Lec1 二进制基础
二进制运算
字节(byte)是 8 个比特(bit)的组合,,取值范围从 00000000 到 11111111,即十进制 0 到 255,一共
无符号整数(unsigned int)只表示非负数, n 可以表示为 0 到 0b, 二进制转十进制就是按位展开;反之可以通过不断减去比当前数小的最大2的幂来实现
二进制加减法和十进制类似,逐位运算并处理进位(carry)。
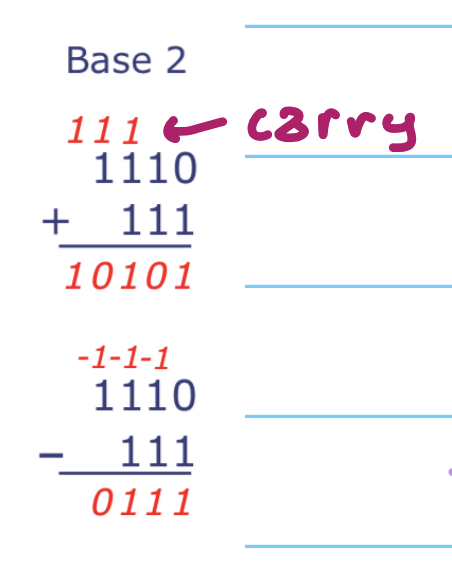
需要注意位数固定带来的问题:寄存器位数有限,运算结果超出范围时会发生回绕(wraparound),即高位被丢弃,也就是说计算机硬件执行固定位宽的模运算(mod)。例如对一个固定位宽的数做左移,移出去的高位会丢失,低位补 0。
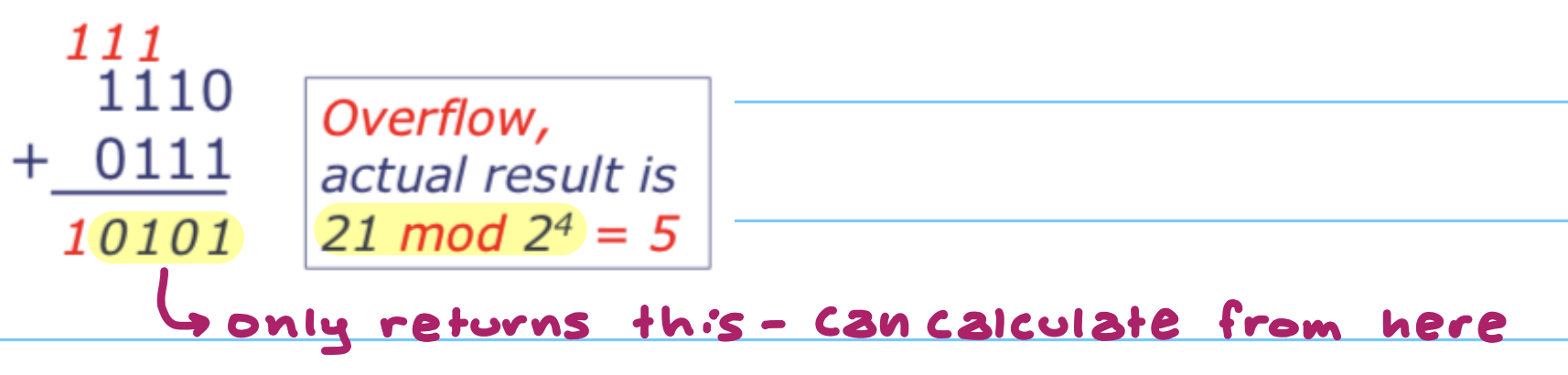
十六进制前缀为0x,一位十六进制对应 4 位二进制。底层的比特是一样的,十六进制只是更紧凑的书写形式。
位运算
C 提供六个位运算符,直接作用在整数的每一个比特上(区别于逻辑运算符 && || !,后者把整个值看成一个"真/假"):
| 运算符 | 名称 | 作用 |
|---|---|---|
& | 按位与(AND) | 两位都为 1 才得 1 |
| | 按位或(OR) | 有一位为 1 就得 1 |
^ | 按位异或(XOR) | 两位不同得 1 |
~ | 按位取反(NOT) | 0↔1 |
<< | 左移 | 低位补 0,相当于 ×2ⁿ |
>> | 右移 | 无符号补 0 / 有符号补符号位,相当于 ÷2ⁿ |
常用惯用法(idioms)——底层编程和考试里反复出现的套路:
| 目的 | 写法 |
|---|---|
| 取第 n 位 | (x >> n) & 1 |
| 置第 n 位为 1 | x | (1 << n) |
| 清第 n 位为 0 | x & ~(1 << n) |
| 翻转第 n 位 | x ^ (1 << n) |
| 取低 8 位(掩码) | x & 0xFF |
| 判断奇偶 | x & 1(为 1 即奇数) |
| 乘 / 除 2 的幂 | x << k / x >> k |
| 清除最低位的 1 | x & (x - 1)(常用于统计比特中 1 的个数) |
XOR 的性质很有用:x ^ x == 0、x ^ 0 == x、可交换可结合;由此能不借助临时变量交换两数(但实战别用,可读性差,且两操作数同地址时会被清零)。~0 是全 1(即 −1 的补码 / 无符号最大值),常用来造掩码。
容易踩坑的点:
&不是&&,|不是||。 位运算逐位计算且不短路;逻辑运算只看整体真假并短路。1 & 2是 0(按位与),而1 && 2是 1(都为真)——误用是高频 bug。- 移位优先级低于
+ -:1 << n + 1实际是1 << (n + 1),不是(1 << n) + 1。养成加括号的习惯。 - 移位量 ≥ 位宽、对有符号负数移位的坑,见下面"整数知识点"一节。
有符号数与补码
把一个二进制数当作有符号还是无符号来解释,得到的值不同。最高位(most significant bit,MSB)在有符号解释下是符号位。
补码(two's complement)是 RISC-V 采用的有符号表示法。求一个数的相反数(negate)的方法是:按位取反(invert)后再加 1,即 −A = ~A + 1。这种表示法的好处是天然支持环绕取模,加减法不需要为符号位做特殊处理。判断范围时,n 位二补码能表示的最小值是 0b1000...0(即 0b0111...1(即
举例:
- 对 4 位二补码,
0b0001取反得0b1110,加 1 得0b1111,即 −1。
逻辑移位与算术移位的区别很重要:逻辑右移(logical shift,用于无符号数)高位一律补 0;算术右移(arithmetic shift,用于有符号数)在 MSB 为 1 时高位补 1,以保持符号不变。是否补符号位取决于数据类型。
硬件完全不需要知道这些数是"有符号"还是"无符号"的。加法器只是把两个 4 位二进制数逐位相加,高位溢出的进位丢弃——这个"丢弃进位"的操作,在数学上恰好等价于对
取模,而补码的编码方式保证了取模后的结果,用有符号方式解读时仍然是正确的。这就是"天然支持环绕取模"的含义
容易踩坑的整数知识点
这些点在课堂上常一带而过,但考试和实际编程里最容易出错:
有符号溢出是未定义行为(UB),无符号溢出才是良定义的环绕。 硬件层面两者都是丢进位、对
取模;但在 C 语言语义上, signed int溢出是未定义行为——编译器可以假设它"永不发生"并据此优化,结果可能完全反直觉(例如x + 1 > x被优化成恒为真)。无符号则保证mod 2^n环绕。有符号 / 无符号混合比较,会被统一转成无符号。 这是最隐蔽的坑:
cint i = -1; if (i < sizeof(arr)) { ... } // sizeof 返回无符号 size_t-1被转成一个巨大的无符号数,条件意外为假。记住-1 > 0u在 C 里是真。补码不对称:负数比正数多一个。 n 位补码范围是
。所以 INT_MIN(如 32 位的 −2147483648)没有对应的正数:-INT_MIN仍是INT_MIN(溢出),abs(INT_MIN)是 UB。移位的三个坑:① 移位量 ≥ 位宽是 UB(32 位
int左移 32 位结果未定义,并非简单得 0);② 对负数右移是实现定义(多数平台算术右移补符号,但标准不保证);③ 左移把 1 移进或越过符号位是 UB。八进制字面量陷阱:以
0开头的整数字面量是八进制。010等于十进制 8,int x = 0123;是 83 而不是 123——对齐写代码时给数字补前导 0 会悄悄改变它的值。char的符号性由实现决定。char可能是signed也可能是unsigned(平台相关)。char c = 0xFF;在 signed char 上是 −1,参与比较或被提升为 int 时会符号扩展成0xFFFFFFFF。处理原始字节时应显式用unsigned char。整数提升(integer promotion):比
int小的类型(char、short)在参与运算前会先被提升为int。所以两个unsigned char相乘可能在int里进行、不会环绕,行为和你以为的"8 位运算"不同。
字节序(endianness)
一个多字节的值(如 4 字节的 int)要占用连续的几个字节地址,这些字节按什么顺序排列就是字节序:
- 小端(little-endian):低位字节放在低地址。RISC-V、x86、常见配置的 ARM 都是小端。
- 大端(big-endian):高位字节放在低地址。网络传输(network byte order)和部分嵌入式系统用大端。
以 int x = 0x12345678 存在地址 0x100 为例:
| 地址 | 小端存放 | 大端存放 |
|---|---|---|
| 0x100 | 0x78 | 0x12 |
| 0x101 | 0x56 | 0x34 |
| 0x102 | 0x34 | 0x56 |
| 0x103 | 0x12 | 0x78 |
为什么要关心它:只要把同一块内存"按不同宽度"重新解读,就会撞上字节序——这是底层编程绕不开的点:
- 把
int *转成char *逐字节读,读到的顺序依赖字节序。检测本机字节序的经典写法:cint x = 1; char *p = (char *)&x; // *p == 1 → 小端;*p == 0 → 大端 - 网络协议、文件格式常规定用大端,跨机器传二进制数据要用
htonl/ntohl等转换,否则收到的数会"字节翻转"。 - 用
gdb或十六进制工具查看内存时,小端机器上一个int看起来是"倒着"的,别被吓到。
字节序只影响字节之间的排列,不影响一个字节内部的位顺序,也不影响数组元素顺序(
a[0]永远在更低地址)。
浮点数
浮点数的表示
浮点数用指数格式表示,以牺牲精度换取更大的数值范围。32 位浮点数只有
IEEE 754
32 位单精度的字段划分是:1 位符号、8 位指数、23 位尾数(mantissa)。指数采用偏移码,偏移量(bias)为 127,即实际指数 = 存储的指数值 − 127。

为什么需要用偏移码?指
Sol: 指数可正可负。比较数字时,直接按照无符号进行比较算出大小即可。
为什么最高位一定是 1?
Sol: 十进制科学表示法,我们不会写成0.6 * 10^3,二进制也一样; 又因为二进制的关系,最高位必须是1
指数的取值是多少? 另外指数字段全0、全1分别代表什么?
Sol: 8 位指数字段存的是 0~255,但 0 和 255 被保留作特殊语义,所以规格化数(normalized)的存储指数只能取 1~254,对应真实指数 −126 ~ +127(减去偏移 127)。两个保留值的含义是:
| 指数字段 | 尾数字段 | 含义 |
|---|---|---|
| 全 0(0) | 全 0 | ±0(带符号的零) |
| 全 0(0) | 非 0 | 次正规数(subnormal/denormal):没有隐含的前导 1,用 0.fff × 2^(−126) 表示,填补 0 附近的"下溢空洞",实现渐进下溢 |
| 全 1(255) | 全 0 | ±∞(由符号位决定正负,常见于除以 0、溢出) |
| 全 1(255) | 非 0 | NaN(Not a Number,如 0/0、∞−∞、sqrt(−1)) |
常见误区:把"指数全 0"当成无穷大。其实全 0 对应零/次正规数,全 1 才对应无穷大/NaN——记反了在判题里很容易丢分。
25 = 0b11001 = 1.1001 × 2^4,指数 4 + 127 = 131 = 0b10000011,符号位 0,尾数取 1001 后补零。
化为二进制小数 0.00111,规格化后实际指数为 −3,存储指数 = −3 + 127 = 124 = 0b01111100。
容易踩坑的浮点知识点
大多数小数无法精确表示,不能用
==比较浮点数。0.1、0.2在二进制里是无限循环小数,存储时被舍入,所以0.1 + 0.2 != 0.3。正确做法是判断fabs(a - b) < epsilon。浮点加法不满足结合律。
(a + b) + c未必等于a + (b + c),求和的顺序会影响结果和精度。这也是为什么并行/向量化求和可能得到和串行不同的结果。大数吸收小数(吸收误差)。 当两个数量级相差很大时,小数会被直接舍弃:
1e8f + 1e-8f的结果就是1e8f。在循环里反复"大数加小数"会丢失全部贡献。int → float也可能丢精度。float的有效位只有 24 位(23 位尾数 + 1 位隐含),所以大于(约 1677 万)的整数转成 float可能无法精确表示——别以为"整数转浮点一定无损"。NaN 不等于任何值,包括它自己。
NaN == NaN为假,NaN != NaN为真。判断一个数是不是 NaN 必须用isnan(),而不是x == x(虽然x != x恰好能用来检测 NaN)。+0.0和−0.0相等但不完全等价。+0.0 == -0.0为真,但1.0/+0.0 = +∞而1.0/-0.0 = -∞,符号会通过除法泄露出来。
printf

printf易踩的坑:%d/%u/%x把同一组比特按不同方式解读,传错说明符是 UB;float实参传给printf会被自动提升为double,所以打印浮点统一用%f/%lf都可;%d配long或指针、%s配一个非字符串指针,都会读到错误内存甚至崩溃。格式说明符必须和实参类型严格对应。