Lec 17 AWS Lambda:按需容器加载
阅读材料
- 论文:On-demand Container Loading in AWS Lambda (USENIX ATC 2023)
- 课程材料:Marc Brooker 客座讲座 slides(
mbrooker_cs_slides_2026.pdf)
一句话总览:Lambda 在 2020 年要支持把最大 10GiB 的容器镜像当函数运行,同时保住冷启动(cold start)低至 50ms。难点纯粹是数据搬运:单客户每秒可起 15,000 个容器,若每个都搬运并解包 10GiB,需要 150 Pb/s 带宽——不可能。解法是利用容器镜像的可缓存性、共性、稀疏性三大特性,组合出一套:块级按需加载 + 内容寻址去重(收敛加密)+ 分层缓存 + 纠删码的存储系统。它已可靠服务了数千亿次调用、上百万客户。 ddd
1. 问题:让冷启动扛得住 10GiB 镜像
Serverless / FaaS(Function-as-a-Service):客户只上传代码,平台按事件触发、自动扩缩。冷启动时间(从需要新容量到能执行,常 <1s、低至 50ms)是 FaaS 最关键的体验指标。早期 Lambda 用 ≤250MiB 的 .zip 包,整包下载并解包后才能干活——镜像一大就崩。
幸运的是,容器镜像有三个可利用的性质:
设计哲学(贯穿全文):为大规模云的现实而优化——故障频繁、故障常是部分而复杂的、安全第一。整套方案对客户零额外复杂度(照常 push 镜像即可)。
2. 既有架构(尽量少改)
请求(invoke) ─► Frontend(无状态,负载均衡) ─► Worker Manager(有状态,粘性LB) ─► Worker
加载元数据/鉴权 跟踪每个函数的容量/位置/预测 执行函数每个 Worker 上:一个 Micro Manager 控制进程 + 日志/监控代理 + 大量 MicroVM。每个 MicroVM 基于 Firecracker 虚拟机管理器,内含单一客户单一函数的:精简 Linux guest 内核、提供 Lambda 编程模型的 shim、运行时(如 JVM/CoreCLR)、客户代码与库。
IMPORTANT
安全是第一约束:客户代码与数据不可信。MicroVM 内的负载与共享 Worker 组件之间,唯一的通信是经过简单、久经测试、形式化验证的 virtio 实现(virtio-net / virtio-blk)。这条红线直接决定了后面"为什么选块级而非文件级"。
旧架构(本工作之前):起新 MicroVM 时从 S3 下载 ≤250MiB 的 .zip 并解包进 guest 文件系统——阻塞式整包下载,且即使只用一部分也要解包全部。
3. 块级按需加载(Block-Level Loading)
3.1 为什么是"块级"而非"文件级"
Slacker、Starlight 等在文件系统层做懒加载(对容器很自然,因其本就是文件级归档的叠加栈)。但 Lambda 不选这条路:文件系统本身的复杂度 + 叠加多层文件系统(overlayfs)的复杂度,会不可接受地扩大共享组件的攻击面。于是保留 guest 与 hypervisor 之间的 virtio-blk 块接口,把所有文件系统操作留在 guest 内——代价是必须在块而非文件粒度做稀疏加载。
3.2 确定性扁平化(Deterministic Flattening)
OCI 镜像是一摞 tarball 层,运行时用 overlayfs 叠加。Lambda 改在函数创建时(低频控制面操作,客户分钟级才改一次;而调用是百万级/秒)就把各层按序合并成单个 ext4 文件系统镜像。
扁平化用串行、确定性的文件系统实现(普通实现为性能引入并发 → 不确定;这里确定地选定修改时间等可变参数)。这保证:含未改文件的块逐字节相同 ⇒ 共享基础层的不同镜像之间可做块级去重。
扁平化后,文件系统被切成固定 512KiB 的块(chunk),按内容寻址(块名是其内容的函数)上传到三层缓存的 origin 层(S3)——同内容必同名、只需缓存一份,无需中央索引即可去重。块大小权衡:小块去重更好(减少假共享)、利于随机访问;大块减少元数据与请求数、利于顺序预读。
3.3 Per-MicroVM 加载与写时复制
新增两个组件:① per-function local agent——经 FUSE 向 Firecracker 暴露一个块设备,再经 virtio 进入 guest 挂载;② per-worker local cache——缓存本机常用块、与远程缓存交互。
guest 代码 IO ─(未命中 page cache)─► virtio-blk ─► Firecracker ─► local agent
读: 命中本地缓存直接读;否则从分层缓存取块
写: 写入"块覆盖层"(加密存于 worker),用页粒度 bitmap 标记"该读覆盖层还是底层镜像"guest 可读可写,而本地缓存(及所有缓存层)里的数据保持不可变、可被多个 guest 共享。写经覆盖层 + bitmap 实现;不覆盖整页的写需"读-改-写"。
4. 无信任去重(Deduplication Without Trust)
去重价值巨大:约 80% 新上传函数产生零唯一块(CI/CD 自动重传旧镜像);其余 20% 里平均仅 4.3%、中位 2.5% 是唯一块。去重可减少存储多达 23×,并大幅提升缓存有效性。难点是在加密下去重且最小化信任——每个 Worker 只应能访问发给它的那些函数的数据。
矛盾:去重要"相同内容相同",加密要"一切看起来随机"。解法(源自 Farsite):用块内容自身派生密钥——对块算 SHA256 当密钥,用 AES-CTR + 全零 IV 加密。于是相同明文恒得相同密文,既能去重又加密(SHA256 抗碰撞保证一个 key/IV 只用于一个明文块,零 IV 安全)。
每块还登记进一个 manifest(含每块的偏移、密钥、SHA256)。manifest 用每客户专属的 KMS 密钥(AES-GCM)加密,但只加密"密钥表"部分、整体做认证——这样 GC 能读到块清单却读不到块密钥。manifest 极小(16GiB 镜像的 manifest <3MiB,开销 0.02%)。好处:去重无需共享密钥、无需协调(扁平化进程只需"若不存在则上传")、并提供端到端完整性(Worker 用 manifest 里的 MAC 校验下载的块,篡改即拒)。
NOTE
不压缩:① 网络带宽足够,解压延迟收益边际;② 压缩+加密会泄露明文(压缩后大小是侧信道)。故除"剔除全零块"外不压缩。
热门块被广泛引用,一旦损坏/变慢就影响巨大,还会在分布式存储里造成热点。对策:在密钥派生里加入会变化的盐(salt)(随时间、块热度、可用区/机房而变)。盐不同 → 密钥不同 → 密文不同 → 不互相去重。调节盐轮换频率,即可在去重效率与爆炸半径之间连续权衡。盐完全封装在"块创建层"内,其余组件无感。
💁🏼♀️提示
垃圾回收(GC)—— 基于 roots 的代际回收:无中央引用目录,无法精确引用计数(GC 错块会跨客户大范围伤害)。做法:周期性创建新 root R2(接收新数据)、把旧 root R1 置为 retired(只读),把 R1 中仍被引用的 manifest 连同其块迁移到 R2,迁完才删 R1。删前先入 expired 态——此态仍可读,但任何访问都触发告警并自动停止删除,作为防数据丢失的额外一层。当前活跃 root 的 ID 也混入盐,确保新块不与旧 root 共享。
5. 分层缓存(Tiered Caching)
Worker 取块: 本地缓存(L1) ──未命中──► AZ 级分布式缓存(L2) ──未命中──► S3 origin(L3)- L1(worker 本地) 命中 67%;
- L2(AZ 级) 命中 99.9%(中位);
- L3(S3) 仅 0.06%。
- L2 命中中位 550µs vs 从 S3 origin 取 36ms(P99.9:3.7ms vs 175ms)。
L2 是自研:HTTP2 取块、内存层(热) + flash 层(冷) 两级、LRU-k 淘汰、一致性哈希分布(带负载均衡优化)。
5.1 尾延迟优化:纠删码 + 冗余请求
单副本缓存有三患:尾延迟(单台慢拖累全局,且每次冷启动要取大量块——取 1000 块时有 63% 概率撞上 P99.9 尾延迟)、命中率掉(节点故障/部署即丢)、吞吐受限(单机带宽封顶)。复制能解但成本随副本数线性涨(缓存主要在内存,很贵)。于是选纠删码(erasure coding):
Worker 未命中时从 origin 取块,再把块编码成条带(stripe) 存入缓存。取块时多请求几条(超过重建所需),够数即重建。生产用 4-of-5 码:25% 存储开销、25% 请求率上涨,换来尾延迟大降,且节点故障/部署时命中率不掉。
NOTE
这体现了 "恒定工作量(constant work)" 哲学:成功与失败路径做相同量的工作。常见的"靠重试掩盖故障"会在大系统中诱发亚稳态故障(metastable failure)——纠删码避开了这点。
5.2 稳定性与亚稳态(Metastability)
端到端命中率常 >99.8%。一旦缓存被清空(断电/运维)或命中率骤降(客户行为变),下游流量可能暴涨至正常的 500×。S3 扛得住,但延迟上升 → 据利特尔法则(Little's Law) 应用并发需求上升 → 需要更多 Lambda slot → 负载更高、工作集变化 → 系统填不满缓存,陷入亚稳态雪崩。
类比:Denning 1968 的工作集模型早已描述过——程序缺页 → 换页流量 → 挤掉更多有用页 → 更多缺页……自我强化的危机。
缓解:系统设计为并发受限(concurrency-limited)——容器启动变慢、并发任务超限时,拒绝新启动直到在途完成;并定期在最大并发下从空缓存冷启动测试,确保能从冷缓存恢复。
💁🏼♀️提示
淘汰与定容:用 LRU-k(记最近 k 次访问而非仅最近一次)实现抗扫描——否则大量低频 cron 函数启动会把热条目全顶出去。缓存大小取"达到命中率目标所需"与"按 Five Minute Rule 成本最优所需"两者的较大值。
6. 工程经验与更广泛的教训
- 语言选 Rust(local agent / 缓存均用 tokio + hyper/reqwest):性能稳定、便于形式化验证;但遇到自动向量化脆弱的坑——纠删码的奇偶计算按 64B(AVX512)/32B 做比逐字节快 5–10×,可朴素 Rust 循环却生成逐字节码,且改动易触发回退;最终靠特定写法 +
criterion微基准在构建期断言向量化成功来防回归。 - FUSE 开销:用 FUSE 暴露文件再当块设备,一次读要经 guest 内核 → Firecracker → host FUSE → local agent 来回,需调度 4 个线程,稳态低效、压力下抖动大 → 正迁移到 userfaultfd + mmap(去掉两层)。但不后悔从 FUSE 起步:它提供了便捷接口、清晰的安全隔离,让非系统编程专长的团队也能做出可接受性能。
- 多模态延迟(multi-modality):端到端读延迟呈多峰(<100µs 本地命中、~2.75ms L2 命中、罕见 origin)。多模态是存储系统常态,但给运维出难题:均值对各峰频率敏感、百分位/裁剪均值会掩盖多峰、且难决定该优化哪个峰。
- 客户多把容器当"大规模静态链接" 用——想把函数及全部依赖打成一个原子单元;但容器在此用途下很低效,逼出了去重与稀疏加载。业界需要更轻量的依赖封装机制。
- 缓存是几乎一切有状态系统的关键,却带来亚稳态故障与多模态延迟等风险;对大系统中缓存动态行为的理解仍远远不够。
- MicroVM 提供近乎容器/进程的轻量隔离,又能插入本地/分布式 OS 逻辑,是 OS 研究者工具箱里的强力新工具。
7. 小结与工程视角
稀疏性 ⇒ 块级按需加载(确定性扁平化成 ext4 + 512KiB 内容寻址块 + COW);
共性 ⇒ 收敛加密去重(SHA256 派生密钥 + 全零 IV,manifest 用 KMS 客户密钥,加盐控爆炸半径,root 代际 GC);
可缓存性 ⇒ 三层缓存(L1 67% / L2 99.9% / S3)+ 纠删码 4-of-5 降尾延迟 + 并发限制防亚稳态。
- 整体取舍:表面"零件很多",但全为云的现实服务——频繁/部分/复杂的故障 + 安全至上。同一套加载系统也支撑 Lambda SnapStart(用内存快照进一步降冷启动)。
- 对你(分布式 SaaS)的可借鉴点:① 内容寻址 + 去重是分发镜像/资产/备份的通用利器,尤其当 CI/CD 高频重传时(你正用 GCP Cloud Build 推 Artifact Registry,思路一致);② 收敛加密让"多租户共享存储又互不信任"成为可能,对多客户 SaaS 很有参考;③ 分层缓存 + 纠删码降尾延迟优于盲目复制或重试,且能规避亚稳态雪崩——任何高命中率缓存(含你的 API 网关/边缘缓存)都该想清楚"缓存被清空时下游能否扛住",并用并发限制兜底;④ 确定性构建(固定时间戳等)是实现可去重/可复现产物的前提。
论文阅读
摘要
AWS Lambda 是一种无服务器、事件驱动的计算服务,属于云计算服务中的一个子类别,通常被称为函数即服务(Function-as-a-Service,简称 FaaS)。在最初发布时,AWS Lambda 函数的代码和依赖被限制在 250MB 以内,并以一个简单的压缩包形式打包。2020 年,我们推出了支持将最大 10GiB 的容器镜像部署为 Lambda 函数的功能,使客户能够将更大规模的代码库和依赖项引入 Lambda。在支持更大体积的程序包的同时,仍需满足 Lambda 的一系列目标:快速扩展(单一客户每秒最多新增 15,000 个容器,系统总量远超这个数字)、高请求速率(每秒数百万次请求)、大规模支持(数百万个独立工作负载)以及低启动时延(最短可达 50 毫秒)——这些都带来了巨大的挑战。
本文介绍了我们为 Lambda 构建的存储与缓存系统,该系统经过优化,能够按需高效地分发容器镜像。我们将重点讲述在安全性、效率、延迟和成本方面所面临的挑战,以及我们如何通过结合缓存、重复数据删除、收敛加密、纠删码和块级按需加载等技术手段来解决这些挑战。
自该系统构建以来,已稳定地支撑了数千亿次 Lambda 函数调用,服务超过一百万 AWS 客户,并在高负载和基础设施故障场景下展现出卓越的弹性。
引言
AWS Lambda 是一种无服务器、事件驱动的计算服务,属于一种被称为“函数即服务”(FaaS)的云计算产品类别。自 2015 年首次推出以来,AWS Lambda 函数如今每秒运行数百万次,覆盖了数百万个不同的客户工作负载。
吸引客户使用 Lambda 的一个关键因素是其出色的扩展能力:当负载增加时,它能够在不到一秒钟的时间内完成扩容(通常快至 50 毫秒)。这个扩容时间,客户通常称之为“冷启动时间( cold-start time)”,是决定 FaaS 系统用户体验的最关键指标之一。我们意识到:在冷启动过程中减少数据移动是至关重要的。当时,客户以压缩归档(.zip 文件)的形式将函数部署到 Lambda,并在每次函数实例被创建时进行解压。随着 Lambda 的不断演进,客户越来越希望部署更复杂的应用程序,因而对于更大规模部署的需求迅速增长。同时,客户也希望能够使用容器工具(如 Docker)来构建和管理部署镜像。
然而,客户也不希望在使用容器镜像时牺牲冷启动性能。因此,如何在不增加冷启动时间的前提下,为 AWS Lambda 添加容器支持,成为我们团队面临的一项重大技术挑战。挑战的核心问题非常明确:数据移动。如今,Lambda 每秒最多可以为生产工作负载启动 15,000 个容器,我们预计未来还会继续扩展。如果为这 15,000 个容器中的每一个都传输并解压一个 10GiB 的镜像,那么所需的网络带宽将高达 150Pb/s(拍比特每秒)。为了实现既定的可扩展性和冷启动延迟目标,我们依赖于以下三个关键因素,来简化这一难题:
- 可缓存性(Cacheability):虽然 Lambda 支持数十万个独立的工作负载,但在突发大规模扩容场景中,往往只涉及少量的镜像,这说明这些工作负载具有很高的可缓存性。
- 公共性(Commonality):许多流行的镜像都基于通用的基础层构建(如我们自己的 AWS 基础镜像,或 Alpine 等开源镜像)。对这些通用基础层进行缓存和去重,能减少所有依赖它们的容器的数据传输量。
- 稀疏性(Sparsity):大多数容器镜像中包含了大量文件,而这些文件在应用启动时并不需要(有些甚至永远不会被用到)。Harter 等人 [15] 的研究发现,平均只有 6.4% 的容器数据在启动时是必须的。
我们的解决方案结合了缓存、去重、纠删码(erasure coding)和稀疏加载(sparse loading)等技术,以满足系统的需求。在不增加客户使用复杂度的前提下(客户只需将容器镜像上传到一个便捷的镜像仓库),我们就实现了既定的扩展性和冷启动延迟目标,同时还为未来的进一步扩展留有充足的余地。
在本节中,我们将介绍 AWS Lambda 的现有架构,以及我们构建系统的整体架构。第 2 节将介绍我们稀疏加载方案的底层实现,第 3 节介绍基于收敛加密(convergent encryption)的安全去重架构,第 4 节介绍缓存架构以及我们如何使用纠删码提升可扩展性与尾延迟(tail latency)。第 6 节将我们的方法与学术界和工业界的其他方案进行比较。
1.1 现有架构概述
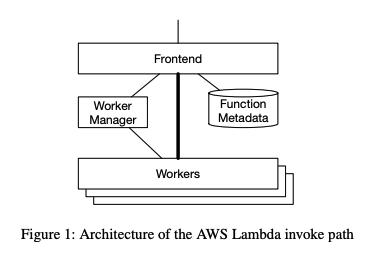
为了降低风险并加快产品发布速度,我们希望在尽量少改动现有 Lambda 架构的前提下,加入上述新能力,如图 1 所示。
当客户请求执行某个函数(我们称之为 invoke)时,请求首先到达一个无状态、负载均衡的前端服务。该服务会加载请求相关的元数据,完成身份验证和权限校验,然后向 Worker Manager 发送请求以申请资源容量。
Worker Manager 是一个有状态的、粘性(sticky)的负载均衡器。它为系统中每个唯一函数维护资源信息:目前有哪些可用资源可以运行该函数,这些资源分布在哪些机器上,何时可能需要新增资源等。
- 如果系统中已有资源可用,Worker Manager 会指示前端将请求负载转发给某个 Worker,Worker 上就会执行这个函数。
- 如果没有资源可用,Worker Manager 会找到一台拥有可用 CPU 和内存的 Worker,发送请求以为该函数启动一个 sandbox(沙箱环境)。启动完成后,前端被通知,函数即可开始执行。
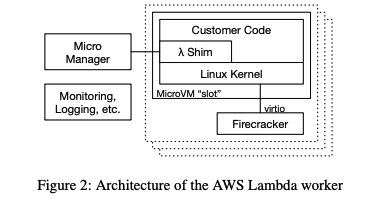
如图 2 所示,每个 Lambda Worker 包含一个小型控制进程(Micro Manager),一些用于日志与监控的附加代理进程,以及大量的 MicroVM(微虚拟机)。
每个 MicroVM 都基于我们的 Firecracker 超级管理程序(hypervisor),运行一个客户的单个 Lambda 函数。MicroVM 内部包括一个最小化的 Linux 客户内核(guest kernel)、一个为 Lambda 提供编程模型的小型 shim 程序、指定的运行时环境(例如 Java 的 JVM 或 .NET 的 CoreCLR)以及客户自己的代码和依赖库。
如 Firecracker 论文 [3] 所述,核心关注点是安全性:客户的代码和数据是不被信任的,MicroVM 内部的工作负载与 Worker 上的共享组件之间只能通过一个简单、经过良好测试且形式化验证的 virtio 实现进行通信(特别是 virtio-net 和 virtio-blk 协议)[27, 32]。
在第一代架构中(即本项工作之前),当为某个函数创建新的 MicroVM 时,Worker 会从 Amazon S3 下载该函数镜像(最大 250MiB 的 .zip 文件),并将其解压到 MicroVM 的文件系统中。 这种模型非常简单,对于小型镜像效果良好,但缺点是:只有等整个归档文件下载和解压完成后,MicroVM 才能开始执行任何任务。
为了支持更大的镜像,我们希望避免这种“阻塞式下载”,并避免当只使用镜像的一部分内容时,仍然需要为整个归档文件的解压承担存储成本。
2. 块级挤在
为了利用容器镜像的“稀疏性”特性,我们需要让系统仅在应用实际需要时加载(和存储)所需的数据,最好还能实现按需加载。一些已有的系统(如 Slacker [15] 和 Starlight [8])尝试在文件系统级别解决这个问题——这对容器来说是比较自然的选择,因为容器镜像通常是多个文件级归档的叠加结构。
但对于我们所处的环境而言,这种做法并不合适。我们认为传统文件系统的复杂性,加上多个文件系统叠加带来的额外复杂性,会不可接受地增加 Lambda 共享组件的攻击面。因此,我们选择保持 MicroVM 来宾系统与管理程序之间使用 块设备接口 virtio-blk,并将所有文件系统操作限制在 guest(来宾系统)内部进行。这就要求我们在块级(block-level)*而非*文件级(file-level)进行稀疏加载。
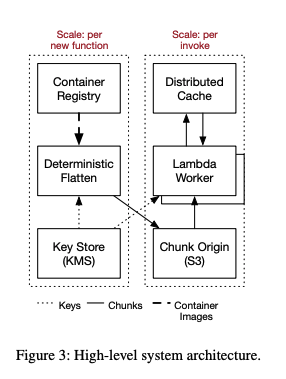
图 3 展示了我们系统的高层架构,包括运行客户代码的 Lambda Worker(在图 4 中详述)、包含容器镜像主副本的容器镜像仓库,以及我们用于分块创建与缓存的基础设施。
我们支持块级加载的第一步是将容器镜像“折叠”为一个块设备镜像。根据 OCI 镜像规范 [1],容器镜像是由一系列 tarball 层堆叠而成的。在典型的容器执行环境中,这些层在运行时使用 overlayfs 进行动态叠加。而在我们的实现中,我们在函数初始创建时执行这种叠加操作,遵循一种确定性的“扁平化”过程,按顺序应用每一层 tarball,最终构造出一个单一的 ext4 文件系统。
函数创建属于控制面操作,频率较低,通常仅在客户修改其代码、配置或架构时才会触发。即使是最积极采用持续集成的用户,也往往是每几分钟才修改一次函数,而函数的调用则可以达到每秒百万次级别。
我们的“扁平化”过程专门设计为:对于包含未变更文件的文件系统块,其内容完全一致,这样就可以在多个函数之间对共享基础层内容进行 块级去重。我们将在第 3 节中详细讨论这个机制,这里仅指出:不同函数之间(甚至同一个函数的不同版本之间)的差异通常比函数本身要小得多。
在扁平化过程中,我们按顺序解包每一层 tarball 到 ext4 文件系统中,使用我们修改过的文件系统实现来确保整个过程是确定性的(deterministic)。大多数文件系统会利用并发来提升性能,因此往往是非确定性的,而我们的实现是串行的,对原本可能变动的参数(如文件修改时间)都做了固定选择。
完成扁平化后,整个文件系统会被切分为固定大小的块(chunks),这些块会被上传到三层缓存架构中的“源站层”(origin tier,使用 S3 实现),以备后续使用。
这些块在共享存储中的命名方式基于其内容的哈希值,这确保了内容相同的块拥有相同名称,从而只需缓存一份即可。第 3 节会详细描述这种机制,它使我们可以高效地在存储层和缓存层实现内容去重,而无需一个中心目录或块索引。
每个固定大小的块为 512KiB:
- 块越小,去重效果越好,可减少“虚假共享”,同时对于访问模式高度随机的工作负载来说加载更快;
- 块越大,元数据更少,加载数据所需的请求次数也更少(提高吞吐量),并可自然支持顺序访问场景下的预读(read-ahead);
- 最优块大小会随着系统演进而变化。我们预计在未来的系统迭代中,随着我们对客户使用模式的理解加深,可能会选择不同的块大小。