试是最常见的计划。
使用形式化方法也很常见;以下是一些示例链接
Understanding Inconsistency in Azure Cosmos DB with TLA+
How Amazon Web Services Uses Formal Methods
Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3
Formal Verification of a Distributed Dynamic Reconfiguration Protocol
An Empirical Study on the Correctness of Formally Verified Distributed Systems
Q: 线性一致性检查器如何工作
该检查器会尝试每一种可能的顺序(或线性化点的选择),以查看是否有一种顺序符合线性一致性的定义规则。由于在大型历史记录上这样做会非常慢,聪明的检查器避免查看明显不可能的顺序(例如,如果一个提议的线性化点在操作的开始时间之前),将历史记录分解为可以单独检查的子历史记录,当可能时,使用启发式方法优先尝试更有可能的顺序。
Faster linearizability checking via P-compositionality
[Testing for Linearizability](paper.pdf (ox.ac.uk))
其他一致性模型
阅读: 一种测试线性一致性的方法
一种测试线性一致性的方法 Testing Distributed Systems for Linearizability
分布式系统的正确实现很有难度,因为必须要处理并发和失效的问题,网络可能会延迟、重排序、重复、或者丢包,很难避免在实现中发现一些潜在bug。检测分布式本身也是一项很有挑战的事,特别是并发且非确定性程序。
在线性一致的KV存储系统中,两个客户端在同时发出get()请求获取同个key后可能收到不同的值吗? 如果不能解释一下原因,如果能,它如何发生?