Lec 4 RISC-V 汇编:寄存器与指令
本节内容
本节按"寄存器 → 指令"的顺序展开。我们先从 RISC-V 处理器的组成结构和指令集设计的三条原则出发,理解"为什么这样设计";然后系统地讲解寄存器及其作用——RISC-V 有哪 32 个寄存器、各自的角色、为什么是 32 个;接着讲解指令的几种类型及其区别(计算指令、存取指令、控制流指令、伪指令),并深入到所有 6 种指令格式的编码、符号扩展、寻址模式等细节;最后通过若干例题把这些拼到一起,并附一节单周期数据通路的扩展阅读。
调用约定、栈与活动记录、内存布局放在 Lec 5 单独讲。本节出现的
jal/jalr只作概念性介绍,完整的过程调用机制见下一节。
一、处理器组成与设计原则
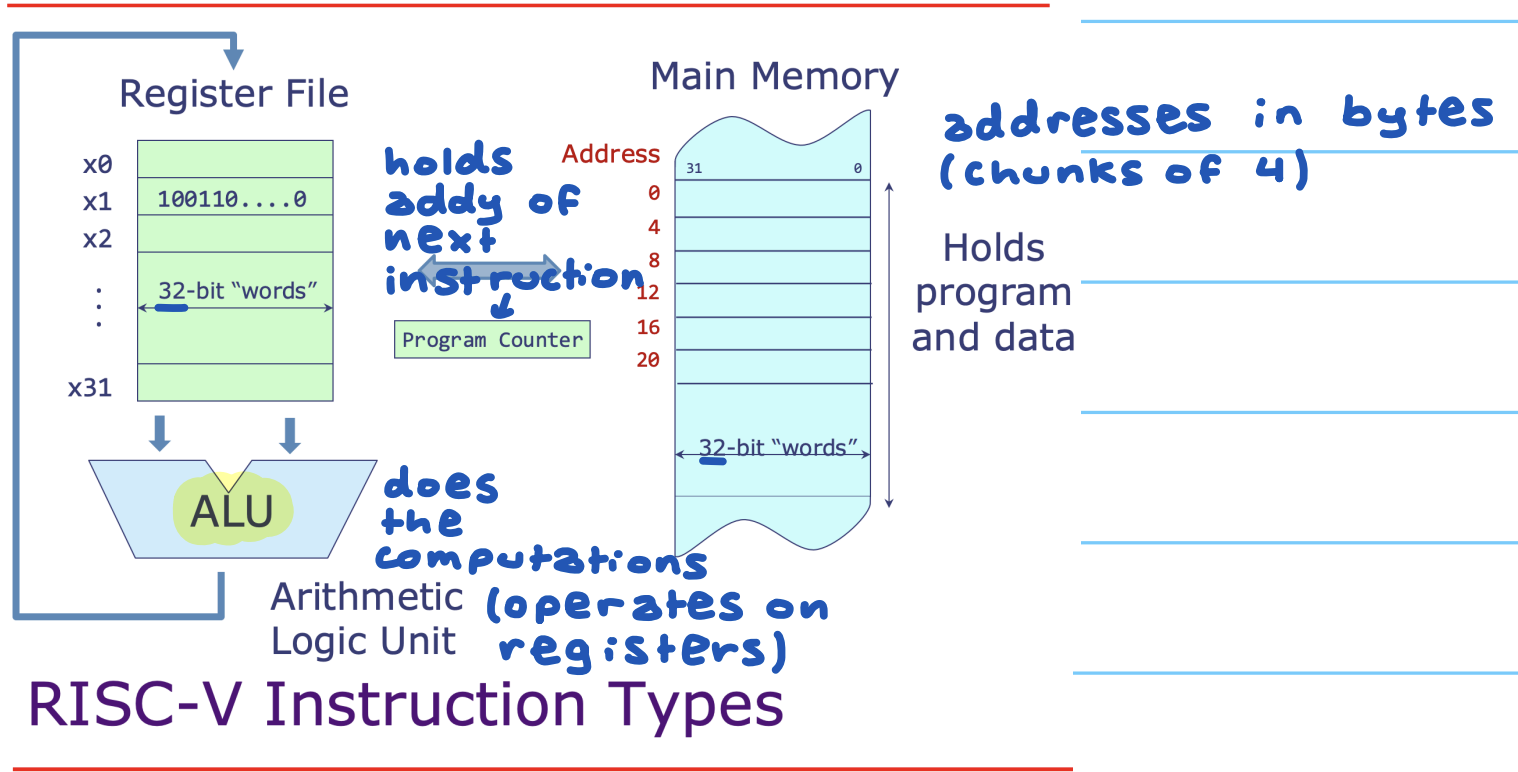
上图是 RISC-V 处理器的组成结构(简易版,更完整的数据通路见本节末尾的扩展阅读)。核心部件有:PC(程序计数器) 跟踪当前指令地址、寄存器堆保存 32 个通用寄存器、ALU 执行运算、指令存储器/数据存储器分别存放代码和数据,上图未画出。
指令集设计的三条原则
RISC-V 的指令集设计遵循三条核心原则:
- 原则一:简单源于规整(simplicity favors regularity)。 所有算术指令都保持相同的格式——三个操作数(两个源、一个目的),这种规整性让硬件设计更简单。
- 原则二:越小越快(smaller is faster)。 RISC-V 只有 32 个通用寄存器,而不是更多。寄存器数量越少,硬件中的信号传播距离越短,时钟周期越快。如果寄存器超过 32 个,每个寄存器字段就需要多于 5 位来编码(
),指令格式会更复杂,硬件也更慢。 - 原则三:优秀的设计需要好的折中(good design demands good compromises)。 "所有指令长度固定为 32 位"和"保持单一指令格式"之间存在矛盾——不同类型的指令需要不同的字段划分。RISC-V 的折中是:所有指令都是 32 位长,但允许多种指令格式(R-type、I-type、S-type 等),由 opcode 字段区分。
pc = pc + 4;控制流(分支/跳转)时 pc = 目标地址。如果 PC 指向某处,就默认那里是指令,不要把它当数据覆写。 二、寄存器及其作用
2.1 为什么用寄存器?
寄存器是 CPU 内部的一小块高速存储,直接连在数据通路上,访问只需一个时钟周期——比访问内存快一两个数量级。RISC-V 是一台 load/store 架构:ALU 只能对寄存器里的值做运算,所有内存数据都必须先 load 进寄存器、算完再 store 回内存。因此寄存器是几乎所有指令的操作对象,理解寄存器是理解全部指令的前提。
RV64 中每个通用寄存器宽 64 位(一个 doubleword)。一共有 32 个通用寄存器,编号 x0~x31。"32 个"正是上面"越小越快"原则的结果:刚好用 5 位(
2.2 x0:硬连线的 0
x0 被硬件固定为常数 0,写它无效、读它恒为 0。这个看似浪费的设计极其有用,许多伪指令靠它实现:
mv x2, x1=addi x2, x1, 0(拷贝寄存器)li x2, 3=addi x2, x0, 3(把立即数搬进寄存器)j Label=jal x0, Label(跳转但丢弃返回地址,因为写 x0 等于不保存)beq x0, x0, Exit(条件恒真,实现无条件跳转)
2.3 ABI 命名与寄存器约定
虽然硬件只认识 x0~x31,但汇编程序员和编译器按 ABI(应用二进制接口)约定给它们起了有意义的别名,并约定了每个寄存器的用途和"谁负责保存"。下表是完整的约定("保存者"一列的含义在 Lec 5 的调用约定中详细展开,这里先建立印象):
| 寄存器 | 符号名 | 英文 | 用途 | 跨调用保存者 |
|---|---|---|---|---|
| x0 | zero | Hardwired zero | 硬件固定为 0 | — |
| x1 | ra | Return address | 返回地址 | 调用者 |
| x2 | sp | Stack pointer | 栈指针 | 被调用者 |
| x3 | gp | Global pointer | 全局指针 | — |
| x4 | tp | Thread pointer | 线程指针 | — |
| x5–x7 | t0–t2 | Temporaries | 临时寄存器 | 调用者 |
| x8 | s0/fp | Saved register / Frame pointer | 保存寄存器/帧指针 | 被调用者 |
| x9 | s1 | Saved register | 保存寄存器 | 被调用者 |
| x10–x11 | a0–a1 | Function arguments / return values | 参数和返回值 | 调用者 |
| x12–x17 | a2–a7 | Function arguments | 函数参数 | 调用者 |
| x18–x27 | s2–s11 | Saved registers | 保存寄存器 | 被调用者 |
| x28–x31 | t3–t6 | Temporaries | 临时寄存器 | 调用者 |
记忆要点:a(argument)传参/返回,s(saved)跨调用稳定保留,t(temporary)随时可能被覆盖,ra 存返回地址,sp 指栈顶。
三、指令类型及其区别
按功能划分,RISC-V 指令大致分为四类。注意这和后面按编码划分的"指令格式"是两个不同的维度:
- 由 ALU 执行的计算指令
- 寄存器-寄存器:
oper rd, rs1, rs2 - 寄存器-立即数:
oper rd, rs1, constant(12-bit),或lui rd, luiConstant(20-bit)
- 寄存器-寄存器:
- 存取指令(load/store)
ld rd, offset(rs1)/sd rs2, offset(rs1)(doubleword);lw/sw(word)等- 内存地址 =
reg[rs1] + 符号扩展(offset)
- 控制流指令
- 条件型:
comp rs1, rs2, label - 非条件型:
jal rd, label和jalr rd, offset(rs1)
- 条件型:
- 伪指令
- 其他真实指令的简写形式
下面逐类展开它们的区别。
3.1 计算指令(ALU)
R-type:寄存器-寄存器运算。 形如 add x9, x20, x21,三个操作数都是寄存器:两个源 rs1、rs2,一个目的 rd。涵盖 add、sub、and、or、xor、sll、srl、sra 等。
I-type 运算:寄存器-立即数运算。 形如 addi x5, x6, 3,一个源是寄存器、另一个是嵌在指令里的 12 位常数。涵盖 addi、andi、ori、slli 等。
RISC-V 没有
subi指令——因为立即数是二补码表示,addi x5, x5, -3就等价于减 3,再造一条减法的立即数指令是冗余的。
-1 编码 0xFFF 扩展后仍是 64 位的 -1。这正是"没有 subi"能成立的底层原因。 lui / auipc:构造大常数与大地址。 12 位立即数只能表示 −2048~2047,要装入一个完整的 32 位常数需要两条指令配合:
lui rd, imm20(Load Upper Immediate):把 20 位立即数放进rd的第 31~12 位,低 12 位清零。配合一条addi补上低 12 位,即可拼出任意 32 位常数。auipc rd, imm20(Add Upper Immediate to PC):把 20 位立即数左移 12 位后加到当前 PC,结果写入rd。它是实现 PC 相对地址(位置无关代码、访问全局符号)的关键,配合addi/jalr可以跳到/取到任意 32 位距离外的地址。
lui + addi 的符号扩展补偿:用
lui+addi拼 32 位常数时,如果低 12 位的最高位(第 11 位)是 1,addi会把这 12 位当负数处理(符号扩展),相当于多减了。补偿办法是给 lui的 20 位常数额外加 1(lui的常数左移 12 位,加 1 恰好补回)。汇编器处理 li伪指令时会自动补偿,手动拆分时必须自己注意。
3.2 存取指令(load / store)
计算指令只能操作寄存器,访问内存得靠 load/store:
ld rd, offset(rs1):从地址rs1 + offset读一个 doubleword 到rd。sd rs2, offset(rs1):把rs2写到地址rs1 + offset。- 同族还有
lw/sw(word,4 字节)、lh/sh(half)、lb/sb(byte);load 的窄宽度版本还分符号扩展(lw)和零扩展(lwu)。
地址计算:内存地址 = reg[rs1] + 符号扩展(offset)。rs1 是基地址寄存器,offset 是 12 位有符号偏移——这就是"基址偏移寻址"。
i 要先乘以元素大小(左移 3 位=×8,左移 2 位=×4)再加基地址——这是汇编里最常见的易错点。例如长度 10 的 int 数组占 40 字节。 3.3 控制流指令
计算机区别于计算器的核心能力是做决策。控制流指令改变 PC 的去向。
条件分支(6 条):覆盖所有有符号/无符号比较。
| 指令 | 含义 | 比较类型 |
|---|---|---|
beq rs1, rs2, label | 若 rs1 == rs2 跳转 | 有/无符号 |
bne rs1, rs2, label | 若 rs1 ≠ rs2 跳转 | 有/无符号 |
blt rs1, rs2, label | 若 rs1 < rs2 跳转(有符号) | 有符号 |
bge rs1, rs2, label | 若 rs1 ≥ rs2 跳转(有符号) | 有符号 |
bltu rs1, rs2, label | 若 rs1 < rs2 跳转(无符号) | 无符号 |
bgeu rs1, rs2, label | 若 rs1 ≥ rs2 跳转(无符号) | 无符号 |
有符号与无符号的区别在于对最高位的解读:有符号比较里最高位为 1 表示负数(小于任何正数);无符号比较里最高位为 1 表示一个很大的正数。
数组越界检查的技巧:要检查
(数组索引 x 是否合法),只需一条无符号比较 bgeu x20, x11, IndexOutOfBounds。原理是:如果 x 是负数,它在无符号解读下会变成一个非常大的正数,一定 ≥ y;如果 x ≥ y,条件同样成立。一条指令同时完成了"x 是否为负"和"x 是否越界"两个检查。
无条件跳转(本节先建立概念,完整用途见 Lec 5 调用约定):
jal rd, label(jump-and-link):跳到 label,同时把返回地址(PC+4)写入rd。写x0即丢弃返回地址,等价于纯跳转j label。jalr rd, offset(rs1)(jump-and-link register):跳到rs1 + offset(最低位强制清零,即target = (rs1 + offset) & ~1),返回地址写入rd。它能跳到寄存器算出来的任意地址,是函数返回和间接调用的基础。
3.4 伪指令(pseudo-instruction)
伪指令是若干真实 RISC-V 指令的简写,汇编器会把它们展开成等价的真实指令:
| 伪指令 | 展开为 | 作用 |
|---|---|---|
mv x2, x1 | addi x2, x1, 0 | 将 x1 的值复制到 x2(寄存器拷贝) |
li x2, 3 | addi x2, x0, 3 | 立即数 3 装入 x2(12 位以内单指令) |
li x3, 0x4321 | lui x3, 0x4 + addi x3, x3, 0x321 | 超过 12 位的常数需 lui+addi 两条;先放高 20 位、清零低 12 位,再加低 12 位 |
j label | jal x0, label | 无条件跳转,不保存返回地址 |
ble x1, x2, label | bge x2, x1, label | 若 x1 ≤ x2 跳转(交换操作数实现) |

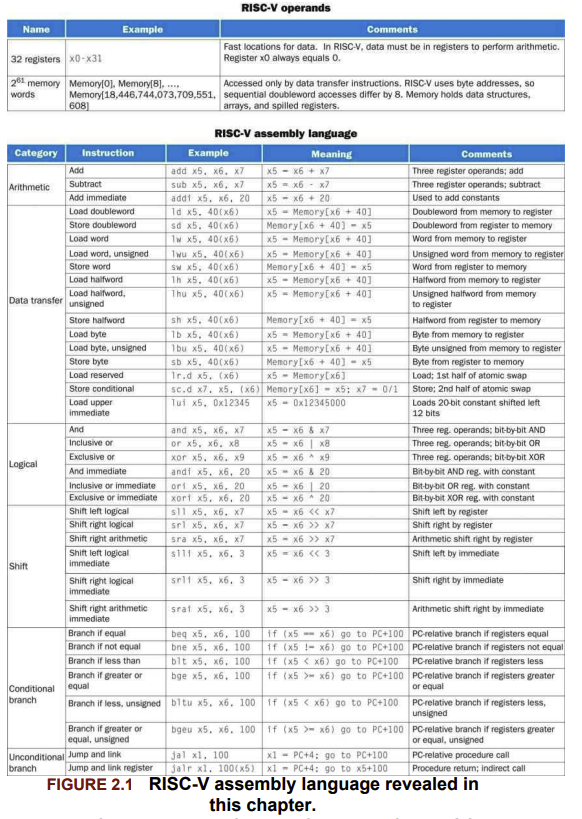
图:RISC-V 操作数与操作指令类型汇总
四、指令格式(Instruction Formats)
上一节按"功能"分类,这一节按"编码"分类。RISC-V 所有指令都是 32 位长。不同类型的指令需要不同的字段划分,因此有 6 种指令格式,每种由 opcode 字段区分,硬件据此决定如何解读剩余的位。
各字段含义:opcode 标识基本操作和格式;rd 是目的寄存器;rs1/rs2 是源寄存器;funct3/funct7 是辅助操作码,用来在同一 opcode 下区分具体操作;immediate 是嵌在指令里的常数。
R-type(寄存器型) | 寄存器-寄存器算术/逻辑运算(add、sub、and、or、sll…) [funct7(7) | rs2(5) | rs1(5) | funct3(3) | rd(5) | opcode(7)] 三个寄存器字段加 funct7、funct3 共同确定操作。例 add x9, x20, x21:opcode=0110011,funct7=0000000,funct3=000,rs1=20,rs2=21,rd=9。
I-type(立即数型) | 带一个常数的运算(addi、andi)及加载(lw、ld、jalr) [immediate(12) | rs1(5) | funct3(3) | rd(5) | opcode(7)] 12 位立即数以二补码解释,范围 −2048~2047。对 load 指令,这 12 位就是相对基地址 rs1 的字节偏移。
S-type(存储型) | store 指令(sw、sd) [imm[11:5](7) | rs2(5) | rs1(5) | funct3(3) | imm[4:0](5) | opcode(7)] store 需要两个源寄存器(基址 rs1、数据 rs2)加偏移量,没有目的寄存器。12 位立即数被拆成两段分布在指令两端。
B-type(分支型,又叫 SB-type) | 条件分支(beq、bne、blt…) 格式类似 S-type,12 位立即数编码相对 PC 的偏移(以 2 字节为单位),跳转范围 −4096~+4094 字节。分支地址 = PC + 符号扩展后的偏移,即 PC 相对寻址。
U-type(高位立即数型) | lui、auipc [imm[31:12](20) | rd(5) | opcode(7)] 20 位立即数放入 rd 的高 20 位,低 12 位清零。
J-type(跳转型,又叫 UJ-type) | jal [imm(20) | rd(5) | opcode(7)] 20 位立即数编码 PC 相对偏移(以 2 字节为单位),跳转范围 ±1 MiB;同时把 PC+4 写入 rd 作返回地址。
| 格式 | 用途 | 示例指令 |
|---|---|---|
| R-type | 寄存器-寄存器运算 | add、sub、and、or、sll、srl |
| I-type | 立即数运算、加载 | addi、andi、lw、ld、jalr |
| S-type | 存储 | sw、sd |
| B-type | 条件分支 | beq、bne、blt、bge、bltu、bgeu |
| U-type | 高位立即数 | lui、auipc |
| J-type | 无条件跳转 | jal |
rs1、rs2、funct3 字段在所有格式中固定在相同的位置,于是寄存器读取、立即数符号位(永远在第 31 位)的提取电路可以共用,硬件译码大大简化。换言之,牺牲一点"立即数对人类的可读性",换来硬件的规整——又是"简单源于规整"原则的体现。 五、寻址模式总结
| 寻址模式 | 描述 | 示例 |
|---|---|---|
| 立即数寻址(immediate) | 操作数是指令中的常数 | addi x5, x6, 4 |
| 寄存器寻址(register) | 操作数在寄存器中 | add x5, x6, x7 |
| 基址偏移寻址(base/displacement) | 地址 = 寄存器 + 指令中的常数 | ld x5, 40(x6) |
| PC 相对寻址(PC-relative) | 地址 = PC + 指令中的常数 | beq x5, x6, Label |
PC 相对寻址的细节
条件分支和 jal 中的立即数不是绝对地址,而是相对当前 PC 的偏移量,实际跳转地址 = PC + 偏移量。好处是:分支通常跳到附近指令(循环体、if-else 的另一分支),12 位偏移足以覆盖大多数情况(SPEC 基准里约一半的条件分支跳转距离不超过 16 条指令)。
如果分支距离超出 12 位偏移范围,汇编器会自动把远距离条件分支拆成两条:先用条件取反的分支跳过一条无条件跳转,再用 jal(20 位偏移,范围更大)跳到真正的目标。例如 beq x10, x0, L1(L1 太远)会被替换为:
bne x10, x0, L2 ; 条件取反,跳过下面一条
jal x0, L1 ; 无条件跳到远处的 L1
L2:如果连 jal 的 20 位也不够(需跳到任意 32 位地址),可用 auipc/lui + jalr 组合:先把目标地址高 20 位放入临时寄存器,再用 jalr 加上低 12 位并跳转。
例题
if (i == j) f = g + h; else f = g - h;编译的一般技巧是:测试与原始条件相反的条件,跳过 then 分支。这样条件为真时不需要额外跳转,代码更高效:
bne x22, x23, Else ; 如果 i ≠ j,跳到 Else
add x19, x20, x21 ; f = g + h(i == j 时执行)
beq x0, x0, Exit ; 无条件跳到 Exit
Else: sub x19, x20, x21 ; f = g - h(i ≠ j 时执行)
Exit:beq x0, x0, Exit 是实现无条件跳转的一种方式(条件永远为真),等价于伪指令 j Exit。
while (save[i] == k) i += 1;Loop: slli x10, x22, 3 ; x10 = i * 8(doubleword 偏移)
add x10, x10, x25 ; x10 = save + i*8 = &save[i]
ld x9, 0(x10) ; x9 = save[i]
bne x9, x24, Exit ; 如果 save[i] ≠ k,退出循环
addi x22, x22, 1 ; i = i + 1
beq x0, x0, Loop ; 跳回 Loop
Exit:常见易错点:数组索引 i 要乘以元素大小(doubleword 是 8 字节)再加基地址,用左移代替乘法(左移 3 位=×8)。
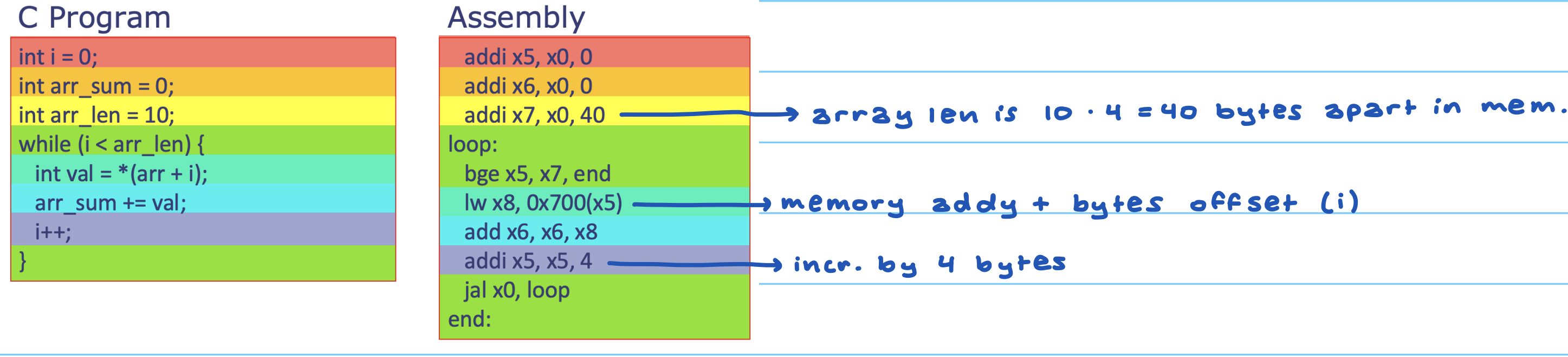
回顾要点:数据内存和指令内存是不同区段,PC 指向处默认是指令、不要覆写;相邻内存位置相隔 1 个字节,长度 10 的 int 数组占 40 字节,遍历时每步地址 +4。
扩展阅读:单周期处理器数据通路

图中是一个单周期 RISC-V 处理器的数据通路(datapath),各组件作用:
- PC(程序计数器):32 位寄存器,保存当前指令地址。每周期末更新为 PC+4 或分支/跳转目标。底部的 MUX(标 M)在两个来源间选择。
- 指令存储器(Instr mem):只读,PC 作地址输入,输出 32 位指令,再拆成各字段分发。
- 控制单元(Control):根据 opcode(及 funct3/funct7)译码,生成控制信号——ALU 做加还是减?数据存储器读还是写?寄存器写回口接 ALU 还是数据存储器?
- 寄存器堆(Register file):32 个寄存器,两个读端口(同时读 rs1、rs2)、一个写端口(写回 rd)。读是组合逻辑,写在时钟上升沿。
- 立即数生成器(Imm gen):按指令格式(I/S/B/U/J)从不同位置抽取立即数,做拼接和符号扩展,输出完整的立即数。
- ALU:输入 A 来自 rs1;输入 B 经 MUX 选 rs2(R-type)或立即数(I/S/B-type)。操作由控制单元的 ALU op 信号决定,并输出"零标志"供分支判断。
- 数据存储器(Data mem):读写存储器,只有 load/store 用到。ALU 算出的地址作输入;store 把 rs2 写入,load 把读出的值送回寄存器堆写 rd。
- MUX(多路选择器):三个关键 MUX——ALU 输入 B(rs2 还是立即数)、写回(ALU 结果还是内存读出)、PC 更新(PC+4 还是分支目标)。
不同指令类型在数据通路上走的路径不同:
- R-type(
add x9, x20, x21):取指 → 读 rs1、rs2 → ALU 运算 → 写回 rd。数据存储器不参与。 - I-type 运算(
addi x5, x6, 3):同 R-type,但 ALU 的 B 输入来自立即数生成器。 - Load(
ld x9, 40(x10)):读 rs1 → ALU 算地址 → 数据存储器读 → 写回 rd。 - Store(
sd x9, 40(x10)):读 rs1(基址)和 rs2(数据)→ ALU 算地址 → 写入数据存储器。不写回寄存器堆。 - Branch(
beq x5, x6, label):读 rs1、rs2 → ALU 做减法比较 → 若为零则 PC 选分支目标,否则选 PC+4。