Lec 15 分布式数据库
总览
IMPORTANT
- 并行数据库: 研究如何让多个处理器/机器来执行一个SQL查询的不同部分。
- 特别适用于大规模、运行缓慢的查询
- 分布式数据库:当这些机器物理上分离并独立故障时会发生什么
- 特别适用于事务处理
- 并行架构
- 并行查询处理
- 并行操作
- Join策略
- 并行策略
并行处理数据库
目标:在多个处理器上加快SQL的查询
怎么判断是否执行更快? 或者说评价指标是什么:
- 加速比 在同个问题上的 speed up(加速比) = 原耗时时间/新耗时时间
- 放大比 scale up(放大) = 在一倍机器上的一倍的问题 / N倍的机器上的N倍问题
- 两者不一定相同,小问题的可能意味着很难并行化
数据库特别指标
事务加速比(Transaction speedup): 固定的一组事务,用1 vs N 个机器做比较
批量加速比(Batch speedup): 固定大小DB,用1 vs N个机器
事务放大比(Transaction scaleup): 用N个机器来执行N 倍的事务来与单个机器和单个事务做比较
批量放大比(Batch scaleup): 用N个机器来执行用N倍的一个事务来与单个机器和单个事务做比较
加速比目标
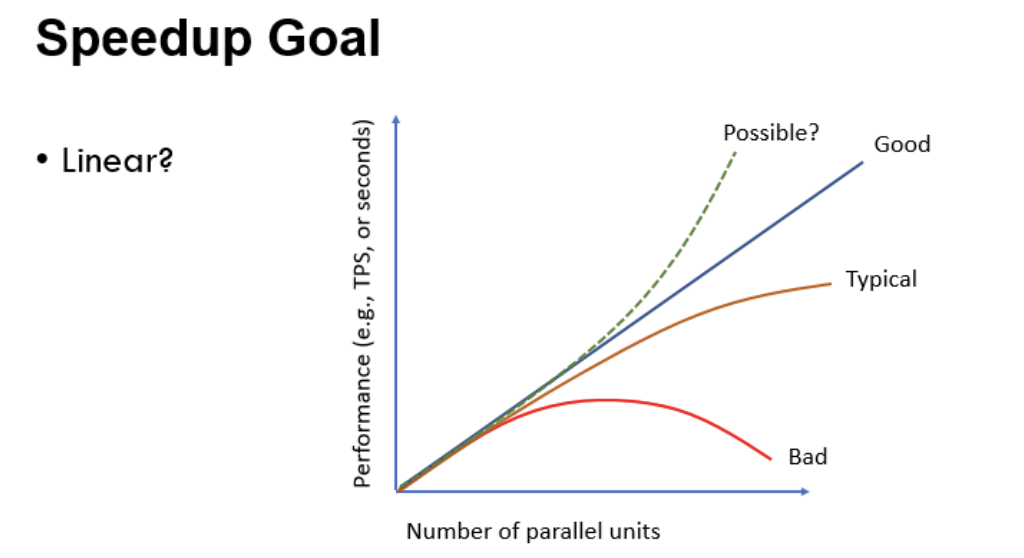
- 线性增长的阻碍
- 启动时间。启动并行执行器需要花费一点时间
- 干扰竞争(interference contention): 受限于一些共享资源;比如输入输出队列,等等
- 工作倾斜: 每个处理器分配的工作量并不相同
- 几乎所有的工作量的增长都会某个点停止
- 可并行工作量的性质
- 提供线性的加速比
- 通常能够被分解成若干小的单元独立执行
- 我们将会看到,关系模型通常会提供这个性质
并行架构
有几种方法来并行化数据库
Shared Everything——共享所有
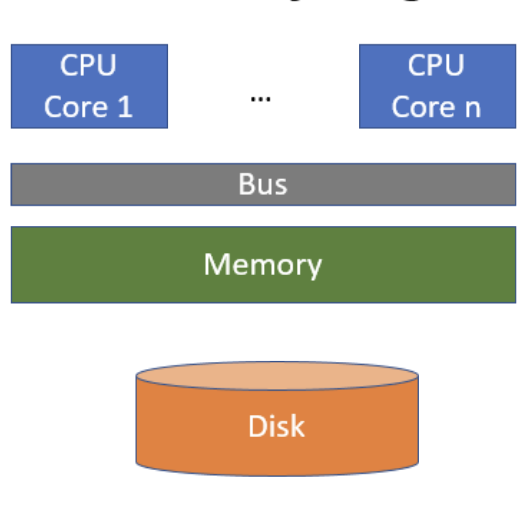
- 优点
- 容易构建多核计算机就是如此,易于编程
- 多线程执行
- 每个核都能访问任何记录
- 缺点
- 没有容错;如果内存/甚至一个处理器崩了,那么这个模型也就崩了
- 难以在一些核上扩展
Shared-Disk——共享磁盘
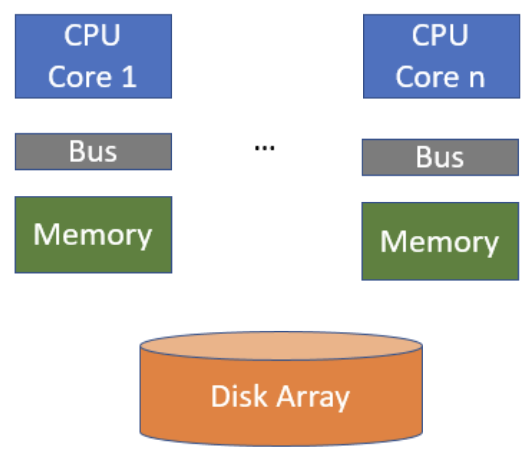
- 多机器;每个机器都能访问磁盘的任何记录
- 需要协调机制保证写入磁盘是安全的(缓存一致性)
- 磁盘会抽象成服务
- 容错机制取决于可靠磁盘阵列,成本较高
- Oracle用的很多
Shared-Nothing——分布式
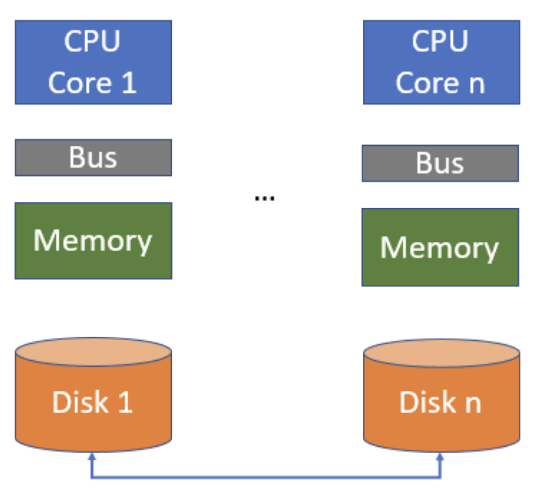
- 多机器
- 数据分区;每个机器各自负责处理&修改其负责的数据;意味着需要新的并发控制/恢复机制
- 扩展性非常好: 添加机器或者分区都非常容易
- 通过复制技术来容错
Shared-Nothing——基于分布式文件系统的分布式
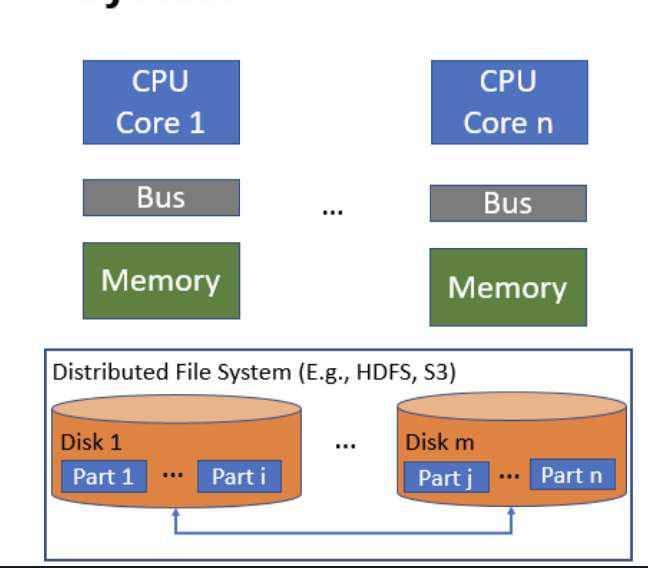
- 将存储扩展与计算扩展分离
- 存储层实现了容错机制
- 数据进行了逻辑分区且被不同的处理器操作
- 在云计算已经很普遍了,比如SnowFlake、MapReduce
小结
| 优点 | 缺点 | |
|---|---|---|
| 共享内存 | 容易构建 并发控制和恢复无需更改 | 性能、扩展性和容错较差 |
| 共享磁盘 | 更好的扩展性和容错 | 复杂的缓存一致性 扩展性差 依赖高昂的磁盘阵列 |
| 无共享(分区数据) | 成本低,扩展性好、容错性好 | 传统的并发控制和恢复机制(如事务锁、日志恢复等)需要重新设计 由于数据被分区并分布在多个节点上,因此执行查询或操作时需要新的执行引擎 |
并行化查询处理
有三种方法并行
运行多条查询,每个查询都在不同的线程
流水线并行: 不同的线程执行各自的操作
分区并行:不同的处理器处理每个分区
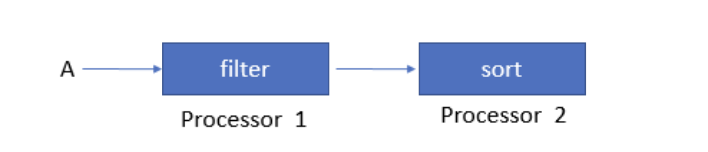
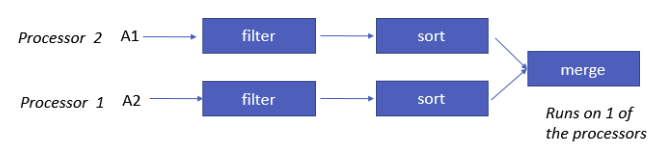
流水线并行
- 只有在每个流水线阶段的速度大致相同时才有效
- 只能在有限的阶段内实现并行化
- 在阶段
i+1的输入取决于阶段i - 如果阶段
i阻塞了(比如,排序),将会“阻塞”流水线 - 由于以上管道并行的局限性,数据库系统通常采用分区并行来实现扩展
分区并行
数据分区策略
随机/轮转分区
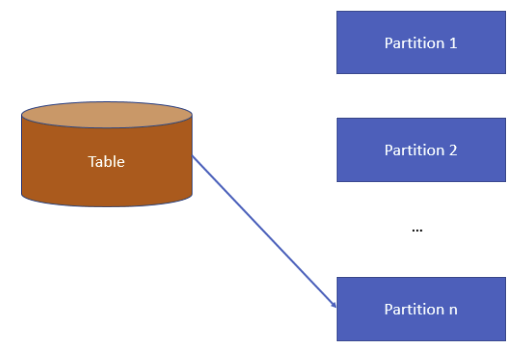
- 优点:负载比较平均,没有数据倾斜(no skew),
- 缺点:
- 连接时, 需要我们重新分区(repartitioning),重新分区目的是使得具有相同连接属性的记录被分到同一个分区中
- 不能提供下推谓词的能力
范围分区
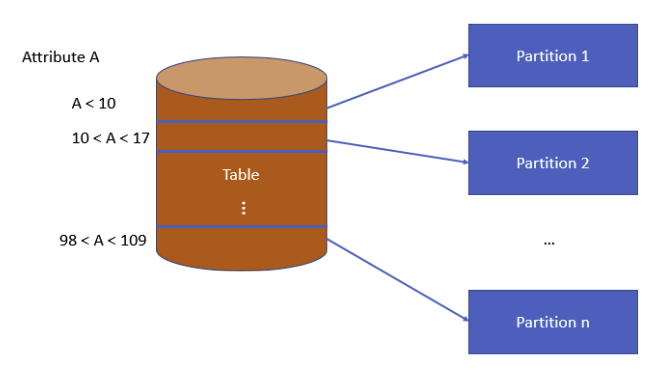
- 当表根据连接属性被分区好了后,允许我们用连接而无需重新分区
- 优点:容易下推谓词(根据分区的属性)
- 缺点:
- 难以保证等量的分区,特别是插
Hash分区
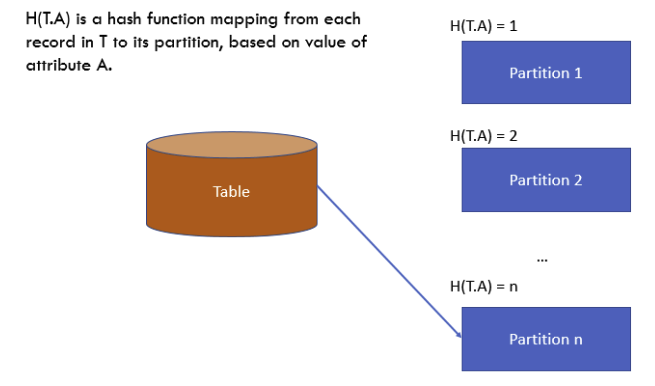
- 当表根据连接属性被分区好了后,允许我们用连接而无需重新分区
- 数据倾斜问题主要发生在数据中存在大量重复值的情况下
- 优点:每个分区大小大致相同,除非相同值非常频繁;有可能能够下推等价谓词(基于分区属性)
- 缺点:不能下推范围谓词
在分区数据库中的并行操作
选择SELECT
- 很自然”下推“到每个工作者
- 取决与分区属性,可能可以跳过一些分区
投影PROJECT
- 假设所有列都在每个节点上,没什么可做的
连接JOIN
- 取决于数据分区,能够处理独立的分区,然后Merge,或者可能需要重分区
聚合AGGREGATE
- 在每个节点分别聚合,然后Merge最终结果
Join 策略
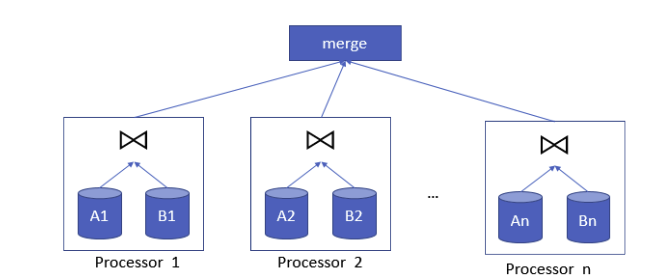
- 如果按照相同属性进行分区后,只在本地运行Join操作
- 并且,如果一个表被复制到所有节点上,就不需要join了
- 否则,有几个选项:
- 将所有表搜集到一个节点
- 这种方法通常不理想,除非在极端情况下,例如当表非常小的时候
- 重新分区一个或两个表——"shuffle join"
- 根据初始的分区策略,可以选择重新分区一个或两个表
- 在所有节点上复制(较小的)表
- 将所有表搜集到一个节点
根据连接属性预分区
查询: SELECT * FROM A, B WHERE A.a = B.b
假设我们hash 在A的a属性,用hash函数 F 来得到F(A, a) ->1...n (n = #machines)
同样地,用hash函数F来对B进行Hash
由于A和B使用了相同的hash函数,意味着相匹配的记录都会被分配到相同分区
重新分区例子——”shuffle join“
- 假设表A对a属性进行了预分区,因此不需要重新分区
- 表B也要按照属性a进行连接,但是初始分区与表A不一致,因此需要重新分区
- 有n个节点处理这个分区
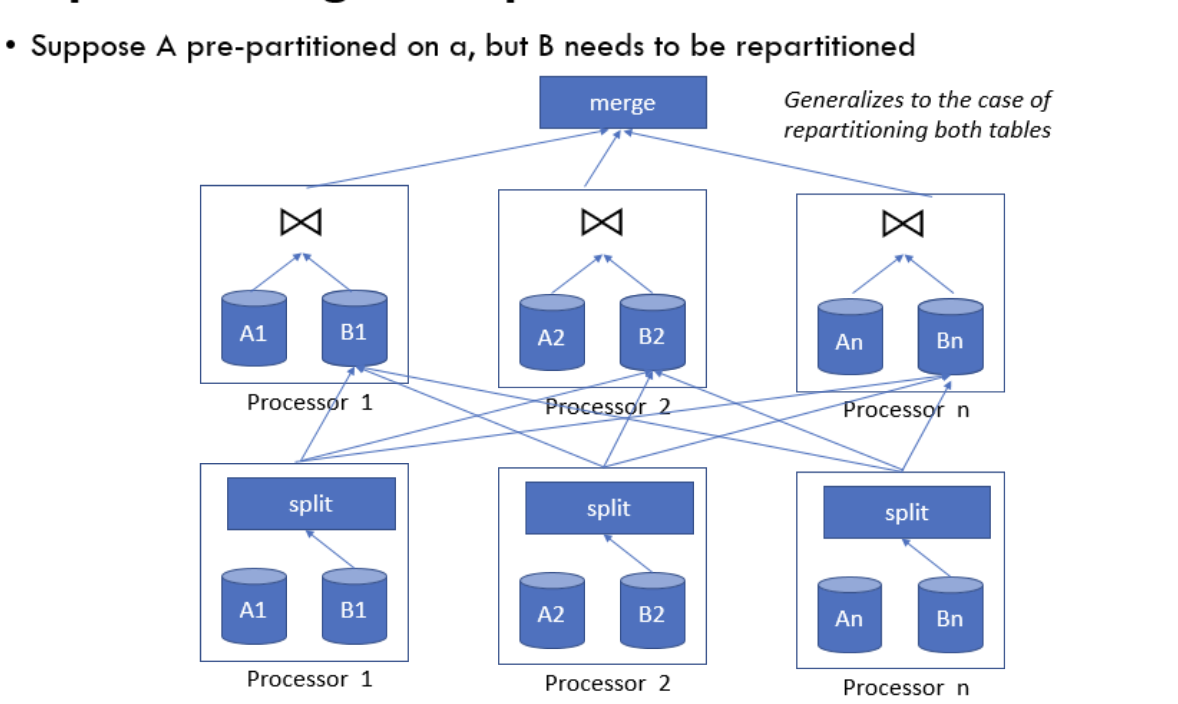
重新分区操作
- 重新分区:
- 表B的每个分区被分割成n个新分区(每个节点一个新分区)
- 每个节点会把它持有的分区数据按照分区规则分配到所有n个节点中,包括自身。这意味着每个节点都会把原分区分割成n份,发送到n个不同节点
- 数据传输:
- 假设表B的分区大小是|B|/n 字节,因此每一份大小就是|B|/n / n字节
- 因为每个节点上都有一个新的分区,所以每个节点需要把
n-1份数据发送到其他节点,每份数据大小为
每台机器需要接受和发送多少字节的数据?
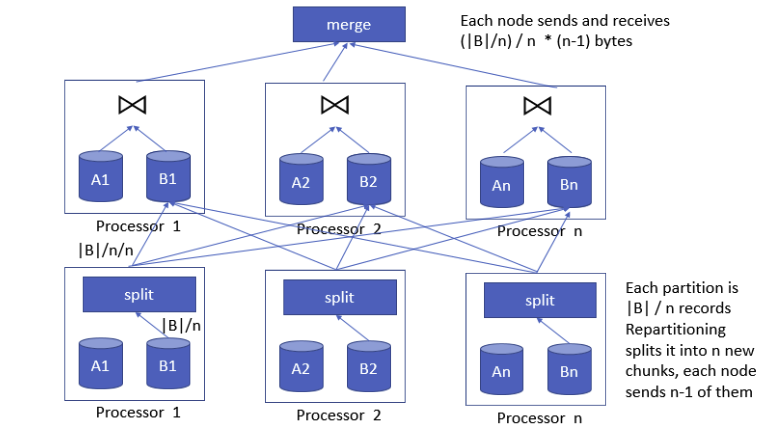
- 每个分区有 |B| / n个记录, 重分区将它水平拆分成n个chunk,每个节点发送n-1
- 每个节点: 发送 = 接受 =$ (n-1) * |B| / n^2$ bytes
假如表A,B都需要重新分区,每台机器需要接受和发送多少字节的数据?
每个节点: $(|A| / n^2)* (n-1) + (|B|/n^2) * (n-1) $bytes
复制的例子
- 假设我们需要将B复制到所有节点
- 在复制策略中,较小的表需要被复制到所有其他节点上。每个节点发送的字节数计算公式为
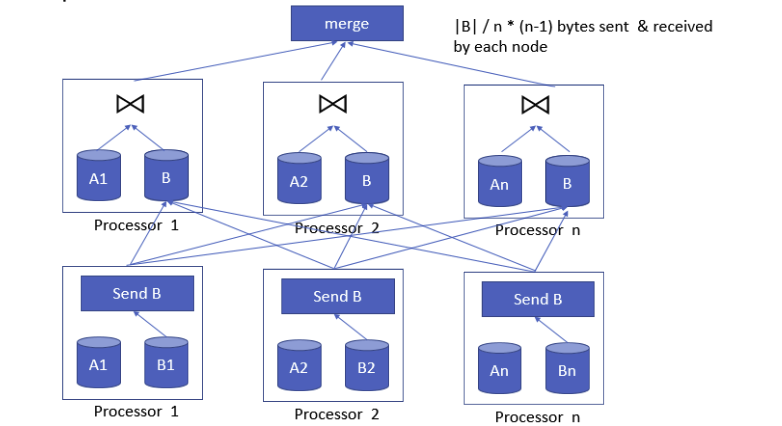
复制 vs. 分区
- 复制需要每个节点将较小的表发送给所有其他节点
- 每个节点发送
(|T| / n) * (n-1)字节 - 而重分区一个表的情况下,每个节点发送
((|T| / n) / n) * (n-1)字节
- 每个节点发送
- 在什么情况下,复制会优于重分区来执行连接操作?
- 如果较小表的大小 小于 需要重分区一个或两个表时发送的数据量。
- 还需考虑连接操作的成本:使用复制的表时成本会更高。
例子:假设
|B| = 1 MB,|A| = 100 MB,n = 3
需要对 A 进行重分区(B 按连接属性分布)。
重分区策略:重分区 A 的每个节点数据量为
|A| / 3 / 3 * 2 = 22.2 MB- 这个数据量明显大于B表大小,所以重分区A表开销较高
- 连接操作将 .33 MB 的数据与 33 MB 的数据进行连接。
复制策略:广播 B 的数据量为
|B| = 1 MB,即1 / 3 * 2 = 0.66 MB。- 连接 1 MB 数据与 33 MB 数据进行连接。
结论: 分布式数据库执行连接操作时
- 当较小表的大小小于重分区时所需传输的数据量时,复制会是更好的选择。复制可以避免复杂的重分区操作,尤其是当较小表的大小相对较小时
- 如果需要进行连接的表大小较大
假设我们有两个表 A 和 B,它们分布在 3 个节点上。
A 的大小为 9 MB。
B 的大小为 90 MB。
连接条件是
A.a = B.b。
- B 表根据 b 属性进行了哈希分区,而 A 表没有根据 a 属性分区。
如果我们执行以下操作,每个节点需要发送多少数据:
- 重分区 A 表。
- 复制 A 表。
Solution: 1. (9 / 3) / 3 * 2 = 2MB ; 2. 9 / 3 * 2 = 6MB
其他选择
- 预先复制小表
- 如果空间允许,是一个不错的选择
- ”半连接“
- 首先,将 B 表的连接属性值(例如
B.b)的列表发送给 A 表所在的节点。 - 然后,A 表仅选择那些与 B 表中的值匹配的记录,并将这些匹配记录发送回 B 表所在的节点
- 最后,B 表使用从 A 表接收到的匹配记录列表来完成最终的连接计算
- 适合处理宽表(列数多的表),因为宽表的数据量较大,直接传输会很耗费资源。通过预过滤,只传输在 B 表中实际存在的值,避免了不必要的数据传输,提高了效率
- 首先,将 B 表的连接属性值(例如
半连接的例子
聚合策略
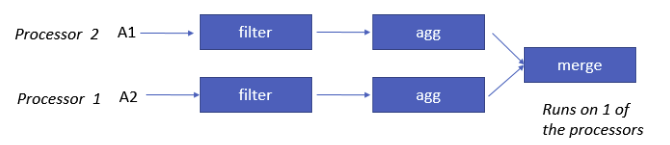
通常来说,每个几点
DP并行处理 vs 一般的并行处理
无共享分区并行是主流的方法。
为关系模型欢呼!
在并行化系统时,应用程序无需更改(物理数据独立性!)。
可以在不更改应用程序的情况下调整和扩展系统!
可以任意划分记录,无需同步。
基本上没有同步,除了设置和拆除阶段。
没有障碍、缓存一致性等问题。
数据库事务在并行处理中工作良好。