Lec 2 RPC & 线程
为什么用 Go:线程支持好 + RPC 方便 + 类型/内存安全 + GC(消除 use-after-free)+ 业界广用。
课件精讲:线程与 RPC 的要点
n=n+1 丢更新)→ 用 sync.Mutex 锁临界区,或干脆不共享可变数据;用 -race 检测。② 协调(生产者/消费者要等待与唤醒)→ channel / sync.Cond / sync.WaitGroup。③ 死锁(互相等待成环,锁/channel/RPC 都可能造成)。口诀:channel = "通信"思维,lock = "状态"思维,多数问题两者皆可解。爬虫例子:ConcurrentMutex 用共享
fetched map + 锁做 test-and-set;ConcurrentChannel 不共享 map、用 channel 同时做通信与同步。- at-least-once(至少一次):超时就重发——可能重复执行,只适合只读或幂等操作(
Put("k",10);Put("k",20)这种非幂等会出错)。 - at-most-once(至多一次):Go RPC 默认(单 TCP 连接、不重发、超时即报错),服务器不会见到重复请求;但对复制系统太受限(不能换个副本重试)。
- exactly-once(恰好一次):最难,需在 at-most-once 之上加去重等机制——后面实验里实现。
Args/Reply 结构体字段须大写(导出)才能编码;服务器每个请求开一个 goroutine,故 handler 内要加锁;不能编码 channel/函数。FAQ(Go tour 答疑整理)
- 为什么 6.5840 用 Go? GC、类型安全、goroutine、内置 RPC 包都比从前的 C++ 更适合分布式实验。
- goroutine 真并行吗? 是,运行时把 goroutine 铺到所有核上并行;多于核数时分时。
- channel 怎么保持同步? 内部用锁+缓冲;发送方拿锁、等接收方、再交接消息。
- 不阻塞地唤醒 goroutine? 当不确定有没有接收方时,用
sync.Cond(条件变量)而非 channel。 - 同时从多个 channel 收? 每个 channel 一个 goroutine,或用
select。 WaitGroupvs channel? 等任务完成用 WaitGroup;要更通用的通信用 channel。- 每秒执行一次? 专门一个 goroutine 循环 +
time.Sleep()。 - goroutine 开多少合适? 实验性加直到吞吐不再涨;CPU 密集大致匹配核数。
- channel 能跨网络吗? 不能,只在单进程内;跨进程用 RPC 包。
- slice 怎么实现? 指向底层数组的指针 + 起止下标,多个 slice 可共享底层数组。
- Go 调试工具?
fmt.Printf最有效;gdb 对 Go 支持弱。 - 初学者常见坑? map 并发未加锁访问、channel 死锁、循环变量未捕获、goroutine 泄漏。
- Go 有继承吗? 没有 C++ 式继承;用泛型、接口、结构体嵌入。
- main 结束后 goroutine? 随 main 一起终止(语言规范明确)。
- 值接收者 vs 指针接收者? 要改接收者状态或避免拷贝大结构用指针;含 mutex 的类型避免值接收者(拷贝锁有害)。
远程过程调用
远程过程调用(RPC)是分布式系统中的一个关键组件,采用C/S模型通信,隐藏网络协议的细节,让开发者可以像调用本地函数一样调用远程函数,从而简化分布式系统的开发过程。
RPC 的工作原理是将数据(如字符串、数组、映射等)转换为一种称为"wire format"(即网络传输格式)的格式,然后在网络上传输。这样做的好处是,开发者不需要了解底层网络协议的细节,只需要调用远程函数并传递参数即可。
另外,RPC 还具有可移植性和互操作性的优点。由于 RPC 隐藏了底层的网络细节,因此可以轻松地在不同的平台和编程语言之间进行通信,从而提高了系统的可移植性和互操作性
软件架构
客户端 服务端
客户端app 服务器处理函数 handler fns
存根函数(stub fns) 调度器(dispatcher)
RPC库 RPC库
网络 -------------- 网络Go RPC示例——KV服务器
基于Golang提供的RPC库,我们实现K/V存储服务器——Put(k, v)和Get(k)->v,见附录(KV服务器)
公共模式:
- 为每个服务器hander函数声明Args和Reply结构体
客户端:
- connect()中使用Dial()创建与服务器的TCP连接
- get()和put()是客户端的"存根"函数
- Call()请求RPC库执行指定的调用,需要提供:连接、函数名、参数和存放回复的位置
- 库负责序列化参数、发送请求、等待响应、反序列化回复
- Call()的返回值表明是否收到回复
- 通常还有reply.Err表示服务层面的失败
服务器:
- Go要求服务器声明一个带有方法的对象作为RPC处理程序
- 服务器将该对象注册到RPC库
- 服务器接受TCP连接,将它们提供给RPC库
- RPC库处理流程:
- 读取每个请求
- 为请求创建新的goroutine
- 反序列化请求
- 查找注册表中的命名对象
- 调用对象的命名方法(dispatch)
- 序列化回复
- 将回复写入TCP连接
服务器的Get()和Put()处理程序:
- 必须加锁,因为RPC库为每个请求创建新的goroutine
- 读取参数,修改回复
挑战
RPC在分布式系统中面临着与本地过程调用截然不同的挑战。首先,它通过复制指针指向的数据来传递指针,但不支持传递通道和函数类型,且只序列化以大写字母开头的导出字段。
然而,RPC最大的挑战在于故障处理。网络环境中的丢包、连接中断、服务器响应延迟或崩溃都会导致调用失败。当客户端未收到服务器响应时,它无法确定服务器是否已接收并处理了请求。这种不确定性是RPC与本地调用的根本区别:请求可能完全未到达服务器,也可能服务器已执行操作但在发送响应前发生故障,甚至可能响应在网络传输过程中丢失。
最基本的故障处理策略是"尽力而为RPC",即Call()函数等待响应一段时间,若无响应则重发请求,重试数次后放弃并返回错误。然而,这种机制会导致非确定性行为。例如,客户端执行两次Put("k", 10)和Put("k", 20)操作,若因超时和重发导致请求顺序颠倒,Get("k")的结果将难以预测。因此,"尽力而为"策略仅适用于只读操作或重复执行无害的情境。
更严格的语义如"至多一次"则提供了更强的保证。Go的RPC实现了一种简单的"至多一次"语义:它建立TCP连接后,只发送一次请求,从不重试,若无响应则返回错误。这确保了服务器不会处理重复请求,但在分布式环境中仍显得过于受限,特别是需要在多副本间进行容错重试的场景。
线程
线程是一种有用的结构化工具,但可能会有一些棘手的问题。在Go语言中,它们被称为goroutines;而在其他语言中,通常称为线程。一个进程内的线程共享内存空间, 但是每个线程包含了各自的线程状态: PC、寄存器、栈空间等
为什么要使用线程呢?
Solution: 主要有以下几个原因:
I/O并发:线程使得程序可以在进行I/O操作时同时执行其他任务。例如,客户端可以并行发送请求给多个服务器,并等待它们的响应;服务器可以同时处理多个客户端请求,即使某些请求被阻塞在I/O操作上。
多核性能:利用多核处理器的并行执行能力,线程可以加速程序的执行。通过在多个CPU核心上同时执行代码,可以提高程序的性能。
便利性:线程提供了一种方便的机制,用于管理并发任务和异步操作。例如,可以在后台周期性地检查工作者线程的状态,以确保它们仍然处于活动状态。
有没有替代线程的方法?
Solution: 有的。称为“事件驱动”编程模型,活动显式地交替执行,运行在单线程上。 通过维护一个关于每个活动的状态的表,例如每个客户端请求。一个“事件”循环: 检查每个活动的新输入(例如服务器的响应到达), 执行每个活动的下一步, 更新状态。 事件驱动可以实现I/O并发, 并消除线程的成本, 但无法获得多核加速, 而且编程起来比较繁琐。
使用线程面临哪些挑战?
Solution:
- 数据安全共享。当多个线程同时修改共享变量(如
n = n + 1),或一个线程读取数据而另一个线程修改数据时,就会发生竞态条件(race condition)。解决方法包括使用锁(sync.Mutex)或避免共享可变数据。 - 线程间协调。主要出现在生产者-消费者模型中,消费者如何高效等待数据、生产者如何通知消费者,可通过Go通道、sync.Cond或sync.WaitGroup解决。
- 死锁。主要发生在线程形成循环等待、如锁、通道或RPC相互依赖,导致程序无法继续运行。
线程示例——网络爬虫
Web爬虫是一种用于获取网页的工具,其目标是递归地抓取所有网页以提供给索引器。爬虫从一个起始页面开始,沿着页面中的链接不断探索,形成一个有向图结构。在这个过程中,爬虫面临两个核心挑战:一是避免重复抓取同一页面,二是防止陷入链接循环。
爬虫的主要挑战在于有效利用I/O并发性。由于网络延迟(约0.1秒)比网络容量更为限制性,并行抓取多个页面可以显著提高URL获取速率。此外,爬虫需要记住已访问的URL,以避免浪费网络带宽、防止陷入链接循环,并对远程服务器保持友好。最后,爬虫还需要明确何时完成任务。
针对这些挑战,可以采用三种解决方案:串行爬虫、基于共享数据的并发爬虫和基于通道的并发爬虫。
- 串行爬虫通过递归调用实现深度优先探索,使用"fetched"映射避免重复和打破循环。虽然这种方法在所有链接探索完成时自然终止,但一次只能抓取一个页面,效率较低。
- 基于互斥锁的并发爬虫为每个页面抓取创建一个线程,实现多个并发抓取以提高获取率。线程间共享fetched映射,确保每个页面只被一个线程抓取。互斥锁(Lock()和Unlock())在testAndSet()中的应用解决了两个问题:一是防止多线程同时确认并抓取同一URL;二是保护映射的内部数据结构不受并发更新/读取的破坏。此爬虫使用sync.WaitGroup计数器来跟踪所有子线程的完成情况,从而确定任务完成。
- 基于通道的并发爬虫使用Go的通道进行线程间通信和同步。通道允许一个线程向另一个线程发送对象,发送者会等待直到某个goroutine接收数据。在这种实现中,coordinator()为每个页面创建工作goroutine,worker()则通过通道发送页面的URL切片。通道在这里提供了两个功能:传递值和通知事件(如线程终止)。由于fetched映射不再共享,因此无需锁定。coordinator通过跟踪工作线程的数量来确定任务完成。
推荐对状态使用共享+锁的方式,而对等待/通知则可以使用sync.Cond、通道或time.Sleep()。选择哪种风格主要取决于程序员的思维方式:对于状态思维,适合使用共享和锁;对于通信思维,适合使用通道。
调试
调试分布式系统是一项困难的任务,可以通过利用好的日志实践和命令行工具,简化分布式日志的解析,降低简化调试难度。举个例子,Raft实验有N个Raft对端并行执行,并且在独立的机器上。
Go端的实现说明
动态日志级别控制
为了方便在不修改Go代码的情况下调整日志的详细程度(后续也便于自动化脚本控制),我们可以通过环境变量VERBOSE实现动态配置。
基于主题的日志分类
我将常用的printf函数改造为 首参数接收日志主题,标志消息的类别。主题使用常量而非字符串,精细化的主题分类便于后续过滤、搜索和按颜色高亮。
type logTopic string
const (
dClient logTopic = "CLNT" // 客户端相关
dCommit logTopic = "CMIT" // 提交日志
dError logTopic = "ERRO" // 错误
dLeader logTopic = "LEAD" // 领导者事件
dTimer logTopic = "TIMR" // 定时器
)日志输出函数
最终的日志函数Debug会输出以下信息:
- 时间戳: 程序启动后毫秒数(移除冗余的日期/时间,简化调试)
- 主题标志:如
LEAD表示领导者变更 - 服务器ID:通过格式化字符串嵌入(例如
S1表示服务器1) - 自由文本:具体日志内容
var debugStart time.Time
var debugVerbosity int
func init() {
debugVerbosity = getVerbosity()
debugStart = time.Now()
log.SetFlags(log.Flags() &^ (log.Ldate | log.Ltime)) //禁用日期和时间
}
func Debug(topic logTopic, format string, a ...interface{}) {
if debugVerbosity >= 1 {
time := time.Since(debugStart).Microseconds() / 100 // 转换为0.1毫秒单位
prefix := fmt.Sprintf("%06d %v ", time, string(topic))
log.Printf(prefix + format, a...)
}
}
// 日志示例
Debug(dTimer, "S%d Leader, checking heartbeats", rf.me)
// 输出格式
// 008262 TIMR S1 Leader, checking heartbeats优势
- 可扩展性:通过环境变量控制日志级别, 无需宠你想你编译代码
- 主题分类和服务器标识为后续自动化分析
- 毫秒级时间戳更适合高频事件(如心跳检测)的调试
美化日志输出
目前的日志虽然功能完整,但在排查数百行代码中的隐蔽错误时,阅读体验仍显吃力。我们将用 Python 编写一个日志解析器,实现过滤和美观打印功能。Go在快速脚本编写上不如python灵活,我们选择python的主要原因是Rich 和 Typer两个库——他们能轻松构建终端用户界面TUI
人类对视觉信息更敏感,因此利用颜色、分栏等元素区分日志类型可以显著提升调试效率。但直接在终端实现美观打印往往代码杂乱,而 Rich 库完美解决了这一问题。它提供直观的 API 来处理彩色输出和多列排版
rich.print("[red]这是红色文字[/red]") # 输出红色文本相比 Bash 中晦涩的 ANSI 转义码 echo -e "\033[91m这是红色\e[0m",Rich 的语法清晰得多。以下是关键实现
# 颜色映射
TOPICS = {
"TIMR": "bright_black", # 定时器
"VOTE": "bright_cyan", # 投票
"LEAD": "yellow", # 领导者变更
"ERRO": "red", # 错误
# ... 其他主题
}
# 动态过滤与分栏
## 支持从文件或管道读取输入
input_ = file if file else sys.stdin
## 按主题过滤(包含/排除)
if just: topics = just
if ignore: topics = [t for t in topics if t not in ignore]
## 彩色打印(自动跳过不符合格式的日志行)
if colorize and topic in TOPICS:
msg = f"[{TOPICS[topic]}]{msg}[/{TOPICS[topic]}]"
## 单列模式(测试日志)
if n_columns is None:
print(time, msg)
## 多列模式(按服务器ID分栏)
else:
cols = [""] * n_columns
cols[server_id] = msg
print(Columns(cols, width=console.width // n_columns))
# 异常处理
except:
if line.startswith("panic"): # 捕获 panic 输出
print("-" * console.width)
print(line, end="") # 原始格式输出测试信息
# 使用示例
## 基础用法:直接管道传输 Go 测试日志
VERBOSE=1 go test -run InitialElection | dslogs
## 高级过滤:忽略定时器日志,按5列分栏显示
VERBOSE=1 go test -run Backup | dslogs -c 5 -i TIMR,DROP,LOG2
## 离线分析:先保存日志文件,再筛选提交和持久化事件
VERBOSE=1 go test -run Figure8Unreliable > output.log
dslogs output.log -j CMIT,PERS
美化日志输出结果
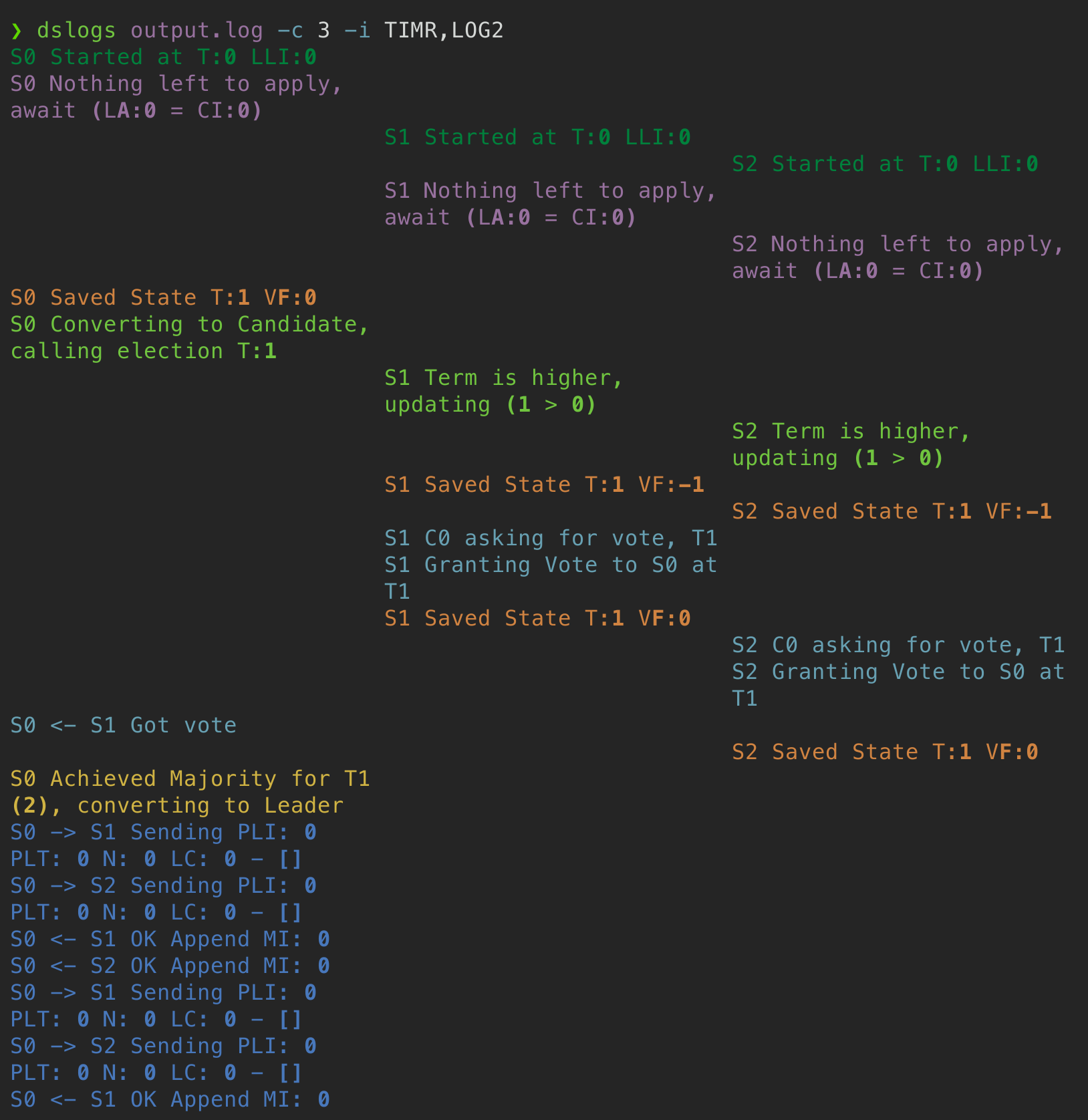
LEC 6: DebuggingPreparation: Read Debugging by Pretty Printing (Question)
捕获罕见的故障
我们现在有了强大的日志分析工具,但失败的测试日志往往难以获取。尤其是随着分布式系统实现的逐步完善,某些 Bug 可能会变得极其罕见——比如某个测试平均每 50 到 100 次运行才失败一次。
理想情况下,我们需要一个能实现以下目标的脚本:
- 批量执行:自动运行 N 轮测试
- 保存故障:保留失败测试的日志
- 并行执行:加速测试过程并提高并发冲突概率
串行测试(bash实现)
#!/usr/bin/env bash
trap 'exit 1' INT # 允许 Ctrl+C 退出
echo "Running test $1 for $2 iters"
for i in $(seq 1 $2); do
echo -ne "\r$i / $2" # 进度显示
LOG="$1_$i.txt"
go test -run $1 &> $LOG
if [[ $? -eq 0 ]]; then # 成功则删除日志
rm $LOG
else
echo "Failed at iter $i, saving log at $LOG"
fi
done只能完全前两个任务串行;串行执行效率低;无法模拟高并发场景(可能掩盖竞态条件问题)
并行测试(Python 实现)
通过 Python 的 concurrent.futures 模块实现并行化,核心逻辑如下
def run_test(test: str, race: bool):
# 构造测试命令(支持 -race 检测)
test_cmd = ["go", "test", f"-run={test}"]
if race: test_cmd.append("-race")
# 创建临时文件存储日志
f, path = tempfile.mkstemp()
start = time.time()
proc = subprocess.run(test_cmd, stdout=f, stderr=f)
runtime = time.time() - start
os.close(f)
return test, path, proc.returncode, runtime
# 使用线程池并行执行
with ThreadPoolExecutor(max_workers=workers) as executor:
futures = []
while completed < total:
# 动态分配任务
if len(futures) < workers:
for test in itertools.islice(tests, workers-len(futures)):
futures.append(executor.submit(run_test, test, race))
# 等待任意任务完成
done, not_done = wait(futures, return_when=FIRST_COMPLETED)
for future in done:
test, path, rc, runtime = future.result()
if rc != 0: # 失败时保存日志
dest = (output / f"{test}_{completed}.log").as_posix()
shutil.copy(path, dest)
print(f"Failed test {test} - {dest}")
os.remove(path)
completed += 1
futures = list(not_done)效果展示
[=== ] 45% TestSnapshotBasic (3 failures)
[===== ] 68% TestFigure8Unreliable (1 failure)统计报告
╭───────────────┬─────────┬────────────╮
│ Test Name │ Failed │ Avg Time │
├───────────────┼─────────┼────────────┤
│ TestSnapshot │ 12 │ 1.23s │
│ TestFigure8 │ 1 │ 4.56s │
╰───────────────┴─────────┴────────────╯- 加速复现:通过
-workers提高并发数(如dstest -w 8) - 竞态检测:添加
-race标志(dstest --race) - 日志分析:结合之前的
dslogs工具美化失败日志
关于真彩(Truecolor)支持的说明
日志解析脚本需要色彩支持,默认的大多数情况下, 终端支持8-bit色彩,即总共256种颜色,然而,大多数UI支持每个通道8bit,即支持24-bit的色彩。truecolor显示需要整个工具链协同支持,包括:
- 终端模拟器(iTerm、Windows Terminal等),多书现代终端支持truecolor,但是优势需要将
TERM的环境变量指定为xterm-256color - 远程客户端,ssh通常能处理truecolr,但是使用PuTTY等工具需要单独验证
- 编辑器支持,如果您的vim/neovim仅显示256色,可能需要单独启用真彩模式
FQA
Q1: goroutine是并行执行吗?
S1: Go 的 goroutines 与其他语言中的线程相同。Go 运行时在所有可用内核上并行执行 goroutine。如果内核数少于可运行的 goroutine,则运行时将在 goroutine 之间抢占时间片。 □
Golang的channel如何工作的? Golang如何保证在众多goroutines之间实现同步?从高层次看,chan是一个包含一个buffer和一个锁的数据结构。发送时需要获取锁,waiting到一些线程交接到数据以后。接受时需要获取锁,并waiting到有发送方发送数据。你也可以实现用sync.Mutex和sync.Cond实现自己的channel □
我通过向用一个channel发送一个bool数据唤醒另外一个goroutine。但如何另外一个goroutine正在运行(因此没有从该通道获取到数据),然后发送goroutine被阻塞了,那该怎么办?
Solution: 应该尝试用条件变量,而不是通道。条件变量很适合用来通知可能在等待某事的 goroutine。通道因为是同步的,所以如果你不确定通道的另一端是否会有 goroutine 在等待,它们就会显得有些尴尬。 有时候你需要的可能只是一个引用计数,golang提供了sync或者sync/atomic包,里面提供了锁、条件变量等等,它们提供了处理这些小问题等工具。goroutine或者channel对于复杂的操作比如,多输入、多输出、超时、失败等等比较复杂的操作进行简化□
要如何让一个 goroutine 在多个不同的通道中等待输入?如果没有可读取的数据, 尝试在任何一个通道上接收数据会导致阻塞,这会阻止 goroutine 检查其他通道。
尝试为每个通道创建一个单独的 goroutine,并让每个 goroutine 在其通道上阻塞。这并不总是可行的,但当可行时,这通常是最简单的方法。否则,可以尝试使用 Go 语言的 select 语句□
什么情况下我应该用sync.WaitGroup而不是通道?反之呢?
Solution: WaitGroup 是相当特殊用途的;只有在等待一堆活动完成时才有用。通道更通用一些;例如,你可以通过通道进行值的通信。你可以使用通道等待多个 goroutine 的完成,尽管相比于 WaitGroup,需要多写几行代码。□
有哪些重要/有用的 Go 特定并发模式值得了解?
Solution: 这里有一个来自 Go 专家的关于这个主题的幻灯片 □
□
defer的设计初衷?
Solution: Defer是Go中的新功能。最初我们添加它是为了提供一种从panic中恢复的方式(参见规范中的"recover"),但事实证明它也非常适用于像"defer mu.Unlock()"这样的惯用法□
为什么类型放在变量声明后面,而不像C语言那样?
这里挑出来简单说,就是
x: int
p: pointer to int
a: array[3] of int
x int
p *int
a [3]int
// f 返回一个函数
f func(func(int,int) int, int) func(int, int) int这种声明方式很清晰,你只需要从左往右,优点类似上面的那种表达方式。当类型变得更加复杂时,它仍然能够很好地工作。
为了保持熟悉性,Go语言的指针采用了C语言的*符号,但我们无法让指针类型也采用类似的反向方式。因此指针的工作方式如下:
var p *int
x = *p
// 而不能是
var p *int
x = p* // 因为后置的*会与乘法运算符混淆。为什么Go语言拒绝编译带有未使用变量或导入的程序,以及如何在开发过程中处理这种情况?
Solution: 通过unused包解决,示例如下
import "unused"
// 通过引用包中的项目来使用此声明标记导入为已使用。
var _ = unused.Item // 在提交前删除!
func main() {
debugData := debug.Profile()
_ = debugData // 仅在调试时使用。
....
}□
Go函数传值还是指针?
Solution: 对于大多数类型(如数字、结构体),Go 会传递值的副本,这意味着调用者看不到被调用函数所做的任何修改。字符串因为其内容无法修改,所以实际上是按值传递的。然而,一些内置类型,如通道(channels)、映射(maps)和切片(slices),在更新数据结构时会被调用者和被调用者都看到,因此在某种意义上可以看作是按引用传递的。
当调用一个带有指针接收器的方法时,会通过引用传递对象,即使在调用中没有使用 & 符号,这种不一致性可能会引起困惑。例如,如果想将 sync.WaitGroup 传递给一个函数,可能需要使用 &wg 传递指针,而传递通道(channel)时则不需要使用 &。□
附录
网络爬虫
package main
import (
"fmt"
"sync"
)
//
// Several solutions to the crawler exercise from the Go tutorial
// https://tour.golang.org/concurrency/10
//
//
// 串行爬虫
//
func Serial(url string, fetcher Fetcher, fetched map[string]bool) {
if fetched[url] {
return
}
fetched[url] = true
urls, err := fetcher.Fetch(url)
if err != nil {
return
}
for _, u := range urls {
Serial(u, fetcher, fetched)
}
return
}
//
// Concurrent crawler with shared state and Mutex
//
type fetchState struct {
mu sync.Mutex
fetched map[string]bool
}
func (fs *fetchState) testAndSet(url string) bool {
fs.mu.Lock()
defer fs.mu.Unlock()
r := fs.fetched[url]
fs.fetched[url] = true
return r
}
func ConcurrentMutex(url string, fetcher Fetcher, fs *fetchState) {
if fs.testAndSet(url) {
return
}
urls, err := fetcher.Fetch(url)
if err != nil {
return
}
var done sync.WaitGroup
for _, u := range urls {
done.Add(1)
go func(u string) {
ConcurrentMutex(u, fetcher, fs)
done.Done()
}(u)
}
done.Wait()
return
}
func makeState() *fetchState {
return &fetchState{fetched: make(map[string]bool)}
}
//
// Concurrent crawler with channels
//
func worker(url string, ch chan []string, fetcher Fetcher) {
urls, err := fetcher.Fetch(url)
if err != nil {
ch <- []string{}
} else {
ch <- urls
}
}
func coordinator(ch chan []string, fetcher Fetcher) {
n := 1
fetched := make(map[string]bool)
for urls := range ch {
for _, u := range urls {
if fetched[u] == false {
fetched[u] = true
n += 1
go worker(u, ch, fetcher)
}
}
n -= 1
if n == 0 {
break
}
}
}
func ConcurrentChannel(url string, fetcher Fetcher) {
ch := make(chan []string)
go func() {
ch <- []string{url}
}()
coordinator(ch, fetcher)
}
//
// main
//
func main() {
fmt.Printf("=== Serial===\n")
Serial("http://golang.org/", fetcher, make(map[string]bool))
fmt.Printf("=== ConcurrentMutex ===\n")
ConcurrentMutex("http://golang.org/", fetcher, makeState())
fmt.Printf("=== ConcurrentChannel ===\n")
ConcurrentChannel("http://golang.org/", fetcher)
}
//
// Fetcher
//
type Fetcher interface {
// Fetch returns a slice of URLs found on the page.
Fetch(url string) (urls []string, err error)
}
// fakeFetcher is Fetcher that returns canned results.
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) ([]string, error) {
if res, ok := f[url]; ok {
fmt.Printf("found: %s\n", url)
return res.urls, nil
}
fmt.Printf("missing: %s\n", url)
return nil, fmt.Errorf("not found: %s", url)
}
// fetcher is a populated fakeFetcher.
var fetcher = fakeFetcher{
"http://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"http://golang.org/pkg/",
"http://golang.org/cmd/",
},
},
"http://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"http://golang.org/",
"http://golang.org/cmd/",
"http://golang.org/pkg/fmt/",
"http://golang.org/pkg/os/",
},
},
"http://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"http://golang.org/",
"http://golang.org/pkg/",
},
},
"http://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"http://golang.org/",
"http://golang.org/pkg/",
},
},
}KV服务器
package main
import (
"fmt"
"log"
"net"
"net/rpc"
"sync"
)
//
// Common RPC request/reply definitions
//
type PutArgs struct {
Key string
Value string
}
type PutReply struct {
}
type GetArgs struct {
Key string
}
type GetReply struct {
Value string
}
//
// Client
//
func connect() *rpc.Client {
client, err := rpc.Dial("tcp", ":1234")
if err != nil {
log.Fatal("dialing:", err)
}
return client
}
func get(key string) string {
client := connect()
args := GetArgs{ key }
reply := GetReply{}
err := client.Call("KV.Get", &args, &reply)
if err != nil {
log.Fatal("error:", err)
}
client.Close()
return reply.Value
}
func put(key string, val string) {
client := connect()
args := PutArgs{ key, val }
reply := PutReply{}
err := client.Call("KV.Put", &args, &reply)
if err != nil {
log.Fatal("error:", err)
}
client.Close()
}
//
// Server
//
type KV struct {
mu sync.Mutex
data map[string]string
}
func server() {
kv := &KV{data: map[string]string{}}
rpcs := rpc.NewServer()
rpcs.Register(kv)
l, e := net.Listen("tcp", ":1234")
if e != nil {
log.Fatal("listen error:", e)
}
go func() {
for {
conn, err := l.Accept()
if err == nil {
go rpcs.ServeConn(conn)
} else {
break
}
}
l.Close()
}()
}
func (kv *KV) Get(args *GetArgs, reply *GetReply) error {
kv.mu.Lock()
defer kv.mu.Unlock()
reply.Value = kv.data[args.Key]
return nil
}
func (kv *KV) Put(args *PutArgs, reply *PutReply) error {
kv.mu.Lock()
defer kv.mu.Unlock()
kv.data[args.Key] = args.Value
return nil
}
//
// main
//
func main() {
server()
put("subject", "6.5840")
fmt.Printf("Put(subject, 6.5840) done\n")
fmt.Printf("get(subject) -> %s\n", get("subject"))
}