Lec 3 C语言的数组&字符串&结构体
数组与指针
指针是一种用于存放另外一个变量的地址的变量。 地址位宽为32bit,不同的数据类型有不同的字节大小,因此需要指定指针的类型,这样它就能知道如何读取 & 解释有多少字节。函数中常用来更改原始数据的值,函数默认是值拷贝。
指针的错误用法;
int *x = 0; // x 存储的内存地址为 0; 或者说x指向地址0; 或者x的值为0
*x = 5; // Segmentment fault ❌,地址 0 被保留用于表示空指针(null)并且不能被更改int a = 1;
int *x; // 没有指向特别的地址
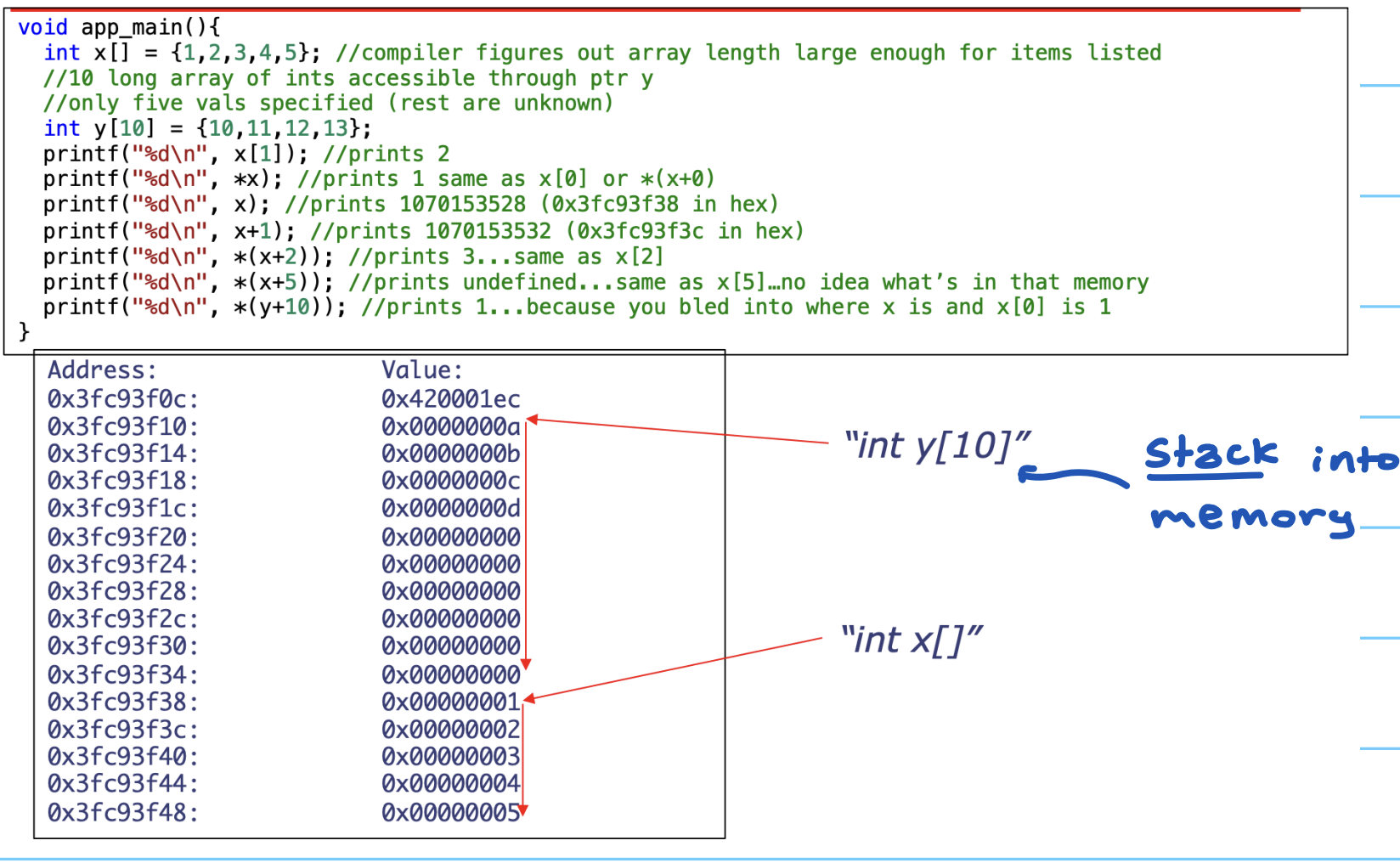
*x = a; // Segmentment fault ❌, x存储的地址不合法C 里的数组(array)是一段连续的内存,长度固定,定义时需指定类型和长度。
声明数组会做两件事:为数组分配内存;创建一个指针,通过它访问这段内存。数组是一个固定指针,不能重新赋值。C 不做越界检查,用指针访问数组时可能读到内存中未知的部分,这是潜在的 bug 来源。
把数组传入函数时,函数实际看到的只是数组的首地址指针,无法从中得知数组长度,所以在函数内部没有内在办法知道数组有多大,长度通常需要额外作为参数传入。C 中所有函数参数都是按值传递(passed by value),传进去的是副本而非原件。
初始化方法:
int x[] = {1, 2, 3, 4};构成4个int长的长度数组,并取名为xint y[10];创建一个10个int长度的数组,取名为y(但是没有声明其值)int z[5] = {1};创建5个int长度的数组,取名为z;下标为0的元素是1,其余为0char a[10] = {'t', 'h', 'e', ' ', 'c', 'a', 't', '.'};10个char长度的数组,结尾有两个nullchar b[] = "the cat.";9个长度为char的数组,结尾跟着null
指针与数组的关系十分密切。
int a[10];
int *pa;
pa = &a[0]; // 将pa指向a的第0个元素*(pa+1) 与 a[1]是等价的
sizeof 给出一个数据对象在内存中占用的字节数,它不是函数,而是一个运算符。在编译期就被替换成结果。因为它在编译期求值,所以当数组作为参数传入函数后,函数内对参数用 sizeof 得到的是指针的大小,而不是整个数组的大小。同样,没有任何内在方式能在运行期得知数组真实长度。
- 指针运算以元素为单位,而不是字节。
- 数组名就是首元素地址,因此
a与&a[0]等价。 - 指针加减整数时,编译器会根据所指类型自动进行地址缩放。
- 指针相减得到的是两个指针之间相隔的元素数量,而非字节数。
- 指针比较和相减仅在指向同一数组(或尾后位置)时才有定义。
指针与数组容易踩坑的点
指针的大小取决于架构,不是数据类型。 指针存的是地址,在 32 位机器上占 4 字节,在 64 位机器上占 8 字节——和它指向
char还是double无关。本讲开头说"地址位宽 32bit"是按 32 位机的约定;但例题 3 在 Apple M1(64 位)上sizeof(指针)得到的是 8,这正是同一段代码在不同位宽机器上结果不同的根源。写依赖指针大小的代码前一定要确认目标架构。a与&a地址相同、类型不同。 数组名a退化成"指向首元素的指针",a + 1跨过一个元素;而&a的类型是"指向整个数组的指针",&a + 1跨过整个数组。两者打印出来的地址值一样,加 1 后却差了一整个数组的字节数——非常隐蔽。数组退化(array decay)会丢失长度信息。 数组一旦作为参数传入函数,就退化成裸指针,
sizeof只能得到指针大小(4 或 8),无法还原数组长度。所以长度必须额外作为参数传进去,没有任何运行期手段从指针反推数组有多大。void *不能做指针算术。 因为不知道元素大小、无法缩放(GCC 把它当作 1 字节是非标准扩展)。要算术先转成具体类型的指针。越界访问不会报错,但是 UB。 C 不做边界检查,越界读写可能"看起来正常",也可能悄悄破坏相邻变量,是最难复现的一类 bug。


从我的macbook m1 64位程序来说,得到72。 因为,sizeof(ai) 得到的是8,因此循环计算了8次。
如果是32位机器,下面打印如图

函数指针
普通指针保存的是变量的地址, 而函数指针保存的是函数的指针。
int (*comp)(void *, void *);很多初学者都会觉得难懂,其实一步一步读就行。
- 先找到变量名,外面有
(*comp),说明comp是一个指针 - 继续往右看,它指向的是一个函数,这个函数有两个参数。
- 最后最左边,它返回int
comp 是一个指向函数的指针,这个函数接受两个 void* 参数,返回 int。
(*pfa[])()- 找到变量名
[]: 说明pfa是数组*: 说明数组里面的元素是指针- 右边,
()说明这些指针指向函数,
结论: pfa是一个向函数指针数组
字符串
字符串在 C 里是字符数组(char array),用一个常量指针表示,采用 ASCII 编码,以空字符 '\0'(null char)标记结尾。ASCII 用 8 位,共 256 种可能,实际只用了前 128 个。注意:'A'(单引号)是字符 65,"A"(双引号)是字符串。函数读取字符串时会一直读到遇见 '\0' 为止。
字符串函数
在string.h的函数
strlen返回字符串长度(不含'\0',与sizeof不同)。strcpy把源串复制到目标串直到遇到'\0',若目标空间小于源串会溢出(overflow)并破坏相邻内存;strncpy最多复制 n 个字符,控制更精确。
strcat把源串拼接到目标串末尾(找到末尾\0开始写入),同样可能溢出;strncat最多拼接到第 n 个字符。
strcmp比较两个字符串:相等返回 0;在第一个不同的字符处,若 s1 的字符 ASCII 大于 s2 则返回正数,小于则返回负数。strncmp最多比较 n 个字符。
strchr查找某字符在串中第一次出现的位置,返回指向该处的指针,找不到返回 NULL。strrchr查找最后一次出现。前者找到就停,后者必须扫描完整串
sprintf类似 printf,但把格式化结果写入一个字符串而非终端。返回值是本次写入的字符数strstr:在字符串中查找子串。strstr(haystack, needle)在字符串 haystack 里查找子串 needle 第一次出现的位置,找到就返回指向该位置的指针,找不到返回 NULL。strrchr:从后往前找字符,意味着找最后一次出现的位置
strtok: 把字符串按分隔符切成多段。它的用法比较特殊:第一次调用时传入要切割的字符串;后续每次调用传 NULL,表示继续切割同一个字符串,直到切完返回 NULL。strtok 有两个需要特别注意的地方。c// strtok(str, delimiters) char str[] = "Hello,World,Foo"; char *token = strtok(str, ","); // 第一次调用,传入 str while (token != NULL) { printf("%s\n", token); token = strtok(NULL, ","); // 后续调用传 NULL } // 依次输出: // Hello // World // Foo- 第一,它会修改原字符串:每次切割时,strtok 会把找到的分隔符直接替换成
'\0',所以原始字符串会被破坏;如果你之后还要用原串,应该先拷贝一份再传给 strtok。 - 第二,它内部维护了一个静态指针(static pointer)来记录上次切割到了哪个位置,这就是为什么后续调用传 NULL 它还能接着往下切;但这也意味着 strtok 不是线程安全的——如果两个地方同时在用 strtok 切不同的字符串,它们会互相干扰。
- 第一,它会修改原字符串:每次切割时,strtok 会把找到的分隔符直接替换成
atoi: 将字符串转换成int类型
字符串容易踩坑的点
字符串字面量是只读的。
char *s = "hello";让s指向只读区,s[0] = 'H';是未定义行为(多半段错误)。要修改内容必须用数组:char s[] = "hello";(这会把字面量拷贝到栈上的可写数组)。char *和char []看起来都能存字符串,可写性却天差地别。strncpy不保证以'\0'结尾。 当源串长度 ≥ n 时,strncpy只复制 n 个字符、不补结尾的'\0'。之后把目标当字符串用就会越界读到内存里的垃圾。"安全版本"反而藏着这个坑,通常要手动补一句dst[n-1] = '\0';。比较字符串内容必须用
strcmp,不能用==。s1 == s2比较的是两个指针(地址)是否相同,而不是内容是否相等。内容比较一律用strcmp(s1, s2) == 0。缓冲区大小要算上
'\0'。 存放 n 个字符的字符串需要 n + 1 字节空间。少留一个字节,'\0'就会写到相邻内存,是经典的差一错误(off-by-one)。strlen是 O(n) 的。 它每次都从头扫到'\0'。在循环条件里反复调用strlen(或反复strcat找结尾)会让算法退化成——这正是下面例题 4 第一版慢的原因。

分析: 第一个版本性能弱,因为每次调用 strcat 都重复需要从头开始扫描找到null的位置。
第二个版本更好,利用sprintf的返回值是每次写入的字符数的特性,将tally作为游标。
结构体
结构体类似 Python 里的类,但只能包含变量(成员),不包含函数。用 . 访问成员;为避免直接复制大型结构体(参数按值传递会产生大量拷贝),通常传指针;通过指针访问成员时先解引用再取成员,可用 (*ptr).member 或更常用的 ptr->member。
C 中所有函数参数都是按值传递,结构体也不例外。这意味着把结构体直接传进函数时,整个结构体会被完整复制一份,函数内部操作的是副本,对原件没有任何影响。如果想让修改生效,一种办法是让函数返回修改后的结构体,再覆盖原来的变量:
our_course = make_subject2(our_course);但这种做法有两个代价:传入时要复制一遍,返回时又要复制一遍,既浪费时间又浪费内存,结构体越大开销越明显。
更好的做法是传指针。和其它类型一样,结构体也可以有指向它的指针。通过指针,函数拿到的是结构体在内存中的地址,可以直接修改原件,不需要任何复制,相当于间接实现了按引用传递。
void make_subject3(struct Subject *s);
make_subject3(&our_course); // 传入 our_course 的地址这样 make_subject3 内部通过指针 s 修改的就是 our_course 本身,函数返回后 our_course 的值已经被改好了,不需要再用返回值覆盖
通过指针访问结构体成员时,需要先解引用(dereference)再取成员。写法上有两种等价形式
(*s).units = 12;// 因为.的优先级比*高s->units = 12;// 但写起来更简洁,实际代码中几乎都用这种形式
结构体的初始化
// 声明但没有初始化
struct Subject our_course;
// 声明并且初始化
struct Subject other_course = {9, 12, "9.01: Intro Brain Stuff", 100};
// 声明并初始化
struct Subject other_course = {.dept=9, .units=12, .name="9.01: Intro Brain Stuff", .num_students=100};Null
在C语言中, Null的语义是 none,
结构体容易踩坑的点
sizeof(结构体)通常大于成员大小之和——因为内存对齐(padding)。 编译器会在成员之间插入填充字节,让每个成员落在它对齐要求的地址上(如 8 字节的double要落在 8 的倍数地址)。例如:cstruct A { char c; int i; char d; }; // 很可能 sizeof == 12,而不是 6 struct B { int i; char c; char d; }; // 重排后很可能 sizeof == 8成员声明顺序会影响结构体大小:把大的、对齐要求高的成员放前面、小的归拢在一起,能减少填充。这点在算内存、做序列化、和硬件/文件格式打交道时极易被忽视。
结构体不能用
==比较。s1 == s2编译报错;即使能比,padding 里的垃圾字节也会让逐字节比较不可靠。要比较得逐个成员比,或在确保无 padding 时用memcmp。结构体赋值是逐成员浅拷贝。
s1 = s2会复制每个成员的值;如果成员里有指针,复制的是指针本身(两个结构体指向同一块内存),不是它指向的数据。按值传结构体会复制整个结构体。 大结构体按值传参开销很大(前面已说要传指针);同理,按值返回结构体也会整体拷贝。
例题
Sol: *(&vals[7]-2) = val[7]这个地址往回退两个元素,得到值为 15
Sol:每个int类型元素需要4字节,因此, x = x + 3 = x + 3(4) = 12