Lec 5 Golang
Go 编程的思维
Go 是什么 & 不是什么
首先Go是面向对象而不是面向类型。Go 没有继承,任何类型都可以有方法,但没有类、和子类
第二、Go(大部分情况下)是隐式的不是显式的。类型通过推断,而不是声明; 对象通过实现方法自动获得接口,而不是指定。
第三,Go 是并发的,不是并行的。Go 的并发是为了更好的程序结构,而不是追求最高性能,不过它依然可以很好地利用所有 CPU 核心,而且有些程序即使完全不并行,使用并发编写也会更优雅。
Go无层次对象
Go有对象但无层次结构。 在 Java 中,类型层次结构是程序的基础,随着设计的演变,很难改变它。(妥协设计比改变基础更容易。)
Go 编程的主要内容并非类型和继承。Go 没有类型层次结构。最重要的设计决策无需事先做出,而且随着程序的开发,更改类型也很容易,因为编译器会自动推断它们之间的关系。 因此,Go 程序更加灵活,适应性更强。
Go无继承
我们先看JAVA的做法。
public static class ZlibCompressor {
public int compress(byte[] in, int intOffset, int inLength, byte[] out, int outOffset) { ... }
}假设你想泛化到不同的压缩器,我们需要定义一个抽象数据类型
public abstract class AbstractCompressor {
abstract int compress(byte[] in, int intOffset, int inLength, byte[] out, int outOffset);
// compresses byte buffers using abstract compress method
// assumes buffers are based on arrays
public void compress(Buffer in, Buffer out) {
int nWritten = compress(in.array(), in.arrayOffset() + in.position(), inremaining(), out.array(), out.arrayOffset() + out.position());
out.position(out.positioin() + nWritten);
}
}继承抽象类
public static class ZlibCompressor extends AbstractCompressor {
public int compress(byte[] in, int intOffset, int inLength, byte[] out, int outOffset) { ... }
}这就是常用的JAVA风格,继承抽象行为。
我们现在看Golang的做法。
type Compressor interface {
Compress(in, out []byte) int
}
func CompressBuffer(c Compressor, in, out *Buffer) {
n := c.Compress(in.Bytes(), out.Bytes())
out.Advance(n)
}这是一个Good的Golang风格,只是使用抽象行为。
隐式意味着灵活性
在Go中,可以使用任何数量的Wrapper。一个类型可以满足多个接口,因此可以被任意数量的 抽象wrapper 使用。而在Java中,只能扩展一个抽象类, 可以使用Java接口,但仍需要注释原始实现,也就是说,需要编辑现有代码。(代码不属于你怎么办?)
在Go中,Compressor的实现者不太需要了解 CompressBuffer 甚至 Compressor接口。
接口是轻量级的
典型的GO接口只有1个或两个方法,新的程序员可能会将接口视为类型继承来构建块,并且打算用很多方法来创建接口,但这是错误的,他们应是小而准确的;因为接口小,它们更灵活;Go 的接口经常是为特定场景、特定目的临时定义的
Go 接口是按需抽象,不是先建塔后填砖。
举个例子,泛化RPC
Go 中的 RPC 包使用 gob 包来对连接中的对象进行编组。我们需要一个使用 JSON 的变体。
type ServerCodec interface {
ReadRequestHeader(*Request) os.Error
ReadRequestBody(interface{}) os.Error
WriteRequest(*Response, interface{}) os.Error
Close() os.Error
}// 原函数签名
func sendResponse(sending *sync.Mutex, req *Request,
reply interface], enc gob.Encoder, errmsg string)
// 这里用的 enc 是 gob.Encoder 类型,也就是说 RPC 系统强依赖 gob 编码器
// 修改后的签名
func sendResponse(sending *sync.Mutex, req *Request,
reply interface{}, enc ServerCodec, errmsg string)也就是说,为了实现这个解耦,整个 RPC 系统只需要改几行函数签名(可能两个函数),其余代码基本不用动。函数体里只改了一点点(比如从 .Encode(...) 改成调用 enc.WriteResponse(...) 之类的).
发现其实 RPC 系统只需要两个能力:Read 和 Write。于是他们从已有代码中抽出一个只包含这两个方法的接口,如:
这个抽象是“事后”加上的。
相比而言,Go无需管理类型层次,只是传了一个接口stub。不像Java那样,需要重构一个抽象类,创建JsonRPC/GobRPC 子类。
Go 编程语言和环境
一致性
我们对 Go 的一个目标是让它在不同的实现、执行上下文,甚至随着时间的推移,都能保持相同的行为。这种“枯燥乏味”的一致性行为,让开发者能够专注于日常工作,而 Go 则逐渐淡出人们的视线。
首先,Go 语言尽可能地指定一致的结果,即使对于诸如空指针引用和数组越界索引之类的错误行为也是如此。Go 要求不一致行为的一个例外是map的迭代。我们发现,程序员经常会不经意地编写依赖于哈希函数的代码,导致在不同的架构或 Go 实现上得到不同的结果。
为了使程序在所有情况下都保持相同的行为,一种选择是强制使用特定的哈希函数。然而,Go 却将映射迭代定义为非确定性的。该实现为每个映射使用不同的随机种子,并从哈希表中的随机偏移量开始对映射进行每次迭代。结果是,映射在不同实现之间始终不可预测:代码不会意外地依赖于实现细节。
一致性的另一个方面是程序生命周期内的性能。Go 决定使用传统的编译器(而不是 Java 和 Node.js 等语言使用的 JIT)来实现,这在启动时以及对于短生命周期程序提供了一致的性能:没有“慢启动”来惩罚每个进程生命周期的前几秒。这种快速启动使得 Go 成为命令行工具(如上一节所述)和可扩展网络服务器(例如 Google App Engine)的理想选择
工具辅助开发
大规模软件开发需要大量的自动化和工具化。Go 语言从一开始就旨在通过简化工具化创建来鼓励此类工具的使用。
开发人员的日常 Go 体验是通过 go 命令进行的。与仅编译或运行代码的语言命令不同,go 命令为开发周期的所有关键部分提供了子命令:go build 和 go install 用于构建和安装可执行文件,go test 用于运行测试用例,go get 用于添加新的依赖项。go 命令还支持通过编程方式访问构建细节(例如包图),从而创建新的工具。
go vet 就是这样一个工具,它执行增量式、一次一个包的程序分析,其缓存方式与缓存编译后的目标文件支持增量构建的方式相同。go vet 工具旨在高精度地识别常见的正确性问题,以便开发人员习惯于关注其报告。简单的例子包括检查 fmt.Printf 及相关函数调用中的格式和参数是否匹配,或者诊断对变量或结构体字段的未使用写入。这些并非编译器错误,因为我们不希望旧代码仅仅因为发现了新的可能错误就停止编译。它们也不是编译器警告;用户会逐渐忽略这些警告。将检查放在单独的工具中,可以让它们在方便开发者的时间运行,而不会干扰正常的构建过程。即使使用 Go 编译器的其他实现,例如 Gccgo 或 Gollvm,所有开发者都可以使用相同的检查。增量方法使这些静态检查足够高效,以至于我们在运行测试本身之前,在 go test 期间自动运行它们。测试本身就是用户寻找错误的时刻,而报告通常有助于解释实际的测试失败。此增量框架也可供其他工具重用。
分析程序的工具固然有用,但编辑程序的工具则更加出色,尤其是在程序维护方面,因为程序维护工作繁琐乏味,极易实现自动化。
Go 程序的标准布局是通过算法定义的。gofmt 工具会将源文件解析为抽象语法树,然后使用统一的布局规则将其格式化回源代码。在 Go 中,在将代码存储到源代码管理中之前进行格式化被认为是最佳实践。这种方法使成千上万的开发人员能够在共享代码库上工作,而无需像大型项目那样为括号样式和其他细节而争论不休。更重要的是,工具可以通过操作抽象语法形式来修改 Go 程序,然后使用 gofmt 的打印器输出结果。我们只会修改实际更改的部分,从而生成与人工手动生成的“差异”完全一致的“差异”。这样,开发人员和程序就可以在同一个代码库中无缝协作。
为了实现这种方法,Go 的语法设计为无需类型信息或任何其他外部输入即可解析源文件,并且无需预处理器或其他宏系统。Go 标准库提供了一些软件包,允许工具重新创建 gofmt 的输入和输出端,以及完整的类型检查器。 在发布 Go 1.0(第一个稳定的 Go 版本)之前,我们编写了一个名为 gofix 的重构工具,它使用这些软件包来解析源代码、重写树并编写出格式良好的代码。例如,当从 map 中删除条目的语法发生更改时,我们就使用了 gofix。每次用户更新到新版本时,他们都可以在其源文件上运行 gofix,以自动应用更新到新版本所需的大部分更改。
这些技术也适用于构建 IDE 插件 和其他支持 Go 程序员的工具(分析器、调试器、分析器、构建自动化程序、测试框架等等)。 Go 的常规语法、成熟的算法代码布局约定以及直接的标准库支持,使得这类工具的构建比以往更加容易。因此,Go 世界拥有一个丰富、不断扩展且互操作性极强的工具包。
库管理
除了语言和工具之外,用户体验 Go 的下一个关键方面是可用的库。作为一门分布式计算语言,Go 无需设置一个中央服务器来发布 Go 包。相反,每个以域名开头的导入路径都会被解释为一个 URL(隐式以 https:// 开头),指明远程源代码的位置。例如,导入“github.com/google/uuid”会获取托管在相应 GitHub 仓库中的代码。
托管源代码最常见的方式是指向公共 Git 或 Mercurial 服务器,但私有服务器也同样受到良好支持,并且作者可以选择发布静态文件包,而无需开放对源代码控制系统的访问权限。
仅仅下载包是不够的;我们还必须知道要使用哪些版本。Go 将包分组到称为模块(module)的版本化单元中。模块可以为其依赖项之一指定最低要求版本,但不能指定其他限制。在构建特定程序时,Go 会通过选择最高版本来解决依赖项模块的版本冲突:如果程序的一部分需要依赖项的 1.2.0 版本,而另一部分需要 1.3.0 版本,则 Go 会选择 1.3.0 版本——也就是说,Go 要求使用语义版本控制 ,其中 1.3.0 版本必须是 1.2.0 的直接替代品。另一方面,在这种情况下,即使 1.4.0 版本可用,Go 也不会选择它,因为程序的任何部分都没有明确要求该较新版本。此规则使构建可重复,并最大限度地降低了新版本引入的意外破坏性更改导致的潜在破坏风险。
Go并发模式
并发不是并行
并发concurrency: composition of independently executing processes
并行parallelism: simultaneous execution of computations
并发是关于一次性处理很多事情;而并行是同时执行很多事情
状态机goroutine
目的: /"([^"\\]|\\.)*"/ 检测字符串是否以双引号包围
// 第一版
state := 0
for {
c := read()
switch state {
case 0:
if c != '"' {
return false
}
state = 1
case 1:
if c == '"' {
return true
}
if c == '\\' {
state = 2
} else {
state = 1
}
case 2:
state = 1
}
}
// 第2版
state0:
c := read()
if c != '"' {
return false
}
goto state1
state1:
c := read()
if c == '"' {
return true
}
if c == '\\' {
goto state2
} else {
goto state1
}
state2:
read()
goto state1
// 第3版
state0:
c := read()
if c != '"' {
return false
}
state1:
c := read()
if c == '"' {
return true
}
if c == '\\' {
read()
goto state1
} else {
goto state1
}
// 第4版
state0:
c := read()
if c != '"' {
return false
}
state1:
c := read()
if c == '"' {
return true
}
if c == '\\' {
read()
}
goto state1
// 第5版
c := read()
if c != '"' {
return false
}
for {
c := read()
if c == '"' {
return true
}
if c == '\\' {
read()
}
}
// 第6版
if read() != '"' {
return false
}
var c rune
for c != '"' {
c = read()
if c == '\\' {
read()
}
}
return true
// 第7版
type quoter struct {
state int
}
func (q *quoter) Init() {
r.state = 0
}
func (q *quoter) Write(c rune) Status {
switch q.state {
case 0:
if c != '"' {
return BadInput
}
q.state = 1
case 1:
if c == '"' {
return Success
}
if c == '\\' {
q.state = 2
} else {
q.state = 1
}
case 2:
q.state = 1
}
return NeedMoreInput
}提示,可用
// 最终版
type quoter struct {
char chan rune
status chan Status
}
func (q *quoter) Init() {
q.char = make(chan rune)
q.status = make(chan Status)
go q.parse()
<-q.status // always NeedMoreInput
}
func (q *quoter) Write(c rune) Status {
q.char <- c
return <-q.status
}
func (q *quoteReader) parse() {
if q.read() != '"' {
q.status <- SyntaxError
return
}
var c rune
for c != '"' {
c = q.read()
if c == '\\' {
q.read()
}
}
q.status <- Done
}
func (q *quoter) read() int {
q.status <- NeedMoreInput
return <-q.char
}在程序中引入额外的 goroutine,用于执行特定的任务或管理特定的状态。这样可以将不同任务或状态的处理逻辑分离开来,提高代码的模块化和可维护性
Pattern#1 发布订阅服务器
type PubSub interface {
// Publish publishes the event e to
// all current subscriptions.
Publish(e Event)
// Subscribe registers c to receive future events.
// All subscribers receive events in the same order,
// and that order respects program order:
// if Publish(e1) happens before Publish(e2),
// subscribers receive e1 before e2.
Subscribe(c chan<- Event)
// Cancel cancels the prior subscription of channel c.
// After any pending already-published events
// have been sent on c, the server will signal that the
// subscription is cancelled by closing c.
Cancel(c chan<- Event)
}
type Server struct {
mu sync.Mutex
sub map[chan<- Event]bool
}
func (s *Server) Init() {
s.sub = make(map[chan<- Event]bool)
}
func (s *Server) Publish(e Event) {
s.mu.Lock()
defer s.mu.Unlock()
for c := range s.sub {
c <- e
}
}
func (s *Server) Subscribe(c chan<- Event) {
s.mu.Lock()
defer s.mu.Unlock()
if s.sub[c] {
panic("pubsub: already subscribed")
}
s.sub[c] = true
}
func (s *Server) Cancel(c chan<- Event) {
s.mu.Lock()
defer s.mu.Unlock()
if !s.sub[c] {
panic("pubsub: not subscribed")
}
close(c)
delete(s.sub, c)
}这些是处理慢速 goroutines 的一些选项:
- 减缓事件生成。
- 放弃事件, 以确保系统不会因为事件积压而崩溃。
- 队列任意数量的事件:可以使用无界队列来存储事件,无论事件生成的速度如何,都可以将事件存储在队列中,等待处理。这样可以防止事件丢失,但可能会导致队列无限增长,最终耗尽系统资源
type Server struct {
publish chan Event
subscribe chan subReq
cancel chan subReq
}
type subReq struct {
c chan<- Event
ok chan bool
}
func (s *Server) Init() {
s.publish = make(chan Event)
s.subscribe = make(chan subReq)
s.cancel = make(chan subReq)
go s.loop()
}
func (s *Server) loop() {
sub := make(map[chan<- Event]bool)
for {
select {
case e := <-s.publish:
for c := range sub {
c <- e
}
case r := <-s.subscribe:
if sub[r.c] {
r.ok <- false
break
}
sub[r.c] = true
r.ok <- true
case c := <-s.cancel:
if !sub[r.c] {
r.ok <- false
break
}
close(r.c)
delete(sub, r.c)
r.ok <- true
}
}
}
func (s *Server) Publish(e Event) {
s.publish <- e
}
func (s *Server) Subscribe(c chan<- Event) {
r := subReq{c: c, ok: make(chan bool)}
s.subscribe <- r
if !<-r.ok {
panic("pubsub: already subscribed")
}
}
func (s *Server) Cancel(c chan<- Event) {
r := subReq{c: c, ok: make(chan bool)}
s.cancel <- r
if !<-r.ok {
panic("pubsub: not subscribed")
}
}提示: 如果能将代码可读性变好的话,将锁改成goroutine
func helper(in <-chan Event, out chan<- Event) {
var q []Event
for in != nil || len(q) > 0 {
// Decide whether and what to send.
var sendOut chan<- Event
var next Event
if len(q) > 0 {
sendOut = out
next = q[0]
}
select {
case e, ok := <-in:
if !ok {
in = nil // stop receiving from in
break
}
q = append(q, e)
case sendOut <- next:
q = q[1:]
}
}
close(out)
}
Pattern#2 工作调度
func Schedule(servers []string, numTask int,
call func(srv string, task int)) {
idle := make(chan string, len(servers))
for _, srv := range servers {
idle <- srv
}
}这个提示告诉我们,可以使用一个带缓冲的通道作为并发的阻塞队列。这种方法允许在一开始就将所有服务器添加到队列中,然后在需要时按顺序获取空闲的服务器
func Schedule(servers []string, numTask int,
call func(srv string, task int)) {
idle := make(chan string, len(servers))
for _, srv := range servers {
idle <- srv
}
for task := 0; task < numTask; task++ {
go func() {
srv := <-idle
call(srv, task)
idle <- srv
}()
}
}提示,可以使用 goroutines 让独立的任务并发地运行。在这个例子中,每个任务都被包装在一个 goroutine 中,并从 idle 通道中获取空闲的服务器。通过使用 goroutines,每个任务可以独立运行,不会阻塞其他任务的执行
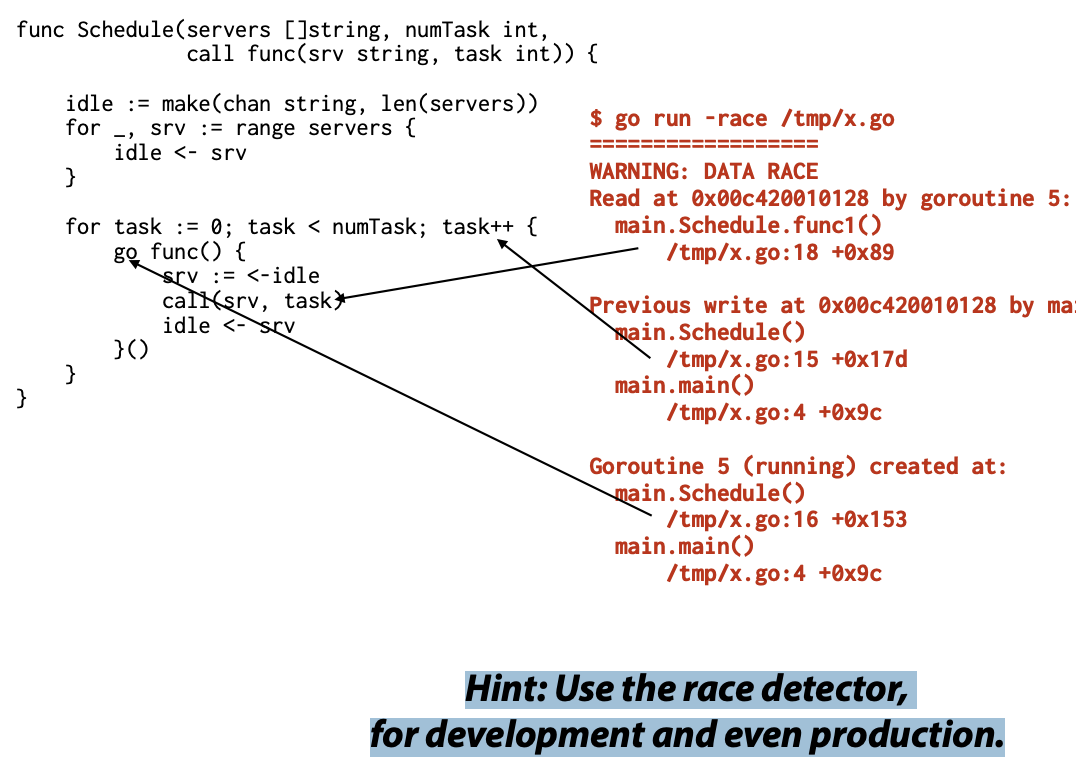
func Schedule(servers []string, numTask int,
call func(srv string, task int)) {
idle := make(chan string, len(servers))
for _, srv := range servers {
idle <- srv
}
for task := 0; task < numTask; task++ {
task := task
go func() {
srv := <-idle
call(srv, task)
idle <- srv
}()
}
}提示,在引入无界队列之前,要仔细考虑一下。在这段代码中,使用了一个带有缓冲区的通道(idle),但并没有限制其大小,因此它是一个无界队列。在并发编程中,引入无界队列可能会导致一些问题,例如内存泄漏或者资源耗尽
func Schedule(servers []string, numTask int,
call func(srv string, task int)) {
idle := make(chan string, len(servers))
for _, srv := range servers {
idle <- srv
}
for task := 0; task < numTask; task++ {
task := task
srv := <-idle
go func() {
call(srv, task)
idle <- srv
}()
}
for i := 0; i < len(servers); i++ {
<-idle
}
}这段代码实现了一个调度器(Schedule)函数,它用于在多个服务器上并发执行任务。函数接受三个参数:服务器列表(servers)、任务数量(numTask)和一个回调函数(call),回调函数用于在服务器上执行任务。函数首先创建了一个带有缓冲区的通道(idle),缓冲区大小与服务器列表的长度相同。然后,它将每个服务器的名称发送到通道中,以表示这些服务器当前是空闲的。接下来,通过一个循环,函数会根据任务数量并发执行任务。在每次迭代中,都会从通道中接收一个服务器名称,并在新的 goroutine 中执行任务。由于 goroutine 是并发执行的,因此需要注意确保在读取服务器名称后,将任务和服务器名称传递给回调函数。最后,函数通过循环从通道中接收所有服务器名称,以等待所有任务执行完毕。这样做可以确保在函数退出之前,所有的任务都已经完成。
func Schedule(servers []string, numTask int,
call func(srv string, task int)) {
work := make(chan int)
done := make(chan bool)
runTasks := func(srv string) {
for task := range work {
call(srv, task)
}
done <- true
}
for _, srv := range servers {
go runTasks(srv)
}
for task := 0; task < numTask; task++ {
work <- task
}
close(work)
for i := 0; i < len(servers); i++ {
<-done
}
}提示:如果不再向通道发送数据时需要关闭通道
func Schedule(servers chan string, numTask int,
call func(srv string, task int)) {
work := make(chan int)
done := make(chan bool)
runTasks := func(srv string) {
for task := range work {
call(srv, task)
}
done <- true
}
go func(){
for _, srv := range servers {
go runTasks(srv)
}
}
for task := 0; task < numTask; task++ {
work <- task
}
close(work)
for i := 0; i < len(servers); i++ {
<-done
}
}提示: 开发者使用 goroutines 来让独立的任务和关注点能够并行执行,这样可以更好地利用并发特性,提高程序的效率和性能
func Schedule(servers chan string, numTask int,
call func(srv string, task int) bool) {
work := make(chan int, numTask)
done := make(chan bool)
exit := make(chan bool)
runTasks := func(srv string) {
for task := range work {
if call(srv, task) {
done <- true
} else {
work <- task
}
}
done <- true
}
go func() {
for {
select {
case svr := <-servers:
go runTasks(srv)
case <-exit:
return
}
}
}()
for task := 0; task < numTask; task++ {
work <- task
}
close(work)
exit <- true
}Pattern#3 复制C/S
type ReplicatedClient interface {
// Init initializes the client to use the given servers.
// To make a particular request later,
// the client can use callOne(srv, args), where srv
// is one of the servers from the list.
Init(servers []string, callOne func(string, Args) Reply)
// Call makes a request on any available server.
// Multiple goroutines may call Call concurrently.
Call(args Args) Reply
}
type Client struct {
servers []string
callOne func(string, Args) Reply
mu sync.Mutex
prefer int
}
func (c *Client) Init(servers []string, callOne func(string, Args) Reply) {
c.servers = servers
c.callOne = callOne
}提示: 如果使用互斥锁是编写代码的最清晰方式,那么就使用它。这意味着在实现Client结构体的方法时,如果需要确保对数据的安全并发访问,可以使用互斥锁来保护共享数据,以避免并发访问导致的数据竞争和不确定行为
func (c *Client) Call(args Args) Reply {
type result struct {
serverID int
reply Reply
}
done := make(chan result, 1)
id := ...
go func() {
done <- result{id, c.callOne(c.servers[id], args)}
}()
}这个提示告诉我们,可以使用 goroutines 来让独立的任务在独立的 goroutines 中并发执行。在这个例子中,我们希望在调用远程服务器时异步执行,以允许请求并发处理。通过使用 goroutines,我们可以让请求调用函数 c.callOne 在一个单独的 goroutine 中执行,而不会阻塞当前的执行流程。这样可以提高程序的并发性能,并允许独立的任务在独立的 goroutines 中并行执行,从而提高整体系统的吞吐量和响应性
func (c *Client) Call(args Args) Reply {
type result struct {
serverID int
reply Reply
}
const timeout = 1 * time.Second
t := time.NewTimer(timeout)
defer t.Stop()
done := make(chan result, 1)
id := ...
go func() {
done <- result{id, c.callOne(c.servers[id], args)}
}()
select {
case r := <-done:
return r.reply
case <-t.C:
// timeout
}
}这个提示提醒我们需要停止我们不再需要的定时器,以避免资源浪费。在这个例子中,我们设置了一个定时器 t,用于控制调用的超时时间。但是,一旦我们从通道 done 中接收到结果,我们就不再需要等待超时事件了,因此我们应该停止定时器以释放资源。
另外,提示还提醒我们需要了解每个 goroutine 何时退出的原因和时机。在这个例子中,goroutine 在发送结果到通道 done 后就会退出,因为它完成了任务。知道 goroutine 的退出时机可以帮助我们更好地管理资源和避免潜在的泄漏问题。
最后,提示还提醒我们需要知道每个通信操作何时会继续进行。在这个例子中,我们使用 select 语句来等待通道 done 中的结果或者定时器 t 的超时事件。了解通信操作何时会继续进行可以帮助我们编写更加健壮和可靠的并发代码
func (c *Client) Call(args Args) Reply {
type result struct {
serverID int
reply Reply
}
const timeout = 1 * time.Second
t := time.NewTimer(timeout)
defer t.Stop()
done := make(chan result, len(c.servers))
for id := 0; id < len(c.servers); id++ {
id := id
go func() {
done <- result{id, c.callOne(c.servers[id], args)}
}()
select {
case r := <-done:
return r.reply
case <-t.C:
// timeout
t.Reset(timeout)
}
}
r := <-done
return r.reply
c.mu.Lock()
prefer := c.prefer
c.mu.Unlock()
var r result
for off := 0; off < len(c.servers); off++ {
id := (prefer + off) % len(c.servers)
go func() {
done <- result{id, c.callOne(c.servers[id], args)}
}()
select {
case r = <-done:
goto Done
case <-t.C:
// timeout
t.Reset(timeout)
}
}
r = <-done
Done:
c.mu.Lock()
c.prefer = r.serverID
c.mu.Unlock()
return r.reply
}这个提示告诉我们,有时使用 goto 语句是编写清晰代码的最佳方式。在这个例子中,goto 被用来跳出循环,并在最后处理完逻辑后返回结果。在这种情况下,使用 goto 可以简化代码逻辑,避免重复代码,并更清晰地表达程序的控制流程。
Pattern#4 协议复用
type ProtocolMux interface {
// Init initializes the mux to manage messages to the given service.
Init(Service)
// Call makes a request with the given message and returns the reply.
// Multiple goroutines may call Call concurrently.
Call(Msg) Msg
}
type Service interface {
// ReadTag returns the muxing identifier in the request or reply message.
// Multiple goroutines may call ReadTag concurrently.
ReadTag(Msg) int64
// Send sends a request message to the remote service.
// Send must not be called concurrently with itself.
Send(Msg)
// Recv waits for and returns a reply message from the remote service.
// Recv must not be called concurrently with itself.
Recv() Msg
}
type Mux struct {
srv Service
send chan Msg
mu sync.Mutex
pending map[int64]chan<- Msg
}
func (m *Mux) Init(srv Service) {
m.srv = srv
m.pending = make(map[int64]chan Msg)
go m.sendLoop()
go m.recvLoop()
}
func (m *Mux) sendLoop() {
for args := range m.send {
m.srv.Send(args)
}
}
func (m *Mux) recvLoop() {
for {
reply := m.srv.Recv()
tag := m.srv.ReadTag(reply)
m.mu.Lock()
done := m.pending[tag]
delete(m.pending, tag)
m.mu.Unlock()
if done == nil {
panic("unexpected reply")
}
done <- reply
}
}
func (m *Mux) Call(args Msg) (reply Msg) {
tag := m.srv.ReadTag(args)
done := make(chan Msg, 1)
m.mu.Lock()
if m.pending[tag] != nil {
m.mu.Unlock()
panic("mux: duplicate call tag")
}
m.pending[tag] = done
m.mu.Unlock()
m.send <-args
return <-done
}这种方式在协议复用的模式中是常见的,因为它允许在并发环境中安全地处理消息通信。编写代码的最清晰方式--使用goroutines、channels和mutexes
建议
- 在开发和甚至生产中使用竞态检测器(race detector)来检测并发问题。
- 当数据状态变得复杂时,将其转换为状态机以提高程序清晰度。
- 当程序更清晰时,将互斥锁(mutexes)转换为goroutines。
- 使用额外的goroutines来保存额外的代码状态。
- 使用goroutines让独立的关注点独立运行。
- 考虑慢goroutines的影响。
- 理解每次通信何时进行以及每个goroutine何时退出的原因和时间。
- 使用Ctrl-\ 终止程序并转储所有其goroutine的堆栈。
- 使用HTTP服务器的 /debug/pprof/goroutine 来检查活动goroutine的堆栈。
- 使用带缓冲的通道作为并发阻塞队列。
- 在引入无界队列之前,请仔细考虑。
- 关闭通道以表示不再发送值。
- 停止不需要的定时器。
- 优先使用defer解锁互斥锁。
- 如果这是编写代码的最清晰的方式,请使用互斥锁。
- 如果这是编写代码的最清晰的方式,请使用goto。
- 如果这是编写代码的最清晰的方式,请同时使用goroutines、通道和互斥锁。
FQA
如何阻止未使用变量的报错?
Solution: 可以用空标识符 _来让未使用的内容暂时保存下来。例如,
import "unused"
// 通过引用该包的某个项,标记该导入为已使用
var _ = unused.Item //TODO: 提交前删除
func main() {
debugData := debug.Profile()
_ = debugData //仅在调试时使用
// ...
}goimports,它可以自动重写 Go 源文件以添加或删除正确的导入项,当 Go 源文件被保存时自动运行gopls中, Go 的官方语言服务器,vscode用它来自动补全、跳转定义、类型检查、自动修复等。
这些在VScode中默认会被集成到Go插件里面。无需手动配置。
defer 的用法注意事项。
Solution:
- defer是FILO,栈的思维,示例。
// prints 3 2 1 0 before surrounding function returns
for i := 0; i <= 3; i++ {
defer fmt.Print(i)
}
// f returns 42
func f() (result int) {
defer func() {
// result is accessed after it was set to 6 by the return statement
result *= 7
}()
return 6
}- 调用的函数值和参数都会照常计算并重新保存,只不过不会被调用。
- 最初引入
defer,是为了配合panic/recover机制,用于异常处理。后来发现defer mu.Unlock()这样的编程习惯也很有用。
panic、recover 的用法
Solution:Go 没有像 Java 或 Python 那样的异常机制(try-catch),但它提供了 panic 和 recover:
panic(interface{}): 引发一个运行时崩溃。可以传入任何值(数字、字符串、error 对象等)作为 panic 原因。recover() interface{}: 用来捕获 panic,让程序恢复正常执行。但它必须在defer函数中调用才有效。
Panic的传播过程,称为Panicking
当执行函数F时发生panic(显式调用panic):
- 终止F的执行
- 所有被F defer执行的函数会照常执行(后进先出)。
- 逐层向上传播 panic,直到 goroutine 的顶层。
- 没有被recover捕获,程序会打印堆栈信息并退出,包括panic参数值。
recover 的作用和限制
recover 只能在 defer 函数中调用,并且只能捕获当前 goroutine 的 panic。
- 如果当前 goroutine 没有 panic,
recover()返回nil。 - 果当前 goroutine 正在 panic,
recover()返回传给 panic 的值 - 一旦 recover 被成功调用(没有引发新的panic),panic 被“吞掉”,程序恢复正常执行。
示例: 保护函数不让panic崩溃程序
func protected(g func()) {
defer func() {
log.Println("done") // 即使发生恐慌,Println 仍会正常执行
if x := recover(); x != nil {
log.Printf("run time panic: %v", x)
}
}()
log.Println("start")
g()
}error 处理方式。
Solution:最佳实践
- 自定义错误类型。出错了就返回
error,调用者自己判断并处理
// PathError records an error and the operation and
// file path that caused it.
type PathError struct {
Op string // "open", "unlink", etc.
Path string // The associated file.
Err error // Returned by the system call.
}
func (e *PathError) Error() string {
return e.Op + " " + e.Path + ": " + e.Err.Error()
}
//PathError's Error generates a string like this:
// open /etc/passwx: no such file or directory- 精细处理 error:用断言判断具体类型
for try := 0; try < 2; try++ {
file, err = os.Create(filename)
if err == nil {
return
}
if e, ok := err.(*os.PathError); ok && e.Err == syscall.ENOSPC {
deleteTempFiles() // Recover some space.
continue
}
return
}FAQ(Go 语言与环境 答疑整理)
来自
go-faq.txt,多为语言设计取舍。
- 能关掉"未使用变量/导入"的报错吗? 不能,Go 故意把未用代码当错误(强制整洁)。
defer别的语言有吗? Go 首创(用于 panic 恢复与清理),Swift 后来也加了类似功能。- 为什么类型写在变量名后面? 刻意区别于 C 风格声明,官方文档有设计理由。
- 为什么不像 C++/Java 那样用类和 OOP? Go 用更简单的对象模型(更接近 Smalltalk),便于改造大型系统。
- 多行 struct/定义为何要尾逗号? 因为自动分号插入——没逗号会被隐式分号提前终止行。
- 为什么 while 循环也叫
for? 只需一个循环关键字,C 的 while 与 for 作用相同。 - 从 Rust/Swift 等新语言学到什么? 关注其所有权推断与类型系统增强(Rust/Midori/Pony 的思想),仍是潜在改进方向。
- 为什么强调并发与 goroutine? 源于 Google 的系统编程需求;channel + 轻量并发简化复杂分布式系统。
- 参数按值还是按引用传? 多数类型按值;channel/map/slice 是引用语义;指针接收者也按引用。