Lec 14 故障恢复(Part I)
阅读资料
ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging, 1992 ,读1-7节,泛读12和13节
恢复算法(Recovery algorithm)是保证数据库一致性、事务原子性和持久性的技术,当crash发生时,所有存在于内存但未提交到磁盘的数据将会丢失。恢复算法发挥崩溃后组织信息丢失的作用,每个恢复算法包含两个部分:
- 在正常事务处理期间保证DBMS能从故障中恢复的动作
- 在故障发生后,将数据库恢复到能够保证原子性、一致性和持久性的状态。
在恢复算法中最关键的两个原语是 UNDO 和 REDO。
这是一篇冗长且难度较高的论文,我们将在两次讲座的大部分时间里探讨它。重点理解ARIES恢复算法的核心。
存储类型
| 存储类型 | 数据持久性 | 典型示例 | 适用场景 |
|---|---|---|---|
| 易失性存储 | 断电丢失 | DRAM、SRAM | 高速缓存、内存计算 |
| 非易失性存储 | 断电保留 | HDD、SSD | 文件存储、数据库 |
| 稳定存储(理论) | 永不丢失(需冗余实现) | 无直接对应硬件,但可通过多设备冗余(如 RAID、分布式存储)来近似实现 | 关键数据备份(如金融交易、分布式系统) |
DBMS使用易失性存储(如内存)来缓存缓冲池中的页数据,因为易失性存储的读写速度远快于非易失性存储(如硬盘)。然而,DBMS 需要保证数据的持久性(Durability),因此为了性能考虑,允许缓冲池中存在脏页(Dirty Pages)(即已被修改但尚未写入磁盘的页),并在必要时才将其刷入非易失性存储。
故障分类
由于DBMS的组件基于不同存储设备划分,系统需应对多种可能的故障。其中部分故障可恢复,而另一些则无法自动修复。
Type #1: 事务故障
当事务执行过程中出现错误并被迫中止时,即发生事务故障。主要分为两类:
- 逻辑错误,事务因内部错误条件无法完成(如违反完整性约束、数据一致性冲突)
- 内部状态错误:DBMS 因系统状态异常必须终止活动事务(如死锁)
恢复方式: 通过事务日志UNDO未提交的操作,确保数据库恢复到一致状态
Type #2: 系统故障
系统故障指运行 DBMS 的底层软件或硬件意外失效,需通过崩溃恢复协议处理。
- 软件故障: DBMS实现缺陷导致系统中断(如未捕获的除零异常)
- 硬件故障:主机意外崩溃(如断点)。此时假设非易失性存储数据未被破坏(即故障停止假设,Fail-stop),以简化恢复流程
恢复方式: 利用预写日志(WAL)和检查点(checkpoint),通过REDO重放已提交的事务,UNDO未提交失误。
Type #3 存储介质故障
存储介质故障指物理存储设备损坏且无法修复,需从备份中还原系统。此类故障 无法由 DBMS 自动恢复,必须人工干预。
- 不可修复的硬件故障(如磁头撞击导致磁盘损坏),破坏部分或全部非易失性存储数据(假设损坏可被检测到)。
加锁粒度
背景:权衡
性能和一致性的权衡
- 一个涉及许多记录的事务将不得不获取许多锁!
- 这增加了每个操作的开销
- 一个只需要访问部分表格但却锁定整个表格的事务将限制并发性。
- 允许的情况包括:
- 当事务只需要修改或查询少量记录时, 最好使用较细粒度的锁定机制,如记录级别或页面级别的锁定
- 锁定多个记录的事务使用表格锁
多粒度锁定增加了复杂性
需要确保不同粒度的锁可以共存
并非简单问题,例如:
- 如果事务 T1 尝试在表 A 的某个记录上获取锁,而事务 T2 已经获取了表 A 的写锁,则应该阻止 T1 获取该记录的锁
解决方案: 引入层次锁(或者说,锁的层次结构)
Table Page Record 或者是 Table Range Record关键思想: 在获取低级别锁(如记录锁)之前,先获取高级别锁(如表锁)。
如果一个事务想要修改单个记录?它是否需要在整个表上获取 X 锁定?
这似乎违背了记录级别锁定的目的!
意向锁(Intention Locks)
解决方案: 意向锁
Table
Page
Record关键思想:
- 假设事务 T1 想要写记录 R1
- 需要在包含 R1 的表和页上获取意向锁
- 意向锁在更高层次上标记某个事务在较低层次上有一个锁
- 意向锁
- 可以是读意向(IS)锁或写意向(IX)锁
- 防止当一个事务在较低层次对象上工作时,其他事务获取整个对象的锁。例如, 当 T1 在记录 R1 上有写锁时,意向锁确保其他事务不能在 T1 完成之前锁定整个表进行修改。
- 不同事务可以同时持有对同一个对象的锁,前提是这些锁是兼容的。下面是 锁兼容性矩阵
NOTE
根据锁在意图分类,有:
- S (Shared):共享锁,提供读取权限。
- X (eXclusive):排他锁,提供读取和写入权限。
- IX (Intention eXclusive):意向排他锁。
- IS (Intention Shared):意向共享锁。
- SIX (Shared Intention eXclusive):共享意向排他锁。
锁在粒度上分类,包括(从上到下,层次越来越高):
- 元祖(记录级别锁)--> 慢
- 页
- 表
- DB --> 限制并发
| T2 trying to acquire \ T1 holds | S | X | IX | IS | SIX |
|---|---|---|---|---|---|
| S | ✔ | ✔ | |||
| X | |||||
| IX | ✔ | ✔ | |||
| IS | ✔ | ✔ | ✔ | ||
| SIX |
从上图中我们可以发现
如果T1正在更新较低层次数据,T2不能读取整个层次的数据
如果T1正在读取较低层次数据,T2可以读取整个层次的数据
如果T1正在更新较低层次数据,T2不能更新整个层次的数据
如果T1正在读取较低层次数据,T2可以更新整个层次的数据
如果 T1 正在读取/更新较低层次的数据,T2 可以读取/更新较低层次的数据
那如果它们尝试访问相同的较低层次对象呢?
A: 较低层次的锁将会阻止它们
意图锁 (IS/IX )的协议
- 考虑事务 T 尝试在层次结构的第 j 层对记录 R 获取 S/X 锁
- for each level L in 1 ... j - 1
- 在L层中, R所在对象获取IS / IX 锁
- 如果不能兼容,则阻塞
- 在L层中, R所在对象获取IS / IX 锁
- 获取记录的 S/X锁
- 当释放锁的时候按照相反的顺序
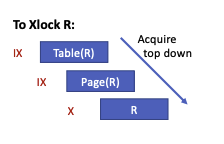
举个例子,如果想读取X记录, 先在X所在数据库加IS锁, 然后在X所在表获取IS锁, 接着在X所在页添加IS锁,最终将得到X的S锁。
思考题
给定上述的层次结构,准备将3个记录添加到同个表的两个页中
以下哪对事务可以在不阻塞的情况下并发执行?
A) T1: Read P1 T2: Write A
B) T1: Write P2 T2: Read T
C) T1: Write P1 T2: Write P2
D) T1: Read P1 T2: Write C
C,D
恢复
恢复是关于你如何处理一个已经crashed的系统,主要有两件事:
- 确保故障时的原子性
- 确保故障时的持久性
当发生crash时, 所有的内存状态, 所有的进程,以及缓冲池中的所有内存都消失了,你只能从磁盘上面带回一些东西,通过恢复过程, 将数据库带入一个事务一致的状态,也就是说
- 要确保故障时的原子性
- 需要撤销未被commit的工作
- 确保故障时的持久性
- 已提交的事务保存在稳定存储(磁盘)上
为什么要回滚未提交的事务? 为什么会出现未提交的事务?
- 系统崩溃后,所有的客户端连接都断掉了
- 一般不可能确定还有哪些工作没有完成
- 最好的选择是将数据库恢复到事务没有发生的状态
- 保持原子性
- 意味着客户端不能依赖未提交的结果
DBMS运行时状态
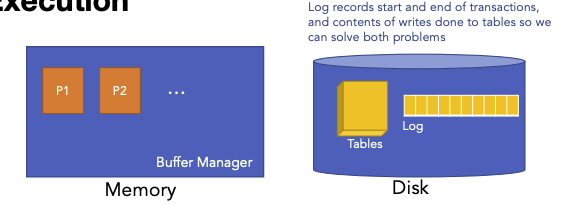
在crash后
内存的东西,没了!
有些事务可能尚未把已经commit的状态回刷到表中——需要重做
有些事务可能把尚未commit的状态写入到表中了——需要撤销
关键思想: 日志记录了事务的开始和结束,以及对表进行写操作的内容。因此我们可以解决上述两个问题。
- 日志捕捉了所有写操作开始和结束的状态
- 比如, 页 X 以前是 X0 现在是 X1
- 并且告诉我们哪些事务已经提交,哪些没有提交。
为什么我们需要记录写操作的内容?
- 如果没有,将无法判定写操作是否被应用
- 如果磁盘上没有表的状态,能够让我们重做已经提交的写操作
- 如果磁盘上有表状态, 能够让我们撤销未提交的写操作。
基于日志的恢复
物理日志 vs. 逻辑日志

逻辑日志:不直接关注数据在磁盘上的物理存储结构,而是记录操作的逻辑意义和效果。 比如: tid 100: sal += 1000
物理日志:关注数据在磁盘上的存储位置
虽然逻辑日志记录方式更为紧凑,但它要页必须准确地反映事务操作的变化状态,以便正确执行恢复过程中的撤销和重做操作。
预写日志 WAL
预写日志 WAL (Write-Ahead logging) 策略是指所有的数据的修改操作之前,都会将修改操作写到日志记录中。日志记录包括
- 开始或提交事务
- 当系统执行写操作,将页数据写入到磁盘上的表时,这些写操作会被记录到日志中(读取操作不记录日志)
如果我们不这样,会有什么差错?或者说为什么要预写日志?
如果不这么做, 在未提交的事务中更新页面,系统崩溃(这时应该回滚该更新操作),但是,我们没有任何方法来知道页面是否已被更新。
在执行操作之前,先记录我们计划要做的事情,并在日志中留下足够的信息,以便我们可以确定是否已经执行了这些操作。
需要注意的是,我们必须将所有操作写两次,但日志记录是追加进行的,不像对数据库的写操作是随机的
日志记录类型及其字段
- Start(SOT)
- LSN: 递增的日志序列号
- TID:事务ID
- 记录事务的开始,标记事务的起始点
- End(EOT)
- LSN
- TID
- 结果(commit 还是 abort)
- 记录事务的结束
- UNDO
- LSN
- TID
- Before image: 事务执行前快照
- 记录撤销操作,用于事务回滚
- REDO
- LSN
- TID
- after image:事务执行后的数据快照。
- 记录重做操作,用于在系统崩溃后恢复事务提交的修改。
- CheckPoint(检查点
- LSN
- TID
- state to limit how much is logged:记录检查点的状态,用于限制日志记录的量
- CLR(Compensation Log Record,补偿日志记录 )
- LSN
- TID
- 允许重新启动恢复过程的记录
日志的两个复杂性
脏页写回
有时候我们想要将脏页(尚未commited)刷回数据库, 为什么?
- 如果我们不将脏页面写回,它们必须在内存中保存直到事务完成
- 考虑一个更新表中所有记录的事务。如果数据库不将脏页面写回,这些页面就必须在事务执行期间一直保持在内存中,内存可能顶不住这么大。
- 将脏页写回数据库的过程称为,Steal
- 数据库执行“STEAL”时,即使事务尚未提交,也可以将脏页面写回数据库。当恢复时,需要用
UNDO来移除未提交的事务
已提交的更改未写回
如果每次提交都把页面刷回,不就可以解决这个问题吗?
这样做会让性能变慢,需要在commit时候进行大量的写操作
不强制在提交时写回所有写入的数据库被称为NO FORCE
追加日志记录足以确保可恢复性,因此对于可恢复性来说,FORCE是不必要的
NO FORCE需要通过
REDO将记录的写操作应用到数据库
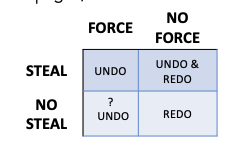
这里我们会发现,Steal、Non-force 与 UNDO/REDO 是一一对应的。
如果我们采用了Steal策略,则我们需要UNDO
如果不采用强制写回策略,则我们需要用REDO
如果我们 FORCE 页面,在 FORCE 和 COMMIT 之间发生崩溃时,我们需要能够执行UNDO操作。
非强制写回/Steal策略的恢复
在系统崩溃后,我们必须执行以下操作:
- REDO已提交的“胜利”事务
- UNDO未提交的“失败”事务
赢家事务指的是在日志中同时包含了事务开始(SOT)和提交(COMMIT)记录的事务。
- 这些事务需要通过REDO操作从头到尾重新执行。
失败事务指的是在日志中包含了事务开始(SOT),但没有提交(EOT),或者标记为ABORT的事务。这些事务需要通过UNDO操作,
- 按照相反的顺序,从末尾到开头进行撤销。
此外,我们还需要执行UNDO操作来撤销已中止(ABORT)的事务。
恢复3阶段
- 分析: 扫描日志,找到胜利和失败事务
- 重做: 从头扫尾扫描日志,找到胜利事务
- 撤销: 从头扫尾扫描日志,找到失败事务
具体顺序可以有多种
- 先撤销在重做
- 先重做再撤销
下一节会详细讨论。
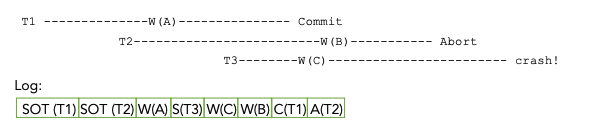
案例分析
- 假设我们有三个事务,采用NO Force, Steal策略
- T1写A,commited
- T2写B,abort
- T3写C,系统crash
恢复过程
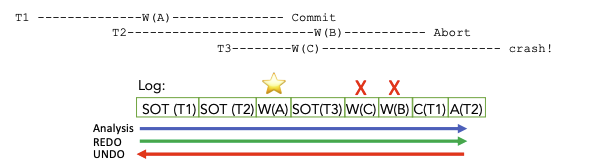
- 分析: T1 是胜利事务,T2,T3是失败事务
- REDO:正向扫描,重放WA
- UNDO: 反向扫描,撤销WB,WC操作
恢复后,T1的效果还在,而T2,T3的就没了。
恢复和隔离性
- 在一个正确隔离的数据库中,如果使用页面级别的锁定,同时运行的事务不会读写同一页面
- 因此,我
论文阅读: ARIES
大纲
- ARIES目标
- ARIES总览
- 数据结构
- 正常处理
- 重启处理
- 重启过程的检查点
- 媒体恢复
故障恢复的难点
- B树
- 逻辑插入创建不同的B树
- 在更新多页B-树或B-树与数据页不一致时崩溃
- 检查点成本
- 在执行检查点操作时,我们是否必须阻塞系统?
- 恢复时间
- 在系统再次可用之前,我们需要等待多久?
- 恢复期间崩溃
- 在执行恢复过程中,如果系统再次崩溃,会发生什么?
- 托管更新(Escrow updates)
- 托管更新是指某些事务可能需要保留某些资源的部分更新,在恢复过程中处理这些更新可能会非常复杂。
大纲
- 日志记录的黄金准则
- 指定所有细节
- NO Force / Steal
- 可恢复的故障恢复
- 日志记录的哲学
- 低开销的checkpoint
- 支持托管更新
- E.g., increment / decrements
ARIES恢复方法: 3次日志遍历
- 分析: 确定需要完成的工作(前向扫描)。
- 重做阶段:确保数据库反映日志中记录但尚未写入表的更新(前向扫描)
- 包括那些属于最终将被回滚的事务的更新!
- 为什么?这样可以确保数据库达到“操作一致”的状态,从而允许逻辑上的撤销操作
- 这一步被称为“重复历史”,因为它会重新应用已经记录的操作。
- 撤掉阶段: 回滚失败的事务(反向扫描)。
日志记录格式

- LSN: 每条日志记录都有LSN
- prevLSN: 写在这个事务前面的LSN
- Undo Image/Redo Image 更新记录都有UNDO和REDO的信息
- pageLSN: 每次写入一个页面时,与该日志记录相关的最新LSN(日志序列号)会作为pageLSN包含在页面中。
日志记录的哲学
REDO 是物理的。
- 在崩溃时,数据库可能不处于“操作一致”的状态
- 一些操作可能包含多个非原子物理操作
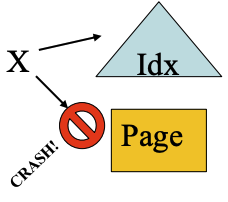

X 可能在索引中反映出来了,但在表中没有反映出来,或者反过来
- 用物理日志重放会比较容易
- 重放时按照日志中的顺序逐条应用即可,不需要考虑操作的依赖关系和顺序问题
UNOD 是逻辑的。
- 我们只需要撤销一些操作。
- 意味着在进行 UNDO 时的状态可能与写入日志时的状态不同(可能有其他事务在此期间修改了数据库)
- 因此,物理日志记录的具体前快照和后快照可能已经不再适用,无法直接用于撤销操作
撤销的例子
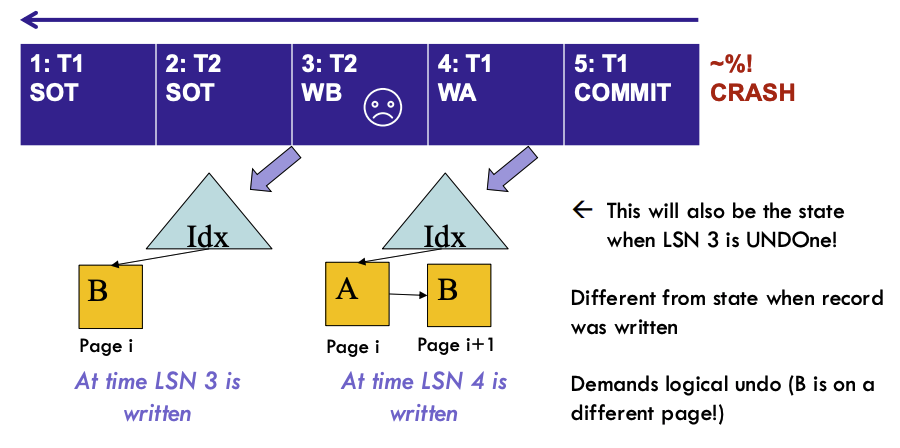
- 在序号3时刻,LSN = 3 已经写回了到页 i
- 在序号4时刻,LSN = 4 事务已经写回到页 i + 1
- 当发生crash时候,我们反向扫描进行撤销
此时会发现,当我们对T2(LSN =3 )进行撤销时候,数据库的状态与最初日志记录时的状态不同了,因此需要逻辑撤销(B 已经移动到不同的页了)
为什么不需要REDO?
因为我们已经重复了历史,已经回放了所有东西。自上次操作以来对数据库进行的物理修改仍将是正确的
ARIES 的正常操作
- 两个关键数据结构
- 事务表 Transaction table —— 活跃事务的列表
- 脏页表 —— 哪些已经更改但没有写回磁盘的页的列表
- 随着系统运行数据结构会更新
- 页是异步刷回磁盘
- 在刷新之前,日志被强制写入(但不是在写入之前)
- 刷回不会被日志记录
- 在commit被确认之前,日志被强制写入
- 页是异步刷回磁盘
事务表
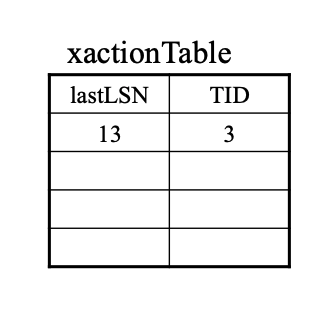
- 所有活跃事务都在表上
- lastLSN: 指特定事务所写入的最新日志记录的LSN(日志序列号)
脏页表
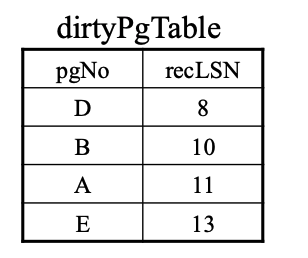
- 脏页是指已被修改但尚未写回到磁盘的数据库页, 将脏页写回到磁盘的过程称为刷新,刷新时从脏页表中移除相应的条目。
- recLSN: 是指第一个将该页面标记为脏页的日志记录的LSN
检查点checkpoints
- 会定期执行检查点,以记录当前数据库的状态
- 检查点记录包括两部分内容:脏页表的状态和事务表的状态
- 不要求在检查点期间刷新页到磁盘
- 检查点可以帮助数据库系统在发生崩溃时限制需要重放的日志量。这样可以加快系统的恢复速度
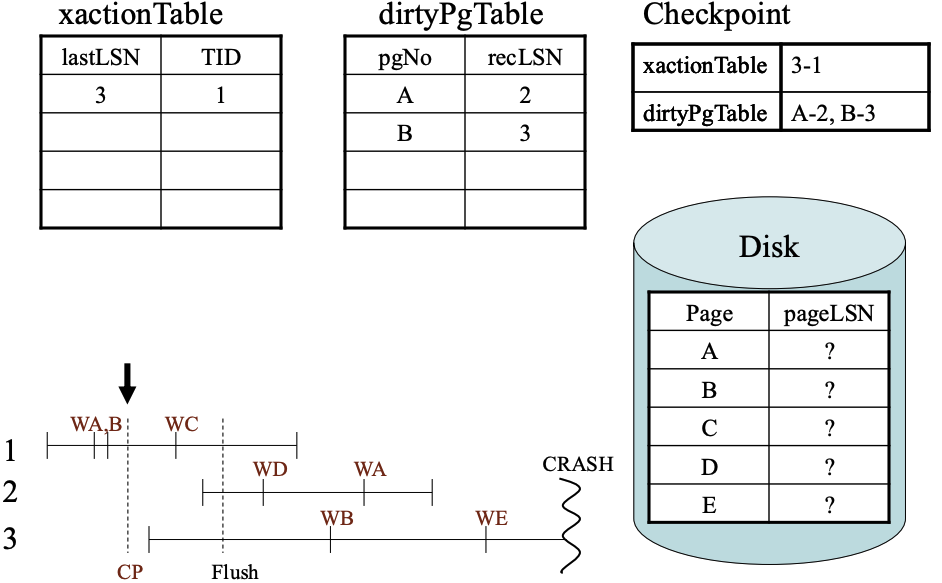
ARIES的例子
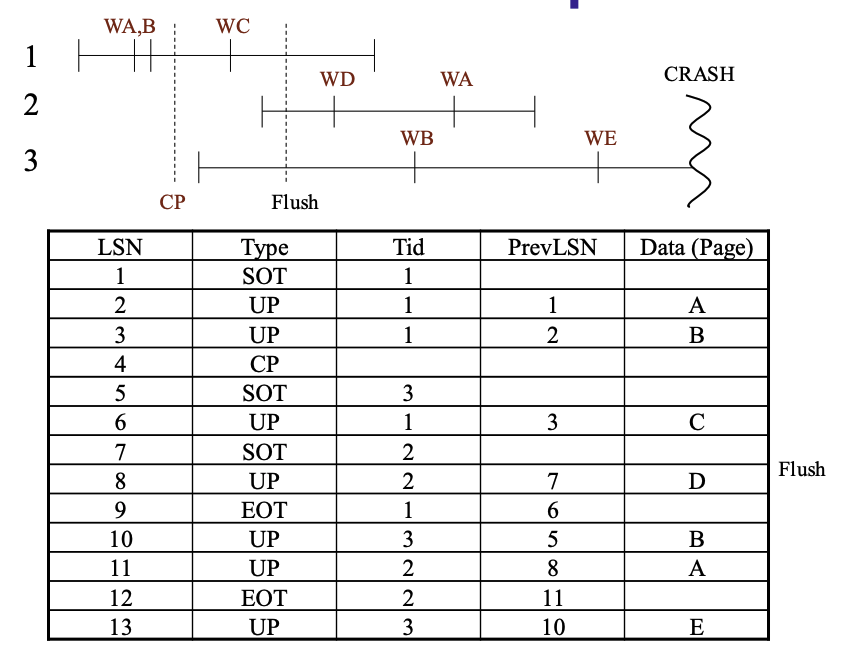
- UP:update page
- CP: checkpoint
ARIES数据结构
xactionTable
dirtyPgTable
Checkpoint
Disk page
从事务开始
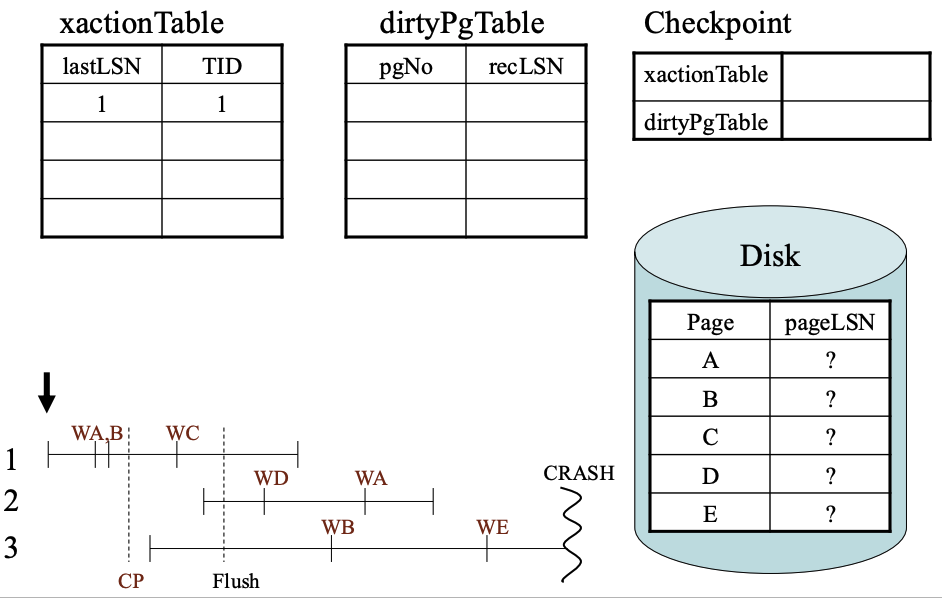
执行checkpoint的变化
刷新后变化
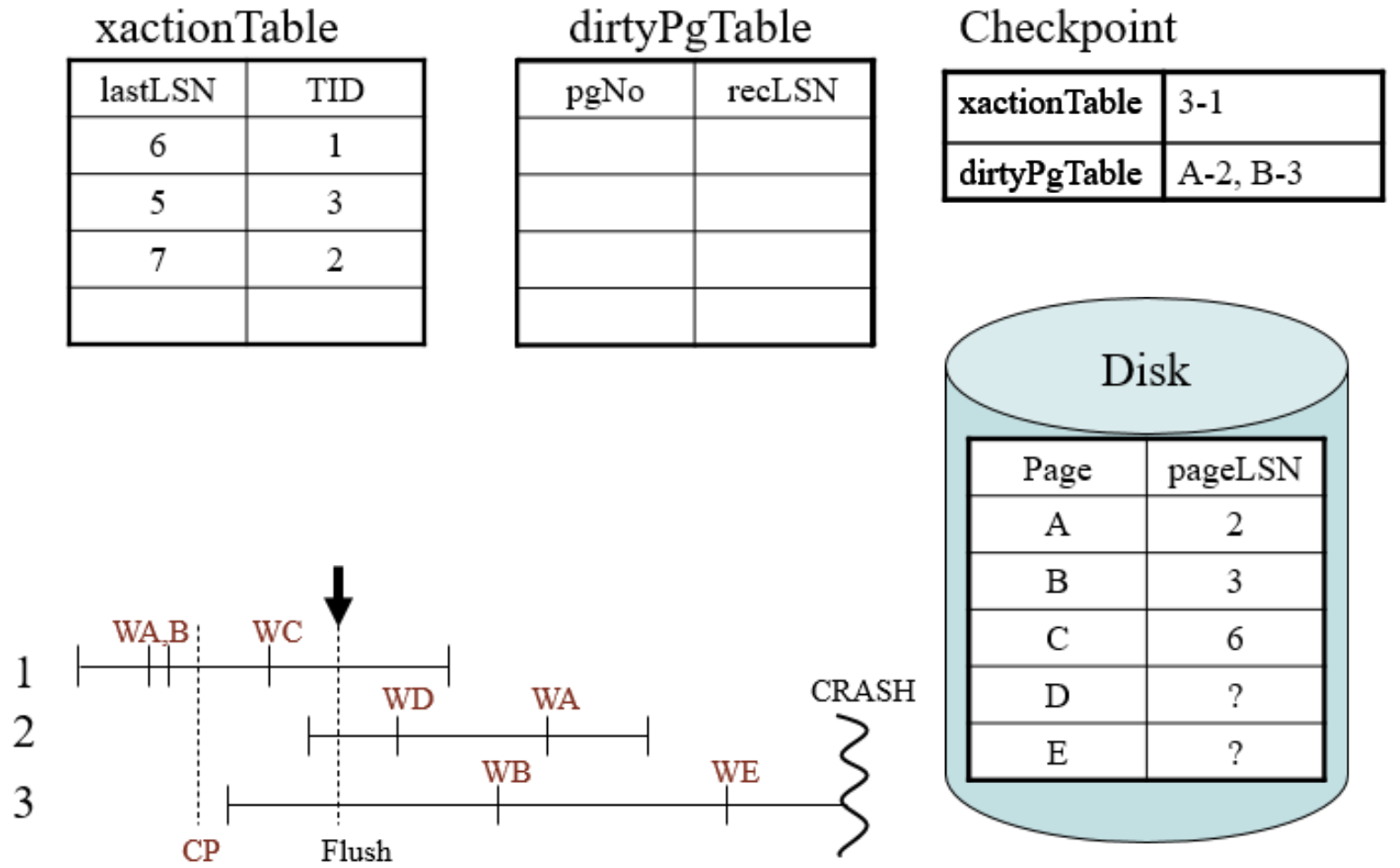
- 将脏页的对应条目移除
- 在磁盘页上记录
完成一个事务后
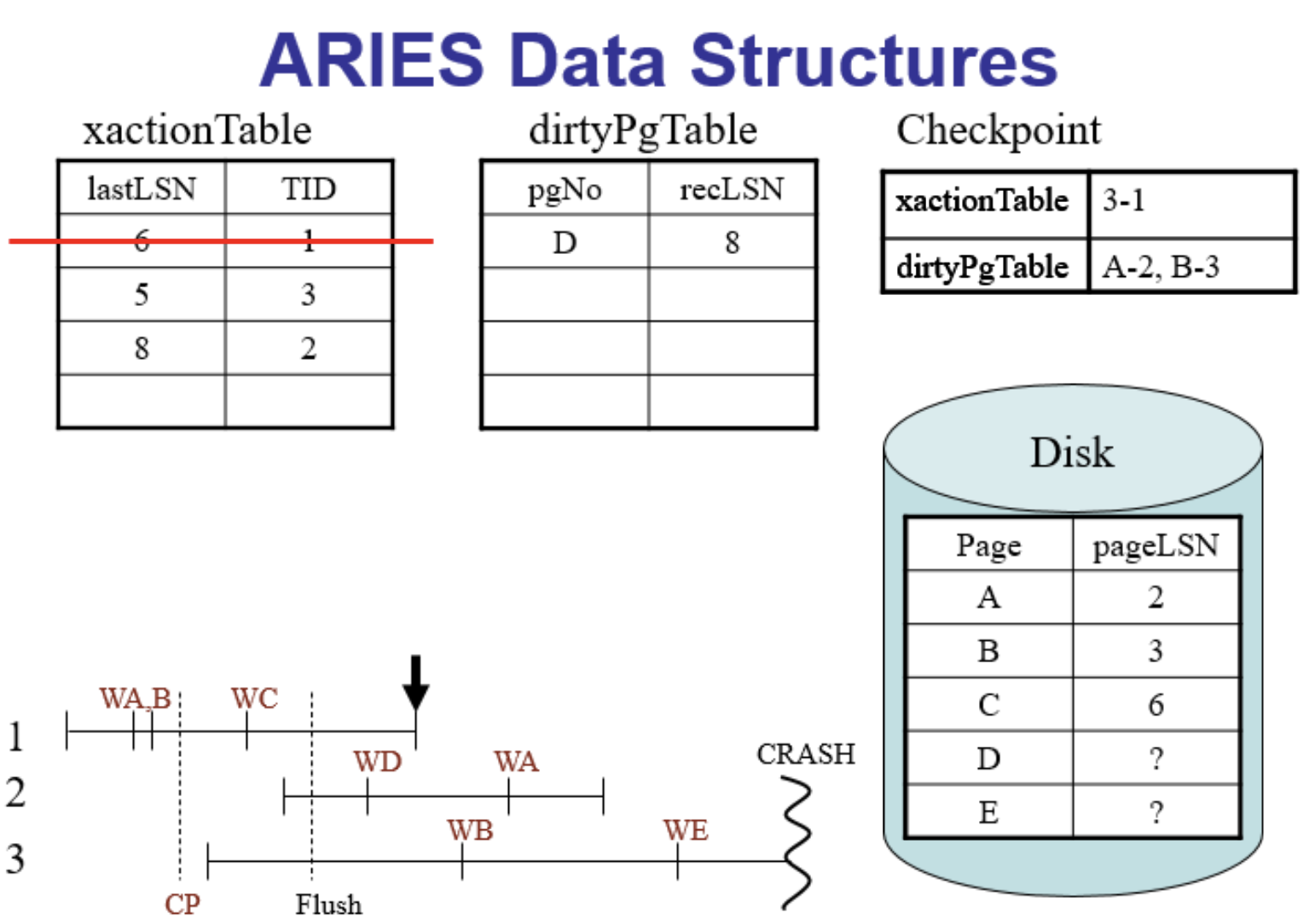
crash前最近的状态
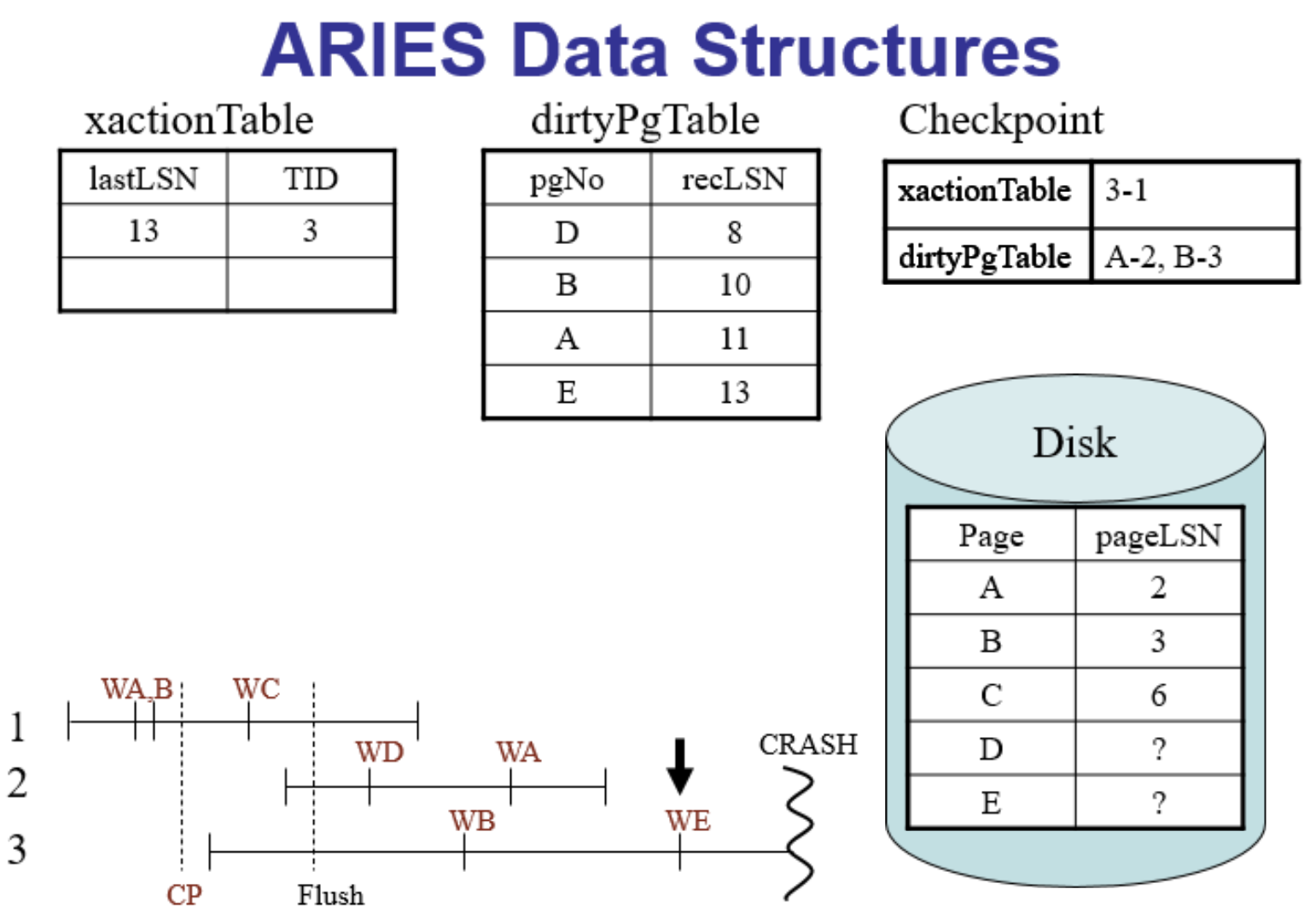
分析阶段
主要目标是重建系统在崩溃发生时的状态,特别是恢复事务表(Transaction Table)和脏页表(Dirty Page Table)的状态
正向重放日志
- 事务表的更新:根据日志中的SOT(事务开始)、COMMIT(提交)和ABORT(回滚)记录,将事务添加到或从事务表中移除,并更新相关的事务状态。
- 对于每个页面的更新操作(UP日志记录),更新事务的lastLSN(最近日志序列号)
- 随着日志中写入操作的发生而更新脏页表。
分析后的状态的分析
分析完成后,我们可以了解到脏页表(Dirty Page Table)和事务表(Transaction Table)的状态如何了。
事务表告诉我们需要撤销(UNDO)哪些操作。
脏页表是一个保守的列表,标记了需要重新执行(REDO)的页面。
为什么说它是保守的?
- 因为我们实际上并不知道磁盘上的确切状态;一些页面可能已经应用了更新;前面已经提到刷新不会写入日志
我们从哪里开始分析?
最近一次checkpoint开始。当然你也可以从头开始,不过需要扫描很多日志
我们哪里找到这个checkpoint?
在磁盘上的一个已知位置保留指向检查点的指针。
例子
还是回到上面的例子,我们
从最近的检查点开始扫描
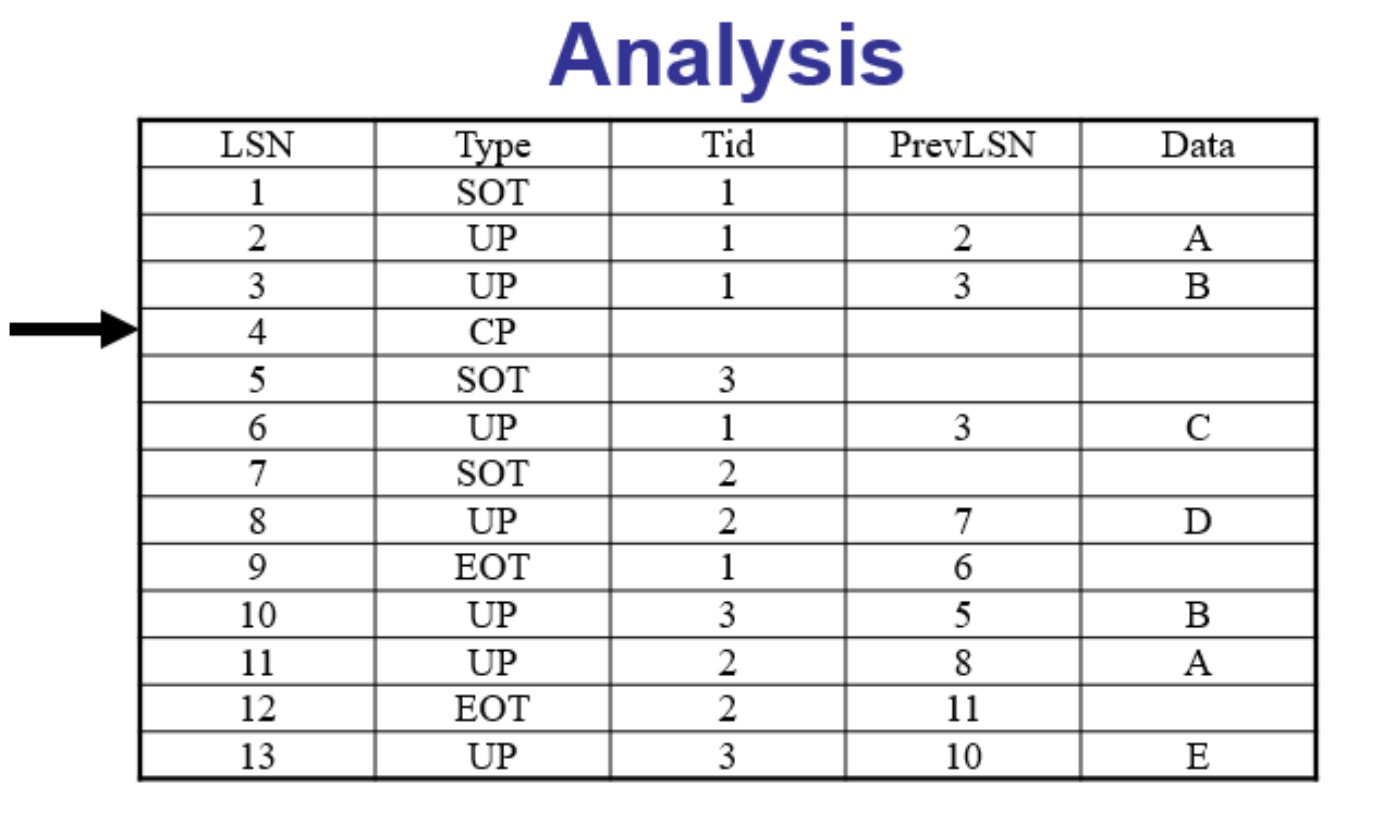
正向回放
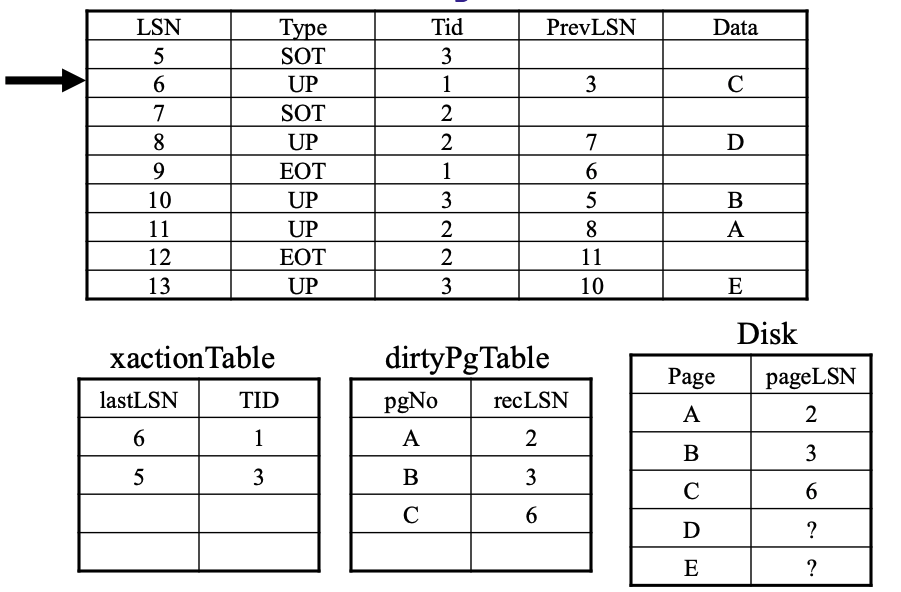
扫描最后一条日志
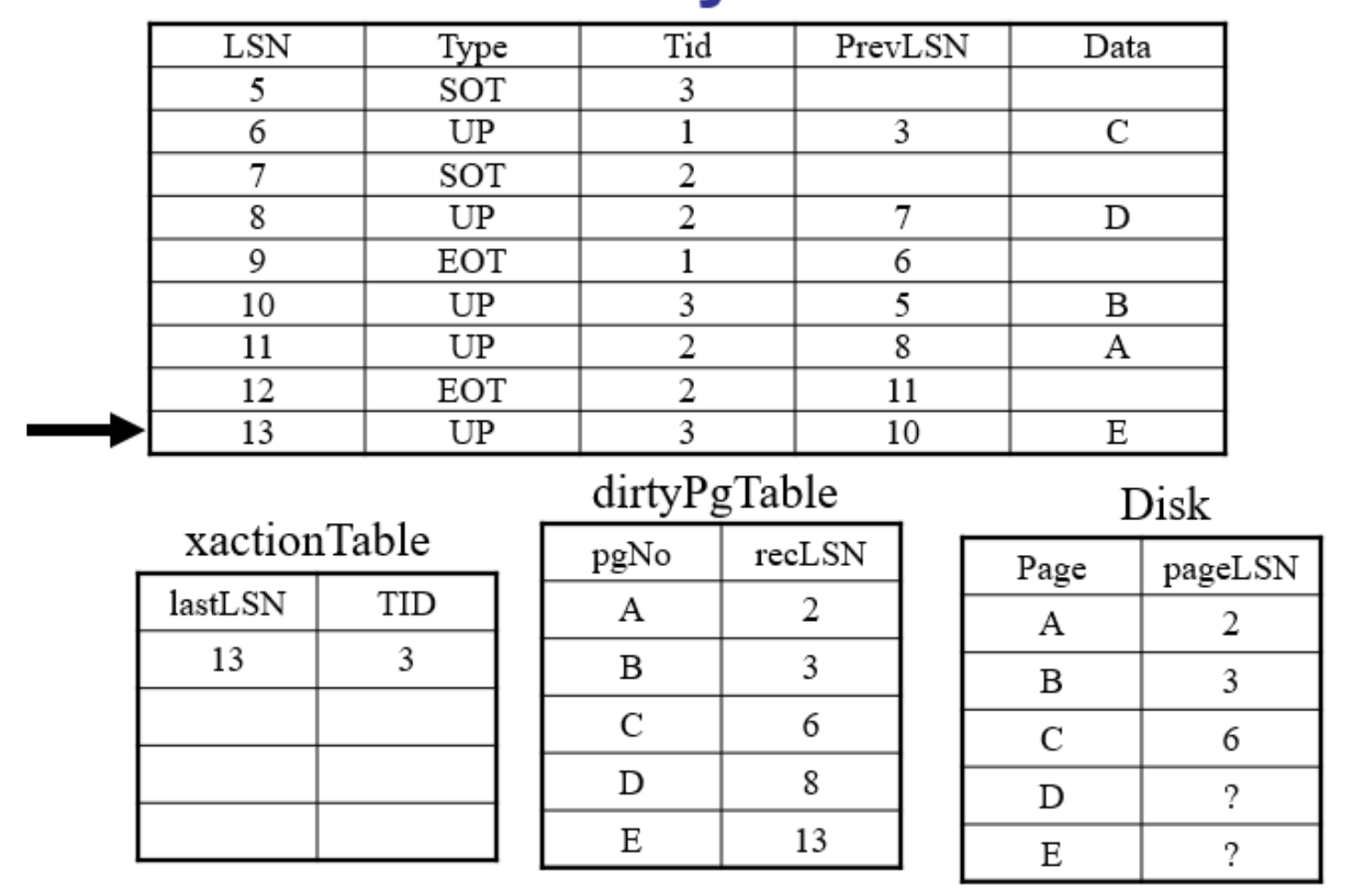
- 此时活跃事务表上面的事务都是”失败“事务
- 脏页表没有反映磁盘上出正确的状态
- 保守性: 尽管我们不能确定所有脏页表中列出的页都需要被重放(REDO),但我们确保磁盘上的数据至少包含了所有这些LSN所记录的更新操作
Redo阶段
从哪里开始?
可以从检查点开始。
也可以从最小的recLSN(最早未刷新的更新)开始。
需要执行什么?
- 所有东西?
- 太慢了
- 可能会出现问题,尤其是在使用逻辑日志/托管日志
- 除非以下条件之一,否则需要重做一个更新操作:
- 页面不在脏页表(dirtyPgTable)中
- 意味着该页面在崩溃前已经被写回到磁盘,并且没有再次变脏。
- LSN < recLSN
- 页面在检查点之前被刷新 & 再次变脏只可能在检查点之前
- LSN <= pageLSN
- 页面在检查点之后被刷新
- 页面不在脏页表(dirtyPgTable)中
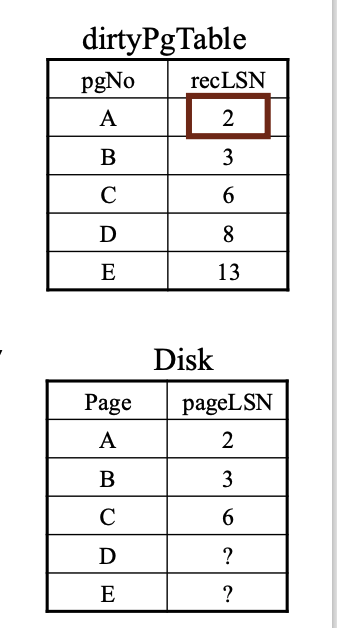
IMPORTANT
redo阶段是恢复过程中唯一需要访问磁盘的阶段,因为它需要查看页面的物理状态以决定是否需要重放操作
REDO的条件的例子
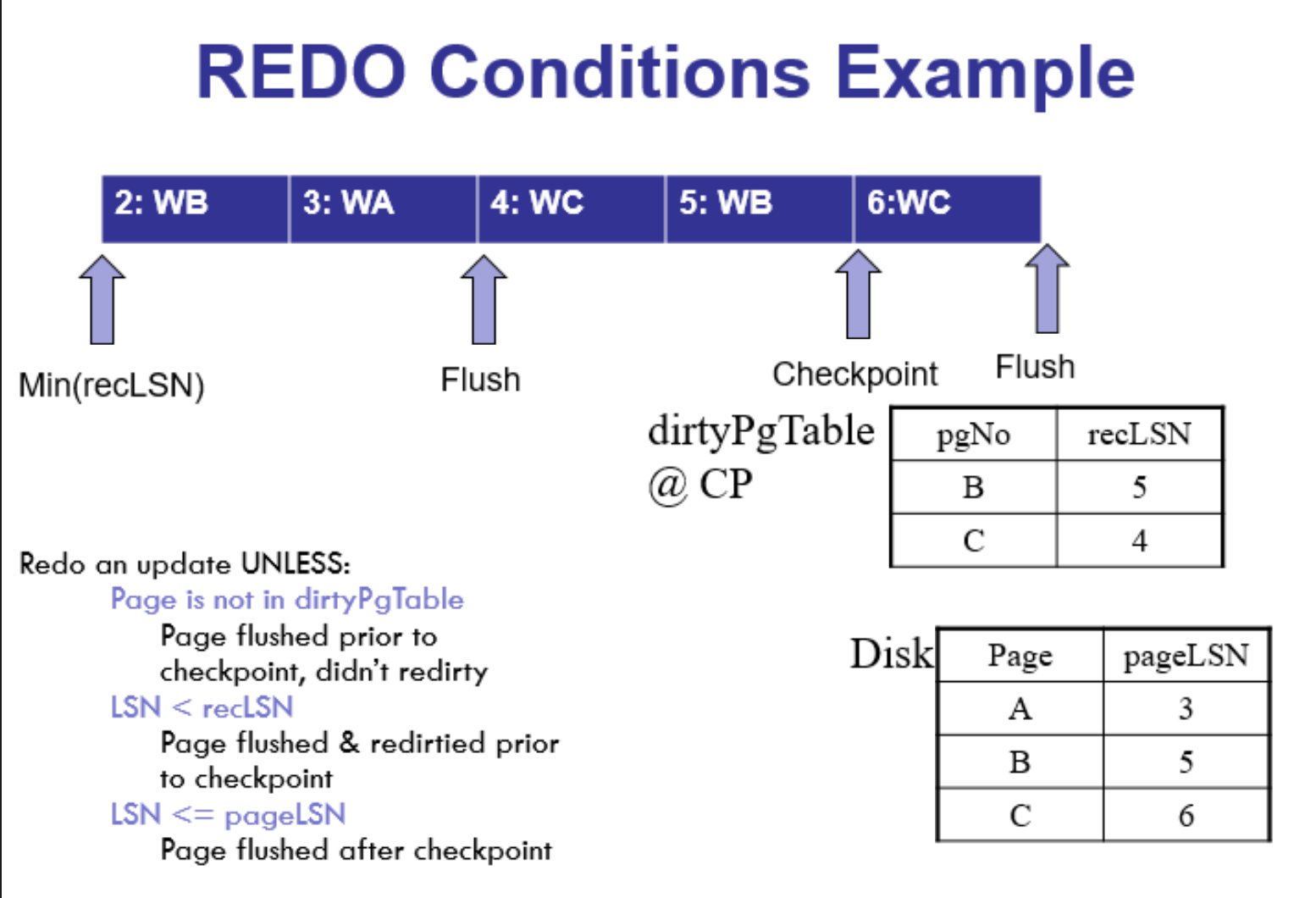
第一个情况: A/LSN 3
第二个情况: B/LSN 2
第三个情况: C/LSN6
将整个日志执行完
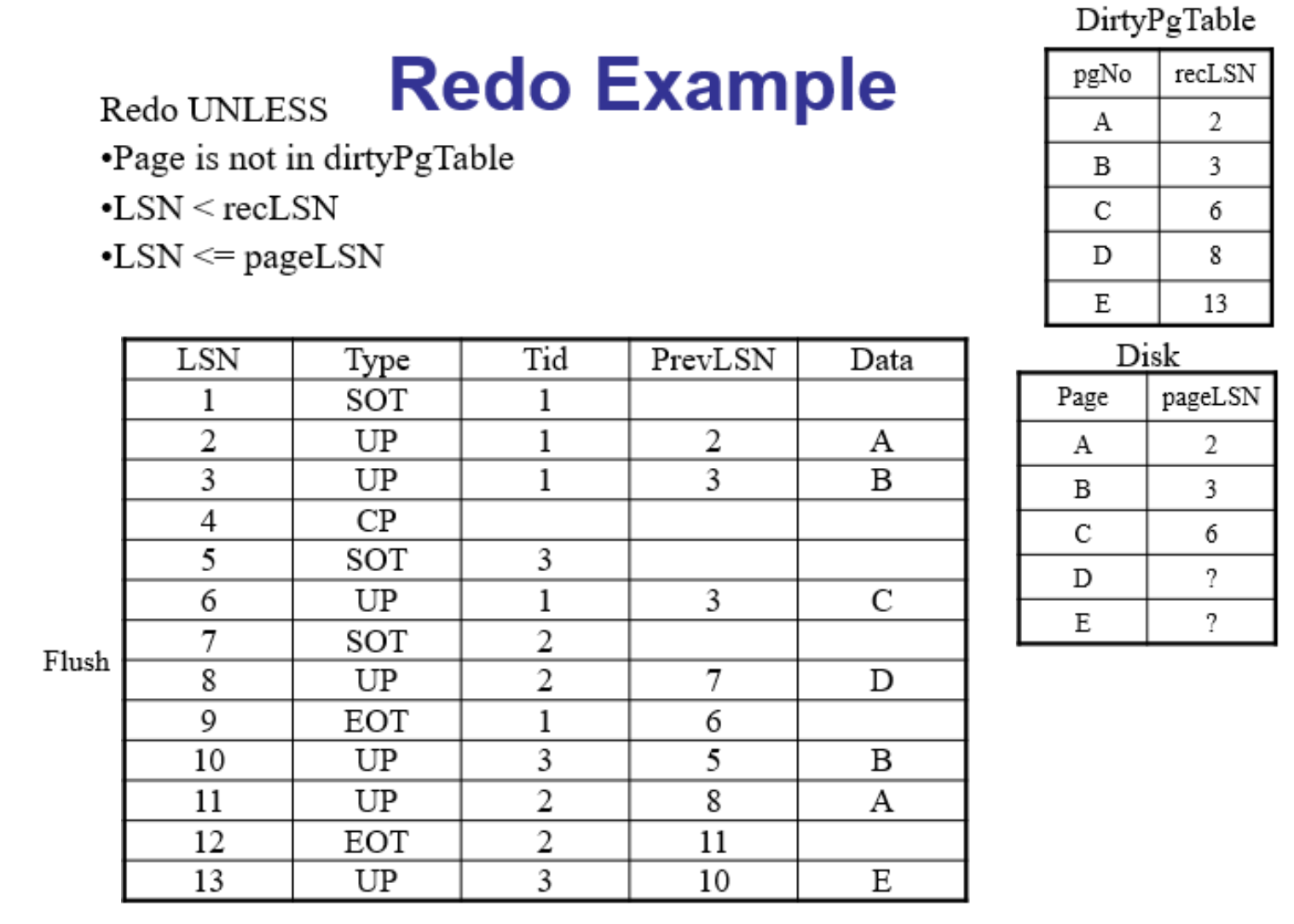
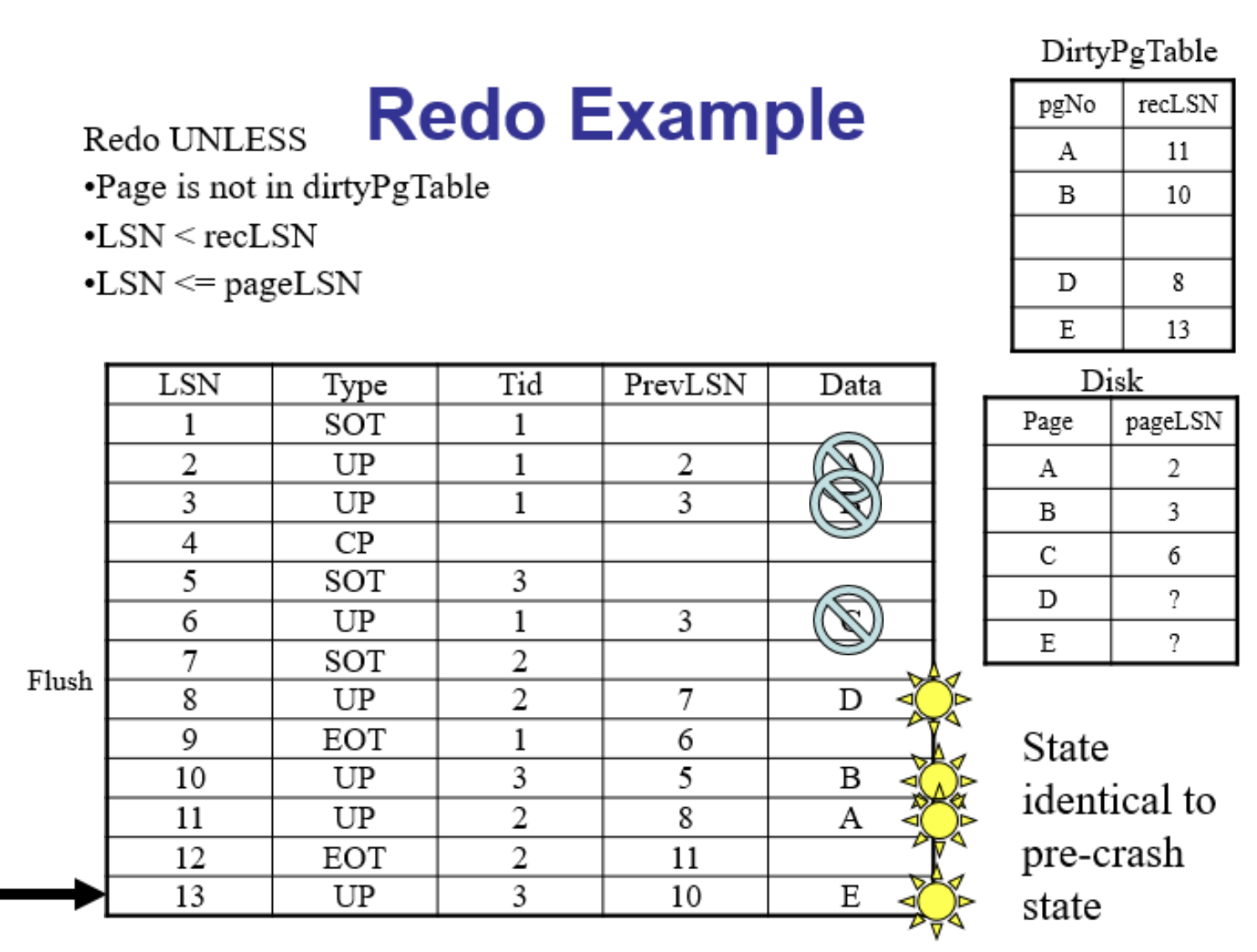
Undo阶段
系统会按照事务最后一个LSN的prevLSN链(前向链)的逆序顺遍历,以回滚未提交的事务(失败事务)所做的修改
为什么可以简单地按照prevLSN链逆序执行UNDO操作呢?
因为恢复过程中的UNDO操作实际上是在重复历史操作,只不过这次是反向操作,将数据库状态回滚到事务执行之前的状态。
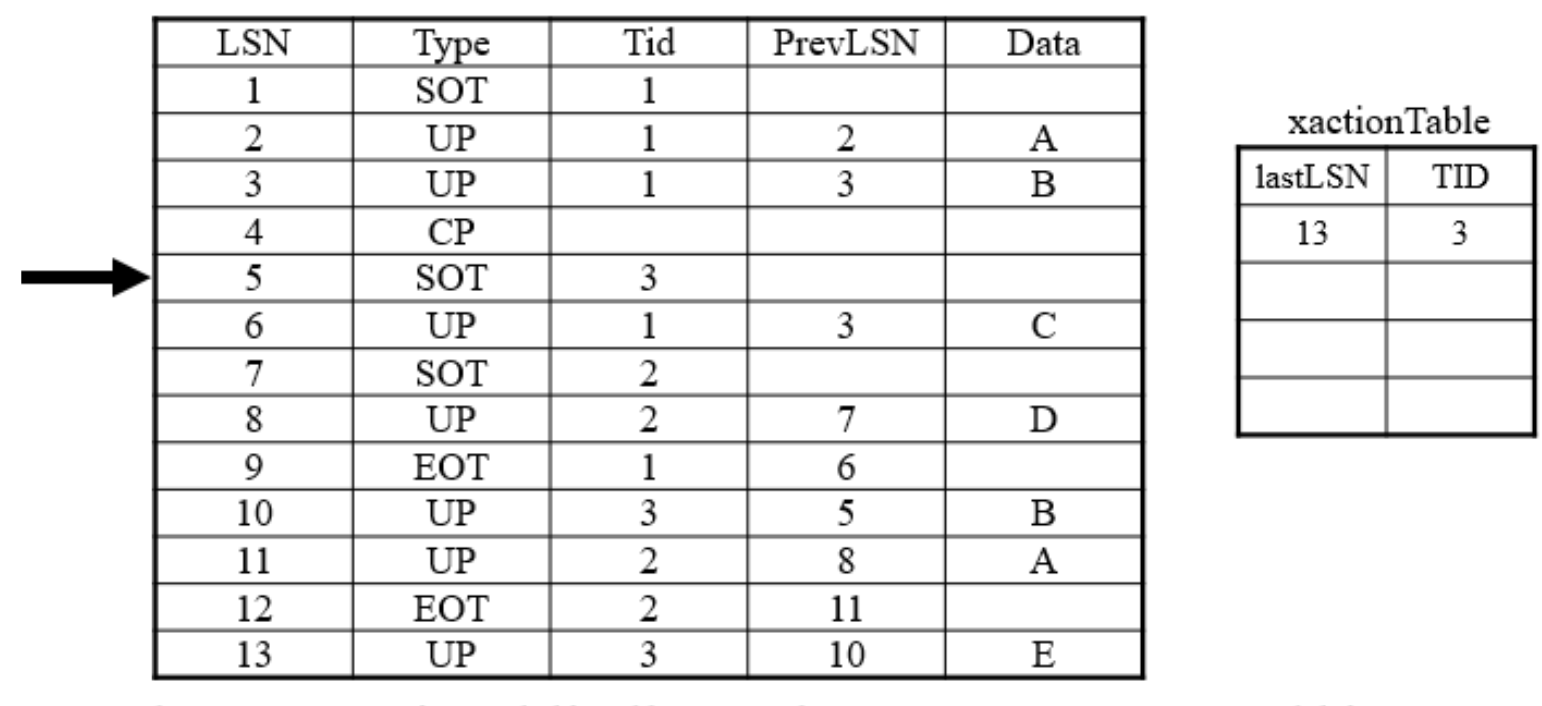
数据库运行过程中,没有执行任何刷新(flush)操作。在第一个检查点(checkpoint1)的时候,脏页表(dirty page table)和事务表(transaction table)都是空的。
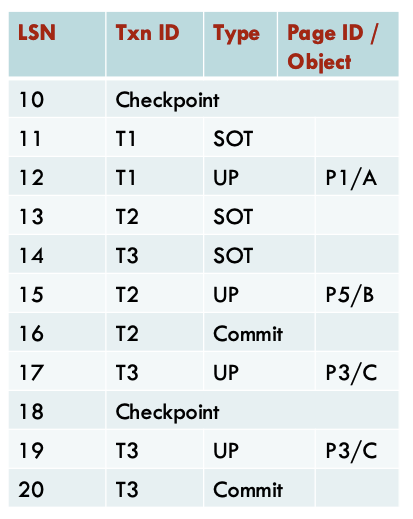
在崩溃发生时,表的状态必须是什么?
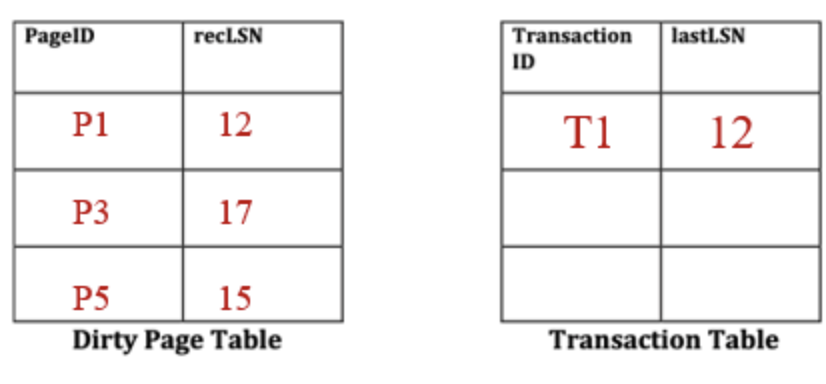
分析阶段从哪个LSN开始?
18
重做阶段从哪个LSN开始?
Min(recLSN) = 12
第一个被撤销的LSN是什么?
12
日志截断
- 我们必须永久保留日志吗?
- 我们将会查看日志中的最早的点是什么?
- min(last checkpoint, min(recLSN))
- 我们可以安全的阶段任何在这之前的内容
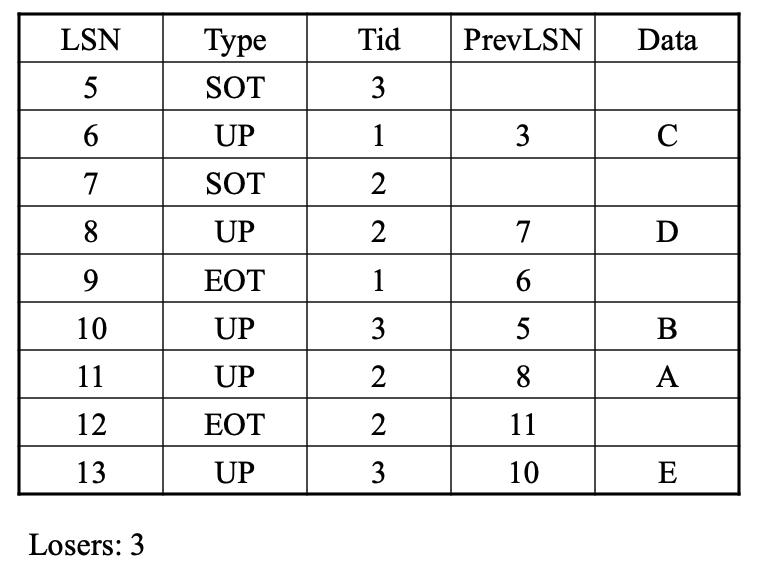
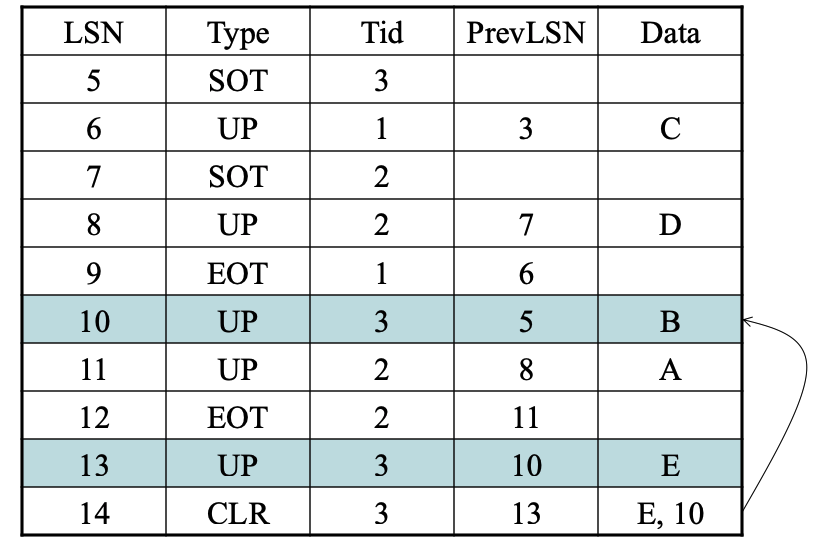
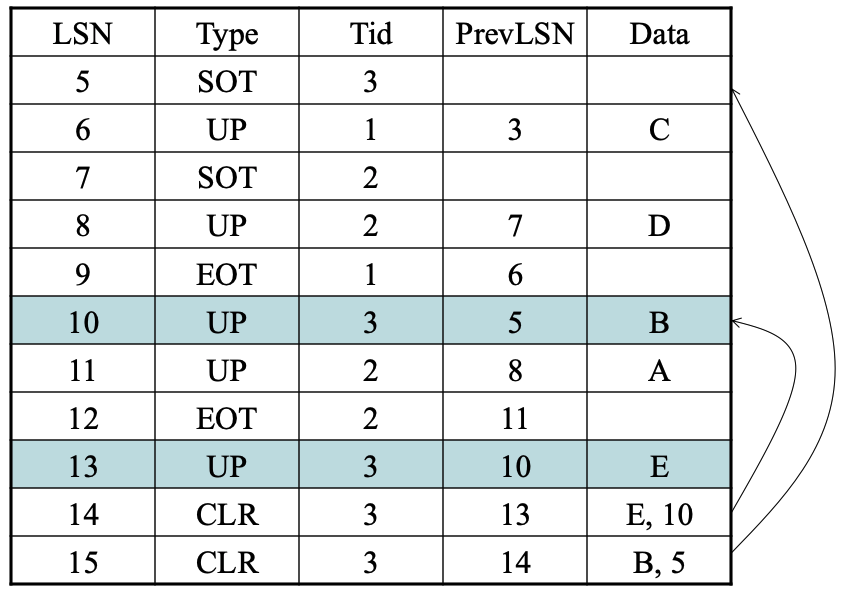
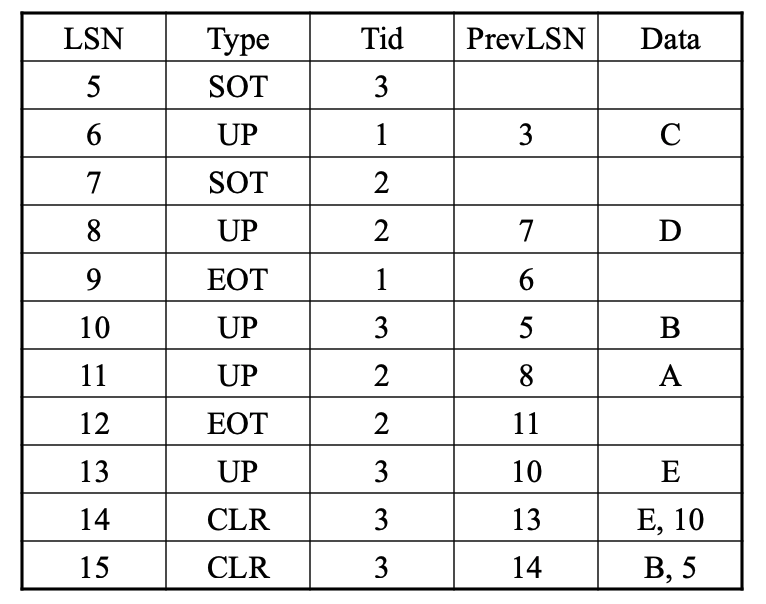
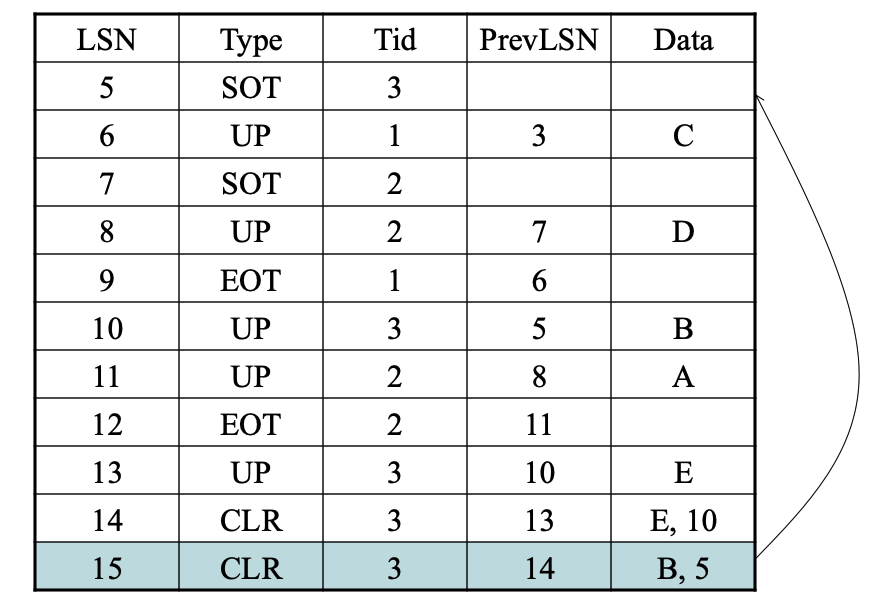
补偿日志记录CLRs
Compensation Log Records,
- 在每次UNDO后写入CLR记录
- 避免重复撤销操作
- 为什么?
- 因为UNDO是逻辑性的,我们不检查记录是否已经被撤销。如果重新撤销了某些逻辑操作,可能会出现问题。
用CLR来UNDO
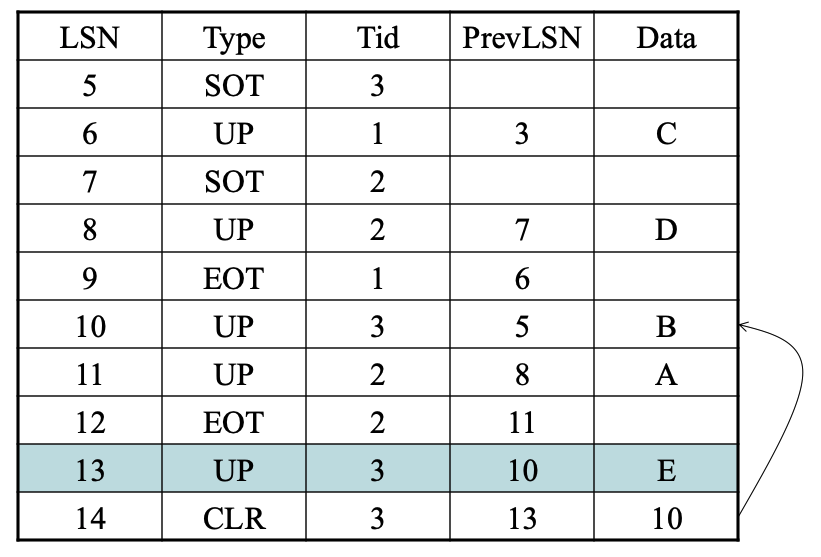
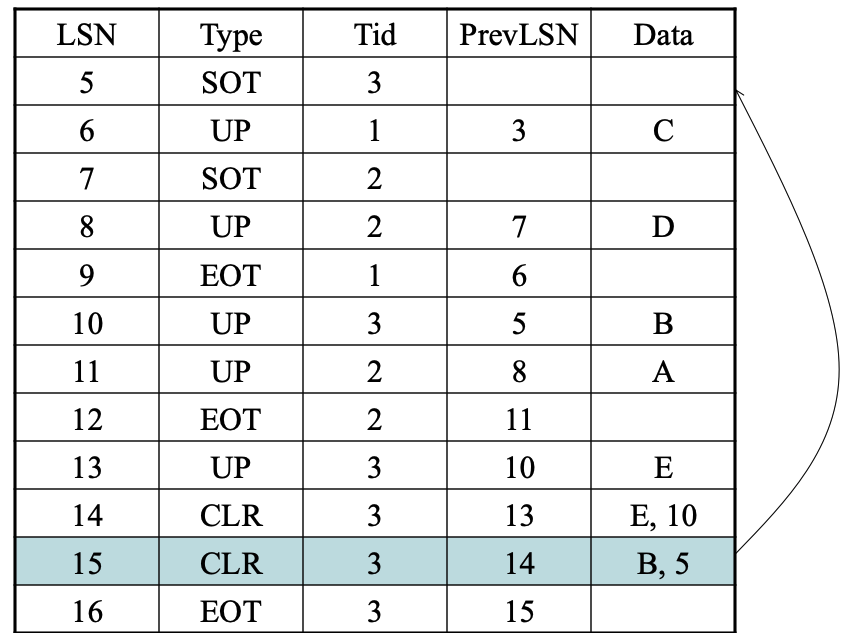
使用CLR来REDO
- 在崩溃恢复时重做CLR
- 使用REDO规则检查CLR中的更新是否完成
- 避免重复进行操作(托管)操作
- 理CLR后,在xactionTable中更新lastLSN字段
- 允许UNDO从正确位置开始,如果我们在UNDO过程中进行检查点
灾难级恢复
解决方案: 复制
复制
典型方法:专用的“热备份”
- 通过“日志传送”保持最新 - 它按照与主数据库完全相同的顺序执行日志中的操作
可能有多个副本,一个在本地数据中心附近,一个在更远的地方
- ”飓风半径“
副本通常用于只读查询
- 由于它们只是重放日志而不处理事务,因此具有多余的处理能力 副本故障转移
故障恢复
在故障时,开始将查询引导到副本
启动新的副本
- 使用例如每晚备份 + 日志
在实践中比较复杂:
必须确实确定数据库失败了
- 许多组织依赖手动故障转移
需要经常测试故障转移
复制负载可能会很大