Lec 10 分布式事务
[toc]
阅读参考
《Principles of Computer design》 §9.1.5、 §9.1.6、 §9.5.2 、§9.5.3 、§9.6.4,其中两阶段锁(2PL)和两阶段提交(2PC)是最主要的。
本节主题是, 分布式事务。 简单来说, 分布式事务 = 并发控制 + 原子提交。
到目前为止,课程主要关注点在容错型的分布式系统,即多个服务器协作以呈现一个可靠的服务。但如今我们转向了性能导向的分布式系统:将数据分片(shared)分布在多个服务器上以实现并行性。这种设计在客户端每次只访问一个数据项时运作良好,但若一次操作涉及多个分片(如银行转账、社交图中的双向链接建立,或记录插入与索引更新),就必须应对失败处理与原子性问题。 涉及到原子性地更新多条记录的操作,黄金标准就是使用事务,往往是数据库提供,通常是两阶段锁(2PL) + Logging实现。 当事务内涉及的记录存储在不同的位置(比如在分片存储系统),就需要用到分布式事务,通常需要添加两阶段提交(2PC)协议,这个思想、协议确实很有效。后面将继续遇到(Spanner和FaRM)。Spanner 分布式数据库领域的标杆,是Google Cloud基础设施的核心之一,它树立了现代云数据库的方向。FaRM是乐观并发控制(OCC)的系统。
思考题:
在什么情况下,两阶段锁比简单锁具备更高性能?
我们的网络在可能出现消息重排序的情况下, 我们如何处理?
两阶段提交(2PC)协议 是什么? 解决了什么问题? 如何工作?需要的成本多大?
2PC协议中,正常流程是怎么样,即没有丢失或失败?
- 协调者向机器发送哪些消息?向客户端发送哪些消息?
- 什么是提交点(commit point)?
为什么这个协议有两个阶段而不是一个?
2PC存在哪些性能问题?是什么原因导致这些问题?
2PC能用Raft替代吗?
- Solution:2PC产生的结果是,不同的计算机做了 不同 的事,并且他们 全 都在做自己事,或者谁都没有做。2PC 在有人没到达目标的情况下,系统是无法访问的,因为他们必须等待所有人都完成各自的事务的那一部分任务; 而Raft产生的是大部分人都做了 同样的事,对于Raft,只要求 大部分 参与者(副本)做完自己事,因此我们再面临失败时,可以让系统保持可用性。
2PC 和 2PL 有什么区别?
- Solution: 两个除了有两个阶段相同外, 其他毫无相关。2PC是这样的模式,在多个机器上执行一个事务,保证了每个机器做了属于他的事务一部分; 2PL是事务中获取锁模式,获取锁的目的是访问记录,保证在不同事务使用同一个记录时,不会干扰到彼此。在分布式和非分布式场景都适用。
Outline
- 问题背景
- 两阶段锁
- 两阶段提交
- 分布式事务
- 当下 & 趋势
1. 问题背景
数据库中早已存在一个经典问题,银行转账。
假设有两个银行账户x 和 y,每个账户初始余额为 $10,存在以下两个事务:T1:从 x 转账 $1 到 y; T2:审计,计算银行的总金额。传统的解决方案是事务,其核心思想是由程序员标记事务的开始和结束,而系统自动确保事务具备良好的行为。END-X 表示事务想要提交。但可能会成功,也可能失败,取决于系统的调度和故障情况。
T1: T2:
BEGIN-X BEGIN-X
add(x, 1) tmp1 = get(x)
add(y, -1) tmp2 = get(y)
END-X print tmp1, tmp2
END-X对于具备良好的行事务(正确的),通常由ACID 四个特性定义:
- Atomic原子性 —— 全写或全无,即便发生故障
- Consistent 一致性 —— 遵循应用特定的不变量
- Isolated 隔离性—— 并发事务的执行结果必须与某种串行顺序的执行结果等效(可串行化)
- Durable持久性——写入是永久的
满足ACID 的事务如同魔法,也是本节课的目标,如下所示
- 程序员只编写简单的顺序代码
- 系统自动添加正确的锁,确保并发安全
- 系统自动提供故障恢复,保证数据不会丢失
当今的存储系统有些提供事务,有些并不提供,因为有些应用能在事务中受益,有些并不能够。SQL数据库提供事务,但是事务很慢,特别是对于分片数据。因此有一段时间,简单的K/V存储 能够获得青睐,但是只能在单个记录上,PUT和GET。不管怎么说,事实是事务正在回来了。
今天的目标是如何满足在多个服务器下对分片数据的分布式事务的ACID特性。
我们知道, 可串行化(serializable) 事务隔离级别,是说并发的操作执行结果,与某一种顺序执行的结果保持一致。串行意思,就是同一时刻只执行一条。(这个定义应该让你想起另外一个叫可线性化linearizability,无论系统内部多么并发,对外表现的结果必须等价于某个顺序的执行, 但可线性化关注的是单个操作,要求瞬间生效,必须复合真实事件顺序)
验证(test)执行结果是否是可串行化一种方法是,找到一种执行顺序能够达到同样的结果。即便两个操作是并行执行,他们也会产生像是顺序执行的结果。
分布式事务的实现主要依赖两个核心组件:并发控制和原子提交。前者负责确保事务之间的隔离性与可串行化,后者在系统故障的情况下仍能实现事务的原子性。我们首先来看并发控制,其目标是在单个数据库服务器上,实现多个并发事务的隔离与串行等效执行。事务的并发控制的两种类型:
- 悲观并发控制(Pessimistic)。其特点是,在访问记录前先加锁; 冲突会导致延迟(等待获取锁)
- 乐观并发控制(Optimistic):在不加锁的前提下直接读取/修改记录,直到"validation"阶段再检查是否存在读写冲突(判断是否可串行化);若检测到冲突则Abort并重试。该方法也被称为乐观并发控制(OCC)
- 在"validation"阶段会持有锁,但是比悲观并发控制会短很多。
如果事务冲突频繁,前者比较快;如果事务冲突很少,则后者比较快。
2. 两阶段锁
两阶段锁是实现 可串行化 的事务隔离等级 的经典方法,数据库每个记录都关联一个锁,规则如下:
- 事务在使用某个记录之前必须获取该记录的锁,并且
- 必须一直持有这些锁直到事务提交或中止之后才能释放。
还是银行取钱的例子, 假设 T1 和 T2 同时开始,事务系统会自动获取所需要的锁。首先获取到锁的,才能用x,另一个事务只能等待第一个事务完全结束(达到 END-X)后才能继续。这种机制有效地防止了非串行化的交叉执行。
具体细节如下:
- 事务在运行过程中按需自动加锁,例如
add()和get()操作会隐性地获取该记录的锁;而END-X()会自动释放所有锁。 - 所有的锁都具有排他性(这个讨论,没有读写锁存在),全程叫强严格两阶段锁(Strong Strict 2PL),强严格 = 持有锁直到COMMIT后
- 远比比Golang锁更加结构化
- 程序猿必须提供
BEGIN-X/END-X - DB自动对首次使用的每条记录上锁
- DB在事务结束时自动释放锁
- DB可能会自动
ABORT来解决死锁
- 程序猿必须提供
为什么一定要等到提交或中止后再释放锁?
Solution: 如果在用完某个记录后立即释放,会导致不一致的读取。例如,如果 T2 在读取 x 后立即释放锁,而此时 T1 执行并修改了 x 和 y,再轮到 T2 读取 y,就可能得到 (10, 9) 的结果,这无法对应任何一个串行化顺序(既不是 T1;T2,也不是 T2;T1),从而破坏了事务的隔离性。
两阶段锁也会有死锁吗?系统如何检测并打破的?
Solution: 当然。比如
T1 T2
get(x) get(y)
get(y) get(x)系统需要检测并打破死锁。主要有以下方法
- 检测循环依赖(detect cycles):系统维护一个等待图(wait-for graph),如果检测到图中有环,就说明发生了死锁,可以选择中止其中一个事务来打破循环。但这个方法在分布式系统中很难实现,,因为锁分散在不同服务器上,收集和分析信息的开销大,延迟高。
- 超时。
- Wound-wait策略。给每个事务分配一个时间戳(启动时间),时间越早,优先级越高。如果一个事务请求的锁被一个“更年轻的事务”占着,它就“wound”(伤害)那个年轻事务,直接把它中止。如果锁被一个“更年长的事务”持有,那么这个事务只能老实等待(wait)
□
描述一个场景,两阶段锁比普通锁更加高效。
Solution:Simple Locking在事务开始时就一次性锁住所有可能用到的记录,直到事务结束才释放;2PL在使用记录时才获取锁,直到事务结束才释放。
场景:银行系统里有很多账户记录。T1 事务要遍历账户,查找余额大于 10,000 的账户,最多只查 3 个,找到就停止。T2、T3 是其他事务,也在读或更新一些账户记录。
SImple Locking的行为: T1 在开始时会锁住所有账户记录,因为它不知道自己会用哪些记录(即使最终只用了前 3 个)。这会阻塞 T2 和 T3,对性能影响非常大。
2PL的行为: T1 只在实际用到一个账户时才锁住它,找到 3 个合适账户后立刻停止,锁的数量和时间都更少。因此 T2 和 T3 有更大机会并行进行,提高了系统吞吐量。
经验: 如果事务的“用到哪些记录”取决于运行时的条件(而不是提前知道的静态集合),那么 2PL 就能减少锁的数量和时间,从而提高性能。□
”两阶段“是指事务获取和释放锁的过程分为两个阶段:
- 增长阶段(Growing Phase):在食物到达锁点之前,事务可以不断获取锁,但不能释放任何锁。
- 收缩阶段(Shrinking Phase):在事务到达锁点之后,事务可以释放已持有的锁,但不能再获取新锁
3. 两阶段提交
下面我们介绍一个分布式事务如何处理失败的情况。
还是刚刚银行转账例子
- 假设X、Y在不同的存储服务器上,X的服务器加1,但是Y在做减法之前就Crash了
- 或者是X服务器加1,但是Y所在服务器发现到这个账户Y并不存在
- 或者是X 和 Y 都能做到自己负责的部分,但是不确定对方是否会这样做
T1: T2:
BEGIN-X BEGIN-X
add(x, 1) tmp1 = get(x)
add(y, -1) tmp2 = get(y)
END-X print tmp1, tmp2
END-X实质上我们想要一个原子提交:在一组计算机合作完成某些任务,每个计算机都有不同的角色, 我们想要原子性,即要么全部执行,要么没人任何机器执行。这里的挑战就是,失败和性能问题。
3.1 设置
协议的运行背景如下:
数据被分片存储在多个服务器上。
每个事务由一个 事务协调器(Transaction Coordinator, TC) 负责管理。
对数据的每次读写操作,TC 都会通过 RPC 向相关的数据分片服务器发送请求。
- 每个分片服务器称为一个 参与者(participant)
- 每个参与者负责管理本地数据的锁。
系统中可能同时存在很多并发事务和多个 TCs,
- 每个事务由 TC 分配一个唯一的事务 ID(TID)。
- 所有消息、状态等都会标记 TID,以防不同事务之间混淆。
3.2 无失败下的2PC
首先,事务协调器(TC)向参与的分片服务器(如 A 和 B)发送一系列操作请求,例如 put()、get() 等 RPC。这些服务器在收到请求后,会对涉及的记录加锁(如果已经被其他事务锁定,则需等待),并在一个临时副本上执行修改。此时修改尚未生效,只有在最终提交后才会写入真实数据库。当 TC 执行完事务所有的操作后,它会向所有参与者(如 A 和 B)发送 PREPARE 消息。此时:
- 如果一个参与者能够成功提交(例如锁都拿到了,验证无误等),它会回复 YES,并进入“已准备(prepared)”状态。
- 如果无法提交,它会回复 NO。
TC 收集所有参与者的响应后:
- 如果 所有参与者都回复 YES,TC 就会向它们发送 COMMIT 消息;
- 如果 任意一个参与者回复 NO,TC 则向所有参与者发送 ABORT 消息。
收到 COMMIT 消息的参与者会将之前的临时修改正式写入数据库,并释放该事务加的锁。收到 ABORT 消息的参与者则会丢弃临时修改,并同样释放锁。所有参与者在完成后会向 TC 发送确认(acknowledge)。
高层次角度
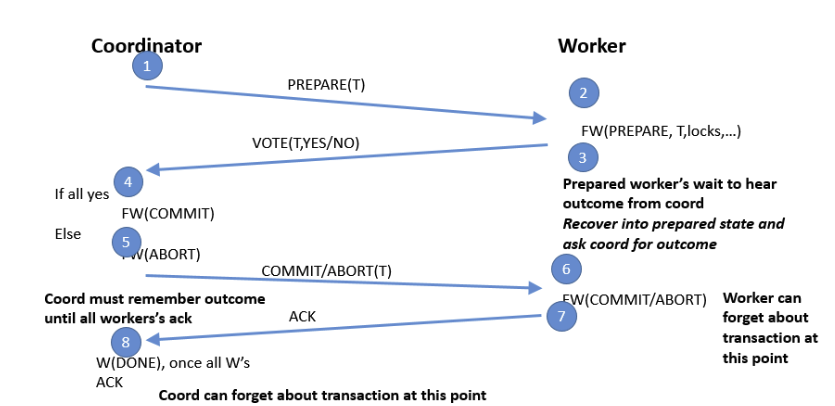
注:”FW(Force Write)“ 意思是强制写入
阶段1(准备阶段): 事务协调者(TC)询问每个工作者是否完成与该事务相关的任务并准备好提交。每个工作者返回“是”或“否”。
阶段2(提交阶段或中止): 协调者统计所有的响应。如果每个工作者都回应“是”,则该事务将被提交;否则,将回滚。协调者会将最终的提交发送给每个工作者,并接受确认回复。
为什么这个过程是正确的? 换句话说,如何保证一致性
Solution: 只有TC和参与者都同意的情况下才会提交事务,因此可以保证事务的原子性。□
协调者角度
- 日志记录事务的开始,以确保事务的启动被正确记录
- 在参与者上执行事务
- 记录每个参与者的“最终决定”
- 一旦所有的参与者都准备好,需要强制写入事务COMMIT
- 如果有任何参与者在准备阶段失败,则向每个参与者发送中止请求,以撤销事务
- 给每个参与者发送COMMIT请求
- 确认所有事务已完成,用Logging记录DONE状态。
事务协调者TC何时可以完全忘记已经提交的事务?
Solution:当接收到所有参与者发送COMMIT确认时,TC可以安全忘记该事务,因为没有节点会再次请求事务状态。□
参与者角度
在准备阶段:
- Logging 事务的开始,以确保事务的启动被正确记录
- 需要Logging记录上锁的对象,以及在回复“PREPARE”状态请求之前将日志强制写入磁盘。这是因为,假如准备状态崩溃,需要恢复到"PREPARE"状态(比如重新获取之前持有的锁),并在在回复 PREPARE 请求之前, Logging记录它已经“YES”。
- 回复协调者"PREPARE"状态的询问请求
- 直到收到Commit或者Abort指令之前,都需要持有锁,需要确保资源的状态不会发生变化,以避免事务的不一致性。
可以看出,每个工作者对事务都拥有“否决权”。
参与者何时可以完全忘记已经提交的事务?
Solution:在向 TC 发送 COMMIT 确认 后,可以忘记事务。如果再次收到同一事务的 COMMIT 指令,且已无记录,说明该事务已经提交并被遗忘,参与者可以直接再次确认 □
3.3 有异常下2PC
参与者角度
参与者崩溃并重启,有如下情况
- 如果参与者在收到 PREPARE 之前崩溃,他可以安全地忘掉该事务。(你不能相信之前自己做了啥,是否成功等,因为也没有写进磁盘)
- 如果参与者在回复"PREPARE"请求且为 YES 之后崩溃,他必须记住该事务的状态,因为其他参与者可能已经接收到COMMIT并提交了。为了保证正确性,B必须能够在重启后恢复,并决定是否提交。
- 参与者在发送YES之前将事务状态(包括锁和临时修改数据)写入持久性存储(磁盘)。如果该参与者在重启时发现磁盘上有YES,但还没收到COMMIT,他必须联系协调者TC询问最终决定,或者等待TC重新发送 PREPARE请求 。同时,必须继续持有该事务的锁。
协调者角度
假如协调者崩溃或者重启, 首先,日志会告诉我们哪个事务当时正在运行,其次,TC必须记住在崩溃前有没有发送过COMMIT,因为参与者可能已经提交事务了(如果发送过的话),因此,TC 在发送 COMMIT 消息前,必须先将 COMMIT 写入磁盘。如果 TC 重启,要能重发 COMMIT 或 ABORT 消息,或者在参与者询问时提供结果。参与者需要根据事务 ID (TID) 去重,避免重复提交。
如果崩溃在协调者COMMIT之前。结果是,所有的参与者都应该中止,有些可能已经“准备好了”,有些可能没有,且参与者可能会被要求终止“未准备”的事务
- 如果崩溃在协调者COMMIT之后,但是还没有Done,那么所有参与者应该Commit,工作者有些可能已经提交了,有些可能没有。不管怎样,参与者必须要求重新提交事务。
如果如果 TC 一直收不到 某个参与者的 YES/NO(如 参与者崩溃或网络故障)
Sulution: TC 可以设置超时并选择中止事务(因为尚未决定 COMMIT),这样可以释放锁资源。
如果某个参与者在等待TC的PREPAR消息时发送超时或者Crash?
Solution: 因为B还没回复Prepar,因此TC不会提交,所以B可以单方面中止,并释放锁,会未来可能的"PREPARE"消息说NO
假如某个参与者说了YES,但是没有收到COMMIT / ABORT?
Solution: 这种情况,B没有单方面宣布的权利了。他必须阻塞,等待TC的决定。
流程角度
(下面的序号对应上图的失败的位置)
TC 在发送
PREPARE之前崩溃并重启(或者是部分发送了)- TC :中止事务,丢弃所有状态。
- 由于没有事务的记录,如果参与者询问,将告知参与者中止事务。
- 参与者:轮询TC ,获取未完成事务的状态。此时会收到TC abort的处理结果。
- TC :中止事务,丢弃所有状态。
参与者在收到
PREPARE之前崩溃:- TC : 永远不会收到其回复,因此会中止事务。
- 参与者: 会在重启时回滚事务。
参与者在
PREPARE之后崩溃:TC : 正常等待ACK,超时则ABORT
参与者:必须轮询TC ,获取确定事务的结果。有两种情况:
参与者已ACK,TC 在等待确认,可以询问TC 得知事务的最终结果。
参与者未发送ACK,在这种情况下,TC 可能已经或可能没有超时。
- 如果TC 没有超时,参与者可以ACK。
- 如果TC 已经超时,它肯定已经中止事务,并会通知参与者这一结果。
TC 在收到所有投票之前崩溃:
- TC : 在恢复时中止事务,并通知参与者。
- 参与者:对于已经准备好的参与者,必须等待TC 重新启动,以得知事务的结果;
TC 在写入
COMMIT之后崩溃:- TC : 没有
DONE记录,TC 会向所有参与者发送COMMIT指令。 - 参与者:必须等待结果的通知。
- TC : 没有
参与者在收到
COMMIT/ABORT之前崩溃:- 参与者:恢复进程会轮询事务结果。
- TC : 尚未收到确认,它仍然知道事务的状态。
参与者在写入
COMMIT记录后、ACK COMMIT前崩溃:- 参与者: 将恢复,事务将被提交。
- TC : 会定期发送
COMMIT消息,参与者会ACK 而无需写入额外的状态。
TC 在收到部分确认后崩溃:
- TC 会向所有参与者发送
COMMIT/ABORT指令,参与者会确认。
- TC 会向所有参与者发送
协调者何时可以忘记已经提交的事务?
Solution: 当收到所有参与者的COMMIT 回复之后,此时没有参与者会再次询问,因此可以忘记。
参与者何时可以完全忘记已经提交的事务?
Solution: 当 参与者 给 TC 发送 ACK 之后,就可以把这条事务的状态清掉。如果未来 TC 因为网络丢包或重试,又发来一次 COMMIT,而此时 参与 已经把事务日志忘掉了:(说明我之前一定已经提交过(并且忘记了),所以我可以 再给一个 ACK。)
只读参与者
如果一个是参与者是只读,不涉及任何数据的修改,因此他的事务处理比普通的参与者更加高效和简单。因为只要涉及数据修改,才需要将数据的更改记录到日志中,以便崩溃后恢复,否则,事务的结果对它没有影响。一旦它发送了PREPARE确认,就可以立即忘记该事务。同时,协调者可以忽略只读参与者,不需要发送最终结果,减少通信开销。
假设这里有参与者日志,且该参与者从crash恢复过来了,请问事务T1-T3的结果怎么?
W X T1 W Y T2 W Z T3 PREPARE T1 PREPARE T2 COMMIT T1
Solution: T1: Committed; T2: 未知(需要与TC 通信确认); T3: 中止
3.4 复杂度分析
工作者在阶段1中投票“是”之前拥有否决权。一旦投票“是”,就不能更改其投票结果。但如果工作者在投票“是”后立即崩溃,从而可能认为自己仍然有否决权,并可能会中止事务。为了防止这种情况,工作者必须在发送“是”投票前将其投票结果持久化写入。
假如参与者有的N个。
对于正常的更新
- 协调者:2次写入 (准备 和 DONE记录),1次强制写入(COMMIT/ABORT),2N次消息传递(PREPARE 和 COMMIT/ABORT)
- 工作者:2次强制写入(准备 和 Commit/Abort),2个消息传递 (准备ACK、COMMIT/ABORT的ACK)
对于只读,
- 协调者: 1次写入(准备),1次强制写入(COMMIT/ABORT),1N消息传递(PREPARE)
- 工作者:0次(强制)写入,1个消息传递(ACK)
3.5 2PC的局限性
在 分片数据库 (sharded DBs) 里,如果一个事务涉及多个 shard,就需要一个协议来保证跨 shard 的原子提交,2PC 就是用来保证这种跨节点/跨分片事务原子性的经典协议。但 2PC 在实践中声誉并不好,主要原因有以下几点:
- 多轮消息交换,2N次网络往返。
- 慢:磁盘写入
- 持锁时间长,在PREPARE和COMMIT阶段,参与者需要保持锁,阻塞其他事务。
- 协调者崩溃会导致无限阻塞 (indefinite blocking): 如果 TC 在 commit/abort 决定阶段崩溃,参与者就卡在
prepared状态。- 为了一致性牺牲了系统的可用性
因此,2PC 通常只在一个小的、受控的系统域内使用,比如同一个数据库集群内部。不适用于银行之间、航空公司之间,或广域网中的事务。
破局思路
已经解决了原子问题, 那如果我们想要高可用 + 原子性呢?
既然单点会导致阻塞, 那就把TC和各个参与者都复制成一个高可用的副本,每个副本内部通过Raft(or Paxos)保证强一致性和容错。副本组之间,运行 2PC,保证全局原子提交。 Spanner就是这样设计的典型代表。
2PC也涌现出一些针对特定场景下的优化版:
- 三阶段提交,允许参与者在TC崩溃情况下提交或中止。
- 当参与者能够可靠地区分TC是宕机和网络未传送数据包时,三阶段提交才能正常工作。例如如果存在网络分区,三阶段提交无法正常工作。在大多数网络中,无法区分宕机还是网络故障
3.6 示例: Postgres
协调者代码
all_prepared = True
# log Start, Get TID
tid = logger.start_coord_txn() # FW
for worker in workers:
logger.start_worker_txn(worker, tid)
do_work(worker)
result = logger.prepare(worker, tid)
all_prepared = all_prepared & result
if (all_prepared):
logger.log(tid, "COMMIT") # FW
else:
logger.log(tid, "ABORT")
for worker in workers:
if (all_prepared):
logger.commit(worker, tid)
else:
logger.abort(worker, tid)
logger.log(tid, "DONE") # FW(W?)Logger
def start_coord_txn(self):
cur_tid = self.tid
self.log(cur_tid, 'Start')
self.tid = self.tid + 1
return cur_tid
def start_worker_txn(slef, cursor, tid):
cursor.execute("BEGIN TRANSACTION")
def prepare(self, cursor, tid): #RT
try:
cursor.execute("prepare transaction '%s'" % (t_name%(tid)))
return True
except psycopg2.DatabaseError as error:
return False
def commit(self, cursor, tid): #RT
cursor.execute("commit prepared '%s'" %(t_name%(tid)))故障恢复
def reover(self):
to_abort = []
to_commit = []
max_tid = 0
for (tid, cmd) in self.log_lines()
if cmd = 'Start':
to_abort.append(tid)
max_tid = max(self.tid, tid)
if cmd = 'Commit':
to_abort.remove(tid)
to_commit.append(tid)
if cmd = 'Done':
if tid in to_abort:
to_abort.remove(tid)
if tid in to_commit:
to_commit.remove(tid)
if (len(to_abort) > 0) or (len(to_commit) > 0):
workers = self.get_workers()
for txn in to_abort:
for worker in workers:
self.abort(worker, txn)
self.log(txn, "DONE")
for txn in to_commit:
for worker in workers:
self.commit(worker, txn)
self.log(txn, "DONE")
for worker in workers:
worker.close()
self.tid = max_tid + 1 #为了确保下一个新事务的 ID 是唯一且递增的参与者没有发送消息或者运行恢复过程;协调者做了所有的恢复
4. 趋势
http://dbmsmusings.blogspot.com/2019/01/its-time-to-move-on-from-two-phase.html
两阶段提交协议(2PC)在企业级系统中已沿用三十余年,是保障跨分区/分片事务原子性与持久性的核心协议。2PC的核心问题是阻塞问题、拥塞问题(较少被讨论)——事务必须等待2PC完成才能知道结果,阻塞了冲突事务
上一篇文章的思路具有革命意义:它挑战了数十年来"事务可能在任何时候因任何原因中止"的基本假设。通过重新设计系统架构,让事务要么因数据逻辑失败,要么必须成功,从而完全消除了复杂的分布式提交协议的需要。】=
作者用一个很好的例子说明:
传统方式(需要2PC):
Worker 1: X = 42
Worker 2: if (Y > 0) Y = Y - 1; else ABORT新方式(无需2PC):
Worker 1: temp = Do_Remote_Read(Y); if (temp > 0) X = 42
Worker 2: if (Y > 0) Y = Y - 1; Z = Y这样两个工作节点都基于Y的值来做决定,消除了协调的需要。
作者提到了两类中止:
- 数据状态导致的中止 - 可以通过条件逻辑处理
- 系统导致的中止(如故障、死锁)- 需要完全消除
摒弃系统级中止、将应用逻辑与状态检查解耦——我们既能保留强一致性,又无需2PC的开销。这一范式已被Calvin、FaunaDB等系统验证,现需在更广泛的分布式系统中推广。