Lec 16 缓存一致性
阅读论文
本节的阅读材料是一篇经验论文。Facebook团队如何扩展(scale up)系统,遇到了什么问题以及如何解决这些问题。跟他们学习权衡性能、一致性和实用性的。大部分论文主要讨论如何避免缓存数据过时,但我想说的是, 数据过时其实是为提升性能而付出的努力。
思考题
- 在 Facebook 的 Memcache 系统中,Section 3.3 暗示客户端在写入数据时不会从 Gutter 服务器删除相应的键,尽管客户端会尝试从普通的 Memcached 服务器删除这些键。解释一下为什么让写入客户端从 Gutter 服务器删除键会是个坏主意。
问题背景
社交软件Facebook
- 包含大量的用户、还有列表、状态、帖子、点赞和照片等数据
- 数据的实时性和一致性并非关键——用户可以承受
- 读操作占多数
- 数据的局部性很差
- 高负载:每秒数十亿次读取操作,远超单台存储服务器的处理能力。
- 比如Mysql每秒能处理十万次简单查询
- Memcached每秒处理约一百万次get/put请求
- 每个数据中心称为一个“region”。
- 真实数据在 MySQL 数据库上”逻辑分片“——磁盘空间大,但速度慢
- Memcached 层 (mc)——速度快,但内存有限
- Web 服务器(Memcached 和数据库的客户端)——“无状态”
- 每个数据中心都包含完整的数据副本。西海岸为主数据中心,其他数据中心是通过 MySQL 异步日志复制建立的副本
Memcached
memcached(MC)是什么?
Solution:
一个简单的K/V服务器,put(k, v)、get(k)、delete(k)。存储在内存中,不持久,无复制。存储客户端的指令,通常会部署许多memcached服务器,由客户端决定将数据存储在何处。
Facebook 如何使用 MC?
Solution:
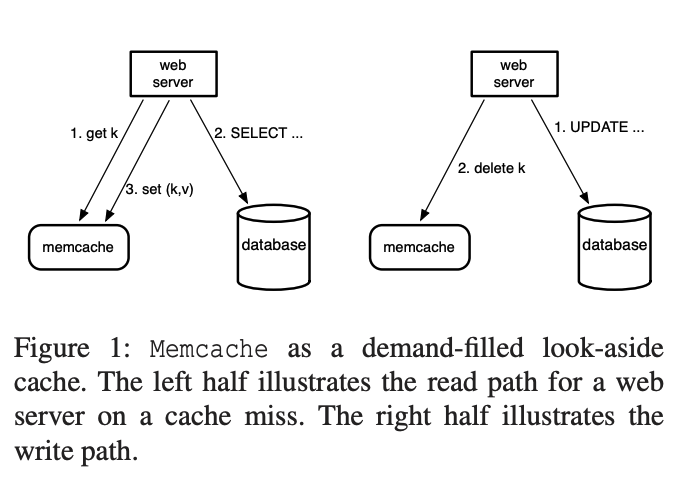
如图1所示,Facebook将 mc 作为旁路缓存(look-aside cache),实际数据存储在数据库中,应用单独与 Memcached 和数据库通信。Memcached并不知道DB的存在。
读操作
h = hash(k) % n # 哈希的值用于确定与哪个memcache 服务器通信
v = mc[h].get(k)
if v is NULL:
v = fetch from DB
put(k, v)写操作
write(k, v):
send k, v to DB
h = hash(k) % n
mc[h]delete(k)使用MC有什么好处?
Solution:提供缓存,而缓存的目标并非减少用户可见的延迟,而是保护数据库服务器避免严重过载。
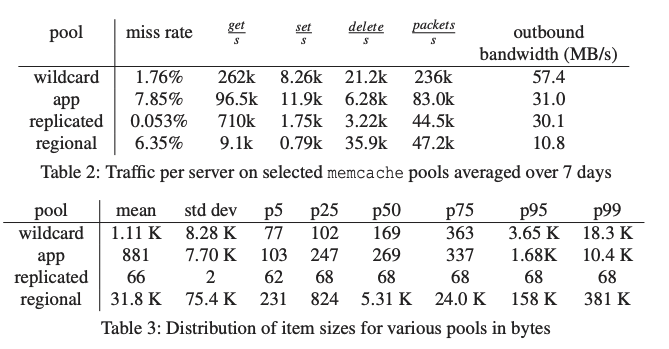
它只对读取操作有效,但这是目前占据了大多数操作, 高缓存命中率可以极大减轻DB的负载( 表2,说明 99% 的命中率,意味着数据库读负载减少了 100 倍)。这里引出了一个MC服务器的职责——负载均衡
负载均衡
为了解决总负载量大的问题,我们需要用到大量的mc服务器。主要问题有:
- CPU/网络并行度
- 总RAM,以及
- 如何在mc服务器之间分配负载
客户端的哈希函数决定了键如何分配到 Memcached 服务器,可以进行分片(partition)或复制(replication),或者两者的组合。所有 Web 服务器使用相同的 hash(k) 函数,因此若 C1 缓存了键 k,则 C2 也能访问该缓存项。中央配置管理器会告诉客户端如何进行哈希运算。
分片 或者 复制技术 能带来最高的吞吐量吗?
Solution:
分片的目的是将Key划分到各个mc服务器上,好处在于,内存效率高(每个K/V 只有一个副本);缺点在于,1,如果只有少量热点数据,则效率不高;2,每个Web服务器必须与多个mc服务器通信(数据包开销大)
复制的目的将客户端划分到各个mc服务器上,优点在于,1,如果少数键非常常用,则很有用;2,每个数据包可可以打包多个请求/响应(开销低)。缺点在于,1,占用更多内存,减少缓存项;2,写入开销更高
多区域性能
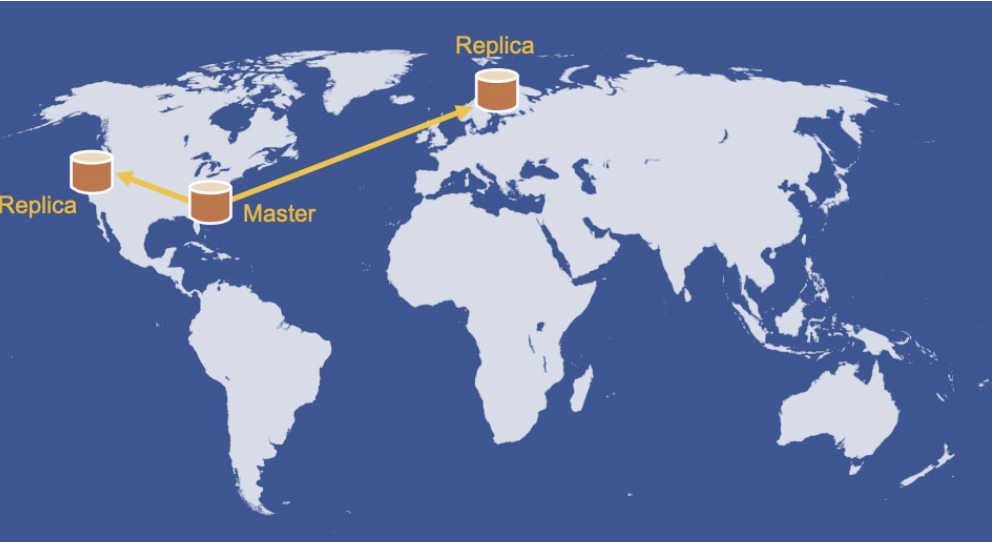
西海岸(West)数据中心,MySQL 数据库是主库(primary shards),存储“真实数据”。MySQL 数据库是从库(secondary shards),用于容灾和负载分担。
设置多个region的意义是什么?为什么要使用完整的副本(regions)?
Solution:
- 减少用户访问RTT: 东西海岸都能快速访问本地数据
- 快速本地读取:可以直接从本地的Memcached或数据库读取
- 当主节点发生故障时,有热备副本可用,确保数据的高可用性,减少停机时间
为什么不按用户分区来分布数据?
Solution: e.g 东海岸用户的数据放在东海岸 region,西海岸用户的数据放在西海岸 region,这样就不需要复制,硬件成本可能减半!原因:社交网络数据没有明显的地理局部性(用户朋友可能遍布全球)。这种按用户分区的方法可能适合电子邮件等应用。
尽管写操作都发送到主 region,为什么性能仍然可以?
Solution: 1)写操作比读操作要少得多;2)用户不需要等待写操作完成,即写操作可以一步操作。
区域内性能
在一个区域(region)内,有1个存储集群,多个前端集群。每个前端集群自成一体,包含自己的缓存服务器和服务这些缓存的 web 服务器。每个 web 服务器只对自己 cluster 的 mc 服务器做哈希分配,当 web 服务器要缓存某个 key 时,它只会在自己 cluster 的 mc 服务器里选择目标,而不会跨 cluster 去访问其他 cluster 的 mc 服务器。
为什么每个Region有多个集群?为什么不在单区域使用一个超大集群,将负载划分到并行的MC服务器上?
Solution:
1, 对于热点数据,多个MC服务器没有帮助,但是复制技术(每个集群复制一个)能够有帮助。
2, 一个集群中,MC服务器越多,分片就越细,每个Web视图就需要发送更多的数据包(到更多的MC服务器上),即不便于批处理。并且,会出现更多的 in-cast 拥塞,一个 web 页面可能要拉取 20~500 个Keys。客户端必须并行发请求,否则总延迟太高。 如果这些请求分散到很多台 memcached 机器,返回时可能几百个数据包同时涌向一个客户端,交换机/NIC 的 buffer 很容易被挤爆(叫做 in-cast congestion)
3,截面带宽(cross-section bandwidth)压力大。大集群,客户端和服务器分布在很多机架上,那么任意一对客户端-服务器之间都要能高速通信。
一个大集群 → 任意客户端可能访问任意服务器 → 网络必须能承载 “全量互连”。
两个集群 → 每个客户端只访问一半的服务器 → 网络压力直接减少一半。□
但是对于不太常用的数据,复制会浪费内存。
解决思路: 所有集群共享一个区域池(Region pool),将不常用的对象(无需多次复制)。由应用软件决定哪些键放入区域池,释放多集群服务器以复制更常用的对象。
过载问题
新集群加入
当新的集群加入时存在性能问题。 新集群的命中率为 0%。 因此,其客户端可能会导致数据库负载大幅飙升。因此,新集群的客户端首先从现有集群获取数据,然后将其放入新集群。这基本是现有集群惰性复制到新集群。
惊群效应
另外一个过载问题——惊群效应(thundering herd)。一个客户端更新数据库并删除了某个键。许多其他客户端在尝试读取(get())该键时都失败了,因为它已经被删除了。这些客户端接下来都会去数据库重新获取这个键,这就导致了数据库负载飙升。这是不必要的数据库负载。
解决方案: MC的租约机制。租约 = 从数据库中刷新的权限
缓存给第一个客户端“租约”:当多个客户端发现缓存中的键不存在时,缓存系统只允许第一个、客户端去读取数据库(lease)。这个租约是对第一个客户端的“许可”,允许它从数据库中刷新数据。
对其他客户端的处理:对于后续的客户端,缓存会告诉它们:“稍等几毫秒再重试get()操作”。
MC服务器故障
如果MC服务器发生故障怎么办?
- 无法让数据库服务器处理未命中——DB负载过重
- 无法将负载转移到另一个MC服务器——MC负载过重
解决方法:Gutter 池
预留一小部分空闲MC服务器池,不存常规数据。只有当某个 mc 服务器挂掉时,客户端才会把请求指向 Gutter 上。当挂掉的 mc server 被替换后,Gutter 服务器又空闲下来。
为什么不把 其他Web服务器造成的 invalidate(删除/更新操作)发送给 Gutter?
Solution:这样的话,1, 每个 key 的删除/更新操作要发两份;2, 对少数 Gutter 服务器造成沉重的负载。 Gutter 可以存任何 key。它不是普通分片,它是备用的缓存池,任何 key 在原服务器失败时都可能被写入。代价是 Gutter 上可能暂时存一些已经被删除的 key, 只要原 mc server 恢复,Gutter 会释放这些 key。
一致性
缓存一致性
假如他们想要线性化的缓存,则他们需要一个缓存一致性协议,就像是多个CPU一样。已经存在许多一致性的方案,但成本高昂。下面是其中一种,假如
【DB: x = 1; A Cache:x=1; B Cache: NULL】,以下是不同情形的处理:
- 读未命中: Cache 向DB请求 x 的值,缓存的数据总是来自数据库,而不是客户端通过
put()实现 - 写操作:
- 客户端将写操作发送到 主数据库。
- 数据库会将
x标记为 "锁定",以确保在写操作进行时,缓存无法读取到旧值。这是为了避免读取到陈旧的数据。 - 数据库通知所有的缓存节点 使其无效化(即删除缓存中存储的
x)。这是告诉缓存,"你持有的x数据已经不再有效"。 - 数据库会等待所有缓存确认数据已经无效化(这一步在论文中没有执行,可能会跳过)。
- 数据库更新
x的值为2。 - 更新完成后,数据库 解锁 该项数据,允许缓存重新读取最新的
x。 - 最后,数据库回复客户端,确认写操作已完成。
写操作的问题, 太慢了,写操作必须等待所有副本确认无效化,这个过程数据无法被读取。
要实现线性一致性的缓存,系统需要一个严格的缓存一致性协议来确保。
本文的一致性
本文在不同场景下的处理如下:
写操作:
- 写操作直接发送到主数据库,并使用事务来保证数据库的一致性。通例如 点赞 计数 + 1 时,操作会按照事务来进行,确保一致性。
读操作:
- 读取操作不保证看到最新的写入数据。这意味着不同的客户端可能看到不同的数据,尤其是当数据已经被更新但缓存尚未同步时。
- 但也不会太过时。一般情况下,数据会在几秒钟内同步到缓存,保证最终一致性(eventual consistency)和 read-your-own-writes
这是一种常见的模式。即更新是ACID的——而且很慢。 读取操作不太一致——但速度很快。
数据库副本如何跨区域保持同步?
Solution: 其中有一个Region是主区域,所有客户端仅向主区域的数据库服务器发送更新。主数据库将更新日志分发到辅助区域的数据库。备份数据库时完整的副本(而非缓存),数据库复制延迟可能相当大(数秒)
为什么客户端仅向主区域的数据库服务器发送更新? 为什么不向本地区域的数据库服务器发送更新?
Solution: 多主写入带来的复杂性和数据冲突风险,简化系统并保证写入顺序的一致性。
缓存与DB的一致性
数据库写入后, 如何处理现在过时的缓存数据?
Solution:
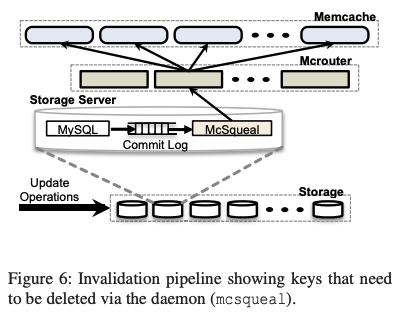
- 缓存失效: 每当数据库进行写操作时,数据库会向相关Region的缓存服务器发送失效消息(即删除操作),以确保客户端不会读取过时的数据。(McSqueal组件)
- 写入客户端也会Invalidate本地集群,确保read-your-write
备份DB听到更新后,也会发送Invalidates。
NOTE
McRouter 的核心目的是聚合来自众多客户端的 memcached RPC 请求,并将它们批量发送到 memcached 服务器。与让大量独立客户端直接与 memcached 通信相比,使用少量 McRouter 服务器与 memcached 对话效率更高。原因之一是每个网络(TCP)连接都有开销;让每个 memcached 服务器与每个 McRouter 建立一个 TCP 连接,远比与每个客户端建立连接要好。另一个原因是每个数据包都有开销(数据包头空间和中断处理),因此 McRouter 能够将多个客户端请求打包到一个 TCP 数据包中是非常有帮助的。
竞态的例子:
加入客户端的写入操作如下;
def write(k, v):
send k, v to DB
put(k, v) in mc # 而不是 delete如果两个客户端同一时刻对同一个key值写入会怎么样?可能发送数据库的更新顺序与MC的更新顺序不一样,导致永久缓存失效,因此需要 delete(k)
再细化一下并发更新的问题——多个客户端同时尝试更新同一个键(key)这可能导致数据库和缓存之间的数据不一致。如下所示(对应论文3.2.1节)
k not in cache
C1 get(k), misses
C1 v1 = read k from DB
C2 writes k = v2 in DB
C2 delete(k)
C1 put(k, v1)此时MC有过期数据,永远保持保持过时,直到k的下次写入。
解决方法: 租约。
- MC给予客户端C1针对键K MISS的租约——写入K的权限
- 客户端C2 删除K,无效化C1的租约
- 因此MC会忽略C1的put(k)的请求
- 键仍然在missing状态,写一次reader会从DB获取并更新它
一致性问题难道不是客户端将DB数据复制到多副本mc造成的吗?
为什么不让客户端将新值发送到多副本mc呢,这样客户端就只能直接读取到mc了?
Solution: 这个方案通常被称为 “Write-Through”缓存 或 “Write-Back”缓存(如果DB异步推数据)。它的核心思想是:让数据库成为缓存数据的唯一写入者。现实障碍:
- 数据库通常不知道如何计算mc的值哈希值,通常客户端应用代码会根据数据库结果计算这些值
- 数据库不知道MC缓存了什么,最终会发送大量未缓存的K/V,而MC只会简单丢弃,因为键不存在。
- 违背了缓存热点数据的初衷。
存储系统设计者经验
- 分离缓存和持久化存储,可以让我们独立地扩展它们
- 管理有状态组件 比无状态组件的运营要复杂。因此,将逻辑保持在无状态客户端有助于功能迭代,并最小化系统干扰
- 缓存对于应对高负载至关重要,而不仅仅是为了降低延迟, 需要灵活的工具来控制数据分片与数据复制。
- 线性一致性的要求往往过高;而最终一致性又常常不够
FQA
自本文发表以来,Facebook 开展了哪些存储系统方面的工作?
答:以下是示例:
https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf
https://www.cs.princeton.edu/~wlloyd/papers/existential-sosp15.pdf
http://www.cs.cmu.edu/~beckmann/publications/papers/2020.osdi.cachelib.pdf
https://www.usenix.org/system/files/fast21-pan.pdf问:MySQL 复制系统是如何工作的?
答:请参阅 https://dev.mysql.com/doc/refman/8.0/en/replication.html。FB 使用基于日志的复制方案作为发布/订阅系统的一个组件,正如 Sharma 等人在 2015 年发表的“Wormhole:可靠的发布/订阅以支持地理复制互联网服务”一文中所述。复制方案的核心是从 MySQL 的事务日志中读取更新,并将其发送到备份服务器,备份服务器将其应用于其数据。