Lec 5 数据库存储管理
我们专注于面向磁盘的DBMS架构,至顶向下存储层次中,离CPU越近速度越快,但是空间更小, 且单位成本更高。
先总览面向磁盘的DBMS。数据库完全在磁盘上,数据库文件的数据被组织成页(pages),第一页为目录页。为了操作数据,DBMS需要将数据搬到内存,它通过缓冲池(buffer pool)来管理数据从磁盘到内存的来回搬动。DBMS有一个执行引擎用来执行查询(queries),执行引擎会询问缓冲池特定页面,缓冲池会小心地将页数据带过来,并给到执行引擎指向内存中该页的指针。缓冲池管理器会确保执行引擎在这部分内存操作时,页仍然保持在那。
存储管理上,OS vs DBMS
Outline
有两个主线问题
- DBMS如何表示用磁盘上的文件来表示数据库?
- DBMS如何管理内存,以及从磁盘上往返移动数据的?
分为7个部分讲解
- OS vs DBMS的存储管理
- 文件存储
- 页的布局
- 元组的布局
- 结构化日志存储
- 数据表示
- 系统目录
1. 存储管理: OS vs DBMS
在高层次设计目标来看,DBMS需要支持数据库能够超过可用内存。因为R/W磁盘非常昂贵,磁盘需要非常小心的管理,我们非常不希望花费大量的Stall(停顿)来从磁盘中Fetch数据,导致系统变得很慢。我们希望DBMS在同时处理多个查询(比如上一下再等待fetch,但是可以执行另外一个查询)。这个设计目标优点类似虚拟内存。一种实现虚拟内存的方式就是通过mmap系统调用,映射一个进程地址空间的文件内容,这让OS有义务将其刷回磁盘。不幸的是,这意味着如果mmap触发了页错误,进程必须阻塞,而你并不希望在DBMS中当你想写入操作有种状况。
DBMS(大部分)总是想自己控制所有的东西,并且确实也能做的比OS好 。比如哪些数据正在被访问,哪些查询正在被处理。mmap当然也有应对这些问题解决方法,如下所示,历史中也有数据库采用这个方法。 比如SQLite, MongoDB(现在已经不用了)
- madvise: 告知操作系统你预计如何读取某些页面
- mlock:告知操作系统内存范围不能被换出
- msync:告知操作系统将内存范围刷新到磁盘
总得来说, 操作系统并不是你的朋友的!(论文: Are You Sure You Want to Use MMAP in Your Database Mangement System?)
2. 文件存储
DBMS 通常以专有格式将数据库存储为磁盘文件。有些使用文件分层,有些则用单一文件(比如SQLite),OS对这些文件一无所知,只有DBMS知道如何辨认它们的内容,因为它被编码成DBMS特有格式。DBMS的存储管理器(storage manager)负责维护数据库文件,它将文件组织为页面集合,并且,跟踪已经读取出或写入页面的数据, 跟踪这些页面的可用空间
页面的概念
在DBMS里面有3种“页面”概念,默认是说第三种
- 硬件页面(hardware page),通常是4KB
- OS页,通常4KB
- 数据库页(1K ~ 16KB)
- 4K: SQLlite, Oracle
- 8K: SQL Server 、PostgreSQL
- 16K: MySQL
- 更大的页需要的系统调用就比较少
一个数据库页面是固定大小的数据块,可能跨1个或多个文件。也能够包含多种数据类型(元组、元数据、索引、日志记录等)。大多数系统不会在同一个页混合多种数据类型(比如存记录的和存日志的不会混在一起),有些系统要求页面是自包含(self-contained)的,即解释这个页所有元数据信息。每个页面都有一个唯一标识符,页ID(如果单个文件的话,页ID用文件偏移表示),绝大部分DBMS 使用一个间接层将页面ID映射到 <某个文件路径 + 偏移>, 顶层系统会询问某个页号,存储管理器将必须通过页号转成某个文件及偏移量来找到这个页。
大多数数据库管理系统(DBMS)采用固定大小的页(fixed-size pages)设计,以避免支持可变大小页(variable-sized pages)带来的工程复杂度。例如,若使用可变大小页,删除页时会在文件中产生空洞(hole),导致DBMS难以高效复用这些空间存放新页;空间管理需要额外的元数据跟踪碎片,增加存储引擎的实现难度。
存储设备能够保证硬件页大小(如4KB)的原子写入,这意味着我们的数据库页若大于硬件页,崩溃时可能导致部分写入,需要采取额外的手段来修复不一致性。
页面的存储
有很多种方法在磁盘上找到DBMS想要的页的位置,大致有如下
- 堆文件组织(最简单的方式)
- 树形文件组织
- 顺序/有序文件组织(ISAM)
- 哈希文件组织
在层次结构的这一点上,我们不需要了解页面内部的具体内容。
堆文件组织
堆文件是一个无序的页面集合,元组以随机顺序存储在页面中。每页都是等大小的。每页由头部信息和记录组成。头部信息包含了每条记录的起始偏移量、该页的哪些部分被占用等信息。而且,假如只有一个堆文件,想要获取堆文件的某个页ID的页所在位置,只需要通过页序号*页大小即可。另外, 读、写、缓存数据都是在页的粒度下进行,堆扫描时, 按照存储顺序读取堆文件。即使有谓词,也要读取所有的文件。

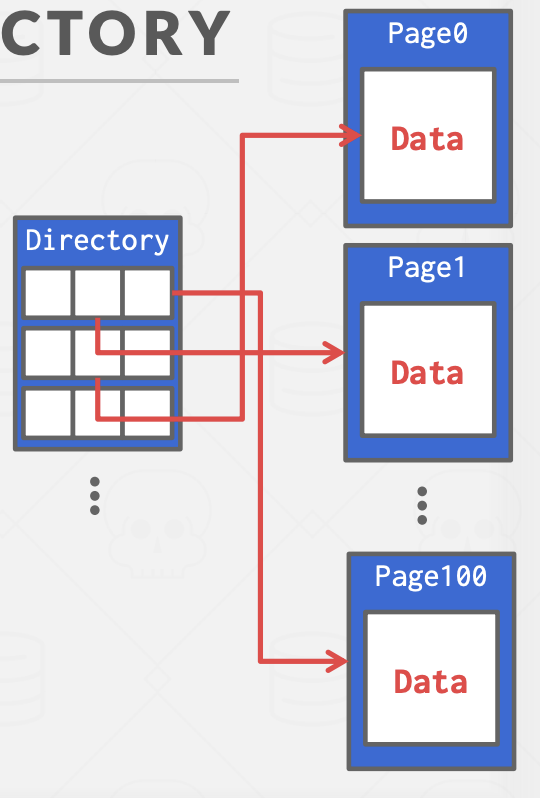
更通用说,DBMS能够通过给定页ID找到在磁盘的页,需要借助链表页或者页目录实现。
链表法:头部页维持着空闲页链表和数据页链表。缺点:当DBMS需要找特定页时,他需要做线性扫描
页目录法:DBMS维护这一个特殊页,里面跟踪着数据页位置以及每页的空闲位置。(后面有详细介绍),缺点:必须确保目录页面与数据页面保持同步。
树形文件组织
todo
顺序文件组织
todo
哈希文件组织
todo
3. 页面的布局
每个页都包含一个头部,里面记录着这个页的元数据
- 页大小
- checksum
- DBMS版本
- 事务可视性信息
- 自包含信息(有些系统比如Oracle需要这个,关于怎么解读这些数据的schema信息等,用于恢复)
除了头部外,如何布局数据呢? 一个简单的方法是跟踪该页有多少条记录(元祖),并且每次新增元祖都从尾部添加。但是问题出现在元祖删除和元祖有可变属性的场景时。
主要有两种方法来布局数据:一个是分槽页(Slotted Page)表示,一个是日志结构( log-structured)表示
分槽页
最通用的布局方式。 用slot数组映射出所有元组的起始位置,这个方法适合固定或者不定长的元组。页结构的组成同样为头部+数据。其中头部记录已使用的槽位数(used_slots)、最后一个槽位的起始偏移量(last_slot_offset)和槽位数组,存储每个元祖的起始位置。而数据存储区域,元祖是从尾部向头部填充,区别于槽位数组从页头部向尾部填充。
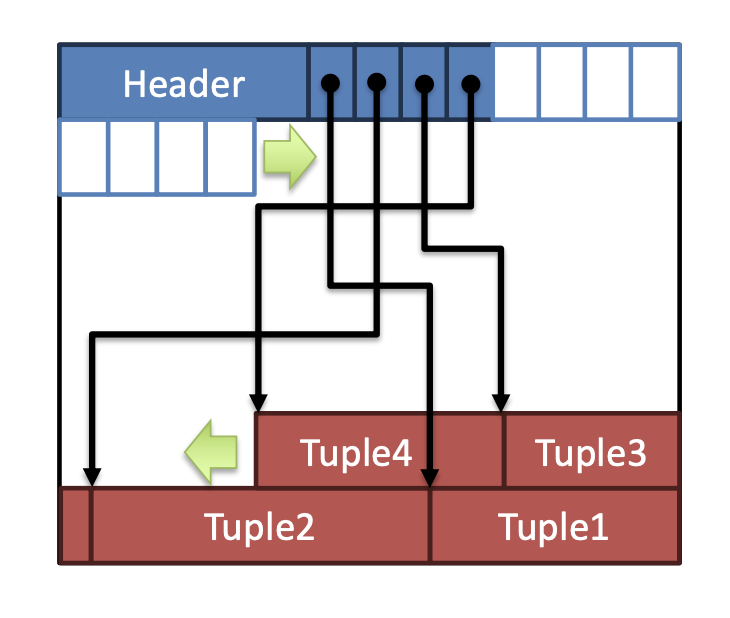
如果我删除了元组3,会发生什么?
Solution:将元祖3对应的slot标记为空闲(比如设置为-1或者NULL),used_slots(已用槽位数)减1,其他元祖的偏移量保持不变,元组3的数据仍保留在页中,但逻辑上被视为“可覆盖”的无效数据。不会立即整理空间,避免额外I/O,当页内空间碎片化严重时,可以触发页内整理。□
如果我插入/更新元祖会发送什么?
Solution: 有两个情况:
向页面插入一个元组的处理:
→ 检查页面目录,找到一个有空闲槽的页面。
→ 从磁盘取回页面(如果不在内存中)。
→ 检查槽数组,找到页面中适合新数据的空闲空间并插入。
当需要根据记录 ID(Record ID 或 RID)更新一个已有的元组时
→ 检查页面目录,找到页面的位置。
→ 从磁盘取回页面(如果不在内存中)。
→ 使用槽数组找到页面中的偏移量。
→ 覆盖现有数据(如果新数据适合)。□
分槽页面设计存在的一些问题:
- 碎片化(Fragmentation):删除元组后可能在页面中留下空隙,导致空间无法充分利用;
- 无效磁盘 I/O(Useless Disk I/O):由于非易失性存储的块式特性,更新一个元组时必须整个块都读入内存;
- 随机磁盘 I/O(Random Disk I/O):如果要更新 20 个不同的元组,磁盘读写器可能需要跳转到 20 个不同位置,速度会很慢。
日志结构页
如果我们面对的是一个只能创建新页面而不能重写已有页面的系统,比如云存储(S3),HDFS, 那么日志结构化存储模型(Log-Structured Storage)就是专门为这种假设而设计的,并能解决上述的一些问题。
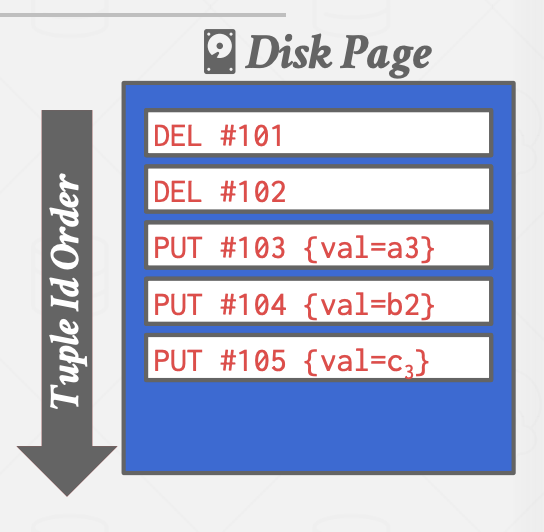
DBMS 不再直接存储元组,而是只记录对元组的更改日志。它会将新的日志条目追加到内存缓冲区中,而不检查之前的记录,然后将这些更改按顺序写入磁盘。
- 每条记录包括元祖的唯一标识符、操作类型(PUT 或 DELETE),如果是PUT、还包括元祖的内容;
- 读取记录时,DBMS 会从日志文件的末尾向前扫描,查找元组的最新内容
- 写入速度快,但读取可能较慢。磁盘写入是顺序的,已有页面不可修改,能减少随机 I/O,适合只追加写入的场景
- 为避免读取时太慢,DBMS 可以维护索引以便跳转到日志中的特定位置;
- 日志文件最终会变得非常大,DBMS 可定期压缩(compaction)日志,只保留每个元组的最新更改;
- 压缩后,每个元组只剩下一个版本,不再需要保留写入顺序,因此可以按 ID 排序以加快查找。这类结构称为 有序字符串表(SSTables, Sorted String Tables);
当页面满了之后,数据库管理系统(DBMS)会将其写入磁盘,并开始使用下一个页面来存储记录。
- 所有的磁盘写入操作都是顺序的。
- 磁盘上的页面是不可变的。
要读取具有特定ID的元组,DBMS会查找与该ID对应的最新日志记录。
- 从最新到最旧扫描日志记录。
- 维护一个索引,将元组ID映射到最新的日志记录。
- 如果日志记录在内存中,则直接读取。
- 如果日志记录在磁盘页面上,则取回它。
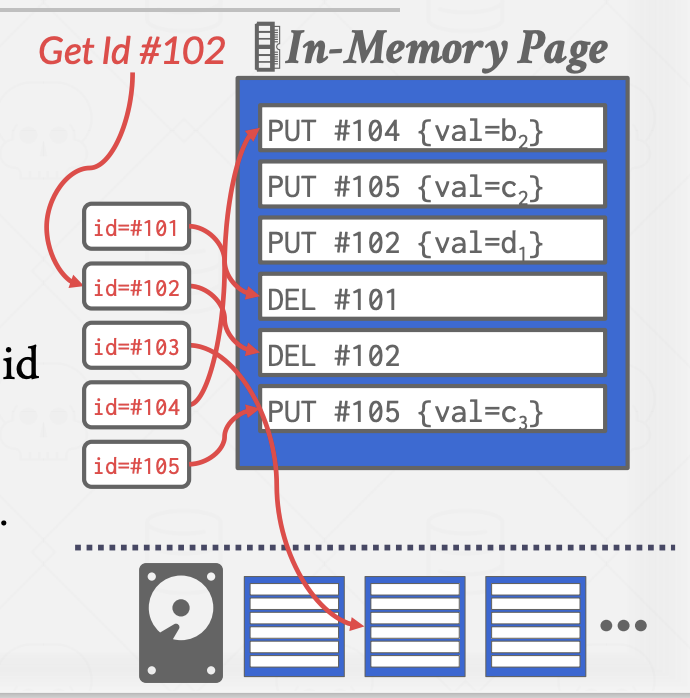
压缩页
日志会永久增长,因此DBMS需要定期压缩页来减少空间的浪费

在页面被压缩后,数据库管理系统(DBMS)不需要维护页面内记录的时间顺序。每个元组ID在页面中最多出现一次。相反,DBMS可以根据ID顺序对页面进行排序,以提高将来查找的效率。这被称为Sorted String Tables(SSTables)。
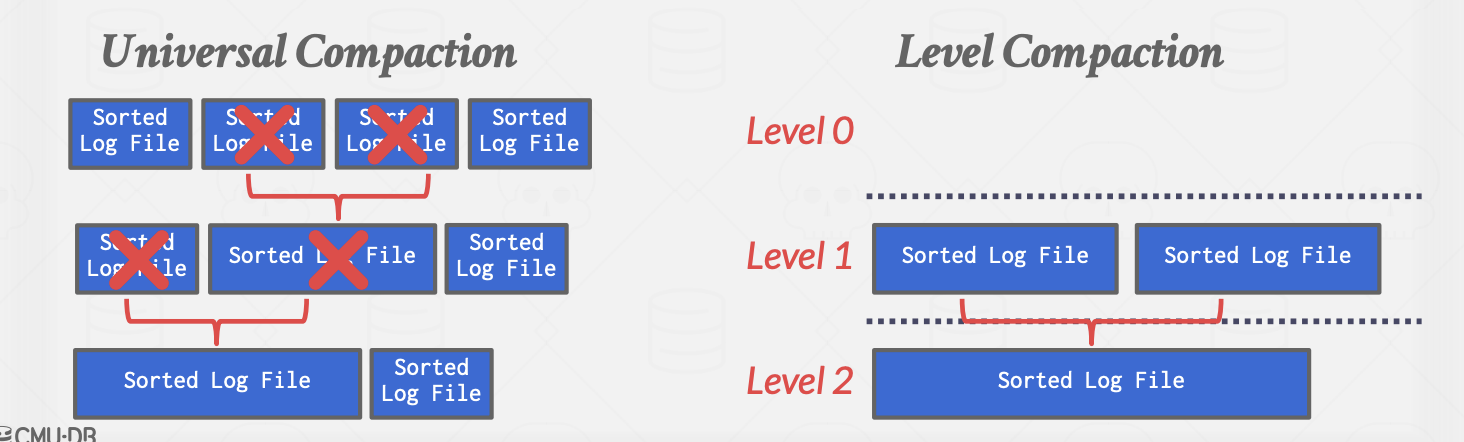
用RocksDB而言有两种方式,
- Universal Compaction
- Level Compaction
日志结构化存储管理器如今更为常见。这在一定程度上归因于RocksDB的普及。
这种方法的一些缺点包括:
- 写放大(Write-Amplification):写了一个记录,然后就不碰它了,导致每次压缩都得带上它,但是又消除不了。
- 压缩代价高昂
索引组织存储
可以看到,无论是面向页面的存储(page-oriented storage)还是日志结构化存储(log-structured storage),都依赖额外的索引来查找单个元组,因为表本身是无序的。而在索引组织存储方案中,DBMS 直接将表中的元组作为索引数据结构的值来存储。
DBMS 会采用一种类似“槽式页面(slotted page)”的页面布局方式,并且页面中的元组通常会按照键值进行排序。
4. 元组的布局
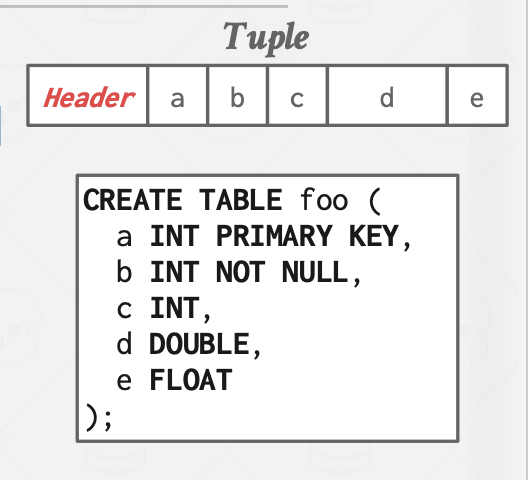
一个元组本质上是一系列字节,解释这些字节为属性类型和值是 DBMS 的职责。元祖包括如下信息:

元祖头部: 包含了元祖的元数据。
- 包含用于并发控制协议的可见性信息(比如那个事务创建/修改了这个元祖的信息)
- NULL值位图(bitmap):标记哪些属性值是NULL
- 注意:元祖头部不需要存储数据表的schme信息,因为schema是全局定义的。
元祖数据:存储实际的属性值
属性通常按照创建表时定义的顺序进行存储
大多数 DBMS 不允许一个元组超出一个页面的大小(即每个元组必须完整地存储在一个页面内)
唯一标识符
- 数据库每个元祖都有一个唯一标识符
- 最常见的形式: 页ID + 偏移量或者槽位编号(offset 或 slot)
- 应用程序不能依赖这些标识符来表达任何语义,它们仅用于 DBMS 内部管理。因为这个ID可能会被数据更改,这是逻辑和物理之间的抽象或者分离,我们知道元组是什么即知道他们的逻辑信息,但是实际存储在哪里,如何存储,我们不应该知道。
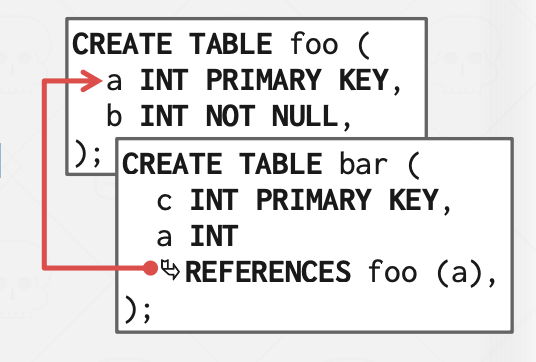
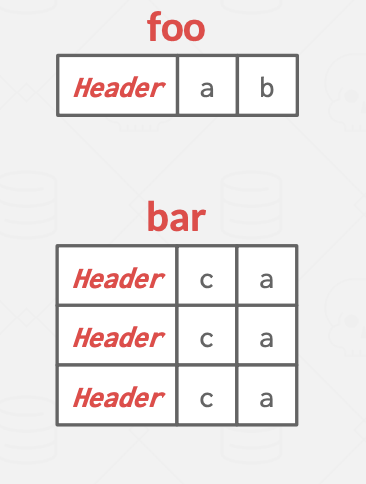
去范式化的元祖数据:
- 如果两个表有关联,物理上进行非规范化(例如,"预连接")相关元组,并将它们存储在同一页面中,也有不少NoSQL这样做
- 这样可以加快读取速度,因为 DBMS 只需要加载一个页面而不是两个
- 但这会让更新操作变得更昂贵,因为每个元组需要更多的存储空间
5. 数据表示
元组中的数据本质上只是字节数组(byte arrays),不会记录各个属性的具体数据类型。由 DBMS 来负责跟踪这些信息,并解释这些字节。数据表示schema(data representation scheme)是指DBMS如何将某个值以字节的形式存储起来。
DBMS 希望元组在内存中是按字对齐(word-aligned)的,这样 CPU 在访问数据时不会出现意外行为,也无需额外操作。通常有两种方法实现对齐:
- 填充(padding):在某些属性之后添加空位(bits),以确保整个元组是字对齐的;
- 重排(reordering):在物理布局中调整属性的顺序,以确保对齐;
数据类型
在元组中可以存储的高层次数据类型主要有五种:整数(integers)、变精度数(variable-precision numbers)、定点精度数(fixed-point precision numbers)、变长值(variable length values)、以及日期/时间(dates/times)。
整数
大多数DBMS用”原生“C/C++类型,根据IEEE-754标准,这些值是固定长度。例如,INTEGER、BIGINT、SMALLINT、TINYINT`
变精度数
这些是非精确的、变精度(variable-precision)数值类型,使用的是由 IEEE-754 标准定义的“原生” C/C++ 数据类型。这类数值的长度是固定的(fixed length)。
与任意精度数(arbitrary precision numbers)相比,变精度数的计算速度更快,因为 CPU 可以直接对其执行指令。但在执行计算时,可能会出现舍入误差(rounding errors),因为某些数值无法被精确表示。
例如:FLOAT、REAL
定点精度数
这些是具有任意精度和小数位数(scale)的数值类型。它们通常以精确的、变长的二进制形式存储(几乎类似于字符串),并附带一些元数据,用于告诉系统诸如数据长度以及小数点位置等信息。
当不能容忍舍入误差时,会使用这类数据类型,但为了获得这种精度,DBMS 需要付出性能上的代价。
例如:NUMERIC、DECIMAL。
变长值
这些是表示任意长度的数据类型。它们通常带有一个头部信息(header),用于记录字符串的长度,方便系统跳转到下一个值的位置。这个头部有时还会包含一个校验和(checksum)用于校验数据完整性。
大多数 DBMS 不允许一个元组的大小超过单个页面(page)的容量。如果超出,有些系统会将数据存储在一个特殊的“溢出页面(overflow page)”上,并在元组中保存对该页面的引用。一个溢出页面可以继续指向其他溢出页面,直到所有数据都被存储完为止。
某些系统还允许将这类大数据值存储在外部文件中,此时元组中只包含一个指向该文件的指针。例如,如果数据库用于存储照片信息,DBMS 可以将照片实际存放在外部文件中,而不是占用数据库的大量空间。但这种方式的缺点是:DBMS 无法直接操作这些文件的内容,因此无法提供持久性(durability)或事务(transaction)保护。
日期与时间
日期/时间的表示方式因系统而异。通常,它们被表示为自 Unix 纪元(Unix epoch)以来经过的某种单位的时间(微秒或毫秒)。
例如:TIME、DATE、TIMESTAMP。
空值数据类型
在 DBMS 中,有三种常见的方法用于表示空值(NULL):
- 空值列位图头(Null Column Bitmap Header):在集中式的头部存储一个位图,用于标记哪些属性是 NULL。这是最常见的方法;
- 特殊值(Special Values):为某种数据类型指定一个特殊的值表示 NULL(例如,
INT32的最小值); - 每个属性独立标志(Per Attribute Null Flag):为每个属性单独存储一个标志位来表示是否为 NULL。由于这种方式在内存使用上效率较低(为了保证字对齐,每个标志不能只占一个比特),所以不推荐使用。
6. 系统目录
系统目录(system catalogs),也称目录管理器(Catalogs Manager)。它会维护一个内部目录,用于存储数据库的元数据(meta-data), 包含数据库使用的表的schema信息,这些信息帮助系统确定元组的布局
元数据的内容包括:
- 数据库中有哪些表(tables)和列(columns),以及这些表上有哪些索引(indexes);
- 数据库的用户信息,以及他们拥有哪些权限(permissions);
- 关于表的统计信息,以及这些表中包含的内容(例如某个属性的最大值);
几乎所有的DBMS的元数据保持与数据一样的格式,可以使得系统在使用上更加紧凑、简 单:用户可以使用同一种语言和工具来研究其他数据的元数据,这是是重要的经验。它们会使用特殊的代码来“引导(bootstrap)”这些目录表的建立。
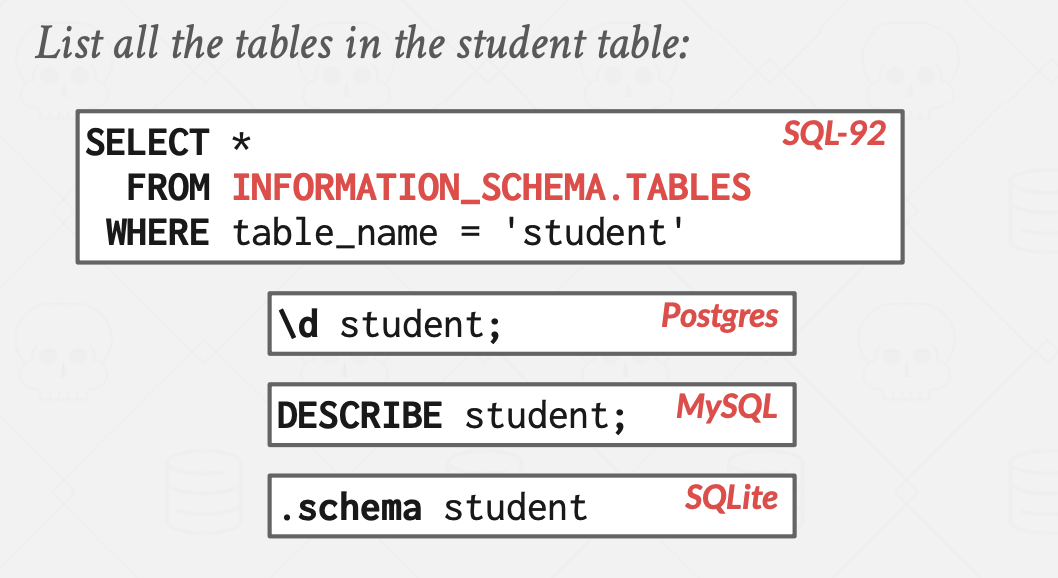
获取表的schema
你可以查询DBMS的内部INFORMATION_SCHEMA目录,获取有关数据库的信息。
- INFORMATION_SCHEMA是ANSI标准的一组只读视图,提供有关数据库中所有表、视图、列和过程的信息。
- DBMS还具有非标准的快捷方式来检索这些信息。