Lec 8 连接算法
阅读资料
参考书 Chapter 15.4-15.6
Join Processing in Database Systems with Large Main Memories, 1986
良好的数据库设计是为了最小化信息冗余,这正是基于规范化理论构建表结构的原因。重点研究用于双表组合的内等值连接算法。等值连接算法通过匹配键值相等的记录来合并表数据,这些算法经过调整后也可支持其他类型的连接操作。特别关注Hash Join 和Sort-Merge join连接,以及这两种方法权衡。
Outline
嵌套循环连接(Nested Loops, NL)
块嵌套循环连接(Bolcked Nested Loops)
索引嵌套循环连接(Index nested loops(INL)
当表能够装入内存时
hash连接(只需一个表装入内存)
- 使用哈希表来连接两个表,只需要其中一个表能装入内存即可,通常在没有合适的索引时使用
排序合并连接(Sort Merge Join, 两个表都需要装入内存)
当表不能装入内存时
- 块哈希连接
- 外部排序合并连接
- 简单哈希
- Grace哈希
评估连接
假设R总是比较小的表
- {S}-S表中的记录
- |S| - S表的页树
- 内存大小为M页
嵌套循环连接
python
for s in S:
for r in R:
if pred(s, r):
output s join r当只有一个表能放入内存时,选择哪个表作为内表(Inner)和外表(Outer)会影响连接的效率
无论选择哪个表作为内表或外表,在最坏的情况下,仍需要进行 {S}(外表的记录数)乘以 {R}(内表的记录数)次比较
| CPU复杂度 | I/O 复杂度 | 说明 | |
|---|---|---|---|
| NI | {R} * | |S| + {S}|R| (R不能装入内存) |S| + |R|(R能够装入内存) | 当R能装入内存,而S不能时,内联和外联的选择会影响到效率 |
块嵌套循环连接
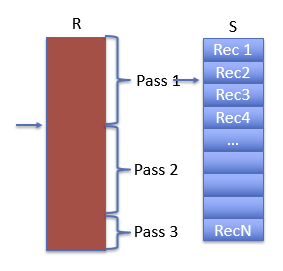
text
B = block size(< M)
while (not at end of R)
R' = read B reocrds from R
for s in S:
for r in R':
if pred(s, r):
output s join r- 选择内联或外联对性能有影响; {S} * {R}次比较
- 但是遍历S的次数是{R}/B
{R}/B 次数遍历 S
| CPU复杂度 | I/O 复杂度 | 说明 | |
|---|---|---|---|
| NI | {R} * | |S| + {S}|R| (R不能装入内存) |S| + |R|(R能够装入内存) | 当R能装入内存,而S不能时,内联和外联的选择会影响到效率 |
| BNI | {R} * | $\lceil { | R} |
索引循环嵌套
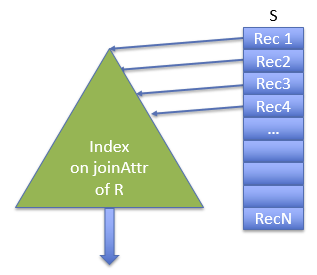
假设在关系R中的连接属性上有一个索引I
python
for s in S:
for r in lookup s.joinAttr in I:
output s join r- 内表和外表的选择很重要
- 有 {S} 次查找
- 内表总是被索引的属性
- 注意,除非 S 按连接属性排序并且索引是按连接属性聚簇的,否则索引查找是随机的
| CPU复杂度 | I/O 复杂度 | 说明 | |
|---|---|---|---|
| NI | {R} * | |S| + {S}|R| (R不能装入内存) |S| + |R|(R能够装入内存) | 当R能装入内存,而S不能时,内联和外联的选择会影响到效率 |
| BNI | {R} * | $\lceil { | R} |
| INL | {R} * D, D是树的深度, <~ 5 | 假设S上有索引 |
哈希连接(内存)
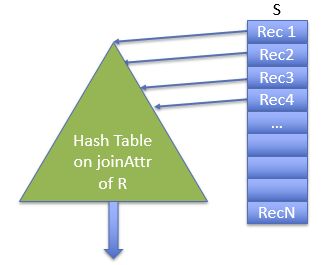
- 基本上与索引嵌套循环连接相同,但在运行时动态构建内存中的哈希“索引”
- 在连接操作中,首先会根据 R 表的连接属性(即用于连接的字段)构建一个哈希表 T
text
T = build hash table on joinAttr of R
for s in S:
for r in lookup s.joinAttr in T:
output s join r- 内表与外表的选择很重要
- 需要进行 {S} 次查找
- 并且需要内存来存储 R 的哈希表
| CPU复杂度 | I/O 复杂度 | 说明 | |
|---|---|---|---|
| NI | {R} * | |S| + {S}|R| (R不能装入内存) |S| + |R|(R能够装入内存) | 当R能装入内存,而S不能时,内联和外联的选择会影响到效率 |
| BNI | {R} * | $\lceil { | R} |
| INL | {R} * D, D是树的深度, <~ 5 | 假设S上有索引 | |
| Hash Join | {R} + | |R| + |S| | 两个表都需要能装入内存 |
分块哈希连接
- 类似与块循环嵌套
- 迭代的执行以下操作
- 构建一个在内存中可以容纳的R的部分哈希表
- 使用S中的所有记录进行探测(在哈希表中查找)
- 使用R的一下个部分重复上述过程
| CPU复杂度 | I/O 复杂度 | 说明 | |
|---|---|---|---|
| NI | {R} * | |S| + {S}|R| (R不能装入内存) |S| + |R|(R能够装入内存) | 当R能装入内存,而S不能时,内联和外联的选择会影响到效率 |
| BNI | {R} * | $\lceil { | R} |
| INL | {R} * D, D是树的深度, <~ 5 | 假设S上有索引 | |
| Hash Join | {R} + | |R| + |S| | 两个表都需要能装入内存 |
| Blocked hash join | {R} + $\lceil { | R} | /M \rceil \times |
排序归并连接
特别适用于排序后的数据或可以按顺序遍历的数据。 将S和R进行排序(如果有合适的索引,可以直接利用索引进行排序后的遍历)
python
while (i < {R} and j < {S}):
if (R[i].joinAttr == S[j].joinAttr):
ouput R[i] join S[j]
if (R[i].joinAttr < S[j].joinAttr):
i = i + 1
else:
j = j + 1NOTE
输出是有序的
处理重复值
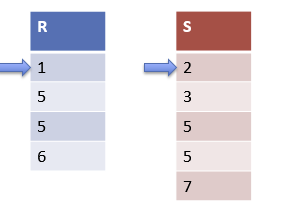
- 思路: 当连接键值相同时,就进入处理重复值逻辑。 计算S和R的运行长度(比如m, n),生成
m x n的连接结果
sql
while (i < {R} and j < {S}):
if (R[i].joinAttr == S[j].joinAttr):
rLen = getRunLen(R, i)
sLen = getRunLen(S, j)
emitRun(R, S, i, j, rLen, sLen)
i = i + rLen
j = j + sLen
if (R[i].joinAttr < S[j].joinAttr):
i = i + 1
else:
j = j + 1
def getRunLen(v, i):
runLen = 1
while (i < len(v)-1):
i = i + 1
if v[i] == v[i-1]:
runLen = runLen + 1
else:
break
return runLen
def emitRun(R, S, r, s, rLen, sLen):
for i in range(r, r+rLen):
for j i range(s, s+sLen):
output R[i] join S[j]| CPU复杂度 | I/O 复杂度 | 说明 | |
|---|---|---|---|
| NI | {R} * | |S| + {S}|R| (R不能装入内存) |S| + |R|(R能够装入内存) | 当R能装入内存,而S不能时,内联和外联的选择会影响到效率 |
| BNI | {R} * | $\lceil { | R} |
| INL | {R} * D, D是树的深度, <~ 5 | 假设S上有索引 | |
| Hash Join | {R} + | |R| + |S| | 两个表都需要能装入内存 |
| Blocked hash join | {R} + $\lceil { | R} | /M \rceil \times |
| Sort Merge join | Rlog{R} + {S}log{S} + {S} + | |R| + |S| | 假设两个表都能放进内存,如果已经有序 |
什么情况下你会请倾向于sort-merge而不是hash join?
什么情况下你会请倾向于索引嵌套循环而不是hash join?
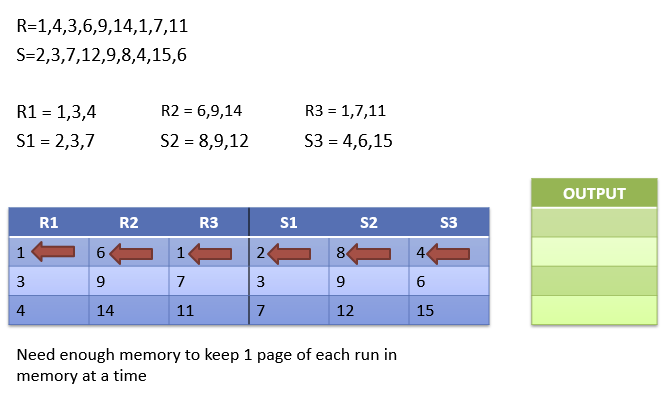
外部排序归并连接
等值连接两个表 S 和 R(假设连接键是相等的,即 Equi-Join)
- |S|: 表示表 S 中的页数
- {S}: 表示表 S 中的元组数
- M: 表示可用的内存页数;并且假设 M > sqrt(|S|),即内存大小大于表 S 页数的平方根
算法:
- 对S和R进行分区
- 将表 S 和表 R 分成大小为内存容量的有序分区(
sorted runs),然后将这些分区写回磁盘
- 将表 S 和表 R 分成大小为内存容量的有序分区(
- 合并所有分区:
- 同时对所有分区进行合并。这一步确保最终连接的结果是有序的,能够高效地进行等值连接。
分析:
- I/O消耗: 需要读取|R| 和 |S|两边, 写一遍
I/O
例子: