Lec 3 Schema设计
阅读资料:
1、 Section 3.2 and 3.3 of "A Practical Introduction to Databases“
2、 Section 2 of of "A Practical Introduction to Databases"
第一篇阐述了Ted Codd提出的“关系代数”,我们将在讲座开始时讨论这一内容,以及基于函数依赖概念的形式化模型,该模型可以用来推理关于模式是否存在导致数据库系统执行中操作问题的异常。您应专注于理解BCNF和3NF;我们不会讨论更高的范式
第二篇讲述了ER建模,这是一种实际的方法,可以用来建模数据库并生成关系数据库模式。这些阅读的关系在于,ER建模通常会生成符合3NF/BCNF的关系模式,尽管这并非绝对
请考虑并准备在讲座中回答以下问题:
- 模式归一化解决了哪些问题?您认为这些问题重要吗?
- BCNF和3NF之间有什么区别?是否有理由更偏好其中之一?
- 想象您最近处理过的数据集,并尝试推导出相应的函数依赖关系集合。在以这种方式对数据建模时,您需要做出什么假设?
- ER建模通常如何导致BCNF/3NF模式?
大纲
- 关系代数
- 规范化
- 数据模型
关系代数
关系代数(relational algebra)是一种能够作用在关系的一组算术操作,关系代数可以被视为一种能够表达数据查询方式的机制,数据是存储在关系里面的。关系代数对于理解关系数据库如何表示和优化查询(queries)很重要。 除了基本的关系代数,还有分组、聚合操作,连接操作。
单目计算
选择
投影
重命名
叉积与连接
叉积
连接
自然连接
集合操作
除法
查询
关系代数的操作作用于关系,并且结果也是关系,
操作序列
表达式树
规范化
(关系对应表,属性对应列,元组对应行)
规范化(Normalization)是修改数据库结构以满足某些要求的过程。这些要求由一系列的范式(normal forms)定义。
规范化的一个主要目标是使维护正确的数据集合更加容易。正确的数据是完整且自洽(self-consistent)的。数据库不应包含与我们理解的事实相矛盾的数据。
为了阐明规范化的必要性,作如下分析
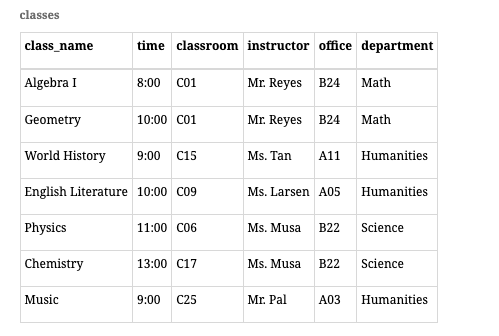
- 插入异常: 新教师加入学校,没有课程,这样导致每个属性选择NULL值或者是创建虚假课程
- 删除异常,如果删除了English Literature,那Larsen的信息全都没了
- 更新异常:考虑Reyes更换办公室,如果忘记更新其中一个,就会导致数据内部不一致。
键 vs 超键
关系的超键是该关系的某些属性的子集, 这些属性能够唯一标识关系中的任何元组。考虑图书馆关系。我们断言,属性集合{author, titile, year}是一个超键,能够保证对关系中任何元组唯一性。关系的任何属性的子集,如果它是某个已知超键的超集,那么它也是关系的超键。{author, title, year, author_birth} 必须是一个超键,因为它是一个已知超键的超集。
而关系的键是关系的一个超键,我们不能从中减去任何属性并仍然得到一个超键。
确定关系的键是分析关系是否已经相对于 2NF 或更高范式规范化的关键步骤
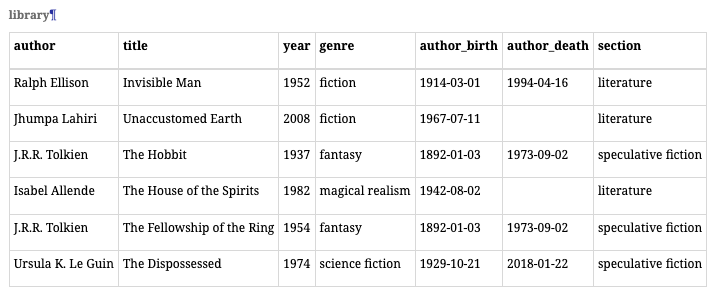
函数依赖
函数依赖,与超键密切相关,是关于关系的两个属性集的声明。考虑两个属性集,我们分别标记为X和Y。如果关系中的两个元组在X上的值相同,那么它们在Y上的值也必须相同,这时我们称X函数决定Y,或者Y函数依赖于X。这个关系用符号表示为X→Y。
和键一样,FD是我们对数据施加的约束。另一种理解函数依赖的方法是:如果你有一个只包含X或Y的属性的关系,那么X将是该关系的超键。也就是说,X唯一地确定了X和Y的并集中的所有内容。(现在我们可以提供另一种超键的定义,即关系中某个属性的子集函数决定了关系的所有属性集。)
另一种理解FD的方法是:如果X函数决定Y,那么如果我们知道X中的值,我们就知道或可以确定Y中的值,因为Y只是关于X的单值事实。
以下是一些图书馆关系的更多FD示例:
- {author, title} →
- {author} →
- {genre} →
- {author, title} →
- {title, genre} →
类型
- 平凡
- 右集是左集的子集
- Ex:第五个
- 非平凡
- 右集有部分不在左集
- Ex:第四个
- 完全非平凡
- 左右两个集合的交集是空集
- Ex:前三个
推理规则
反身规则(Reflexive Rule)
- 如果Y是X的子集,那么X→Y
增强规则(Augmentation Rule)
如果X→Y成立,那么XZ→YZ也是
传递规则(Transitive rule)
- 如果X→Y,Y→Z,那么X→Z
分解规则(Splitting rule (or decomposition, or projective, rule))
- 如果X→YZ成立,那么X→Y和X→Z也成立
合并规则
- 如果X→Y且X→Z,那么X→YZ也成立
闭包
闭包的概念是我们从某个属性集出发,通过应用一系列FD规则,能够推导出该属性集所能确定的所有其他属性。换句话说,闭包帮助我们了解一个属性集的力量——它能确定哪些其他属性。
通过计算属性集的闭包,我们可以验证该属性集是否是一个超键(能唯一标识一条记录的属性集)。此外,闭包在数据库的规范化过程中也起着关键作用,有助于我们分解数据库表并消除冗余。在这个例子中,作者和书名的组合({author, title})可以唯一地确定一本书的所有相关属性,这意味着这个组合是图书馆关系的一个超键。我们通过应用推理规则逐步扩展这个属性集,最终得到它能够确定的所有属性。
2,3范式和BCNF
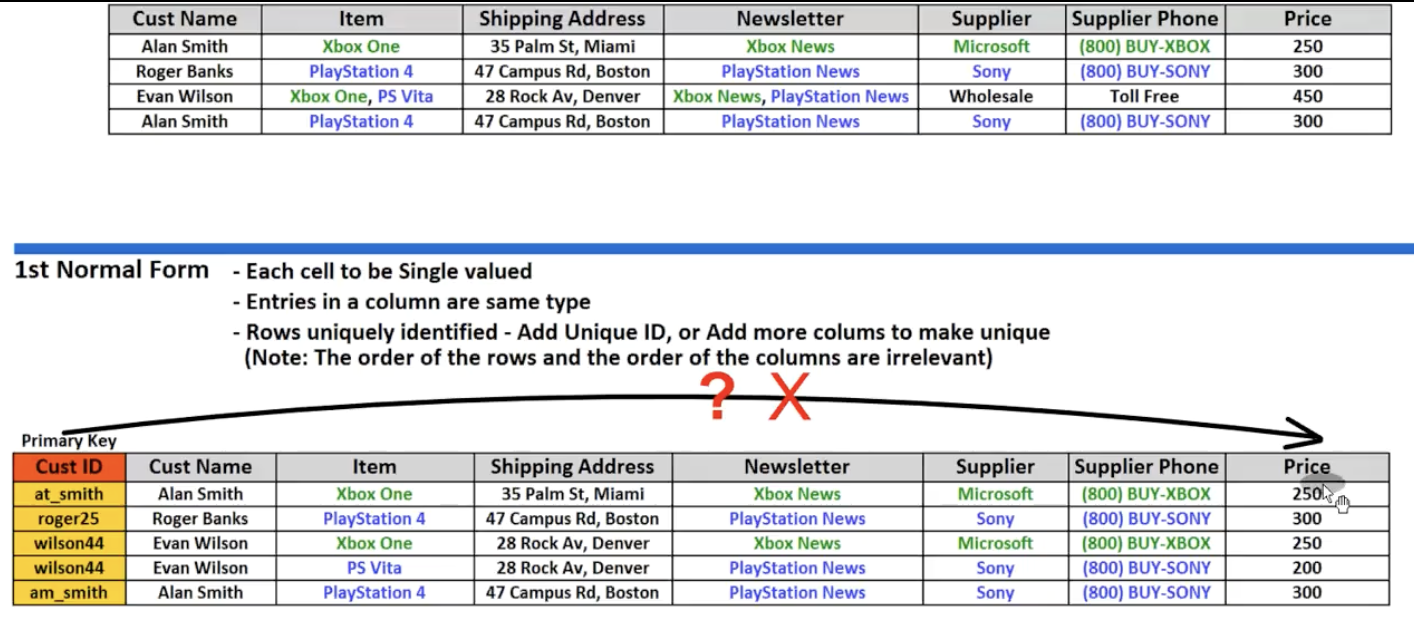
1NF
- 属性是单值的
- 同属性的类型是相同的
- 每个元组应该都是独一无二的——添加uid,或者是多个属性确定唯一性
- EX:
2NF
确保关系中的所有非键属性依赖于键,而不是仅仅依赖于键的某个真子集。
如果一个关系的键只有一个属性,它自动满足2NF,因为不存在真子集的情况。
EX1: 图书馆关系(library)不满足2NF。图书馆关系的键是{author, title}。然而,假如我们有以下函数依赖(FD):
{author} →
在这个依赖中,左侧只包含author。我们称上述FD违反了第二范式。
EX2:
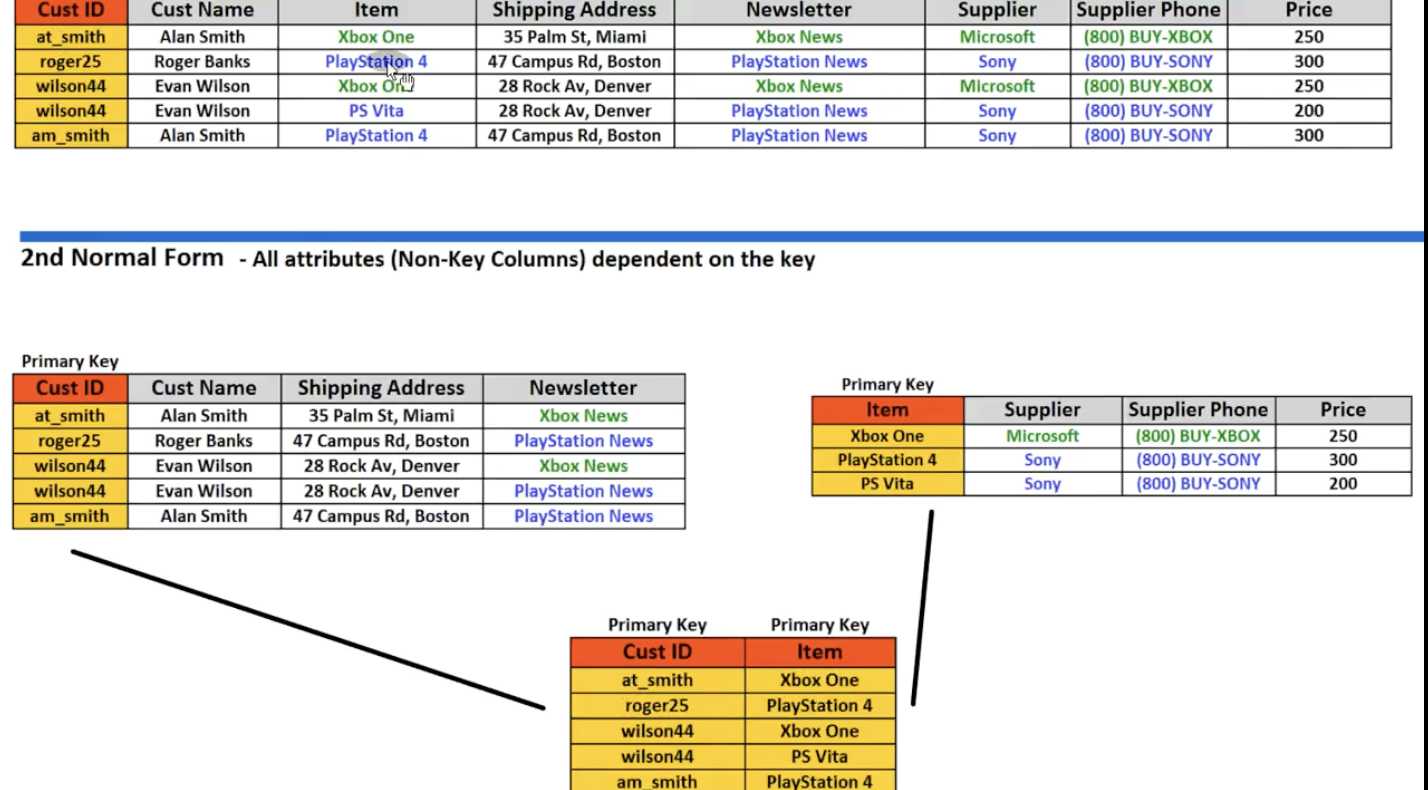
3NF
在满足2NF的基础上,要求关系中不存在非键属性依赖于其他非键属性。这意味着所有非键属性必须直接依赖于键,而不能间接依赖于其他非键属性。
Ex: 违反3NF。考虑图书馆关系中的依赖:
{genre} →
这违反了3NF,因为genre和section都不是任何键的一部分。
Ex2:
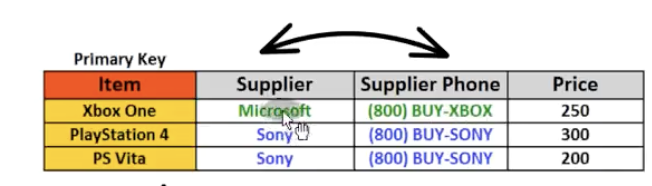
供应商电话依赖供应商,即存在非键属性依赖于其他非键属性
BCNF
Boyce-Codd范式(BCNF):这是比3NF更严格的范式(3.5范式),要求关系中的每个非平凡FD的左侧必须是超键。这意味着BCNF对3NF的要求更加严格,但确保了更强的数据完整性。
BCNF的定义:一个关系处于BCNF当且仅当它处于1NF,并且对于关系中的每个非平凡函数依赖(FD),X是关系的一个超键。
与3NF的比较:
(候选键是最小的超键)
3NF和BCNF之间的区别在于3NF允许函数依赖的右侧是关键属性的子集。这种情况相对少见,这也是为什么大多数符合3NF的关系也符合BCNF的原因。我们将在后续章节中进一步探讨这种区别
分解属性
规范化分解的两个理想属性。
完全恢复性:分解后的关系必须能够通过联接恢复原始关系。这意味着联接后的关系必须包含原始关系中的所有元组,并且没有额外的元组。
- 实际上,BCNF分解算法能够满足这一条件;而任意分解不一定能做到这一点
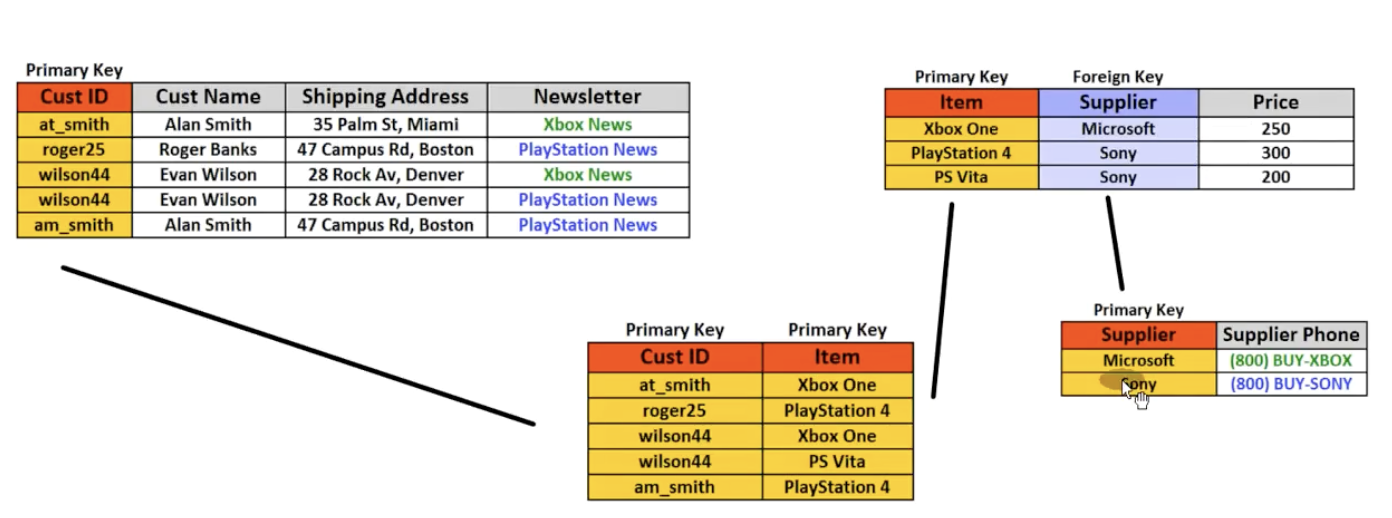
- EX:X属性(作者)作为外键保留,Y属性(作者出生、作者去世)可以被移除在。共享的外键上联接这些关系,可以将Y值恢复到正确的元组中。
依赖保留:所有由原始函数依赖暗示的约束在分解后的数据库中都得到保留。
通过将关系规范化到3NF,我们可以保证这一属性,但BCNF并不总是能满足这一要求。
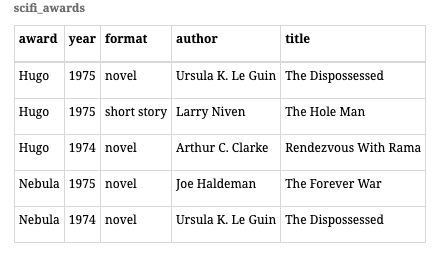
EX:涉及Hugo奖和Nebula奖,这两个奖项每年在多个类别中颁发,假设给定格式的作品在每年中只能获得一个奖项。如果我们知道奖项、年份和格式,我们可以明确确定获奖作品。有两个重要依赖
- 反映每年每种格式只能有一个作品获奖
- {award, year, format} -->
- 不违反3NF或BCNF,因为左侧是关键属性
- 承认每个作品属于某种特定格式
- {author, title} ->
- 属于3NF但不属于BCNF的狭隘类别,因为{author, title}不是该关系的关键属性。即当出现AB→C和C→B时就会出现。然而,FD并不违反3NF,因为右侧({format})是关系的一个关键属性的子集
- 反映每年每种格式只能有一个作品获奖
如果我们按照BCNF的分解方法对一个违反BCNF的关系进行分解,得到的分解关系必须能通过连接恢复原始关系,并且保证原始数据的正确性。在分解后,我们会得到两个关系,例如:
scifi_awards_1:包含属性{author, title, format}scifi_awards_2:包含属性{award, year, author, title}
原始的依赖
award, year, format -> author, title在这两个新关系中不再适用。这样,即使这两个新关系在BCNF下是合理的,数据的完整性约束(如同一年同一类别的奖项只会颁发给一个作品)可能在分解后被破坏具体数据示例 例如,我们在两个新关系中存储了如下数据:
scifi_awards_1:记录了作者、标题和格式scifi_awards_2:记录了奖项、年份、作者和标题
在
scifi_awards_1中,Ursula K. Le Guin和Roger Zelazny的书籍在同一年都获得了Hugo奖。如果这两本书的类别相同,那么第二个关系(scifi_awards_2)中可能会出现无效数据,因为它们应该属于不同的类别。如果我们仅查看分解后的关系而不进行连接,就很难识别这种数据不一致性。解决方案 在这种情况下,保留原始关系的3NF可能更有利,因为我们可以利用主键
{award, year, format}来维持数据的一致性。尽管在3NF下可能存在一些冗余(例如作品可能出现两次),但这种冗余量相对较小。- 如果我们选择保留原始关系在3NF中,就需要在应用程序中处理BCNF违例引起的修改异常。这样,尽管数据可能存在冗余,但可以保持约束和数据的一致性。
- 如果我们决定将关系分解到BCNF水平,则需要在其他地方(例如应用程序逻辑中)强制执行丢失的约束,以确保数据的一致性。
多值依赖和第四范式(4NF)
违反BCNF的关系在正常的数据收集活动中经常出现。例如,一个Web服务器记录活动日志时,可能会记录用户信息以及用户在网站上访问的页面信息。这种情况下,用户信息在多个日志条目中重复出现,显然存在冗余。
相对而言,第四范式(4NF)违例在数据收集中不太常见。4NF解决的问题是在尝试将包含多个独立一对多关系的数据存储到一个关系中时出现的问题。在这种情况下的冗余更为微妙,较难识别。
数据模型
数据库创建需要分析和设计活动。分析可能包括与那些对要存储的数据有深刻理解的人讨论、与数据库的预期用户讨论以及对代表性数据的检查。设计则利用分析中获得的见解来生成能够正确存储必要数据并满足用户需求的数据库结构。分析和设计是相辅相成的活动;分析为设计提供信息,而设计又会揭示出需要进一步分析的新问题。分析与设计之间的互动能够消除由于理解不完全和错误假设而导致的问题。
分析和设计可以通过各种图形和非图形文档来进行。数据模型是创建数据库时最有用的一种文档。数据模型至少必须捕捉到各种数据类型及其相互关系。我们可以使用数据模型来推理数据,从而脱离 SQL 或编程语言的细节
本文的这一部分探讨了在不同抽象层次上的图形数据模型。我们首先讨论了E-R图,这是一种高级的数据模型。ERD 在分析与设计的交汇点上特别有用,有助于与用户和领域专家的讨论。然后解释了如何从 ERD 过渡到关系数据库。最后我们会探讨这些模型与关系数据库的更密切的对应关系。
ER图
Peter Chen 构思,并在 1976 年的一篇论文中描述
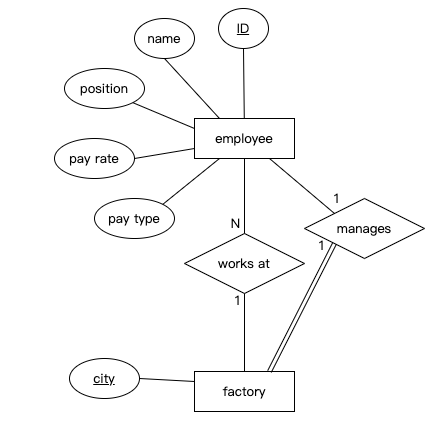
基本模型
- 实体:矩形
- 属性:椭圆形,连接到实体
- 键:每个实体至少一个属性可以唯一标志该实体的实力,用下划线标注
- 允许有多个
- 注意这与多个部分组成的键不同!!!
- 关系:两个或更多实体可能会参与到一个关系中。关系类似动词,用菱形表示,并连接到实体上
- 基数比
- 1:1
- 1:N
- N:M
- 参与度(participation):如果一个实体的每个实例都必须与关系中的另一个实体的实例匹配,则该实体被认为在关系中具有完全参与度。
- 每个工厂都有一个员工管理
其他模型选项
递归关系
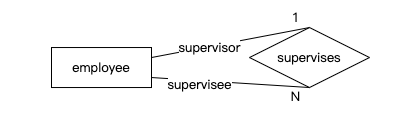
- 关系可以存在于一个实体与其自身之间。
- 每个员工(除公司负责人外)都有一个上司,这个上司也是另一位员工。这可以通过将员工连接到员工的一对多关系来轻松建模: 为了增加清晰度,我们在连接关系的线上标注了员工在关系中所扮演的角色:一个上司监督许多下属
弱实体
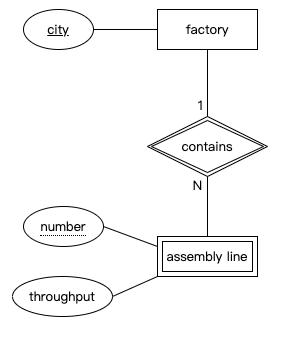
- 在某些情况下,我们可能希望为没有唯一标识符的实体建模,但该实体可以通过与另一个实体的关系唯一识别。例如,我们的计算机制造商的每个工厂都包含生产线。我们希望在数据库中跟踪每条生产线的某些信息,例如生产线的日生产量(它每天可以生产的计算机数量)。我们希望将这些建模为数据模型中的一个实体
- 当然,我们可以为每条生产线生成一个唯一标识符,但还有一种更自然的方式来识别生产线。在每个工厂中,生产线通常从1开始编号,最有可能按其在工厂车间中的位置排序。要识别特定的生产线,我们首先说明它所在的工厂,然后是它在工厂中的编号。
- 当一个实体依赖于另一个实体才能完全识别时,这个依赖实体称为弱实体,我们用双重轮廓的矩形来表示它。弱实体只有部分键或叫弱键——在我们的例子中,这就是生产线在工厂内的编号。我们用虚线下划线标注弱键。这种帮助弱实体获得唯一标识符的关系,我们称这种关系为识别关系,并用双重轮廓的菱形表示。父实体的键与弱实体的弱键共同构成了弱实体实例的唯一标识符。
复合属性
- 当我们的键本身是由多个属性组成时。我们不能简单地将每个组成部分的属性下划线,因为这将意味着每个属性本身都是一个键。相反,我们必须创建一个复合属性;我们在复合属性下划线
- EX:公司构建的每种类型的计算机(或“型号”)都是通过一个名称(表示某一系列的计算机)和一个编号(表示该系列的版本)来标识的。由于没有更好的名称,我们将这些组合为一个复合属性,标记为“designation”(指定)
多值属性
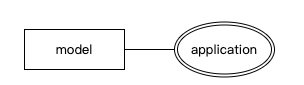
- 某些实体的属性并不是简单的值,而是值的列表或集合。由于在将数据模型创建为数据库时需要对这些属性进行特殊处理,我们通过双重轮廓来区分这些多值属性与常规属性
- 替代创建多值属性的一种方法是将可能的属性值建模为一个单独的实体,该实体通过多对多关系与原始实体相连。单独的实体将只有一个属性,并且其实例将表示可以与原始实体关联的可能值
派生属性(Derived attributes)
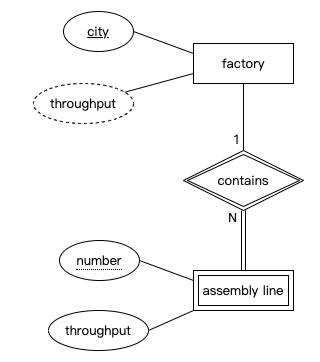
- 一种属性,它更倾向从数据模型中的其他值计算这些属性,而不是将它们存储在数据库中。例如年龄,会随着时间变化,需要定期更新。比如工厂的产量
关系属性(Relationship attributes)
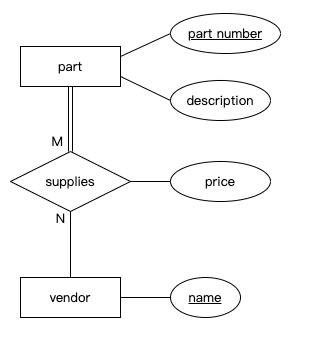
- 大多数属性都附加在实体上,但我们也可以将属性附加在关系上。当一个属性适用于实体的组合而不是单个实体时,我们这样做。这种情况最常见于多对多关系中
多元关系
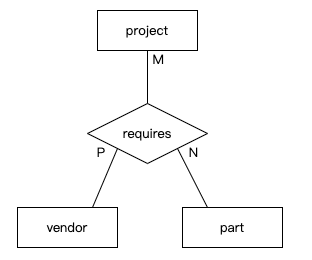
我们之前提到过,两个或两个以上的实体可以参与一个关系。虽然大多数关系是二元的,但你可能会遇到需要关联三个(或更多)实体的情况。
EX:规定某个项目的某种零件必须来自特定的供应商,而另一个项目的同样零件则必须来自另一个供应商。这里的关键点是,这种情况涉及三个实体之间的关系(零件、项目、供应商)