Lec 8 自定义类型
[toc]
从这节开始,我们探讨一下类(class),它提供一种自定义类型的机制,这种机制能将这些自定义类型整合到 Python 语言中。下面从两个方面讲解
- 环境模型
- 实现原理
我们知道引入抽象概念是作为控制复杂度。我们在Lec2 函数的乐趣中, 我们介绍了一种思考复杂系统的框架,它涉及:
原语:系统由哪些最小和最简单的构建块组成?
组合方式:我们如何将这些构建块组合在一起,构建更复杂的复合结构?
抽象手段:我们有哪些机制可以将那些复杂的复合结构视为构建块本身?
我们从思考原语开始:
- 我们必须使用的内置在系统中东西是什么?
- 然后,我们可以考虑如何将这些部分组合在一起,以制作更复杂的东西。
- 最后,要理解真正的能力最终是来自于抽象:我们可以拿一个任意复杂的部分,给它画一个框,给它一个名字,然后将它视为基本部分(与其他部分组合,抽象掉这些部分等)。
在这种情境下,我们可以考虑原语操作,包括算术(+,*等),比较(==,!=等),布尔运算符(and,or等),内置函数(abs,len等),等等。然后,我们可以通过条件语句(if,elif,else),循环结构(for和while),和复合函数(f(g(x)))将这些东西结合在一起。当我们将这些小的操作结合一起来表示一些新操作后,我们可以将这些新操作的细节抽象出去,并通过使用def或lambda关键字定义函数,将它们当作从一开始就内置到Python中的东西来对待。
python还提供了一些机制来创建我们自己的数据类型,那就是class,该关键字为我们提供了一个很好的方法来创建我们自己的数据类型,并将它们紧密集成到Python中,使其行为就好像它们一开始就内置在Python中一样。
环境模型
为了方便理解环境模型,我们会从非惯用的class用法开始分析,不断增加复杂度。
首先看一个例子, 二维向量。 当我们创建了类,我们就可以创建这个类的实例来表示二维向量。下面是最简单类。
class Vector2D:
passclass关键字就做了两件事
- 在堆栈上创建了一个对象表示这个类
- 在我们遇到类关键字时,它将该类对象与帧中的名称(即Vector2D)关联起来。
当我们运行上述代码时,我们从全局帧(global frame,GF)开始,第一条语句就是class的定义,因此它会创建一个新的类对象,我们用一个框来表示(跟函数一样),不同的是,我们需要给他带上标签class帮助我们跟踪。在创建新的类对象之后,Python 接下来执行类的body中的代码(以一种特定的方式进行,我们很快会详细说明)。 这里我们的类体只是 pass,所以没有什么可做的。最后将新的类对象与在全局帧的名称Vector2D关联起来
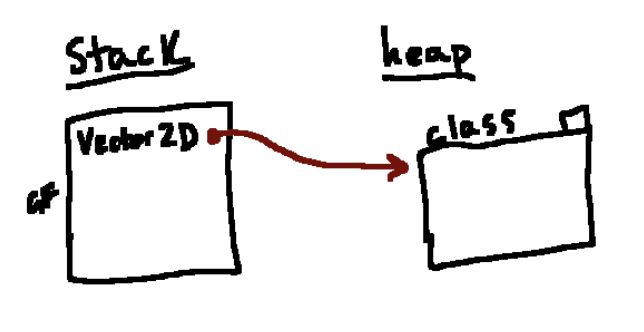
值得注意的是,尽管我们将类对象以类似于绘制函数对象的方式绘制,但类没有enclosing frames。我们仍然在类的右上角上画一个小标签,但这将具有不同的含义,我们稍后将更详细地讨论。
接下来,当我们用一下语句创建类的实例
v = Vector2D()Python首先访问括号左侧的内容,以确定我们将要调用哪个对象。在这种情况下,这是通过跟踪名称Vector2D得到的,即我们刚刚在上一步中创建的类对象。在Python中,当我们使用这种语法调用一个类对象时,Python会通过创建一个代表该类的实例的新对象来继续。
我们用类似的框来表示这个实例,加上instance标签,每个实例还会保存这个类的引用,并且与名称v进行关联,得到
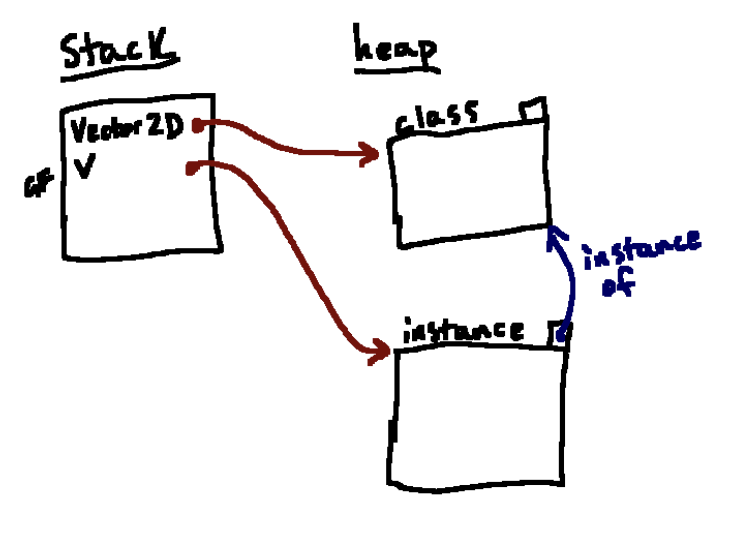
接下来我们用
v.x = 3
v.y.= 4当执行第一个语句时, 我首先会在heap中创建一个int 3的对象, 找到对象 v 引用的对象,在获得对象之后,Python 会在这个对象的内部将名称 x 与3相关联。得到的结果如图。
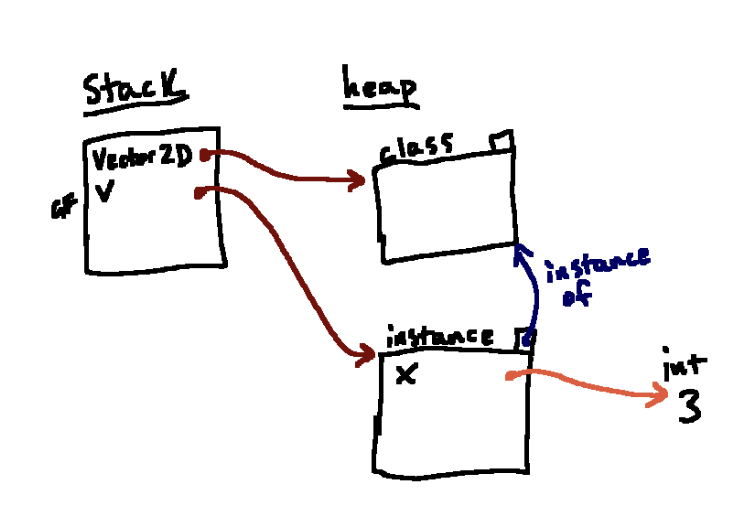
我们称这种关联(在实例对象的内部,而不是一个帧)称为这个对象的属性。
继续看下面例子
class Vector2D:
pass
v = Vector2D()
v.x = 3
v.y = 4
def magnitude(vec):
return (vec.x**2 + vec.y**2) ** 0.5
magnitude(v)我们观察如何执行 magnitude(vec) ,首先我们evaluate vec,得到我们刚刚创建的实例对象(有属性x和y),然后我们知道了我们将要传入的参数。
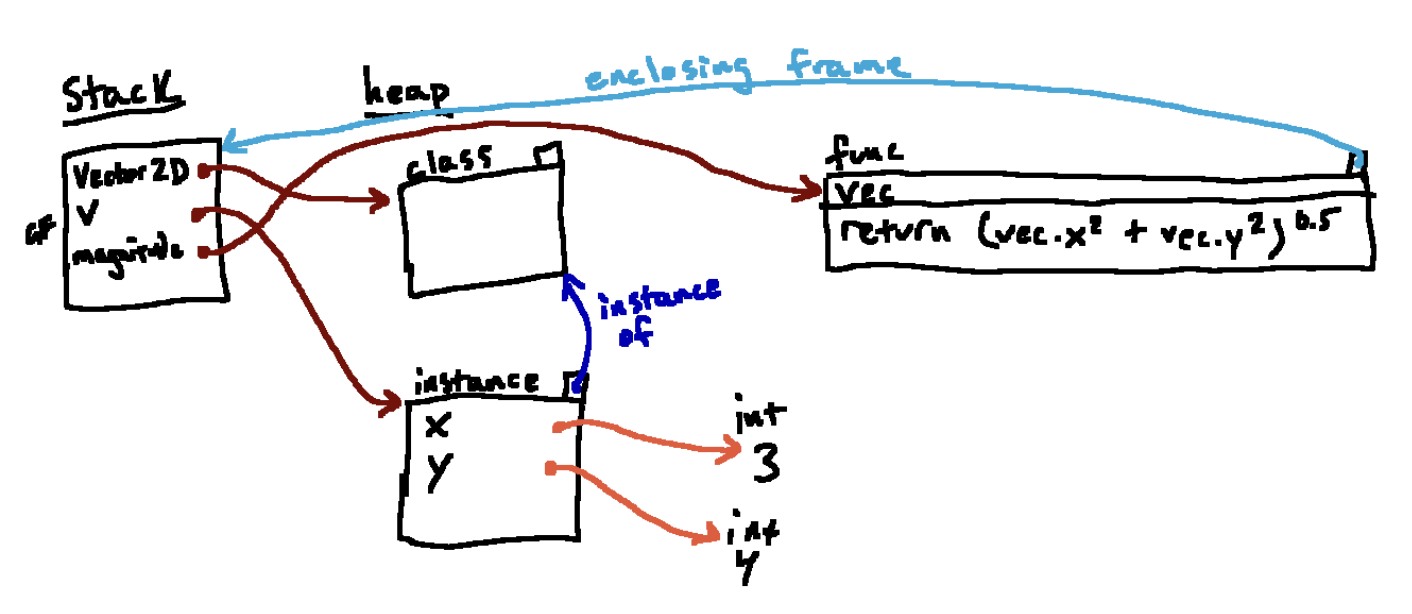
我们知道调用函数就是创建新的帧。但是我们还没有标注它的父指针指向哪个?即,还不知道这个函数的enclosing frame
Review: Enclosing frame(封闭帧)是指在函数调用栈中,一个函数的执行环境(或帧)所依赖的外部函数的执行环境(或帧)。具体来说,它是一个函数的局部作用域以外的更外层的作用域,也就是说,它是一个函数的父作用域。)
因为我们调用的这个函数有全局帧GF作为它的enclosing frame,所以全局帧就是F1的父指针。因为我们已经创建了新帧,现在我们已经设置好了我们的帧,下一步是在新帧上将函数的参数绑定到传入的参数上。
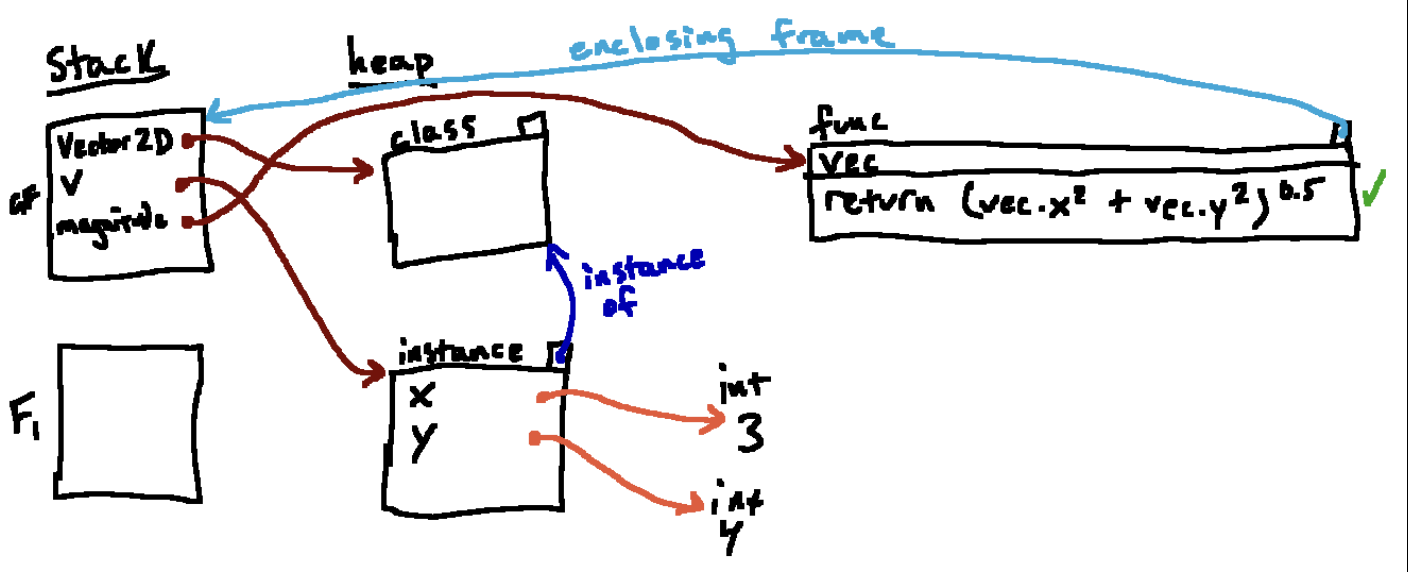
函数的参数vec指向我们传入的参数(即在全局帧中称为v的实例),做完这些以后,就可以运行函数体了
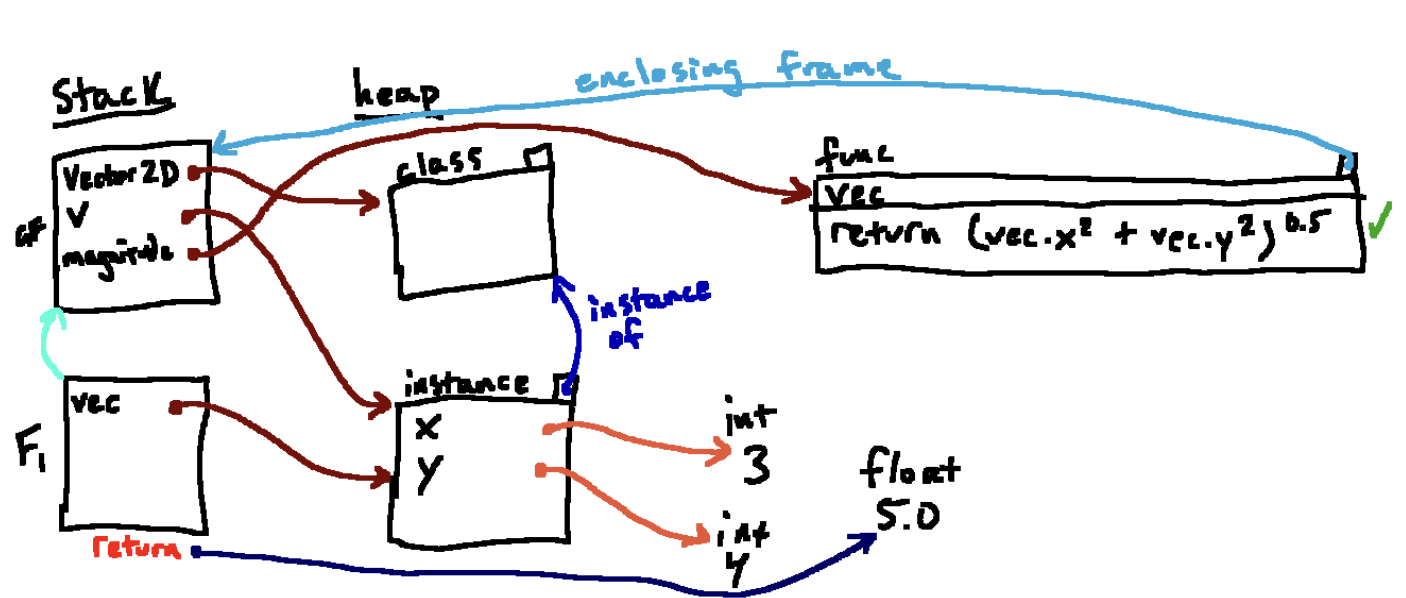
到这里, 这里我们跳过了中间值的创建和垃圾回收。
值得注意的是,这个函数(magnitude)不仅限于仅在 Vector2D 类的实例上运行;它可以适用于任何具有属性 x 和 y,这两者都指向数字的对象。这是一种名为“鸭子类型”的哲学,它来自这样一个思想:如果某物看起来像鸭子,嘎嘎叫起来像鸭子,那么把它当作鸭子是可以的;在这种情况下,如果某物看起来像向量,像向量一样(具有包含数字的属性 x 和 y),那么可以用这个函数。与其他方法相比,对这种方法有不同的看法(有些语言可能更严格地处理类型),但 Python 通常在这类事情上非常灵活。
然而,很明显,这个函数应该与 Vector2D 类一起使用。但就目前而言,在代码方面它们实际上并没有任何连接。从代码清晰度的角度来看,让 magnitude 函数(用于与 Vector2D 实例一起工作的)与 Vector2D 有某种关联会很好。也许我们可以通过将函数命名为 vector_magnitude 来使这种关系更清晰,但即使如此,这种关联也相当弱。因此,让我们对代码进行一点小改动,将 magnitude 函数的定义放在 Vector2D 类的主体内部:
class Vector2D:
ndims = 2
def magnitude(vec):
return (vec.x**2 + vec.y**2) ** 0.5
v = Vector2D()
v.x = 3
v.y = 4Python看到类定义时,像以前一样创建一个新的空类对象。但是,然后,Python会运行类定义的主体,遵循一些特殊规则:
- 我们在该定义中绑定的任何名称都将作为类的属性创建,而不是作为帧中的变量。
- 当我们在类定义体中查找一个名称时,优先查找已定义的类属性,如果名称在类属性中不存在,我们接下来会在定义类时所处的作用域中查找这个名称
请注意,这些规则仅在求解我们正在创建的类的body时适用;以后我们将有不同的名称查找规则。下面我们用环境图进行分析。
类定义,在堆区创建一个类框,接着往下执行类body,同样的,我们给类框内的属性ndims与代表2的int 对象 进行绑定,因为这是发生类定义里面的,因此只作为全局帧的变量。再后面是magnitude的定义。
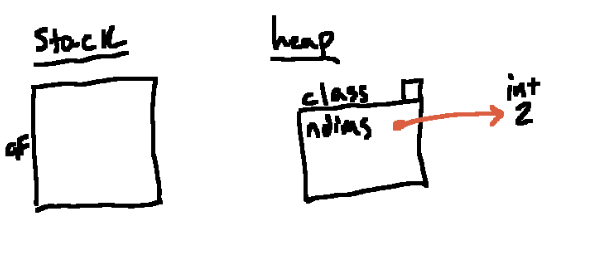
以下是函数定义的结果,需要提及的是
magnitude是绑定在类对象的属性,不是全局帧的变量- 但是, 函数的封闭帧(我们)却仍然在全局帧
这可能感觉有些奇怪,但以这种方式运作是至关重要的,我们将看到一些为什么事情需要以这种方式运作的例子。现在我们已经创建了这个函数对象,我们来到了类定义的底部,并且完成了构建类对象的步骤。接下来的步骤是将该类与全局帧中的名称Vector2D相关联,我们将在下一步展示。
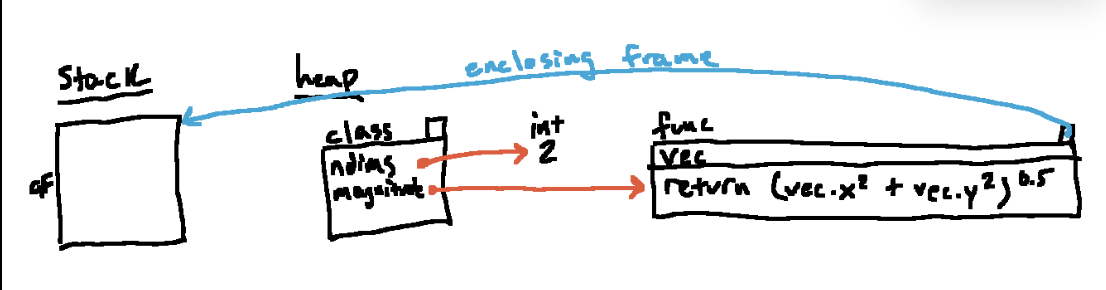
类定义后面执行步骤跟前面的例子相同,这里不再赘述,直接给出最终的环境图
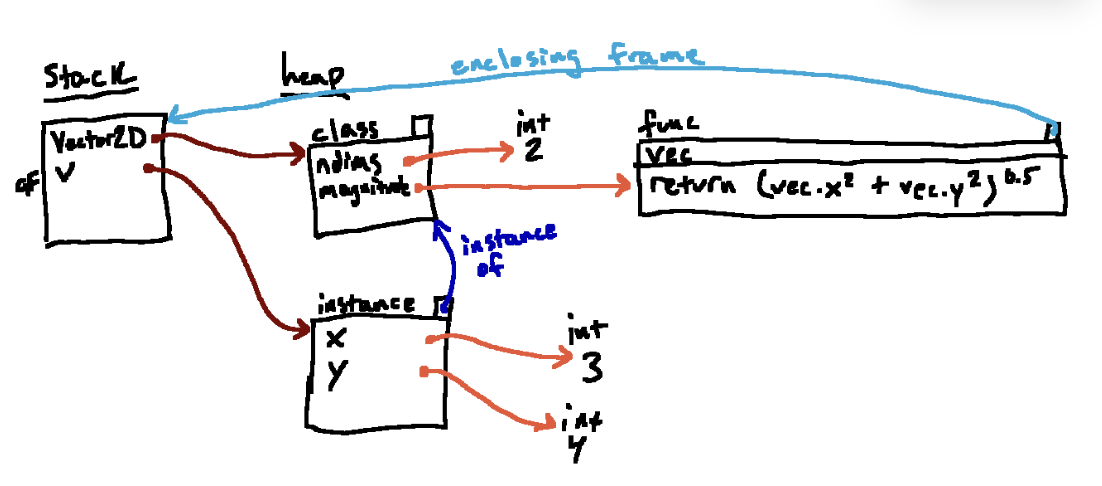
vs 对比之前的
调用方法
常见的调用方法的方式是v.magnitude(),这种调用方式会产生与我们之前调用的Vecotr2D.magnitude(v) 相同的结果。这有点奇怪,我们似乎在没有参数的情况下调用了它。Python实际上在进行一些魔术以使事情变得这样。实际细节有些复杂,但我们可以这样想Python在做什么:当我们通过实例查找方法时,Python会找出它是一个实例的哪个类,然后在该类中查找给定的方法,然后隐式地将该实例作为第一个参数传递进去。因此,我们可以认为这是一种转换,其中调用 v.magnitude() 被转换为 Vector2D.magnitude(v) 。
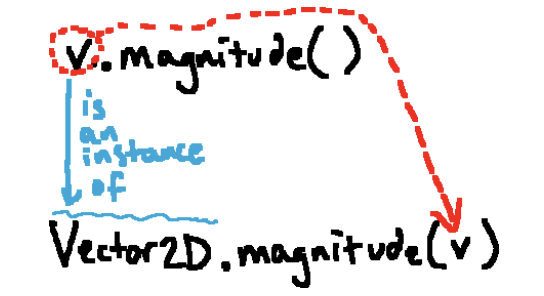
值得一提的是,这并不是实际发生在后台的情况。但对于大多数应用程序来说(实际细节足够复杂!),这是一种非常近似的解释,但我们只需要这样理解就够了,因为真的足够复杂。 广义地说,如果我们通过该类的实例查找类方法,那么我们用于查找的实例将被隐式传递为第一个参数。由于这个过程发生在实际调用方法之前,所以无论我们使用 Vector2D.magnitude(v) 还是 v.magnitude() ,实际调用给定方法的过程的环境图表示都是相同的;它们都导致如下所示的图
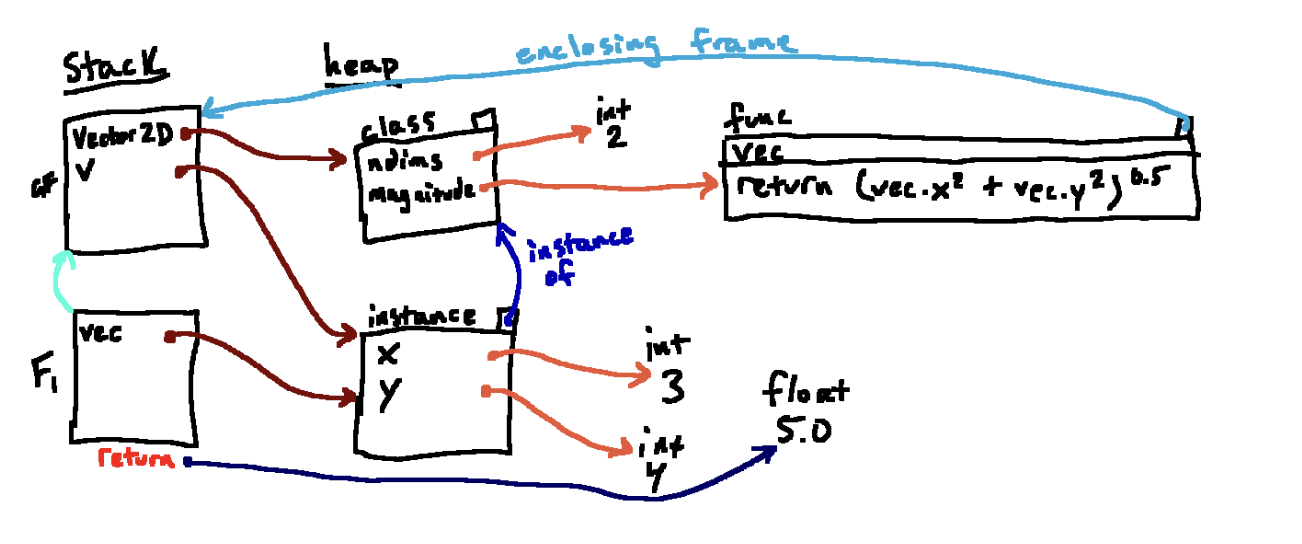
IMPORTANT
print(v.magnitude(v)) 会发生什么?
A: TypeError: Vector2D.magnitude() takes 1 positional argument but 2 were given
self的本质
如果你以前用过 Python 的类,你可能会对这里缺少一个常见的词感到惊讶。通常,当你在“真实世界”中看到 Python 代码时,类方法会有一个名为 self 的第一个参数。但是在这里,self 是缺失的。我们将简要讨论一下 self 的本质。 实际上,它不是一个关键字,也不是一个内置对象或类似的东西。它只是一个用来命名方法的第一个参数(完全是一种命名惯例)
这里澄清了 self 并不是 Python 中的特殊关键字或内置对象,而只是一个非常强烈的命名惯例,用来指代类实例的方法的第一个参数。
当我们该写成
class Vector2D:
ndims = 2
def magnitude(self):
return (self.x ** 2 + self.y ** 2) ** 0.5对我们的程序没有实际的影响,只是将参数名称从vec改成了self而已
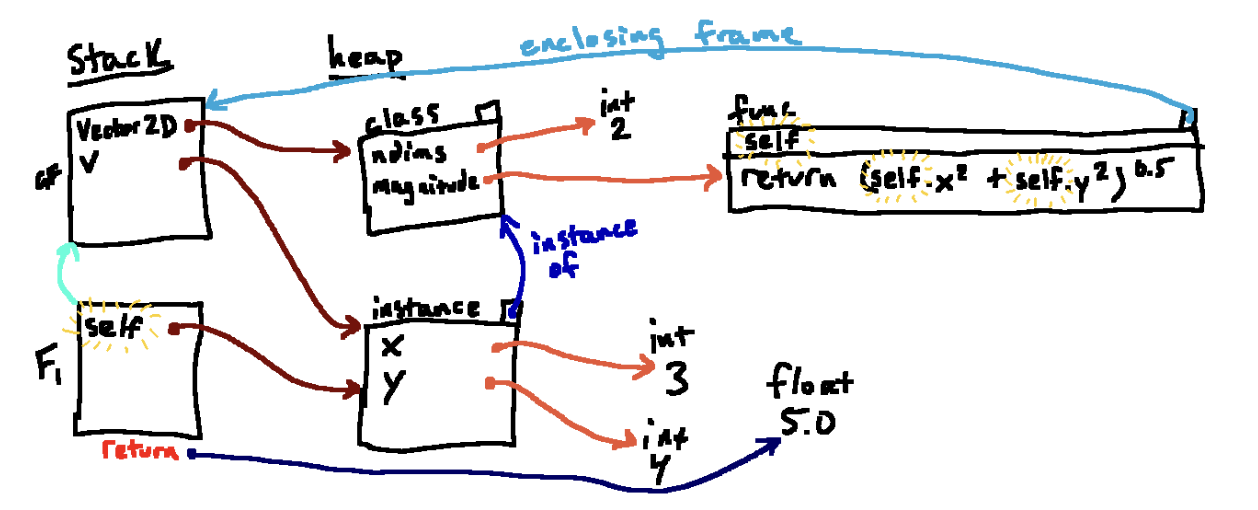
值得遵循惯例。除了每个人都在这样做之外,选择 self 这个名字的另一个原因是它与经常伴随类的引入而产生的观念转变:向“面向对象”的思维转变。从 Vector2D.magnitude(v) 到 v.magnitude() 的转变伴随着视角的转变:在表达式 Vector2D.magnitude(v) 中,感觉好像函数是这里的主动主体。我们是在说:“嘿,Vector2D.magnitude,这里有一个向量,我希望你计算其大小。”当我们改为写成 v.magnitude() 时,计算细节并没有改变,但在这种形式下,感觉像是 v 现在是主动实体。这更像是在说:“嘿,v,告诉我你的大小!”当我们采用这种第二视角时,self 这个名字开始感觉是一个不错的选择。它是关于我们正在询问这些问题的实例,并且这个实例正回答关于自己的这些问题。
在我们继续之前,让我们再多谈一点关于 self。我们学习了环境图中的名字解析:当我要求Python查找一个名称时,它在何处以及如何查找该名称?我们在这里引入了另一套独特的名字解析规则。下面将更具体和清晰解释,两种类型的名字解析规则,并希望通过这种方式让你思考,如何在你自己的程序中使用 self。
我们在课程早期设立的规则是关于查找帧内变量的:该过程总结如下:
帧内变量的查找步骤:
- 先查找当前帧
- 如果未找到,在父帧中查找
- 如果未找到,查找那个帧的父帧(继续跟随该过程,在父帧中查找)
- 如果未找到,查找全局帧如果未找到,
- 查找内置变量(诸如 print、len 等的绑定)
- 如果未找到,引发 NameError
我们在这里引入的是一个另外的东西,我们称之为属性查找。这个概念是我们已经找到一个对象,而不是在帧内查找一个变量,我们想要在该对象内部查找一些内容。
属性查找
- 首先查找对象本身
- 如果未找到,则查找该对象的类
- 如果未找到,则查找该类的超类
- 如果未找到,则查找该超类的超类
- 如果未找到且没有更多的超类,则引发 AttributeError。
还要注意,属性查找过程永远不会跨越到当前函数的栈帧之外;它是一个完全独立的过程。
一个例子
class Vector2D:
ndims = 2
def magnitude(self):
return (self.x ** 2 + self.y ** 2) ** 0.5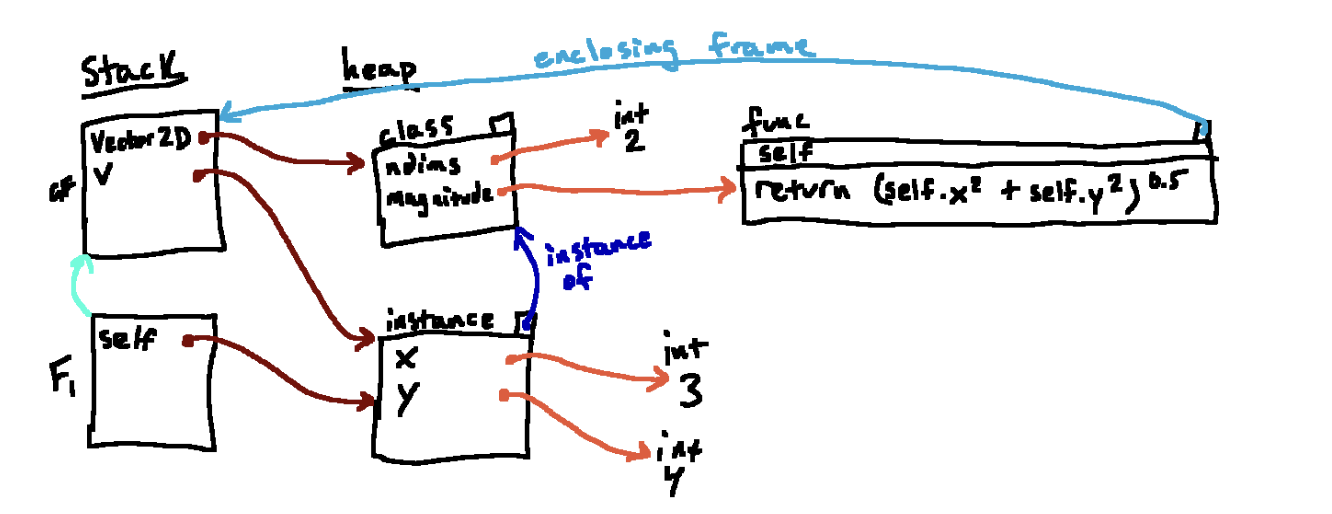
如果magnitude函数变成
return (x**2 + y**2)**0.5已经return了,将会发生什么?
在这种情况下,我们需要evaluate x 。 在 F1 中查找 x,我们找不到它。 因此,我们在全局帧中查找 x。 也找不到那里! 而且没有名为 x 的内置函数,因此我们最终会遇到一个 NameError。
结果表明, 为什么magnitude函数的封闭帧选择全局帧而不是 Vector2D 的类。这样设置可以确保我们既可以访问我们正在处理的实例的信息,也可以从我们帧结构中获取信息。我们可以通过 self 的方式查找属性,也可以与在任何其他函数中一样的方式在环境中查找变量。
__init__魔法函数
1. class Vector2D:
2. ndims =3
3. def __init__(self, x, y):
4. self.x = x
5. self.y = y
6. def magnitude(self):
7. return (self.x ** 2 + self.y ** 2) ** 0.5环境图分析
当我们运行完类定义时如图所示。。现在我们运行 v=Vector2D((6, 8))
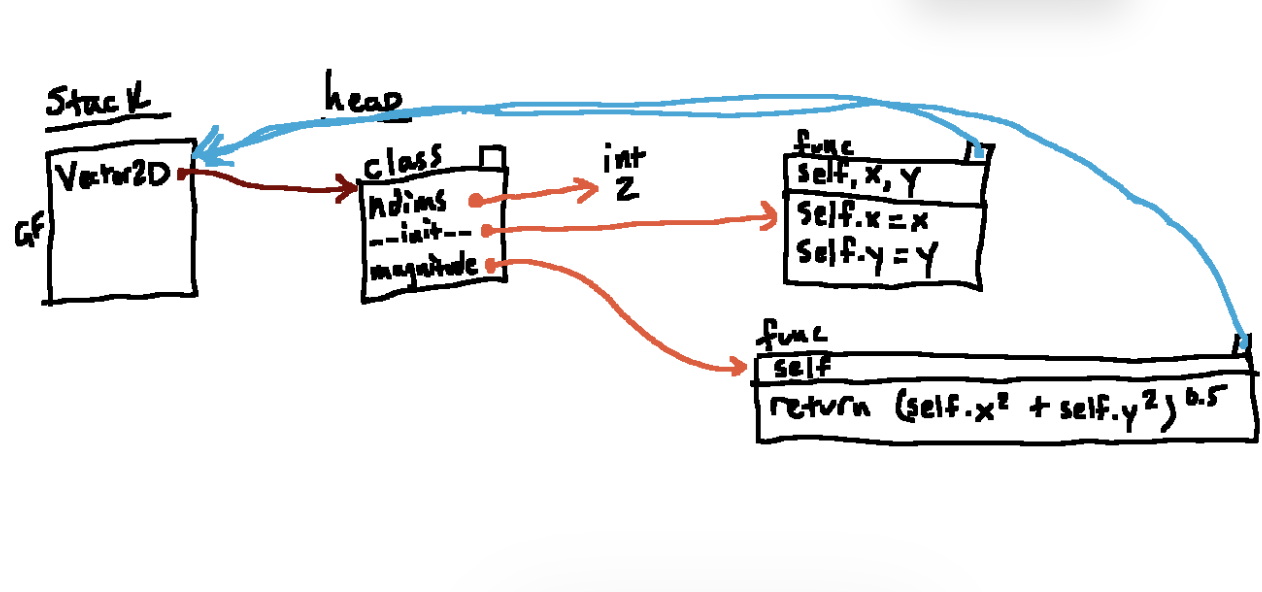
首先我们,创建了6,8的int对象,以及一个空的的实例,然后,由于__init__方法在”属性查找链“上,Python使用我们新创建的实例作为第一个参数隐式调用该函数,然后我们找到传给他的参数。第一个是python隐式传入的实例对象,第二第三是我们刚刚创建6,8对象,然后在新帧F1内将参数绑定到传入参数上。
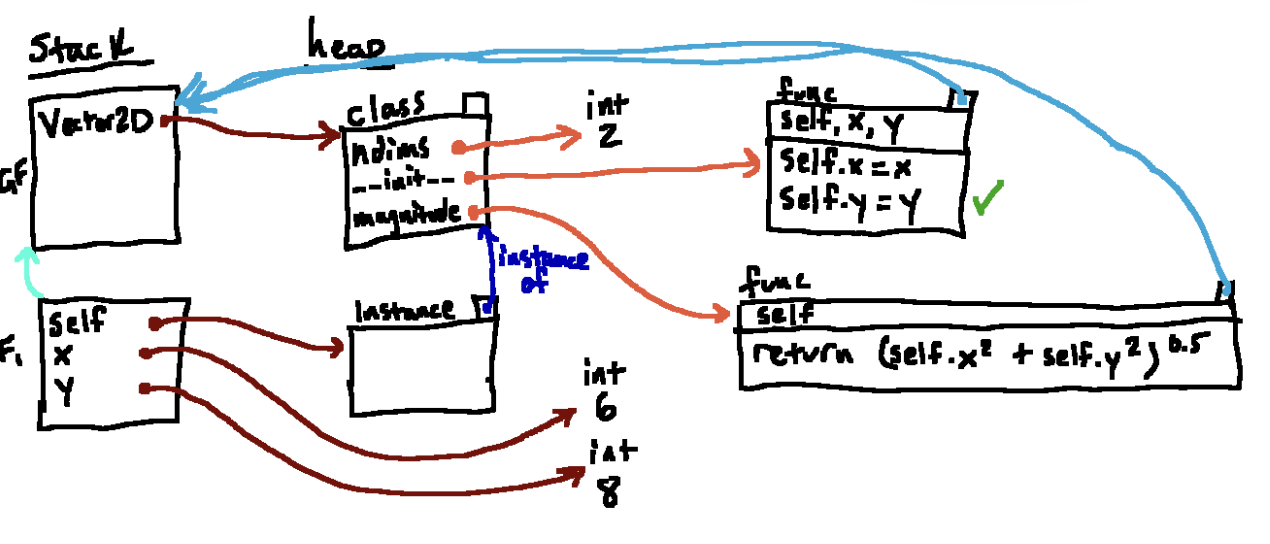
再接下来,我们准备运行函数体,以下是执行完self.x = x的结果。跟一般的赋值语句一样,我们从F1帧找到找到名称x对应的int 对象6,然后我们在F1找到self,顺着箭头找到对应的实例队形啊个, 在里面创建了一个属性x,将它指向对象6。 执行self.y = y同理, 到这里我们执行到__init__函数的末尾,然后我们准备清除F1帧
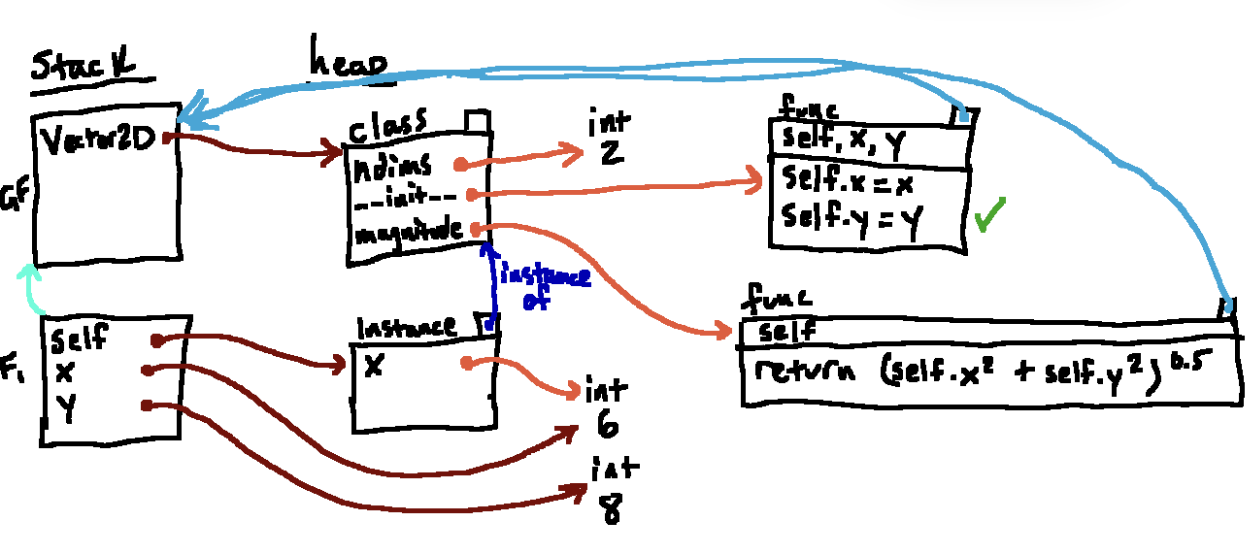
下面是清除完F1帧的状态
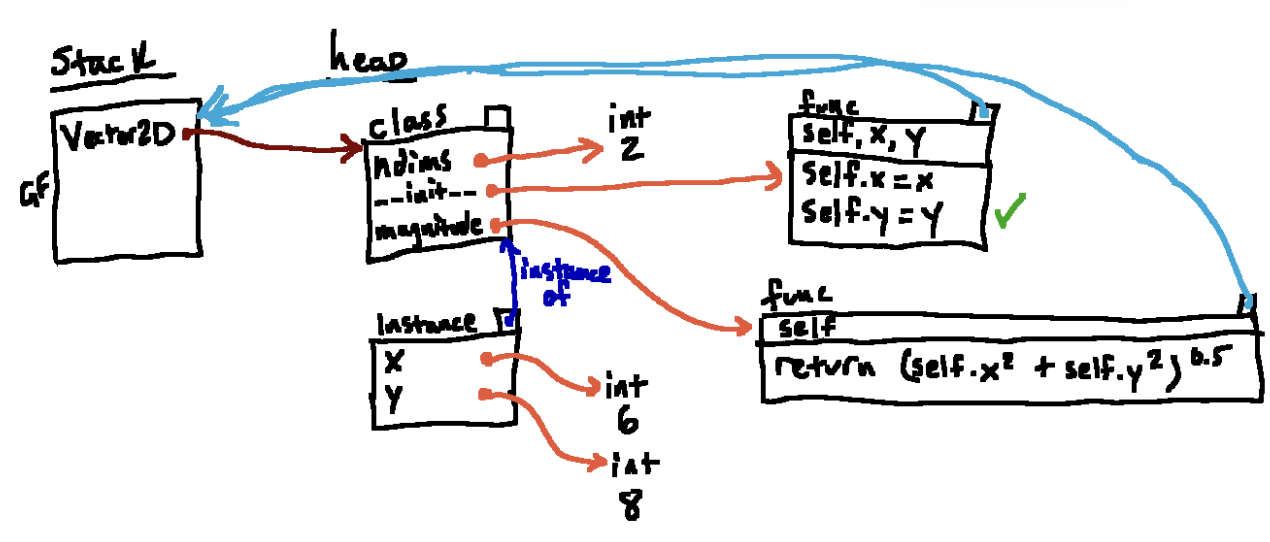
我们的原始目标是在全局帧执行v = Vector2D(6 ,8)最终结果如图
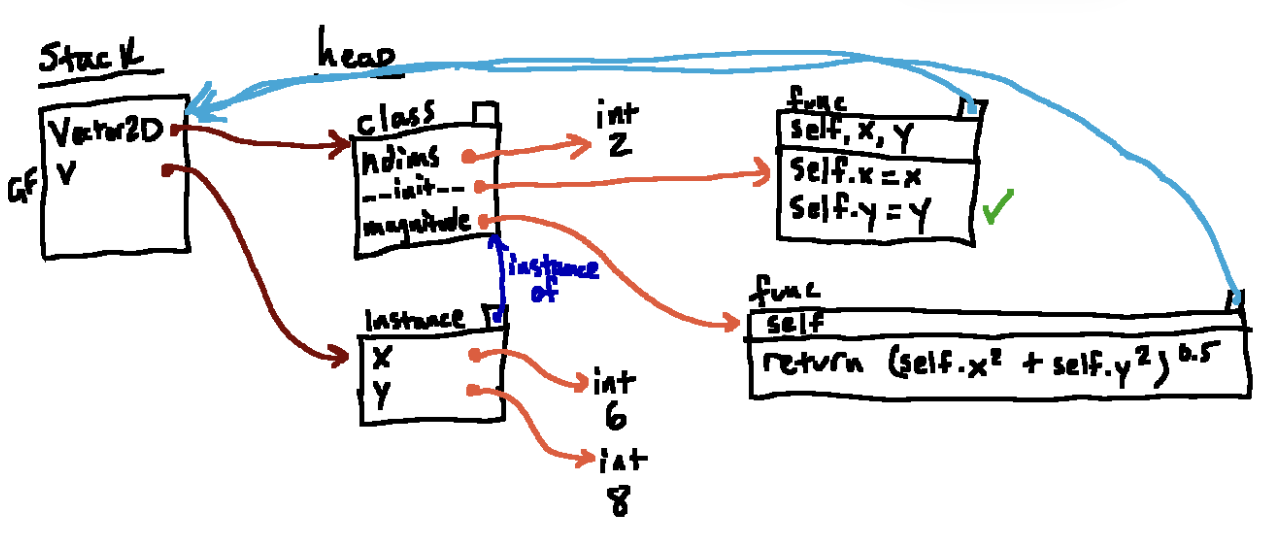
init 不是 Python 隐式调用的唯一方法。 Python 给我们提供了许多方法,通过其他“魔术”方法,我们可以实现与语言更紧密集成我们的自定义类型。我们可以将其中大多数视为翻译。例如: print(x) 隐式翻译为 print(x.str()) abs(x) 隐式翻译为 x.abs() x + y 隐式翻译为 x.add(y) x - y 隐式翻译为 x.sub(y) x[y] 隐式翻译为 x.getitem(y) x[y] = z 隐式翻译为 x.setitem(y, z)
案例: 链表
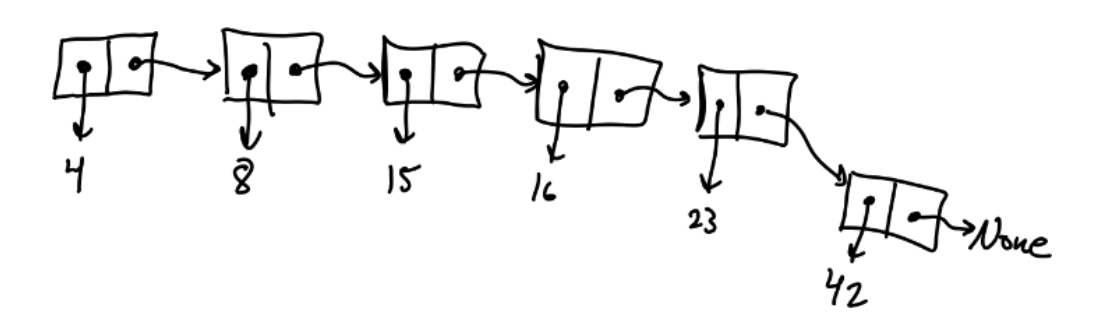
class LinkedList:
def __init__(self, element, next_node=None):
self.element = element
self.next_node = next_node
def get(self, index):
pass
def set(self, index, value):
pass
x = LinkedList(4,
LinkedList(8,
LinkedList(15,
LinkedList(16, LinkedList(54)))))
# 获取一个元素
## 迭代版
def get(self, index):
for _ in range(index):
self = self.next_node
return self.element
## 递归版
def get(self, index):
if index == 0:
return self.element
if self.next_node is None:
raise IndexError('index out of range!')
return self.next_node.get(index-1)
## 设置一个元素
def set(self, index, value):
if index == 0:
self.element = value
if self.next_node is None:
raise IndexError('index out of range!')
return self.next_node.set(index-1, value)这里有很多相似之处。特别是,通过链表递归方式工作以查找给定索引处的节点(包括在适当时间引发异常)的代码在两个函数中几乎完全重复! 当然,不同的是,当我们到达正确的节点时,我们会做什么。在 get 的情况下,我们希望返回该节点的 element 属性;在 set 的情况下,我们想要修改该节点的 element 属性。 因此,我们可以编写一个帮助程序,在给定的索引处返回节点(而不是元素),然后 get 和 set 都可以根据该帮助程序实现。 在查看下面的解决方案之前,请尝试编写此代码:
def _get_node(self, index):
if index = 0:
return self
elif self.next_node is None:
raise IndexError('index out of range!')
else:
return self.next_node._get_node(index-1)
def get(self, index):
return self._get_node(index).element
def set(self, index, value):
self._get_ndoe(index).element = value为了做到这一点,我们需要显式调用 get 和 set 方法,如果我们可以使用我们更熟悉的语法来获取和设置元素,那就更好了。 只需要一个微小的改变就可以做到这一点。特别是,如果我们将这些方法的名称分别更改为__getitem_ 和 __setitem__,那么上面的示例将无需任何其他更改即可工作。 这种变化导致方法仍然可以像正常调用一样调用
x.set(3, 'cat')
# 实现了"填鸭方法”(Dunder Methods) 后
x[3] = 'cat'同样的,print也有填鸭函数如果直接print,将输出
<__main__.LinkedList object at SOME_MEMORY_LOCATION>如果实现了__str__()方法后,比如
def __str__(self):
return f"LinkedList({self.element}, {self.next_node})"遍历链表
for elt in x:
print(elt)
## 等同于
for elt in x.__iter__():
print(elt)
# 下面有几种实现__iter__的方式,
## 一种是通过yield每个元素直到经过了整个链表
def __iter__(self):
current = self
while current is not None:
yield current.element
current = current.next_node
## 通过yeild from实现递归
def __iter__(self):
yield self.element
if self.next_node is not None:
yield from self.next_node # 等同于 yield from self.next_node.__iter__()这与常见的递归模式相似,例如处理列表时,通常会先处理列表的第一个元素,然后递归处理其余元素。对于链表,处理第一个节点(node.data)后,通过递归处理其余节点(node.next),直到到达链表的末尾(node 为 None)。
通过这种递归方法,每次递归调用处理一个节点的数据,并通过 yield from 语法自动将递归调用的结果逐步返回给调用者,从而实现链表的迭代。
总结
在本次阅读中我们涵盖了相当多的内容。我们通过从最小的例子开始构建,介绍了类和实例在环境模型中的操作规则,并逐步展示了类的许多特性,往往依赖于我们之前对名称解析和函数的经验。
我们特别仔细地观察了一些类独有的特性,特别是 Python 在某些情况下会隐式地将参数传递给方法(我们也讨论了它的惯用名称 self)。
接着我们介绍了 "dunder" 方法(也称为“魔术”方法),这些方法允许我们使用更简洁、更“Pythonic”的语法来调用某些方法(例如,允许我们使用正常的索引或加法语法来操作自定义类型的实例)。
最后,我们看了一个综合了这些内容的示例,我们开始实现一个表示链表的类;这不仅提供了思考链式数据结构的机会,还展示了一些我们可以如何利用类的方法。
在本周的实验中,你将体验一种不同类型的链式数据结构,称为前缀树,这也将为我们提供更多练习本次阅读材料的机会。在下周的阅读中,我们将扩展这些思想,介绍继承(允许在多个类之间共享结构),并且我们还会更多地讨论面向对象设计,即如何使用这些思想来帮助我们管理代码的复杂性。