Lec 5 调用约定、栈与内存布局
本节内容
本节按"调用过程 → 活动记录 → 栈 → 内存布局"的顺序展开。我们先讲调用约定:函数之间如何传参、返回、共享寄存器(caller-saved vs callee-saved);然后讲当寄存器不够用时,数据如何溢出到栈上,引出活动记录(栈帧)和帧指针;接着用 leaf_example、swap、fact、sort 等例题把翻译流程走通,并讲清嵌套过程与递归;最后给出完整的内存布局(text/static/heap/stack)以及堆的动态分配。
寄存器的命名与角色、
jal/jalr的指令格式已在 Lec 4 介绍,本节聚焦它们在过程调用中的用法与约定。
一、调用约定与调用过程
1.1 什么是调用约定
函数调用中,如何传递参数和返回值?谁负责保存哪些寄存器?这需要一套调用约定(calling convention)。
过程(procedure)是根据参数执行特定任务的存储子程序。执行一个过程要走六个步骤:
- 将参数放到过程能访问到的地方(寄存器 a0–a7,或栈)。
- 将控制权转移到过程(
jal)。 - 过程获取所需的存储资源(必要时在栈上开栈帧)。
- 执行任务。
- 将结果放到调用者能访问到的地方(a0–a1)。
- 将控制权返回调用点(
jalr,因为同一过程可能从多处被调用)。
1.2 控制转移指令
控制权的转移依赖两条跳转指令:
jal x1, ProcedureAddress(jump-and-link):跳到目标过程,同时把下一条指令地址(PC+4)保存到x1(ra)作为返回地址。"link"就是这个被保存的、指向调用点的链接,让过程执行完能跳回来。jalr x0, 0(x1)(jump-and-link register):跳到x1保存的地址,即回到调用者。目标寄存器写x0表示不保存新的返回地址(只是"回去",不需要再记从哪回去)。
所以:调用者用 jal x1, X 跳到过程 X,被调用者执行完后用 jalr x0, 0(x1) 跳回。
jal也可用作纯无条件跳转(不保存返回地址):jal x0, Label,写入 x0 等于丢弃返回地址。
1.3 参数与返回值寄存器
| 符号名 | 寄存器 | 描述 |
|---|---|---|
| a0 到 a7 | x10 到 x17 | 函数参数 |
| a0 到 a1 | x10 到 x11 | 函数返回值 |
第一个参数在 a0,第二个在 a1……以此类推。调用者有责任在调用前把参数放进 a0–a7。

第一个返回值在 a0,第二个在 a1。被调用者有责任在返回前把返回值放进 a0–a1。

1.4 caller-saved vs callee-saved
如果 caller 和 callee 都要用同一个寄存器怎么办?这正是调用约定要解决的核心冲突。RISC-V 把寄存器分成两类共享策略:
- 被调用者保存(callee-saved):如
s0–s11、sp。约定它们跨调用保持不变。callee 若要使用,必须先存到栈、返回前恢复,使 caller 看到的值不变。 - 调用者保存(caller-saved):如
t0–t6、a0–a7、ra。callee 可以随意覆盖。caller 若在调用后还需要原值,得自己在调用前先保存。
这套划分的意义在于减少不必要的保存:临时用一下的值放 t/a 寄存器(callee 随便用,caller 用完即弃);需要跨越函数调用存活的值放 s 寄存器(callee 负责守护)。两边各自只保存"自己真正在乎"的寄存器。
跨调用保存规则总结
| 需要保存(跨调用不变) | 不需要保存(可能被覆盖) |
|---|---|
| saved 寄存器:s0–s11 | 临时寄存器:t0–t6 |
| 栈指针:sp | 参数/返回值寄存器:a0–a7 |
| 帧指针:fp(如果使用) | 返回地址:ra(caller-saved) |
| 栈中 sp 以上的内容 |
保护栈的方式有三条:callee 不写 sp 以上的区域(保护栈内容);callee 退出时把 sp 加回减去的等量值(保护 sp 本身);callee 把要用的 saved 寄存器先存栈再恢复(保护寄存器值)。
1.5 完整寄存器约定表
| 寄存器 | 符号名 | 英文 | 用途 | 跨调用保存者 |
|---|---|---|---|---|
| x0 | zero | Hardwired zero | 硬件固定为 0 | — |
| x1 | ra | Return address | 返回地址 | 调用者 |
| x2 | sp | Stack pointer | 栈指针 | 被调用者 |
| x3 | gp | Global pointer | 全局指针 | — |
| x4 | tp | Thread pointer | 线程指针 | — |
| x5–x7 | t0–t2 | Temporaries | 临时寄存器 | 调用者 |
| x8 | s0/fp | Saved register / Frame pointer | 保存寄存器/帧指针 | 被调用者 |
| x9 | s1 | Saved register | 保存寄存器 | 被调用者 |
| x10–x11 | a0–a1 | Function arguments / return values | 参数和返回值 | 调用者 |
| x12–x17 | a2–a7 | Function arguments | 函数参数 | 调用者 |
| x18–x27 | s2–s11 | Saved registers | 保存寄存器 | 被调用者 |
| x28–x31 | t3–t6 | Temporaries | 临时寄存器 | 调用者 |
大多数程序可以使用多达八个参数寄存器、十二个保存寄存器和七个临时寄存器而无需访问内存。
二、栈与活动记录
2.1 寄存器不够用 → 溢出到栈
如果一个过程需要的存储超过了寄存器容量怎么办?
Sol:分配一块专门的内存区域来存放,过程完成后必要时再恢复——这叫把寄存器溢出到内存(spill registers to memory)。实现它的理想结构就是栈(stack):一个后进先出(LIFO)的队列,配一个指针指示最近分配的地址,也就是下一个溢出值该放哪。
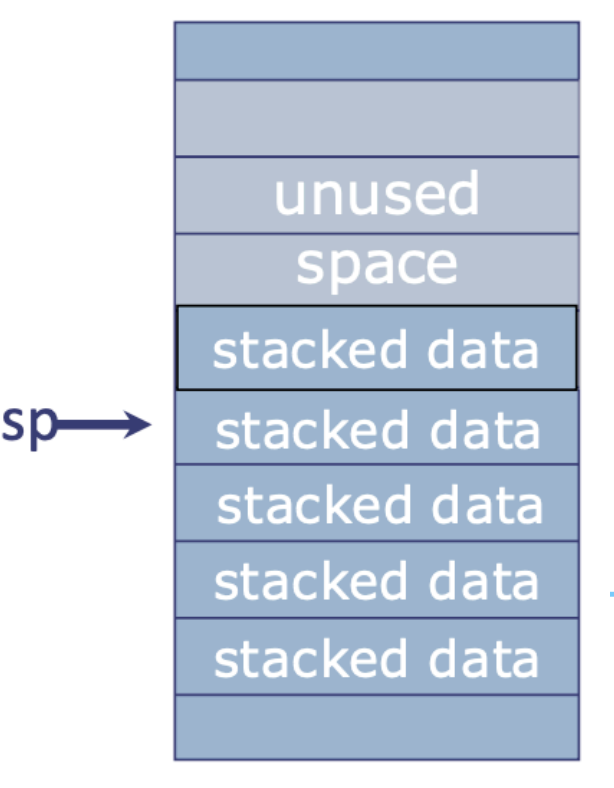
RISC-V 栈的几个基本性质:
- 栈从高地址向低地址增长,后进先出(LIFO)。
- SP(栈指针,sp/x2) 指向栈顶。
- push(压栈):先腾空间,再存数据。assembly
addi sp, sp, -8 # 分配空间(doubleword 占 8 字节) sd a1, 0(sp) # 把元素放进去 - pop(弹栈):先取数据,再移指针。assembly
ld a1, 0(sp) # 把元素拿走 addi sp, sp, 8 # 释放空间
任何过程都可以使用栈,但返回前必须把栈恢复成进入时的样子,即 sp 必须重置为过程开始时的值。
2.2 活动记录(栈帧)
活动记录(activation record,也叫栈帧 stack frame)保存一个过程中所有放不进寄存器的存储需求:需要保存的寄存器、返回地址、较大的局部变量等。它分配在栈上,遵循 LIFO。当前正在执行的过程的活动记录永远位于栈顶。
2.3 叶子过程与非叶子过程
- 叶子过程(leaf procedure)不调用其他过程。它内部不会发生
jal,ra不会被覆盖,所以不需要保存ra;如果只用临时寄存器(t)和参数寄存器(a),甚至连栈都不用碰——最简单的情况。 - 非叶子过程(non-leaf procedure)会调用其他过程。一旦执行
jal x1, ...,ra就被新返回地址覆盖,所以必须在调用前把ra压栈,返回前再恢复。同样,若用了 saved 寄存器(s),也必须先存后恢复。
2.4 帧指针(frame pointer)
有些 RISC-V 编译器用帧指针 fp(即 x8/s0)指向当前栈帧的第一个 doubleword。好处是:fp 在过程执行期间保持不变,而 sp 可能在过程体中被进一步调整(如为局部数组分配空间)。如果 sp 中途变化,同一个局部变量在不同位置就需要不同偏移来访问,代码更难读。帧指针提供一个稳定的基地址,所有栈上变量都用相对 fp 的固定偏移访问。
帧指针在调用时用 sp 的值初始化,返回时用 fp 恢复 sp。如果过程内部不改变 sp(只在入口和出口各调整一次),编译器会省略帧指针以节省一条指令——RISC-V 的 C 编译器只在过程体中会改变 sp 时才使用帧指针。
2.5 C 的两种存储类别
C 变量除了类型(int、char…),还有存储类别(storage class):
- 自动变量(automatic):过程内部的局部变量,过程退出就消失,对应栈上的空间。
- 静态变量(static):整个程序生命周期内存在,不随过程退出消失。所有过程外部声明的变量默认是 static,过程内用
static关键字声明的也是。
RISC-V 编译器保留 x3(gp,全局指针)指向静态数据区(static data segment),方便访问全局变量和常量。
三、过程翻译:三步法与例题
教材给出一个通用的 C → 汇编翻译方法:
- 寄存器分配(register allocation)——参数用 a0–a7,局部变量用 saved 或 temporary 寄存器。
- 生成过程体代码(produce code for the body)——逐行翻译运算、控制流。
- 保存和恢复寄存器(preserve registers)——按调用约定,在过程开头把需要的寄存器存栈,结尾恢复。
下面的例题都按这三步展开。
long long int leaf_example (long long int g, long long int h,
long long int i, long long int j)
{
long long int f;
f = (g + h) - (i + j);
return f;
}Solution:
- 参数 g、h、i、j 对应 x10、x11、x12、x13。
- 局部变量 f(既非参数也非返回值)对应 x20。它不能用参数寄存器(x10–x17),也不能用随时可能被覆盖的临时寄存器。
- 编译后从标签
leaf_example:开始。 - 下一步保存寄存器。由于赋值语句需要两个临时寄存器(x5、x6),加上 x20,先把它们压栈。压栈分两步:在栈上分配空间、把旧值存进去。这里 sp 减 24 字节(每个寄存器 8 字节 × 3)。
addi sp, sp, -24 ; 腾出 3 个 doubleword 的空间
sd x5, 16(sp) ; 保存 x5
sd x6, 8(sp) ; 保存 x6
sd x20, 0(sp) ; 保存 x20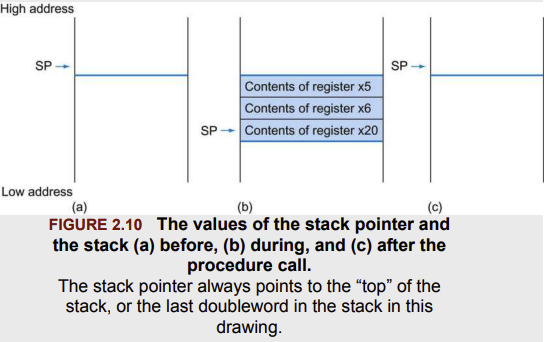
接着是过程主体与收尾:
add x5, x10, x11 ; x5 = g + h
add x6, x12, x13 ; x6 = i + j
sub x20, x5, x6 ; f = (g + h) - (i + j)
addi x10, x20, 0 ; 返回值 f 拷贝到 a0
; 恢复三个寄存器
ld x20, 0(sp)
ld x6, 8(sp)
ld x5, 16(sp)
addi sp, sp, 24 ; 弹出 3 个 doubleword
jalr x0, 0(x1) ; 跳回调用者优化:上面保存了 x5、x6、x20 三个寄存器,但 x5、x6 是临时寄存器(caller-saved),callee 不必保存。实际上只有 x20(saved 寄存器)才必须由 callee 保存。优化后只需保存/恢复 x20,省掉 x5、x6 的两次
sd和两次ld,共减少四条指令。
void swap(long long int v[], long long int k)
{
long long int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}第一步,寄存器分配:v 在 x10,k 在 x11,局部变量 temp 给 x5(叶子过程可用临时寄存器)。
第二步,过程体。常见易错点:内存按字节寻址,doubleword 相隔 8 字节,所以索引 k 要先乘以 8(左移 3 位)再加基地址:
swap:
slli x6, x11, 3 ; x6 = k * 8
add x6, x10, x6 ; x6 = v + k*8,即 &v[k]
ld x5, 0(x6) ; temp = v[k]
ld x7, 8(x6) ; x7 = v[k+1](相邻元素 +8)
sd x7, 0(x6) ; v[k] = v[k+1]
sd x5, 8(x6) ; v[k+1] = temp
jalr x0, 0(x1) ; 返回调用者第三步,保存寄存器:swap 是叶子过程,只用了临时寄存器(x5、x6、x7),没用 saved 寄存器,所以不需要任何保存/恢复。开头就是过程体,结尾就是 jalr 返回——这是叶子过程的最简形式。
四、嵌套过程与递归
嵌套过程(nested procedures)中,callee 自己又会调用别的过程从而覆盖 ra,所以必须先把 ra 压栈,返回前再恢复,才能正确跳回。递归(recursion)是嵌套过程的特例,每层调用都有自己的活动记录。
long long int fact (long long int n)
{
if (n < 1) return 1;
else return (n * fact(n - 1));
}fact:
addi sp, sp, -16 ; 开 2 个 doubleword 的栈帧
sd x1, 8(sp) ; 保存返回地址 ra
sd x10, 0(sp) ; 保存参数 n
addi x5, x10, -1 ; x5 = n - 1
bge x5, x0, L1 ; if (n-1) >= 0 跳 L1
addi x10, x0, 1 ; 否则返回 1
addi sp, sp, 16 ; 弹栈
jalr x0, 0(x1) ; 返回
L1:
addi x10, x10, -1 ; 实参变成 n-1
jal x1, fact ; 递归调用 fact(n-1)
addi x6, x10, 0 ; x6 = fact(n-1) 的结果
ld x10, 0(sp) ; 恢复 n
ld x1, 8(sp) ; 恢复 ra
addi sp, sp, 16 ; 弹栈
mul x10, x10, x6 ; 返回 n * fact(n-1)
jalr x0, 0(x1) ; 返回- 参数 n 对应 x10,过程开头把 ra 和 x10 压栈。
n < 1时返回 1。此分支里 x1、x10 没被改变,所以在弹栈前可以跳过恢复它们的ld(恢复的是没动过的值,没必要)。- 每一层递归都压一次 ra 和 n,靠栈把"调用链"完整记录下来。
尾递归优化(tail recursion)
有些递归可以改写成迭代,避免每层递归的压栈/恢复开销。典型场景是尾递归(tail call)——递归调用是过程的最后一个操作,返回后不再做任何计算:
long long int sum(long long int n, long long int acc) {
if (n > 0) return sum(n - 1, acc + n);
else return acc;
}sum(3,0) → sum(2,3) → sum(1,5) → sum(0,6),因为每次递归后没有其他操作,可以优化成循环,完全不用栈:
sum:
ble x10, x0, sum_exit ; if n <= 0 跳 sum_exit
add x11, x11, x10 ; acc = acc + n
addi x10, x10, -1 ; n = n - 1
jal x0, sum ; 跳回 sum(无条件,不保存返回地址)
sum_exit:
addi x10, x11, 0 ; 返回值 = acc
jalr x0, 0(x1) ; 返回调用者没有 addi sp、没有 sd/ld,整个过程不碰栈——把
void sort(long long int v[], long long int n)
{
long long int i, j;
for (i = 0; i < n; i += 1) {
for (j = i - 1; j >= 0 && v[j] > v[j+1]; j -= 1) {
swap(v, j);
}
}
}这是冒泡排序,内部调用前面写好的 swap。按三步法:
第一步,寄存器分配:参数 v 在 x10,n 在 x11。但 sort 内部要调用 swap,而 swap 也用 x10/x11 传参,所以必须把 sort 自己的参数拷到 saved 寄存器保护:x21 存 v,x22 存 n。循环变量 i 给 x19,j 给 x20。
第二、三步,过程体 + 保存寄存器:
; ---- 保存寄存器(prologue) ----
addi sp, sp, -40 ; 为 5 个寄存器腾空间
sd x1, 32(sp) ; 保存 ra(sort 是非叶子过程)
sd x22, 24(sp)
sd x21, 16(sp)
sd x20, 8(sp)
sd x19, 0(sp)
; ---- 拷贝参数 ----
mv x21, x10 ; x21 = v
mv x22, x11 ; x22 = n
; ---- 外层循环 ----
li x19, 0 ; i = 0
for1tst:
bge x19, x22, exit1 ; if i >= n 退出外层
addi x20, x19, -1 ; j = i - 1
; ---- 内层循环 ----
for2tst:
blt x20, x0, exit2 ; if j < 0 退出内层
slli x5, x20, 3 ; x5 = j * 8
add x5, x21, x5 ; x5 = v + j*8
ld x6, 0(x5) ; x6 = v[j]
ld x7, 8(x5) ; x7 = v[j+1]
ble x6, x7, exit2 ; if v[j] <= v[j+1] 退出内层
; ---- 调用 swap(v, j) ----
mv x10, x21 ; 参数1 = v
mv x11, x20 ; 参数2 = j
jal x1, swap ; 调用 swap
addi x20, x20, -1 ; j -= 1
j for2tst
exit2:
addi x19, x19, 1 ; i += 1
j for1tst
exit1:
; ---- 恢复寄存器(epilogue) ----
ld x19, 0(sp)
ld x20, 8(sp)
ld x21, 16(sp)
ld x22, 24(sp)
ld x1, 32(sp)
addi sp, sp, 40
jalr x0, 0(x1) ; 返回调用者关键点:sort 是非叶子过程(调用了 swap),必须保存 ra;用了四个 saved 寄存器(x19–x22),按约定都要保存/恢复;原始参数 x10/x11 在调用 swap 前会被覆盖(swap 也要用 x10/x11),所以一开始就拷到 saved 寄存器。C 的 9 行变成 34 行 RISC-V 汇编。
过程内联(procedure inlining) 是一种编译器优化:不通过
jal调用,而直接把被调用过程的代码复制到调用点。在 sort 里内联 swap 可省掉参数传递和跳转(约 4 条指令)。缺点是若该过程在多处被调用,代码体积膨胀,可能抬高缓存未命中率(cache miss rate)反而变慢。
jal ra, log_a_x # TIME POINT 0(本行执行后)
ilog2: # 求 a0 的 ilog2
addi sp, sp, -4
sw ra, 0(sp)
addi t1, zero, 1
blt t1, a0, ilog_else
addi a0, zero, 0
beq zero, zero, ilog_ret
ilog_else:
srli a0, a0, 1
jal ra, ilog2
addi a0, a0, 1
ilog_ret:
lw ra, 0(sp)
addi sp, sp, 4
jalr zero, 0(ra)
idiv: # 求 a0 / a1
addi sp, sp, -4
sw ra, 0(sp)
addi t1, zero, 0
bge a0, a1, idiv_else
addi a0, zero, 0
beq zero, zero, idiv_ret
idiv_else:
sub a0, a0, a1
jal ra, idiv
addi a0, a0, 1
idiv_ret:
lw ra, 0(sp)
addi sp, sp, 4
jalr zero, 0(ra)
log_a_x: # 计算以 a1 为底 a0 的对数
addi sp, sp, -12
sw ra, 0(sp)
sw s0, 4(sp)
sw s1, 8(sp)
add s0, a0, zero # TIME POINT 1(第 38 行执行后)
addi a0, a1, 0
jal ra, ilog2
addi s1, a0, 0
addi a0, s0, 0 # TIME POINT 2(第 42 行执行后)
jal ra, ilog2
addi a1, s1, 0
jal ra, idiv
lw s1, 8(sp) # TIME POINT 3(第 46 行执行后)
lw s0, 4(sp)
lw ra, 0(sp)
addi sp, sp, 12
jalr zero, 0(ra) # TIME POINT 4(第 50 行执行后)分析这类题的关键:log_a_x 在入口用 addi sp, sp, -12 开了 3 个字的栈帧,分别保存 ra、s0、s1(它们是 callee-saved,且后续调用 ilog2/idiv 会覆盖 ra);ilog2 和 idiv 各自递归,每层都把 ra 压栈。靠观察栈上 ra 的变化和 sp 的移动,可以反推递归发生了几层、各时间点寄存器的值。
五、内存布局
低地址
│
├── Reserved 区域(操作系统保留)
├── Text segment(代码段:程序的机器码)
├── Static data segment(全局变量、常量等)
├── Heap(堆:动态分配内存,如 malloc)
│ ↓(向高地址增长)
│
│ ↑(向低地址增长)
├── Stack(栈:局部变量、函数调用)
高地址
这些地址只是软件约定,并不是 RISC-V 架构的一部分。用户地址空间设为 0x0000 003f ffff fff0,并向下增长到数据段;程序代码("text")从 0x0000 0000 0040 0000 开始。
注意栈和堆朝彼此生长(栈从高地址向低地址、堆从低地址向高地址),这样可以灵活共享中间的空闲内存。
超过八个参数怎么办?
RISC-V 的约定是:前八个参数放寄存器 x10–x17,其余参数放到栈上,紧挨着帧指针,被调用者通过帧指针寻址。
堆的动态内存分配
静态数据区适合大小固定的数据(全局变量、常量、定长数组),但链表、树这类结构在运行时不断增长缩小,不适合放静态区。堆(heap)就是为动态数据准备的区段,紧挨静态数据区上方,向高地址增长。
C 用两个显式函数管理堆:malloc() 在堆上分配指定大小、返回指针;free() 释放之前分配的空间。完全手动控制内存的分配释放,这正是许多难调 bug 的来源:
- 内存泄漏(memory leak):分配了却忘记释放。程序跑得越久,被"遗忘"的内存越多,最终可能耗尽可用内存导致崩溃。
- 悬空指针(dangling pointer):过早释放了内存,却仍有指针指向那块已释放区域。之后通过它读写,会访问到意义不明的数据,或已被重新分配给别处的内存,导致不可预测的行为。
Java 为避免这两类 bug,采用自动内存管理和垃圾回收(garbage collection),程序员不需要手动 free。